



-
摘要:
在人像超分辨率重建领域,传统方法通常将整幅图像进行统一处理,导致效率低下。为降低模型的推理时延,提出了一种实时超分辨率重建模型RASR。该模型利用门控单元处理低分辨率图像,识别出人像边缘区域;采用分区重建策略,使用不同尺寸的子模型分别针对包含或不包含人像边缘的区域进行重建。实验结果表明:与现有方法相比,RASR模型在4倍上采样重建场景下的推理时延降低了88%,能够更有效地重建高分辨率人像图像。
Abstract:Conventional techniques typically process the entire image uniformly, which leads to low efficiency in the field of portrait super-resolution reconstruction.To reduce the inference latency of the model, this research proposes a real-time super-resolution reconstruction model RASR. The model first uses gating unit to process the low-resolution images and identify the edge of the portrait. Then, a partition reconstruction strategy is adopted, and sub-models of different sizes are used to reconstruct the areas containing or not containing the portrait edge, respectively. The experimental results show that the RASR model is able to reconstruct high-resolution portrait images more efficiently by reducing the inference latency of the RASR model by 88% in a 4-foldsampling reconstruction scene compared to the existing methods.
-
Key words:
- region aware /
- single-image super-resolution /
- gating unit /
- channel-wise split block /
- deep learning
-

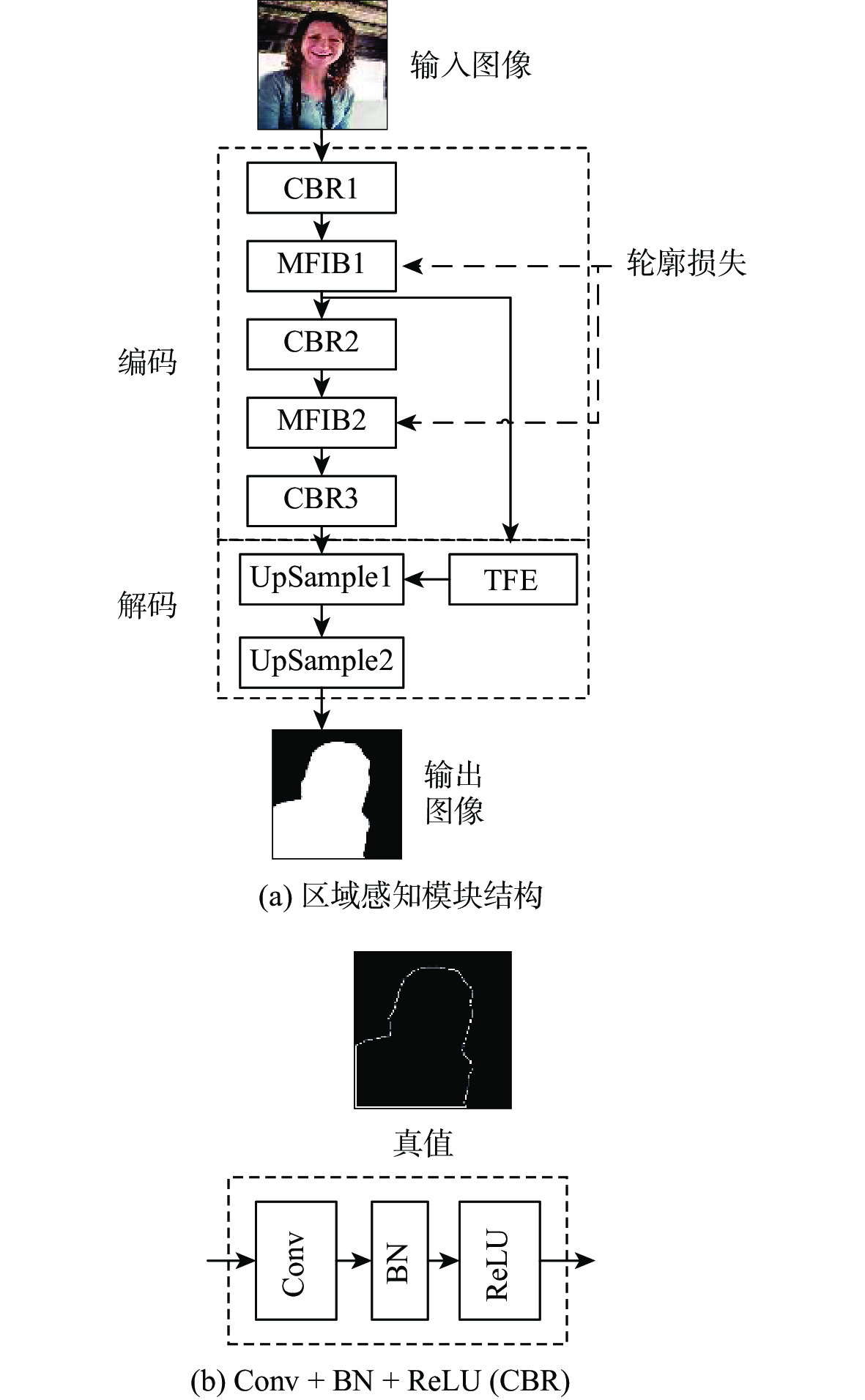
图 1 轻量语义分割模型网络结构
Figure 1. Network architecture of lightweight semantic segmentation model

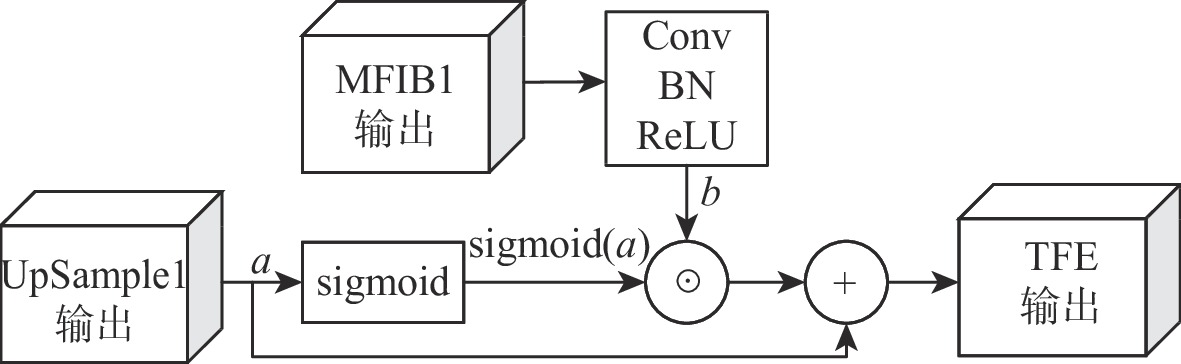
图 3 低分辨率图像与可信特征提取器输出特征图对比
Figure 3. Comparison of low-resolution image and TFE output features

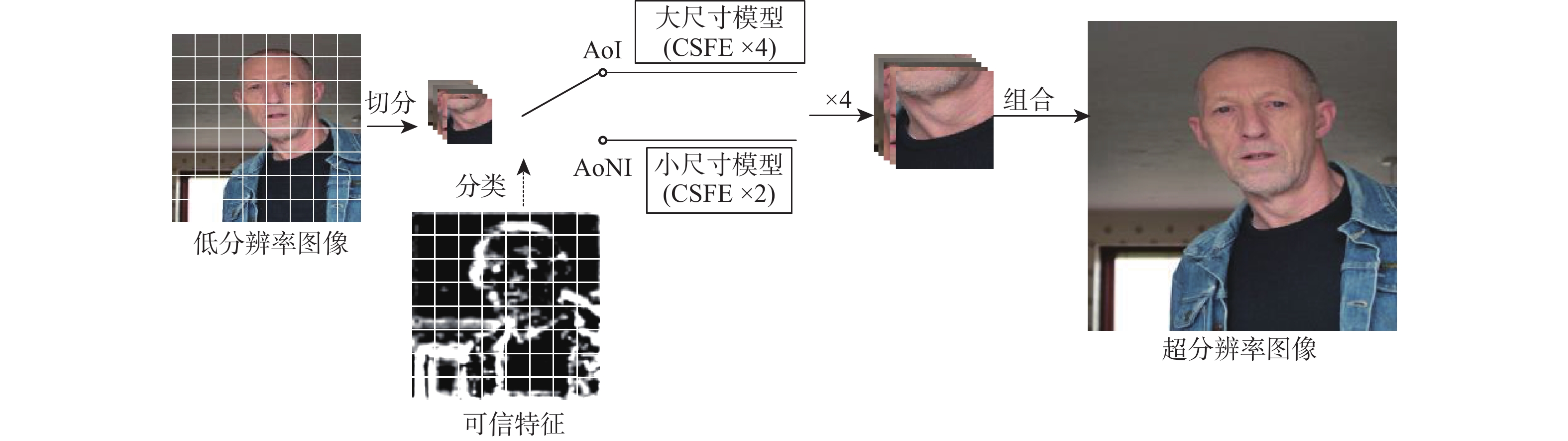
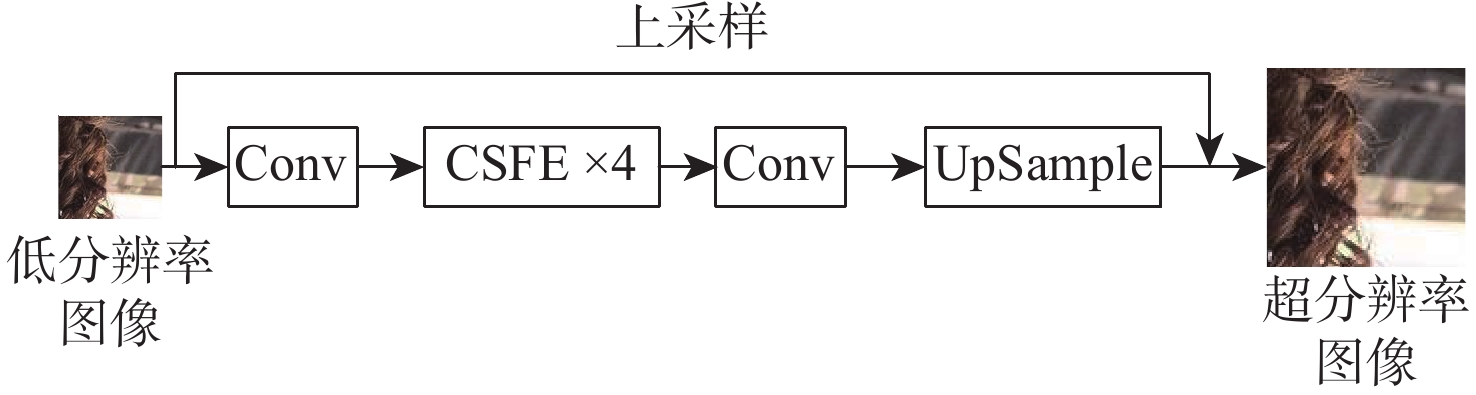
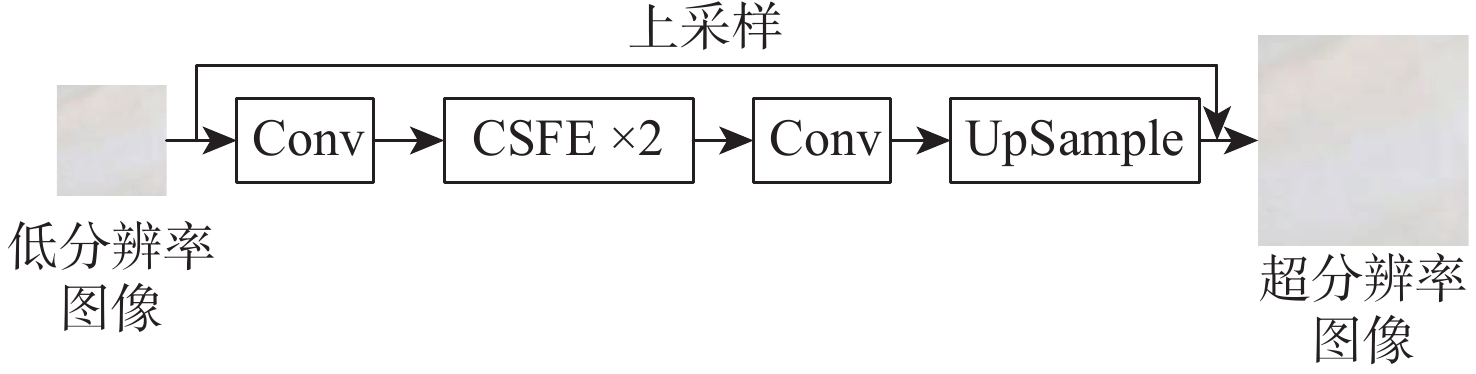
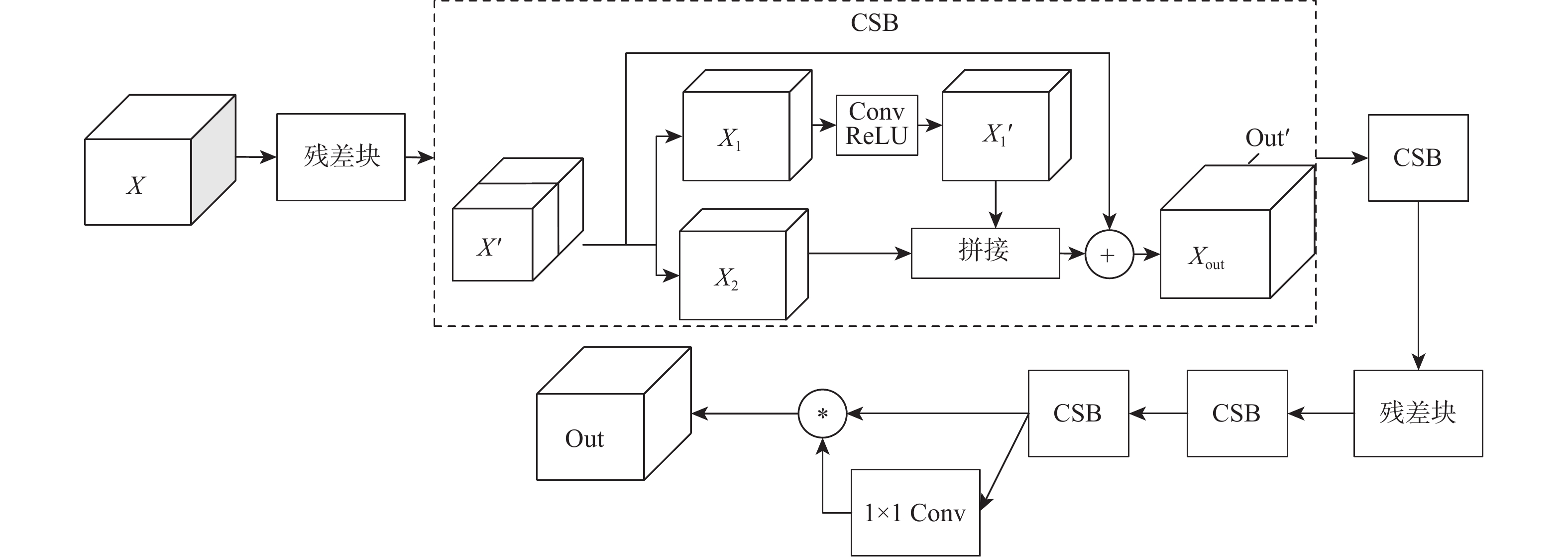
图 4 超分辨率重建模块整体框架示意图
Figure 4. Schematic diagram of overall framework of super-resolution reconstruction module
表 1 CSFE模块性能对比
Table 1. Performance comparison of CSFE module
∂ MAC/109 时延/ms mPSNR/dB mSSIM 0.25 28.29 20.87 32.94 0.9388 0.50 29.01 22.78 32.97 0.9401 0.75 29.12 24.92 33.01 0.9404 1.00 29.21 27.74 33.03 0.9405 注:MAC为前向传播每秒执行的乘累加计算量,mPSNR为平均峰值信噪比,mSSIM为平均结构相似度。  下载: 导出CSV
下载: 导出CSV
表 2 可信特征提取器应用前后语义分割模型性能对比
Table 2. Performance comparison of semantic segmentation models before and after application of TFE
有无TFE 参数量/103 MAC/106 时延/ms mPA/% mIoU 无 150.08 97.01 1.01 91.7 93.26 有 150.18 97.15 1.02 92.2 94.81 注:mPA为平均像素准确率,mIoU为平均交并比。
下载: 导出CSV
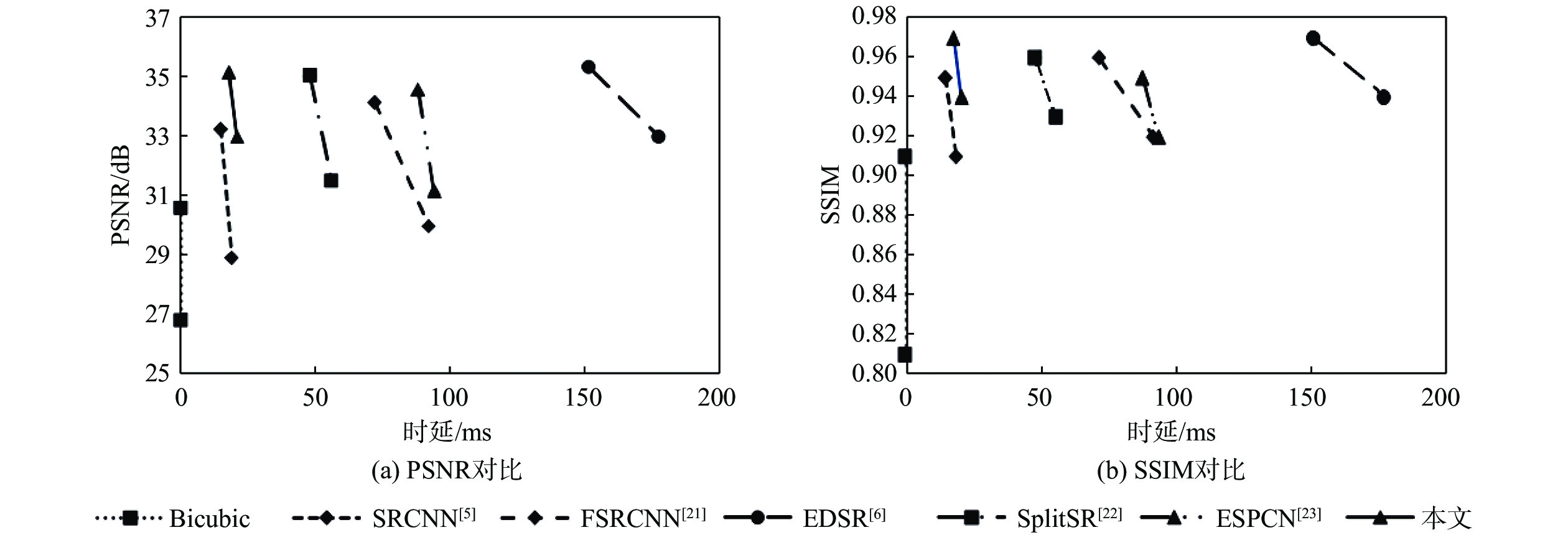
表 3 2倍和4倍重建倍率下各模型的性能对比
Table 3. Performance comparison of various models under2 and 4 reconstruction magnification
方法 PSNR/dB SSIM 时延/ms s=2 s=4 s=2 s=4 s=2 s=4 Bicubic 30.56 26.74 0.91 0.81 0.2 0.2 SRCNN[5] 33.21 28.86 0.95 0.91 15 19 FSRCNN[21] 34.12 29.93 0.96 0.92 72 92 EDSR[6] 35.31 32.96 0.97 0.94 151 177 SplitSR[22] 35.05 31.46 0.96 0.93 48 56 ESPCN[23] 34.54 31.11 0.95 0.92 88 94 本文 35.13 32.94 0.97 0.94 18 21
下载: 导出CSV
-
[1] KEYS R. Cubic convolution interpolation for digital image processing[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(6): 1153-1160. doi: 10.1109/TASSP.1981.1163711 [2] KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1637-1645. [3] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 1646-1654. [4] LIU F, YU Q, CHEN L, et al. Aerial image super-resolution based on deep recursive dense network for disaster area surveillance[J]. Personal Ubiquitous Computing, 2022, 26: 1205-1214. [5] DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2014: 184-199. [6] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 136-144. [7] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [8] TONG T, LI G, LIU X, et al. Image super-resolution using dense skip connections[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 4799-4807. [9] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 1-9. [10] HAN K, WANG Y, TIAN Q, et al. GhostNet: More features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 1580-1589. [11] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141. [12] WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7794-7803. [13] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Berlin: Springer, 2015: 234-241. [14] YU C, WANG J, PENG C, et al. BiSeNet: Bilateral segmentation network for real-time semantic segmentation[C//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 334-349. [15] FAN M, LAI S, HUANG J, et al. Rethinking bisenet for real-time semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 9716-9725. [16] HE Z, LIU K, LIU Z, et al. A lightweight multi-scale feature integration network for real-time single image super-resolution[J]. Journal of Real-Time Image Processing, 2021, 18(4): 1221-1234. doi: 10.1007/s11554-021-01142-7 [17] ACUNA D, LING H, KAR A, et al. Efficient interactive annotation of segmentation datasets with Polygon-RNN++[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 859-868. [18] LING H, GAO J, KAR A, et al. Fast interactive object annotation with Curve-GCN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 5257-5266. [19] BELKIN M, HSU D, MA S, et al. Reconciling modern machine-learning practice and the classical bias-variance trade-off[J]. Proceedings of the National Academy of Sciences, 2019, 116(32): 15849-15854. doi: 10.1073/pnas.1903070116 [20] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. doi: 10.1109/5.726791 [21] DONG C, LOY C C, TANG X. Accelerating the super-resolution convolutional neural network[C]//Proceedings of the European Conference on Computer Vision. Berlin:Springer, 2016: 391-407. [22] LIU X, LI Y, FROMM J, et al. SplitSR: An end-to-end approach to super-resolution on mobile devices[C]//Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies.New York:ACM, 2021, 5(1): 1-20. [23] SHI W, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 1874-1883. -

 下载:
下载:



 点击查看大图
点击查看大图
计量
- 文章访问数: 656
- HTML全文浏览量: 89
- PDF下载量: 5
- 被引次数: 0
