



-
摘要:
单声道歌声分离是指将单声道歌曲中的伴奏和歌声分离,在旋律提取、歌词识别、卡拉OK伴奏等方面有重要应用。针对当前时频谱图预测精度受限的问题,利用高分辨率网络具有并行结构及特征充分交互提高模型性能的优势,提出基于高分辨率网络的单声道歌声分离算法。设计并构建适合单声道歌声分离的高分辨率网络,输入歌曲的时频谱图到网络,得到预测的伴奏和歌声时频谱图。结合歌曲相位进行重构,得到伴奏和歌声的时域信号。实验表明,在公开数据集MIR-1K上,所提算法的SNR、SIR、SAR指标均优于当前代表性算法,提高了分离后伴奏和歌声的质量。
Abstract:Monaural singing voice separation separates singing voice and accompaniment from a song, which can be used for applications such as melody extraction, lyrics recognition, karaoke, etc. To resolve the limited accuracy of predicted spectrogram, this paper proposes a monaural singing voice separation algorithm based on high-resolution neural network, which has the advantages of parallel structure and sufficient features interaction for improving the performance of the model. Firstly, the high-resolution network suitable for singing voice separation is designed and constructed. Then, the spectrogram of the origin song is input to the network in order to get the predicted spectrograms of accompaniment and singing voice. Finally, the time-domain signals are reconstructed by combining the song phases with the separated spectrograms. Experiments conducted on the MIR-1K dataset show that SNR, SIR and SAR indicators of the proposed algorithm are better than those of the state-of-the-art algorithm, and the proposed algorithm improves the quality of the separated accompaniment and singing voice.
-

图 1 基于高分辨率网络的单声道歌声分离
Figure 1. Monaural singing voice separation based on high-resolution network

图 5 不同算法预测的时频谱图及纯净时频谱图
Figure 5. Spectrograms predicted by different algorithms and real spectrograms

图 6 不同歌声分离算法性能评估
Figure 6. Performance evaluation of different singing voice separation algorithms
-
[1] 李伟, 李子晋, 高永伟.理解数字音乐——音乐信息检索技术综述[J].复旦学报(自然科学版), 2018, 57(3):5-47. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=fdxb201803001LI W, LI Z J, GAO Y W.Understanding digital music-A review of music information retrieval technology[J].Journal of Fudan University(Natural Science), 2018, 57(3):5-47(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=fdxb201803001 [2] SIMPSON A J R, ROMA G, PLUMBLEY M D.Deep karaoke: Extracting vocals from musical mixtures using a convolutional deep neural network[C]//International Conference on Latent Variable Analysis and Signal Separation.Berlin: Springer, 2015: 429-436. [3] HUANG P S, KIM M, HASEGAWA-JOHNSON M, et al.Joint optimization of masks and deep recurrent neural networks for monaural source separation[J].IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(12):2136-2147. doi: 10.1109/TASLP.2015.2468583 [4] UHLICH S, PORCH M, GIRON F, et al.Improving music source separation based on deep neural networks through data augmentation and network blending[C]//2017 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP).Piscataway: IEEE Press, 2017: 261-265. [5] JANSSON A, HUMPHREY E, MONTECCHIO N, et al.Singing voice separation with deep U-Net convolutional networks[C]//18th International Society for Music Information Retrieval Conference(ISMIR), 2017: 745-751. [6] PARK S, KIM T, LEE K, et al.Music source separation using stacked hourglass networks[C]//19th International Society for Music Information Retrieval Conference(ISMIR), 2018: 289-296. [7] STOLLER D, EWERT S, DIXON S.Wave-U-Net: A multi-scale neural network for end-to-end audio source separation[C]//19th International Society for Music Information Retrieval Conference(ISMIR), 2018: 334-340. [8] SUN K, XIAO B, LIU D, et al.Deep high-resolution representation learning for human pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2019: 5693-5703. [9] SUN K, ZHAO Y, JIANG B R, et al.High-resolution representations for labeling pixels and regions[EB/OL].(2019-04-09)[2019-09-01].https://arxiv.org/abs/1904.04514. [10] VIRTANEN T.Monaural sound source separation by nonnegative matrix factorization with temporal continuity and sparseness criteria[J].IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(3):1066-1074. doi: 10.1109/TASL.2006.885253 [11] HUANG P S, CHEN S D, SMARAGDIS P, et al.Singing-voice separation from monaural recordings using robust principal component analysis[C]//2012 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP).Piscataway: IEEE Press, 2012: 57-60. [12] HSU C L, WANG D L, JANG J S R, et al.A tandem algorithm for singing pitch extraction and voice separation from music accompaniment[J].IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(5):1482-1491. doi: 10.1109/TASL.2011.2182510 [13] IKEMIYA Y, ITOYAMA K, YOSHⅡ K.Singing voice separation and vocal F0 estimation based on mutual combination of robust principal component analysis and subharmonic summation[J].IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(11):2084-2095. doi: 10.1109/TASLP.2016.2577879 [14] RAFⅡ Z, PARDO B.Music/voice separation using the similarity matrix[C]//13th International Society for Music Information Retrieval Conference(ISMIR), 2012: 583-588. [15] ZHU B L, LI W, LI R J, et al.Multi-stage non-negative matrix factorization for monaural singing voice separation[J].IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(10):2096-2107. doi: 10.1109/TASL.2013.2266773 [16] ZHANG X, LI W, ZHU B L.Latent time-frequency component analysis: A novel pitch-based approach for singing voice separation[C]//2015 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP).Piscataway: IEEE Press, 2015: 131-135. [17] DEIF H, WANG W, GAN L, et al.Local discontinuity based approach for monaural singing voice separation from accompanying music with multi-stage non-negative matrix factorization[C]//2015 IEEE Global Conference on Signal and Information Processing(GlobalSIP).Piscataway: IEEE Press, 2015: 93-97. [18] HE K M, ZHANG X Y, REN S Q, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE Press, 2016: 770-778. -

 下载:
下载:
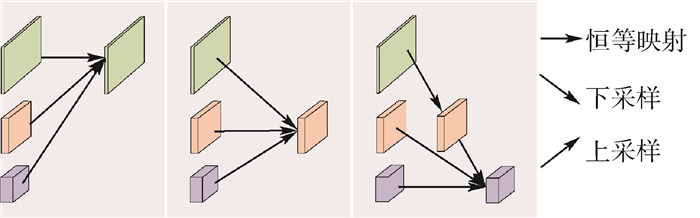
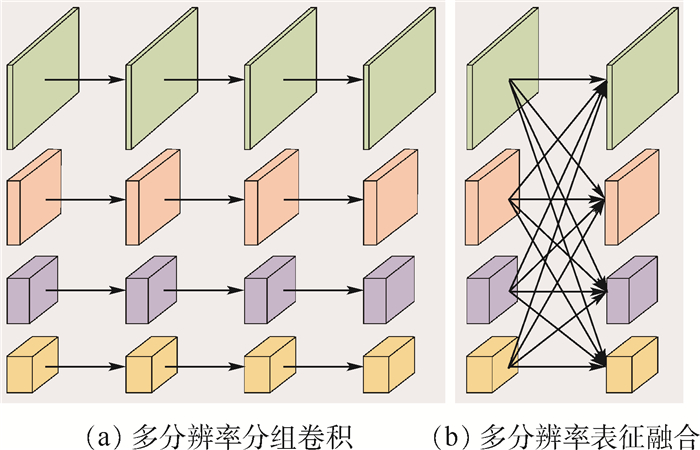




 点击查看大图
点击查看大图

计量
- 文章访问数: 470
- HTML全文浏览量: 74
- PDF下载量: 76
- 被引次数: 0
