



-
摘要:
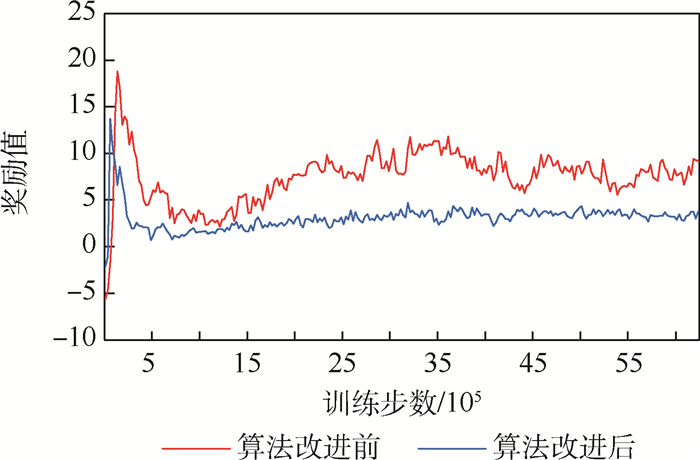
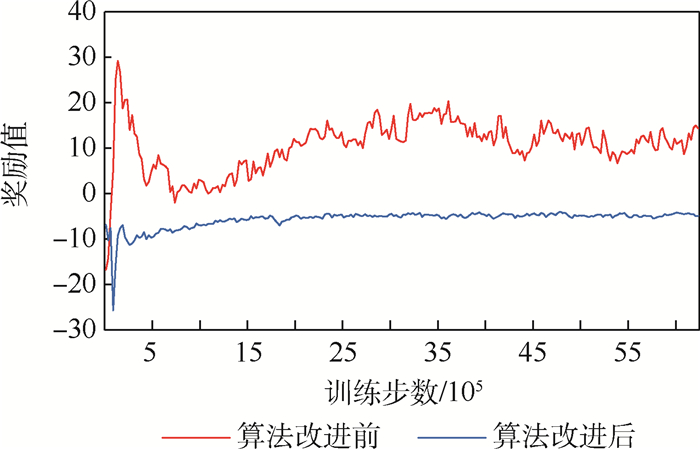
未来作战的发展方向是由多智能体系统构成的无人集群系统通过智能体之间自主协同来完成作战任务。由于每个智能体自主采取行为和改变状态,增加了智能群体行为策略训练的不稳定性。通过先验约束条件和智能体间的同构特性增强奖励信号的实时性,提高训练效率和学习的稳定性。采用动作空间边界碰撞惩罚、智能体间时空距离约束满足程度奖励;通过智能体在群体中的关系特性,增加智能体之间经验共享,进一步优化学习效率。在实验中,将先验增强的奖励机制和经验共享应用到多智能体深度确定性策略梯度(MADDPG)算法中验证其有效性。结果表明,学习收敛性和稳定性有大幅提高,从而提升了无人集群系统行为学习效率。
Abstract:Unmanned swarm system is composed of a multi-agent system, which can meet task requirements through autonomous and cooperative behavior. The instability of agent training is increased because agents adopt behavior and change states autonomously. In this paper, the prior constraints and the isomorphism between agents are used to enhance the real-time performance of reward signals and improve the efficiency of training and the stability of learning. Specifically, it includes the punishment of action space boundary collision and the reward for the satisfaction degree of the space-time distance constraint between agents. At the same time, through the relationship characteristics of agents in the group, experience sharing among agents is increased to further optimize the learning efficiency. In the experiment, the prior enhanced reward mechanism and experience sharing are applied to the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm to verify its effectiveness. It is observed that the learning convergence and stability are greatly improved, and thus the behavior learning efficiency of unmanned swarm system is enhanced.
-

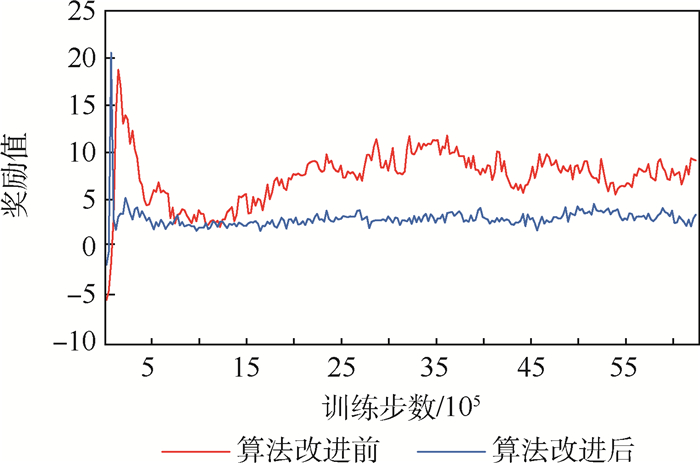
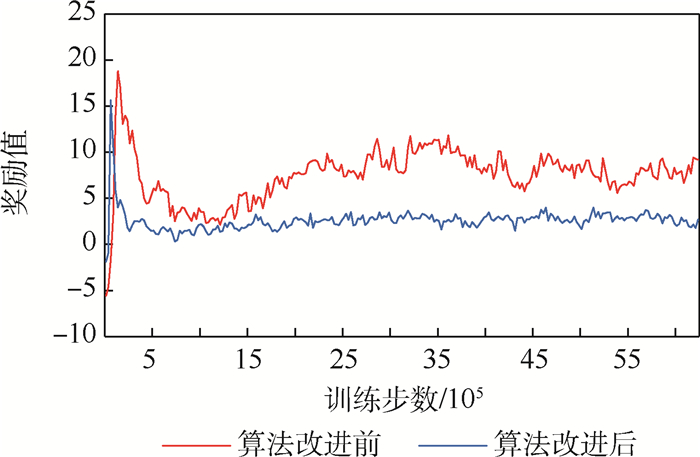
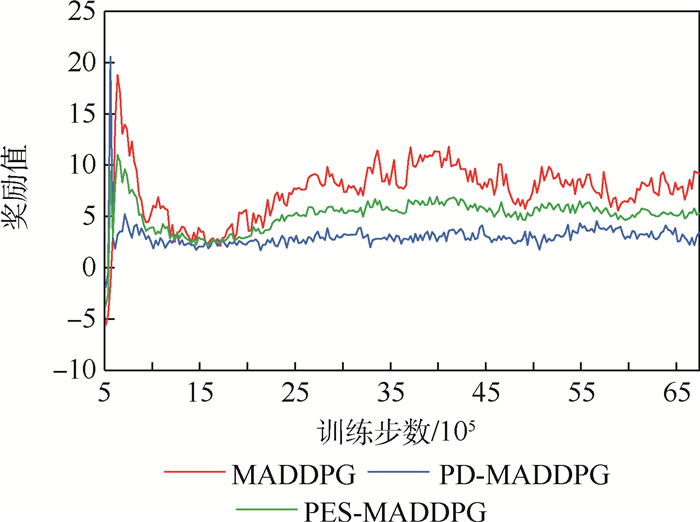
图 9 MADDPG、PD-MADDPG、PES-MADDPG算法奖励函数收敛性对比
Figure 9. Reward function convergence comparison among MADDPG, PD-MADDPG and PES-MADDPG algorithms
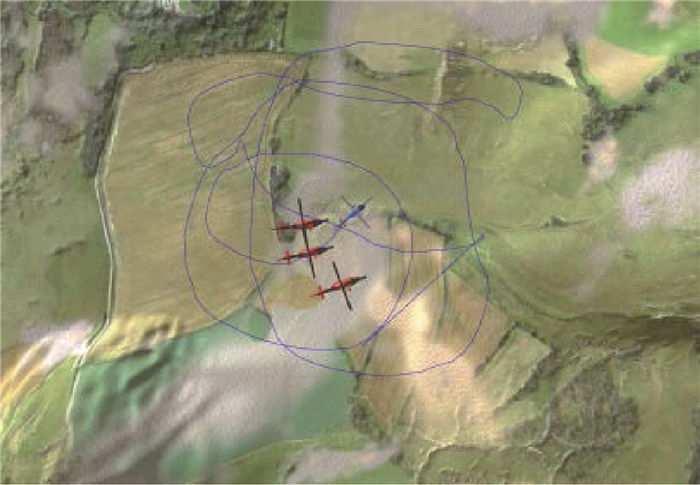
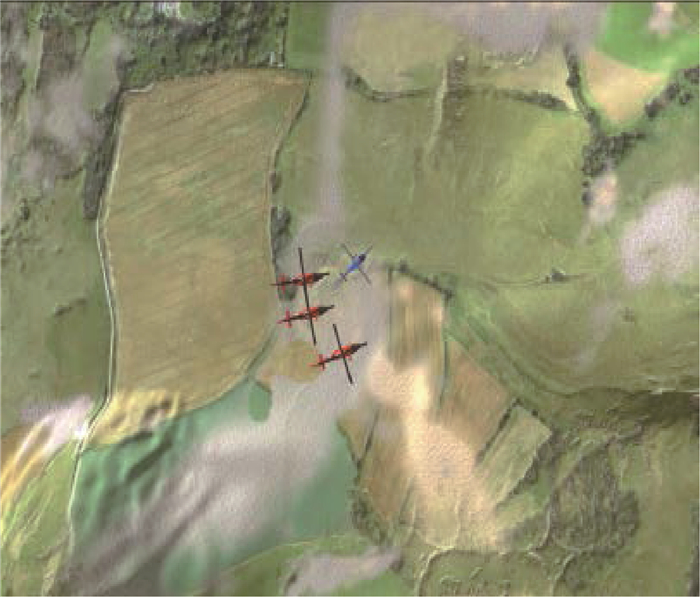
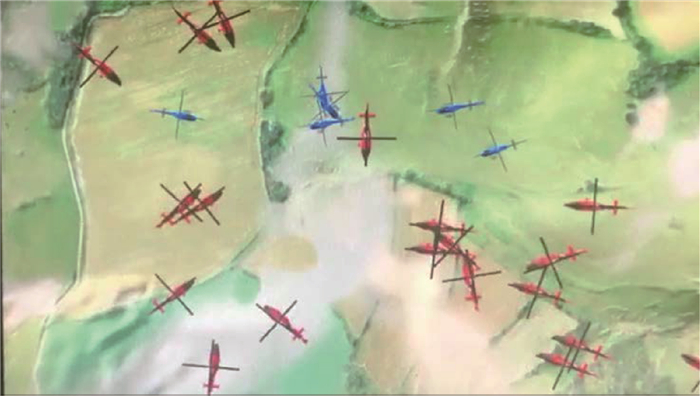
表 2 3V1对抗实验场景
Table 2. Experimental scenario of 3 versus 1 confrontation
场景名称 是否对抗 智能体数量 获胜条件 Simple_tag 是 3红
VS
1蓝蓝:蓝色Agent尽可能避免与3个红色Agent的碰撞
红:3个红色Agent之间尽可能协同与蓝色Agent发生碰撞 下载: 导出CSV
下载: 导出CSV
表 3 平均每步碰撞次数
Table 3. Average number of collisions per step
算法 奖励机制是否改进 平均碰撞次数 MADDPG 是
否0.538
0.521DDPG 是
否0.532
0.523
下载: 导出CSV
-
[1] 张婷婷, 宋爱国, 蓝羽石. 集群无人系统自适应结构建模与预测[J]. 中国科学: 信息科学, 2020, 50(1): 347-362. https://www.cnki.com.cn/Article/CJFDTOTAL-PZKX202003005.htmZHANG T T, SONG A G, LAN Y S. Adaptive structure modeling and prediction of cluster unmanned system[J]. Chinese Science: Information Science, 2020, 50(1): 347-362(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-PZKX202003005.htm [2] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46(7): 1301-1309. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO202007001.htmSUN C Y, MU C X. Important scientific problems of multi-agent deep reinforcement learning [J]. Journal of Automatica Sinica, 2020, 46(7): 1301-1309(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO202007001.htm [3] 陈杰. 多智能体系统中的几个问题[J]. 中国科学人, 2019, 12(1): 40-43. https://www.cnki.com.cn/Article/CJFDTOTAL-KXZG201912022.htmCHEN J. Several problems in multi-agent system [J]. Scientific Chinese, 2019, 12(1): 40-43(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-KXZG201912022.htm [4] LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[EB/OL]. (2020-03-14)[2020-03-22]. http://arxiv.org/abs/1706.02275. [5] 许诺, 杨振伟. 稀疏奖励下基于MADDPG算法的多智能体协同[J]. 现代计算机, 2020(15): 47-51. https://www.cnki.com.cn/Article/CJFDTOTAL-XDJS202015009.htmXU N, YANG Z W. Multi-agent collaboration based on MADDPG algorithm under sparse reward[J]. Modern Computer, 2020(15): 47-51(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-XDJS202015009.htm [6] 杨慧慧, 黄万荣, 敖富江. 基于强化学习的鱼群自组织行为模拟[J]. 国防科技大学学报, 2020, 42(1): 194-202. https://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ202001027.htmYANG H H, HUANG W R, AO F J. Simulation on self-organization behaviors of fish school based on reinforcement learning[J]. Journal of National University of Defense Technology, 2020, 42(1): 194-202(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ202001027.htm [7] 王毅然, 经小川, 贾福凯, 等. 基于多智能体协同强化学习的多目标追踪方法[J]. 计算机工程, 2020, 46(11): 90-96. doi: 10.3778/j.issn.1002-8331.1911-0132WANG Y R, JING X C, JIA F K, et al. Multi-target tracking method based on multi-agent collaborative reinforcement learning[J]. Computer Engineering, 2020, 46(11): 90-96(in Chinese). doi: 10.3778/j.issn.1002-8331.1911-0132 [8] 邹长杰, 郑皎凌, 张中雷. 基于GAED-MADDPG多智能体强化学习的协作策略研究[J]. 计算机应用研究, 2020, 37(12): 3656-3661. https://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ202012027.htmZOU C J, ZHENG J L, ZHANG Z L. Research on collaborative strategy based on GAED-MADDPG multi-agent reinforcement learning[J]. Application Research of Computers, 2020, 37(12): 3656-3661(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ202012027.htm [9] 高昂, 董志明, 李亮, 等. MADDPG算法并行优先经验回放机制[J]. 系统工程与电子技术, 2021, 43(2): 420-433. https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD202102018.htmGAO A, DONG Z M, LI L, et al. Parallel priority experience replay mechanism algorithm of MADDPG[J]. Systems Engineering and Electronics, 2021, 43(2): 420-433(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD202102018.htm [10] WEIREN K, DEYUN Z, ZHEN Y. Air combat strategies generation of CGF based on MADDPG and reward shaping[C]//2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL). Piscataway: IEEE Press, 2020: 651-655. [11] SUN Y, LAI J, CAO L, et al. A novel multi-agent parallel-critic network architecture for cooperative-competitive reinforcement learning[J]. IEEE Access, 2020, 8: 135605-135616. doi: 10.1109/ACCESS.2020.3011670 [12] ZHU P, DAI W, YAO W, et al. Multi-robot flocking control based on deep reinforcement learning[J]. IEEE Access, 2020, 8: 150397-150406. doi: 10.1109/ACCESS.2020.3016951 [13] VAN OTTERLO M, WIREING M. Reinforcement learning and Markov decision processes[M]//WIREING M, VAN OTTERLO M. Reinforcement learning. Berlin: Springer, 2012: 3-42. [14] 陈亮, 梁宸, 张景异, 等. Actor-Critic框架下一种基于改进DDPG的多智能体强化学习算法[J]. 控制与决策, 2021, 36(1): 75-82. https://www.cnki.com.cn/Article/CJFDTOTAL-KZYC202101008.htmCHEN L, LIANG C, ZHANG J Y, et al. A multi-agent reinforcement learning algorithm based on improved DDPG under actor critical framework[J]. Control and Decision, 2021, 36(1): 75-82(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-KZYC202101008.htm [15] 孙彧, 曹雷, 陈希亮, 等. 多智能体深度强化学习研究综述[J]. 计算机工程与应用, 2020, 56(5): 13-24. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG202005003.htmSUN Y, CAO L, CHEN X L, et al. A review of multi-agent deep reinforcement learning research[J]. Computer Engineering and Application, 2020, 56(5): 13-24(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG202005003.htm -

 下载:
下载:




 点击查看大图
点击查看大图

计量
- 文章访问数: 340
- HTML全文浏览量: 90
- PDF下载量: 221
- 被引次数: 0
