


软件缺陷是危害软件质量、增加组织成本、延缓软件开发进度的重要因素.由于质量保证资源的有限,高效地发现和修复缺陷一直是软件工程领域的研究重点.为帮助软件人员有效分配测试和审查资源,软件工程领域的研究者提出两种策略[1]:①在缺陷存在于软件系统之后,识别缺陷 可能存在的区域;②在缺陷即将引入软件系统时,识别引入缺陷的软件变更.第②种策略的优势在于:一是在缺陷引入时给出警告,从而帮助软件人员更加及时地分配资源,发现缺陷;二是通过分析引入缺陷的变更所具有的特征,从而帮助研究者理解缺陷引入的根源.
针对第②种策略,研究者提出了不同粒度的引入缺陷变更识别方法.文献[1]关注于事务粒度引入缺陷变更的识别.基于文本分类思想,首先将事务变更表示为变更发生前后两个软件版本所对应词向量之差,然后作为分类实例训练分类器,对新的事务变更进行识别.文献[2]关注于文件粒度变更的识别,除了将文件粒度变更所涉及的词作为特征之外,还选用了一系列刻画源文件复杂度和历史活跃性的度量作为辅助特征.相比于文献[1],文献[2]的方法不但降低了识别的粒度,并通过构建更加直观的特征集增强了方法的可理解性.
在2012年的软件工程预测模型会议上,专家指出,考虑软件工程实践的成本因素,细粒度的识别和预测将成为未来软件工程预测方法关注的重点.尽管文献[2]的方法将识别粒度降低到了文件级别变更,但是文件级变更常涉及多处语句修改.尤其在文件规模较大,内部结构较复杂时,这种文件内多处修改的现象更为常见.这种情况下,即使识别出了引入缺陷的文件变更,仍然需要软件人员逐一审查所有发生修改的文件语句,才能找到引入缺陷的位置.为进一步降低人力成本,本文提出更细粒度(语句层级)的引入缺陷变更识别方法.该方法从细粒度变更发生的场景(时间、地点、内容、意图以及人员)出发构建特征集,将细粒度软件变更作为实例构建分类器.相比于文献[1, 2],本文的主要贡献包括两个方面:①通过还原细粒度变更发生的场景,描述引入缺陷的变更的特征,增强了识别方法的可理解性;②通过降低识别粒度,节省了软件开发过程中人工审查的成本. 1 基本概念 1.1 细粒度软件变更
假设源文件d的第i个修正版本对应一棵抽象语法树Ti=〈N,P〉,其中N代表语法树中代码实体节点的集合,P代表代码实体之间的父子关系集合.将对语法树Ti的一次节点插入、删除、移动或者更新定义为一个编辑操作,每个编辑操作都代表着一次细粒度软件变更[3],简称SCC.由于操作是基于语法树实体节点进行的,因此细粒度软件变更可以精确至语句层级. 1.2 引入缺陷细粒度软件变更
如果细粒度软件变更会引发缺陷并在后续开发过程中触发代码修复操作,那么定义此次细粒度软件变更为引入缺陷的细粒度软件变更.
图 1是细粒度软件变更示意图,图中共包含3个细粒度软件变更,其中if语句插入属于引入缺陷的细粒度软件变更.
 |
| 图 1 细粒度软件变更 Fig. 1 Fine-grained software changes |
给定一组细粒度软件变更,将其形式化表示为C={SCC1,SCC2,…,SCCn}. i∈{1,2,…,n},SCCi用一组特征F={f1,f2,…,fm}来表征.通过学习C构建分类器L.对一个新的细粒度软件变更SCCn+1,依据其特征对其所属类别进行识别,形式化表示为
i∈{1,2,…,n},SCCi用一组特征F={f1,f2,…,fm}来表征.通过学习C构建分类器L.对一个新的细粒度软件变更SCCn+1,依据其特征对其所属类别进行识别,形式化表示为
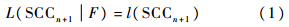
引入缺陷细粒度变更识别方法主要包含两个重要部分:特征集和分类器.本节详细介绍这两部分. 2.1 特征集
本文通过还原细粒度软件变更发生的场景来描述其特征,关注变更发生的时间、地点、内容、意图和人员5个方面.如图 2所示,每个方面代表一个特征集,每个特征集涉及多个因素.
 |
| 图 2 特征集 Fig. 2 Feature sets |
软件变更是由人操纵的活动,由于自身或外界因素,人的工作质量在不同的时段并不相同.Eyolfson等人[4]在分析Linux内核的软件历史库时发现,从午夜至凌晨发生的变更,更易引入缺陷.此外,Sliwerski等人[5]指出,每周五发生的变更具有较高的引入缺陷的风险.基于前人的发现,本文选用了两个刻画时间的因素,即一周内的天和一天的钟点,反映了软件人员的工作周期. 2.1.2 地 点
本文将发生细粒度变更的源文件作为变更地点,它反映了变更所处的上下文环境.源文件的规模,内部结构复杂程度,同其他源文件的交互关系复杂程度,领域功能的多样性,以及历史上的稳定性都会影响细粒度变更引入缺陷的风险.
1) 代码行数:源文件的代码行数过多,会影响可读性从而增加软件人员的理解难度.不透彻的程序理解往往是软件变更引入缺陷的原因.
2) Halstead复杂度[6]:通过源文件算子和算域的数量来反映代码内部操作的复杂程度.Halstead复杂度越高,代码的内部实现越复杂,正确理解和变更它的难度也越大.
3) McCabe复杂度[7]:通过源文件函数中线性独立路径数目来反映代码内部的控制流结构复杂程度.McCabe复杂度越高,说明源文件内的选择和判断逻辑越复杂,变更引入缺陷的风险越大.
4) 软件依赖图复杂度:软件开发是一项复杂的任务,软件模块之间常具有复杂的依赖关系,因此在未充分理解软件整体结构的情况下对软件模块进行更改,经常会引入缺陷.近年来,研究者们开始关注软件模块之间的依赖关系对缺陷分布规律的影响[8].本文将软件系统抽象为依赖图G=〈V,E〉,其中V代表节点(即源文件)集合,E代表边(源文件之间的关系)集合.源文件之间的关系指的是通过源文件中的类和接口所建立的继承、关联、依赖或实现关系.本文选用节点在依赖图中的出入度作为描述源文件和软件系统中其他文件之间依赖关系复杂程度的度量.
5) 语义主题多样性:涉及多种领域功能的源文件,其实现逻辑通常较为繁杂,对其进行变更引入缺陷的风险也较大.反映领域功能的信息存在于源文件的自然语言(如程序实体名称、程序注释等)之中.本文通过挖掘源文件中的自然语言语义主题,定义了一种描述源文件领域功能多样性的度量.由于源文件多个版本存在严重的信息冗余,直接针对软件历史库中的多版本源文件进行语义挖掘会面临推断结果不准确的问题[9].因此本文采用针对源文件相邻版本间编辑文件的主题挖掘方法来消除文本信息冗余.
假设软件系统中蕴含主题为T={t1,t2,…,t|T|},细粒度变更SCCi发生在软件系统的第u个版本的第v个源文件中,将其所对应的软件历史表示为H={V1,V2,…,Vu-1},源文件表示为duv.duv和前一个版本比较得到增加和删除两个编辑文件δuva和δuvd,简写为δuvx,x∈{a,d}.针对历史上所有编辑文件运用LDA Gibbs抽样算法进行主题推断,从而得到δuvx,x∈{a,d}的主题分布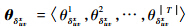 :
:
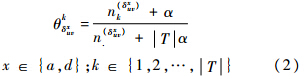
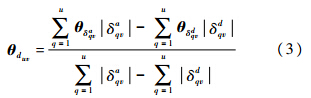
6) 历史活跃度:在软件开发历史上被频繁修改的源文件,其包含缺陷和未来再次发生修改的概率要明显高于历史上较为稳定的源文件[11].本文假设对历史上较为活跃的源文件实施修改更容易引发缺陷.为了描述源文件的历史活跃度,本文选用历史变更次数、修复缺陷次数及历史上参与变更该源文件的软件人员个数这3种度量. 2.1.3 内 容
变更内容本身的语法语义难度对变更质量有着直接的影响.本文通过3个因素描述变更内容.
1) 变更类型:细粒度变更由于完成的抽象语法树操作特点不同,引入缺陷的概率也不同.Pan等人[12]指出,涉及程序逻辑或方法接口的修改(如条件表达式的更改或方法参数的增删)引入缺陷风险较大.Fluri等人[3]针对抽象语法树操作特点将细粒度变更系统地分为48种类型,包括条件表达式更新,方法参数插入等.本文依据该分类法将变更类型作为描述变更内容的特征.
2) 变更实体类型:Pan等人[12]还发现,针对某些语法实体(如if条件语句、switch语句以及while循环语句)的变更,引入缺陷的概率较高.Fluri等人对抽象语法树实体也进行了分类(共104种).基于他们的工作,本文将变更所操纵的语法实体类型也作为描述变更内容的一个特征.
3) 语义主题缺陷倾向性:细粒度变更内容,除了用语法树特征来刻画外,还需通过其涉及的领域功能来描述.Chen等人[13]指出,实现简单领域功能(如数据库操作)的代码片断包含缺陷的概率显著小于实现复杂领域功能(如分析器)的代码片断.本文假设变更所涉及的领域功能不同,引入缺陷的概率也不同.本文提出语义主题缺陷倾向性度量来刻画变更所涉及的领域功能特征.
为细粒度软件变更SCCi,i=1,2,…,n所对应的软件历史H={V1,V2,…,Vu-1}中的每一个编辑文件δpqx,x∈{a,d},p∈{1,2,…,u-1},q∈{1,2,…,Vp}定义缺陷感染率度量,即
 )代表δpqx,x∈{a,d}不为空时值为1,反之为0.假设SCCi涉及m个词W={w1,w2,…,wm},根据LDA Gibbs抽样每个词被分配一个主题,则SCCi涉及的主题集合为Tr={tr1,tr2,…,trl}.最终定义SCCi的语义主题缺陷倾向性度量为
)代表δpqx,x∈{a,d}不为空时值为1,反之为0.假设SCCi涉及m个词W={w1,w2,…,wm},根据LDA Gibbs抽样每个词被分配一个主题,则SCCi涉及的主题集合为Tr={tr1,tr2,…,trl}.最终定义SCCi的语义主题缺陷倾向性度量为
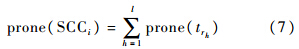
变更是为了某种目的而实施的活动,如增加新功能、重构或者修复缺陷等.Mockus等人[14]提出了分类和识别变更意图的方法.此外他们在研究商业软件变更风险因素时发现,变更意图影响变更质量.Hassan等人[15]针对开源软件提出了变更意图分类方法.借鉴已有研究成果,本文将细粒度变更意图分为缺陷修复、增加新功能和代码改进3类.软件的变更意图蕴藏在软件库的变更描述信息中.不同变更,其描述信息篇幅也不相同.通常较为复杂的变更,其描述信息也较为详尽.因此将变更描述信息容量也作为因素之一.总的来说,描述变更意图的因素包括: 1) 意图类型; 2) 描述变更意图的语句数量; 3) 描述变更意图的词的数量. 2.1.5 人 员
软件人员是细粒度变更的实施者,他们的开发经验和专业技能直接影响着变更的质量.本文定义两种度量来描述变更人员的经验特征.
1) 项目经验:修改整个软件系统的次数.
2) 源文件经验:修改该源文件的次数. 2.2 分类器
本文选择了3种机器学习分类器来进行训练和识别,即K近邻、装袋以及随机森林.这3种分类器被广泛用于缺陷预测模型的构建[1, 16].
1) K近邻:属于一种基于实例的学习或懒学习分类器,它依据特征空间中与待分类实例最相近的实例集中的实例标签做出分类决策.
2) 装袋:属于一种组装学习分类器,主要用来改进统计分类和回归算法的稳定性和准确性.它还通过降低方差来避免学习过程中的过拟合.
3) 随机森林:是一种结合装袋思想与随机特征选择思想的组装学习分类器.它通过降低不同决策树之间的关联度改进了装袋分类器.随机森林分类器被证明在含有噪声和类分布不均衡的数据集上具有较好的分类效果[17]. 3 实验和评估 3.1 数据集和数据收集
为验证识别方法的有效性,本文在6个真实软件系统上开展实验,分别是Eclipse(简称为Ecl),Argouml(简称为Arg),Columba(简称为Col),JBoss(简称为JBo),Scarab(简称为Sca)和Struts(简称为Str).表 1列出了系统的详细信息,包括实验所选择的软件修正版本区间、发生在该区间内的细粒度变更总数、引入缺陷的细粒度变更百分比以及软件系统的应用类型.为了和事务粒度以及文件粒度识别方法进行比较,本文所选择的修正版本区间和文献[1, 2]保持一致.
| 项目 | 修正版本 | 细粒度变更总数 | 引入缺陷细粒度变更百分比/% | 类型 |
| Ecl | 500-1000 | 4467 | 6 | Java IDE |
| Arg | 2500-3000 | 6187 | 18 | UML建模工具 |
| Col | 500-1000 | 4279 | 13 | 邮件客户端 |
| JBo | 500-1000 | 8343 | 7 | J2EE应用服务 |
| Sca | 500-1000 | 2149 | 25 | 缺陷追踪系统 |
| Str | 500-1000 | 2809 | 11 | MVC框架 |
本文采用程序静态分析和自然语言语义分析相结合的方法完成细粒度变更特征的抽取和类标签构建.图 3描述了数据收集过程.其中用来刻画时间、人员、意图以及地点中的历史活跃度的特征通过分析软件历史库的提交日志直接抽取.变更地点中的Halstead复杂度、McCabe复杂度、依赖图复杂度以及变更内容中的细粒度变更类型和实体类型需要通过静态分析技术来抽取.为提高每个版本依赖图构建的效率,本文提出一种不确定性程序静态分析算法实现增量图构建.语义主题多样性和语义主题缺陷倾向性需要通过挖掘源代码文件的自然语言语义信息来抽取.此外还需要为细粒度变更打上类别标签(即是否为引入缺陷的变更).本文采用多版本语句追踪改进了经典的变更实例标签构建SZZ算法[5],从而实现了精确至语句层级的细粒度变更的标签构建.
 |
| 图 3 数据收集过程 Fig. 3 Data collection process |
本文采用10折交叉验证评估方法来评估所提出的细粒度识别方法在3种不同类型分类器上的性能.表 2列出了3种分类器经过10次10折交叉验证所得到的平均识别性能.为了测试不同分类器识别性能的差异,本文采用了t检验法.
| 分类算法 | 项目 | 精确度 | 召回率 | F值 |
| 随机森林 |
|
| 装袋 |
|
| K近邻 | Ecl | 0.576 | 0.518 | 0.545 |
| Arg | 0.685 | 0.634 | 0.658 | |
| Col | 0.569 | 0.479 | 0.520 | |
| JBo | 0.656 | 0.558 | 0.603 | |
| Sca | 0.681 | 0.664 | 0.672 | |
| Str | 0.773 | 0.714 | 0.742 |
经过检验发现,采用不同分类器得到的识别性能不同.随机森林分类器的性能显著优于另外两种分类器,K近邻分类器在大多数系统上的识别性能显著优于装袋分类器(p<0.01).由于软件历史库中所记录的数据并不是绝对完整和准确的,现有的库挖掘技术手段也存在不足,因此实验数据集中常存在噪声.经研究证实,随机森林相比于其他分类器,对数据噪声具有更强的鲁棒性[17].因此随机森林在本文的实验中具有最为突出的识别性能. 从表 1中可以看出,不同的软件系统,引入缺陷的细粒度变更百分比也不同.文献[2]在研究文件粒度变更时指出,引入缺陷变更的百分比对文件变更识别方法的性能具有一定的影响.本文分析了引入缺陷的细粒度变更百分比对本文方法性能的影响.通过表 3列出的Pearson相关性分析结果发现,这种影响在本文提出的方法中要明显弱于文献[2]中针对文件粒度变更的方法,说明本文方法对于不同系统引入缺陷变更比例的差异具有更好的鲁棒性.
| 识别性能 | 相关性 |
| 引入缺陷细粒度变更百分比 vs 精确度 | 0.039 |
| 引入缺陷细粒度变更百分比vs召回率 | 0.520 |
| 引入缺陷细粒度变更百分比vs F值 | 0.363 |
本文遵循以下两个步骤验证特征集中每个因素的识别性能:①仅使用该因素训练分类器;②从特征全集中仅移除该因素训练分类器.这里也采用10折交叉验证法得到识别性能. 图 4显示了各因素在6个软件系统中的平均识别性能.从图中可以看出,移去主题缺陷倾向性因素对整体识别性能的影响最大.变更地点中的语义主题多样性和Halstead复杂度两个因素具有最好的识别性能,刻画变更内容的主题缺陷倾向性和刻画变更人员的项目经验因素次之.意图类型和一周内的天是性能最差的两个因素.为了进一步验证各因素在不同项目间性能表现的一致性,本文为每个软件系统建立因素识别性能向量,然后将6个系统所对应的6个向量两两进行Spearman相关性分析.从表 4看出,相关性值在0.78~0.91之间,且均显著(p<0.05).
 |
| 图 4 各因素的识别性能 Fig. 4 Identification performances of features |
| 项目 | Ecl | Arg | Col | JBo | Sca | Str |
| Ecl | 1.0 | 0.81 | 0.78 | 0.92 | 0.88 | 0.87 |
| Arg | 0.81 | 1.0 | 0.86 | 0.84 | 0.84 | 0.96 |
| Col | 0.78 | 0.86 | 1.0 | 0.90 | 0.85 | 0.92 |
| JBo | 0.92 | 0.84 | 0.90 | 1.0 | 0.94 | 0.91 |
| Sca | 0.88 | 0.84 | 0.85 | 0.94 | 1.0 | 0.91 |
| Str | 0.87 | 0.96 | 0.92 | 0.91 | 0.91 | 1.0 |
由此表明,特征集的各因素在不同软件系统中的表现较为一致,这一发现暗示了进一步研究跨项目的引入缺陷细粒度变更识别的可能性.通过特征分析,可以帮助研究者更好地理解软件开发过程中缺陷引入的根源. 3.3 成本有效性分析
近年来,在比较不同粒度的分类和预测方法时,软件工程领域的研究者常采用成本有效性评估策略[16].该策略将花费的软件工程活动成本考虑在方法的评估中,比精确度和召回率更加客观可信[16].图 5显示了投入20%人力成本时,本文的细粒度方法(SCC-IM)、文献[2]中的文件粒度识别方法(File-IM)以及文献[1]中的事务粒度识别方法(Trans-IM)能够发现的引入缺陷细粒度源代码变更百分比.由于实验含随机化成分,因此将每个方法在6个项目上各运行100次.经曼惠特尼U检验得出,本文方法可识别平均79%的引入缺陷细粒度变更,显著优于文件和事务粒度识别方法(p<0.01).
 |
| 图 5 成本有效性箱线图 Fig. 5 Cost-effectiveness box-plots of the three identification methods |
本文基于机器学习分类思想,提出了一种引入缺陷的细粒度软件变更识别方法,该方法主要由特征集和分类器两部分构成. 本文从时间、地点、内容、意图以及人员5个方面入手构建特征集.通过特征分析实验发现,变更地点中的语义主题多样性和Halstead复杂度两个因素具有最好的识别性能,刻画变更内容的主题缺陷倾向性和刻画变更人员的项目经验因素次之.此外特征集的各因素在不同软件系统中的表现较为一致. 本文选择了缺陷预测领域常用的3种分类器(即K近邻、装袋以及随机森林)来进行训练和识别.通过分类器性能分析发现,随机森林分类器由于对数据噪声具有更强的鲁棒性,其性能显著优于另外两种分类器. 为了验证本文提出的细粒度识别方法在节省人力成本方面的有效性,本文开展了成本有效性分析实验.通过实验得出,本文方法在投入20%人力成本时,能够识别平均79%的引入缺陷细粒度变更,显著优于文件和事务粒度识别方法. 由于现有的库挖掘手段制约,在数据收集过程中引入了噪声,研究噪声对识别效果的影响并开发降噪方法是未来工作的重点.
| [1] | Aversano L,Cerulo L,Grosso C D.Learning from bug-introducing changes to prevent fault prone code[C]//Penta M D.9th International Workshop on Principles of Software Evolution.New York:ACM,2007:19-26 |
| Click to display the text | |
| [2] | Kim S,Whitehead E J,Zhang Y.Classifying software changes:clean or buggy?[J].IEEE Transactions on Software Engineering,2008,34(2):181-196 |
| Click to display the text | |
| [3] | Fluri B,Würsch M,Pinzger M,et al.Change distilling:tree differencing for fine-grained source code change extraction[J].IEEE Transactions on Software Engineering,2007,33(11):725-743 |
| Click to display the text | |
| [4] | Eyolfson J,Tan L,Lam P.Do time of day and developer experience affect commit bugginess?[C]//Deursen A.Proceedings of the 8th Working Conference on Mining Software Repositories.Piscataway,NJ:IEEE,2011:153-162 |
| Click to display the text | |
| [5] | Sliwerski J,Zimmermann T,Zeller A.When do changes induce fixes?[J].ACM Sigsoft Software Engineering Notes,2005,30(4):1-5 |
| Click to display the text | |
| [6] | Halstead M H.Elements of software science[M].Amsterdam:Elsevier North-Holland Press,1977:26-28 |
| [7] | McCabe T J.A complexity measure[J].IEEE Transactions on Software Engineering,1976,2(4):308-320 |
| Click to display the text | |
| [8] | Zimmermann T,Nagappan N.Predicting defects with program dependencies[C]//Mens T.2009 3rd International Symposium on Empirical Software Engineering and Measurement.Piscataway,NJ:IEEE,2009:435-438 |
| Click to display the text | |
| [9] | Thomas S W,Adams B,Hassan A E,et al.Modeling the evolution of topics in source code histories[C]//Deursen A.Proceedings of the 8th working conference on Mining Software Repositories.Piscataway,NJ:IEEE,2011:173-182 |
| Click to display the text | |
| [10] | Yan R,Huang C,Tang J,et al.To better stand on the shoulder of giants[C]//Boughida K.Proceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries.New York:ACM,2012:51-60 |
| Click to display the text | |
| [11] | Graves T L,Karr A F,Marron J S,et al.Predicting fault incidence using software change history[J].IEEE Transactions on Software Engineering,2000,26(7):653-661 |
| Click to display the text | |
| [12] | Pan K,Kim S,Whitehead E J.Toward an understanding of bug fix patterns[J].Empirical Software Engineering,2009,14(3):286-315 |
| Click to display the text | |
| [13] | Chen T H,Thomas S W,Nagappan M,et al.Explaining software defects using topic models[C]//Lanza M.Proceedings of the 9th IEEE Working Conference on Mining Software Repositories.Piscataway,NJ:IEEE,2012:189-198 |
| Click to display the text | |
| [14] | Mockus A,Votta L G.Identifying reasons for software change using historic databases[C]//Fadini B.2000 IEEE Interantional Conference on Software Maintenance.Piscataway,NJ:IEEE,2000:120-130 |
| Click to display the text | |
| [15] | Hassan A E.Automated classification of change messages in open source projects[C]//Wainwright R L.23rd Annual ACM Symposium on Applied Computing.New York:ACM,2008:837-841 |
| Click to display the text | |
| [16] | Hata H,Mizuno O,Kikuno T.Bug prediction based on fine-grained module histories[C]//Glinz M.Proceedings of the 34th International Conference on Software Engineering.Piscataway,NJ:IEEE,2008:837-841 |
| Click to display the text | |
| [17] | Khoshgoftaar T M,Golawala M,Hulse J V.An empirical study of learning from imbalanced data using random forest[C]//Avouris N.Proceedings of the 19th International Conference on Tools with Artificial Intelligence.Piscataway,NJ:IEEE,2007:310-317 |
| Click to display the text |