



-
摘要:
近年来,基于深度学习的视频压缩技术主要基于卷积神经网络(CNN)且采用运动补偿-残差编码的架构,由于常见的CNN只能利用局部的相关性,以及预测残差本身的稀疏特性,难以取得最优压缩性能。因此,提出一种基于Transformer架构的条件视频压缩算法,以实现更优的压缩效果。所提算法基于前后帧之间的运动信息,利用可形变卷积得到对应的预测帧特征;将预测帧特征作为条件信息,对原始输入帧特征进行条件编码,避免了直接编码稀疏的残差信号;利用特征间的非局部相关性,提出一个基于Transformer的深度条件视频压缩编码算法,用来实现运动信息编码和条件编码,进一步提升压缩编码的性能。实验结果表明:所提算法在HEVC、UVG数据集上均超越了当前主流的基于深度学习的视频压缩算法。
-
关键词:
- 视频压缩 /
- Transformer /
- 深度学习 /
- 神经网络 /
- 压缩算法
Abstract:Convolutional neural networks (CNN) are the foundation of most recent learning-based video compression algorithms, which also use residual coding and motion compensation architectures. It is difficult to attain the best compression performance given that typical CNN can only use local correlations and the sparsity of prediction residual. To solve the problems above, this paper proposed a Transformer-based deep conditional video compression algorithm, which can achieve better compression performance. The proposed algorithm uses deformable convolution to obtain the predicted frame feature based on the motion information between the front and rear frames. The predicted frame feature is used as conditional information to conditionally encode the original input frame feature which avoids the direct encoding of sparse residual signals. The proposed algorithm further utilizes the non-local correlation between the features and proposes a transformer-based autoencoder architecture to implement motion coding and conditional coding, which further improves the performance of compression. Experiments show that our Transformer based deep conditional video compression algorithm surpasses the current mainstream learning-based video compression algorithms in both HEVC and UVG datasets.
-
Key words:
- video compression /
- Transformer /
- deep learning /
- neural network /
- compression algorithm
-

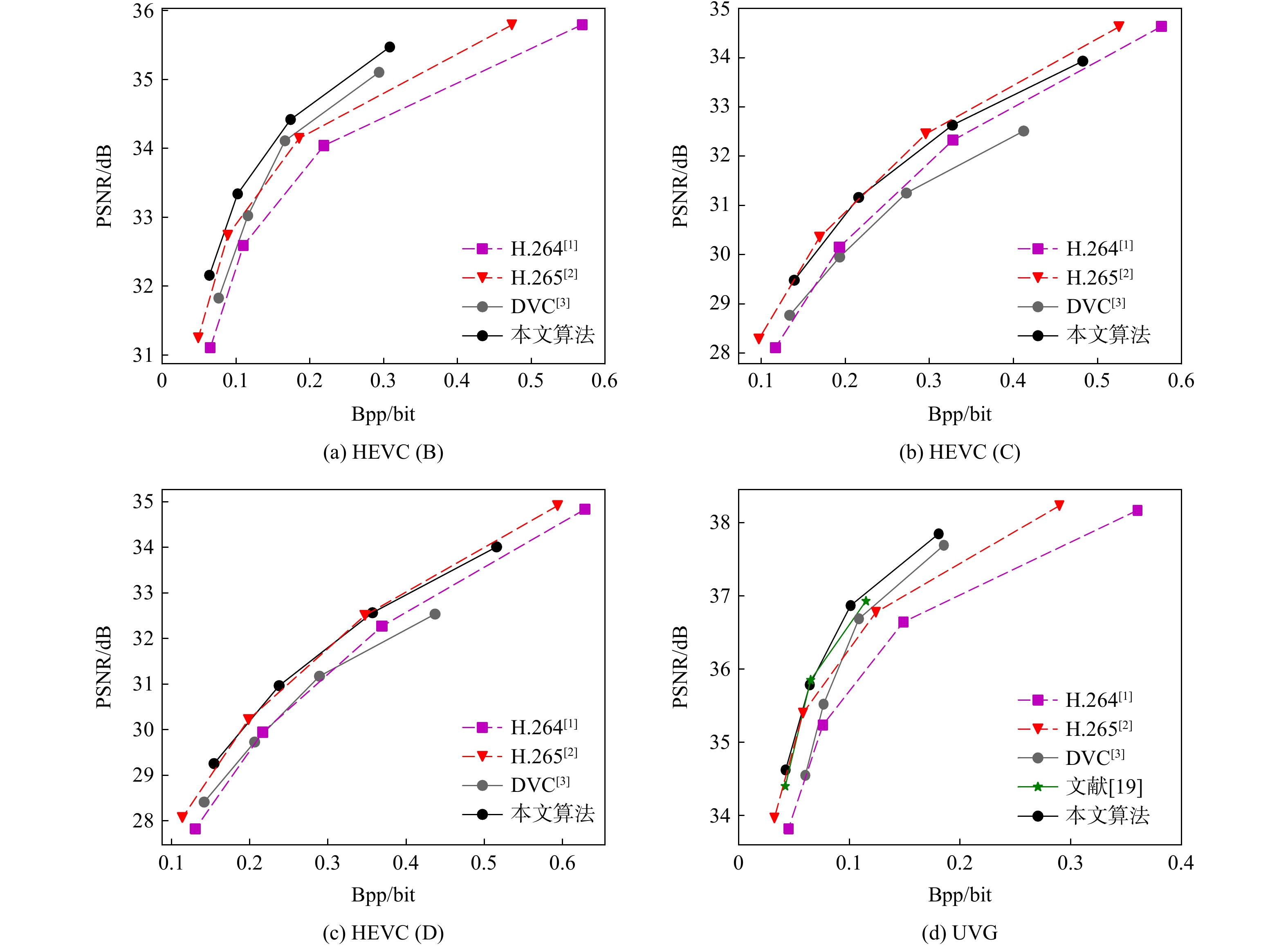
图 3 HEVC、UVG数据集上不同算法的实验结果
Figure 3. Experimental results for different algorithms on HEVC and UVG datasets
表 1 不同训练阶段的损失函数
Table 1. Loss function at different training stages
阶段 步数/$ {10}^{4} $ 损失函数 1 10 $ {\lambda }d\left({{\boldsymbol{x}}}_{t},{\bar{{\boldsymbol{x}}}}_{t}\right) $ 2 10 $ {R}_{\mathrm{m}}+\lambda d\left({{\boldsymbol{x}}}_{t},{\bar{{\boldsymbol{x}}}}_{t}\right) $ 3 20 $ {\lambda }d({{\boldsymbol{x}}}_{t},{\hat{{\boldsymbol{x}}}}_{t}) $ 4 10 $ {R}_{\mathrm{c}}+\lambda d\left({{\boldsymbol{x}}}_{t},{\hat{{\boldsymbol{x}}}}_{t}\right) $ 5 140 $ {R}_{\mathrm{c}}+\lambda d\left({{\boldsymbol{x}}}_{t},{\hat{{\boldsymbol{x}}}}_{t}\right) $ 6 10 $ {R}_{\mathrm{c}}+\lambda d\left({{\boldsymbol{x}}}_{t},{\hat{{\boldsymbol{x}}}}_{t}\right) $  下载: 导出CSV
下载: 导出CSV
-
[1] Joint Video Team of ITU-T and ISO/IEC JTC 1. Advanced video coding:ISO/IEC 14496-10[S].JVT:Pattaya,2003. [2] BROSS B.High efficiency video coding:ISO/IEC 23008-2[S].Shanghai:ITU-T/ISO/IEC Joint Collaborative Team on Video Coding,2012. [3] LU G, OUYANG W L, XU D, et al. DVC: An end-to-end deep video compression framework[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10998-11007. [4] WALLACE G K. The JPEG still picture compression standard[J]. Communications of the ACM, 1991, 34(4): 30-44. doi: 10.1145/103085.103089 [5] BELLARD F. BPG image format[EB/OL]. (2015-02-01)[2022-05-10]. https://bellard.org/bpg. [6] TODERICI G, O’MALLEY S M, HWANG S J, et al. Variable rate image compression with recurrent neural networks[EB/OL]. (2016-05-01)[2022-05-10]. https://arxiv.org/abs/1511.06085.pdf. [7] TODERICI G, VINCENT D, JOHNSTON N, et al. Full resolution image compression with recurrent neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 5435-5443. [8] JOHNSTON N, VINCENT D, MINNEN D, et al. Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4385-4393. [9] BALLÉ J, LAPARRA V, SIMONCELLI E P. End-to-end optimized image compression[EB/OL]. (2017-05-03)[2022-05-10]. https://arxiv.org/abs/1611.01704.pdf. [10] BALLÉ J, MINNEN D, SINGH S, et al. Variational image compression with a scale hyperprior[EB/OL]. (2018-05-01)[2022-05-10]. https://arxiv.org/abs/1802.01436.pdf. [11] MINNEN D, BALLÉ J, TODERICI G. Joint autoregressive and hierarchical priors for learned image compression[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. New York: ACM, 2018: 10794-10803. [12] MINNEN D, SINGH S. Channel-wise autoregressive entropy models for learned image compression[C]//Proceedings of the IEEE International Conference on Image Processing. Piscataway: IEEE Press, 2020: 3339-3343. [13] ZHU Y, YANG Y, COHEN T. Transformer-based transform coding[EB/OL]. (2022-01-29)[2022-05-10]. https://openreview.net/forum?id=IDwN6xjHnK8. [14] KOYUNCU A B, GAO H, BOEV A, et al. Contextformer: A Transformer with spatio-channel attention for context modeling in learned image compression[EB/OL]. (2022-07-20)[2022-05-10]. https://arxiv.org/abs/2203.02452.pdf. [15] QIAN Y C, LIN M, SUN X Y, et al. Entroformer: A Transformer-based entropy model for learned image compression[EB/OL]. (2022-05-14)[2022-05-10]. https://arxiv.org/abs/2202.05492.pdf. [16] LU M, GUO P Y, SHI H Q, et al. Transformer-based image compression[EB/OL]. (2021-11-12)[2022-05-10]. https://arxiv.org/abs/2111.06707.pdf. [17] BAI Y C, YANG X, LIU X M, et al. Towards end-to-end image compression and analysis with Transformers[EB/OL]. (2021-12-17)[2022-05-10]. https://arxiv.org/abs/2112.09300.pdf. [18] HU Z H, CHEN Z H, XU D, et al. Improving deep video compression by resolution-adaptive flow coding[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2020: 193-209. [19] AGUSTSSON E, MINNEN D, JOHNSTON N, et al. Scale-space flow for end-to-end optimized video compression[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 8500-8509. [20] HU Z H, LU G, XU D. FVC: A new framework towards deep video compression in feature space[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 1502-1511. [21] LI J, LI B, LU Y. Deep contextual video compression[EB/OL]. (2021-12-14)[2022-05-01]https://arxiv.org/abs/2109.15047. [22] WU C Y, SINGHAL N, KRÄHENBÜHL P. Video compression through image interpolation[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 425-440. [23] DJELOUAH A, CAMPOS J, SCHAUB-MEYER S, et al. Neural inter-frame compression for video coding[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 6420-6428. [24] YANG R, MENTZER F, VAN GOOL L, et al. Learning for video compression with hierarchical quality and recurrent enhancement[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 6627-6636. [25] PESSOA J, AIDOS H, TOMÁS P, et al. End-to-end learning of video compression using spatio-temporal autoencoders[C]//Proceedings of the IEEE Workshop on Signal Processing Systems. Piscataway: IEEE Press, 2020: 1-6. [26] HABIBIAN A, VAN ROZENDAAL T, TOMCZAK J, et al. Video compression with rate-distortion autoencoders[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 7032-7041. [27] LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: Hierarchical vision Transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2022: 9992-10002. [28] XUE T F, CHEN B A, WU J J, et al. Video enhancement with task-oriented flow[J]. International Journal of Computer Vision, 2019, 127(8): 1106-1125. doi: 10.1007/s11263-018-01144-2 [29] MERCAT A, VIITANEN M, VANNE J. UVG dataset: 50/120fps 4K sequences for video codec analysis and development[C]//Proceedings of the 11th ACM Multimedia Systems Conference. New York: ACM, 2020: 297-302. -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 891
- HTML全文浏览量: 143
- PDF下载量: 24
- 被引次数: 0
