| Citation: | LI Chao, ZHAO Changhai, YAN Haihua, et al. A fault tolerant high-performance reduction framework in complex environment[J]. Journal of Beijing University of Aeronautics and Astronautics, 2018, 44(10): 2115-2124. doi: 10.13700/j.bh.1001-5965.2017.0786(in Chinese)

|
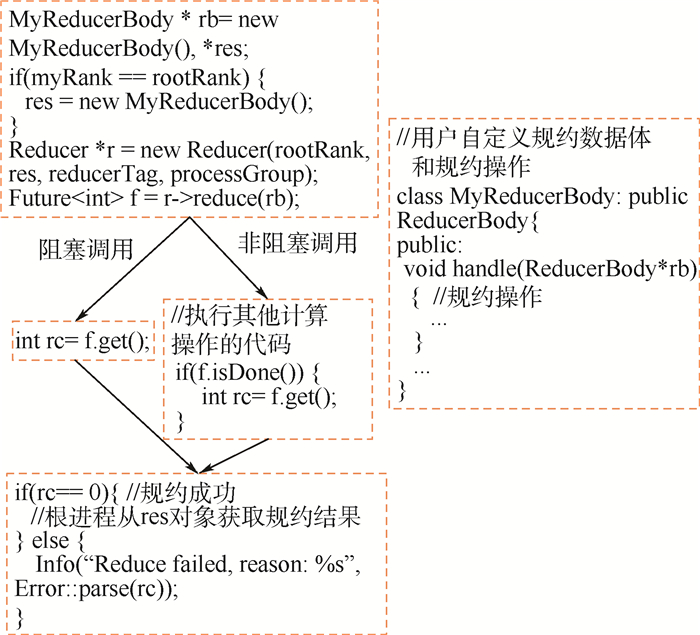
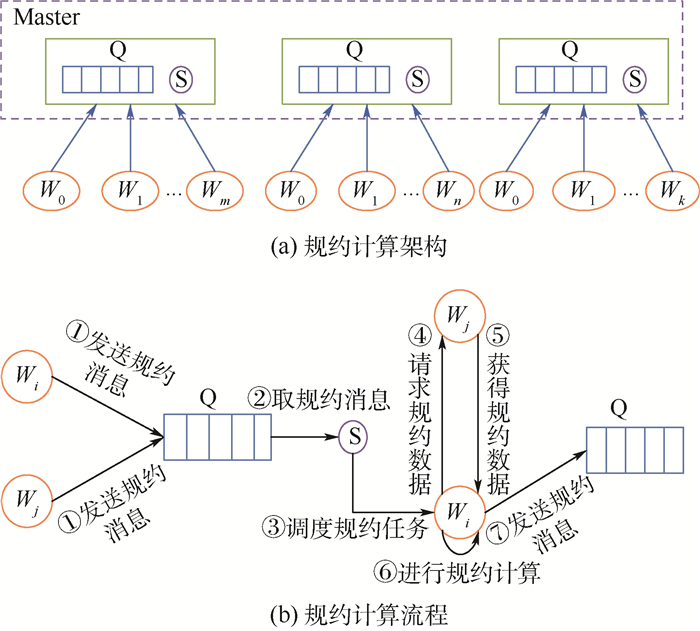
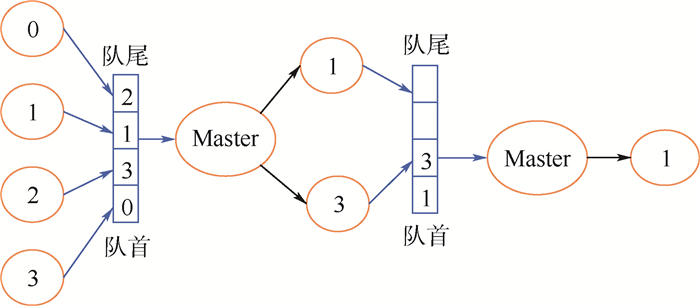
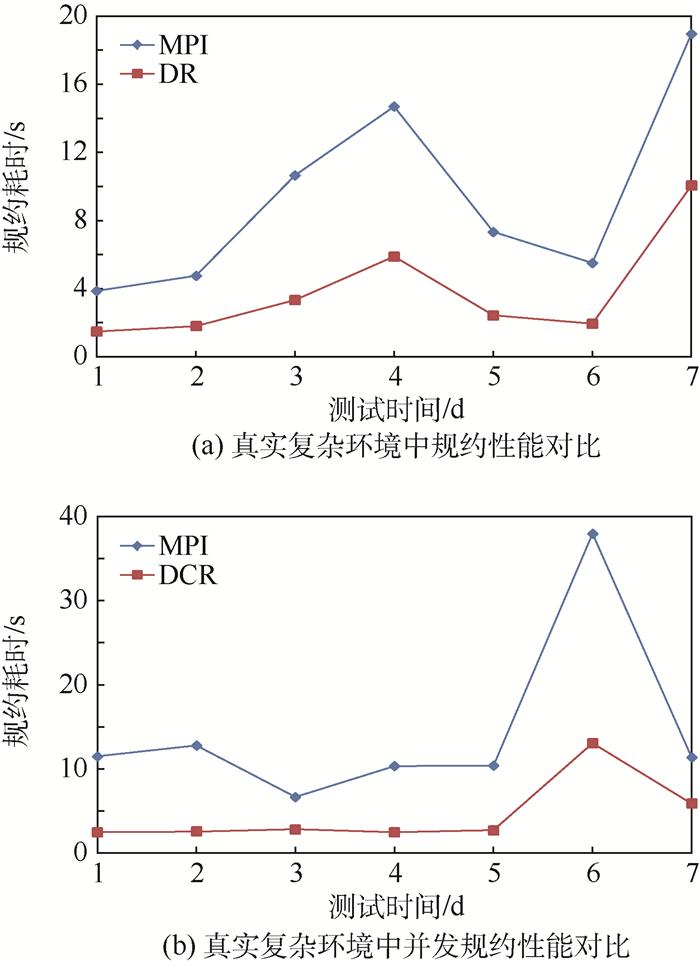
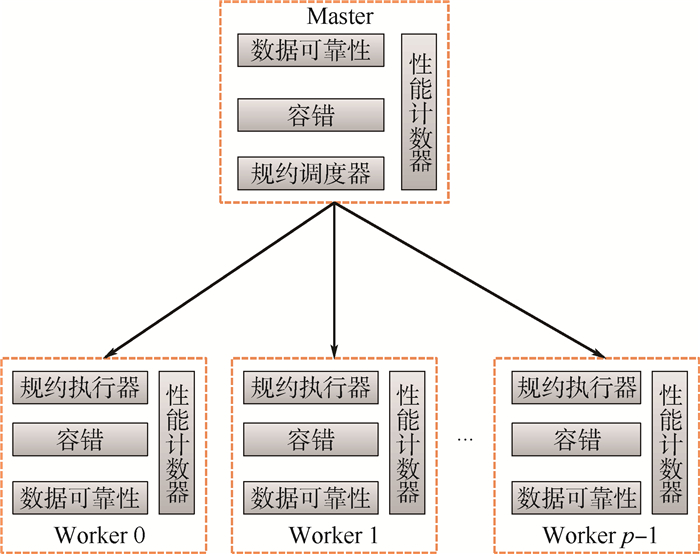
Reduction is one of the most commonly used collective communication operations for parallel applications. There are two problems for the existing reduction algorithms:First, they cannot adapt to complex environment. When interferences appear in computing environment, the efficiency of reduction degrades significantly. Second, they are not fault tolerant. The reduction operation is interrupted when a node failure occurs. To solve these problems, this paper proposes a task-based parallel high-performance distributed reduction framework. Firstly, each reduction operation is divided into a series of independent computing tasks. The task scheduler is adopted to guarantee that ready tasks will take precedence in execution and each task will be scheduled to the computing node with better performance. Thus, the side effect of slow nodes on the whole efficiency can be reduced. Secondly, based on the reliability storage for reduction data and fault detecting mechanism, fault tolerance can be implemented in tasks without stopping the application. The experimental results in complex environment show that the distributed reduction framework promises high availability and, compared with the existing reduction algorithm, the reduction performance and concurrent reduction performance of distributed reduction framework are improved by 2.2 times and 4 times, respectively.

| [1] |
GROPP W, LUSK E, DOSS N, et al.A high-performance, portable implementation of the MPI message passing interface standard[J].Parallel Computing, 1996, 22(6):789-828. doi: 10.1016/0167-8191(96)00024-5
|
| [2] |
RABENSEIFNER R.Automatic MPI counter profiling of all users: First results on a CRAY T3E 900-512[C]//Proceedings of the Message Passing Interface Developer's and User's Conference.Piscataway, NJ: IEEE Press, 1999: 77-85
|
| [3] |
CHAN W E, HEIMLICH F M, PURAKAYASTHA A, et al.On optimizing collective communication[C]//Proceedings of the IEEE International Conference on Cluster Computing.Piscataway, NJ: IEEE Press, 2004: 145-155. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1392612
|
| [4] |
GROPP W, LUSK E.Users guide for mpich, a portable implementation of MPI[J].Office of Scientific & Technical Information Technical Reports, 1996, 1996(17):2096-2097. http://cn.bing.com/academic/profile?id=64fad27e4303ac564329122091eadcbb&encoded=0&v=paper_preview&mkt=zh-cn
|
| [5] |
THAKUR R, RABENSEIFNER R, GROPP W.Optimization of collective communication operations in MPICH[J].International Journal of High Performance Computing Applications, 2005, 19(1):49-66. http://cn.bing.com/academic/profile?id=79fa16e26fbe582c2633beae0863758d&encoded=0&v=paper_preview&mkt=zh-cn
|
| [6] |
HUSBANDS P, HOE J C.MPI-StarT: Delivering network performance to numerical applications[C]//Proceedings of the ACM/IEEE Conference on Supercomputing.Piscataway, NJ: IEEE Press, 1998: 1-15. http://ieeexplore.ieee.org/document/1437304/
|
| [7] |
VADHIYAR S S, FAGG E G, DONGARRA J.Automatically tuned collective communications[C]//Proceedings of the ACM/IEEE Conference on Supercomputing.Piscataway, NJ: IEEE Press, 2000: 3-13. http://dl.acm.org/citation.cfm?id=370055
|
| [8] |
GONG Y, HE B, ZHONG J.An overview of CMPI:Network performance aware MPI in the cloud[J].ACM SIGPLAN Notices, 2012, 47(8):297-298. doi: 10.1145/2370036
|
| [9] |
GONG Y, HE B, ZHONG J.Network performance aware MPI collective communication operations in the cloud[J].IEEE Transactions on Parallel and Distributed Systems, 2015, 26(11):3079-3089. doi: 10.1109/TPDS.2013.96
|
| [10] |
MAKPAISIT P, ICHIKAWA K, UTHAYOPAS P, et al.MPI_reduce algorithm for open flow-enabled network[C]//Proceedings of the IEEE International Symposium on Communications and Information Technologies.Piscataway, NJ: IEEE Press, 2015: 261-264. http://ieeexplore.ieee.org/document/7458357/
|
| [11] |
HASANOV K, LASTOVETSKY A.Hierarchical optimization of MPI reduce algorithms[J].Lecture Notes in Computer Science, 2015, 9251:21-34. doi: 10.1007/978-3-319-21909-7
|
| [12] |
KIELMANN T, HOFMAN R F H, BAl H E, et al.MagPIe:MPI's collective communication operations for clustered wide area systems[J].ACM SIGPLAN Notices, 1999, 34(8):131-140. doi: 10.1145/329366
|
| [13] |
HEIEN E, KONDO D, GAINARU A, et al.Modeling and tolerating heterogeneous failures in large parallel systems[C]//Proceedings of International Conference for High Performance Computing, Networking, Storage and Analysis.Piscataway, NJ: IEEE Press, 2001: 1-11. doi: 10.1145/2063384.2063444
|
| [14] |
SCHROEDER B, GIBSON G.Understanding failures in petascale computers[C]//Journal of Physics: Conference Series.Philadelphia, PA: IOP Publishing, 2007: 12-22. http://adsabs.harvard.edu/abs/2007JPhCS..78a2022S
|
| [15] |
ELNOZAHY E, ALVISI L, WANG Y, et al.A survey of rollback-recovery protocols in message-passing systems[J].ACM Computing Surveys(CSUR), 2002, 34(3):375-408. doi: 10.1145/568522.568525
|
| [16] |
BRONEVETSKY G, MARQUES D, PINGALI K, et al.C3:A system for automating application-level checkpointing of MPI Programs[J].Lecture Notes in Computer Science, 2003, 2958:357-373. http://d.old.wanfangdata.com.cn/Periodical/qhdxxb-zr201306013
|
| [17] |
FAGG E G, DONGARRA J.FT-MPI:Fault tolerant MPI, supporting dynamic applications in a dynamic world[M].Berlin:Springer, 2000:346-353.
|
| [18] |
HURSEY J, GRAHAM R L.Analyzing fault aware collective performance in a process fault tolerant MPI[J].Parallel Computing, 2012, 38(1):15-25. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=JJ0226205679
|
| [19] |
WANG R, YAO E, CHEN M, et al.Building algorithmically nonstop fault tolerant MPI programs[C]//Proceedings of IEEE International Conference on High Performance Computing (HiPC).Piscataway, NJ: IEEE Press, 2011: 1-9. http://ieeexplore.ieee.org/document/6152716/
|
| [20] |
CHEN Z, DONGARRA J.Algorithm-based fault tolerance for fail-stop failures[J].IEEE Transactions on Parallel and Distributed Systems, 2008, 19(12):1628-1641. doi: 10.1109/TPDS.2008.58
|
| [21] |
GORLATCH S.Send-receive considered harmful:Myths and realities of message passing[J].ACM Transactions on Programming Languages & Systems, 2004, 26(1):47-56. http://cn.bing.com/academic/profile?id=69d1c8c7a75a074f254e3132a84064ba&encoded=0&v=paper_preview&mkt=zh-cn
|
| [22] |
LI C, ZHAO C, YAN H, et al.Event-driven fault tolerance for building nonstop active message programs[C]//Proceedings of IEEE International Conference on High Performance Computing.Piscataway, NJ: IEEE Press, 2013: 382-390. http://ieeexplore.ieee.org/document/6831944/
|
| [23] |
LI C, WANG Y, ZHAO C, et al.Parallel Kirchhoff pre-stack depth migration on large high performance clusters[M].Berlin:Springer, 2015:251-266.
|
Figures(9) / Tables(2)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: