



A person re-identification method for fusing convolutional attention and Transformer architecture
-
摘要:
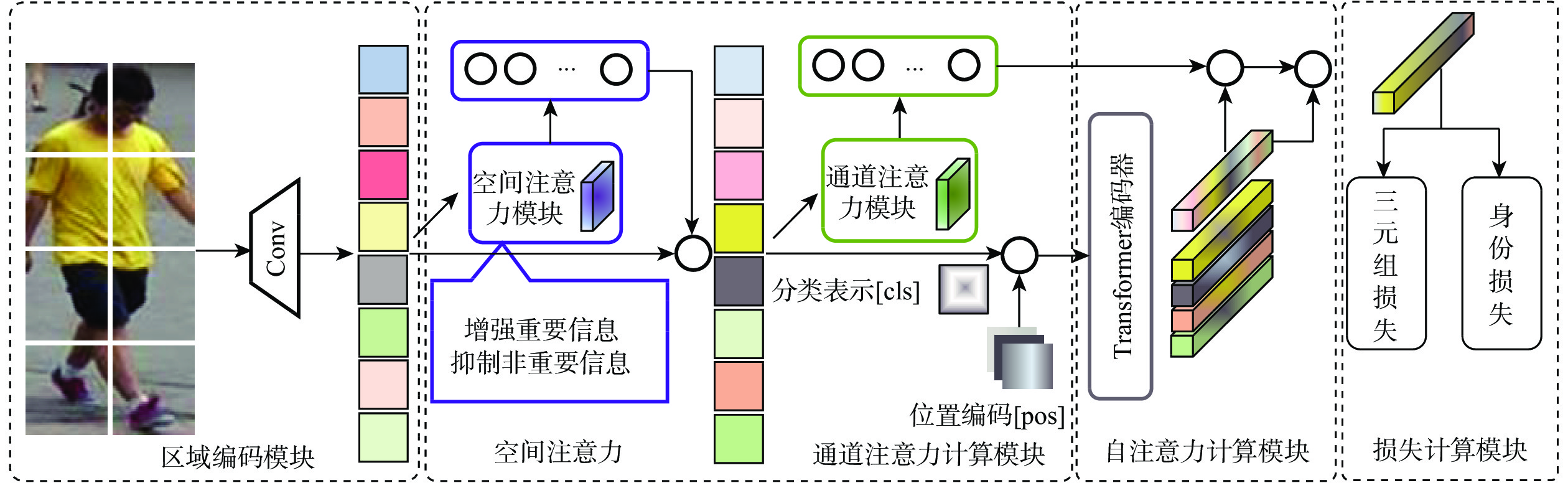
行人重识别技术是智能安防系统中的重要方法之一,为构建一个适用各种复杂场景的行人重识别模型,基于现有的卷积神经网络和Transformer模型,提出一种融合卷积注意力和Transformer(FCAT)架构的方法,以增强Transformer对局部细节信息的关注。所提方法主要将卷积空间注意力和通道注意力嵌入Transformer架构中,分别加强对图像中重要区域的关注和对重要通道特征的关注,以进一步提高Transformer架构对局部细节特征的提取能力。在3个公开行人重识别数据集上的对比消融实验证明,所提方法在非遮挡数据集上取得了与现有方法相当的结果,在遮挡数据集上的性能得到显著提升。所提方法更加轻量化,在不增加额外计算量和模型参数的情况下,推理速度得到了提升。
-
关键词:
- 行人重识别 /
- 深度学习 /
- 卷积神经网络 /
- Transformer /
- 注意力机制
Abstract:Person Re-identification technology is one of the important methods in intelligent security systems. In order to build a person re-identification model suitable for various complex scenarios, this article proposed a method of Fusing Convolutional Attention and Transformer architecture (FCAT) based on existing convolutional neural networks and Transformer models to enhance the Transformer’s attention to local detail information. This method mainly improves the transformer's ability to extract local detail features indirectly by embedding convolutional space attention and channel attention respectively to enhance the attention to important regions and important channel features in the image. Comparative ablation experiments on three publicly available pedestrian re-identification datasets demonstrate that the proposed method achieves comparable results on non-occluded datasets and significantly improves performance on occluded datasets. Additionally, the proposed model is more lightweight, leading to improved inference speed without increasing additional computational load or model parameters.
-
表 1 数据集信息
Table 1. Datasets information
数据集 数据集整体 训练集 查询集 图库集 身份数 图像数 身份数 图像数 身份数 图像数 身份数 图像数 Market-1501 1501 32668 751 12936 750 3368 750 19732 DukeMTMC-ReID 1404 36441 702 16522 702 2228 1110 17661 Occluded-Duke 1404 36441 702 15618 519 2210 1110 17661  下载: 导出CSV
下载: 导出CSV
表 2 FCAT与其他方法的性能对比结果
Table 2. Performance results of FCAT compared to other methods
模型 主干网络 方法 mAP/% Rank-1/% Market-1501 DukeMTMC Occluded-Duke Market-1501 DukeMTMC Occluded-Duke 局部区域
划分模型CNN Spindle[42] 76.9 CNN PDC[20] 63.4 84.1 CNN MGCAM[17] 74.3 83.8 CNN MGN[43] 78.4 78.4 88.7 88.7 CNN AlignedReID[19] 79.3 91.8 CNN Part Aligned[44] 63.4 20.2 81.0 28.8 CNN PGFA[40] 76.8 65.5 37.3 91.2 82.6 51.4 CNN PCB[18] 77.4 66.1 42.6 92.3 81.8 33.7 CNN PCB+RPP[18] 81.6 69.2 93.8 83.3 CNN HOReID[21] 84.9 75.6 43.8 94.2 86.9 55.1 注意力机制模型 CNN HACNN[6] 82.8 63.8 93.8 80.5 CNN MMGA[7] 87.2 78.1 95.0 89.5 CNN RGA-SC[9] 88.4 74.9 96.1 86.1 Transformer DRL-Net[45] 86.9 76.6 50.8 94.7 88.1 65.0 Transformer TransReID/B[4] 86.8 79.3 53.1 94.7 88.8 60.5 Transformer TransReID/JPM[4] 88.2 80.6 55.7 95.0 89.6 64.2 Transformer FCAT 88.4 80.8 55.9 95.1 90.2 64.5 注:其中粗体数字表示最优性能,下划线数字代表次优性能。TransReID/B表示TransReID模型的基线模型,TransReID/JPM表示基线模型附加Jigsaw Patch Module操作。
下载: 导出CSV
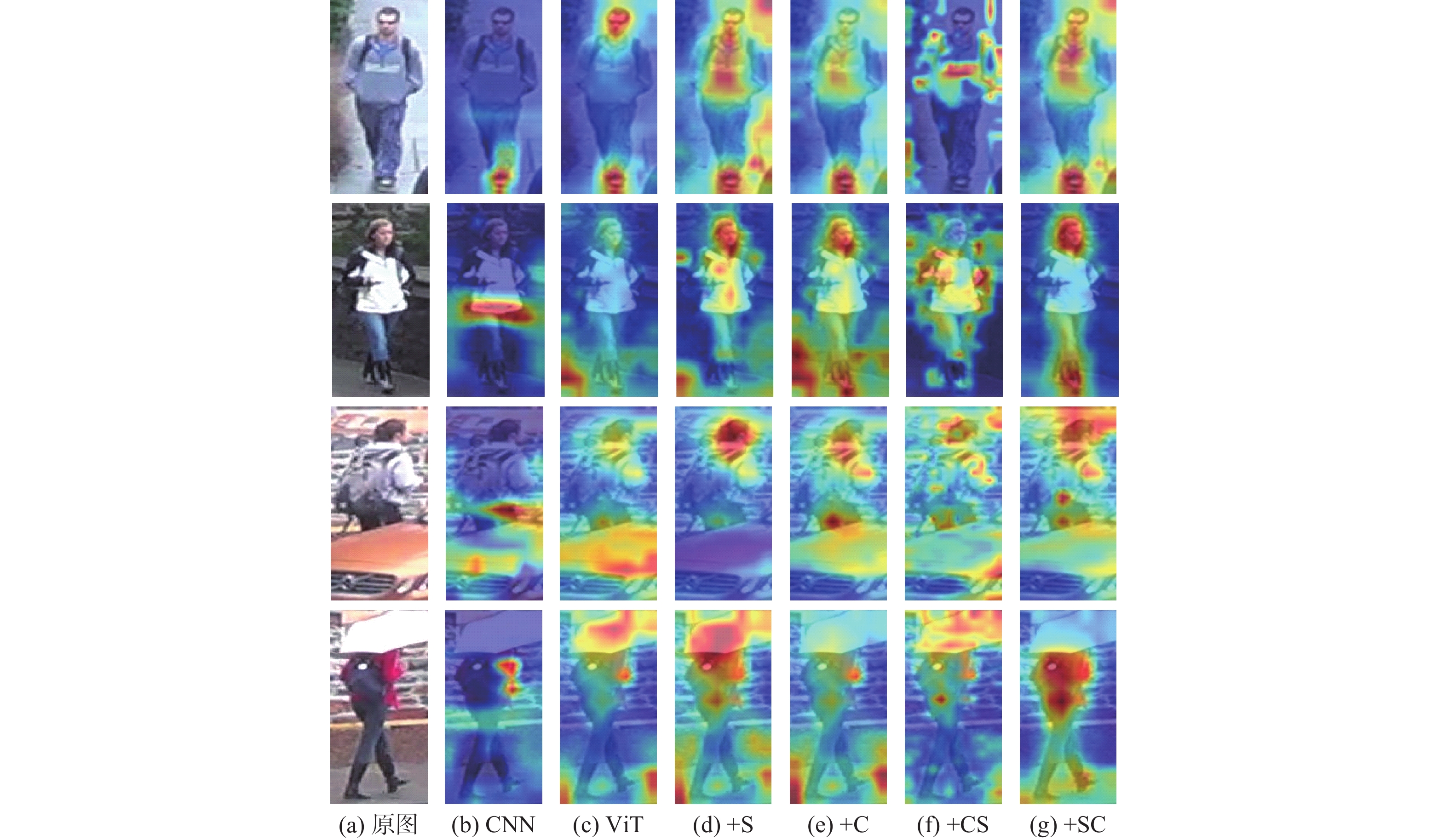
表 3 模型遮挡数据集上的消融研究
Table 3. Ablation studies on Occluded-Duke
% 方法 mAP Rank-1 HOReID 43.8 55.1 基线 53.1 60.5 基线+S 55.8 63.3 基线+C 55.5 63.3 基线+CS 55.8 63.9 基线+ SC 55.9 64.5
下载: 导出CSV
表 4 推理成本的消融研究
Table 4. Ablation studies of inference costs
方法 推理时间 计算量 模型参数量 ResNet50 1x 1x 1x 基线 0.4338x 2.7105x 3.6411x 基线+JPM 0.4595x 2.9401x 3.9427x 基线+S 0.4212x 2.7105x 3.6411x 基线+C 0.3955x 2.7106x 3.6442x 基线+ SC 0.4159x 2.7106x 3.6442x
下载: 导出CSV
-
[1] YE M, SHEN J B, LIN G J, et al. Deep learning for person re-identification: A survey and outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 2872-2893. doi: 10.1109/TPAMI.2021.3054775 [2] ZHENG L, YANG Y, HAUPTMANN A G. Person re-identification: Past, present and future[EB/OL]. (2016-10-10) [2022-05-20]. https://arxiv.org/abs/1610.02984.pdf. [3] LUO H, GU Y Z, LIAO X Y, et al. Bag of tricks and a strong baseline for deep person re-identification[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2020: 1487-1495. [4] HE S T, LUO H, WANG P C, et al. TransReID: Transformer-based object re-identification[C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2022: 14993-15002. [5] PARK H, HAM B. Relation network for person re-identification[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11839-11847. doi: 10.1609/aaai.v34i07.6857 [6] LI W, ZHU X T, GONG S G. Harmonious attention network for person re-identification[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 2285-2294. [7] CAI H L, WANG Z G, CHENG J X. Multi-scale body-part mask guided attention for person re-identification[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2020: 1555-1564. [8] 张晓伟, 吕明强, 李慧. 基于局部语义特征不变性的跨域行人重识别[J]. 北京航空航天大学学报, 2020, 46(9): 1682-1690. doi: 10.13700/j.bh.1001-5965.2020.0072ZHANG X W, LYU M Q, LI H. Cross-domain person re-identification based on partial semantic feature invariance[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(9): 1682-1690 (in Chinese). doi: 10.13700/j.bh.1001-5965.2020.0072 [9] ZHANG Z Z, LAN C L, ZENG W J, et al. Relation-aware global attention for person re-identification[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 3183-3192. [10] CHEN G Y, GU T P, LU J W, et al. Person re-identification via attention pyramid[J]. IEEE Transactions on Image Processing, 2021, 30: 7663-7676. doi: 10.1109/TIP.2021.3107211 [11] 孙义博, 张文靖, 王蓉, 等. 基于通道注意力机制的行人重识别方法[J]. 北京航空航天大学学报, 2022, 48(5): 881-889. doi: 10.13700/j.bh.1001-5965.2020.0684SUN Y B, ZHANG W J, WANG R, et al. Pedestrian re-identification method based on channel attention mechanism[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(5): 881-889 (in Chinese). doi: 10.13700/j.bh.1001-5965.2020.0684 [12] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [13] GALASSI A, LIPPI M, TORRONI P. Attention in natural language processing[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(10): 4291-4308. [14] LIU Y, ZHANG Y, WANG Y X, et al. A survey of visual transformers[J]. IEEE Transaction on Neural Networks and Learning Systems, 2023. [15] KHAN S, NASEER M, HAYAT M, et al. Transformers in vision: A survey[J]. ACM Computing Surveys, 2022, 54(10): 1-41. [16] HADJI I, WILDES R P. What do we understand about convolutional networks? [EB/OL]. (2018-03-23) [2022-05-20]. https://arxiv.org/abs/1803.08834.pdf. [17] SONG C F, HUANG Y, OUYANG W L, et al. Mask-guided contrastive attention model for person re-identification[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 1179-1188. [18] SUN Y F, ZHENG L, YANG Y, et al. Beyond part models: Person retrieval with refined part pooling (and A strong convolutional baseline)[C]// Computer Vision - ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part IV. New York: ACM, 2018: 501-518. [19] ZHANG X, LUO H, FAN X, et al. AlignedReID: Surpassing human-level performance in person re-identification[EB/OL]. (2017-11-22) [2022-05-20].https://arxiv.org/abs/1711.08184.pdf. [20] SU C, LI J N, ZHANG S L, et al. Pose-driven deep convolutional model for person re-identification[C]// 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 3980-3989. [21] WANG G A, YANG S, LIU H Y, et al. High-order information matters: learning relation and topology for occluded person re-identification[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 6448-6457. [22] XU J, ZHAO R, ZHU F, et al. Attention-aware compositional network for person re-identification[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 2119-2128. [23] GUO M H, XU T X, LIU J J, et al. Attention mechanisms in computer vision: a survey[J]. Computational Visual Media, 2022, 8(3): 331-368. doi: 10.1007/s41095-022-0271-y [24] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision. Cham: Springer, 2020: 213-229. [25] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. (2020-10-22) [2022-05-20]. https://arxiv.org/abs/2010.11929.pdf. [26] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]// 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2022: 9992-10002. [27] WU B C, XU C F, DAI X L, et al. Visual transformers: Token-based image representation and processing for computer vision[EB/OL]. (2020-06-05) [2022-05-21]. https://arxiv.org/abs/2006.03677.pdf. [28] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 16514-16524. [29] TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention[EB/OL]. (2020-12-23) [2022-05-21].https://arxiv.org/abs/2012.12877.pdf. [30] D’ASCOLI S, TOUVRON H, LEAVITT M L, et al. ConViT: Improving vision transformers with soft convolutional inductive biases[J]. Journal of Statistical Mechanics:Theory and Experiment, 2022, 2022(11): 114005. doi: 10.1088/1742-5468/ac9830 [31] ZHANG Q L, YANG Y B. ResT: an efficient transformer for visual recognition[EB/OL]. (2021-05-28) [2022-05-21]. https://arxiv.org/abs/2105.13677.pdf. [32] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]//European Conference on Computer Vision. Cham: Springer, 2018: 3-19. [33] PARK J, WOO S, LEE J Y, et al. BAM: Bottleneck attention module[EB/OL]. (2018-07-17) [2022-05-21]. https://arxiv.org/abs/1807.06514.pdf. [34] LI X, WANG W H, HU X L, et al. Selective kernel networks[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 510-519. [35] YAO H T, ZHANG S L, HONG R C, et al. Deep representation learning with part loss for person re-identification[J]. IEEE Transactions on Image Processing, 2019, 28(6): 2860-2871. doi: 10.1109/TIP.2019.2891888 [36] ZHANG Z Z, LAN C L, ZENG W J, et al. Densely semantically aligned person re-identification[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 667-676. [37] YE M, LAN X Y, WANG Z, et al. Bi-directional center-constrained top-ranking for visible thermal person re-identification[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 407-419. doi: 10.1109/TIFS.2019.2921454 [38] ZHENG L, SHEN L Y, TIAN L, et al. Scalable person re-identification: A benchmark[C]// 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2016: 1116-1124. [39] ZHENG Z D, ZHENG L, YANG Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro[C]// 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 3774-3782. [40] MIAO J X, WU Y, LIU P, et al. Pose-guided feature alignment for occluded person re-identification[C]// 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 542-551. [41] WANG X G, DORETTO G, SEBASTIAN T, et al. Shape and appearance context modeling[C]// 2007 IEEE 11th International Conference on Computer Vision. Piscataway: IEEE Press, 2007: 1-8. [42] ZHAO H Y, TIAN M Q, SUN S Y, et al. Spindle net: Person re-identification with human body region guided feature decomposition and fusion[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 907-915. [43] WANG G S, YUAN Y F, CHEN X, et al. Learning discriminative features with multiple granularities for person re-identification[C]// Proceedings of the 26th ACM international conference on Multimedia. New York: ACM, 2018: 274-282. [44] ZHAO L M, LI X, ZHUANG Y T, et al. Deeply-learned part-aligned representations for person re-identification[C]// 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 3239-3248. [45] JIA M X, CHENG X H, LU S J, et al. Learning disentangled representation implicitly via transformer for occluded person re-identification[J]. IEEE Transactions on Multimedia, 2023, 25: 1294-1305. doi: 10.1109/TMM.2022.3141267 -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 976
- HTML全文浏览量: 102
- PDF下载量: 18
- 被引次数: 0
