



-
摘要:
图像中的区域特征更关注于图像中的前景信息,背景信息往往被忽略,如何有效的联合局部特征和全局特征还没有得到充分地研究。为解决上述问题,加强全局概念和局部概念之间的关联得到更准确的视觉特征,提出一种基于多级语义对齐的图像-文本匹配算法。提取局部图像特征,得到图像中的细粒度信息;提取全局图像特征,将环境信息引入到网络的学习中,从而得到不同的视觉关系层次,为联合的视觉特征提供更多的信息;将全局-局部图像特征进行联合,将联合后的视觉特征和文本特征进行全局-局部对齐得到更加精准的相似度表示。通过大量的实验和分析表明:所提算法在2个公共数据集上具有有效性。
Abstract:The regional features in the image tend to pay more attention to the regional features in the image, and the environmental information is often ignored. How to effectively combine local features and global features has not been fully studied. A image-text maxching algorthm based on multi-level semantic alignment is proposed as a solution to this problem and to improve the association between global concepts and local concepts to provide more accurate visual characteristics. In order to obtain different visual relationship levels and provide more information for the joint visual features, this paper first extracts the local image features to obtain the fine-grained information in the image. It then extracts the global image features to introduce the environmental information into the network learning. To provide a more precise similarity representation, the picture characteristics are next integrated, and finally the combined visual and text features are aligned. Through a lot of experiments and analysis, the effectiveness of the proposed algorithm on two public datasets is proven.
-
表 1 本文算法网络细节
Table 1. Details network of the proposed algolithm
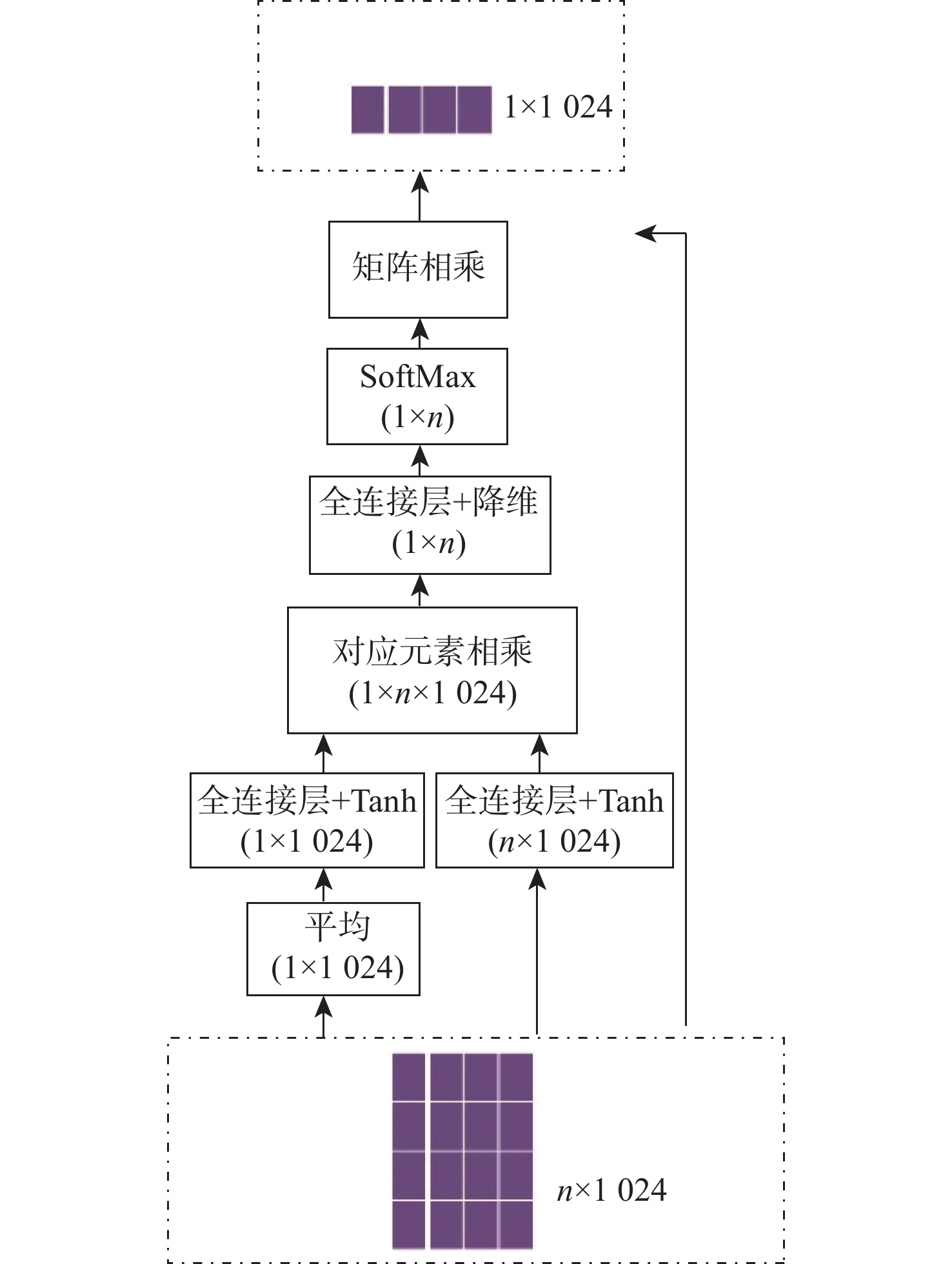
步骤 输出编号 输入 操作 符号 输出 通用表示提取 ① 图像 Faster R-CNN 36×2048 ② ① 全连接层 $ \mathop {\boldsymbol{I}}\nolimits^1 $ 36×1024 ③ 图像 ResNet152,view 49×2048 ④ ③ 全连接层 $ \mathop {\boldsymbol{I}}\nolimits^2 $ 49×1024 ⑤ ②④ 特征拼接 $ {\boldsymbol{I}} $ 85×1024 ⑥ ⑤ 自注意力模态 $ \overline{\boldsymbol{ i}} $ 1×1024 ⑦ 文本 单词嵌入空间 L×300 ⑧ ⑦ Bi-GRU $ {\boldsymbol{T}} $ L×1024 ⑨ ⑧ 自注意力模态 $ \overline {\boldsymbol{t}} $ 1×1024 相似性表示学习 ⑩ ⑥⑨ 式(2) $ \mathop {\boldsymbol{S}}\nolimits_{{\mathrm{glo}}} $ 1×256 ⑪ ②⑧ 式(3)~式(5) $ \mathop {\boldsymbol{S}}\nolimits_{{\mathrm{avg}}} $ L×256 ⑫ ⑩⑪ 特征拼接 (L+1)×256 ⑬ ⑫ 全连接层+sigmoid 1  下载: 导出CSV
下载: 导出CSV
表 2 在MSCOCO数据集上的结果
Table 2. Results on MSCOCO dataset
% 算法类型 算法 R1 R5 R10 Rsum 图像检测文本 文本检测图像 图像检测文本 文本检测图像 图像检测文本 文本检测图像 文本检测图像 1 K
测试集5 K
测试集1 K
测试集5 K
测试集1 K
测试集5 K
测试集1 K
测试集5 K
测试集1 K
测试集5 K
测试集1 K
测试集5 K
测试集1 K
测试集5 K
测试集全局匹配算法 DCCA[23] 22.5 6.9 34.6 21.1 45.5 31.8 19.2 6.6 30.4 20.9 41.3 32.2 193.5 119.5 DSPE[22] 50.1 79.7 89.2 39.6 75.2 86.9 420.7 VSE++[19] 64.6 41.3 90.0 71.1 95.7 81.2 52.0 30.3 84.3 59.4 92.0 72.4 478.6 355.7 GXN[20] 68.5 42.0 97.9 84.7 56.6 31.7 94.5 74.6 区域匹配算法 SCAN[11] 70.9 46.4 94.5 77.4 97.8 87.4 56.4 34.4 87.0 63.7 93.9 75.7 500.5 384.0 SGM[15] 73.4 50.5 93.8 79.3 97.8 87.9 57.5 35.5 87.3 64.9 94.3 76.5 504.1 393.9 双模态集成算法 SCAN[11] 72.7 50.4 94.8 82.2 98.4 90.0 58.5 38.6 88.4 69.3 94.8 80.4 507.9 410.9 多级匹配算法 GRLR[27] 68.9 94.1 98.0 58.6 88.2 94.9 320.4 本文算法 73.5 50.4 95.4 82.4 98.6 90.2 59.0 37.2 89.1 69.6 95.6 80.7 511.2 410.5
下载: 导出CSV
表 3 在Flickr30K数据集上的结果
Table 3. Results on Flickr30K dataset
% 算法类型 算法 R1 R5 R10 Rsum 图像检测文本 文本检测图像 图像检测文本 文本检测图像 图像检测文本 文本检测图像 文本检测图像 全局匹配算法 DCCA[23] 27.9 26.8 56.9 52.9 68.2 66.9 299.6 DSPE[22] 40.3 29.7 68.9 60.1 79.9 72.1 351.0 VSE++[19] 52.9 39.6 80.5 70.1 87.2 79.5 409.8 GXN[20] 56.8 41.5 89.6 80.1 区域匹配算法 SCAN[11] 67.9 43.9 89.0 74.2 94.4 82.8 452.2 SGM[15] 71.8 91.7 53.5 79.6 95.5 86.5 478.6 双模态集成算法 SCAN[11] 67.4 48.6 90.3 77.7 95.8 85.2 465.0 多级匹配算法 GRLR[27] 68.2 43.3 89.1 73.5 94.5 82.5 288.6 本文算法 68.4 53.7 91.8 79.9 95.3 86.6 475.7
下载: 导出CSV
-
[1] ZHANG C Y, SONG J Y, ZHU X F, et al. HCMSL: Hybrid cross-modal similarity learning for cross-modal retrieval[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2021, 17(1s): 1-22. [2] CHUN S, OH S J, DE REZENDE R S, et al. Probabilistic embeddings for cross-modal retrieval[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 8411-8420. [3] YU T, YANG Y, LI Y, et al. Heterogeneous attention network for effective and efficient cross-modal retrieval[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 1146-1156. [4] DONG J F, LONG Z Z, MAO X F, et al. Multi-level alignment network for domain adaptive cross-modal retrieval[J]. Neurocomputing, 2021, 440: 207-219. doi: 10.1016/j.neucom.2021.01.114 [5] WANG X, HU P, ZHEN L L, et al. DRSL: Deep relational similarity learning for cross-modal retrieval[J]. Information Sciences, 2021, 546: 298-311. doi: 10.1016/j.ins.2020.08.009 [6] ZHU L, ZHENG C Q, LU X, et al. Efficient multi-modal hashing with online query adaption for multimedia retrieval[J]. ACM Transactions on Information Systems, 2021, 40(2): 1-36. [7] WU J L, XIE X X, NIE L Q, et al. Reconstruction regularized low-rank subspace learning for cross-modal retrieval[J]. Pattern Recognition, 2021, 113: 107813. doi: 10.1016/j.patcog.2020.107813 [8] JIAO F K, GUO Y Y, NIU Y L, et al. REPT: Bridging language models and machine reading comprehension via retrieval-based pre-training[C]//Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: Association for Computational Linguistics, 2021: 150-163. [9] LU X, ZHU L, LIU L, et al. Graph convolutional multi-modal hashing for flexible multimedia retrieval[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 1414-1422. [10] HU Y P, LIU M, SU X B, et al. Video moment localization via deep cross-modal hashing[J]. IEEE Transactions on Image Processing, 2021, 30: 4667-4677. doi: 10.1109/TIP.2021.3073867 [11] LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 212-228. [12] WANG Y X, CHEN Z D, LUO X, et al. Fast cross-modal hashing with global and local similarity embedding[J]. IEEE Transactions on Cybernetics, 2022, 52(10): 10064-10077. doi: 10.1109/TCYB.2021.3059886 [13] DIAO H W, ZHANG Y, MA L, et al. Similarity reasoning and filtration for image-text matching[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Washington, DC: AAAI, 2021, 35(2): 1218-1226. [14] ZOU X T, WANG X Z, BAKKER E M, et al. Multi-label semantics preserving based deep cross-modal hashing[J]. Signal Processing:Image Communication, 2021, 93: 116131. doi: 10.1016/j.image.2020.116131 [15] WANG S J, WANG R P, YAO Z W, et al. Cross-modal scene graph matching for relationship-aware image-text retrieval[C]//2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2020: 1497-1506. [16] ZHAN Y W, WANG Y X, SUN Y, et al. Discrete online cross-modal hashing[J]. Pattern Recognition, 2022, 122: 108262. doi: 10.1016/j.patcog.2021.108262 [17] ZHU L P, TIAN G Y, WANG B Y, et al. Multi-attention based semantic deep hashing for cross-modal retrieval[J]. Applied Intelligence, 2021, 51(8): 5927-5939. doi: 10.1007/s10489-020-02137-w [18] WEN H K, SONG X M, YANG X, et al. Comprehensive linguistic-visual composition network for image retrieval[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 1369-1378. [19] FAGHRI F, FLEET D J, KIROS J R, et al. VSE++: Improving visual-semantic embeddings with hard negatives[EB/OL]. (2017-07-08)[2022-01-25].https://arxiv.org/abs/1707.05612v4. [20] GU J X, CAI J F, JOTY S, et al. Look, imagine and match: improving textual-visual cross-modal retrieval with generative models[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7181-7189. [21] WANG H R, ZHANG Y, JI Z, et al. Consensus-aware visual-semantic embedding for image-text matching[C]//European Conference on Computer Vision. Berlin: Springer, 2020: 18-34. [22] WANG L W, LI Y, LAZEBNIK S. Learning deep structure-preserving image-text embeddings[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 5005-5013. [23] ANDREW G, ARORA R, BILMES J, et al. Deep canonical correlation analysis[J]. Journal of Machine Learning Research, 2013, 28: 1247-1255. [24] CHEN H, DING G G, LIU X D, et al. IMRAM: Iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 12652-12660. [25] YAO T, LI Y R, GUAN W L, et al. Discrete robust matrix factorization hashing for large-scale cross-media retrieval[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(2): 1391-1401. [26] YAO T, KONG X W, FU H Y, et al. Discrete semantic alignment hashing for cross-media retrieval[J]. IEEE Transactions on Cybernetics, 2020, 50(12): 4896-4907. doi: 10.1109/TCYB.2019.2912644 [27] 李志欣, 凌锋, 张灿龙, 等. 融合两级相似度的跨媒体图像文本检索[J]. 电子学报, 2021, 49(2): 268-274.LI Z X, LING F, ZHANG C L, et al. Cross-media image-text retrieval with two level similarity[J]. Acta Electronica Sinica, 2021, 49(2): 268-274 (in Chinese). -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 190
- HTML全文浏览量: 102
- PDF下载量: 12
- 被引次数: 0
