



-
摘要:
点云被广泛地用于三维物体表达,不过真实世界采集到的点云往往数据庞大,不利于传输与储存,针对点云数据冗余性问题,引入基于注意力机制的Transformer模块,提出一种基于Transformer的端到端多尺度点云几何压缩方法。将点云进行体素化,在编码端利用稀疏卷积提取特征,进行多尺度的逐步下采样,结合Transformer模块加强点空间特征感知与提取;在解码端进行对应的多尺度上采样重建,同样采用Transformer模块对有用特征进行加强与恢复,逐步细化并重建点云。与2种点云标准编码方法对比,所提方法平均获得80%和75%的BD-Rate增益;与基于深度学习的点云压缩方法对比,平均获得16%的BD-Rate增益,在相同码率点有约0.6的PSNR提升。实验结果表明:Transformer在点云压缩领域的可行性与有效性;在主观质量方面,所提方法也有明显的主观效果提升,重建的点云更接近原始点云。
-
关键词:
- 点云几何压缩 /
- Transformer /
- 注意力机制 /
- 深度学习 /
- 稀疏卷积
Abstract:Point clouds are widely used for 3D object representation, however, real-world captured point clouds often have huge data, which is unfavorable for transmission and storage. To address the redundancy problem of point cloud data, an end-to-end Transformer-based multiscale point cloud geometry compression method is proposed by introducing the Transformer module based on the attention mechanism. The point cloud is voxelized, features are extracted using sparse convolution at the encoder, multi-scale gradual downsampling is performed, and the Transformer module is combined to enhance the point-space feature perception and extraction; at the decoder, the corresponding multi-scale up-sampling is performed for reconstruction, and the Transformer module is also used to enhance and recover the useful features, and the point cloud is progressively refined and reconstructed. Compared with two standard point cloud coding methods, the proposed method obtains 80% and 75% BD-Rate gain on average; compared with the deep learning-based point cloud compression method, it obtains 16% BD-Rate gain on average, and there is about 0.6 PSNR enhancement at the same bit rate. The experimental results demonstrate the feasibility and effectiveness of Transformer in the field of point cloud compression. In terms of subjective quality, the proposed method also has significant subjective effect improvement, and the reconstructed point cloud is closer to the original point cloud.
-

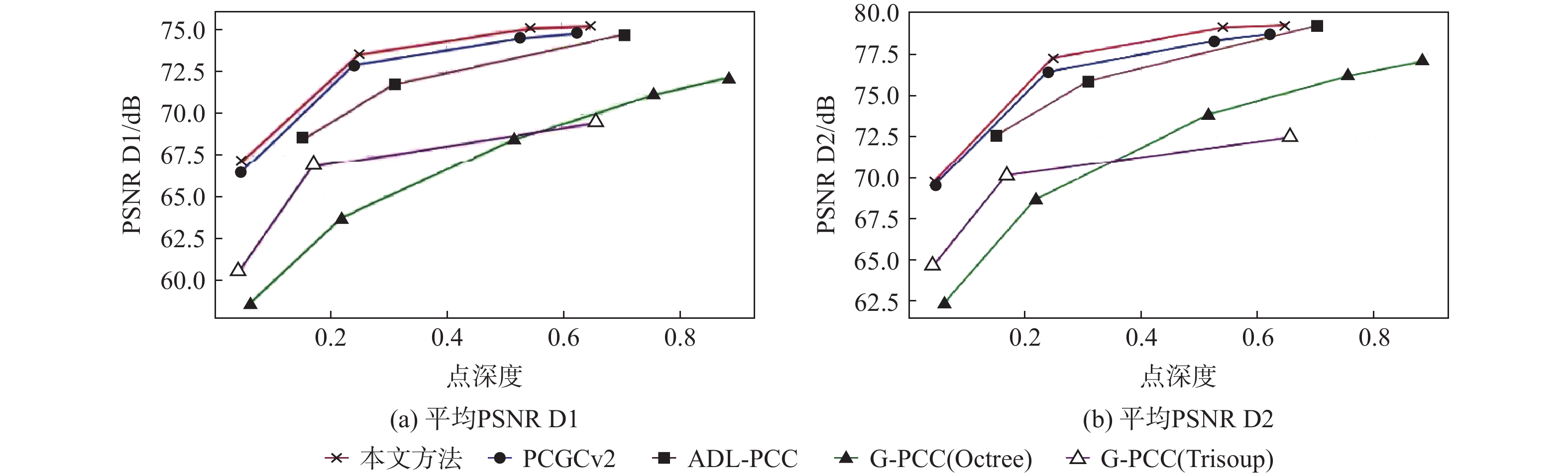
图 3 对比不同方法在客观指标 PSNR D1、PSNR D2 上的平均 RD 曲线
Figure 3. Comparison of different methods with average RD curves on objective metrics PSNR D1, PSNR D2

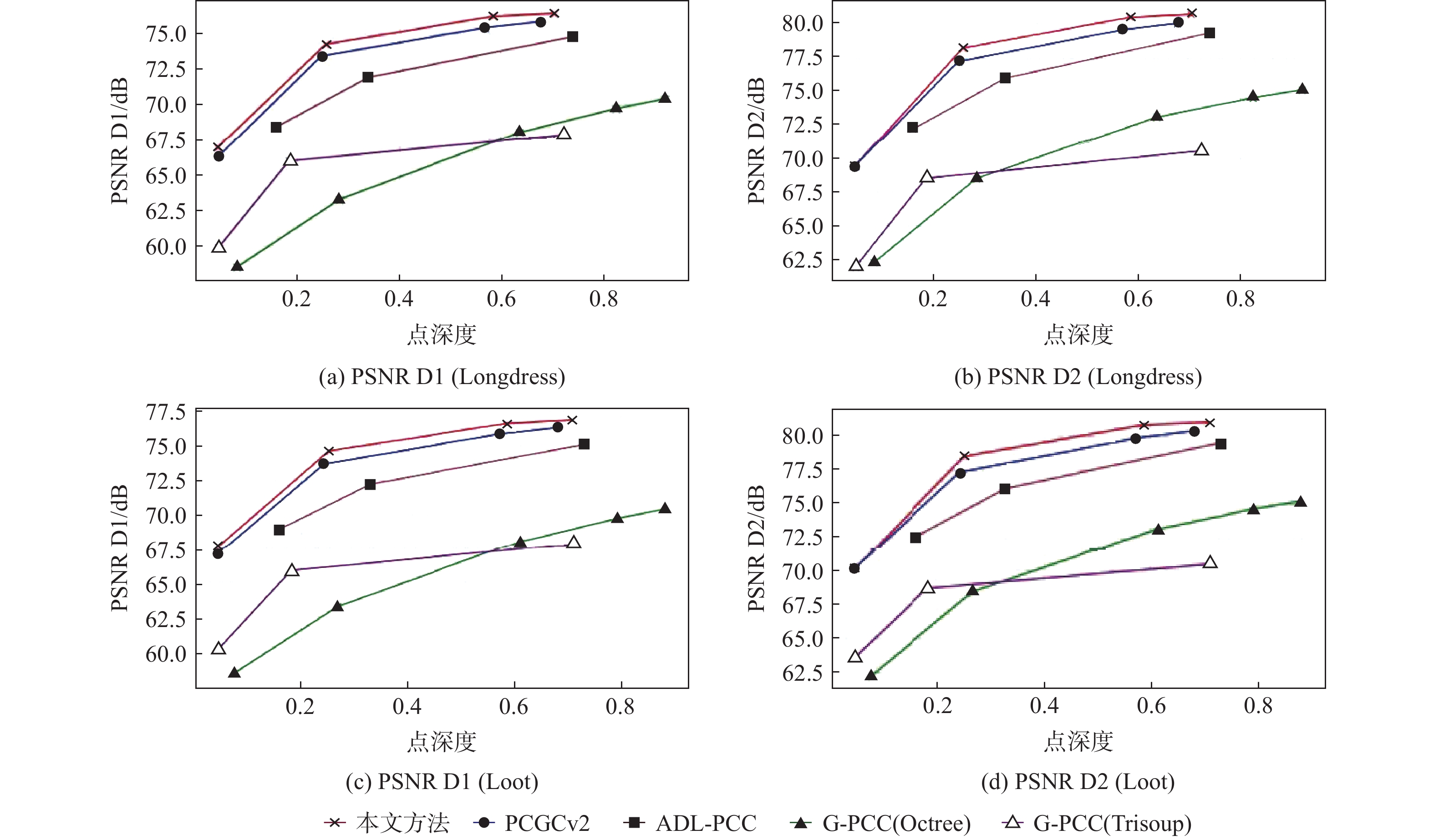
图 4 对比不同方法在单个数据集客观指标 PSNR D1、PSNR D2 上的 RD 曲线
Figure 4. Comparison of different methods with RD curves on objective metrics PSNR D1, PSNR D2 on a single dataset

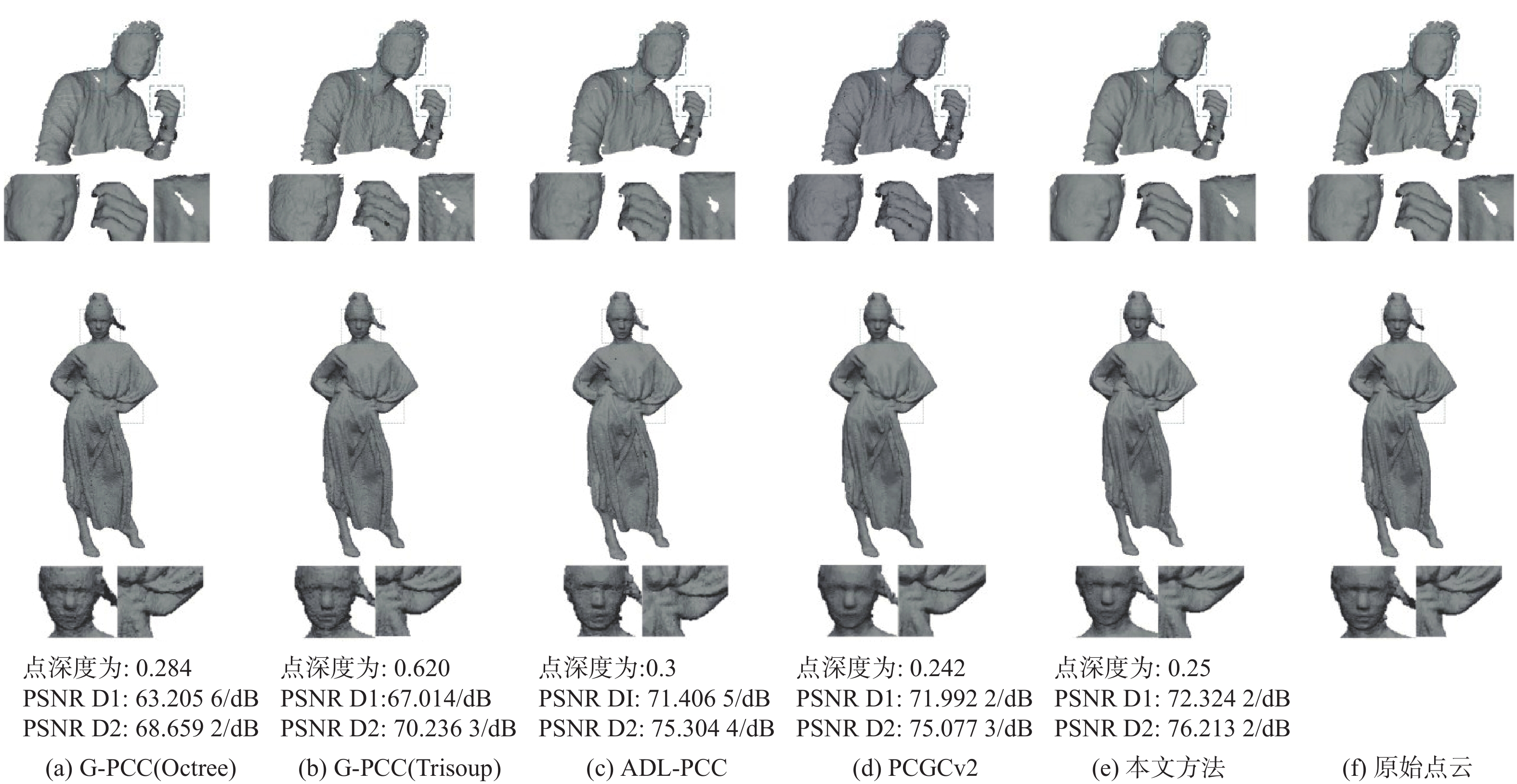
图 5 对比不同方法在单个数据集上的可视化效果
Figure 5. Comparison of visual results of different methods on a single dataset
表 1 实验所用的测试序列及点数
Table 1. Test sequences and point counts used in experiment
序列集合 测试序列 下采样倍率 点数 MVUB Andrew 279 664 David 330 797 Phil 356 258 Sarah 299 363 8iVFB Longdress 857 966 Loot 805 285 Redandblack 757 691 Soldier 0.7 569 520 Owlii Basketball_player 0.375 456 455 Dancer 0.375 402 337 Exercise 0.375 369 267 Model 0.375 375 392  下载: 导出CSV
下载: 导出CSV
表 2 不同对比方法在客观指标PSNR D1、PSNR D2上的平均BD-Rate增益
Table 2. Average BD-Rate gain on objective metrics PSNR D1, PSNR D2 for different comparison methods
% 序列集合 BD-Rate增益 G-PCC(Octree) G-PCC(Trisoup) PCGCv2 PSNR D1 PSNR D2 PSNR D1 PSNR D2 PSNR D1 PSNR D2 8iVFB −91.09 −86.90 −90.75 −90.71 −17.43 −18.11 MVUB −91.59 −87.02 −91.47 −90.91 −14.21 −15.53 Owlii −73.80 −53.85 −47.74 −43.89 −15.02 −15.42
下载: 导出CSV
表 3 不同对比方法在单个数据集客观指标PSNR D1、PSNR D2上的BD-Rate增益
Table 3. BD-Rate gain on objective metrics PSNR D1, PSNR D2 for different comparison methods on a single dataset
% 测试序列 BD-Rate增益 G-PCC(Octree) G-PCC(Trisoup) PCGCv2 PSNR D1 PSNR D2 PSNR D1 PSNR D2 PSNR D1 PSNR D2 Longdress −91.61 −88.09 −91.34 −91.84 −19.13 −17.93 Loot −92.07 −89.05 −93.20 −93.23 −27.32 −28.64 Redandblack −90.36 −86.99 −89.45 −90.66 −13.82 −15.08 Soldier −90.31 −83.45 −89.01 −87.09 −9.45 −10.78
下载: 导出CSV
表 4 对比不同方法在MVUB测试集上的平均编解码时间
Table 4. Comparison of different methods in terms of average encoding and decoding time on MVUB test set
s 方法 编码时间 解码时间 G-PCC(Octree) 0.73 0.07 G-PCC(Trisoup) 2.06 1.10 ADL-PCC 19.06 6.5 PCGCv2 0.53 0.18 本文方法 1.08 0.71
下载: 导出CSV
表 5 结构消融实验在测试序列上的平均客观指标对比
Table 5. Comparison of average objective metrics on test sequences for structural ablation experiments
网络结构 点深度 PSNR D1/dB PSNR D2/dB W/o IRN 0.253 72.623 76.147 W/o Transformer 0.239 72.903 76.389 Attention$ \times $1 0.235 73.086 76.065 Attention$ \times $2(本文方法) 0.248 73.536 77.234 Attention$ \times $3 0.246 73.238 76.228
下载: 导出CSV
-
[1] SCHWARZ S, PREDA M, BARONCINI V, et al. Emerging MPEG standards for point cloud compression[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2019, 9(1): 133-148. doi: 10.1109/JETCAS.2018.2885981 [2] GUARDA A F R, RODRIGUES N M M, PEREIRA F. Point cloud coding: Adopting a deep learning-based approach[C]//Proceedings of the Picture Coding Symposium. Piscataway: IEEE Press, 2019: 1-5. [3] WANG J, ZHU H, LIU H J, et al. Lossy Point Cloud Geometry Compression via End-to-End Learning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(12): 4909-4923. doi: 10.1109/TCSVT.2021.3051377 [4] YAN W, SHAO Y T, LIU S, et al. Deep autoencoder-based lossy geometry compression for point clouds[J/OL]. Computer Vision and Pattern Recognition, 2019. (2019-4-18)[2022-1-22]. https://doi.org/10.48550/arXiv.1905.03691. [5] WEN X Z, WANG X, HOU J H, et al. Lossy geometry compression of 3d point cloud data via an adaptive octree-guided network[C]//Proceedings of the IEEE International Conference on Multimedia and Expo. Piscataway: IEEE Press, 2020: 1-6. [6] WANG J Q, DING D D, LI Z, et al. Multiscale point cloud geometry compression[C]//Proceedings of the Data Compression Conference. Piscataway: IEEE Press, 2021: 73-82. [7] ZHAO H S, JIANG L, JIA J Y, et al. Point Transformer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 16239-16248. [8] GUO M H, CAI J X, LIU Z N, et al. PCT: Point cloud Transformer[J]. Computional Visual Media, 2021, 7(2): 187-199. [9] HUANG L L, WANG S L, WONG K, et al. Octsqueeze: Octree-structured entropy model for lidar compression[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 1310-1320. [10] QUE Z Z, LU G, XU D. Voxelcontext-net: An Octree based framework for point cloud compression[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 6038-6047. [11] NGUYEN D, QUACH M, VALENZISE G, et al. Lossless coding of point cloud geometry using a deep generative model[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(12): 4617-4629. doi: 10.1109/TCSVT.2021.3100279 [12] NGUYEN D, QUACH M, VALENZISE G, et al. Multiscale deep context modeling for lossless point cloud geometry compression[C]//Proceedings of the IEEE International Conference on Multimedia & Expo Workshops. Piscataway: IEEE Press, 2021: 1-6. [13] HUANG T X, LIU Y. 3D point cloud geometry compression on deep learning[C]//Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 890-898. [14] QUACH M, VALENZISE G, DUFAUX F. Learning convolutional Transforms for lossy point cloud geometry compression[C]// Proceedings of the IEEE International Conference on Image Processing. Piscataway: IEEE Press, 2019: 4320-4324. [15] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [16] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[J/OL]. Computer Vision and Pattern Recognition, 2021. (2021-6-3)[2022-1-22]. https://doi.org/10.48550/arXiv.2010.11929. [17] PARMAR N, VASWANI A , USZKOREIT J, et al. Image transformer[EB/OL]. (2018-6-15)[2022-1-22]. https://arxiv.org/abs/1802.05751. [18] LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 10012-10022. [19] QIU S, ANWARS, BARNES N. PU-Transformer: Point cloud upsampling transformer[C]//Proceedings of the Asian Conference on Computer Vision. Berlin: Springer, 2022: 2475-2493. [20] FU C Y, LI G, SONG R, et al. OctAttentioN: Octree-based large-scale contexts model for point cloud compression[C]//Prodeedings of the 36th AAAI conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 625-633. -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 978
- HTML全文浏览量: 120
- PDF下载量: 16
- 被引次数: 0
