



A computing framework for massive scientific data based on auto-partitioning algorithm
-
摘要:
在科学研究领域, 存储容量、处理效率和分析精度并不能适应科学数据的指数级增长速度。通过对科学数据结构与标准的研究, 提出了一个海量科学数据计算框架BSDF。提出了一种基于模型驱动的统一数据接口, 实现对异构科学数据的无差别访问;提出了一种基于元数据的自动分区算法, 通过参数预取与超平面维度计算确定任务颗粒度。实验结果表明:与H5Spark科学数据计算框架的基于9项基准测试的性能相比, BSDF计算框架提升了39%~68%;在特定领域PKTM的算法优化上, BSDF达到了41.62倍的加速比。
Abstract:In the scientific research field, storage capacity, processing efficiency and analysis accuracy cannot keep pace with the exponential growth rate of scientific data. Thus, a massive scientific data calculation framework named BSDF is proposed based on scientific data structure and standards. A unified data interface based on model-driving is integrated to implement indiscriminate access to heterogeneous scientific data. Then an auto-partitioning algorithm based on scientific metadata is proposed, which determines task granularities through parameter prefetching and hyperplane dimension calculation. Experimental results show that compared with the performance of the H5Spark framework, that of the BSDF is increased by 39%-68% in nine benchmark tests. In the optimization of the domain-specific PKTM algorithm, a speedup ratio is increased by 41.62 times.
-

图 3 自动分区算法在3D数据的分区示意图
Figure 3. Schematic diagram of partitioning results of auto partitioning algorithms on 3D data

图 4 BSDF与H5Spark整体性能比较
Figure 4. Overall performance comparison between BSDF and H5Spark

图 5 BSDF与H5Spark在多节点环境可扩展性的比较
Figure 5. Overall scalability comparison between BSDF and H5park in multi-node environments

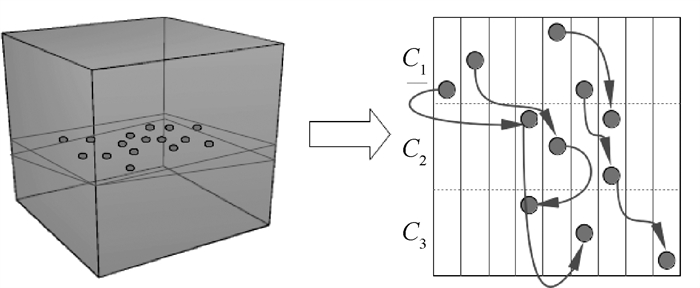
图 6 Apache Spark范围分区与自动分区算法对于Spark Collect任务的整体性能与任务流水线比较
Figure 6. Overall performance comparison between Apache Spark range partitioning and auto partitioning algorithm in both Spark Collect tasks and task pipelines

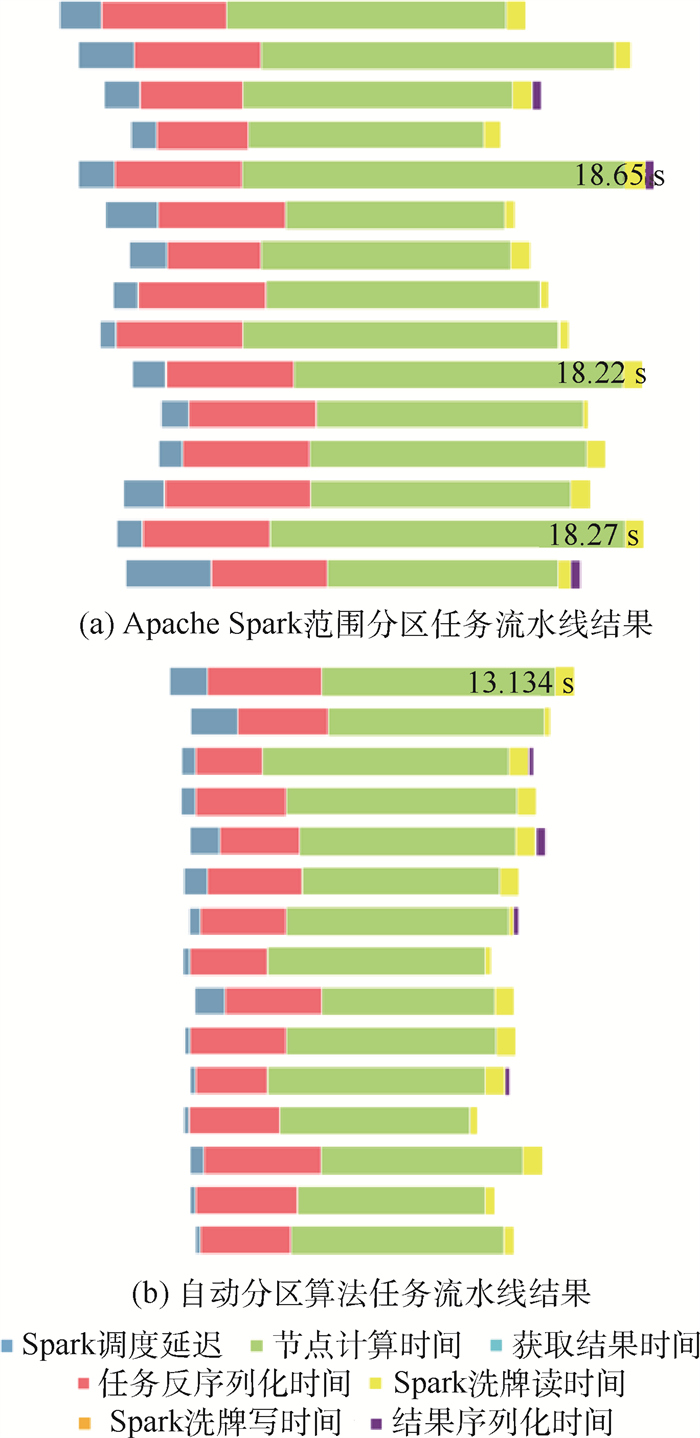
图 7 PKTM算法在多节点与多地震道下基于Hadoop、Spark和BSDF实现的性能比较
Figure 7. Performance comparison of Hadoop, Spark and BSDF based implementations of PKTM algorithm with multiple nodes and multiple seismic traces
表 1 实验数据与对应基准测试程序
Table 1. Experimental data and corresponding benchmark programs
数据类型 数据量/GB 基准测试程序 HDF5 19.23 Mean,Aggregation,Sort, KMeans, Logistic Regression, Alternating Least Squares, Spark Collect, Matrix Multiplication NetCDF 20.13 Mean,Aggression,Sort, KMeans, Logistic Regression, Alternating Least Squares, Spark Collect, Matrix Multiplication SEGY 4.95 PKTM  下载: 导出CSV
下载: 导出CSV
表 2 实验基准测试集列表
Table 2. Experimental benchmark test sets
序号 基准测试程序 基准测试程序描述 1 Mean 用户自定义函数,用于返回整个数据集的平均值 2 Aggregation 用户自定义函数,用于返回整个数据集的累加结果 3 Sort Spark内置函数, 对输入数据进行排序 4 KMeans 聚类算法,用于将输入数据放入预定义的多个类中 5 Logistic Regression 分类算法,采用梯度斜率方法最小化逻辑回归模型训练 6 Alternating Least Squares Spark MLlib内置函数,与矩阵分解协同计算使得差平方和最小 7 Spark Collect Spark内置函数,将数据从各个节点拉取到驱动器节点 8 Matrix Multiplication 用户自定义函数,分布式矩阵相乘 9 PKTM 叠前时间偏移成像算法,专门用于地震数据处理
下载: 导出CSV
-
[1] GRAY J, LIU D T, NIETO-SANTISTEBAN M, et al. Scientific data management in the coming decade[J]. ACM SIGMOD Record, 2005, 34(4): 34-41. doi: 10.1145/1107499.1107503 [2] The HDF Group. Hierarchical data format. Version 5[EB/OL]. [2020-12-01]. http://www.hdfgroup.org/HDF5. [3] UCAR Community Programs. Network common data form (NetCDF)[EB/OL]. [2020-12-01]. https://www.unidata.ucar.edu/software/netcdf. [4] ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: Cluster computing with working sets[C]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing. New York: ACM, 2010: 1-10. [5] SUTTON J, AUSTIN Z. Qualitative research: Data collection, analysis, and management[J]. The Canadian Journal of Hospital Pharmacy, 2015, 68(3): 226-231. [6] MIKAEL N, AMBJÖRN N, ERIK D, et al. Harmonization methodology for metadata models[EB/OL]. [2020-12-01]. https://hal.archives-ouvertes.fr/hal-00591548. [7] DPLA. Metadata application profile. Version 4.0[EB/OL]. [2020-12-01]. http://dp.la/info/wpcontent/uploads/2015/03/MAPv4.pdf. [8] DIAMANTOPOULOS N, SGOUROPOULOU C, KASTRANTAS K, et al. Developing a metadata application profile for sharing agricultural scientific and scholarly research resources[C]//Research Conference on Metadata and Semantic Research. Berlin: Springer, 2011: 453-466. [9] RILEY J. Understanding metadata: What is metadata, and what is it for [M]//WOOLCOTT L. Baltimore: National information standards organization. Oxford: Taylor, 2017: 669-670. [10] BARGMEYER B E, GILLMAN D W. Metadata standards and metadata registries: An overview[EB/OL]. [2020-12-01]. https://www.bls.gov/osmr/research-papers/2000/pdf/st000010.pdf. [11] JONES M B, BERKLEY C, BOJILOVA J, et al. Managing scientific metadata[J]. IEEE Internet Computing, 2001, 5(5): 59-68. doi: 10.1109/4236.957896 [12] HANISCH R J, FARRIS A, GREISEN E W, et al. Definition of the flexible image transport system (FITS)[J]. Astronomy & Astrophysics, 2001, 376(1): 359-380. [13] PARK J K. Improving the performance of HDFS by reducing I/O using adaptable I/O system[C]//2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT). Piscataway: IEEE Press, 2016: 3139-3144. [14] SEG Technical Standards Committee. SEG-Y_r2.0: SEG-Y revision 2.0 data exchange format[S]. [S. l. ]: Society of Exploration Geophysicists, 2017. [15] DEAN J, GHEMAWAT S. MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113. doi: 10.1145/1327452.1327492 [16] YUN H, YU H F, HSIEH C J, et al. NOMAD: Non-locking, stochastic multi-machine algorithm for asynchronous and decentralized matrix completion[J]. Proceedings of the VLDB Endowment, 2013, 7(11): 975-986. [17] LIU J, RACAH E, KOZIOL Q, et al. H5Spark: Bridging the I/O gap between Spark and scientific data formats on HPC systems[C]//Proceedings of the Cray Users Group, 2016. [18] AGARWAL A, CHAPELLE O, DUDÍK M, et al. A reliable effective tera scale linear learning system[J]. Journal of Machine Learning Research, 2014, 15(1): 1111-1133. [19] TIAN Y, LIU C, YAN H H. Accelerate large-scale seismic data Kirchhoff time migration in spark[C]//2018 4th International Conference on Information Management (ICIM). Piscataway: IEEE Press, 2018: 41-45. -

 下载:
下载:



 点击查看大图
点击查看大图

计量
- 文章访问数: 225
- HTML全文浏览量: 111
- PDF下载量: 17
- 被引次数: 0
