



Optimization of office process task allocation based on deep reinforcement learning
-
摘要:
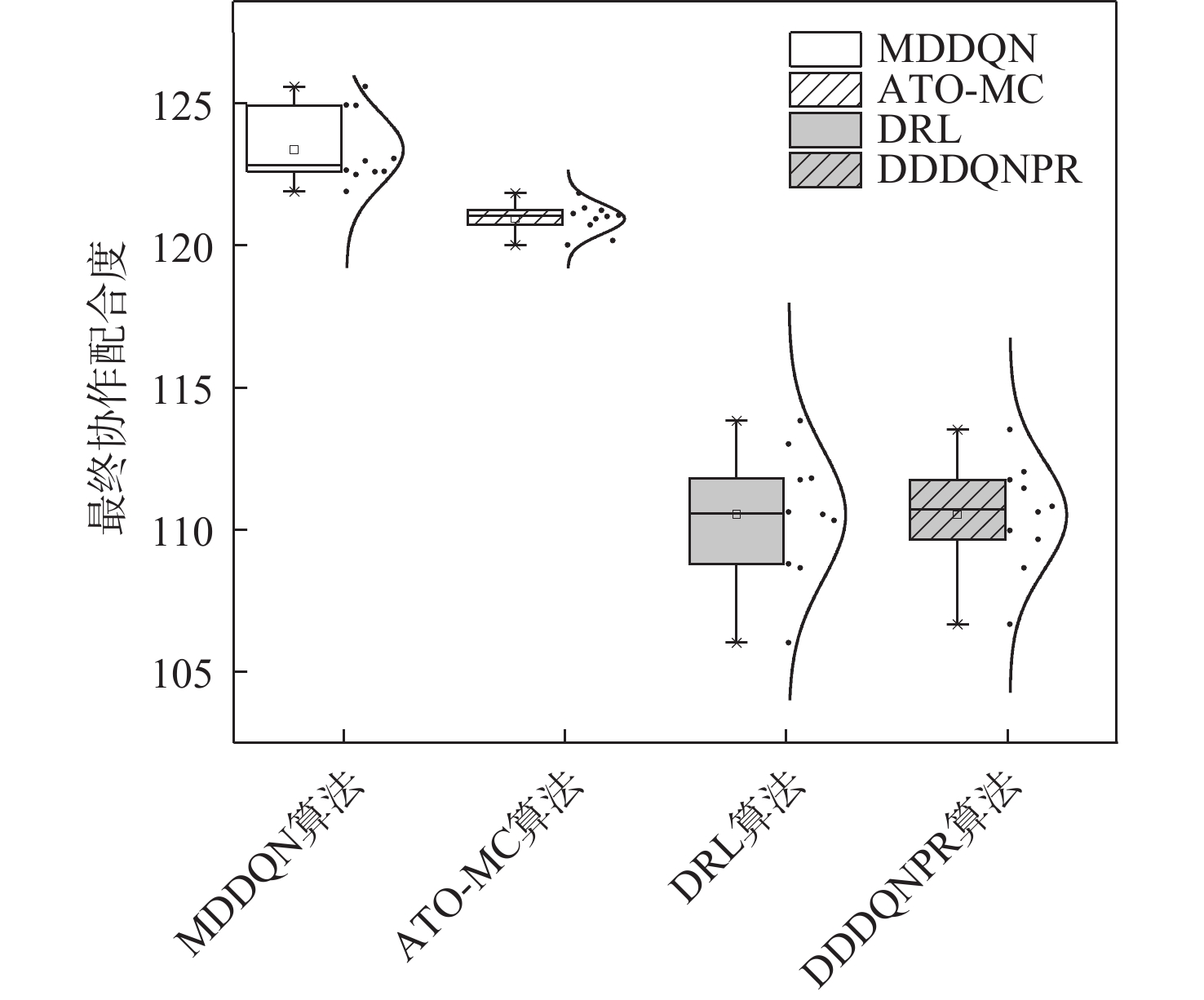
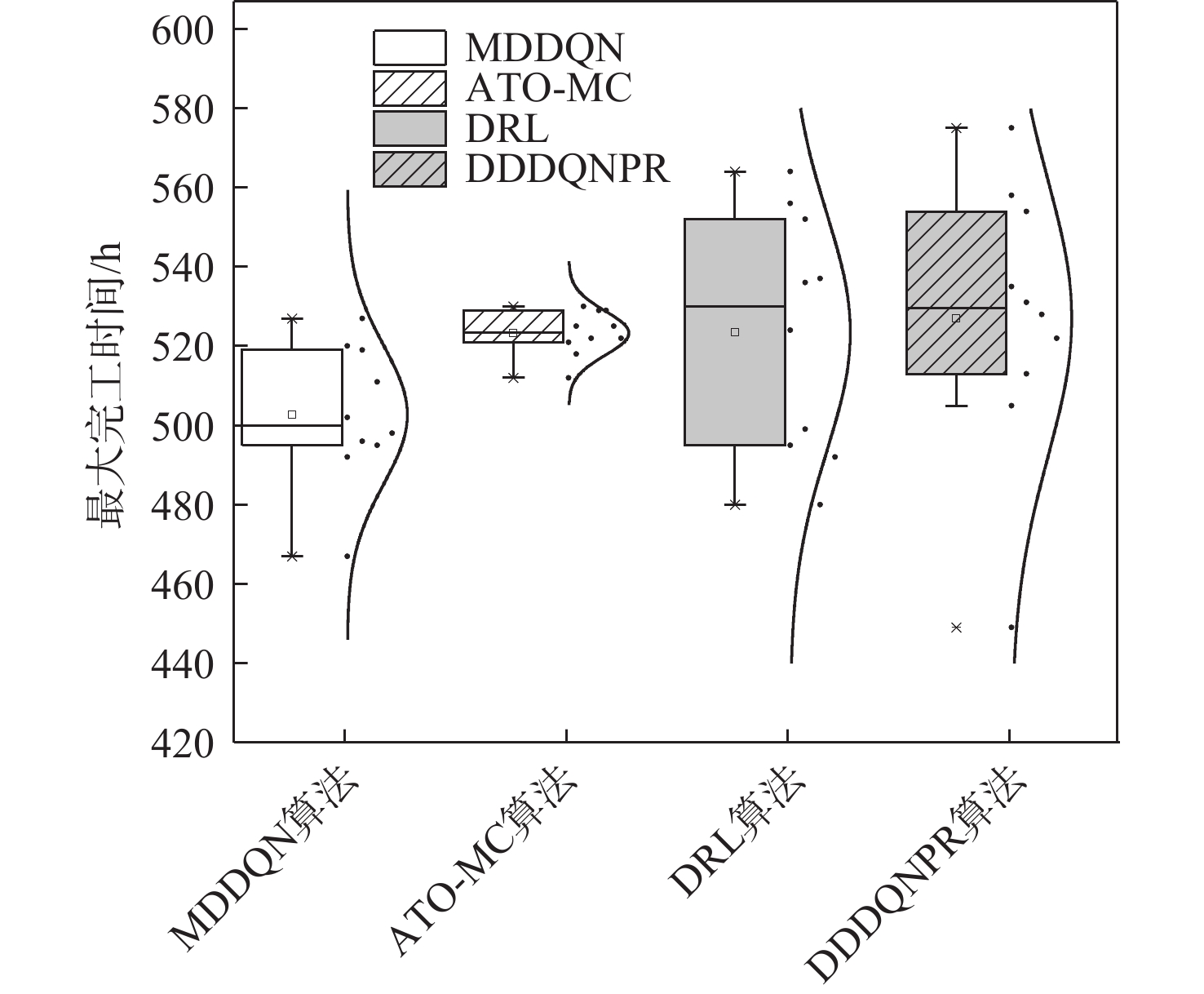
在办公平台中存在异构流程任务大量并行的情况,不仅需要任务执行者具有较强的能力,也对协同调度系统的性能提出了要求。采用强化学习(RL)算法,结合协作配合度、松弛度等定量分析,并基于马尔可夫博弈理论提出多智能体博弈模型,实现以总体流程配合度和最大完工时间为优化目标的优化调度系统,提高了总体执行效率。以真实的业务系统流程作为实验场景,在相同的优化目标下,对比D3QN等3种深度强化学习(DRL)算法和基于蚁群的元启发式算法,验证了所提方法的有效性。
Abstract:In the office platform, we often need to face a large number of parallel heterogeneous process tasks. This not only tests the ability of task executors but also puts forward requirements for the performance of the scheduling system. The multi-agent game model based on Markov game theory is proposed in this paper, which adopts the reinforcement learning (RL) approach along with quantitative analysis of the degree of cooperation and relaxation. This model realizes the optimal scheduling system with the overall process degree and maximum completion time as the optimization objectives and enhances the overall execution efficiency. Finally, to confirm the efficacy of this approach, the meta-heuristic algorithm based on ant colony and the reinforcement learning algorithm based on D3QN and deep reinforcement learning (DRL) are contrasted using the real business system process as the experimental data and the identical optimization targets.
-
Key words:
- work-flows /
- tasks scheduling /
- Markov games /
- deep reinforcement learning /
- cooperation degree
-
表 1 规则与调度函数对应关系
Table 1. Correspondence between rules and scheduling functions
规则
编号采用的
A(选取${O_{i,j}}$)函数采用的
A′(选取${O_{i,j}}$)函数采用的
B(选取$P_{i,j,k} $)函数1 A1( ) A2( ) B1( ) 2 A1( ) A1( ) B2( ) 3 从$ {J_{{\text{uc}}}}(t) $中随机选取流程$J_i,Q_{i,j}$的j由B1( )计算 从$ {J_{{\text{uc}}}}(t) $中随机选取流程$J_i,Q_{i,j}$的j由B1( )计算 B1( ) 4 A3( ) A2( ) B1( ) 5 A2( ) A2( ) B1( ) 6 $ \begin{gathered}{J_i},{P_k} \leftarrow \arg \max i \in \\J_{{\mathrm{uc}}}(t)(\Delta {S_i})\end{gathered} $ $\begin{gathered}{J_i},{P_k} \leftarrow \arg \max i \in \\J_{{\mathrm{uc}}}(t)(\Delta {S_i})\end{gathered} $ B2( )  下载: 导出CSV
下载: 导出CSV
表 2 流程仿真数据类
Table 2. Process simulation data class
类别编号 Edeadline $ {n_1}/{n_2} $ 5 5.6 6 1 0.5 1 √ √ 2 √ √ 3 √ √ 4 √ √ 5 √ √ 6 √ √
下载: 导出CSV
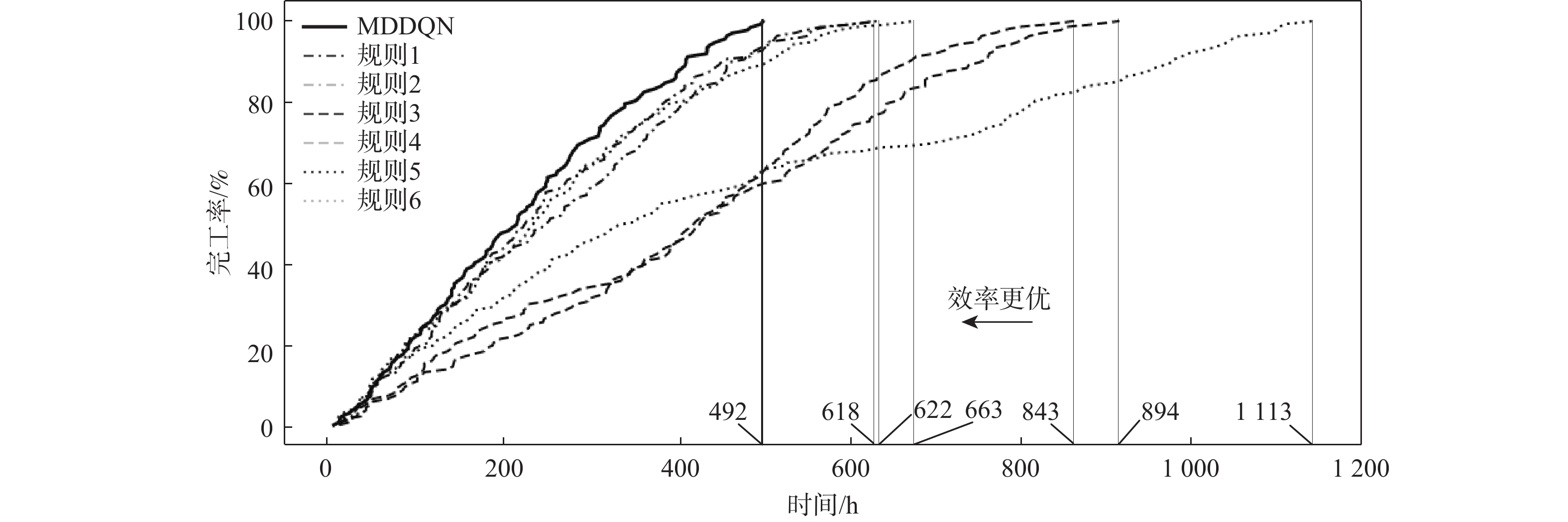
表 3 单一规则最终完工时间
Table 3. Single rule final completion
规则编号 最终完工时间消耗/h 1 622 2 618 3 894 4 843 5 663 6 1113
下载: 导出CSV
-
[1] 关静静, 贺鹏涛, 张冉. 基于作业调度算法的医院OA系统的优化[J]. 中国医疗设备, 2018, 33(2): 155-157. doi: 10.3969/j.issn.1674-1633.2018.02.042GUAN J J, HE P T, ZHANG R. Optimization of hospital OA system based on job scheduling algorithm[J]. China Medical Devices, 2018, 33(2): 155-157(in Chinese). doi: 10.3969/j.issn.1674-1633.2018.02.042 [2] GAO Y Q, ZHANG S Y, ZHOU J T. A hybrid algorithm for multi-objective scientific workflow scheduling in IaaS cloud[J]. IEEE Access, 2019, 7: 125783-125795. doi: 10.1109/ACCESS.2019.2939294 [3] FARAHNAKIAN F, ASHRAF A, PAHIKKALA T, et al. Using ant colony system to consolidate VMs for green cloud computing[J]. IEEE Transactions on Services Computing, 2015, 8(2): 187-198. doi: 10.1109/TSC.2014.2382555 [4] 吕龙, 胡海洋, 李忠金, 等. 基于蚁群算法的工作流系统优化任务分配[J]. 计算机集成制造系统, 2018, 24(7): 1723-1735. doi: 10.13196/j.cims.2018.07.014LYU L, HU H Y, LI Z J, et al. Optimizing task allocation in workflow system based on ant colony optimization[J]. Computer Integrated Manufacturing Systems, 2018, 24(7): 1723-1735(in Chinese). doi: 10.13196/j.cims.2018.07.014 [5] KUMAR A, DIJKMAN R M, SONG M S. Optimal resource assignment in workflows for maximizing cooperation[C]//Proceedings of the 11th International Conference on Business Process. Berlin: Springer, 2013: 235-250. [6] 许荣斌, 鲍广华, 杨培全, 等. 基于最大依赖度及最小冗余度的员工协作优化策略[J]. 计算机集成制造系统, 2017, 23(5): 1014-1019. doi: 10.13196/j.cims.2017.05.012XU R B, BAO G H, YANG P Q, et al. Staff collective optimization strategy based on maximal dependency and minimal redundancy[J]. Computer Integrated Manufacturing Systems, 2017, 23(5): 1014-1019(in Chinese). doi: 10.13196/j.cims.2017.05.012 [7] PIROOZFARD H, WONG K Y, WONG W P. Minimizing total carbon footprint and total late work criterion in flexible job shop scheduling by using an improved multi-objective genetic algorithm[J]. Resources, Conservation and Recycling, 2018, 128: 267-283. doi: 10.1016/j.resconrec.2016.12.001 [8] CUI D L, KE W D, PENG Z P, et al. Multiple DAGs workflow scheduling algorithm based on reinforcement learning in cloud computing[C]//Proceedings of the International Symposium on Computational Intelligence and Intelligent Systems. Berlin: Springer, 2015: 305-311. [9] WU J H, PENG Z P, CUI D L, et al. A multi-object optimization cloud workflow scheduling algorithm based on reinforcement learning[C]//Proceedings of the International Conference on Intelligent Computing. Berlin: Springer, 2018: 550-559. [10] WANG Y F. Adaptive job shop scheduling strategy based on weighted Q-learning algorithm[J]. Journal of Intelligent Manufacturing, 2020, 31(2): 417-432. doi: 10.1007/s10845-018-1454-3 [11] CAO Z, ZHANG H G, CAO Y, et al. A deep reinforcement learning approach to multi-component job scheduling in edge computing[C]//Proceedings of the 15th International Conference on Mobile Ad-Hoc and Sensor Networks. Piscataway: IEEE Press, 2020: 19-24. [12] HAN B A, YANG J J. Research on adaptive job shop scheduling problems based on dueling double DQN[J]. IEEE Access, 2020, 8: 186474-186495. doi: 10.1109/ACCESS.2020.3029868 [13] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. doi: 10.1038/nature14236 [14] VAN HASSELT H, GUEI A, SILLVER D. Deep reinforcement learning with double Q-Learning[C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. New York: ACM, 2016: 2094-2100. [15] VAN HASSELT H. Double Q-learning[C]//Proceedings of the 23rd International Conference on Neural Infor- mation Processing Systems. New York: ACM, 2010: 2613-2621. [16] VAN HASSELT H V, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2016, 30(1): 1509. [17] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-05) [2022-04-01]. https://arxiv.org/abs/1509.02971. [18] SHIUE Y R, LEE K C, SU C T. Real-time scheduling for a smart factory using a reinforcement learning approach[J]. Computers & Industrial Engineering, 2018, 125: 604-614. -

 下载:
下载:
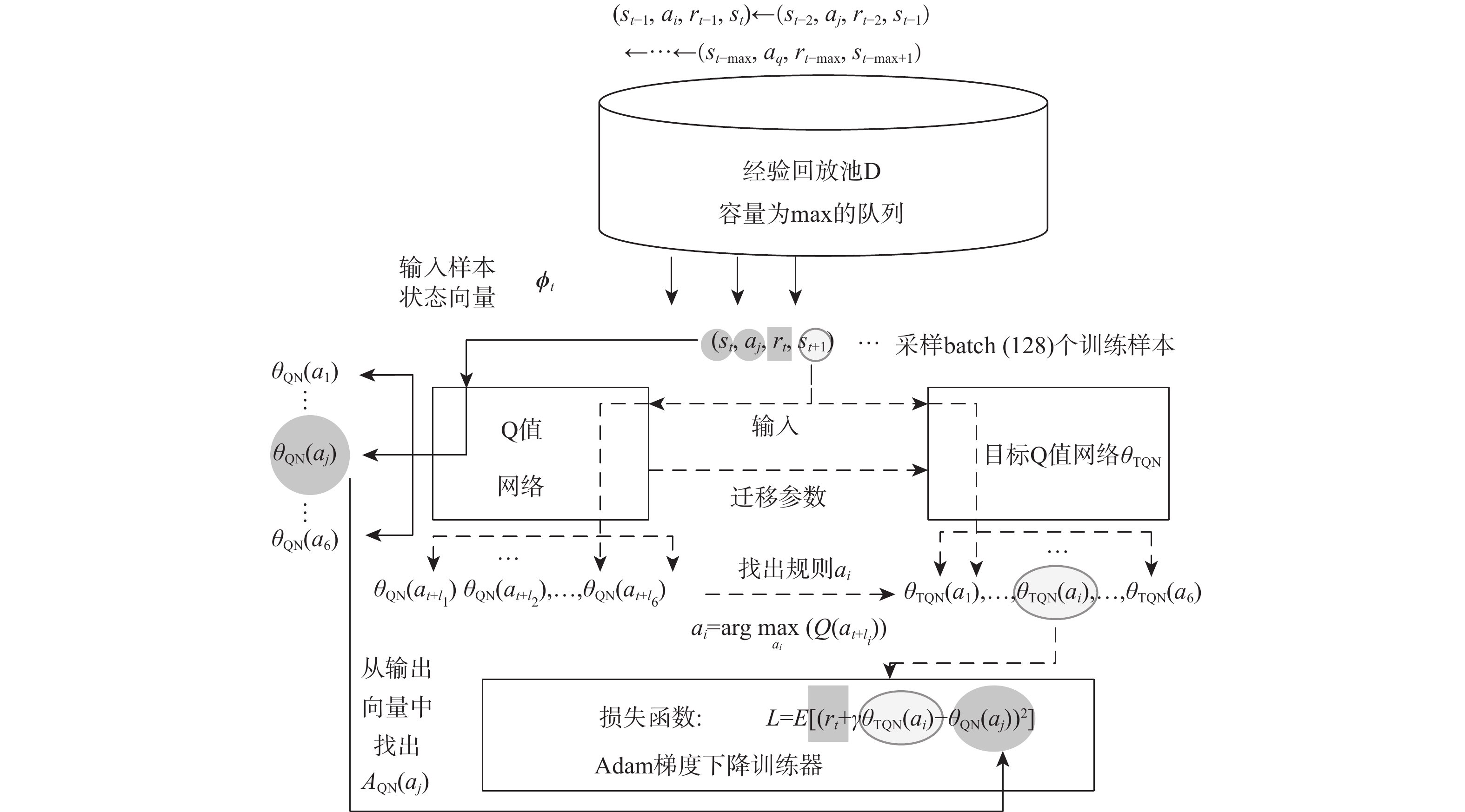
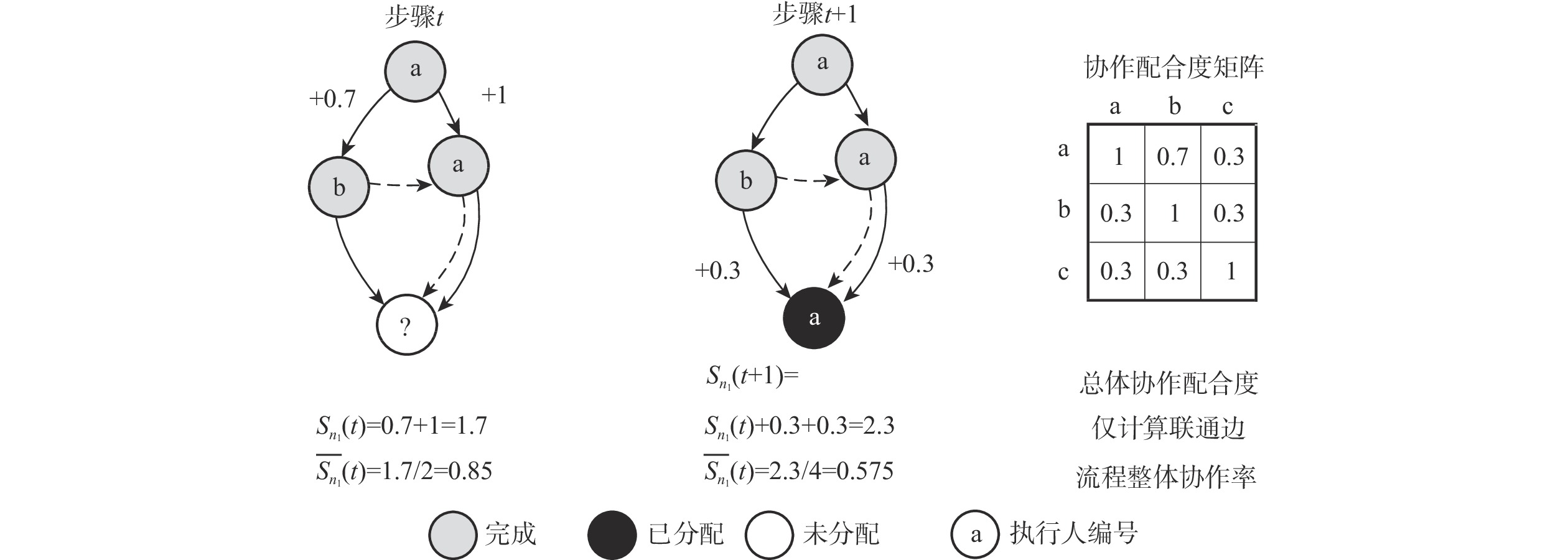
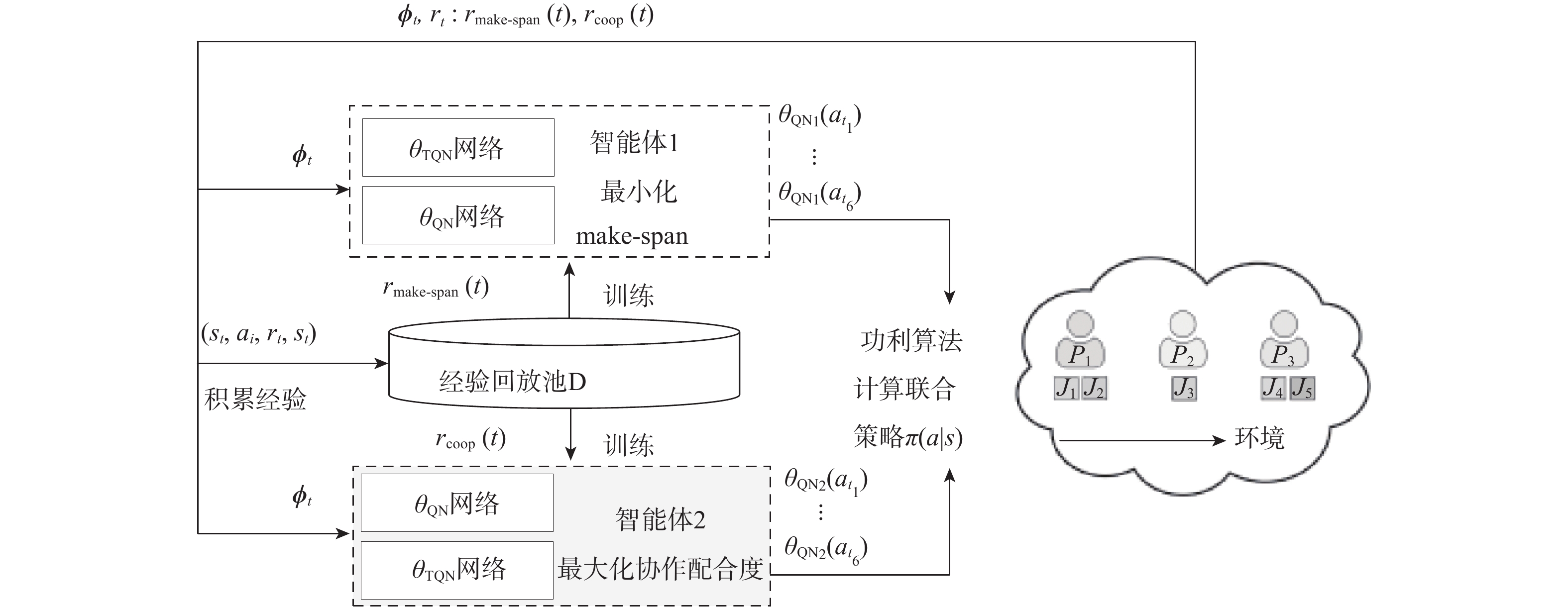
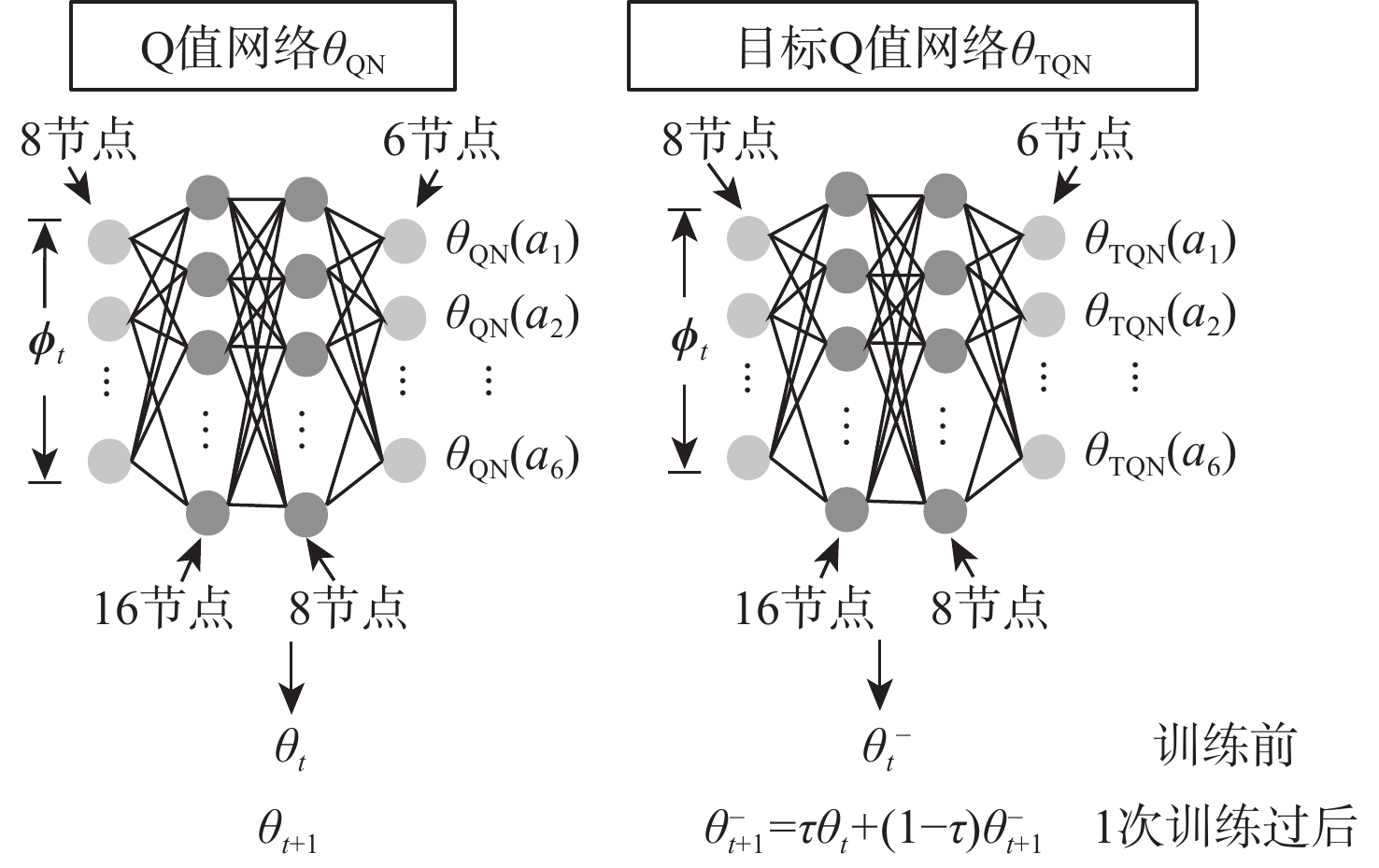

 点击查看大图
点击查看大图

计量
- 文章访问数: 93
- HTML全文浏览量: 14
- PDF下载量: 15
- 被引次数: 0
