



-
摘要:
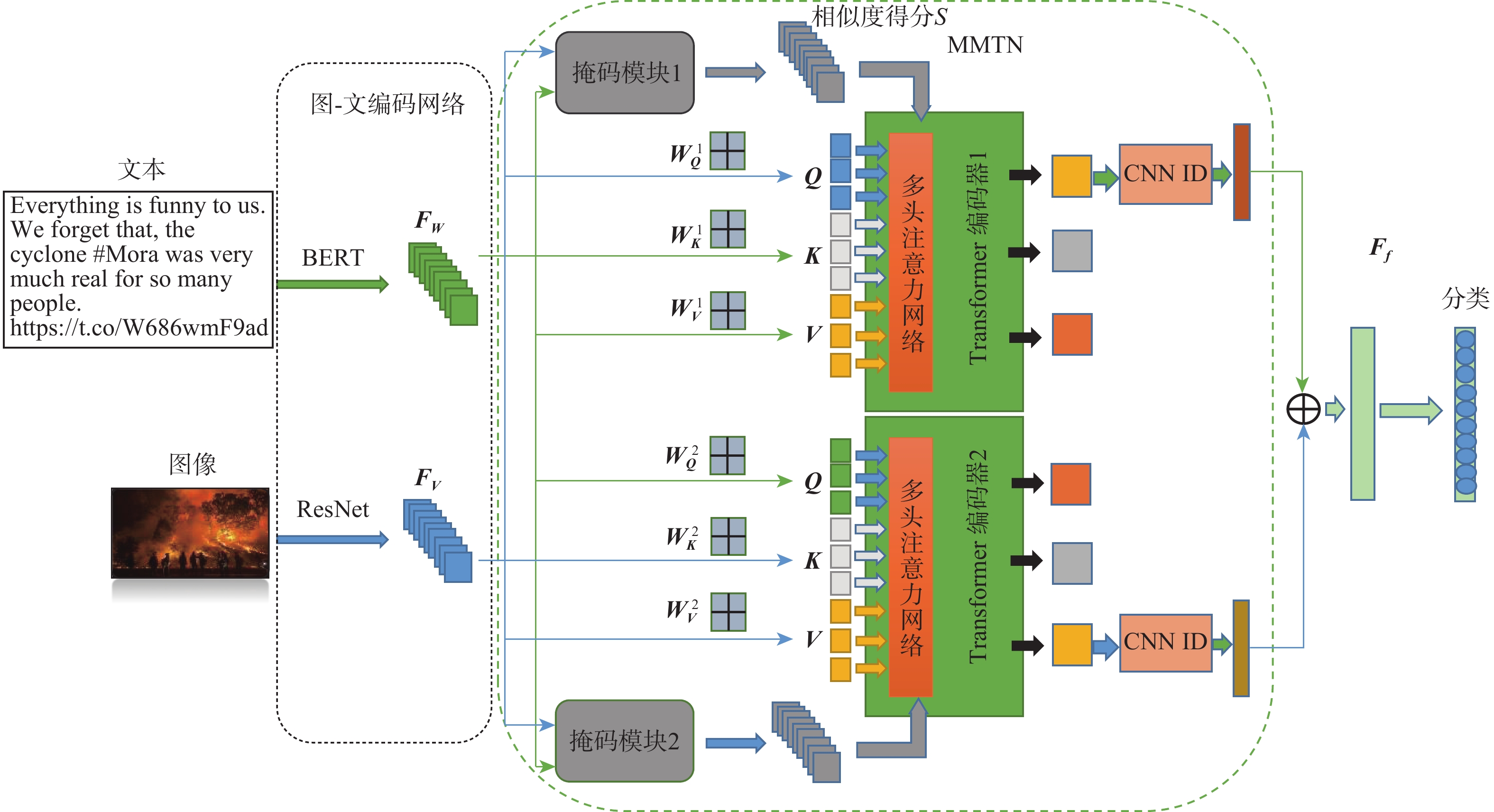
多模态社会事件分类的关键是充分且准确地利用图像和文字2种模态的特征。然而,现有的大多数方法存在以下局限性:简单地将事件的图像特征和文本特征连接起来,不同模态之间存在不相关的上下文信息导致相互干扰。因此,仅仅考虑多模态数据模态间的关系是不够的,还要考虑模态之间不相关的上下文信息(即区域或单词)。为克服这些局限性,提出一种新颖的基于多模态掩码Transformer网络(MMTN)模型的社会事件分类方法。通过图-文编码网络来学习文本和图像的更好的表示。将获得的图像和文本表示输入多模态掩码Transformer网络来融合多模态信息,并通过计算多模态信息之间的相似性,对多模态信息的模态间的关系进行建模,掩盖模态之间的不相关上下文。在2个基准数据集上的大量实验表明:所提模型达到了最先进的性能。
-
关键词:
- 多模态 /
- 社会事件分类 /
- 社交媒体 /
- 表示学习 /
- 多模态Transformer网络
Abstract:Utilizing both the properties of the text and image modalities to the fullest extent possible is essential for multi-modal social event classification. However,most of the existing methods have the following limitations: They simply concatenate the image features and textual features of events. The existence of irrelevant contextual information between different modalities leads to mutual interference. Therefore,it is not enough to only consider the relationship between modalities of multimodal data,but also consider irrelevant contextual information between modalities (such as regions or words). To overcome these limitations,this paper proposes a novel social event classification method based on multimodal mask transformer network (MMTN) model. Specifically,the authors learn better representations of text and images through an image-text encoding network. To combine multimodal data,the resultant picture and word representations are input into a multimodal mask Transformer network. By calculating the similarity between the multimodal information,the relationship between the modalities of the multimodal information is modeled,and the irrelevant contexts between the modalities are masked. Extensive experiments on two benchmark datasets demonstrate that the proposed model achieves the state-of-the-art performance.
-
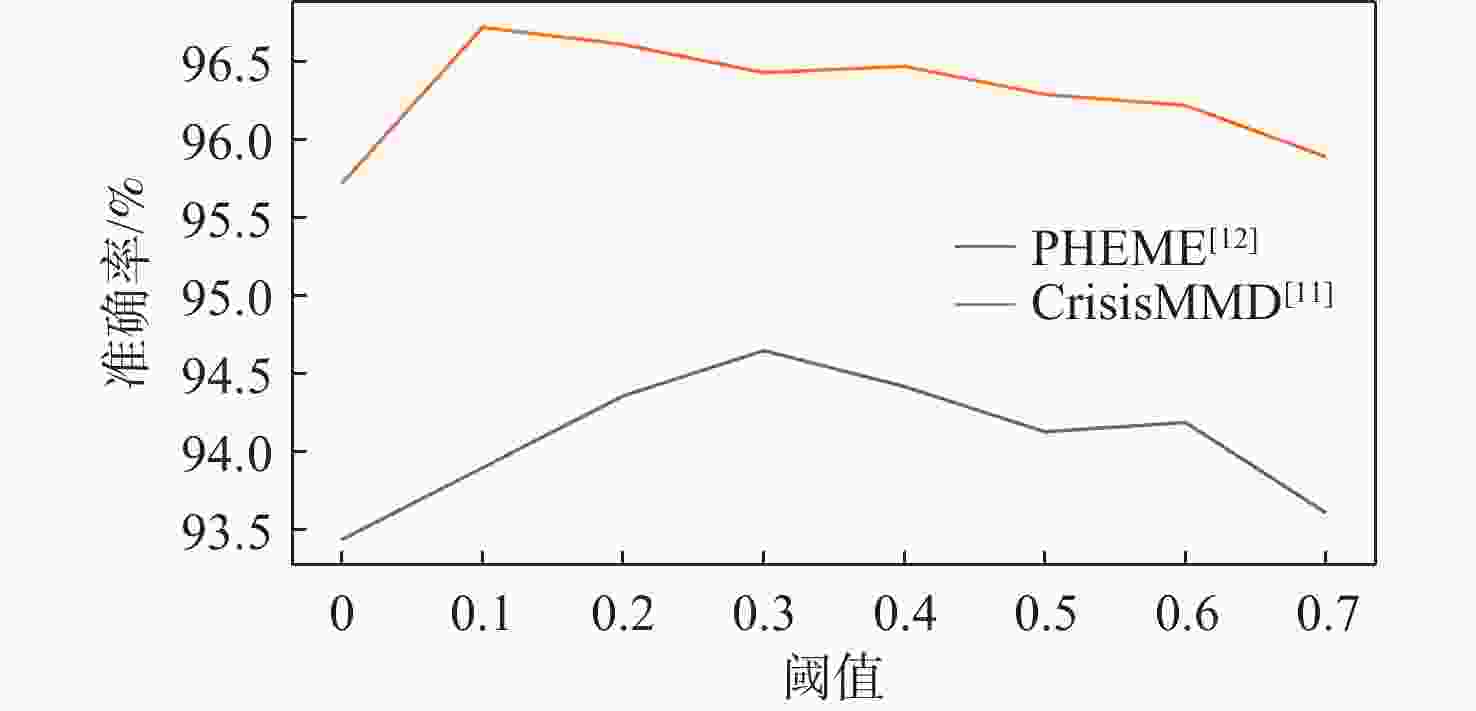
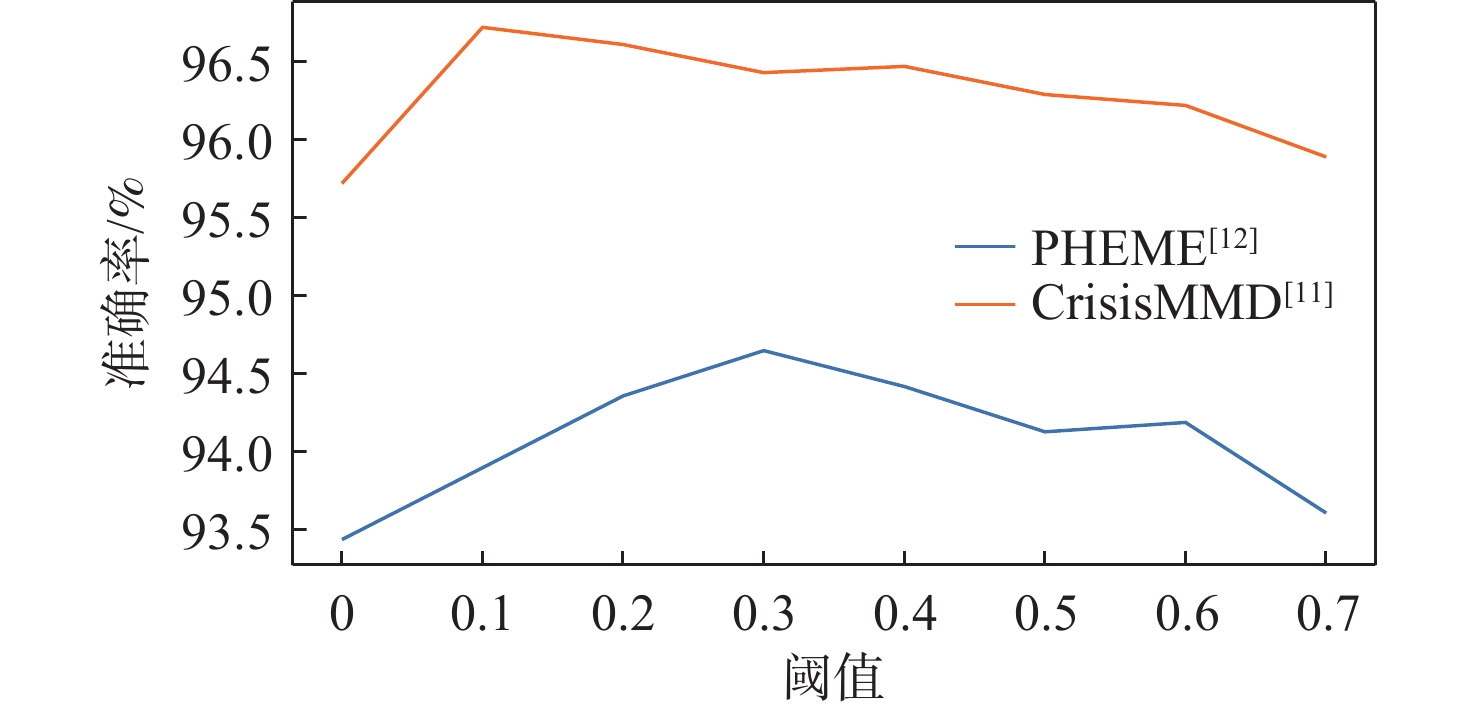
图 3 掩码模块不同阈值实验结果比较
Figure 3. Comparison of experimental results with different thresholds of mask module
事件 文本数量/条 图片/张 Hurricane Irma 4 041 4 525 Hurricane Harvey 4 000 4 443 Hurricane Maria 4 000 4 562 Mexico earthquake 1 239 1 382 California wildfires 1 486 1 589 Sri Lanka floods 832 1 025 Iraq-Iran earthquake 499 600 所有事件 16 097 18 126  下载: 导出CSV
下载: 导出CSV
事件 文本数量/条 图片/张 Charlie Hebdo 2 079 911 Sydney siege 1 221 413 Ferguson 1 143 355 Ottawa shooting 890 231 Germanwings-crash 469 179 所有事件 5 802 2 089
下载: 导出CSV
表 3 不同模型在CrisisMMD数据集上的实验结果
Table 3. Experimental results of different models on CrisisMMD dataset
%
下载: 导出CSV
表 4 不同模型在PHEME数据集上的实验结果
Table 4. Experimental results of different models on PHEME dataset
%
下载: 导出CSV
表 5 MMTN模型的不同变式在CrisisMMD[11]数据集上的检测性能比较
Table 5. Comparison of detection performance of different variants of MMTN model on CrisisMMD[11] dataset
% 模型 准确率 宏F1分数 加权F1分数 $ {\mathrm{MMTN}}\neg {{\boldsymbol{F}}}_{{\boldsymbol{VW}}} $ 94.82 95.63 94.84 $ {\mathrm{MMTN}}\neg {{\boldsymbol{F}}}_{{\boldsymbol{WV}}} $ 93.86 93.63 93.85 $ {\mathrm{MMTN}}\neg {\mathrm{M}} $ 95.72 96.35 95.72 $ {\mathrm{MMTN}}\neg {\mathrm{FI}} $ 94.76 94.75 94.77 $ {\rm{MMTN}} $ 96.72 97.09 96.72
下载: 导出CSV
表 6 MMTN模型的不同变式在PHEME[12]数据集上的检测性能比较
Table 6. Comparison of detection performance of different variants of MMTN model on PHEME[12] dataset
% 模型 准确率 宏F1分数 加权F1分数 $ {\mathrm{MMTN}}\neg {{\boldsymbol{F}}}_{{\boldsymbol{VW}}} $ 91.31 91.61 91.29 $ {\mathrm{MMTN}}\neg {{\boldsymbol{F}}}_{{\boldsymbol{WV}}} $ 91.71 92.42 91.71 $ {\mathrm{MMTN}}\neg {\mathrm{M}} $ 93.44 93.65 93.44 $ {\mathrm{MMTN}}\neg {\mathrm{FI}} $ 92.11 92.78 92.17 ${ \rm{MMTN}} $ 94.65 94.89 94.65
下载: 导出CSV
-
[1] KUMAR S, BARBIER G, ABBASI M, et al. TweetTracker: An analysis tool for humanitarian and disaster relief[C]//Proceedings of the International AAAI Conference on Web and Social Media. Washington, D. C. : AAAI, 2021, 5(1): 661-662. [2] SHEKHAR H, SETTY S. Disaster analysis through tweets[C]//Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics. Piscataway: IEEE Press, 2015: 1719-1723. [3] STOWE K, PAUL M J, PALMER M, et al. Identifying and categorizing disaster-related tweets[C]//Proceedings of the Fourth International Workshop on Natural Language Processing for Social Media. Stroudsburg: Association for Computational Linguistics, 2016. [4] TO H, AGRAWAL S, KIM S H, et al. On identifying disaster-related tweets: Matching-based or learning-based? [C]//Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data. Piscataway: IEEE Press, 2017: 330-337. [5] MOUZANNAR H, RIZK Y, AWAD M. Damage identification in social media posts using multimodal deep learning[C]//Proceedings of the 15th International Conference on Information Systems for Crisis Response and Management. Rochester: ISCRAM, 2018. [6] KELLY S, ZHANG X B, AHMAD K. Mining multimodal information on social media for increased situational awareness[C]//Proceedings of the 14th International Conference on Information Systems for Crisis Response and Management. Albi: ISCRAM, 2017. [7] ABAVISANI M, WU L W, HU S L, et al. Multimodal categorization of crisis events in social media[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 14667-14677. [8] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [9] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional Transformers for language understanding[EB/OL]. (2019-05-24) [2022-02-16]. https://arxiv.org/abs/1810.04805. [10] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [11] ALAM F, OFLI F, IMRAN M. CrisisMMD: Multimodal twitter datasets from natural disasters[C]//Proceedings of the International AAAI Conference on Web and Social Media. Washington, D. C. : AAAI, 2018, 12(1): 465-473. [12] KOCHKINA E, LIAKATA M, ZUBIAGA A. All-in-one: Multi-task learning for rumour verification[C]//Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe: Association for Computational Linguistics, 2018: 3402-3413. [13] LI X K, CARAGEA D, ZHANG H Y, et al. Localizing and quantifying damage in social media images[C]//Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. Piscataway: IEEE Press, 2018: 194-201. [14] NALLURU G, PANDEY R, PUROHIT H. Relevancy classification of multimodal social media streams for emergency services[C]//Proceedings of the 2019 IEEE International Conference on Smart Computing. Piscataway: IEEE Press, 2019: 121-125. [15] NIE X S, WANG B W, LI J J, et al. Deep multiscale fusion hashing for cross-modal retrieval[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(1): 401-410. doi: 10.1109/TCSVT.2020.2974877 [16] WU Y, ZHAN P W, ZHANG Y J, et al. Multimodal fusion with co-attention networks for fake news detection[C]//Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: Association for Computational Linguistics, 2021: 2560-2569. [17] MAO Y D, JIANG Q P, CONG R M, et al. Cross-modality fusion and progressive integration network for saliency prediction on stereoscopic 3D images[J]. IEEE Transactions on Multimedia, 2021, 24: 2435-2448. [18] QI P, CAO J, LI X R, et al. Improving fake news detection by using an entity-enhanced framework to fuse diverse multimodal clues[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 1212-1220. [19] DENG J, DONG W, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]//Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2009: 248-255. [20] KIELA D, BHOOSHAN S, FIROOZ H, et al. Supervised multimodal bitransformers for classifying images and text[EB/OL]. (2019-09-06) [2022-02-18]. https://arxiv.org/abs/1909.02950. [21] FUKUI A, PARK D H, YANG D, et al. Multimodal compact bilinear pooling for visual question answering and visual grounding[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2016: 457-468. [22] KIELA D, GRAVE E, JOULIN A, et al. Efficient large-scale multi-modal classification[EB/OL]. (2008-02-06) [2022-02-18]. https://arxiv.org/abs/1802.02892. [23] OFLI F, ALAM F, IMRAN M. Analysis of social media data using multimodal deep learning for disaster response[EB/OL]. (2020-04-14)[2022-02-18] .https://arxiv.org/abs/2004.11838. [24] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale visual recognition[EB/OL]. (2015-04-10) [2022-02-20]. https://arxiv.org/abs/1409.1556. [25] LI X, CARAGEA D. Improving disaster-related tweet classification with a multimodal approach[C]//Proceedings of the 17th ISCRAM Conference. Blacksburg: ISCRAM, 2020: 893-902. [26] CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN Encoder–Decoder for statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2014: 1724-1734. [27] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. doi: 10.1145/3065386 [28] HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 2261-2269. -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 609
- HTML全文浏览量: 77
- PDF下载量: 5
- 被引次数: 0
