



-
摘要:
为了解决训练过程中卷积模型参数较多、收敛速度较慢的问题,提出了一种基于MobileFaceNet网络改进的人脸识别方法。首先,使用MobileFaceNet网络提取人脸特征,在提取特征的过程中,通过引入可分离卷积减少模型中卷积层参数的数量;其次,通过在MobileFaceNet网络中引入风格注意力机制来增强特征的表达,同时使用AdaCos人脸损失函数来训练模型,利用AdaCos损失函数中的自适应缩放系数,来动态地调整超参数,避免了人为设置超参数对模型的影响;最后,分别在LFW、AgeDB和CFP-FF测试数据集上对训练模型进行评估。实验结果显示:改进后的模型在LFW、AgeDB和CFP-FF测试数据集上的识别精度分别提升了0.25%、0.16%和0.3%,表明改进后的模型相较于改进前的模型在精度和鲁棒性上有所提高。
-
关键词:
- 人脸识别 /
- 深度学习 /
- MobileFaceNet /
- AdaCos /
- 卷积神经网络
Abstract:In order to solve the problem of more convolutional model parameters and slower convergence speed during training, an improved face recognition method based on MobileFaceNet network is proposed. First, we use the MobileFaceNet network to extract facial features. In the process of extracting features, the number of convolutional layer parameters in the model is reduced by introducing separable convolution. Then, the style attention mechanism is introduced in the MobileFaceNet network to enhance the expression of features. At the same time, the AdaCos face loss function is used to train the model, and the adaptive scaling factor in the AdaCos loss function is used to dynamically adjust the hyperparameters to avoid the effect of artificially setting hyperparameters on the model. Finally, we evaluate the training model on the LFW, AgeDB and CFP-FF test dataset, respectively. The experimental results show that the recognition accuracy of the improved model on the LFW, AgeDB and CFP-FF test dataset has increased by 0.25%, 0.16% and 0.3%, respectively, indicating that the improved model has higher accuracy and robustness than the model before improvement.
-
Key words:
- face recognition /
- deep learning /
- MobileFaceNet /
- AdaCos /
- convolutional neural network
-

图 4 MobileFaceNet中bottleneck层结构
Figure 4. Structure of bottleneck layer in MobileFaceNet

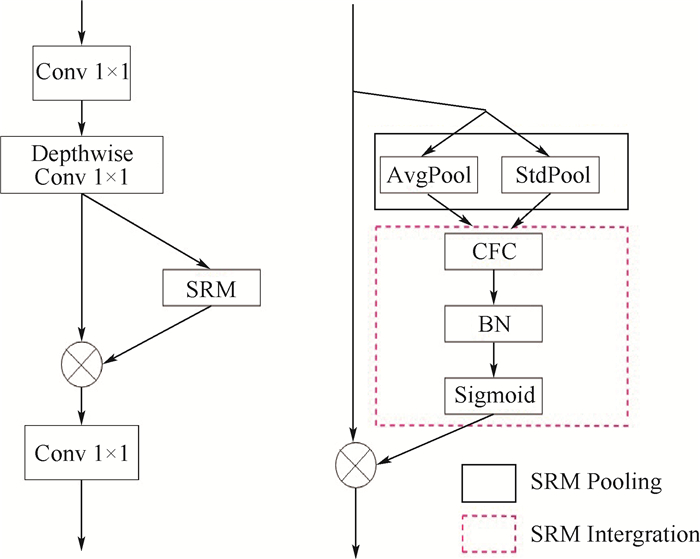
图 5 MobileFaceNet-SRM bottleneck层结构
Figure 5. MobileFaceNet-SRM bottleneck layer structure

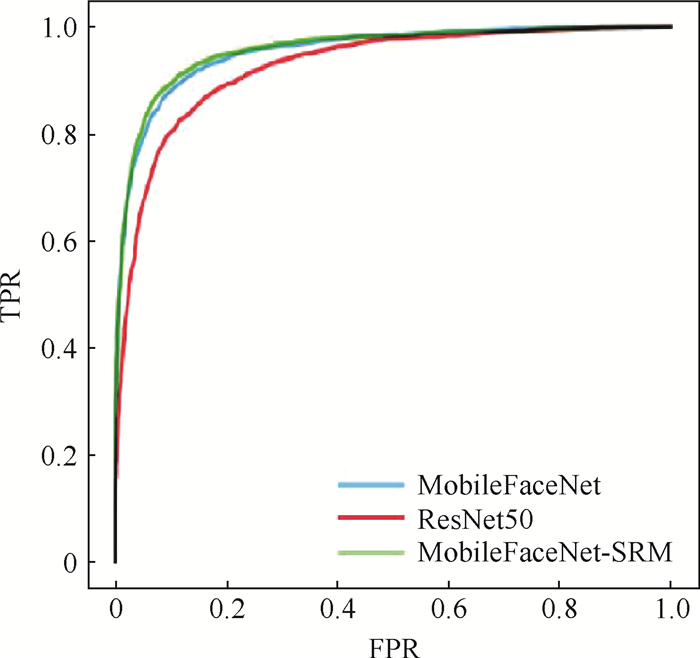
图 6 三种主干网络在AgeDB数据集上的ROC曲线
Figure 6. ROC curves of three backbone networks on AgeDB dataset
表 1 MobileNetV2网络结构
Table 1. MobileNetV2 network structure
输入 卷积操作 z c n v 224×224×3 Conv2d 32 1 2 112×112×32 bottleneck 1 16 1 1 112×112×16 bottleneck 6 24 2 2 56×56×24 bottleneck 6 32 3 2 28×28×32 bottleneck 6 64 4 2 28×28×64 bottleneck 6 96 3 1 14×14×96 bottleneck 6 160 3 2 7×7×160 bottleneck 6 320 1 1 7×7×320 Conv2d 1×1 1280 1 1 7×7×1280 Avgpool 7×7 1 1×1×f Conv2d 1×1 f  下载: 导出CSV
下载: 导出CSV
表 2 MobileFaceNet网络结构
Table 2. MobileFaceNet network structure
输入 卷积操作 z c n v 112×112×3 Conv 3×3 64 1 2 56×56×64 Depthwise Conv 3×3 64 1 1 56×56×64 bottleneck 2 64 5 2 28×28×64 bottleneck 4 128 1 2 14×14×128 bottleneck 2 128 6 1 14×14×128 bottleneck 4 128 1 2 7×7×128 bottleneck 2 128 2 1 7×7×128 Conv 1×1 512 1 1 7×7×512 Linear GDConv 7×7 512 1 1 1×1×512 Linear Conv 1×1 128 1 1
下载: 导出CSV
表 3 基于AdaCos的损失函数不同卷积框架人脸识别模型性能比较
Table 3. Performance comparison of face recognition models with different convolution frames based on AdaCos loss function
网络结构 测试准确度/% 模型大小/MB LFW CFP-FF AgeDB ResNet50 98.41 97.88 88.46 161.5 MobileFaceNet 98.90 98.69 90.94 4.9 MobileFaceNet-SRM 99.15 98.85 91.24 5.2
下载: 导出CSV
-
[1] 徐竟泽, 吴作宏, 徐岩, 等.融合PCA、LDA和SVM算法的人脸识别[J].计算机工程与应用, 2019, 55(18):34-37. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjgcyyy201918005XU J Z, WU Z H, XU Y, et al.Face recognition combined with PCA, LDA and SVM algorithms[J].Computer Engineering and Applications, 2019, 55(18):34-37(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjgcyyy201918005 [2] 任飞凯, 邱晓晖.基于LBP和数据扩充的CNN人脸识别研究[J].计算机技术与发展, 2020, 30(3):62-66. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=wjfz202003012REN F K, QIU X H.Research on CNN face recognition based on LBP and data augmentation[J].Computer Technology and Development, 2020, 30(3):62-66(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=wjfz202003012 [3] SUN Y, WANG X G, TANG X O.Deep learning face representation from predicting 10, 000 classes[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2014: 1891-1898. [4] SUN Y, WANG X G, TANG X O, et al.Deep learning face representation by joint identification-verification[C]//Advances in Neural Information Processing Systems, 2014: 1988-1996. http://www.researchgate.net/publication/263237688_Deep_Learning_Face_Representation_by_Joint_Identification-Verification [5] SUN Y, WANG X G, TANG X O.Deeply learned face representations are sparse, selective, and robust[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 2892-2900. [6] SCHROFF F, KALENICHENKO D, PHILBIN J.FaceNet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2015: 815-823. [7] WANG S S, CHEN Y.A joint loss function for deep face recognition[J].Multidimensional Systems and Signal Processing, 2019, 30(3):1517-1530. doi: 10.1007/s11045-018-0614-0 [8] DENG J, GUO J K, XUE N N, et al.Arcface: Additive angular margin loss for deep face recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2019: 4690-4699. [9] ZHANG X, ZHAO R, QIAO Y, et al.AdaCos: Adaptively scaling cosine logits for effectively learning deep face representations[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2019: 10823-10832. [10] CHEN S, LIU Y, GAO X, et al.MobileFaceNets: Efficient CNNs for accurate real-time face verification on mobile devices[C]//Chinese Conference on Biometric Recognition.Berlin: Springer, 2018: 428-438. https://www.researchgate.net/publication/324690622_MobileFaceNets_Efficient_CNNs_for_Accurate_Real-time_Face_Verification_on_Mobile_Devices [11] HOWARD A G, ZHU M, CHEN B, et al.MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL].(2017-04-17)[2020-02-20].https://arxiv.org/abs/1704.04861. [12] SANDLER M, HOWARD A, ZHU M L, et al.MobileNetV2: Inverted residuals and linear bottlenecks[EB/OL].(2018-01-13)[2019-03-21].https://arxiv.org/abs/1801.04381. [13] LEE H J, KIM H E, NAM H.SRM: A style-based recalibration module for convolutional neural networks[EB/OL].(2019-05-26)[2020-02-20].https://arxiv.org/abs/1903.10829?context=cs. [14] IOFFE S, SZEGEDY C.Batch normalization: Accelerating deep network training by reducing internal covariate shift[EB/OL].(2015-03-02)[2020-02-20].http://arxiv.org/abs/1502.03167. [15] CHU X X, ZHANG B, XU R J.MoGA: Searching beyond MobileNetV3[EB/OL].(2019-08-04)[2020-02-20].https://arxiv.org/abs/1908.01314v2. [16] HU J, SHEN L, ALBANIE S, et al.Squeeze-and-excitation networks[J].(2017-09-05)[2020-02-20].https://arxiv.org/abs/1709.01507. [17] 常思远, 李有乘, 孙培岩, 等.一种基于MTCNN的视频人脸检测及识别方法[J].许昌学院学报, 2019, 38(2):154-157. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xcxyxb201902035CHANG S Y, LI Y S, SUN P Y, et al.A video face detection and recognition method based on MTCNN[J].Journal of Xuchang University, 2019, 38(2):154-157(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xcxyxb201902035 -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 1206
- HTML全文浏览量: 192
- PDF下载量: 148
- 被引次数: 0
