



Autonomous deformation decision making of morphing aircraft based on DDPG algorithm
-
摘要:
针对变体飞行器的自主变形决策问题,提出了一种基于深度确定性策略梯度(DDPG)算法的智能二维变形决策方法。以可同时变展长及后掠角的飞行器为研究对象,利用DATCOM计算气动数据,并通过分析获得变形量与气动特性之间关系;基于给定的展长和后掠角变形动力学方程,设计DDPG算法学习步骤;针对对称和不对称变形条件下的变形策略进行学习训练。仿真结果表明:所提算法可以快速收敛,变形误差保持在3%以内,训练好的神经网络提高了变体飞行器对不同飞行任务的适应性,可以在不同的飞行环境中获得最佳的飞行性能。
-
关键词:
- 变体飞行器 /
- 自主变形决策 /
- 深度强化学习 /
- 深度确定性策略梯度(DDPG)算法 /
- 动力学分析
Abstract:An intelligent 2D deformation decision method based on deep deterministic policy gradient (DDPG) algorithm is proposed for the autonomous deformation decision making of morphing aircraft. The vehicle that can change at the same time the span length and sweepback is taken as the research object, DATCOM is used to calculate the aerodynamic data, and through the analysis, the relation between deformation and aerodynamic characteristics is obtained. DDPG algorithm learning steps are designed based on the given span length and sweepback deformation dynamics equation. The deformation strategy under the condition of symmetrical and asymmetrical deformation is learned and used to train. The simulation results show that the proposed algorithm can achieve fast convergence, and the deformation error is kept within 3%. The trained neural network improves the adaptability of the morphing aircraft to different flight missions, and the optimal flight performance can be obtained in different flight environments.
-

图 2 不同后掠翼变形率和伸缩翼变形率下气动系数随迎角的变化曲线
Figure 2. Variation curves of aerodynamic coefficient with attack angle under different deformation rates of sweptback and retractable wing

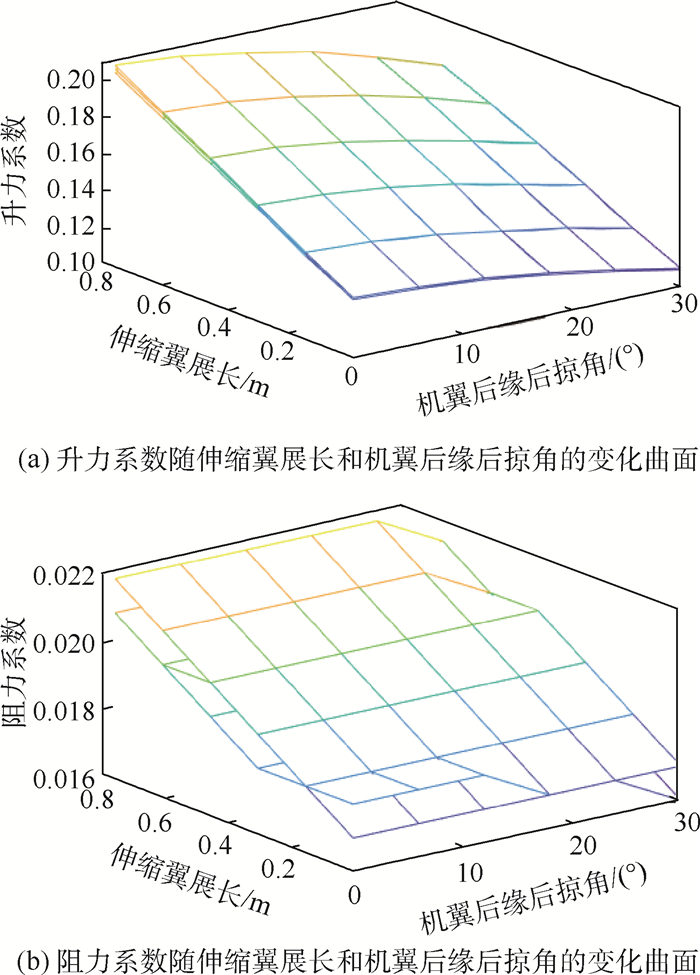
图 3 气动系数随伸缩翼展长和机翼后缘后掠角的变化曲面
Figure 3. Surfaces of aerodynamic coefficients varying with span length of retractable wing and sweepback of wing trailing edge

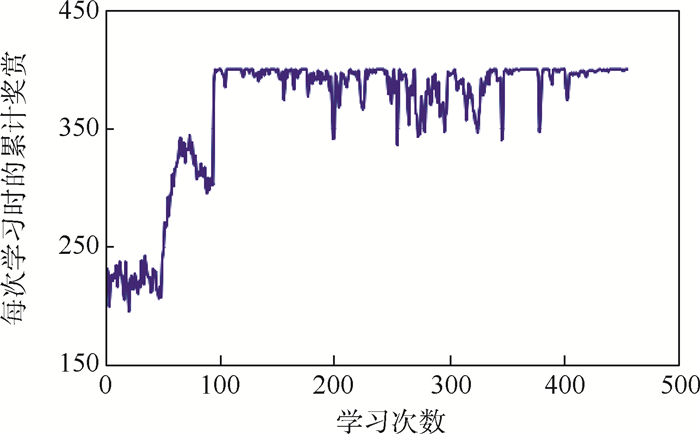
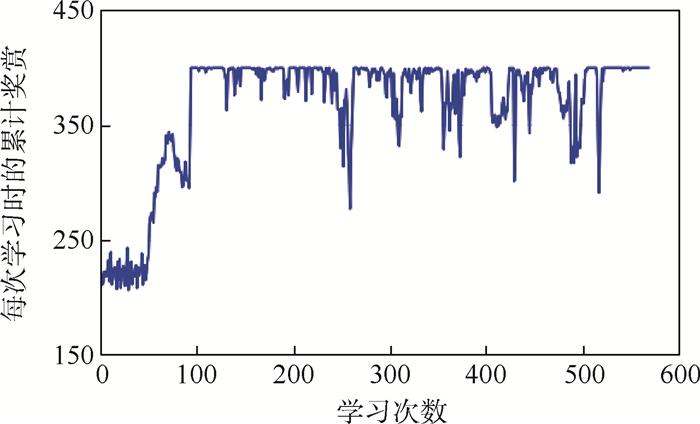
图 5 对称变形时每次学习获得的累计奖赏值
Figure 5. Accumulated rewards for each study under symmetrical deformation

图 7 变体飞行器对称变形测试的仿真结果
Figure 7. Simulation results of symmetric deformation test of morphing aircraft

图 8 不对称变形时每次学习获得的累计奖赏值
Figure 8. Accumulated rewards for each study under asymmetric deformation

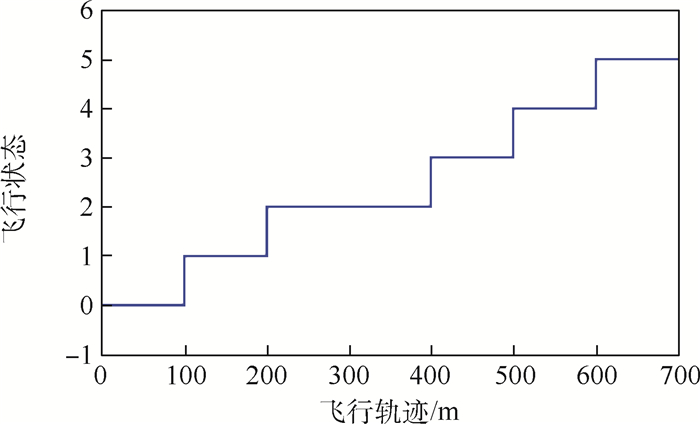
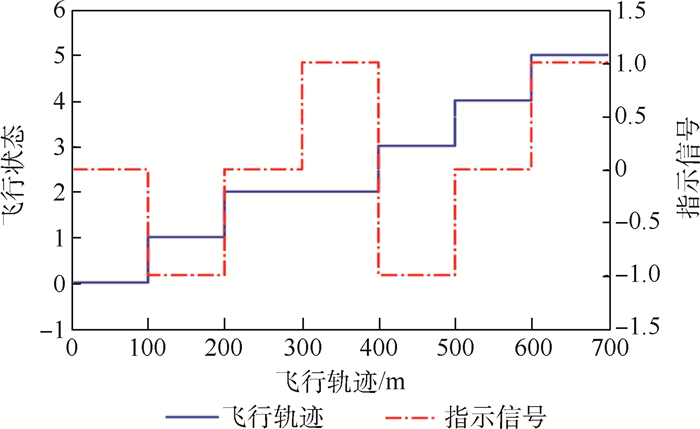
图 9 飞行状态、指示信号与飞行轨迹关系
Figure 9. Relation among flight state, index signal and flight trajectory

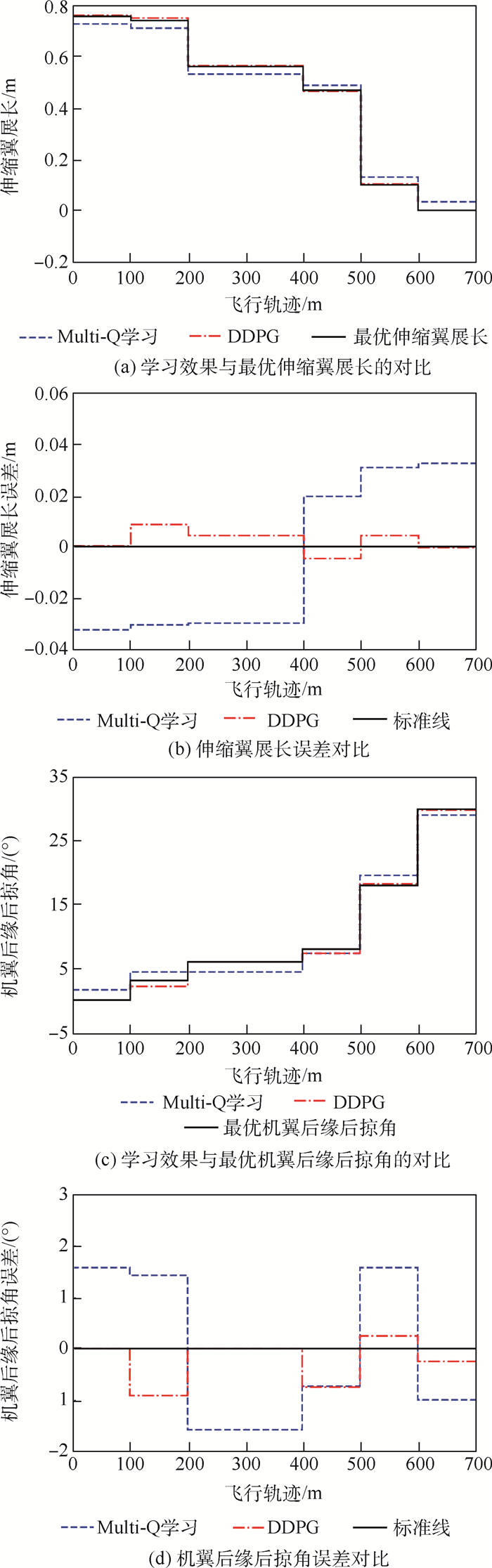
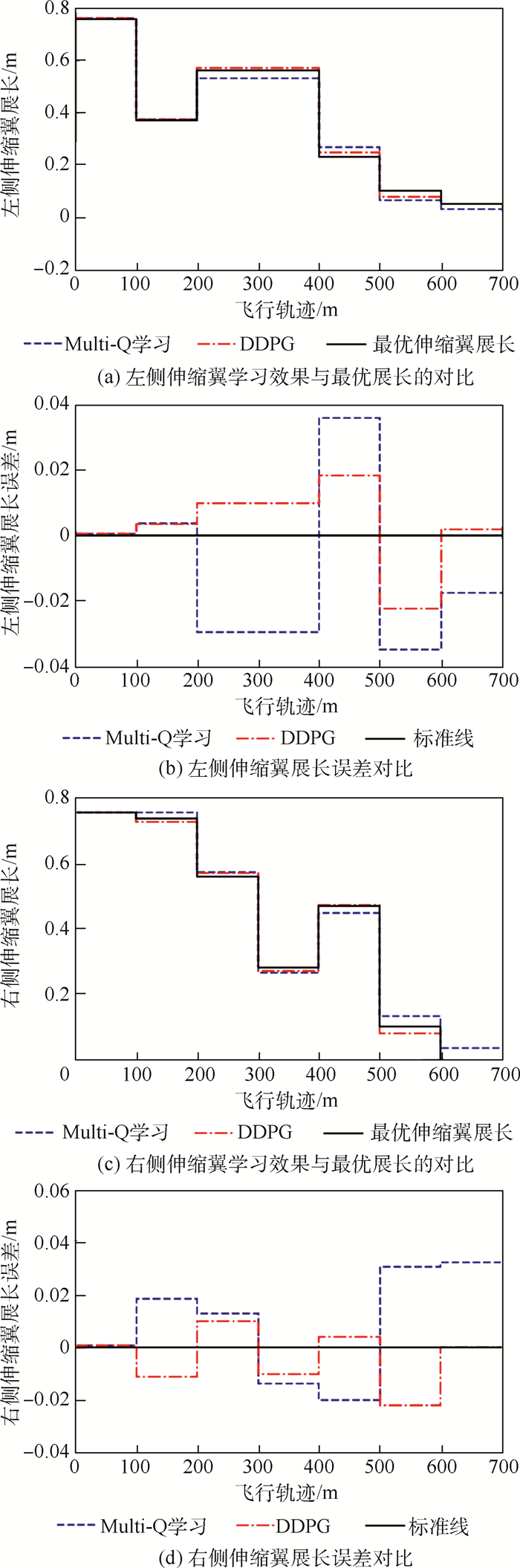
图 10 变体飞行器不对称变形测试的仿真结果
Figure 10. Simulation results of asymmetric deformation test of morphing aircraft
表 1 变体飞行器的基本参数
Table 1. Basic parameters of morphing aircraft
参数 数值 初始质量/kg 32.7 参考长度/m 1.9 伸缩翼的质量/kg 0.8 质心位置/m 0.55 参考面积/m2 1 后掠翼的质量/kg 1.9  下载: 导出CSV
下载: 导出CSV
表 2 飞行状态与飞行高度和马赫数的关系
Table 2. Relation among flight state, flight altitude and Mach number
飞行状态 马赫数 飞行高度/m 0 0.06~0.12 500 1 0.12~0.14 500 2 0.14~0.16 500 3 0.16~0.18 500 4 0.18~0.20 500 5 0.20~0.24 500
下载: 导出CSV
表 3 超参数设置
Table 3. Hyperparameter setting
参数 数值 最大学习次数Maxepisodes 5 000 最大步数T 200 折扣因数γ 0.2 critic学习率 0.002 缓冲区U的大小 10 000 批大小 32 软替代系数τ 0.000 1 actor学习率 0.001
下载: 导出CSV
表 4 变体飞行器对称变形时的最优气动外形
Table 4. Optimal aerodynamic profile of morphing aircraft under symmetrical deformation
飞行状态 最优伸缩翼展长/m 最优机翼后缘后掠角/(°) 0 0.758 0 1 0.740 3 2 0.560 6 3 0.470 8 4 0.100 18 5 0 30
下载: 导出CSV
表 5 变体飞行器不对称变形时左侧伸缩翼的最优气动外形
Table 5. Optimal aerodynamic profile of left retractable wing of morphing aircraft under asymmetric deformation
指示信号 飞行状态 0 1 2 3 4 5 1 0.758 0.74 0.56 0.47 0.10 0.05 0 0.758 0.74 0.56 0.47 0.10 0 -1 0.380 0.37 0.28 0.23 0.05 0
下载: 导出CSV
表 6 变体飞行器不对称变形时右侧伸缩翼的最优气动外形
Table 6. Optimal aerodynamic profile of right retractable wing of morphing aircraft under asymmetric deformation
指示信号 飞行状态 0 1 2 3 4 5 1 0.38 0.37 0.28 0.23 0.05 0 0 0.758 0.74 0.56 0.47 0.10 0 -1 0.758 0.74 0.56 0.47 0.10 0.05
下载: 导出CSV
-
[1] 崔尔杰, 白鹏, 杨基明. 智能变形飞行器的发展道路[J]. 航空制造技术, 2007(8): 38-41. doi: 10.3969/j.issn.1671-833X.2007.08.002CUI E J, BAI P, YANG J M. Development path of intelligent deformation aircraft[J]. Aeronautical Manufacturing Technology, 2007(8): 38-41(in Chinese). doi: 10.3969/j.issn.1671-833X.2007.08.002 [2] 李小飞, 张梦杰, 王文娟, 等. 变弯度机翼技术发展研究[J]. 航空科学技术, 2020, 31(2): 12-24. https://www.cnki.com.cn/Article/CJFDTOTAL-HKKX202002002.htmLI X F, ZHANG M J, WANG W J, et al. Research on variable camber wing technology development[J]. Aeronautical Science & Technology, 2020, 31(2): 12-24(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-HKKX202002002.htm [3] 聂瑞. 变体机翼结构关键技术研究[D]. 南京: 南京航空航天大学, 2018: 12-30.NIE R. Research on key technologies of morphing wing structures[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2018: 12-30(in Chinese). [4] 梁帅, 杨林, 杨朝旭, 等. 基于Kalman滤波的变体飞行器T-S模糊控制[J]. 航空学报, 2020, 41(S2): 61-68. https://www.cnki.com.cn/Article/CJFDTOTAL-HKXB2020S2007.htmLIANG S, YANG L, YANG Z X, et al. Kalman filter based T-S fuzzy control for morphing aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S2): 61-68(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-HKXB2020S2007.htm [5] LEAL P B C, SAVI M A. Shape memory alloy-based mechanism for aeronautical application: Theory, optimization and experiment[J]. Aerospace Science and Technology, 2018, 76: 155-163. doi: 10.1016/j.ast.2018.02.010 [6] XU D, HUI Z, LIU Y, et al. Morphing control of a new bionic morphing UAV with deep reinforcement learning[J]. Aerospace Science and Technology, 2019, 92: 232-243. doi: 10.1016/j.ast.2019.05.058 [7] MNIH V, KAVUKCUGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. doi: 10.1038/nature14236 [8] SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489. doi: 10.1038/nature16961 [9] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. Computer Science, 2015, 8(6): 187-200. [10] MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[EB/OL]. (2016-06-16)[2020-12-01]. https://arxiv.org/abs/1602.01783. [11] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28)[2020-12-01]. https://arxiv.org/abs/1707.06347. [12] VALASEK J, TANDALE M D, RONG J. A reinforcement learning adaptive control architecture for morphing[J]. Journal of Aerospace Computing, Information, and Communication, 2005, 2(4): 174-195. doi: 10.2514/1.11388 [13] LAMPTON A, NIKSCH A, VALASEK J. Reinforcement learning of a morphing airfoil-policy and discrete learning analysis[J]. Journal of Aerospace Computing, Information, and Communication, 2010, 7(8): 241-260. doi: 10.2514/1.48057 [14] LAMPTON A, NIKSCH A, VALASEK J. Reinforcement learning of morphing airfoils with aerodynamic and structural effects[J]. Journal of Aerospace Computing, Information, and Communication, 2009, 6(1): 30-50. doi: 10.2514/1.35793 [15] 温暖, 刘正华, 祝令谱, 等. 深度强化学习在变体飞行器自主外形优化中的应用[J]. 宇航学报, 2017, 38(11): 1153-1159. doi: 10.3873/j.issn.1000-1328.2017.11.003WEN N, LIU Z H, ZHU L P, et al. Deep reinforcement learning and its application on autonomous shape optimization for morphing aircrafts[J]. Journal of Astronautics, 2017, 38(11): 1153-1159(in Chinese). doi: 10.3873/j.issn.1000-1328.2017.11.003 [16] 闫斌斌, 李勇, 戴沛, 等. 基于增强学习的变体飞行器自适应变体策略与飞行控制方法研究[J]. 西北工业大学学报, 2019, 37(4): 656-663. doi: 10.3969/j.issn.1000-2758.2019.04.003YAN B B, LI Y, DAI P, et al. Adaptive wing morphing strategy and flight control method of a morphing aircraft based on reinforcement learning[J]. Journal of Northwestern Polytechnical University, 2019, 37(4): 656-663(in Chinese). doi: 10.3969/j.issn.1000-2758.2019.04.003 [17] 杨贯通. 变外形飞行器建模与控制方法研究[D]. 北京: 北京理工大学, 2015: 36-50.YANG G T. Research on modeling and control of morphing flight vehicles[D]. Beijing: Beijing Institute of Technology, 2015: 36-50(in Chinese). -

 下载:
下载:



 点击查看大图
点击查看大图

计量
- 文章访问数: 632
- HTML全文浏览量: 256
- PDF下载量: 81
- 被引次数: 0
