



-
摘要:
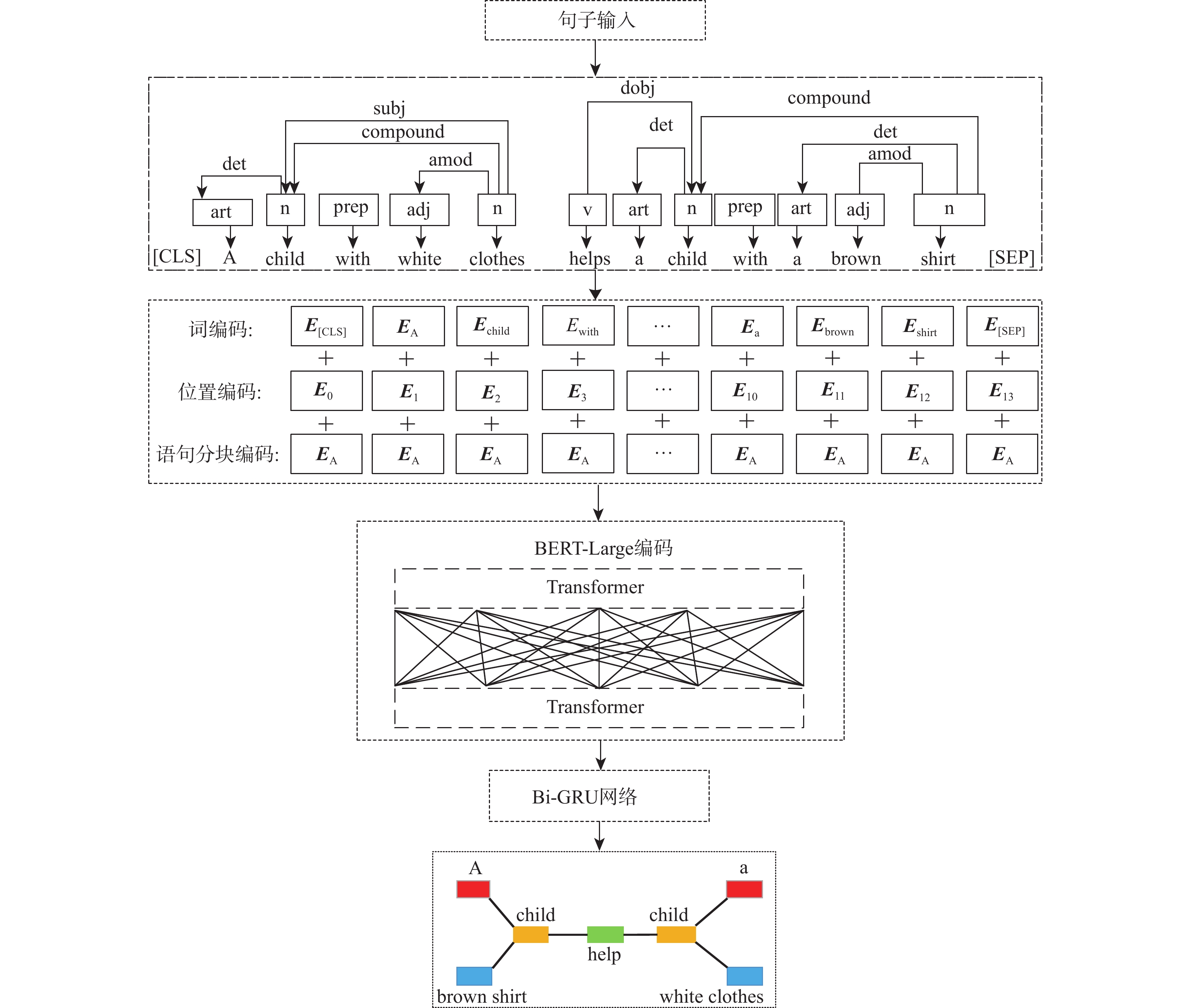
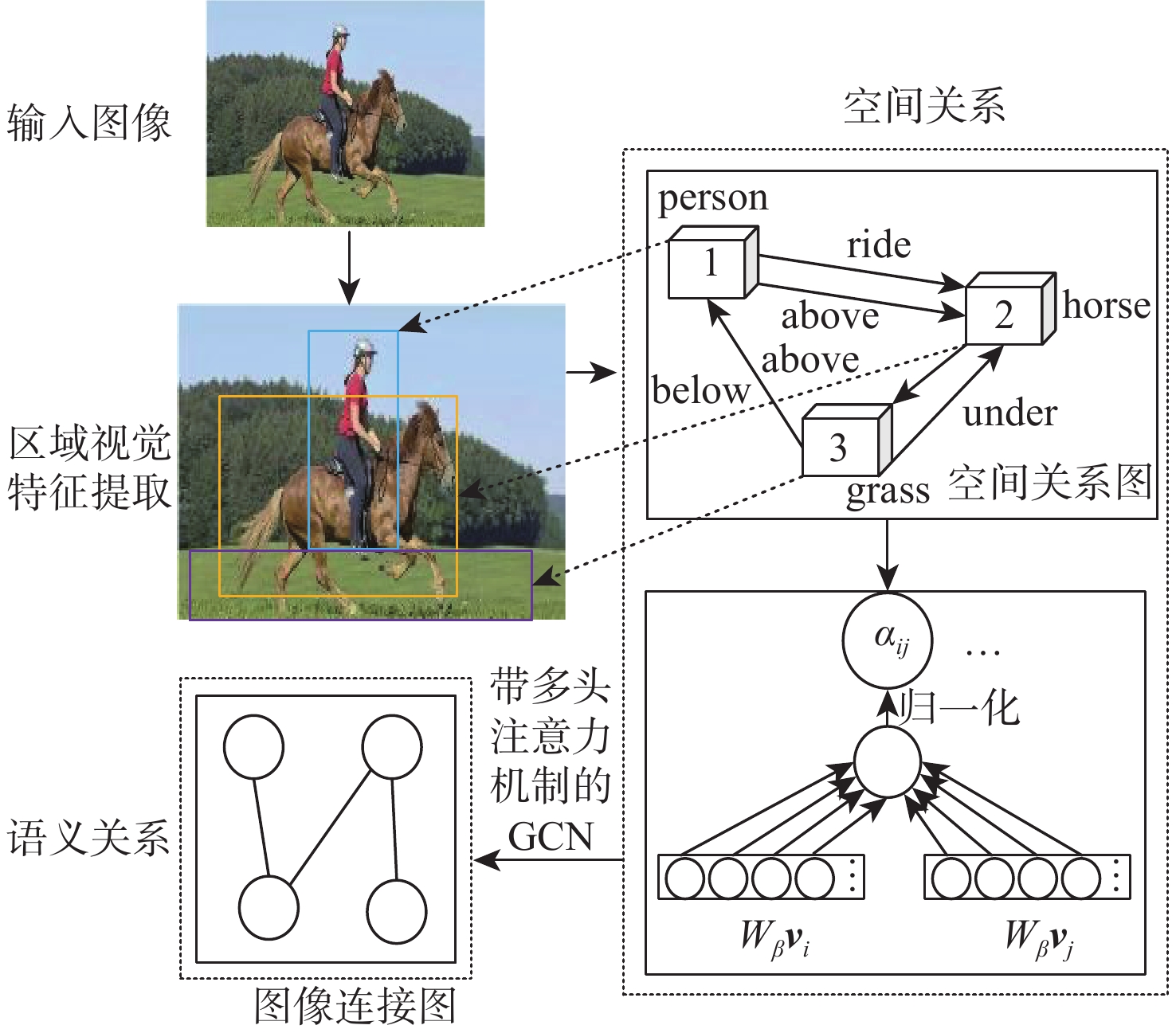
如何高效挖掘多模态数据间隐藏的语义关联是当前多模态知识抽取的重点任务之一,为更细粒度地挖掘图像与文本数据间关系,提出了一种多级关系分析与挖掘(MRAM)方法,引入BERT-Large模型,提取文本特征构建文本连接图,利用Faster-RCNN网络提取图像特征来学习空间位置关系和语义关系并构建图像连接图,进而完成单模态内部语义关系计算,在此基础上,使用节点切分方法和带多头注意力机制的图卷积网络(GCN-MA)进行局部和全局的图文关系融合。此外,为提升关系挖掘效率,采用了基于注意力机制的连边权重剪枝策略,用以增强重要分支表示,减少冗余信息干扰。在公开的Flickr30K、MSCOCO-1K、MSCOCO-5K数据集上进行方法实验,并与11种方法进行实验结果的对比分析,所提方法在Flickr30K上的平均召回率提高了0.97%和0.57%,在MSCOCO-1K上的平均召回率提高了0.93%和0.63%,在MSCOCO-5K上的平均召回率提高了0.37%和0.93%,实验结果验证了所提方法的有效性。
Abstract:How to efficiently mine the hidden semantic association between multi-modal data is one of the key tasks of multi-modal knowledge extraction. In order to mine fine-grained relation between image and text, multilevel relation analysis and mining method of image-text (MRAM) was proposed. BERT-Large (bidirectional encoder representation from transformers-large) extracted text feature and constructed text connection graphs, while the Faster-RCNN network extracted image feature to learn spatial position relation and semantic relation, then constructed image connection graphs, so as to complete the calculation of single-modal internal semantic relation. The node segmentation method and graph convolutional network with multi-head attention (GCN-MA) fused local and global relation of text and image. To improve the efficiency of relation mining, edge weight pruning strategy based on the attention mechanism strengthened the representation of important branches, and reduced the interference of redundant information. The proposed method was tested on Flickr30K, MSCOCO-1K and MSCOCO-5K datasets, and was compared with 11 methods. The average recall rate on Flickr30K was increased by 0.97% and 0.57%, the average recall rate on MSCOCO-1K was increased by 0.93% and 0.63%, and the average recall rate on MSCOCO-5K was increased by 0.37% and 0.93%. Experimental results verify the effectiveness of the proposed method.
-
表 1 数据集统计表
Table 1. Statistical table of dataset
数据集 划分 图像 文本 Flickr30K 训练集 29783 148915 验证集 1000 5000 测试集 1000 5000 MSCOCO-1K 训练集 121287 606435 验证集 1000 5000 测试集 1000 5000 MSCOCO-5K 训练集 113287 566435 验证集 5000 25000 测试集 5000 25000  下载: 导出CSV
下载: 导出CSV
表 2 实验结果分析
Table 2. Analysis of experimental results
% 方法 R1 R5 R10 以文索图 以图索文 以文索图 以图索文 以文索图 以图索文 Flickr-
30KMS-
COCO-
1KMS-
COCO-
5KFlickr-
30KMS-
COCO-
1KMS-
COCO-
5KFlickr-
30KMS-
COCO-
1KMS-
COCO-
5KFlickr-
30KMS-
COCO-
1KMS-
COCO-
5KFlickr-
30KMS-
COCO-
1KMS-
COCO-
5KFlickr-
30KMS-
COCO-
1KMS-
COCO-
5Km-CNN[2] 33.6 42.8 26.2 32.6 64.1 73.1 56.3 68.6 74.9 84.1 69.6 82.8 VSE++[31] 52.9 64.6 41.3 39.6 52.0 30.3 80.5 90.0 71.1 70.1 84.3 59.4 87.2 95.7 81.2 79.5 92.0 72.4 GXN[32] 68.5 42.0 56.6 31.7 97.9 84.7 94.3 74.6 SCO[33] 55.5 69.9 42.8 41.1 56.7 33.1 82.0 92.9 72.3 70.5 87.5 62.9 89.3 97.5 83.0 80.1 94.8 75.5 SCAN[10] 67.4 72.7 50.4 48.6 58.8 38.6 90.3 94.8 82.2 77.7 88.4 69.3 95.8 98.4 90.0 85.2 94.8 80.4 VSRN[16] 70.4 74.0 53.0 53.0 60.8 40.5 89.2 94.3 81.1 77.9 88.4 70.6 93.7 97.8 89.4 85.7 94.1 81.1 CAMP[17] 68.1 72.3 50.1 51.5 58.5 39.0 89.7 94.8 82.1 77.1 87.9 68.9 95.2 98.3 89.7 85.3 95.0 80.2 SGM[21] 71.8 73.4 50.0 53.5 57.5 35.3 91.7 93.8 79.3 79.6 87.3 64.9 95.5 97.8 87.9 86.5 94.3 76.5 多层
语义[35]69.6 74.5 61.5 60.1 91.2 95.1 78.8 87.4 97.1 97.8 88.4 96.5 CANN[20] 70.1 75.5 52.5 52.8 61.3 41.2 91.6 95.4 83.3 79.0 89.7 70.3 97.2 98.5 90.9 87.9 95.2 82.9 MMCA[34] 74.2 74.8 54.0 54.8 61.6 38.7 92.8 95.6 82.5 81.4 89.8 69.7 96.4 97.7 90.7 87.8 95.0 80.8 MRAM 76.2 76.7 55.0 59.7 62.8 42.1 93.7 96.9 83.2 82.5 90.5 72.5 97.1 98.8 91.0 89.0 96.3 82.9
下载: 导出CSV
表 3 消融实验表
Table 3. Table of ablation experiments
% 方法 R1 R10 以文索图 以图索文 以文索图 以图索文 Flickr30K MSCOCO-1K Flickr30K MSCOCO-1K Flickr30K MSCOCO-1K Flickr30K MSCOCO-1K w/o预训练的BERT-Large模型 74.9 75.9 58.1 60.4 95.4 98.1 87.6 94.2 w/o基于多头注意力的空间关系 74.5 74.8 58.7 61.4 95.7 97.1 88.1 95.1 w/o全局对应关系 68.6 68.6 55.4 58.1 95.7 97.2 86.8 93.4 w/o局部对应关系中的节点切分方法 75.8 76.1 57.0 61.9 96.7 97.9 88.8 95.6 w/o全局对应关系中的多头注意力 75.2 75.2 58.7 61.3 96.3 97.5 88.1 94.9 全局对应关系w/2GCN 72.1 73.3 55.6 59.2 92.6 95.9 85.1 93.2 w/o基于注意力机制的连边权重剪枝策略 74.6 75.4 57.3 61.4 95.0 97.3 86.9 95.1 MRAM方法 76.2 76.7 59.7 62.8 97.1 98.8 89.0 96.3
下载: 导出CSV
-
[1] FROME A, CORRADO G S, SHLENS J, et al. Devise: A deep visual-semantic embedding model//Proceeding of the 26th International Conference on Advances in Neural Information Proceeding Systems. New York: ACM, 2013, 26: 2121-2129. [2] MA L, LU Z D, SHANG L F, et al. Multimodal convolutional neural networks for matching image and sentence[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2015: 2623-2631. [3] WEHRMANN J, BARROS R C. Bidirectional retrieval made simple[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7718-7726. [4] WANG T, XU X, YANG Y, et al. Matching images and text with multi-modal tensor fusion and re-ranking[C]//Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 12-20. [5] WANG P, WU Q, CAO J W, et al. Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 1960-1968. [6] MAFLA A, DEY S, BITEN A F, et al. Multi-modal reasoning graph for scene-text based fine-grained image classification and retrieval[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2021: 4022-4032. [7] LIU S, QIAN S S, GUAN Y, et al. Joint-modal distribution-based similarity hashing for large-scale unsupervised deep cross-modal retrieval[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 1379-1388. [8] DONG X F, ZHANG H X, DONG X, et al. Iterative graph attention memory network for cross-modal retrieval[J]. Knowledge-Based Systems, 2021, 226: 107138. [9] KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 3128-3137. [10] LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]//Proceedings of the European Conference on Computer Vision. Berkin: Springer, 2018: 212-228. [11] HUANG Y, WANG W, WANG L. Instance-aware image and sentence matching with selective multimodal LSTM[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 7254-7262. [12] YAO T, PAN Y W, LI Y H, et al. Exploring visual relationship for image captioning[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 711-727. [13] HOU J Y, WU X X, QI Y Y, et al. Relational reasoning using prior knowledge for visual captioning [EB/OL]. (2019-06-04)[2022-08-20]. http://arxiv.org/abs/1906.01290. [14] WANG Y X, YANG H, QIAN X M, et al. Position focused attention network for image-text matching [EB/OL]. (2019-07-23)[2022-08-20]. http://arxiv.org/abs/1907.09748. [15] CHEN H, DING G G, LIU X D, et al. IMRAM: Iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscatawa: IEEE Press, 2020: 12652-12660. [16] LI K P, ZHANG Y L, Li K, et al. Visual semantic reasoning for image-text matching[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 4653-4661. [17] WANG Z H, LIU X H, LI H S, et al. CAMP: Cross-modal adaptive message passing for text-image retrieval[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 5764-5773. [18] YANG Z Q, QIN Z C, YU J, et al. Scene graph reasoning with prior visual relationship for visual question answering[EB/OL]. (2019-08-21)[2020-08-20]. http://arxiv.org/abs/1812.09681. [19] SONG Y, SOLEYMANI M. Polysemous visual-semantic embedding for cross-modal retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 1979-1988. [20] ZHANG Q, LEI Z, ZHANG Z, et al. Context-aware attention network for image-text retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 3533-3542. [21] WANG S J, WANG R P, YAO Z W, et al. Cross-modal scene graph matching for relationship-aware image-text retrieval[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2020: 1497-1506. [22] ZHENG Z D, ZHENG L, GARRETT M, et al. Dual-path convolutional image-text embeddings with instance loss[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2020, 16(2): 51. [23] LI Y, ZHANG D, MU Y. Visual-semantic matching by exploring high-order attention and distraction[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 12783-12792. [24] DONG X Z, LONG C J, XU W J, et al. Dual graph convolutional networks with transformer and curriculum learning for image captioning[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 2615-2624. [25] DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24)[2022-08-20]. http://arxiv.org/abs/1810.04805. [26] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [27] KRISHNA R, ZHU Y K, GROTH O, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. doi: 10.1007/s11263-016-0981-7 [28] LI L J, GAN Z, CHENG Y, et al. Relation-aware graph attention network for visual question answering[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 10312-10321. [29] YOUNG P, LAI A, HODOSH M, et al. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67-78. doi: 10.1162/tacl_a_00166 [30] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755. [31] FAGHRI F, FLEET D J, KIROS J R, et al. Vse++: Improving visual-semantic embeddings with hard negatives[EB/OL]. (2017-07-18)[2022-08-20]. http://arxiv.org/abs/1707.05612. [32] GU J X, CAI J F, JOTY S R, et al. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7181-7189. [33] HUANG Y, WU Q, SONG C F, et al. Learning semantic concepts and order for image and sentence matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6163-6171. [34] WEI X, ZHANG T Z, LI Y, et al. Multi-modality cross attention network for image and sentence matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10938-10947. [35] 杜锦丰, 王海荣, 李明亮, 等. 多层语义对齐的跨模态检索方法研究[J]. 郑州大学学报(理学版), 2021, 53(4): 83-88.DU J F, WANG H R, LI M L, et al. Research on cross-modal retrieval method based on multi-layer semantic alignment[J]. Journal of Zhengzhou University (Natural Science Edition), 2021, 53(4): 83-88(in Chinese). -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 846
- HTML全文浏览量: 87
- PDF下载量: 10
- 被引次数: 0
