



-
摘要:
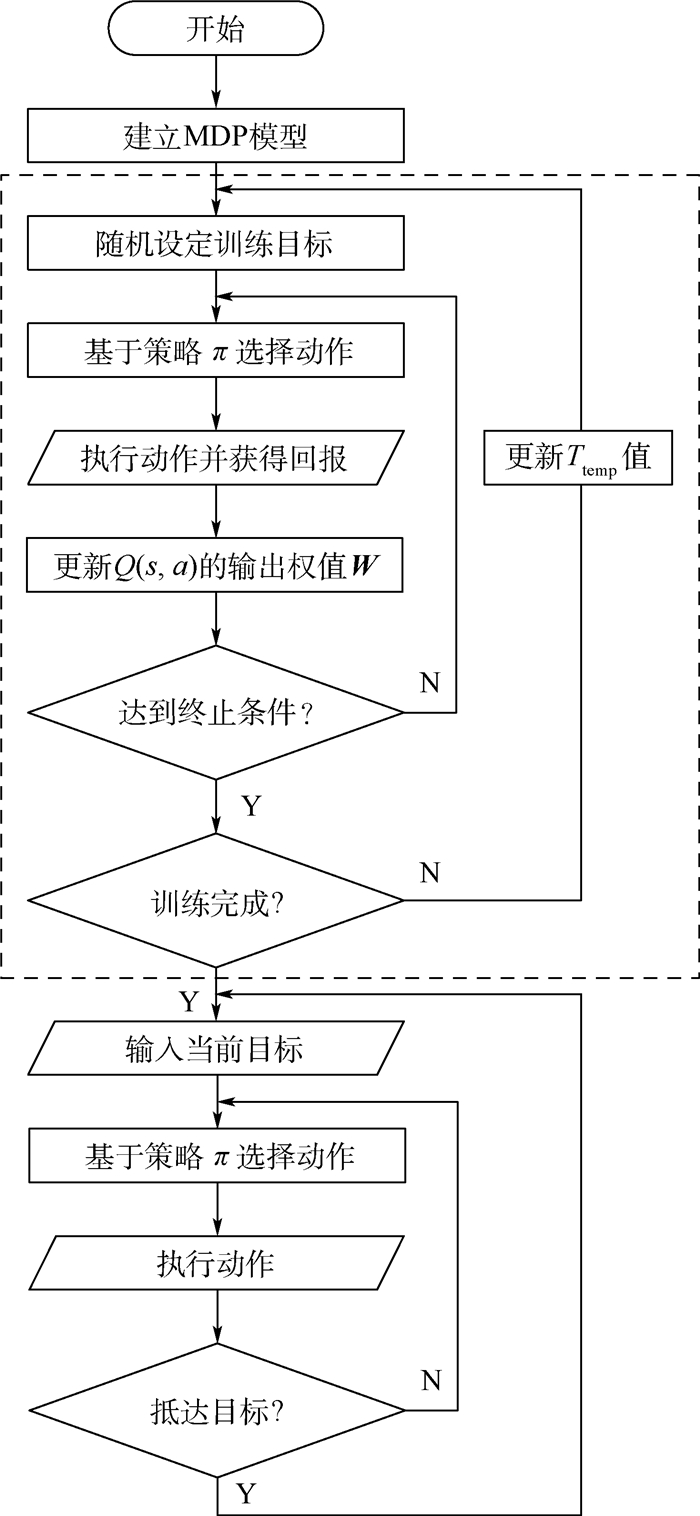
针对现代飞艇控制中动力学模型不确定性带来的系统建模和参数辨识工作较为复杂的问题,提出了一种基于自适应建模和在线学习机制的控制策略。设计了一种在分析实际运动的基础上建立飞艇控制马尔可夫决策过程(MDP)模型的方法,具有自适应性。采用Q-Learning算法进行在线学习并利用小脑模型关节控制器(CMAC)神经网络对动作值函数进行泛化加速。对本文方法进行仿真并与经过参数整定的PID控制器对比,验证了该控制策略的有效性。结果表明,在线学习过程能够在数小时内收敛,通过自适应方法建立的MDP模型能够满足常见飞艇控制任务的需求。本文所提控制器能够获得与PID控制器精度相当且更为智能的控制效果。
-
关键词:
- 飞艇 /
- 马尔可夫决策过程(MDP) /
- 机器学习 /
- Q-Learning /
- 小脑模型关节控制器(CMAC)
Abstract:An autonomous on-line learning control strategy based on adaptive modeling mechanism was proposed aimed at system modeling and parameter identification problems resulting from dynamic model uncertainties in modern airship control. An adaptive method to establish airship control Markov decision process (MDP) model was introduced on the foundation of analyzing airship's actual motion. On-line learning was carried out by Q-Learning algorithm, and cerebellar model articulation controller (CMAC) network was brought in for generalization of action value functions to accelerate algorithm convergence speed. Simulations of this autonomous on-line learning controller and comparisons with parameters turned PID controllers in normal control tasks were presented to demonstrate Q-Learning controller's effectiveness. The results show that the controller's on-line learning processes can converge in a few hours and the airship control MDP model established by the adaptive method satisfies the need of normal control tasks. The controller designed in this paper obtains similar precision as PID controllers and performs even more intelligently.
-

图 2 飞艇和目标相对位置坐标示意图
Figure 2. Coordinate schematic diagram of relative position of airship and target

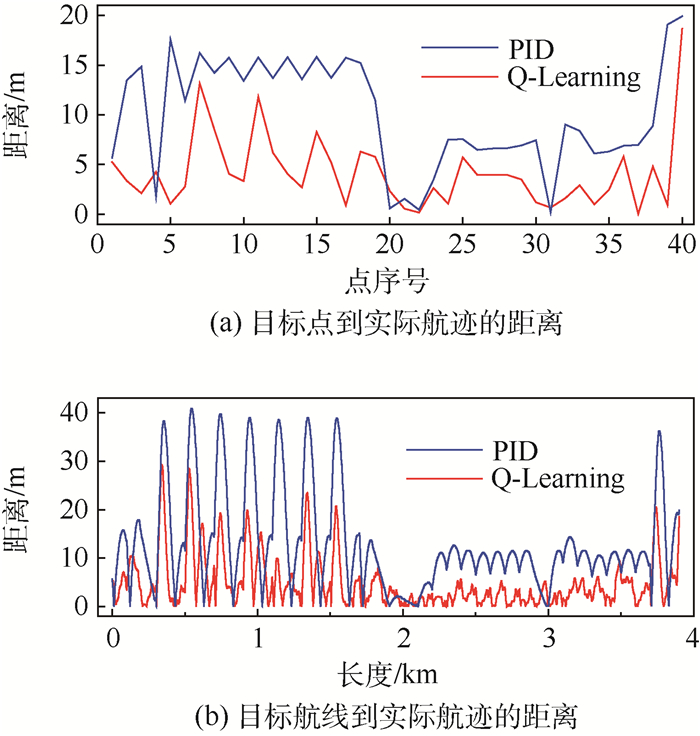
图 8 目标点和目标航线到实际航迹的距离
Figure 8. Distances from target points and paths to actual trajectories
表 1 状态空间S的离散参数
Table 1. Discretized parameters of state spaces
参数 取值规则 本文取值 ψr [-π, +π] [-π, +π] lr ≥4R 4R Δψr 控制要求决定 π/9 Δlr ≤R(1-cos Δψr) R(1-cos Δψr) Tstep ≤TΔψ TΔψ  下载: 导出CSV
下载: 导出CSV
表 2 仿真模型参数
Table 2. Model parameters of simulation
参数 数值 m/kg 100 ▽/m3 79.0 ρ/(kg·m-3) 1.225 Ix/(kg·m2) 324 Iy/(kg·m2) 474 Iz/(kg·m2) 202 k1 0.084 k2 0.856 k3/m2 5.543 CX1 -0.518 CX2 -5.629 CY1 -5.629 CY2 -10.798 CY3 -22.852 CY4 2.336 CZ1 -5.629 CZ2 -10.798 CZ3 -21.622 CZ4 -2.336 CL2 2.337 CM1 36.364 CM2 -56.948 CM3 -42.655 CM4 -12.324 CN1 -36.364 CN2 56.948 CN3 42.655 CN4 -12.324 注:m—飞艇质量;▽—飞艇体积; Ix、Iy、Iz—转动惯量; k1、k2、k3—惯性因子。
下载: 导出CSV
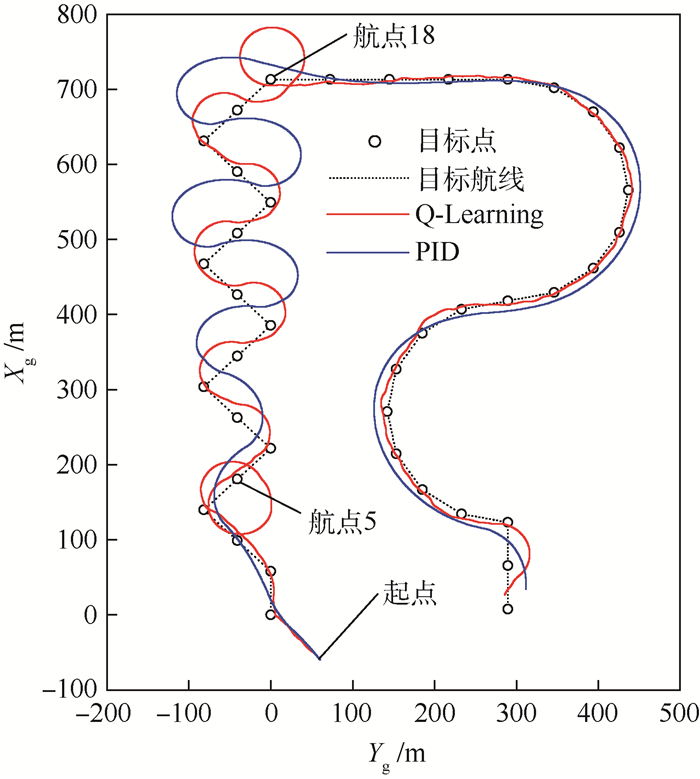
表 3 目标点和目标航线到实际航迹的距离和任务耗时
Table 3. Distances from target points and paths to actual trajectories and time consumption of tasks
控制器 目标点最大偏离/m 目标点平均偏离/m 目标航线最大偏离/m 目标航线平均偏离/m 任务全程耗时/s PID 17.55 10.06 40.89 19.92 443.7 Q-Learning 13.16 4.19 29.23 4.81 419.2
下载: 导出CSV
-
[1] PRENTICE B E, KNOTTS R.Cargo airships:International competition[J].Journal of Transportation Technologies, 2014, 4:187-195. doi: 10.4236/jtts.2014.43019 [2] 赵达, 刘东旭, 孙康文, 等.平流层飞艇研制现状、技术难点及发展趋势[J].航空学报, 2016, 37(1):45-56. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=hkxb201601004&dbname=CJFD&dbcode=CJFQZHAO D, LIU D X, SUN K W, et al.Research status, technical difficulties and development trend of stratospheric airship[J].Acta Aeronautica et Astronautica Sinica, 2016, 37(1):45-56(in Chinese). http://kns.cnki.net/KCMS/detail/detail.aspx?filename=hkxb201601004&dbname=CJFD&dbcode=CJFQ [3] 郭虓. 平流层浮空器轨迹优化研究[D]. 北京: 北京航空航天大学, 2013: 29-36.GUO X.Trajectory optimization research for stratospheric aerostat[D].Beijing:Beihang University, 2013:29-36(in Chinese). [4] KHOURY G A.Airship technology[M].New York:Cambridge University Press, 2012:34-40. [5] YANG Y, WU J, ZHENG W.Positioning control for an autonomous airship[J].Journal of Aircraft, 2016, 53(6):1638-1646. doi: 10.2514/1.C033709 [6] ZHENG Z W, ZHU M, SHI D L, et al.Hovering control for a stratospheric airship in unknown wind:AIAA-2014-0973[R].Reston:AIAA, 2014. doi: 10.2514/6.2014-0973 [7] ZHENG Z, LIU L, ZHU M.Integrated guidance and control path following and dynamic control allocation for a stratospheric airship with redundant control systems[J].Proceedings of the Institution of Mechanical Engineers, Part G:Journal of Aerospace Engineering, 2016, 230(10):1813-1826. doi: 10.1177/0954410015613738 [8] YANG Y, YAN Y, ZHU Z, et al.Positioning control for an unmanned airship using sliding mode control based on fuzzy approximation[J].Proceedings of the Institution of Mechanical Engineers, Part G:Journal of Aerospace Engineering, 2014, 228(14):2627-2640. doi: 10.1177/0954410014523577 [9] ABBEEL P, COATES A, QUIGLEY M, et al.An application of reinforcement learning to aerobatic helicopter flight[C]//Advances in Neural Information Processing Systems, 2007:1-8. http://ieeexplore.ieee.org/document/6287086/ [10] 徐昕.增强学习与近似动态规划[M].北京:科学出版社, 2010:18-27.XU X.Reinforcement learning and approximate dynamic programing[M].Beijing:Science Press, 2010:18-27(in Chinese). [11] PEARRE B, BROWN T X.Model-free trajectory optimization for unmanned aircraft serving as data ferries for widespread sensors[J].Remote Sensing, 2012, 4(10):2971-3005. http://www.oalib.com/paper/166731 [12] RAGI S, CHONG E K P.UAV path planning in a dynamic environment via partially observable Markov decision process[J].IEEE Transactions on Aerospace and Electronic Systems, 2013, 49(4):2397-2412. doi: 10.1109/TAES.2013.6621824 [13] DUNN C, VALASEK J, KIRKPATRICK K.Unmanned air system search and localization guidance using reinforcement learning:AIAA-2012-2589[R].Reston:AIAA, 2012. doi: 10.2514/6.2012-2589 [14] ZHANG B, MAO Z, LIU W, et al.Geometric reinforcement learning for path planning of UAVs[J].Journal of Intelligent & Robotic Systems, 2015, 77(2):391-409. doi: 10.1007/s10846-013-9901-z [15] FAUST A.Reinforcement learning and planning for preference balancing tasks[J].AI Matters, 2015, 1(3):8-12. 10.1145/2735392.2735396 [16] KO J, KLEIN D J, FOX D, et al.Gaussian processes and reinforcement learning for identification and control of an autonomous blimp[C]//Proceedings 2007 IEEE International Conference on Robotics and Automation.Piscataway, NJ:IEEE Press, 2007:742-747. http://ieeexplore.ieee.org/document/4209179/ [17] ROTTMANN A, PLAGEMANN C, HILGERS P, et al.Autonomous blimp control using model-free reinforcement learning in a continuous state and action space[C]//2007 IEEE/RSJ International Conference on Intelligent Robots and Systems.Piscataway, NJ:IEEE Press, 2007:1895-1900. http://ieeexplore.ieee.org/document/4399531/ [18] LIN C M, PENG Y F.Adaptive CMAC-based supervisory control for uncertain nonlinear systems[J].IEEE Transactions on Systems, Man, and Cybernetics, Part B(Cybernetics), 2004, 34(2):1248-1260. doi: 10.1109/TSMCB.2003.822281 [19] SCHMIDT D K.Modeling and near-space station keeping control of a large high-altitude airship[J].Journal of Guidance, Control, and Dynamics, 2007, 30(2):540-547. doi: 10.2514/1.24865 [20] LS-S1200 UAV airship system overview parameters[EB/OL].[2017-12-18].http://www.lonsan.com.cn/english/Products_1.asp?oneclass=5&pid=13. [21] ATAEI M, YOUSEFI-KOMA A.Three-dimensional optimal path planning for waypoint guidance of an autonomous underwater vehicle[J].Robotics and Autonomous Systems, 2015, 67:23-32. doi: 10.1016/j.robot.2014.10.007 -

 下载:
下载:






 点击查看大图
点击查看大图

计量
- 文章访问数: 648
- HTML全文浏览量: 146
- PDF下载量: 564
- 被引次数: 0
