



-
摘要:
零样本目标检测借助语义嵌入作为引导信息,将未见过的物体的视觉特征与类别语义嵌入映射到同一空间,根据其在映射空间的距离进行分类,但由于语义信息获取的单一性,视觉信息缺乏可靠表示,易混淆背景信息和未见过对象信息,使得视觉和语义之间很难无差别对齐。基于此,借助视觉上下文模块捕捉视觉特征的上下文信息,并通过语义优化模块对文本上下文和视觉上下文信息进行交互融合,增加视觉表达的多样化,使模型感知到前景的辨别性语义,从而有效地实现零样本目标检测。在MS-COCO的2个划分数据集上进行实验,在零样本目标检测和广义零样本目标检测的准确率和召回率上取得了提升,结果证明了所提方法的有效性。
Abstract:Existing zero-shot object detection maps visual features and category semantic embeddings of unseen items to the same space using semantic embeddings as guiding information, and then classifies the objects based on how close together the visual features and semantic embeddings are in the mapped space. However, due to the singleness of semantic information acquisition, the lack of reliable representation of visual information can easily confuse background information and unseen object information, making it difficult to indiscriminately align visual and semantic information. In order to effectively achieve zero-shot object detection, this paper uses the visual context module to capture the context information of visual features and the semantic optimization module to interactively fuse the text context and visual context information. By increasing the diversity of visual expressions, the model is able to perceive the discriminative semantics of the foreground. Experiments were conducted on two divided datasets of MS-COCO, and a certain improvement was achieved in the accuracy and recall rate of zero-shot target detection and generalized zero-shot target detection. The results proved the effectiveness of the proposed method.
-
Key words:
- object-detection /
- zero-shot object detection /
- multi-modal /
- context perception /
- semantic optimization
-

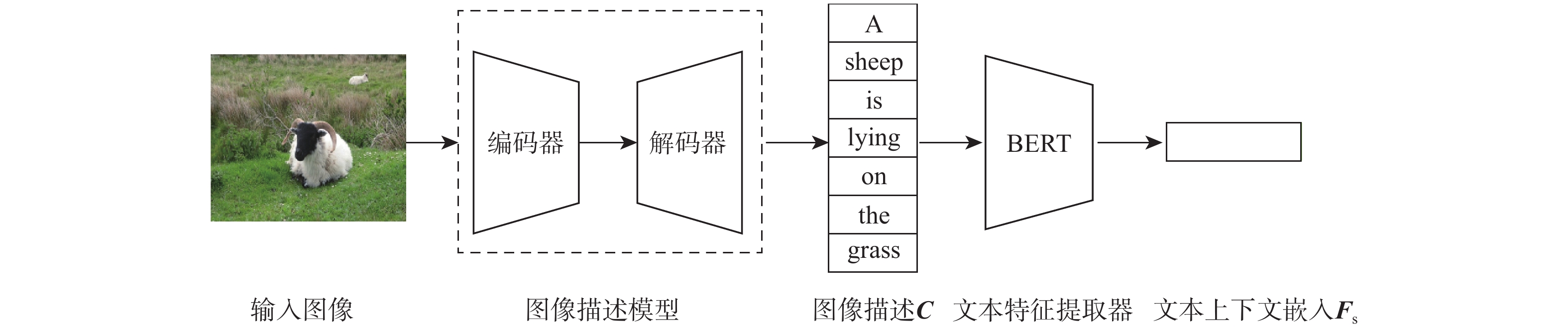
图 1 基于多模态联合语义感知的零样本目标检测整体框架
Figure 1. Overall framework of zero-shot object detection based on multi-modal joint semantic perception
表 1 48/17和65/15数据集上零样本目标检测的实验结果
Table 1. Experimental results of ZSD on 48/17 and 65/16 datasets
方法 可见类/不可见类
数量召回率/% 平均准确率
(阈值0.5)/%阈值0.4 阈值0.5 阈值0.6 SB[2] 48/17 34.46 22.14 11.31 0.32 DSES[2] 48/17 40.23 27.19 13.63 0.54 TD[5] 48/17 45.50 34.30 18.10 CG[17] 48/17 7.2 65/15 10.9 PL[12] 48/17 43.59 10.10 65/15 37.72 12.40 BLC[13] 48/17 49.63 46.39 41.86 9.90 65/15 54.18 51.65 47.86 13.10 BLC(ms)[13] 48/17 51.33 48.87 45.03 10.60 65/15 57.23 54.68 51.22 14.70 本文方法 48/17 51.40 48.69 45.29 12.10 65/15 57.26 55.03 51.50 14.90 注:ms表示多尺度训练和测试。  下载: 导出CSV
下载: 导出CSV
表 2 48/17和65/15数据集上广义零样本目标检测的实验结果
Table 2. Experimental results of GZSD on 48/17 and 65/15 datasets
方法 可见类/不可见类
数量平均准确率/% 召回率/% 可见类 不可见类 HM 可见类 不可见类 HM DSES[2] 48/17 15.02 15.32 15.17 PL[12] 48/17 35.92 4.12 7.39 38.24 26.32 31.18 65/15 34.07 12.40 18.18 36.38 37.16 36.76 BLC[13] 48/17 42.10 4.50 8.20 57.56 46.39 51.37 65/15 36.00 13.10 19.20 56.39 51.65 53.92 本文方法 48/17 44.10 5.10 9.10 61.23 49.18 54.55 65/15 36.30 13.50 21.10 57.53 56.54 57.03 注:HM表示可见类和不可见类的调和平均值。
下载: 导出CSV
表 3 48/17数据集上不可见类别的召回率
Table 3. Recall of invisible categories on 48/17 dataset
% 方法 总体
召回率召回率 bus dog cow elephant umbrella tie skateboard cup knife cake couch keyboard sink scissors airplane cat snowboard 基准(BLC[13]) 46.4 77.4 88.4 71.9 77.2 0 0 41.7 38.0 45.6 34.3 65.2 23.8 14.1 20.8 48.3 79.9 61.8 本文方法 48.7 77.7 93.8 78.6 78.3 0.3 0 64.9 44.3 39.9 39.9 70.2 19.2 17.0 12.5 58.0 85.3 74.0
下载: 导出CSV
表 4 65/15数据集上不可见类别的召回率
Table 4. Recall of invisible categories on 65/15 dataset
% 方法 总体
召回率召回率 airplane train parking meter cat bear suitcase frisbee snowboard fork sandwich hot dog toilet mouse toaster hair drier 基准(BLC[13]) 51.3 58.7 72.0 10.2 96.1 91.6 46.9 44.1 65.4 37.9 82.5 73.6 43.8 7.9 35.9 2.7 本文方法 55.0 67.0 77.4 9.6 96.9 91.8 53.7 49.2 69.0 41.1 86.1 77.6 50.1 10.9 42.3 2.7
下载: 导出CSV
表 5 各模块性能
Table 5. Performance of each module
基准(BLC[13]) 视觉上下文模块 语义优化模块 平均准确率/% √ 10.6 √ √ 10.0 √ √ 11.2 √ √ √ 12.1
下载: 导出CSV
表 6 语义信息的选取
Table 6. Selection of semantic information
语义信息 平均准确率/% 无 11.2 词向量 11.3 图像描述 12.1
下载: 导出CSV
-
[1] TAN C, XU X, SHEN F. A survey of zero shot detection: Methods and applications[J]. Cognitive Robotics, 2021, 1: 159-167. doi: 10.1016/j.cogr.2021.08.001 [2] BANSAL A, SIKKA K, SHARMA G, et al. Zero-shot object detection[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 384-400. [3] ZHANG L, WANG X, YAO L, et al. Zero-shot object detection via learning an embedding from semantic space to visual space[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence and 17th Pacific Rim International Conference on Artificial Intelligence. [S. l.]: IJCAI, 2020: 906-912. [4] GUPTA D, ANANTHARAMAN A, MAMGAIN N, et al. A multi-space approach to zero-shot object detection[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2020: 1209-1217. [5] LI Z, YAO L, ZHANG X, et al. Zero-shot object detection with textual descriptions[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto : AAAI Press, 2019: 8690-8697. [6] YANG X, TANG K, ZHANG H, et al. Auto-encoding scene graphs for image captioning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 10685-10694. [7] FENG Y, MA L, LIU W, et al. Unsupervised image captioning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 4125-4134. [8] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2014: 740-755. [9] WANG W, ZHENG V W, YU H, et al. A survey of zero-shot learning: Settings, methods, and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019, 10(2): 1-37. [10] ZHU P, WANG H, SALIGRAMA V. Don’t even look once: Synthesizing features for zero-shot detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 11693-11702. [11] RAHMAN S, KHAN S, BARNES N. Polarity loss for zero-shot object detection[EB/OL]. (2020-04-02)[2022-05-01]. https://arxiv.org/abs/1811.08982v2. [12] RAHMAN S, KHAN S, BARNES N. Improved visual-semantic alignment for zero-shot object detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 11932-11939. [13] ZHENG Y, HUANG R, HAN C, et al. Background learnable cascade for zero-shot object detection[C]//Proceedings of the Asian Conference on Computer Vision. Berlin: Springer, 2020: 107-123. [14] CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6154-6162. [15] GU X, LIN T Y, KUO W, et al. Zero-shot detection via vision and language knowledge distillation[EB/OL]. (2022-05-12)[2022-05-15]. https://arxiv.org/abs/2104.13921v1. [16] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]//Proceedings of the International Conference on Machine Learning. [S. l.]: PMLR, 2021: 8748-8763. [17] LI Y, SHAO Y, WANG D. Context-guided super-class inference for zero-shot detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 944-945. [18] GU Z, ZHOU S, NIU L, et al. Context-aware feature generation for zero-shot semantic segmentation[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1921-1929. [19] YANG Z, WANG Y, CHEN X, et al. Context-Transformer: Tackling object confusion for few-shot detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 12653-12660. [20] YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. (2016-04-30)[2022-05-01]. https://arxiv.org/abs/1511.07122. [21] XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//Proceedings of the International Conference on Machine Learning. [S. l. ]: PMLR, 2015: 2048-2057. [22] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2022-05-01]. https://arxiv.org/abs/1409.1556. [23] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[EB/OL]. (2016-05-19)[2022-05-01]. https://arxiv.org/abs/1409.0473v5. [24] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. doi: 10.1162/neco.1997.9.8.1735 [25] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24)[2022-05-01]. https://arxiv.org/abs/1810.04805v2. [26] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [27] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [28] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 2117-2125. [29] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. New York: ACM, 2013: 3111-3119. -

 下载:
下载:


 点击查看大图
点击查看大图

计量
- 文章访问数: 996
- HTML全文浏览量: 95
- PDF下载量: 37
- 被引次数: 0
