



-
摘要:
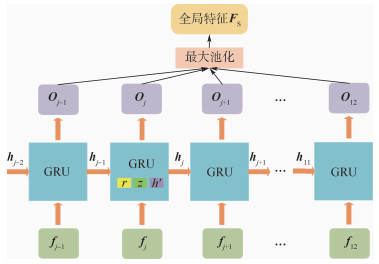
随着媒体数据的多样化发展,联合图像与三维模型的跨域检索成为三维模型检索问题的一个新挑战。针对图像与三维模型差异大、难匹配问题,提出了一种基于三元组网络的跨域数据检索方法。以端到端的方式构建真实图像与三维模型的特征联合嵌入空间,通过特征间的距离度量不同模态数据之间的相似性,实现从单张图像检索相似的三维模型。为了提高跨域检索准确度,将三维模型用一组顺序视图表示,结合门控循环单元(GRU)聚合视图级特征,同时引入注意力机制提取图像特征,缩小真实图像与投影视图间的语义差异。实验结果表明:相比于同类方法,所提方法在两个跨域数据集上的检索平均准确率至少提升2.98%~3.05%。
Abstract:With the diversified development of media data, the cross-domain retrieval between images and 3D models becomes a new challenge for 3D model retrieval. In view that images and 3D models are extremely different and hard to match, a cross-domain retrieval algorithm based on triple network is proposed to construct a joint embedding space for real images and 3D shapes in an end-to-end manner. Then the similarity between different modal data could be effectively computed by the distance in the space, leading to accurate retrieval of similar 3D models from single image. In order to improve the accuracy of cross-domain retrieval, the 3D model was represented by a set of sequential views, and the Gate Recurrent Unit (GRU) was utilized for view-level features to generate the global feature. In addition, an attention mechanism was introduced to extract image features and bridge the semantic gaps between the real image and the rendered 3D views. Experimental results show that the mean average precision can be improved by at least 2.98%-3.05% on two cross-domain datasets compared with other similar algorithms.
-

图 4 基于单张图像的三维模型检索结果示例
Figure 4. Examples of monocular image based 3D model retrieval results
表 1 IM2MN数据集消融实验测试结果
Table 1. Test results of ablation experiment onIM2MN dataset
自适应层 注意力模块 GRU mAP/% 无 无 无 42.16 有 无 无 48.74 有 有 无 51.93 有 无 有 54.48 有 有 有 55.65  下载: 导出CSV
下载: 导出CSV
表 2 MI3DOR数据集消融实验测试结果
Table 2. Test results of ablation experiment onMI3DOR dataset
自适应层 注意力模块 GRU mAP/% 无 无 无 42.78 有 无 无 49.67 有 有 无 53.75 有 无 有 55.24 有 有 有 56.53
下载: 导出CSV
-
[1] BU S H, WANG L, HAN P C, et al.3D shape recognition and retrieval based on multi-modality deep learning[J].Neurocomputing, 2017, 259:183-193. doi: 10.1016/j.neucom.2016.06.088 [2] 蔡轶珩, 王雪艳, 胡绍斌, 等.基于多源图像弱监督学习的3D人体姿态估计[J].北京航空航天大学学报, 2019, 45(12):2375-2384. doi: 10.13700/j.bh.1001-5965.2019.0387CAI Y H, WANG X Y, HU S B, et al.Three-dimensional human pose estimation based on multi-source image weakly-supervised learning[J].Journal of Beijing University of Aeronautics and Astronautics, 2019, 45(12):2375-2384(in Chinese). doi: 10.13700/j.bh.1001-5965.2019.0387 [3] GIRDHAR R, FOUHEY D F, RODRIGUEZ M, et al.Learning a predictable and generative vector representation for objects[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 484-499. [4] TULSIANI S, GUPTA S, FOUHEY D F, et al.Factoring shape, pose, and layout from the 2d image of a 3d scene[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2018: 302-310. [5] IYER N, JAYANTI S, LOU K, et al.Three-dimensional shape searching:State-of-the-art review and future trends[J].Computer-Aided Design, 2005, 37(5):509-530. http://www.sciencedirect.com/science/article/pii/S001044850400140X [6] XIE J, FANG Y, ZHU F, et al.Deepshape: Deep learned shape descriptor for 3d shape matching and retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 1275-1283. [7] MIAN A S, BENNAMOUN M, OWENS R A.Matching tensors for pose invariant automatic 3D face recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2005: 120. [8] KRIZHEVSKY A, SUTSKEVER I, HINTON G E.Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems.Cambridge: MIT Press, 2012: 1097-1105. [9] 杨思晨, 王华锋, 王月海, 等.深度学习机制与小波融合的超分辨率重建算法[J].北京航空航天大学学报, 2020, 46(1):189-197. doi: 10.13700/j.bh.1001-5965.2019.0146YANG S C, WANG H F, WANG Y H, et al.Super-resolution reconstructing algorithm based on deep learning mechanism and wavelet fusion[J].Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(1):189-197(in Chinese). doi: 10.13700/j.bh.1001-5965.2019.0146 [10] GRABNER A, ROTH P M, LEPETIT V.Location field descriptors: Single image 3D model retrieval in the wild[C]//Proceedings of the 2019 International Conference on 3D Vision (3DV).Piscataway: IEEE Press, 2019: 583-593. [11] WU Z Z, ZHANG Y H, ZENG M, et al.Joint analysis of shapes and images via deep domain adaptation[J].Computers & Graphics, 2018, 70:140-147. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=464c4602d6b160c53d6eb7368840f7a7 [12] WOO S, PARK J, LEE J Y, et al.CBAM: Convolutional block attention module[C]//European Conference on Computer Vision.Berlin: Springer, 2018: 3-19. [13] CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[EB/OL].(2014-06-03)[2020-02-25].https://arxiv.org/abs/1406.1078. [14] LEE T, LIN Y L, CHIANG H Y, et al.Cross-domain image-based 3D shape retrieval by view sequence learning[C]//Proceedings of the 2018 International Conference on 3D Vision (3DV).Piscataway: IEEE Press, 2018: 258-266. [15] LI W, LIU A, NIE W Z, et al.SHREC 2019-Monocular image based 3D model retrieval[EB/OL].(2019-01-28)[2020-02-25].https://www.iti-tju.org/MI3DOR19/. [16] FANG Y, XIE J, DAI G, et al.3D deep shape descriptor[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 2319-2328. [17] 李海生, 武玉娟, 郑艳萍, 等.基于深度学习的三维数据分析理解方法研究综述[J/OL].计算机学报, 2019, 42: 1-25.(2019-07-09)[2020-02-21].http://kns.cnki.net/kcms/detail/11.1826.TP.20190709.1509.002.html.LI H S, WU Y J, ZHENG Y P, et al.A survey of 3D data analysis and understanding based on deep learning[J/OL].Chinese Journal of Computers, 2019, 42: 1-25.(2019-07-09)[2020-02-21].http://kns.cnki.net/kcms/detail/11.1826.TP.20190709.1509.002.html(in Chinese). [18] OSADA R, FUNKHOUSER T, CHAZELLE B, et al.Shape distributions[J].ACM Transactions on Graphics (TOG), 2002, 21(4):807-832. doi: 10.1145/571647.571648 [19] MAHMOUDI M, SAPIRO G.Three-dimensional point cloud recognition via distributions of geometric distances[J].Graphical Models, 2009, 71(1):22-31. http://www.sciencedirect.com/science/article/pii/S1524070308000313 [20] SUN J, OVSJANIKOV M, GUIBAS L.A concise and provably informative multi-scale signature based on heat diffusion[J].Computer Graphics Forum, 2009, 28(5):1383-1392. doi: 10.1111/j.1467-8659.2009.01515.x [21] AUBRY M, SCHLICKEWEI U, CREMERS D.The wave kernel signature: A quantum mechanical approach to shape analysis[C]//Proceedings of 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops).Piscataway: IEEE Press, 2011: 1626-1633. [22] WANG P S, SUN C Y, LIU Y, et al.Adaptive O-CNN:A patch-based deep representation of 3D shapes[J].ACM Transactions on Graphics (TOG), 2018, 37(6):1-11. http://arxiv.org/abs/1809.07917 [23] FENG Y, FENG Y, YOU H, et al.MeshNet: Mesh neural network for 3D shape representation[C]//Proceedings of the AAAI Conference on Artificial Intelligence.Palo Alto: AAAI Press, 2019, 33: 8279-8286. [24] QI C R, YI L, SU H, et al.Pointnet++: Deep hierarchical feature learning on point sets in a metric space[C]//Advances in Neural Information Processing Systems.Cambridge: MIT Press, 2017: 5099-5108. [25] HUANG H B, KALOGERAKIS E, CHAUDHURI S, et al.Learning local shape descriptors from part correspondences with multiview convolutional networks[J].ACM Transactions on Graphics (TOG), 2017, 37(1):1-14. doi: 10.1145/3137609 [26] WANG P S, LIU Y, GUO Y X, et al.O-CNN:Octree-based convolutional neural networks for 3d shape analysis[J].ACM Transactions on Graphics (TOG), 2017, 36(4):1-11. http://dl.acm.org/citation.cfm?id=3073608 [27] HAN Z, SHANG M, LIU Z, et al.SeqViews2SeqLabels:Learning 3D global features via aggregating sequential views by RNN with attention[J].IEEE Transactions on Image Processing, 2018, 28(2):658-672. http://ieeexplore.ieee.org/document/8453813/ [28] LAN S Y, YU R C, YU G, et al.Modeling local geometric structure of 3D point clouds using Geo-CNN[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2019: 998-1008. [29] SU H, MAJI S, KALOGERAKIS E, et al.Multi-view convolutional neural networks for 3d shape recognition[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway: IEEE Press, 2015: 945-953. [30] FENG Y, ZHANG Z, ZHAO X, et al.GVCNN: Group-view convolutional neural networks for 3D shape recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2018: 264-272. [31] JIANG J, BAO D, CHEN Z, et al.MLVCNN: Multi-loop-view convolutional neural network for 3D shape retrieval[C]//Proceedings of the AAAI Conference on Artificial Intelligence.Palo Alto: AAAI Press, 2019, 33: 8513-8520. [32] TASSE F P, DODGSON N.Shape2Vec:Semantic-based descriptors for 3D shapes, sketches and images[J].ACM Transactions on Graphics (TOG), 2016, 35(6):1-12. http://www.zhangqiaokeyan.com/academic-journal-foreign_other_thesis/0204110052953.html [33] AUBRY M, MATURANA D, EFROS A A, et al.Seeing 3d chairs: Exemplar part-based 2d-3d alignment using a large dataset of cad models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2014: 3762-3769. [34] MOTTAGHI R, XIANG Y, SAVARESE S.A coarse-to-fine model for 3d pose estimation and sub-category recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 418-426. [35] KULIS B.Metric learning:A survey[J].Foundations and Trendsin Machine Learning, 2013, 5(4):287-364. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?bkn=8186753 [36] XIANG Y, KIM W, CHEN W, et al.ObjectNet3D: A large scale database for 3d object recognition[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 160-176. [37] WANG F, KANG L, LI Y.Sketch-based 3d shape retrieval using convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 1875-1883. [38] LI Y Y, SU H, QI C R, et al.Joint embeddings of shapes and images via CNN image purification[J].ACM Transactions on Graphics (TOG), 2015, 34(6):1-12. http://dl.acm.org/citation.cfm?id=2818071 [39] DAI G, XIE J, ZHU F, et al.Deep correlated metric learning for sketch-based 3d shape retrieval[C]//Proceedings of the AAAI Conference on Artificial Intelligence.Palo Alto: AAAI Press, 2017: 4002-4008. [40] DAI G X, XIE J, FANG Y.Deep correlated holistic metric learning for sketch-based 3d shape retrieval[J].IEEE Transactions on Image Processing, 2018, 27(7):3374-3386. doi: 10.1109/TIP.2018.2817042 [41] SCHROFF F, KALENICHENKO D, PHILBIN J.FaceNet: Aunified embedding for face recognition and clustering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 815-823. [42] SIMONYAN K, ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[EB/OL].(2014-09-04)[2020-02-25].https://arxiv.org/abs/1409.1556. -

 下载:
下载:



 点击查看大图
点击查看大图

计量
- 文章访问数: 889
- HTML全文浏览量: 419
- PDF下载量: 114
- 被引次数: 0
