



-
摘要:
现有图像描述文本生成模型能够应用词性序列和句法树使生成的文本更符合语法规则,但文本多为简单句,在语言模型促进深度学习模型的可解释性方面研究甚少。将依存句法信息融合到深度学习模型以监督图像描述文本生成的同时,可使深度学习模型更具可解释性。图像结构注意力机制基于依存句法和图像视觉信息,用于计算图像区域间关系并得到图像区域关系特征;融合图像区域关系特征和图像区域特征,与文本词向量通过长短期记忆网络(LSTM),用于生成图像描述文本。在测试阶段,通过测试图像与训练图像集的内容关键词,计算2幅图像的内容重合度,间接提取与测试图像对应的依存句法模板;模型基于依存句法模板,生成多样的图像描述文本。实验结果验证了模型在改善图像描述文本多样性和句法复杂度方面的能力,表明模型中的依存句法信息增强了深度学习模型的可解释性。
Abstract:Current image captioning model can automatically apply the part-of-speech sequences and syntactic trees to make the generated text in line with grammar. However, the above-mentioned models generally generate the simple sentences. There is no groundbreaking work in language models promoting the interpretability of deep learning models. The dependency syntax is integrated into the deep learning model to supervise the image captioning, which can make deep learning models more interpretable. An image structure attention mechanism, which recognizes the relationship between image regions based on the dependency syntax, is applied to compute the visual relations and obtain the features. The fusion of image region relation features and image region features, and the word embedding are employed into Long Short-Term Memory (LSTM) to generate the image captions. In testing, the content keywords of the testing and training image datasets are produced due to the content overlap of two images, and the dependency syntax template corresponding to the test image can be indirectly extracted. According to the dependency syntax template, the diverse descriptions can be generated. Experiment resultsverify the capacity of the proposed model to improve the diversity of generated captions and syntax complexity and indicate that the dependency syntax can enhance the interpretability of deep learning model.
-

图 9 基于依存句法的图像描述文本生成示例
Figure 9. Examples of image captioning based on dependency syntax
表 1 超参数设置
Table 1. Hyperparameter setting
参数 数值 图像特征向量/维 14×14×2 048 词向量/维 512 依存句法向量/维 512 LSTM隐向量/维 512 自注意力机制头数 8 批处理大小 32  下载: 导出CSV
下载: 导出CSV
表 2 Flickr30K数据集的实验结果
Table 2. Experimental results on Flickr30K dataset
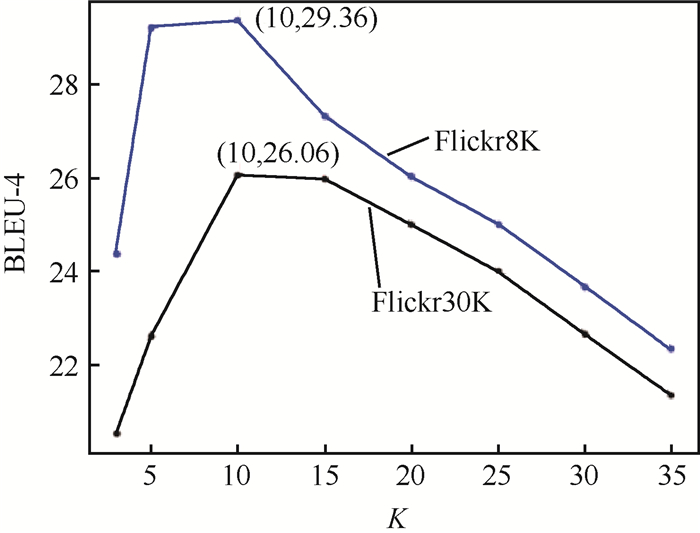
模型 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE-L CIDEr Len NIC+ATT(Baseline) 62.84 39.00 25.07 17.52 17.98 44.57 30.18 11.06 AdaptAtt 60.69 41.80 25.92 18.63 19.71 45.61 33.36 NIC+WC+WA+RL 24.50 21.50 51.60 58.40 MLO/MLPF-LSTM+(BS) 66.20 47.20 33.10 23.00 19.60 CACNN-GAN(ResNet-152) 69.30 49.90 35.80 25.90 22.30 NIC+DS(Top-5) 57.09 39.35 28.66 20.73 20.81 48.24 49.78 17.58 NIC+DSSA(Top-5) 58.62 40.46 29.81 22.62 20.96 49.98 51.74 17.56 NIC+DS(Top-10) 59.76 44.53 31.48 24.75 21.31 51.36 50.91 18.43 NIC+DSSA(Top-10) 61.81 47.33 33.97 26.06 23.57 52.81 52.48 18.62
下载: 导出CSV
表 3 Flickr8K数据集的实验结果
Table 3. Experimental results on Flickr8K dataset
模型 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE-L CIDEr Len NIC+ATT(Baseline) 60.32 37.88 24.66 16.33 18.48 46.16 34.99 11.17 NIC+DS(Top-10) 57.76 41.16 30.70 27.78 19.54 48.81 36.69 14.47 NIC+DSSA(Top-10) 59.45 45.86 36.05 29.36 21.92 50.06 40.24 15.72
下载: 导出CSV
表 4 Flickr8K-CN数据集的实验结果
Table 4. Experimental results on Flickr8K-CN dataset
模型 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE-L CIDEr Len NIC+ATT(Baseline) 59.16 36.30 22.73 16.02 16.87 43.59 31.09 10.82 NIC+DS(Top-10) 56.28 40.03 29.42 25.61 17.48 46.21 34.16 13.45 NIC+DSSA(Top-10) 58.72 46.86 33.05 28.16 20.57 49.10 38.48 14.36
下载: 导出CSV
表 5 描述文本中连接词数量统计
Table 5. Statistics of conjunction numbers in captions
模型 连接词数量 NIC 1 NIC+DSSA 66 参考文本 58
下载: 导出CSV
-
[1] XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//Proceedings of the 32nd International Conference on Machine Learning, 2015: 2048-2057. [2] LU C, KRISHNA R, BERNSTEIN M S, et al. Visual relationship detection with language priors[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 852-869. [3] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems 28, 2015: 91-99. [4] GUO Y, CHENG Z, NIE L, et al. Quantifying and alleviating the language prior problem in visual question answering[C]//Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2019: 75-84. [5] ADITYA D, JYOTI A, LIWEI W, et al. Fast, diverse and accurate image captioning guided by part-of-speech[C]//Proceedings of the 32nd IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 10695-10704. [6] WANG Y, LIN Z, SHEN X, et al. Skeleton key: Image captioning by skeleton-attribute decomposition[C]//Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 7272-7281. [7] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 5998-6008. [8] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems, 2014: 3104-3112. [9] VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: Lessons learned from the 2015 MSCOCO image captioning challenge[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(4): 652-663. http://europepmc.org/abstract/MED/28055847 [10] ZHU Z, XUE Z, YUAN Z. Topic-guided attention for image captioning[C]//Proceedings of the 25th IEEE International Conference on Image Processing. Piscataway: IEEE Press, 2018: 2615-2619. [11] WANG T, HU H, HE C. Image caption with endogenous-exogenous attention[J]. Neural Processing Letters, 2019, 50(1): 431-443. doi: 10.1007/s11063-019-09979-7 [12] LIU F, LIU Y, REN X, et al. Aligning visual regions and textual concepts: Learning fine-grained image representations for image captioning[EB/OL]. (2019-05-15)[2020-08-01]. https://arxiv.org/abs/1905.06139v1. [13] FALENSKA A, KUHN J. The (non-) utility of structural features in BiLSTM-based dependency parsers[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 117-128. [14] LI Z, PENG X, ZHANG M, et al. Semi-supervised domain adaptation for dependency parsing[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 2386-2395. [15] WANG X, TU Z, WANG L, et al. Self-attention with structural position representations[EB/OL]. (2019-09-01)[2020-08-01]. https://arxiv.org/abs/1909.00383. [16] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [17] CHRISTOPER D M, MIHAI S, JOHN B, et al. The stanfordCoreNLP natural language processing toolkit[C]//Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics, 2014: 55-60. [18] PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 2002: 311-318. [19] CHOUEIRI T K, ESCUDIER B, POWLES T, et al. Cabozantinib versus everolimus in advanced renal cell carcinoma (METEOR): Final results from a randomised, open-label, phase 3 trial[J]. The Lancet Oncology, 2016, 17(7): 917-927. doi: 10.1016/S1470-2045(16)30107-3 [20] LIN C Y. Rouge: A package for automatic evaluation of summaries[C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, 2004: 74-81. [21] VEDANTAM R, ZITNICK C L, PARIKH D. CIDER: Consensus-based image description evaluation[C]//Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 4566-4575. [22] LU J, XIONG C, PARIKH D, et al. Knowing when to look: Adaptive attention via a visual sentinel for image captioning[C]//Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 3242-3250. [23] FAN Z, WEI Z, HUANG X, et al. Bridging by word: Image grounded vocabulary construction for visual captioning[C]//Proceedings of the International Conference on the Association for the Advance of Artificial Intelligence, 2019: 6514-6524. [24] 汤鹏杰, 王瀚漓, 许恺晟. LSTM逐层多目标优化及多层概率融合的图像描述[J]. 自动化学报, 2018, 44(7): 1237-1249. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201807007.htmTANG P J, WANG H L, XU K S. Multi-objective layer-wise optimization and multi-level probability fusion for image description generation using LSTM[J]. Acta Automatica Sinica, 2018, 44(7): 1237-1249(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201807007.htm [25] 薛子育, 郭沛宇, 祝晓斌, 等. 一种基于生成式对抗网络的图像描述方法[J]. 软件学报, 2018, 29(2): 30-43. https://www.cnki.com.cn/Article/CJFDTOTAL-WJFZ202003010.htmXUE Z Y, GUO P Y, ZHU X B, et al. Image description method based on generative adversarial networks[J]. Journal of Chinese Information Processing, 2018, 29(2): 30-43(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-WJFZ202003010.htm [26] SALVARIS M, DEAN D, TOK W H, et al. Generative adversarial networks[EB/OL]. (2014-06-10)[2020-08-01]. https://arxiv.org/abs/1406.2661. [27] LIU M, HU H, LI L, et al. Chinese image caption generation via visual attention and topic modeling[J/OL]. IEEE Transactions on Cybernetics, 2020(2020-06-22)[2020-08-01]. https://ieeexplore.ieee.org/document/9122435. -

 下载:
下载:








 点击查看大图
点击查看大图

计量
- 文章访问数: 485
- HTML全文浏览量: 112
- PDF下载量: 174
- 被引次数: 0
