



-
摘要:
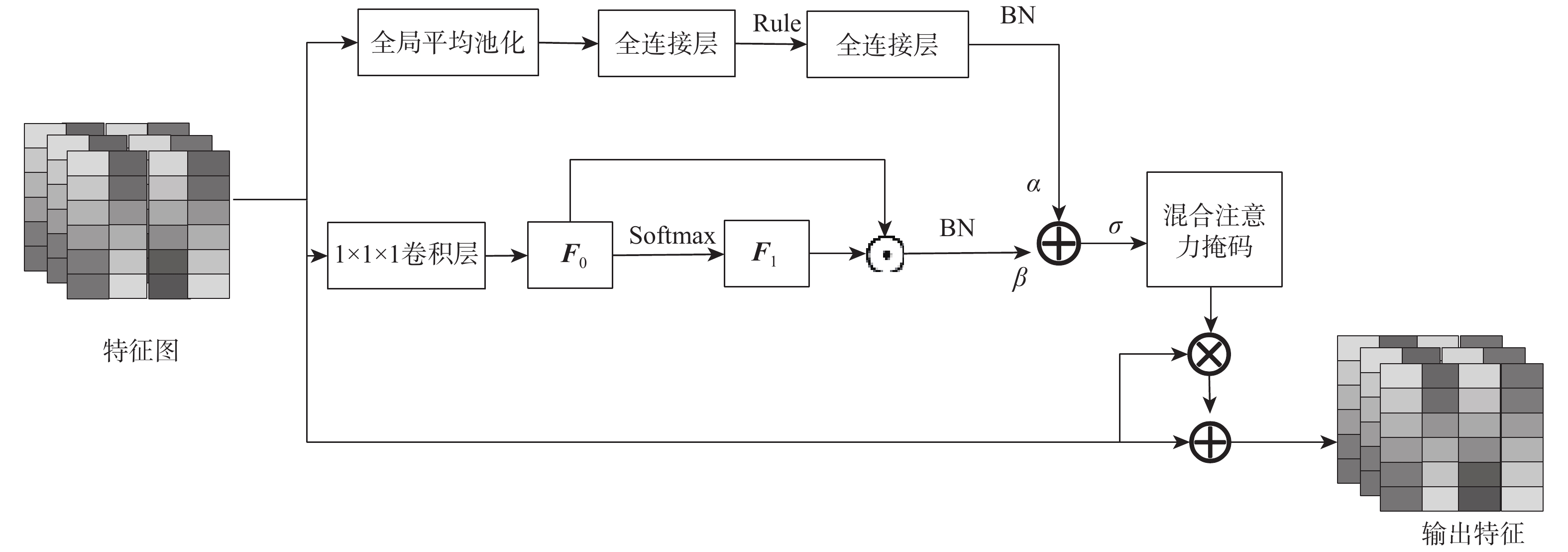
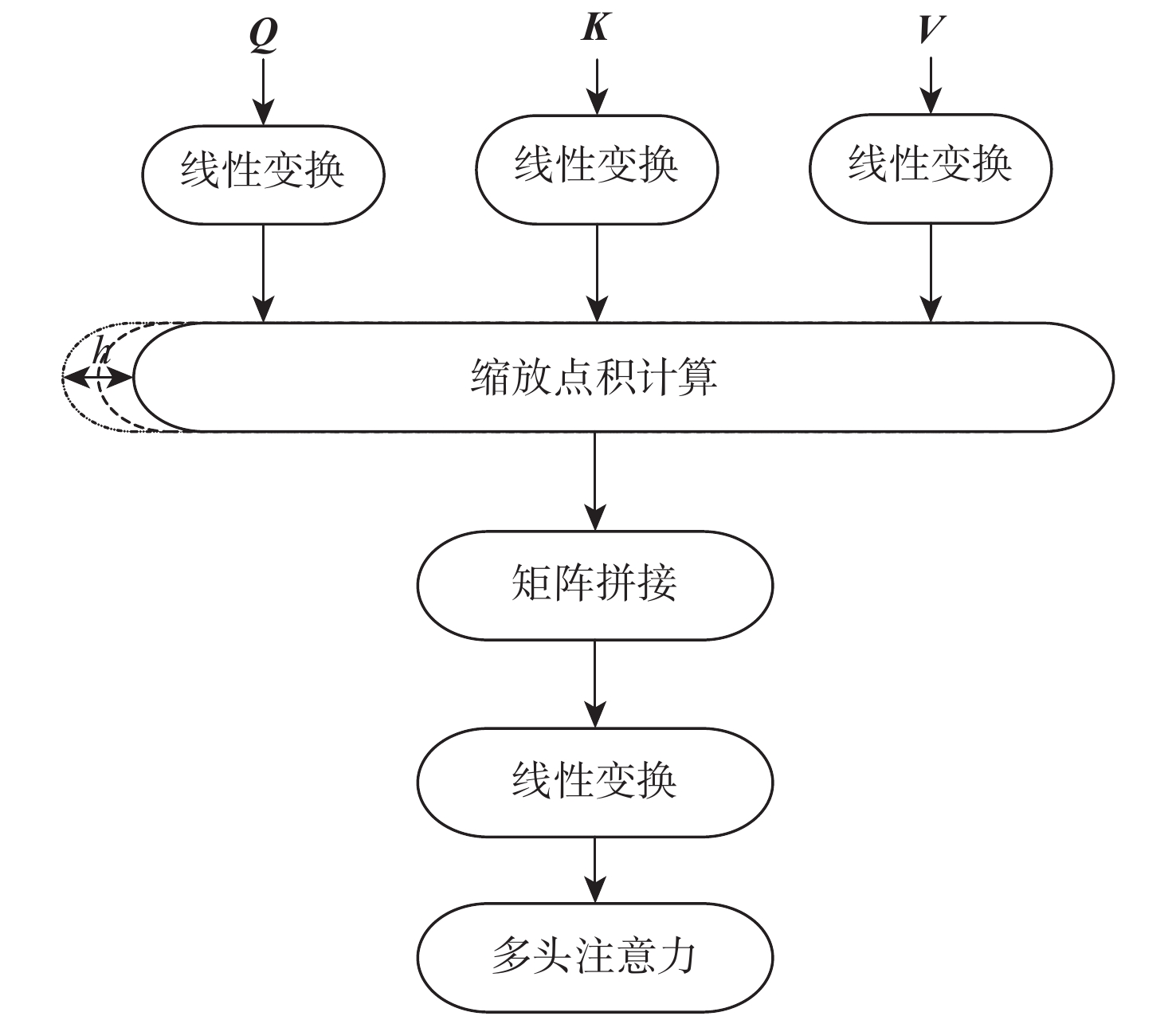
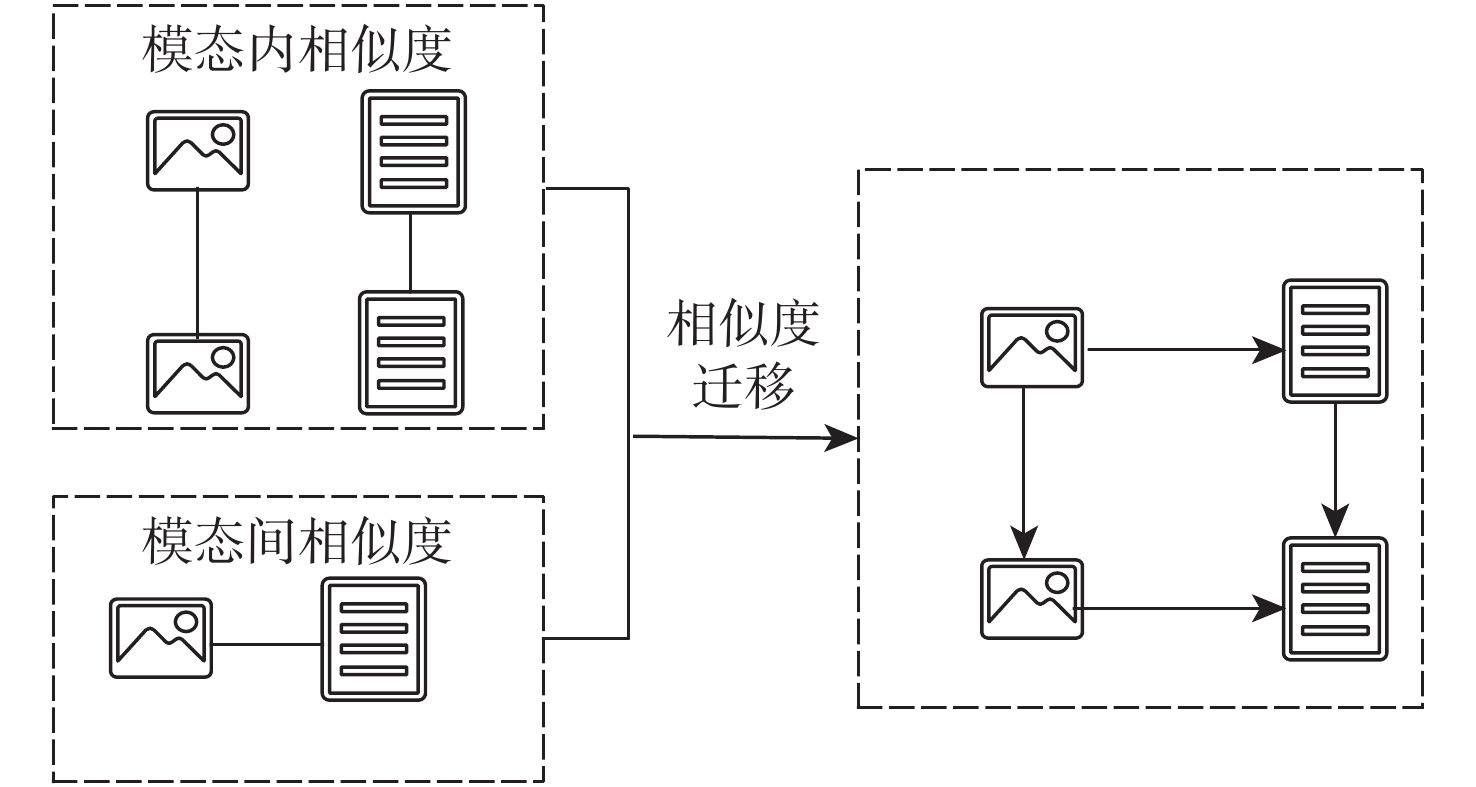
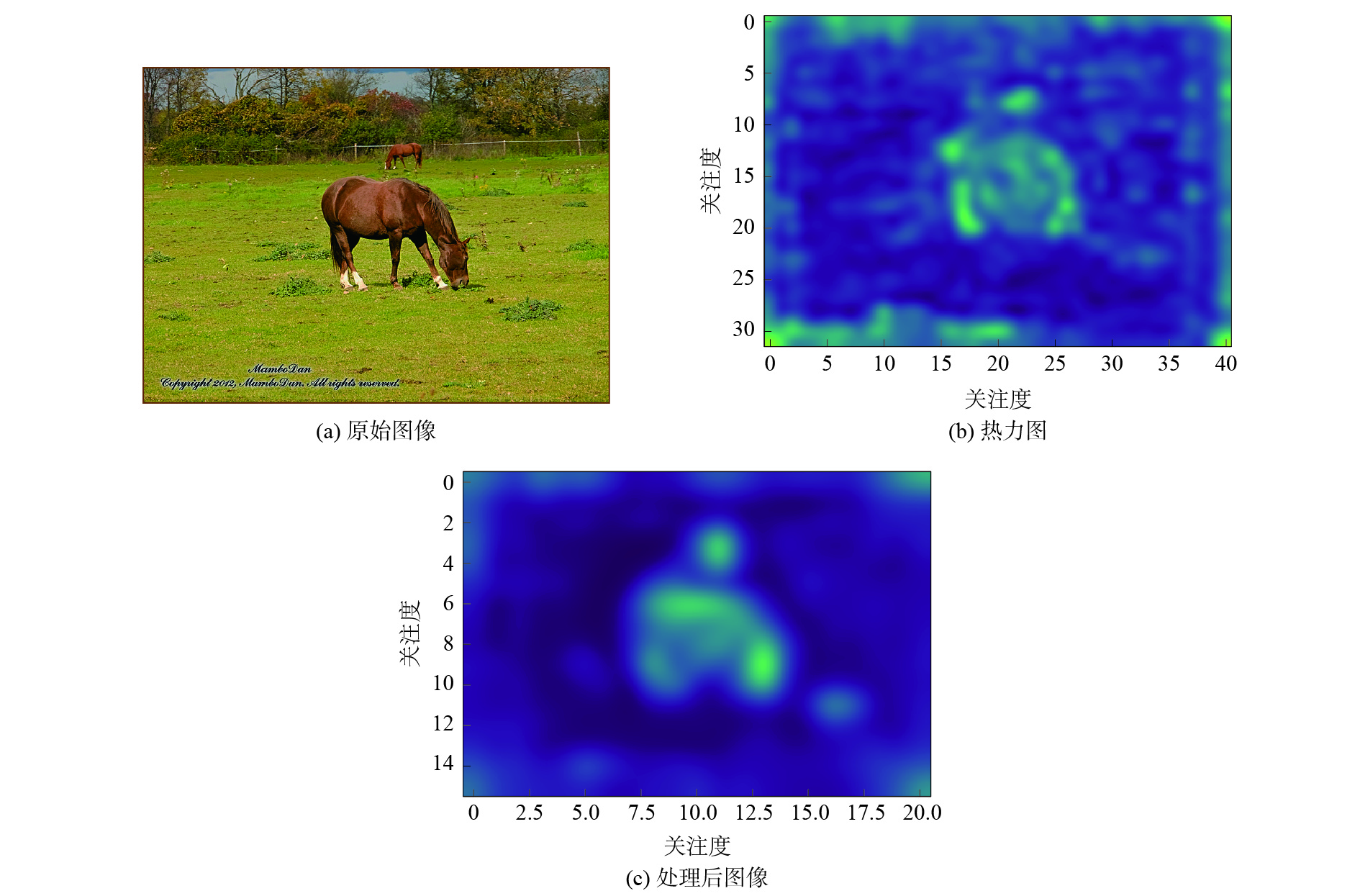
为进一步提升跨模态检索性能,提出自注意力相似度迁移跨模态哈希网络模型。设计了一种通道空间混合自注意力机制强化关注图像的关键信息,并使用共同注意力方法加强模态信息交互,提高特征学习质量;为在哈希空间重构相似关系,采用迁移学习的方法利用实值空间相似度引导哈希码的生成。在3个常用的数据集MIRFLICKR-25K、IAPR TC-12和MSCOCO上与深度跨模态哈希(DCMH)、成对关系引导的深度哈希(PRDH)、跨模态汉明哈希(CMHH)等优秀方法进行对比实验,结果显示哈希码长度为64 bit的条件下,所提模型在3个数据集图像检索文本任务的平均精确度均值(MAP)达到72.3%,文本检索图像任务的MAP达到70%,高于对比方法。
Abstract:To further improve the performance of cross-modal retrieval, a cross-modal hashing network model is proposed based on self-attention similarity transfer. A channel spatial hybrid self-attention mechanism is designed to strengthen the key information of the concerned image, and the common attention method is used to enhance the interaction of modal information, thus improving the quality of feature learning. To reconstruct the similarity relationship in the hash space, the transfer learning method is used to guide the generation of hash codes by using the real-valued space similarity. Comparative experiments are carried out on three commonly used datasets, MIRFLICKR-25K, IAPRTC-12 and MSCOCO, with excellent methods such as deep cross-modal hashing (DCMH), pairwise relationship guided deep hashing (PRDH) and cross-modal hamming hashing (CMHH). The results show that when the length of the hash code reaches 64 bit, the mean average precision (MAP) of the text retrieval task with image queries in three datasets is 72.3%, and that the MAP of the image retrieval task with text queries is 70%. These values are higher than those of other methods.
-
表 1 数据集配置表
Table 1. Configuration table of datasets
数据集 总数目/个 训练集/个 验证集/个 MIRFLICKR-25K 20015 10000 2000 MSCOCO 122218 10000 5000 IAPR TC-12 19998 10000 2000  下载: 导出CSV
下载: 导出CSV
表 2 在3个公共数据集上各方法的MAP
Table 2. MAP of each method on three public datasets
检索任务 方法 MIRFLICKR-25K上的MAP MSCOCO上的MAP IAPR TC-12上的MAP 16 bit 32 bit 64 bit 16 bit 32 bit 64 bit 16 bit 32 bit 64 bit 图像检索文本 DCMH 0.71 0.72 0.72 0.49 0.55 0.53 0.45 0.47 0.49 PRDH 0.64 0.66 0.65 0.51 0.52 0.51 0.45 0.43 0.46 CMHH 0.72 0.72 0.74 0.52 0.53 0.54 0.41 0.42 0.43 SCAHN 0.78 0.78 0.79 0.59 0.62 0.63 0.46 0.48 0.51 CHN 0.73 0.71 0.71 0.54 0.55 0.53 0.42 0.45 0.49 SSAH 0.75 0.76 0.78 0.48 0.51 0.51 0.52 0.54 0.55 UCH 0.65 0.67 0.68 0.52 0.53 0.55 0.45 0.47 0.47 本文模型 0.85 0.85 0.88 0.65 0.70 0.69 0.54 0.57 0.60 文本检索图像 DCMH 0.72 0.72 0.74 0.48 0.49 0.51 0.49 0.51 0.53 PRDH 0.69 0.72 0.71 0.45 0.48 0.49 0.41 0.45 0.47 CMHH 0.74 0.76 0.77 0.49 0.52 0.56 0.41 0.43 0.44 SCAHN 0.78 0.79 0.81 0.61 0.63 0.65 0.51 0.53 0.56 CHN 0.75 0.74 0.74 0.49 0.51 0.52 0.49 0.51 0.53 SSAH 0.72 0.75 0.77 0.42 0.46 0.48 0.49 0.51 0.53 UCH 0.66 0.67 0.67 0.50 0.52 0.55 0.45 0.47 0.49 本文模型 0.83 0.86 0.87 0.64 0.68 0.66 0.55 0.57 0.57
下载: 导出CSV
表 3 消融实验结果
Table 3. Results of ablation experiments
模型 MAP 图像检索文本 文本检索图像 SSMH-1 0.6978 0.6841 SSMH-2 0.6876 0.6755 SSMH-3 0.6983 0.6692 SSMH-4 0.6857 0.6772 SSMH-5 0.6917 0.6832
下载: 导出CSV
-
[1] 邵杰. 基于深度学习的跨模态检索[D]. 北京: 北京邮电大学, 2017: 10-13.SHAO J. Cross-modal retrieval based on deep learning [D]. Beijing University of Posts and Telecommunications, 2017: 10-13(in Chinese). [2] ZHANG Y, OU W, ZHANG J, et al. Category supervised cross-modal hashing retrieval for chest x-ray and radiology reports [J]. Computers and Electrical Engineering, 2022,98: 107673. [3] KAI L, QI G J, YE J, et al. Linear subspace ranking hashing for cross-modal retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(9): 1825-1838. [4] LI C, DENG C, LI N, et al. Self-supervised adversarial hashing networks for cross-modal retrieval[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4242-4251. [5] WU J, WENG W, FU J, et al. Deep semantic hashing with dual attention for cross-modal retrieval[J]. Neural Computing and Applications, 2022, 34(7): 5397-5416. [6] HUANG Z, WANG X, HUANG L, et al. CCNet: Criss-cross attention for semantic segmentation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 603-612 . [7] LI X, WANG W, HU X, et al. Selective kernel networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 510-519. [8] YU C, WANG J, PENG C, et al. BiSeNet: Bilateral segmentation network for real-time semantic segmentation[C]//Proceedings of the European Conference on Computer Vision. Piscataway: IEEE Press, 2018: 325-341. [9] FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 3146-3154. [10] 柳兴华, 曹桂涛, 林秋斌, 等. 自适应混合注意力深度跨模态哈希[J]. 计算机应用, 2022, 42(12): 3663-3670.LIU X H, CAO G T, LIN Q B, et al. Adaptive hybrid attention hashing for deep cross-modal retrieval[J]. Journal of Computer Applications, 2022, 42(12): 3663-3670(in Chinese). [11] WU G, LIN Z, HAN J, et al. Unsupervised deep hashing via binary latent factor models for large-scale cross-modal retrieval[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence. New York: ACM, 2018: 2854-2860. [12] KAUR P, PANNU H S, MALHI A K. Comparative analysis on cross-modal information retrieval: A review[J]. Computer Science Review, 2021, 39(2): 100336. [13] LI C, DENG C, WANG L, et al. Coupled CycleGAN: Unsupervised hashing network for cross-modal retrieval[C]//Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019, 33(1): 176-183. [14] CHENG S, WANG L, DU A. Deep semantic-preserving reconstruction hashing for unsupervised cross-modal retrieval[J]. Entropy, 2020, 22(11): 1266. [15] 康培培, 林泽航, 杨振国, 等. 成对相似度迁移哈希用于无监督跨模态检索[J]. 计算机应用研究, 2021, 38(10): 3025-3029.KANG P P, LIN Z H, YANG Z G, et al. Pairwise similarity transferring hash for unsupervised cross-modal retrieval[J]. Application Research of Computers, 2021, 38(10): 3025-3029 (in Chinese). [16] WANG D, WANG Q , HE L. et al. Joint and individual matrix factorization hashing for large-scale cross-modal retrieval[J]. Pattern Recognition, 2020, 107: 107479. [17] GUO M H, XU T X, LIU J J, et al. Attention mechanisms in computer vision: A survey[J]. Computational Visual Media, 2022, 8(3): 331-368. doi: 10.1007/s41095-022-0271-y [18] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141. [19] WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7794-7803. [20] GUO J, MA X, SANSOM A, et al. Spanet: Spatial pyramid attention network for enhanced image recognition[C]//Proceedings of the IEEE International Conference on Multimedia and Expo. Piscataway: IEEE Press, 2020: 1-6. [21] WOO S, PARK J, LEE J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision. Piscataway: IEEE Press, 2018: 3-19. [22] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13713-13722. [23] JIANG Q Y, LI W J. Deep cross-modal hashing[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 3232-3240. [24] YANG E, DENG C, LIU W, et al. Pairwise relationship guided deep hashing for cross-modal retrieval[C]//Proceedings of the 31st AAAI Conference on Artificial Intelligence. New York: ACM, 2017: 1618-1625. [25] CAO Y, LIU B, LONG M, et al. Cross-modal hamming hashing[C]//Proceedings of the European Conference on Computer Vision. Piscataway: IEEE Press, 2018: 202-218. [26] WANG X, ZOU X, BAKKER E M, et al. Self-constraining and attention-based hashing network for bit-scalable cross-modal retrieval[J]. Neurocomputing, 2020, 400: 255-271. doi: 10.1016/j.neucom.2020.03.019 [27] CAO Y , LONG M , WANG J , et al. Correlation hashing network for efficient cross-modal retrieval[C]//Proceedings of the British Machine Vision Conference 2017. London: British Machine Vision Association, 2017: 1-7. [28] LI C, DENG C, LI N, et al. Self-supervised adversarial hashing networks for cross-modal retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4242-4251. -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 737
- HTML全文浏览量: 60
- PDF下载量: 7
- 被引次数: 0
