| Citation: | ZHANG R Y,NIE J,SONG N,et al. Remote sensing image-text retrieval based on layout semantic joint representation[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):671-683 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0527

|
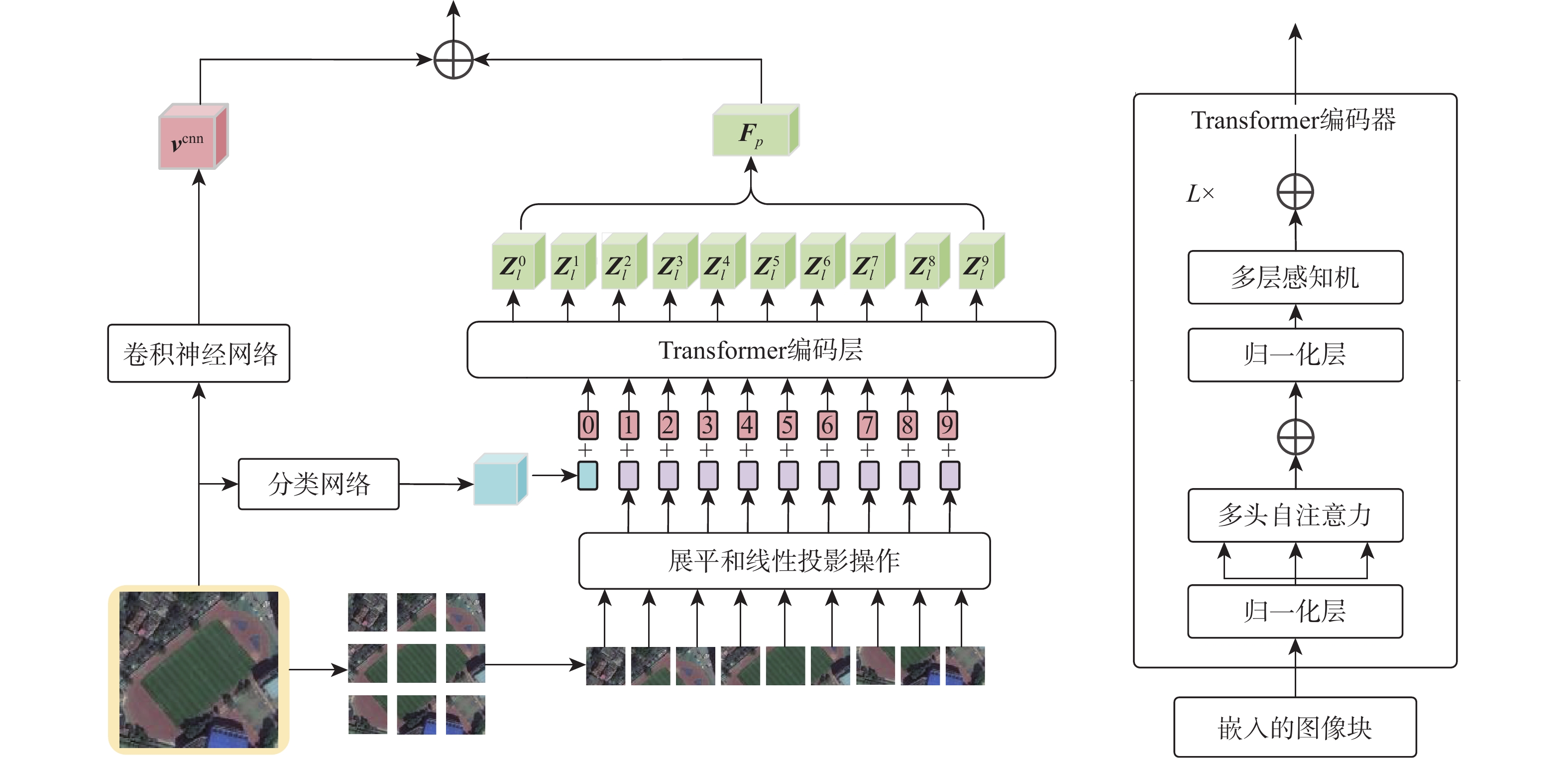
Remote sensing image-text retrieval can retrieve valuable information from remote sensing data. It is of great significance to environmental assessment, urban planning and disaster prediction. However, there is a key problem that the spatial layout information of remote sensing images is ignored, which is mainly reflected in two aspects: one is the difficulty of long-distance modeling of remote sensing targets; the other, the submerge of the remote sensing adjacent secondary targets. Based on the above problems, this paper proposes a cross modal remote sensing image-text retrieval model based on layout semantic joint representation, which includes the dominant semantic supervison layout visual feature extraction module (DSSL), Layout visual-global semantic cross guidance (LV-GSCG) and multi-view matching (MVM). The DSSL module realizes the layout modeling of images under the supervision of dominant semantic category features. The LV-GSCG module calculates the similarity between the layout visual features and the global semantic features extracted from text to realize the interaction of different modal features. The MVM module establishes a cross-modal feature-guided multi-view metric matching mechanism to eliminate the semantic gap between the cross-modal data. Experimental validation on four baseline remote sensing image text datasets shows that the model can achieve state-of-the-art performance in most cross-modal remote sensing image text retrieval tasks.

| [1] |
LIU Y J, LI X F, REN Y B. A deep learning model for oceanic mesoscale eddy detection based on multi-source remote sensing imagery[C]// IGARSS 2020 - 2020 IEEE International Geoscience and Remote Sensing Symposium. Piscataway: IEEE Press, 2020: 6762-6765.
|
| [2] |
ZHANG Q L, SETO K C. Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data[J]. Remote Sensing of Environment, 2011, 115(9): 2320-2329. doi: 10.1016/j.rse.2011.04.032
|
| [3] |
NOGUEIRA K, FADEL S G, DOURADO I C, et al. Exploiting ConvNet diversity for flooding identification[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(9): 1446-1450. doi: 10.1109/LGRS.2018.2845549
|
| [4] |
CHENG Q M, ZHOU Y Z, FU P, et al. A deep semantic alignment network for cross-modal image-text retrieval in remote sensing[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 4284-4297. doi: 10.1109/JSTARS.2021.3070872
|
| [5] |
YUAN Z Q, ZHANG W K, FU K, et al. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4404119.
|
| [6] |
葛芸, 马琳, 叶发茂, 等. 基于多尺度池化和范数注意力机制的遥感图像检索[J]. 电子与信息学报, 2022, 44(2): 543-551.
GE Y, MA L, YE F M, et al. Remote sensing image retrieval based on multi-scale pooling and norm attention mechanism[J]. Journal of Electronics & Information Technology, 2022, 44(2): 543-551(in Chinese).
|
| [7] |
李彦甫, 范习健, 杨绪兵, 等. 基于自注意力卷积网络的遥感图像分类[J]. 北京林业大学学报, 2021, 43(10): 81-88. doi: 10.12171/j.1000-1522.20210196
LI Y F, FAN X J, YANG X B, et al. Remote sensing image classification farmework based on self-attention convolutional neural network[J]. Journal of Beijing Forestry University, 2021, 43(10): 81-88(in Chinese). doi: 10.12171/j.1000-1522.20210196
|
| [8] |
YUAN Z Q, ZHANG W K, TIAN C Y, et al. Remote sensing cross-modal text-image retrieval based on global and local information[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 3163706.
|
| [9] |
RONG X E, SUN X, DIAO W H, et al. Historical information-guided class-incremental semantic segmentation in remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5622618.
|
| [10] |
ZHANG Z Y, HAN X, LIU Z Y, et al. ERNIE: Enhanced language representation with informative entities[C]//Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 1441-1451.
|
| [11] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale[C]//International Conference on Learning Representations. Washington DC: ICLR, 2020: 16-28.
|
| [12] |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// In European Conference on Computer Vision. Berlin: Springer, 2020: 213-229.
|
| [13] |
SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition[C]// /IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 16514–16524.
|
| [14] |
HE K M, ZHANG X Y, REN S Q, et al . Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
|
| [15] |
LIU S L, ZHANG L, YANG X, et al. Query2Label: A simple transformer way to multi-label classification[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 661-670.
|
| [16] |
MESSINA N, AMATO G, FALCHI F, et al. Towards efficient cross-modal visual textual retrieval using transformer-encoder deep features[C]// 2021 International Conference on Content-Based Multimedia Indexing. Piscataway: IEEE Press, 2021: 1-6.
|
| [17] |
GABEUR V, SUN C, ALAHARI K, et al. Multi-modal transformer for video retrieval[C]// Conference on Computer Vision. Berlin: Springer, 2020: 214-229.
|
| [18] |
MALEKI D, TIZHOOSH H R. LILE: look in-depth before looking elsewhere -- A dual attention network using transformers for cross-modal information retrieval in histopathology archives[J]. Proceedings of Machine Learning Research. Virtual: PMLR, 2022: 3002-3013.
|
| [19] |
SHI Z W, ZOU Z X. Can a machine generate humanlike language descriptions for a remote sensing image[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(6): 3623-3634. doi: 10.1109/TGRS.2017.2677464
|
| [20] |
LU X Q, WANG B Q, ZHENG X T, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183-2195. doi: 10.1109/TGRS.2017.2776321
|
| [21] |
HOXHA G, MELGANI F, SLAGHENAUFFI J. A new CNN-RNN framework for remote sensing image captioning[C]//2020 Mediterranean and Middle-East Geoscience and Remote Sensing Symposium. Piscataway: IEEE Press, 2020: 1-4.
|
| [22] |
LI X L, ZHANG X T, HUANG W, et al. Truncation cross entropy loss for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(6): 5246-5257. doi: 10.1109/TGRS.2020.3010106
|
| [23] |
LU X Q, WANG B Q, ZHENG X T. Sound active attention framework for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(3): 1985-2000. doi: 10.1109/TGRS.2019.2951636
|
| [24] |
FAGHRI F, FLEET D J, KIROS J R , et al. VSE++: improving visual-semantic embeddings with hard negatives[C]// British Machine Vision Conference. London : British Machine Vision Association, 2017: 1707-1717.
|
| [25] |
LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 212-228.
|
| [26] |
WANG T, XU X, YANG Y, et al. Matching images and text with multi-modal tensor fusion and re-ranking[C]// the 27th ACM International Conference. New York: ACM, 2019, 1: 12-20.
|
| [27] |
DEVLIN J, CHENG H, FANG H, et al. Language models for image captioning: the quirks and what works[J]. Computer Science, 2015, 2(53): 100-105.
|
| [28] |
ABDULLAH, BAZI, RAHHAL A, et al. TextRS: Deep bidirectional triplet network for matching text to remote sensing images[J]. Remote Sensing, 2020, 12(3): 405. doi: 10.3390/rs12030405
|
| [29] |
QU B, LI X L, TAO D L, et al. Deep semantic understanding of high resolution remote sensing image[C]// International Conference on Computer. Piscataway: IEEE Press, 2016: 124-128.
|
| [30] |
WANG Z H, LIU X H, LI H S, et al. CAMP: Cross-modal adaptive message passing for text-image retrieval[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2010: 5763-5772.
|

Figures(5) / Tables(8)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: