



Language-guided target segmentation method based on multi-granularity feature fusion
-
摘要:
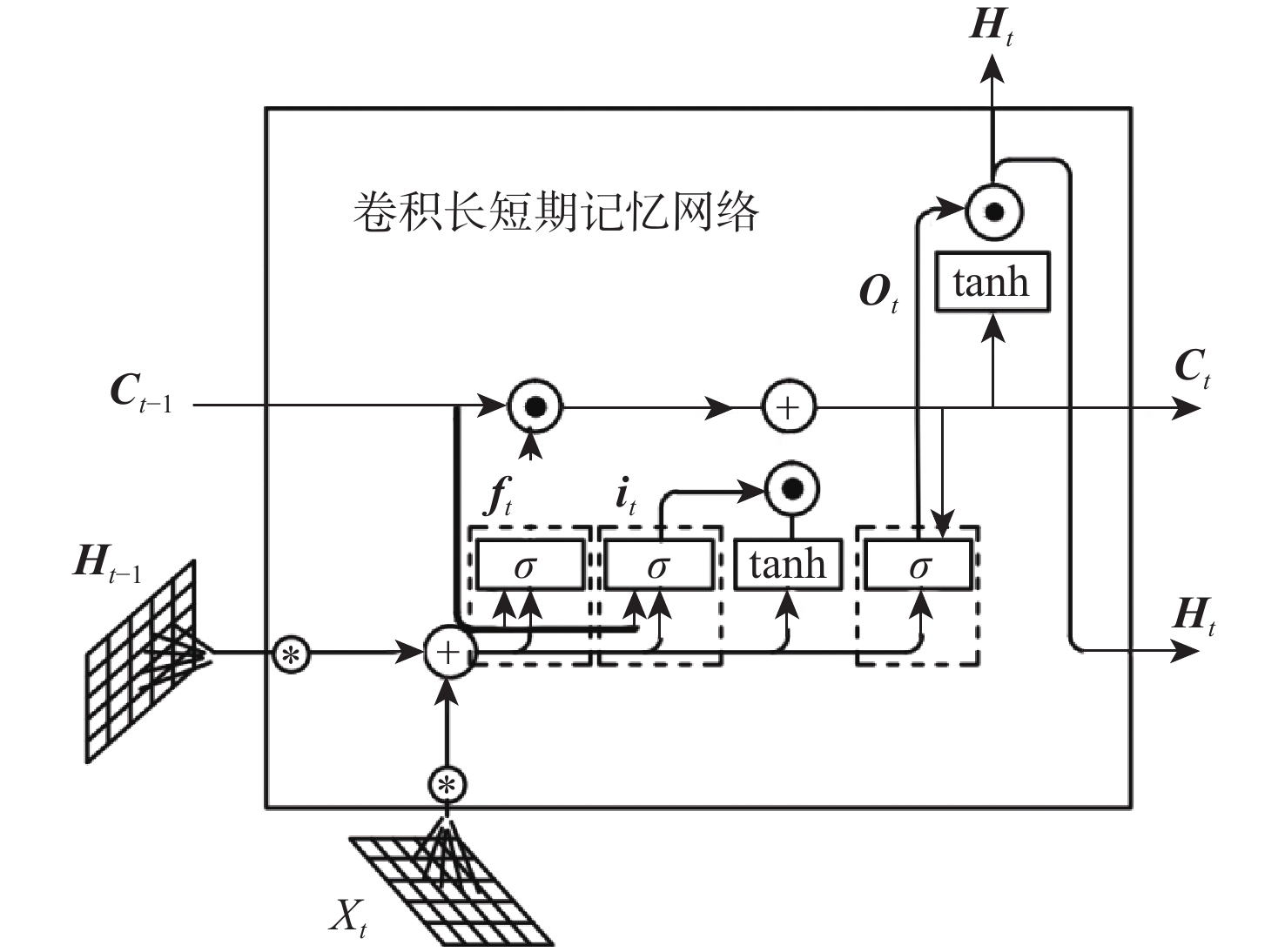
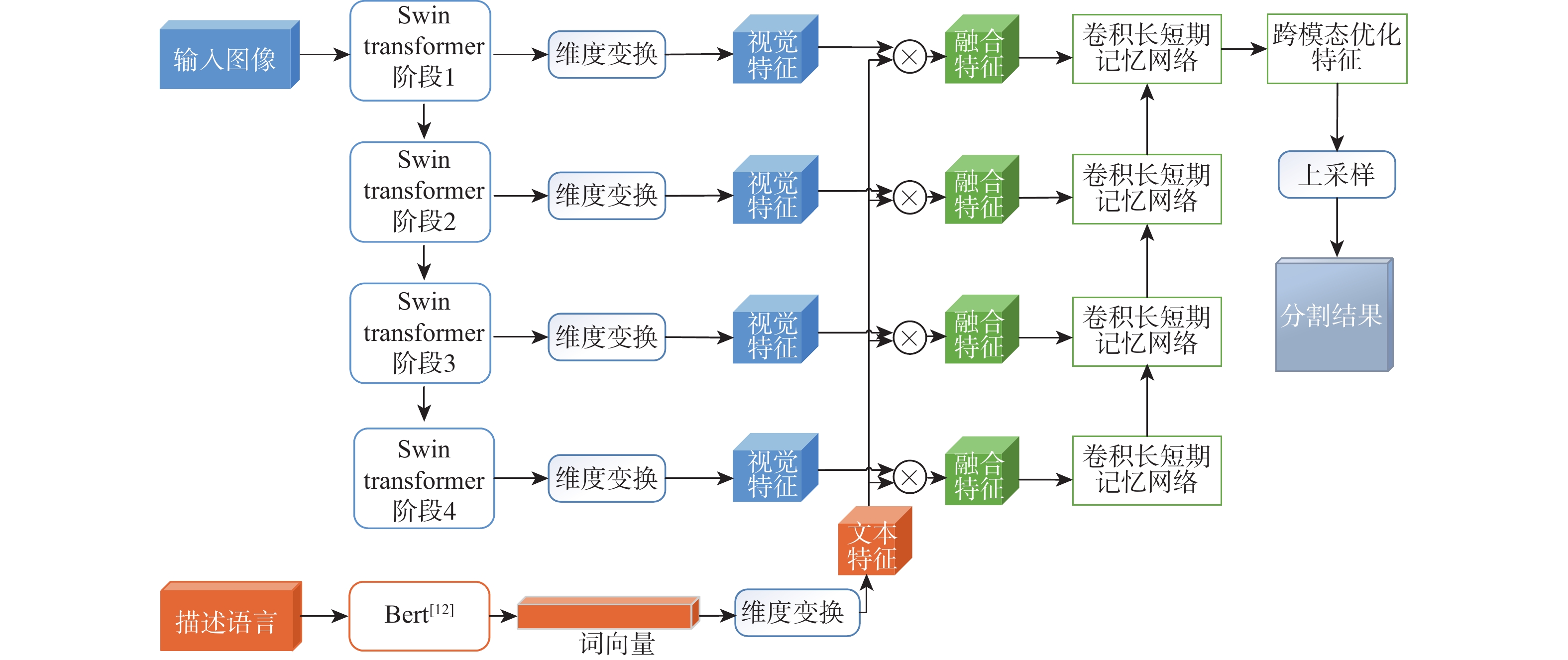
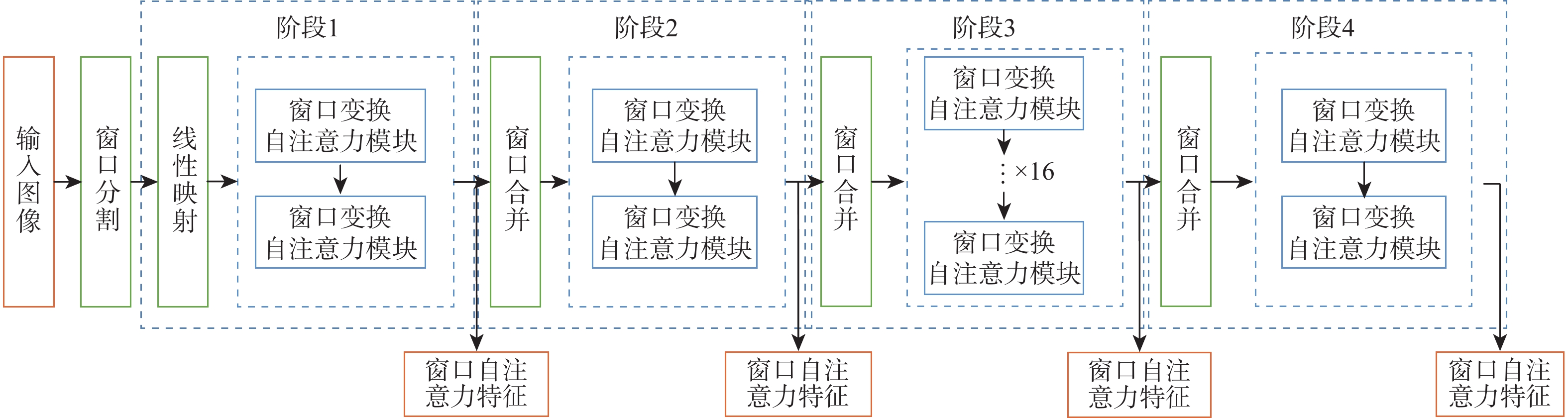
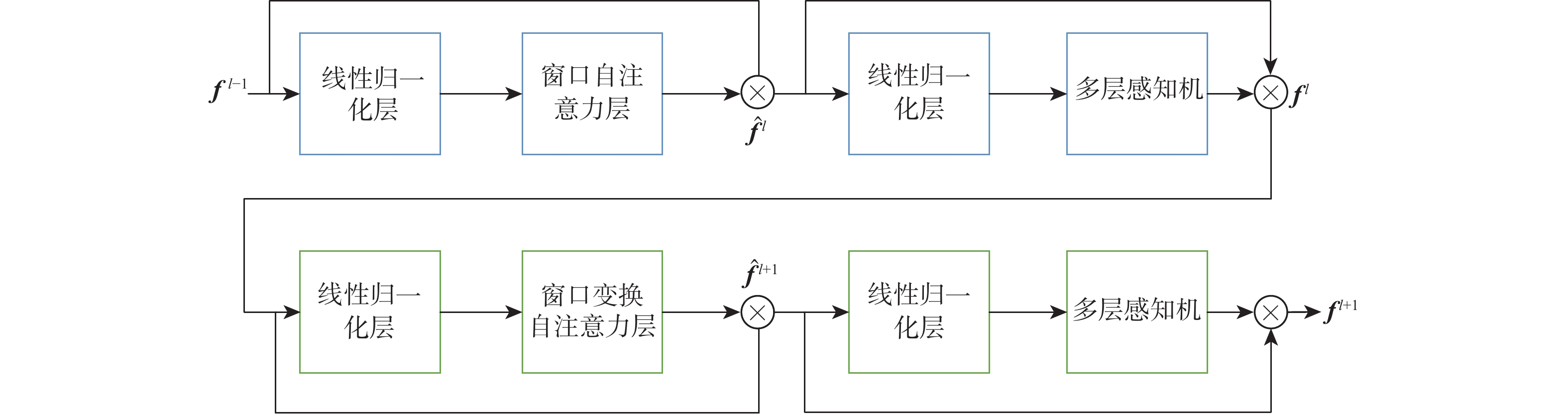
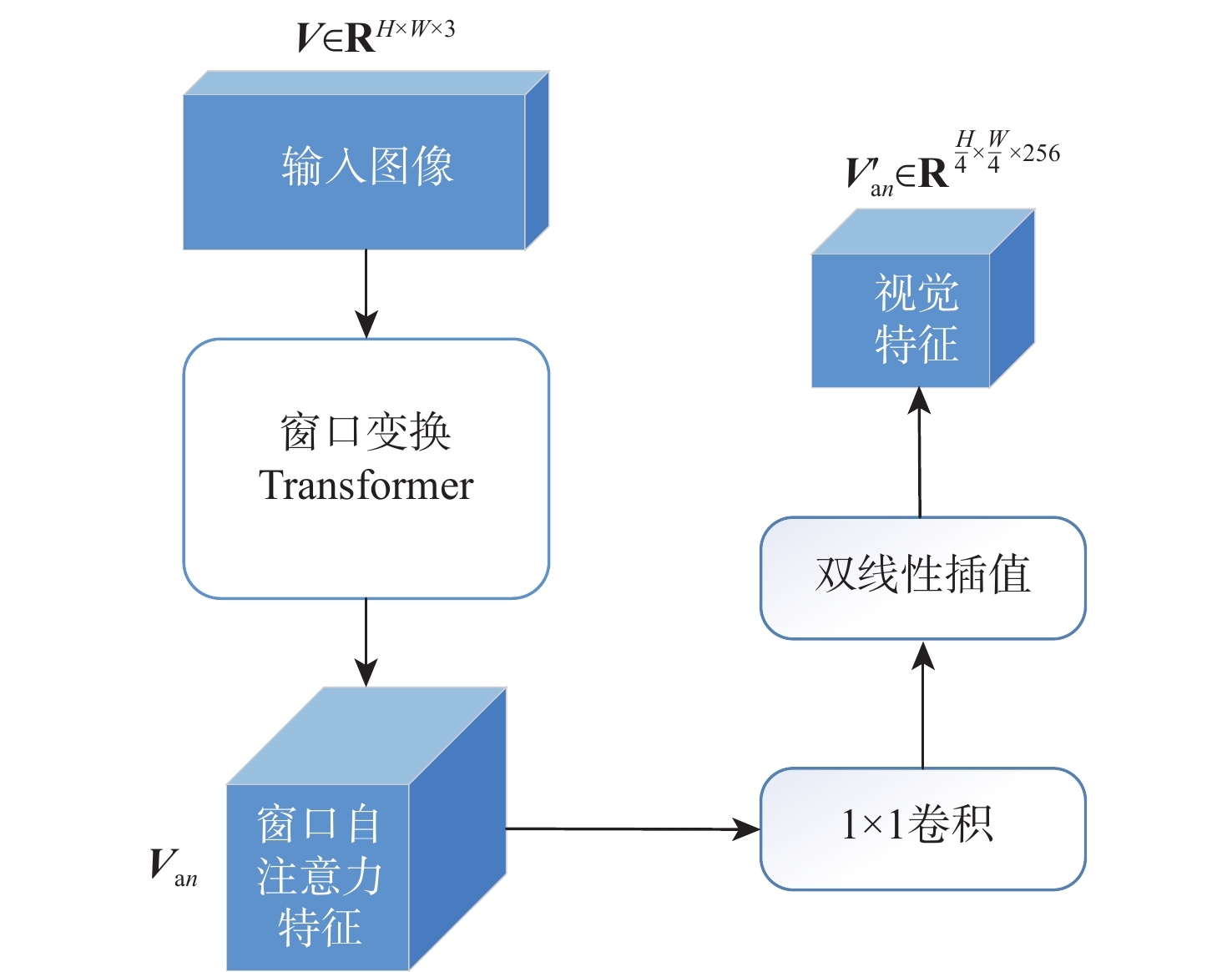
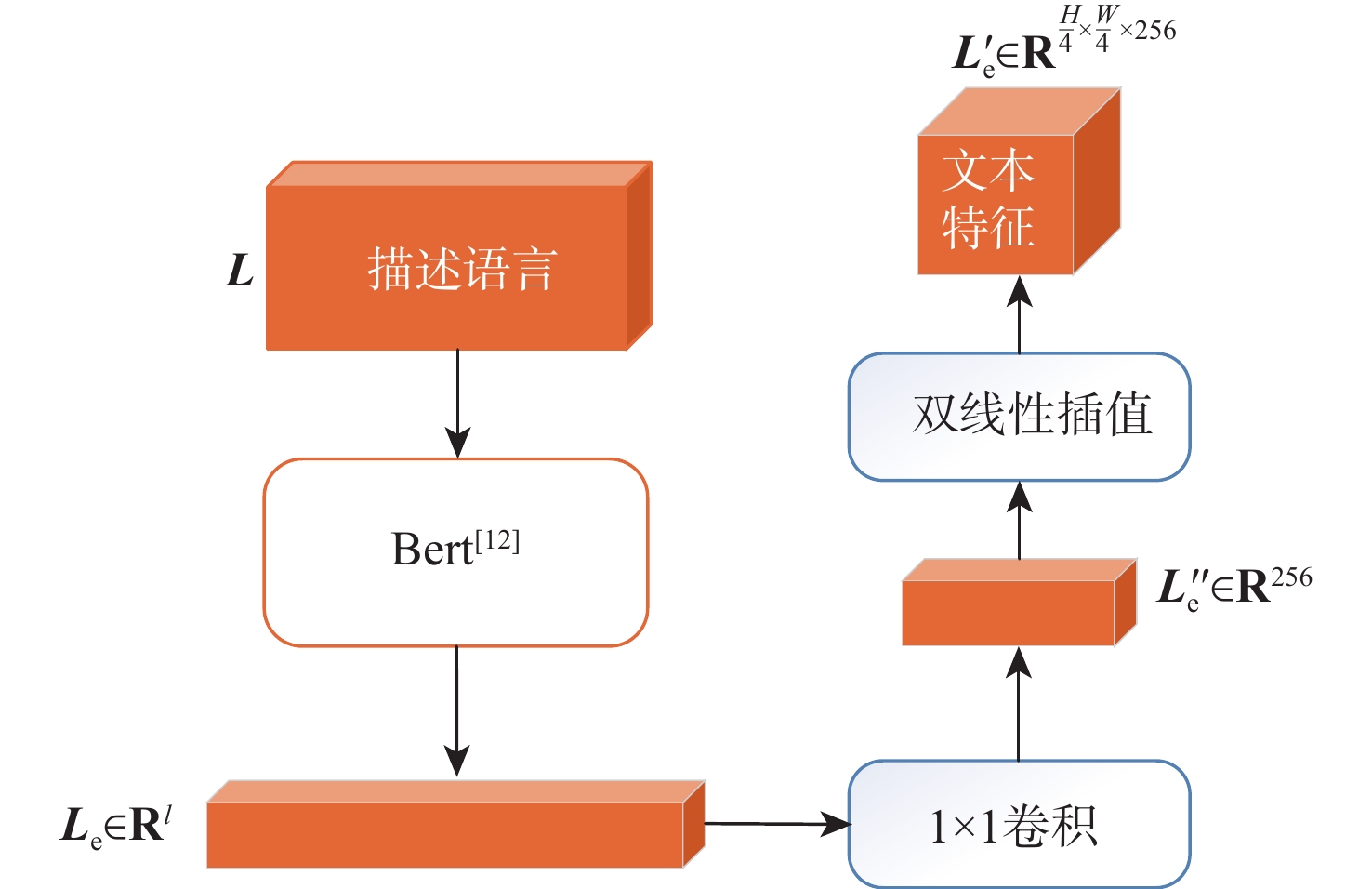
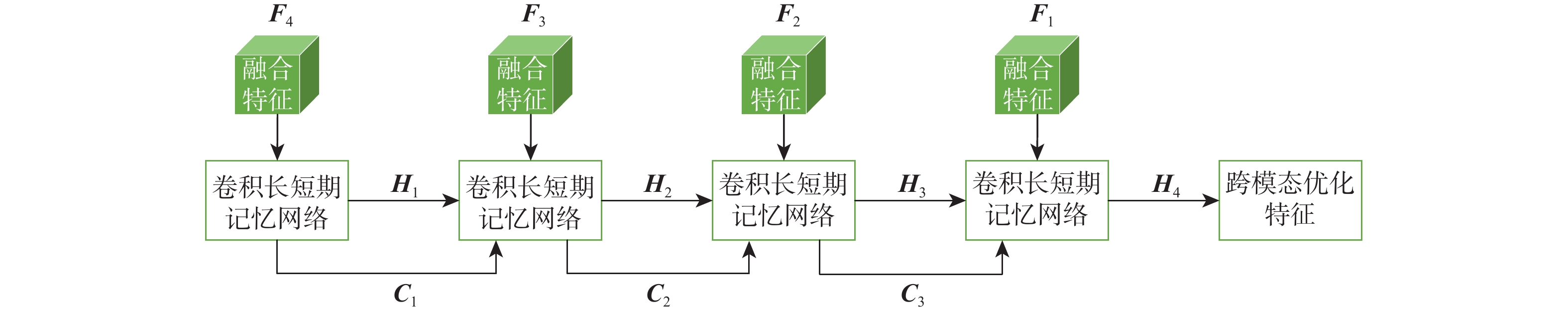
语言引导的目标分割旨在将文本描述的目标与其所指代的实体进行匹配,从而实现对文本、实体之间关系的理解与指代目标的定位。该任务在信息抽取、文本分类、机器翻译等应用场景中具有重要的应用价值。基于Refvos模型提出一种语言引导的多粒度特征融合目标分割方法,能够对特定目标精准定位。利用Swin Transformer和Bert网络,分别提取多粒度的视觉特征和文本特征,提高对整体与细节的表征能力;将文本特征分别与不同粒度视觉特征进行融合,通过语言引导增强特定目标表达;通过卷积长短期记忆网络对多粒度融合特征进行优化,在不同粒度特征间进行信息交流,得到更精细化的分割结果。在UNC、UNC+、G-Ref、ReferIt数据集上进行训练并测试所提方法。实验结果表明:相比Refvos,所提方法在UNC数据集的val、testB子集中IoU结果分别提升0.92%、4.1%,在UNC+数据集的val、testA、testB子集中IoU结果分别提升1.83%、0.63%、1.75%。所提方法在G-Ref、ReferIt数据集的IoU结果分别为40.16%和64.37%,达到前沿水平,证明所提方法的有效性与先进性。
Abstract:The objective of language-guided target segmentation is to match the targets described in the text with the entities they refer to, thereby achieving an understanding of the relationships between text and entities, as well as the localization of the referred targets. This task has significant application value in scenarios such as information extraction, text classification, and machine translation. The paper proposes a language-guided multi-granularity feature fusion target segmentation method based on the Refvos model, which can accurately locate segment-specific targets. Using the Swin Transformer and Bert network to extract multi-granularity visual features and text features respectively, so as to obtain features that have strong expression ability to the whole and part. Through language direction, text features are combined with visual features of varying granularities to improve targeted expression. Ultimately, in order to achieve more precise segmentation results, we enhance multi-granularity fusion features using convolutional long and short-term memory networks to facilitate information flow across features of different granularities. The model was trained and tested on UNC and UNC+ datasets. Experimental results show that the proposed method compared with Refvos, IoU results in UNC dataset Val and testB are improved by 0.92% and 4.1% respectively, and IoU results in UNC+ dataset Val, testA and testB are improved by 1.83%, 0.63%, and 1.75% respectively. The proposed method IoU results of G-Ref and ReferIt data sets are 40.16% and 64.37%, reaching the frontier level. It is proved that the proposed method is effective and advanced.
-
Key words:
- target segmentation /
- referring segmentation /
- feature fusion /
- cross-model /
- text understanding
-

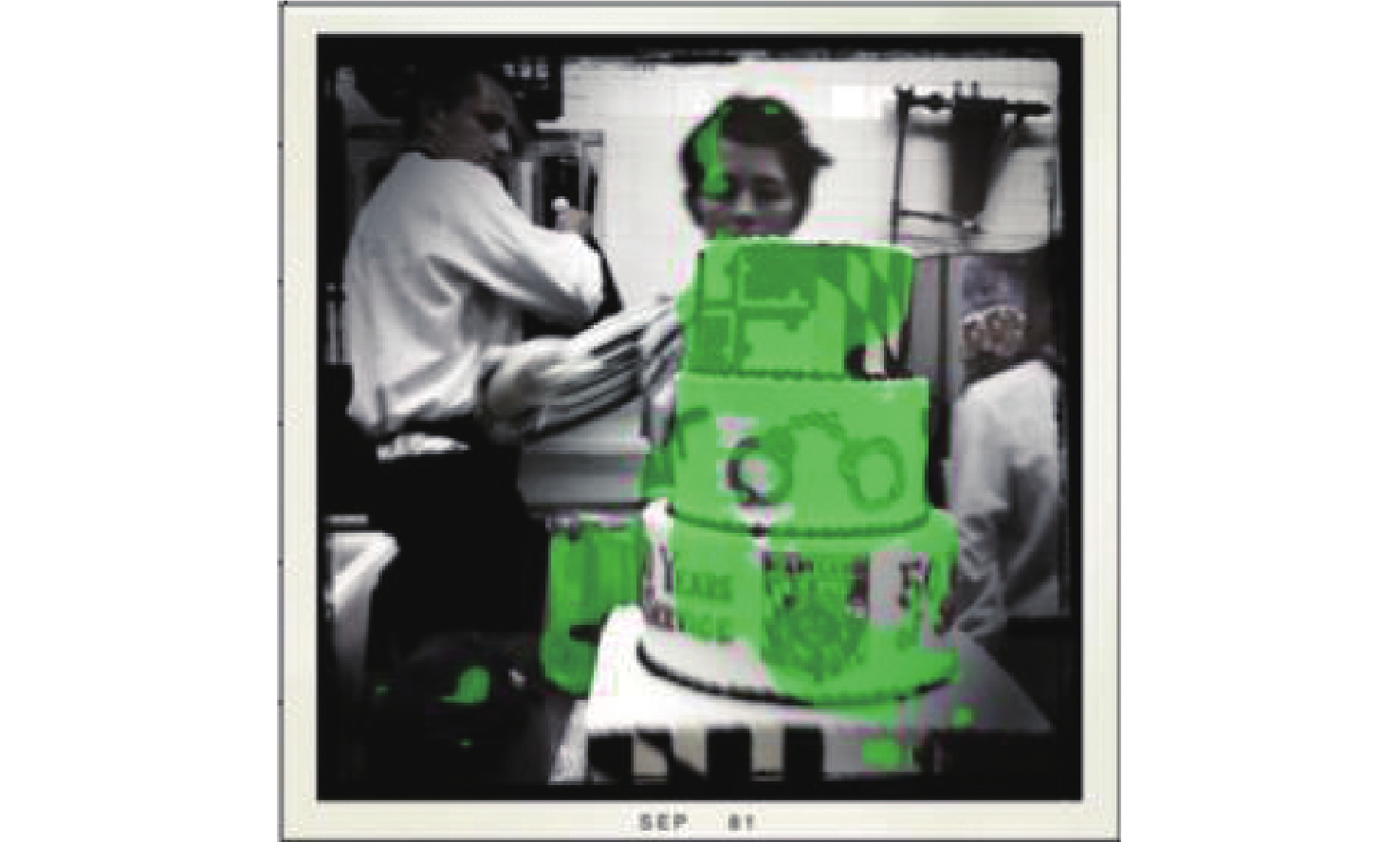
图 10 “站在中间戴着围巾的女人”分割结果
Figure 10. "The woman in the center with the scarf" split results
表 1 总体IoU实验结果对比
Table 1. Overall IoU comparison of experimental results
% 语言引导分割方法 UNC[18] UNC+[18] G-Ref[19] ReferIt[20] val testA testB val testA testB val test RMI[2] 45.18 45.69 45.57 29.86 30.48 29.50 34.52 58.73 DMN[3] 49.78 54.83 45.13 38.88 44.22 32.29 36.76 52.81 RRN[5] 55.33 57.26 53.95 39.75 42.15 36.11 36.45 63.63 MattNet[24] 56.51 62.37 51.70 46.67 52.39 40.08 CMSA[6] 58.32 60.61 55.09 43.76 47.60 37.89 39.98 63.80 Refvos[10] 59.45 63.19 54.17 44.71 49.73 36.17 STEP[7] 60.04 63.46 58.97 48.18 52.33 40.41 46.40 64.13 BRINET[25] 61.35 63.37 59.57 48.57 52.87 42.13 47.57 CMPC[8] 61.36 64.53 59.64 49.56 53.44 43.23 49.05 65.53 本文方法 60.37 62.31 58.27 46.54 50.36 37.92 40.16 64.37  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果总体IoU对比
Table 2. Overall IoU comparison of ablation experiment results
% 方法 val testA testB 单一粒度 55.31 55.70 53.85 无特征优化 57.99 59.62 56.62 本文方法 60.37 62.31 58.27
下载: 导出CSV
-
[1] HU R H, ROHRBACH M, DARRELL T. Segmentation from natural language expressions[C]//Proceeding of the European Conference on Computer Vision. Berlin: Springer, 2016: 108-124. [2] LIU C X, LIN Z, SHEN X H, et al. Recurrent multimodal interaction for referring image segmentation[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 1280-1289. [3] MARGFFOY-TUAY E, PÉREZ J C, BOTERO E, et al. Dynamic multimodal instance segmentation guided by natural language queries[C]//Proceedings of the European Conference on Computer Vision. New York: ACM, 2018: 656–672. [4] LEI T, ZHANG Y. Training RNNs as fast as CNNs[EB/OL]. (2017-09-12)[2022-01-05]. https://arxiv.org/abs/1709.02755v2. [5] LI R Y, LI K C, KUO Y C, et al. Referring image segmentation via recurrent refinement networks[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 5745-5753. [6] YE L W, ROCHAN M, LIU Z, et al. Cross-modal self-attention network for referring image segmentation[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 10494-10503. [7] CHEN D J, JIA S H, LO Y C, et al. See-through-text grouping for referring image segmentation[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 7453-7462. [8] HUANG S F, HUI T R, LIU S, et al. Referring image segmentation via cross-modal progressive comprehension[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10485-10494. [9] HUI T R, LIU S, HUANG S F, et al. Linguistic structure guided context modeling for referring image segmentation[C]//Proceeding of the European Conference on Computer Vision. Berlin: Springer, 2020: 59-75. [10] BELLVER M, VENTURA C, SILBERER C, et al. A closer look at referring expressions for video object segmentation[J]. Multimedia Tools and Applications, 2023, 82(3): 4419-4438. doi: 10.1007/s11042-022-13413-x [11] CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05)[2022-01-12]. https://doi.org/10.48550/arXiv.1706.05587. [12] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[EB/OL] . (2018-11-11)[2022-01-12].https://arxiv.org/abs/1810.04805. [13] LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 9992-10002. [14] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [15] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03)[2021-12-11]. https://doi.org/10.48550/arXiv.2010.11929. [16] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. doi: 10.1162/neco.1997.9.8.1735 [17] SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM Network: A machine learning approach for precipitation nowcasting[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems. New York: ACM, 2015: 802–810. [18] YU L C, POIRSON P, YANG S, et al. Modeling context in referring expressions[C]//Proceeding of the European Conference on Computer Vision. Berlin: Springer, 2016: 69-85. [19] MAO J H, HUANG J, TOSHEV A, et al. Generation and comprehension of unambiguous object descriptions[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 11-20. [20] KAZEMZADEH S, ORDONEZ V, MATTEN M, et al. ReferItGame: Referring to objects in photographs of natural scenes[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2014: 787-798. [21] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//Proceeding of the European Conference on Computer Vision. Berlin: Springer, 2014: 740-755. [22] ESCALANTE H J, HERNÁNDEZ C A, GONZALEZ J A, et al. The segmented and annotated IAPR TC-12 benchmark[J]. Computer Vision and Image Understanding, 2010, 114(4): 419-428. doi: 10.1016/j.cviu.2009.03.008 [23] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. doi: 10.1145/3065386 [24] YU L C, LIN Z, SHEN X H, et al. MAttNet: Modular attention network for referring expression comprehension[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 1307-1315. [25] HU Z W, FENG G, SUN J Y, et al. Bi-directional relationship inferring network for referring image segmentation[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 4423-4432. -

 下载:
下载:



 点击查看大图
点击查看大图

计量
- 文章访问数: 1068
- HTML全文浏览量: 84
- PDF下载量: 12
- 被引次数: 0
