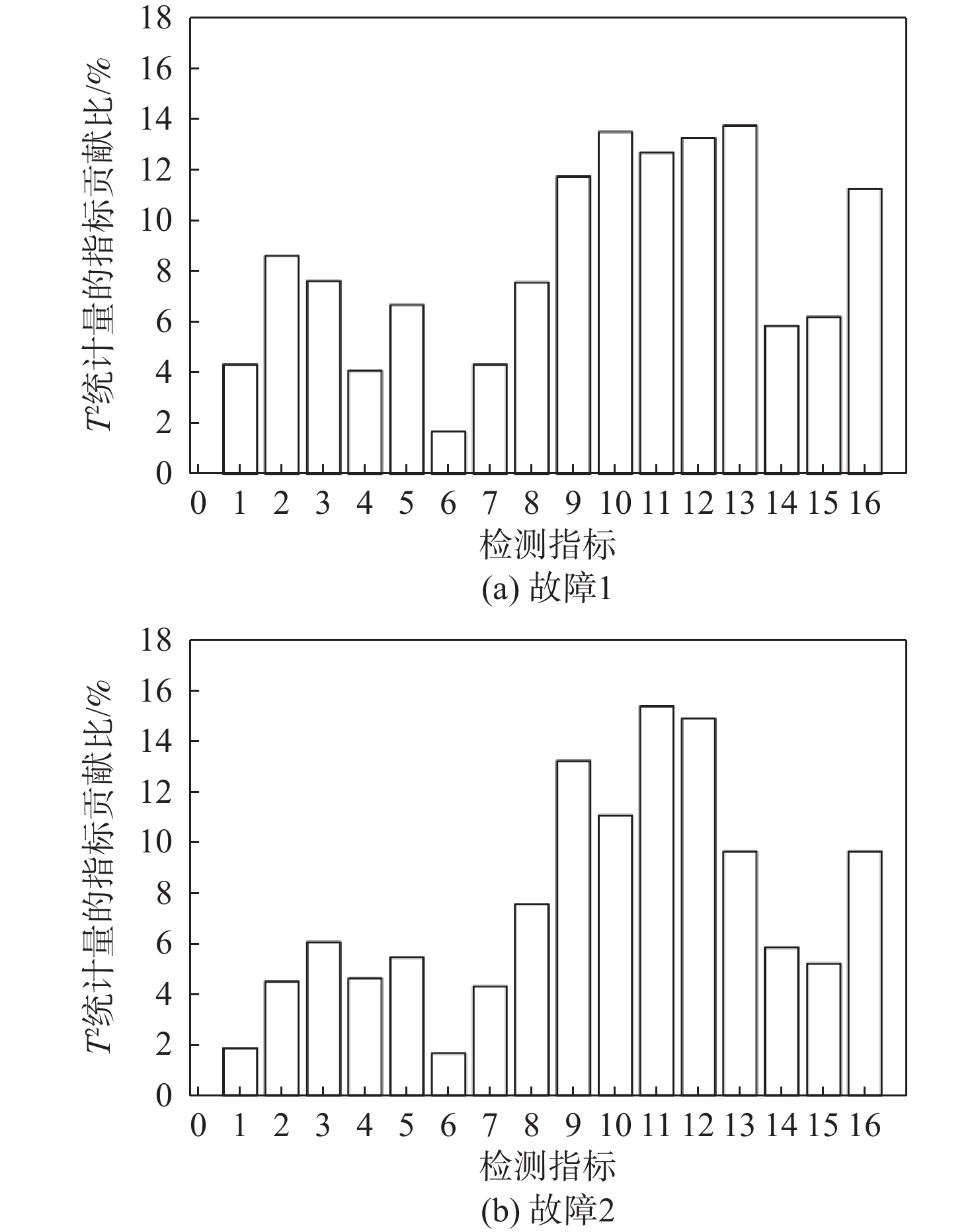
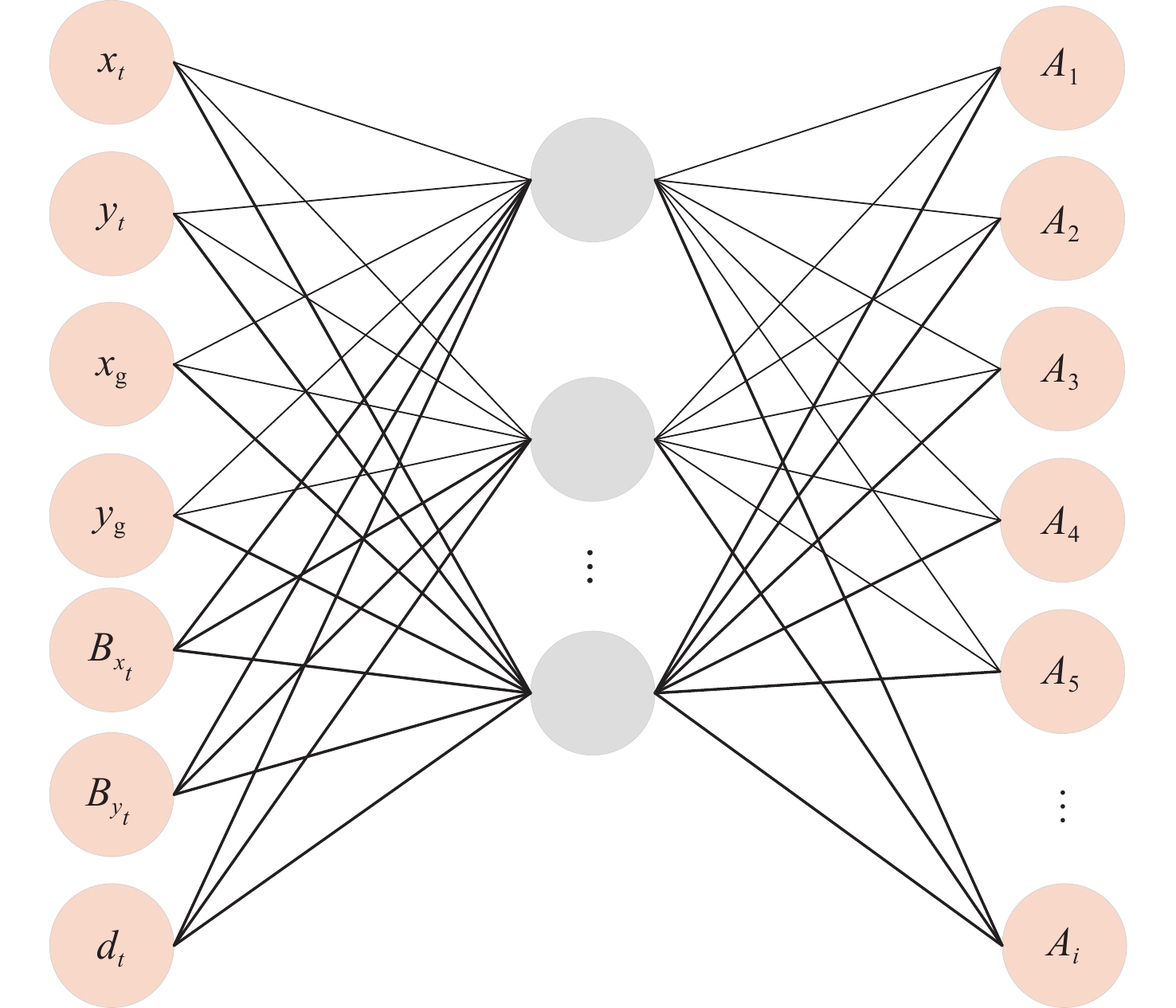
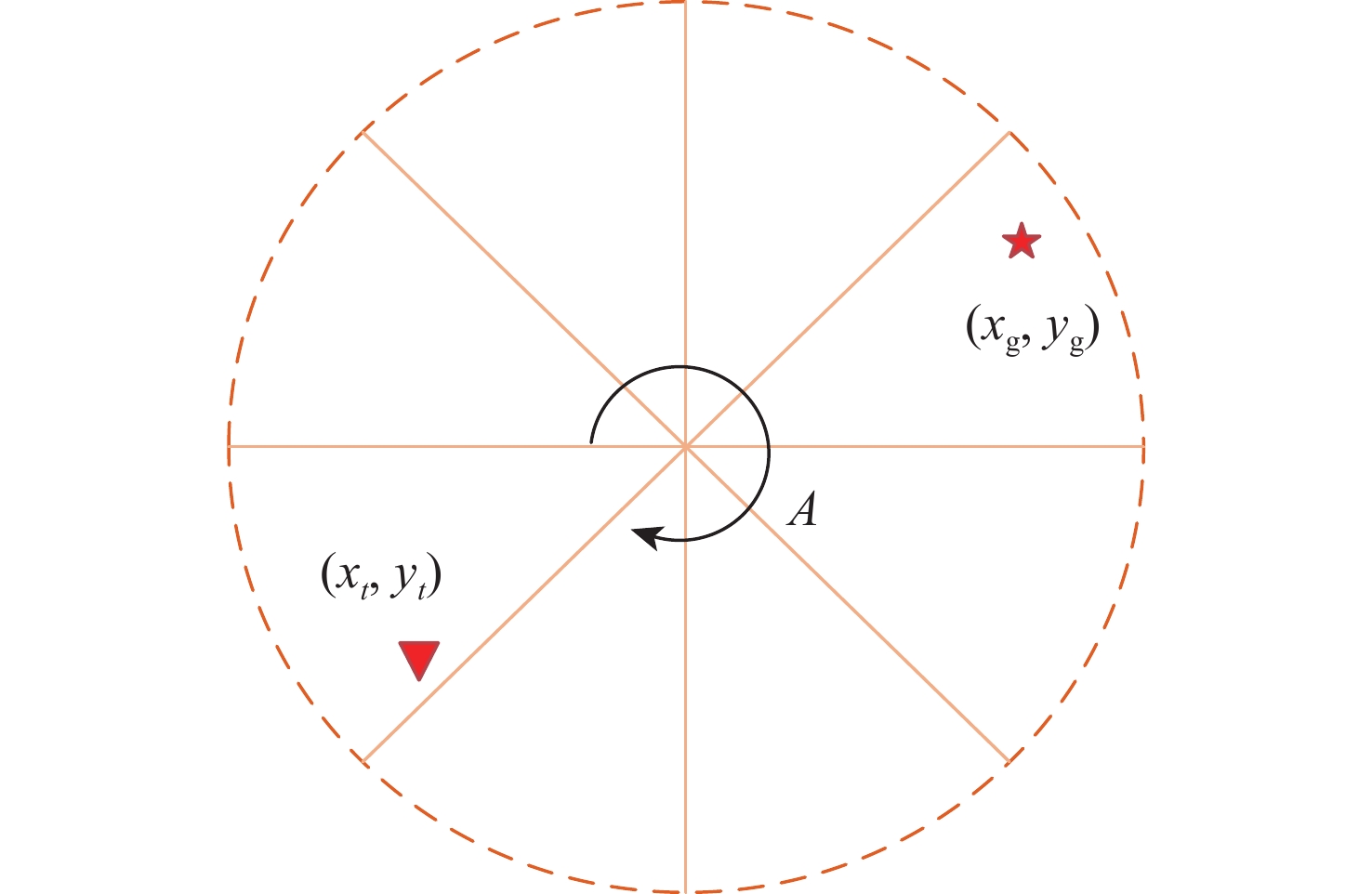
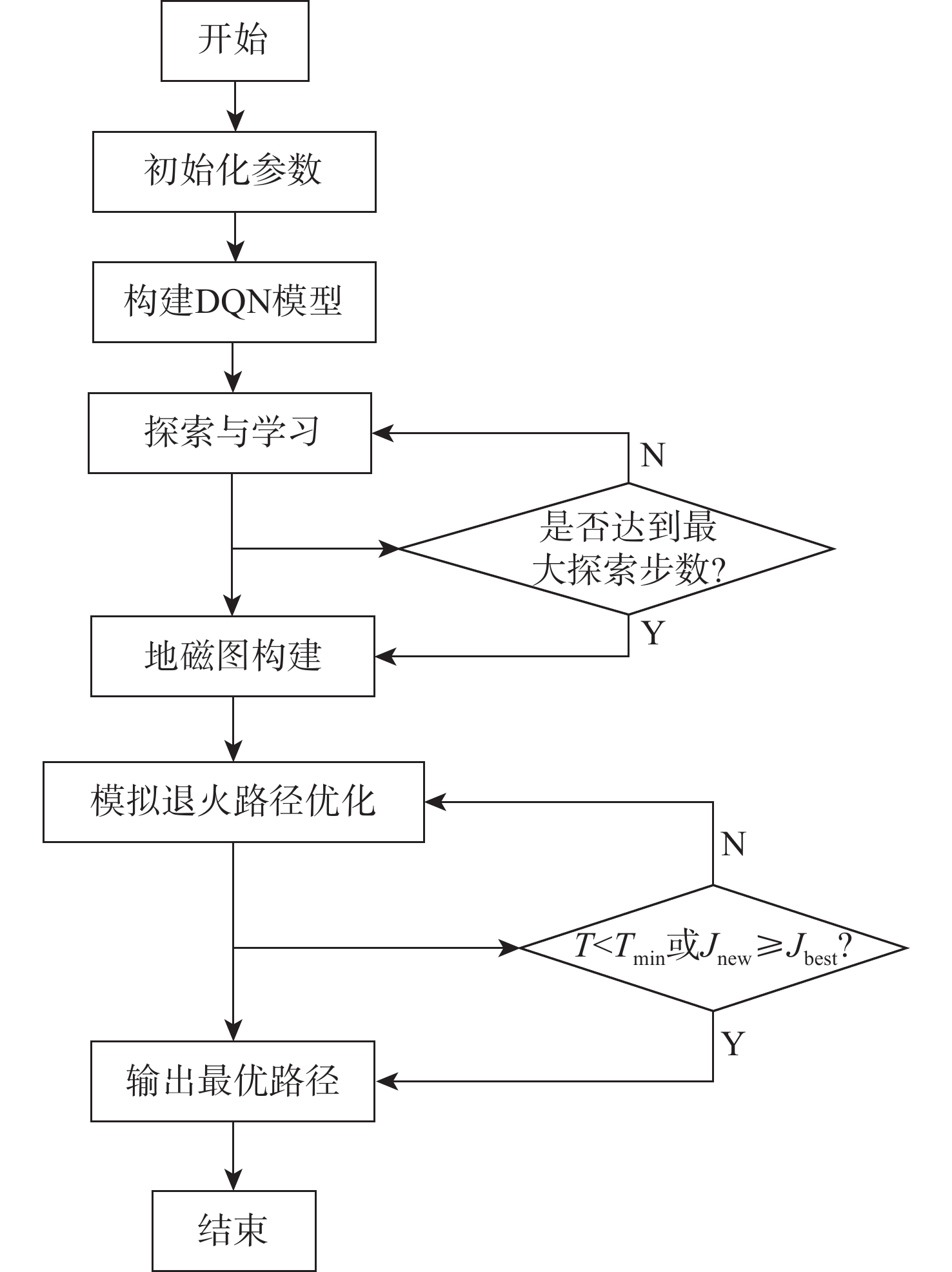
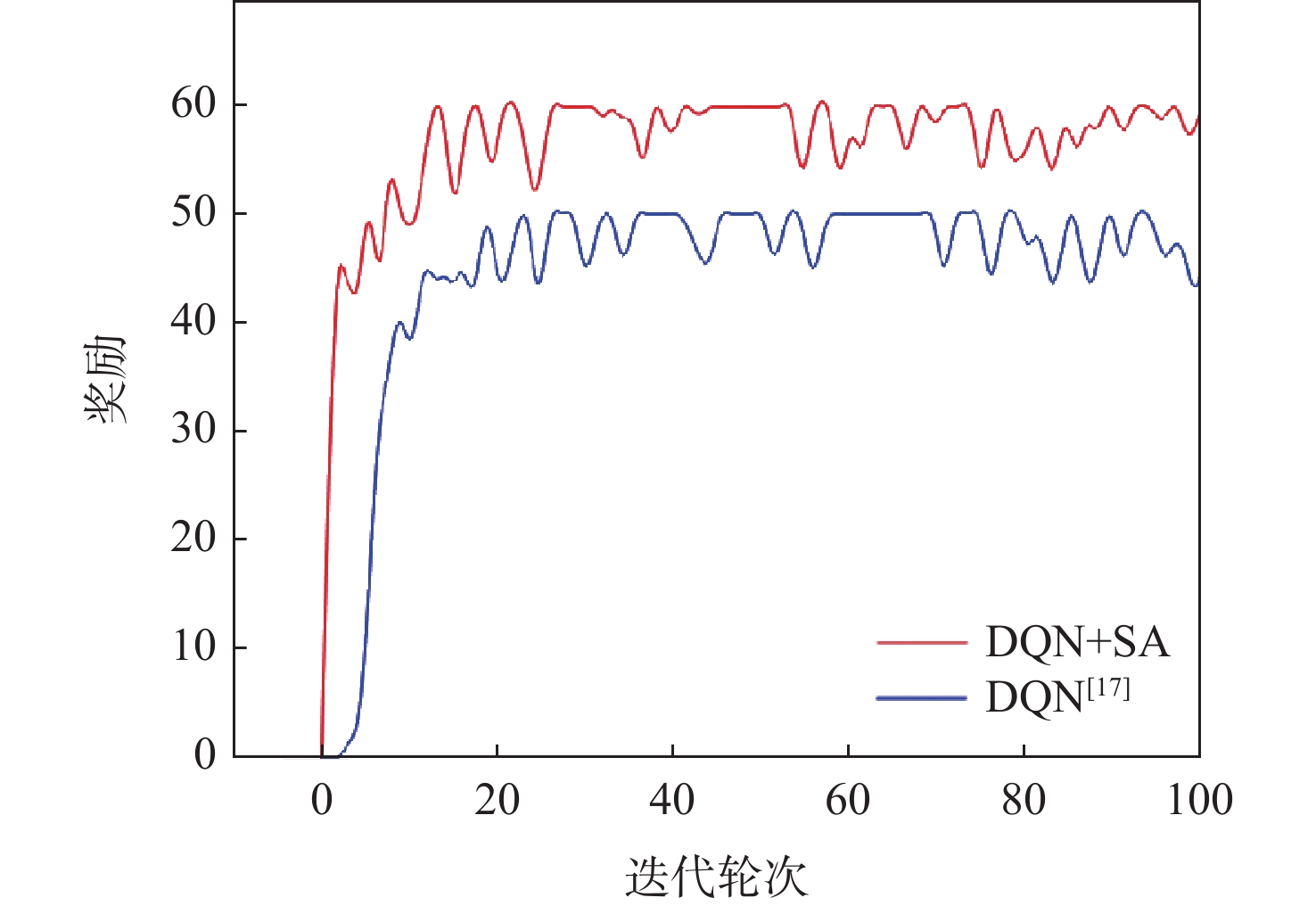
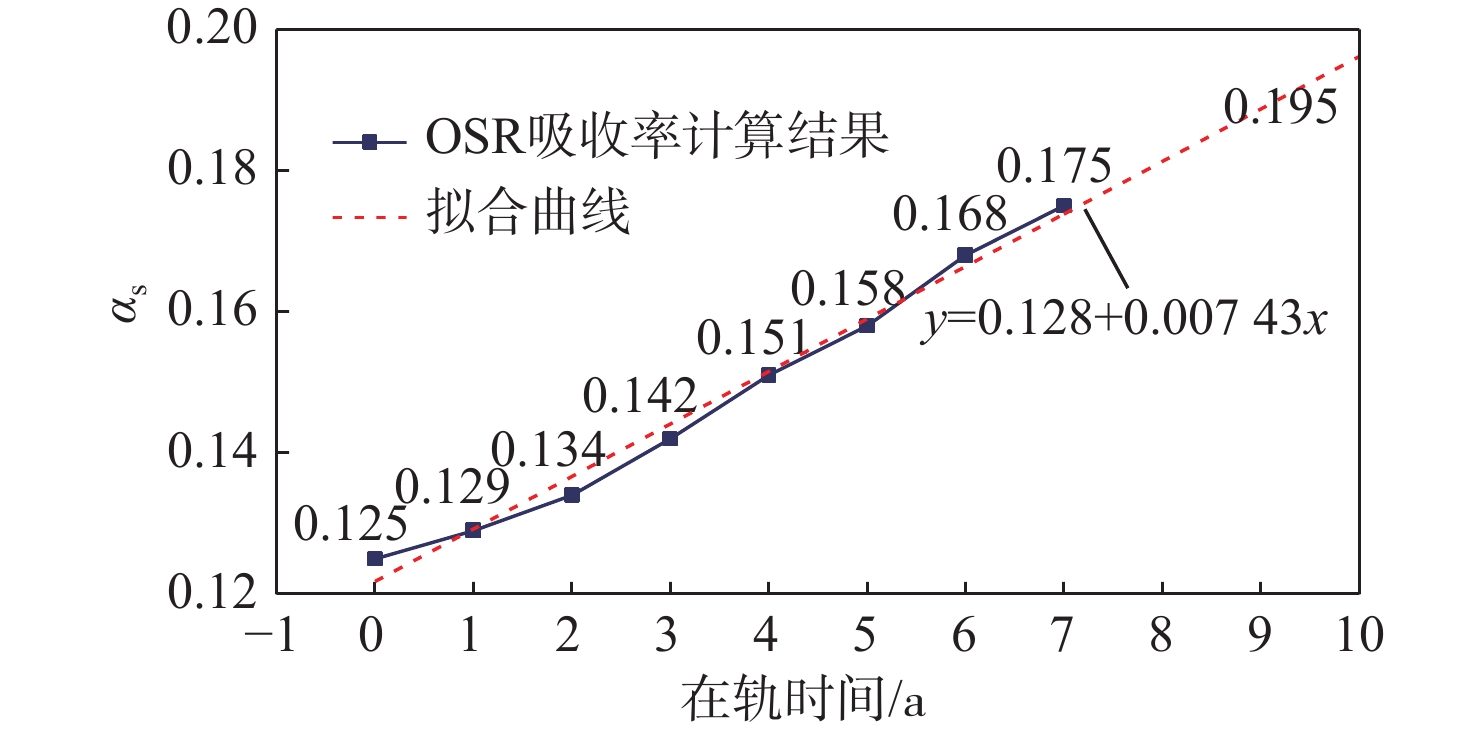
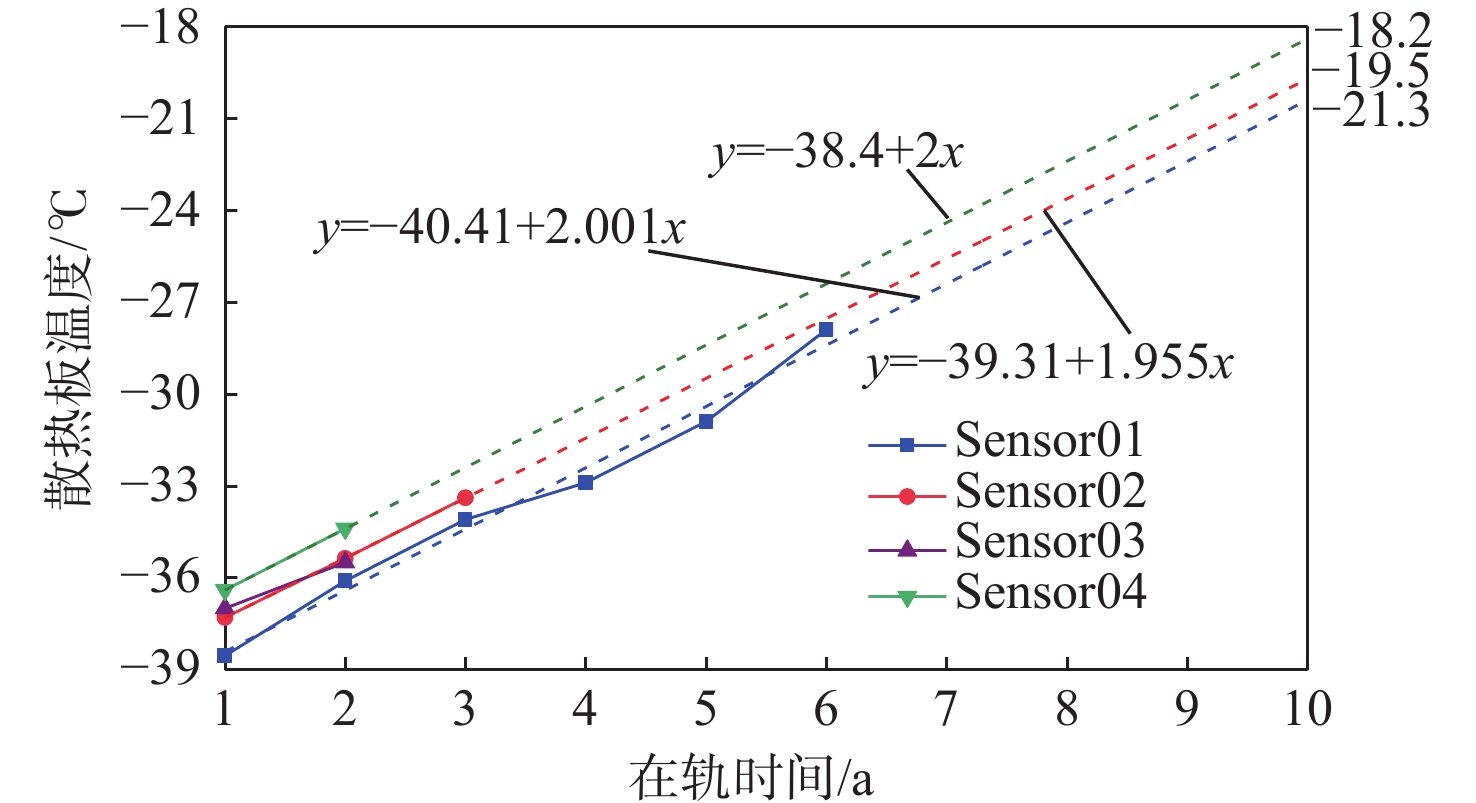
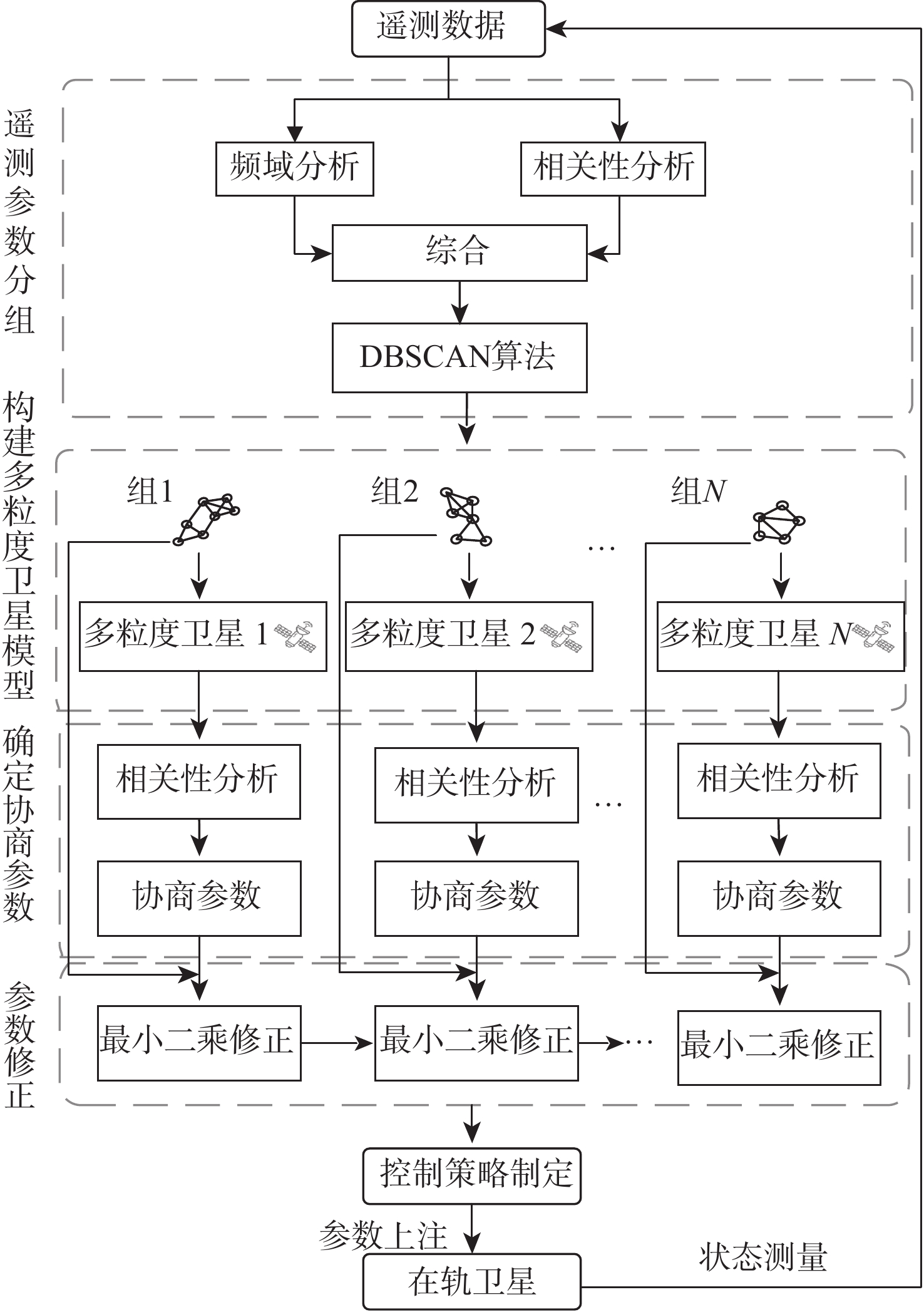
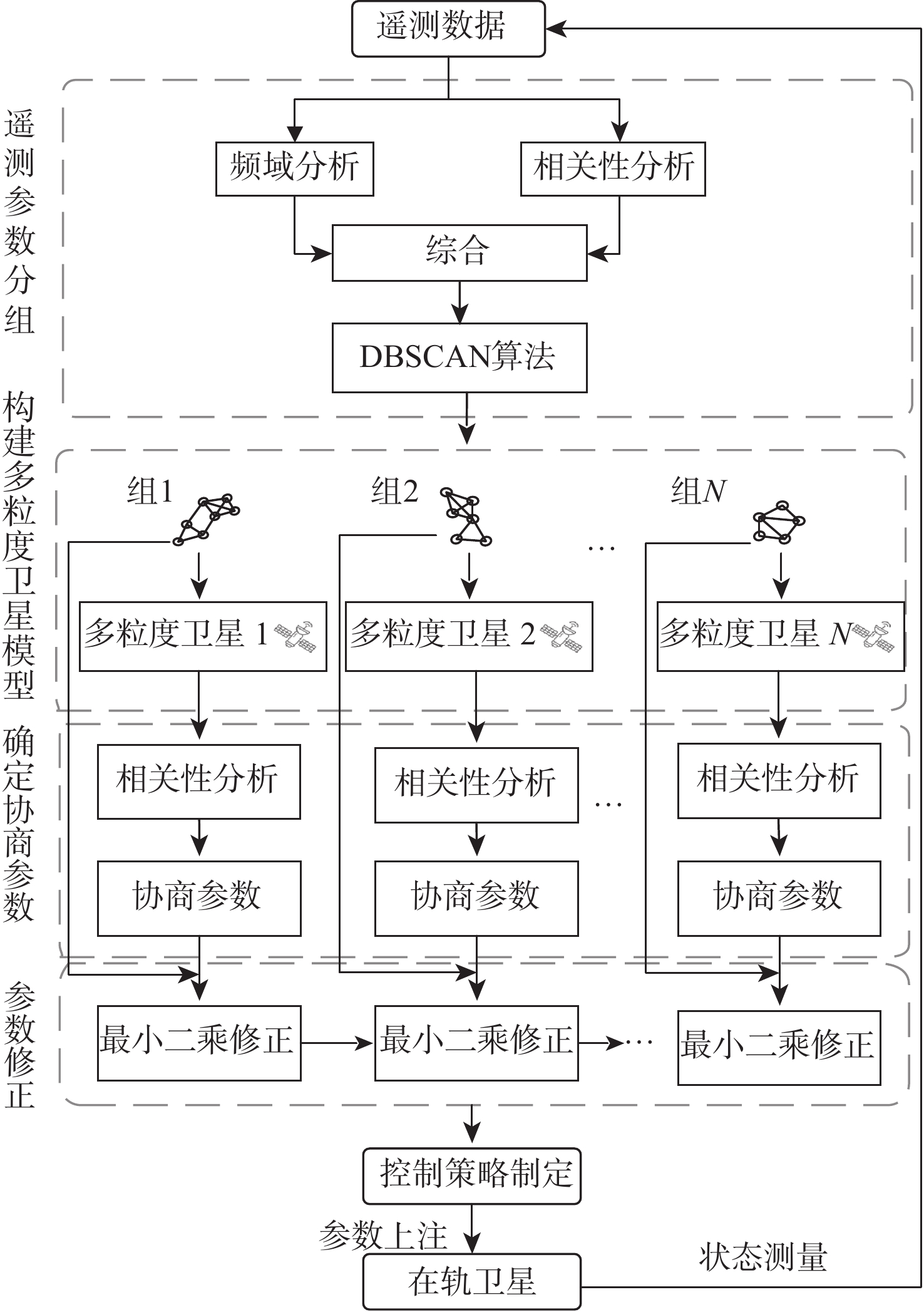
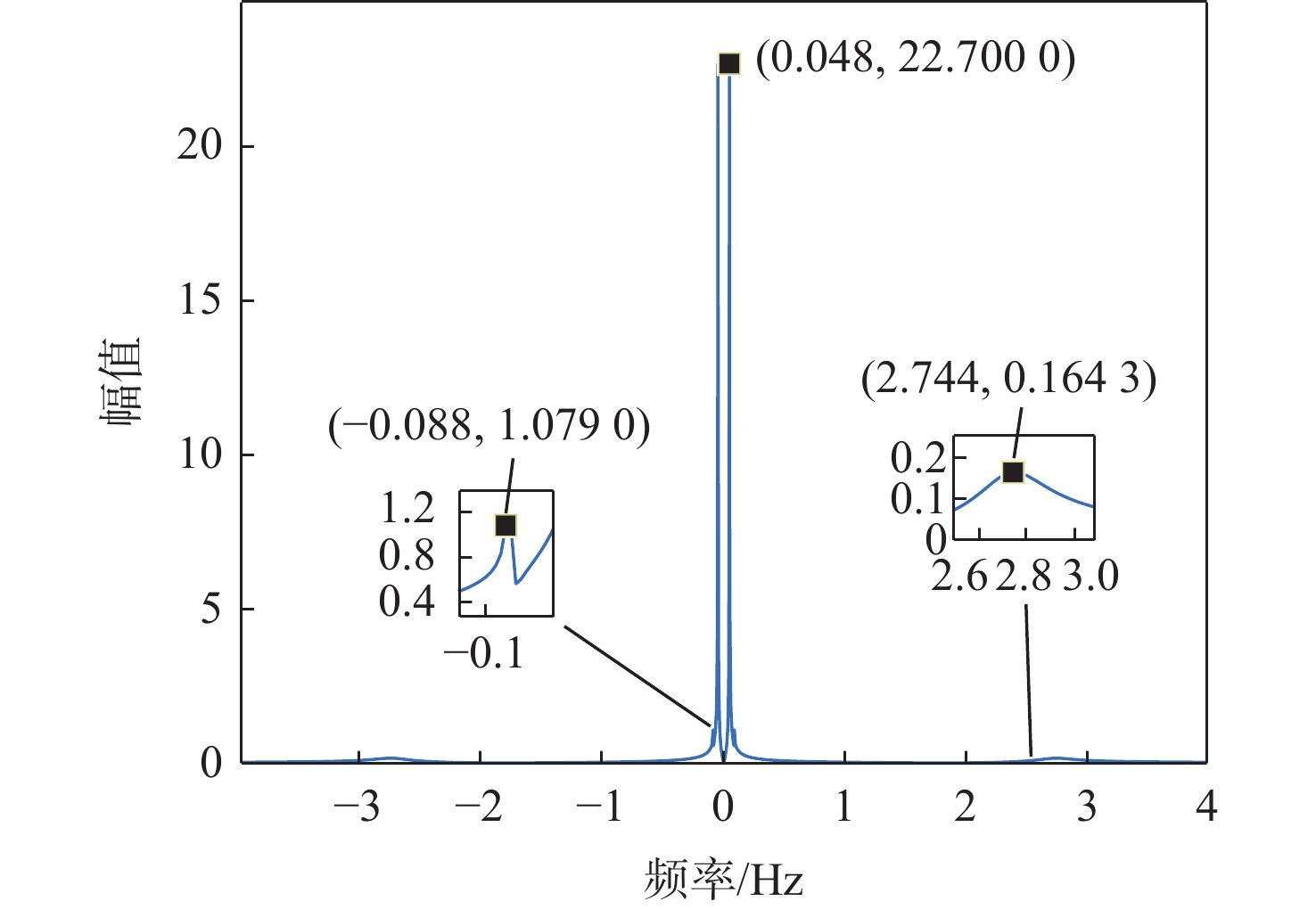
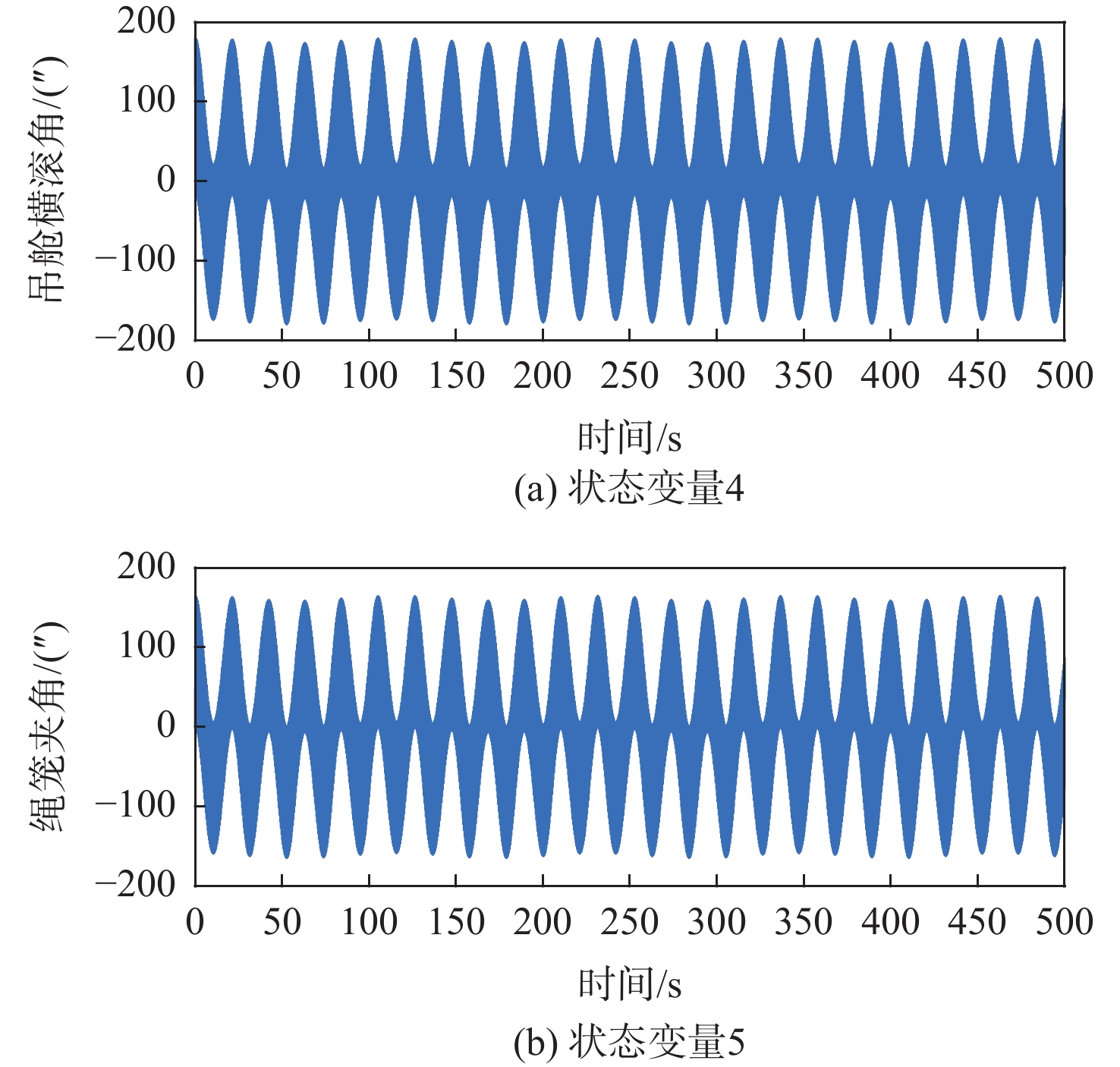
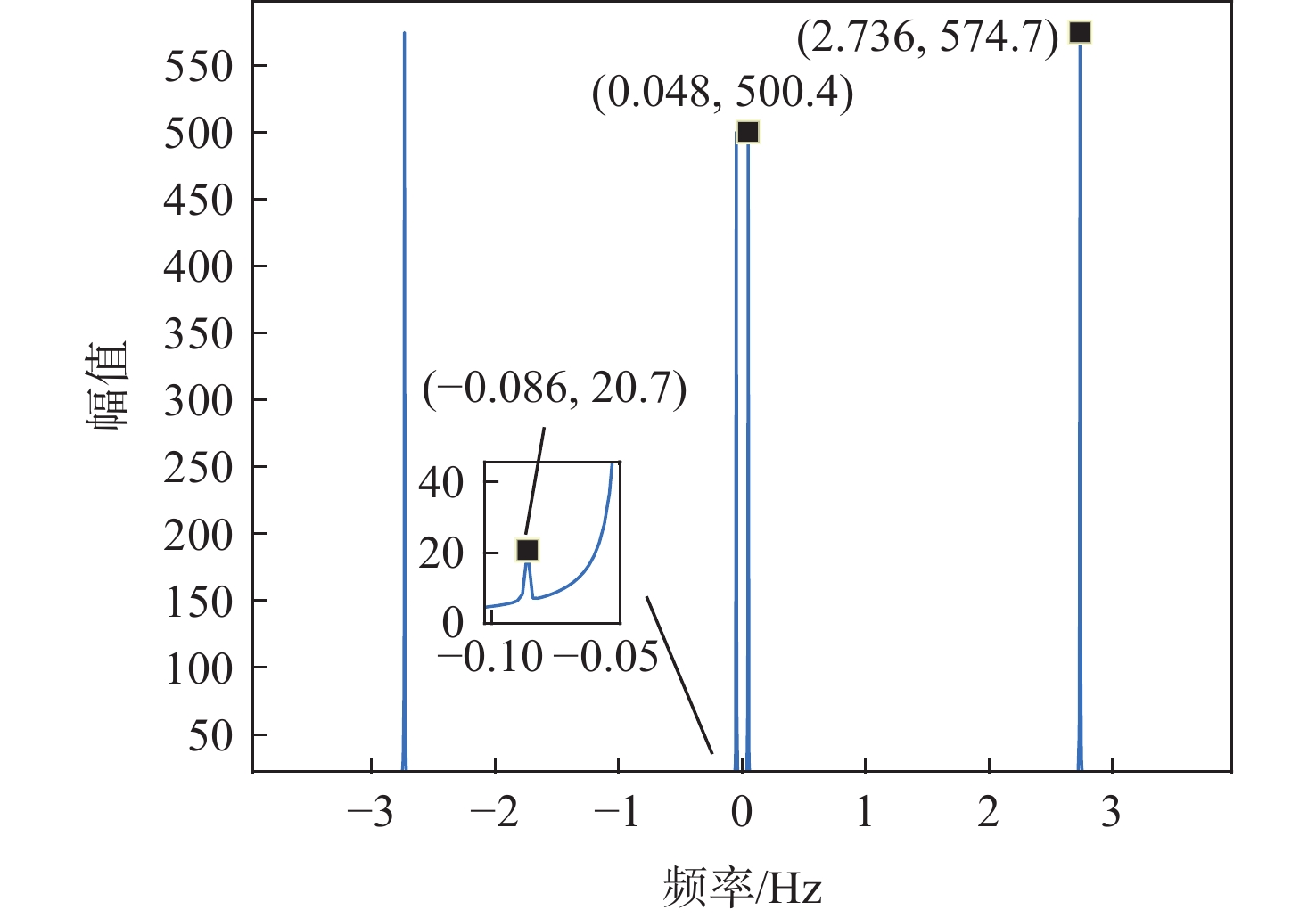
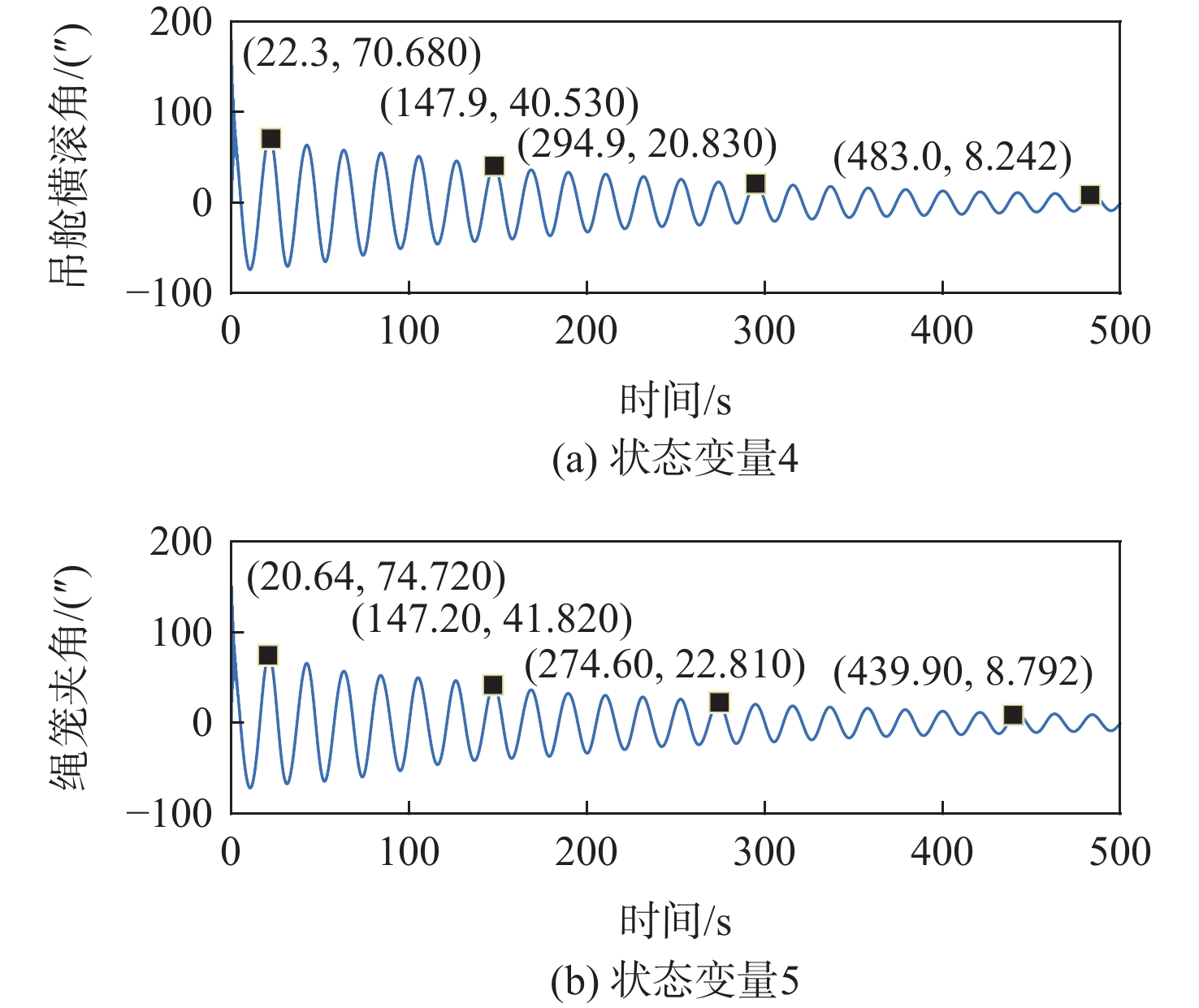
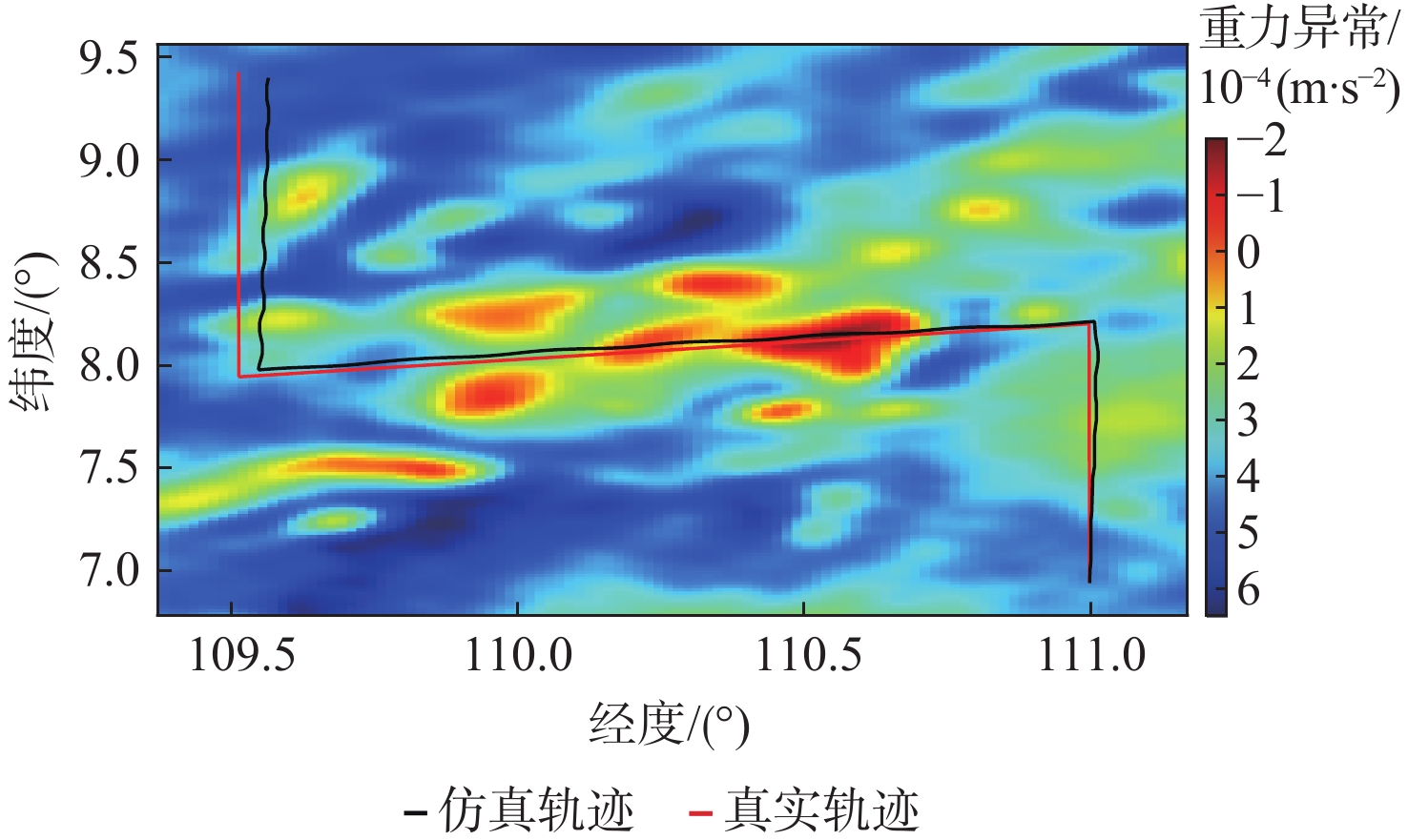
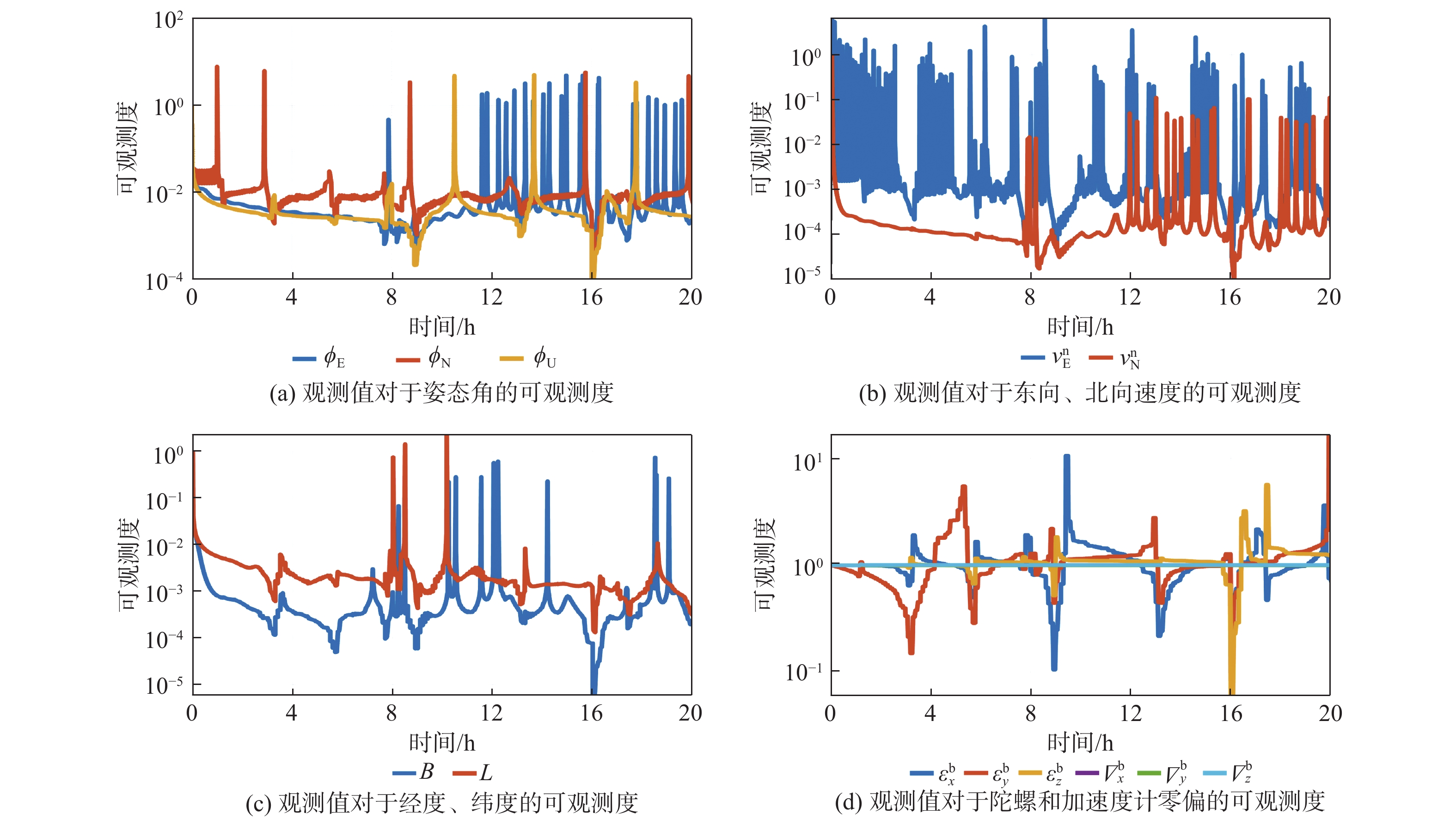
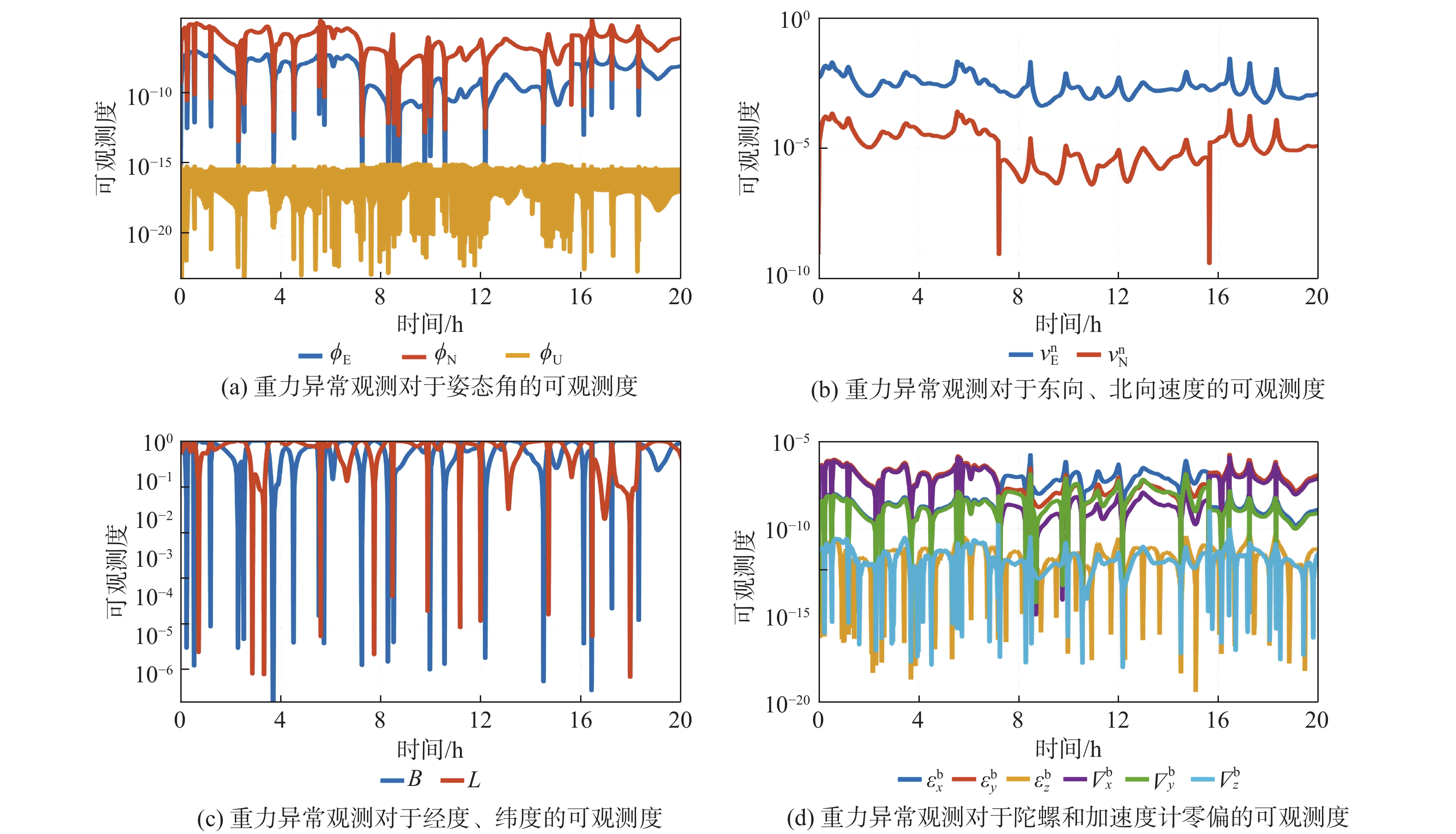
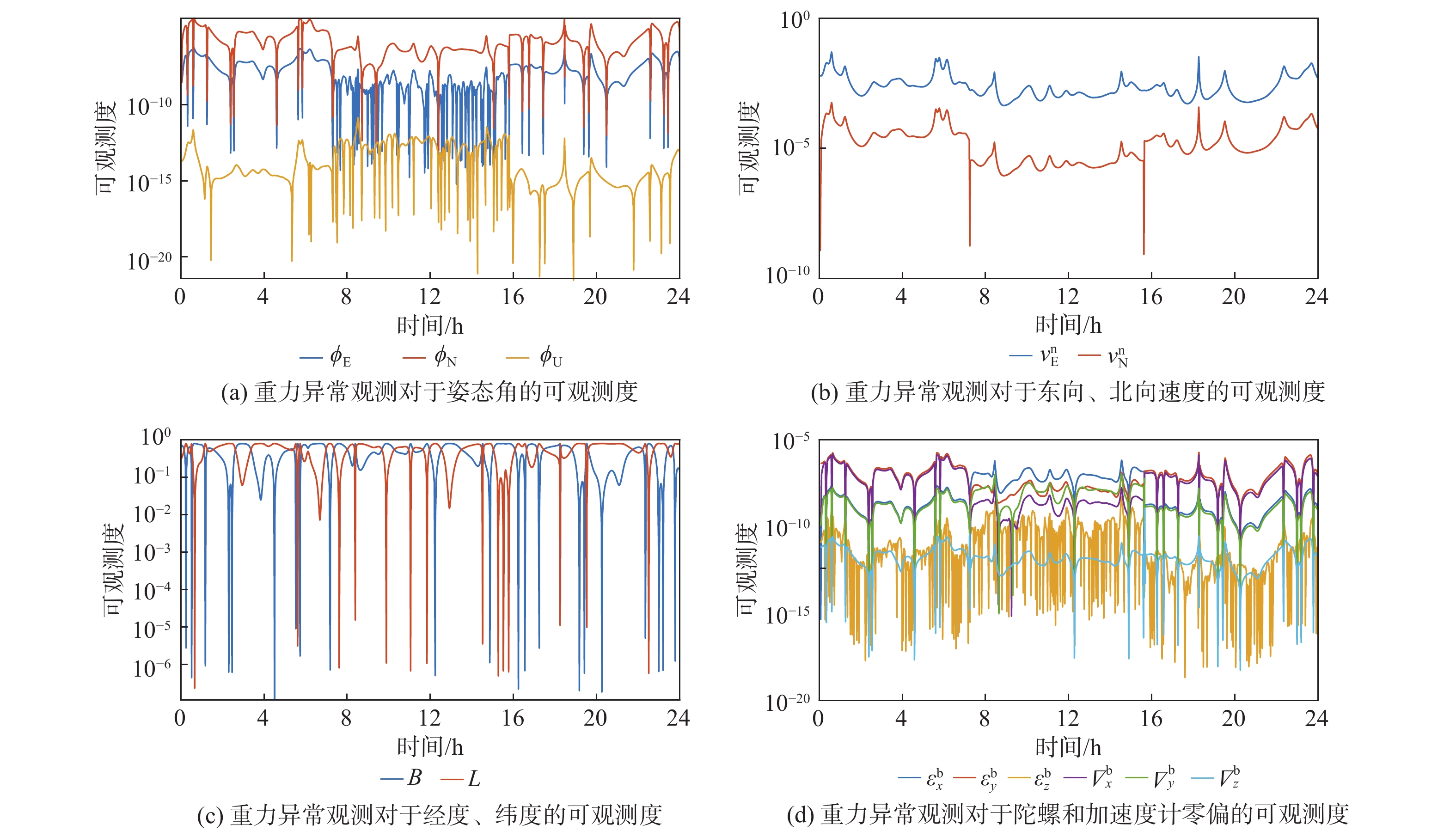
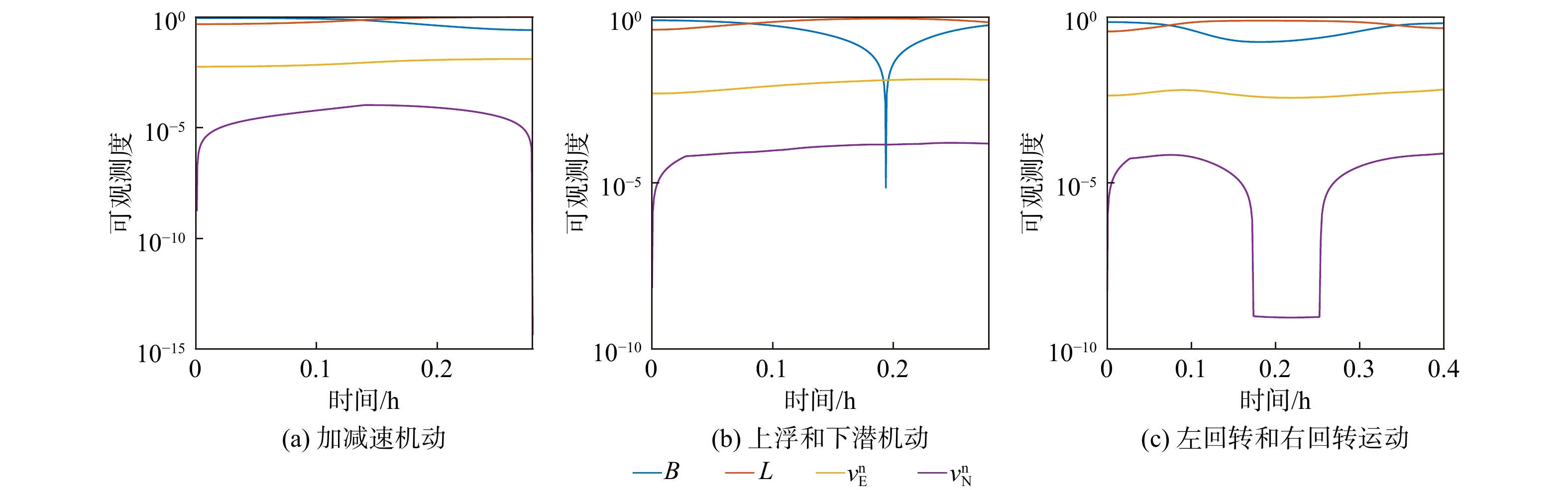
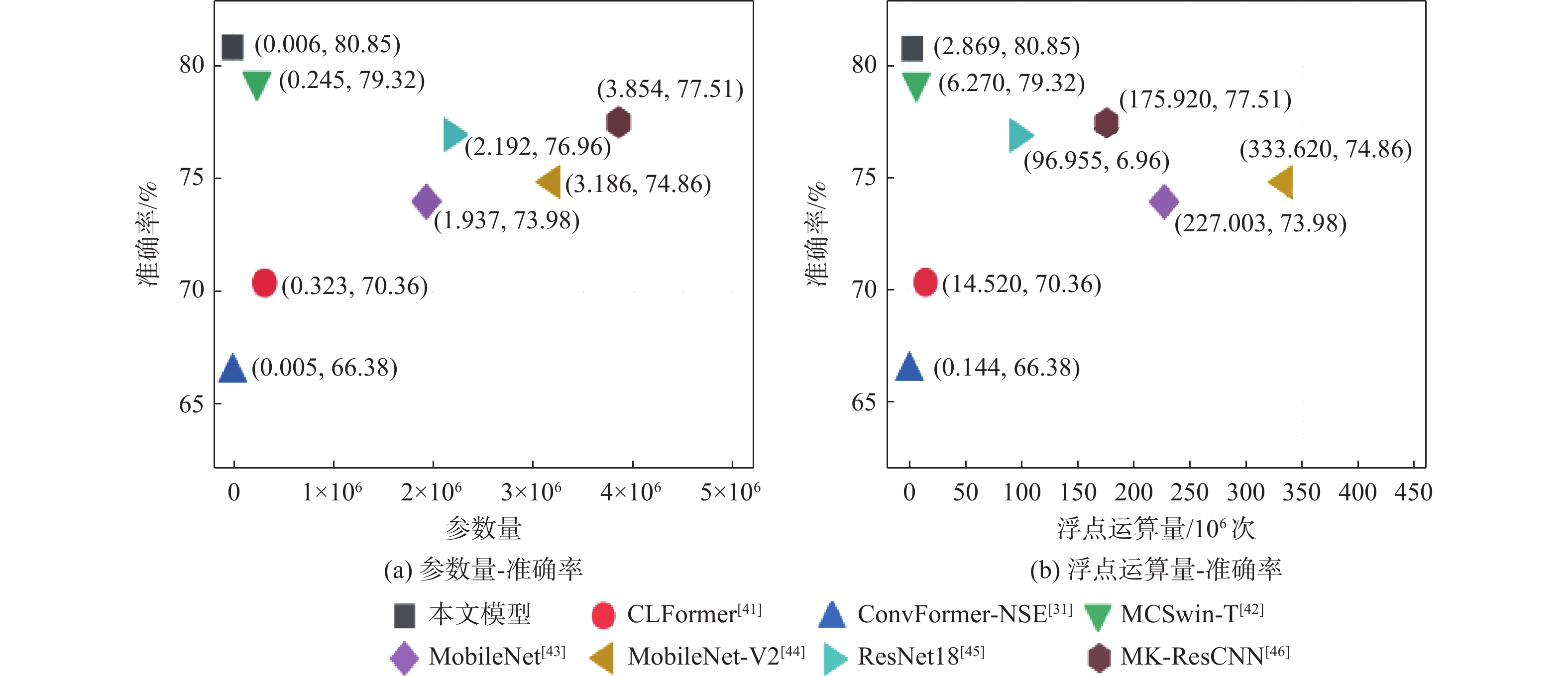
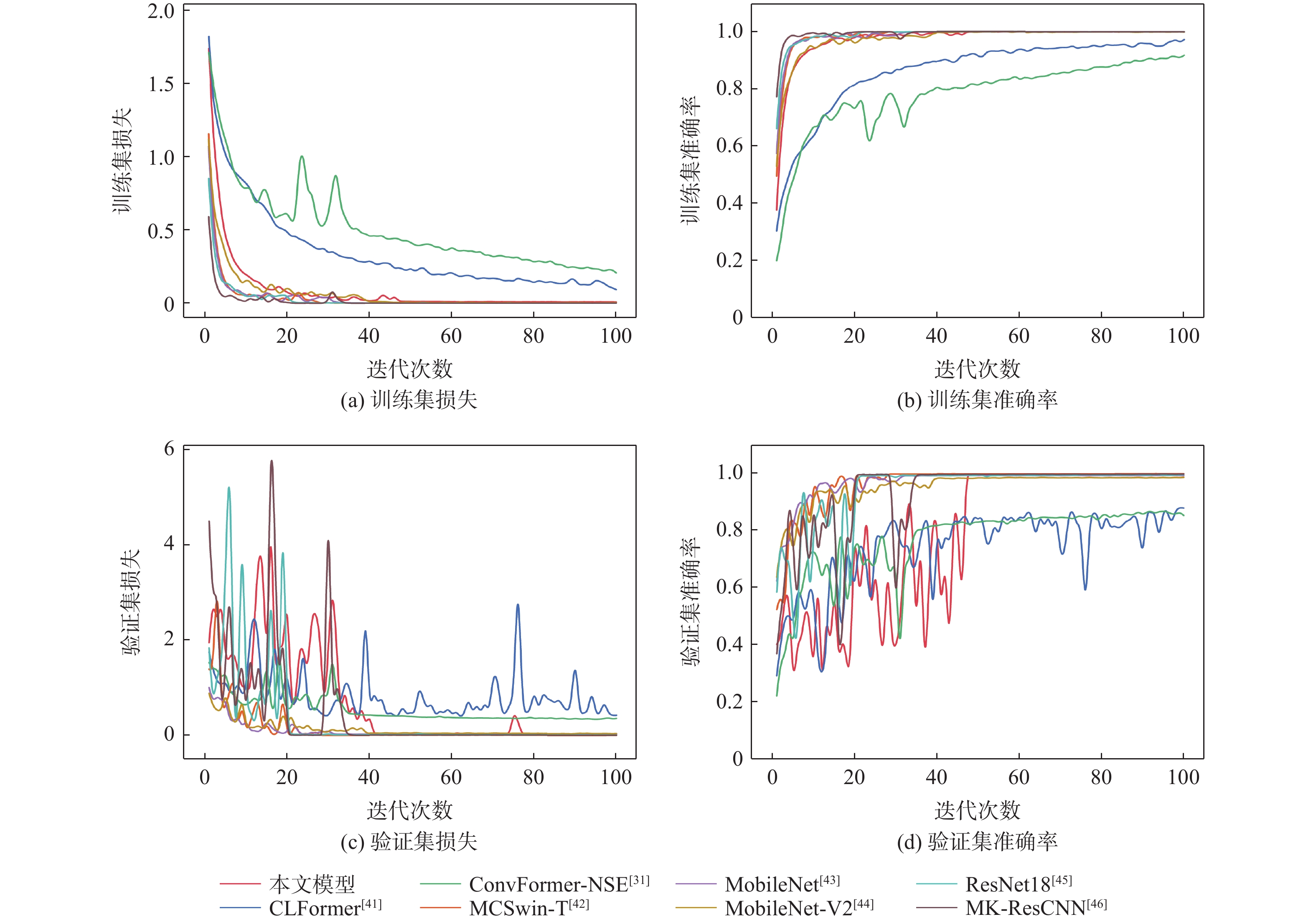
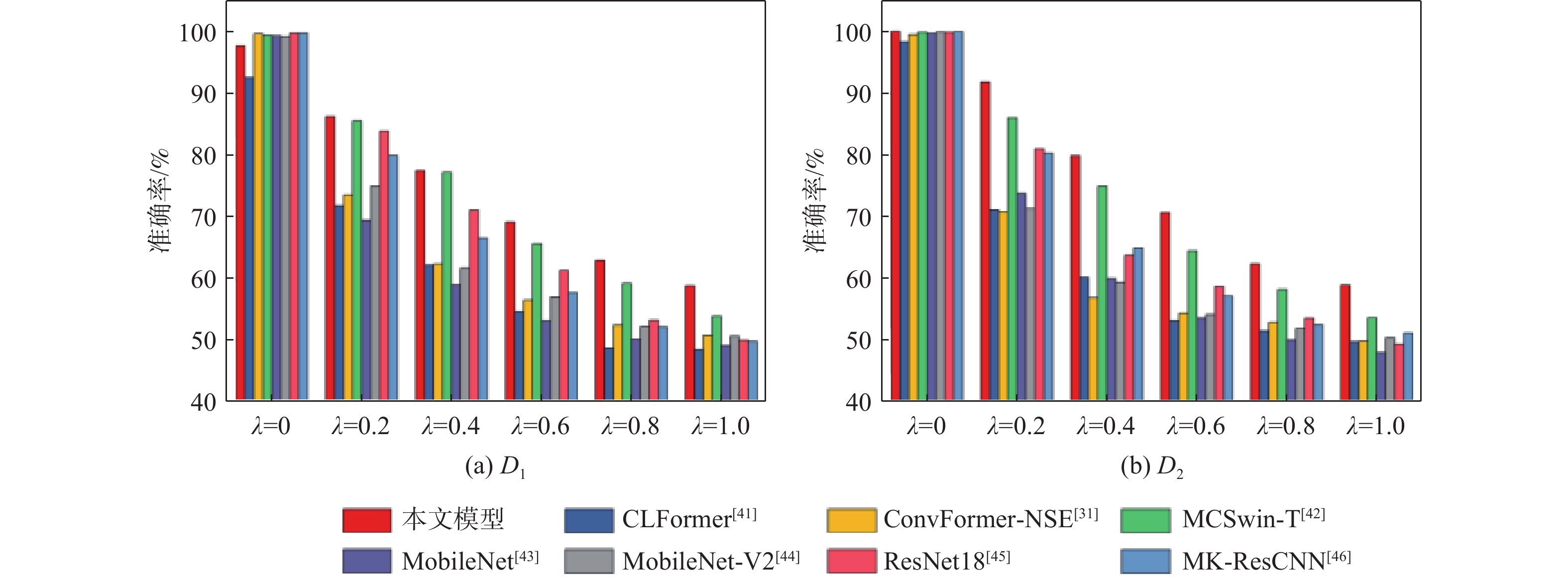
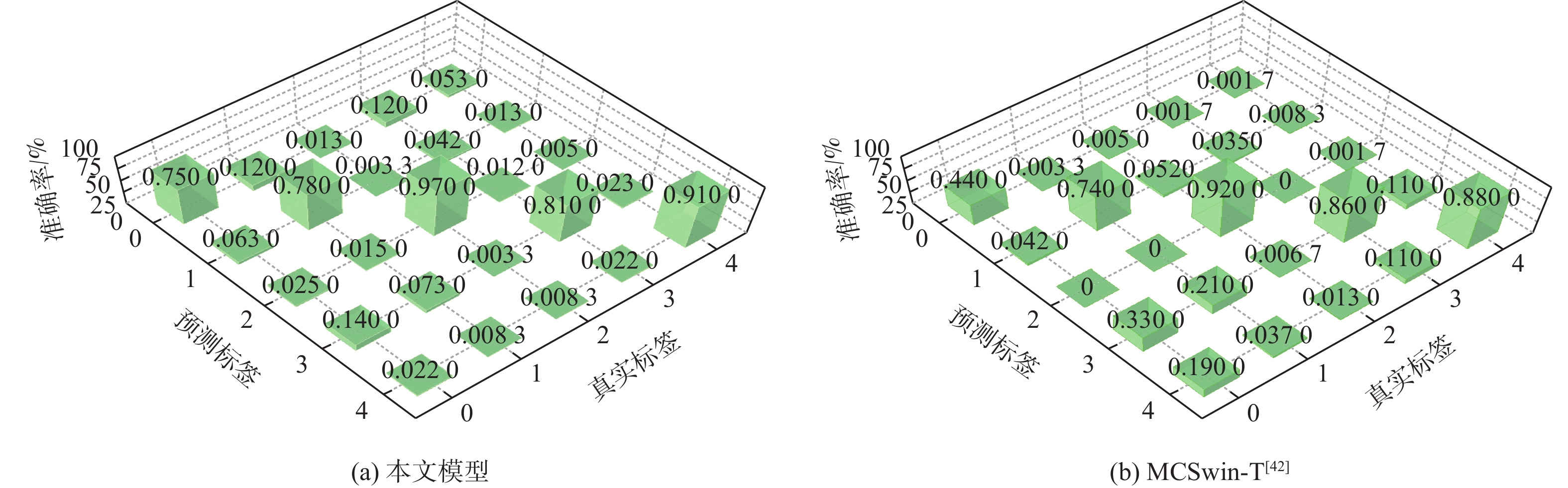
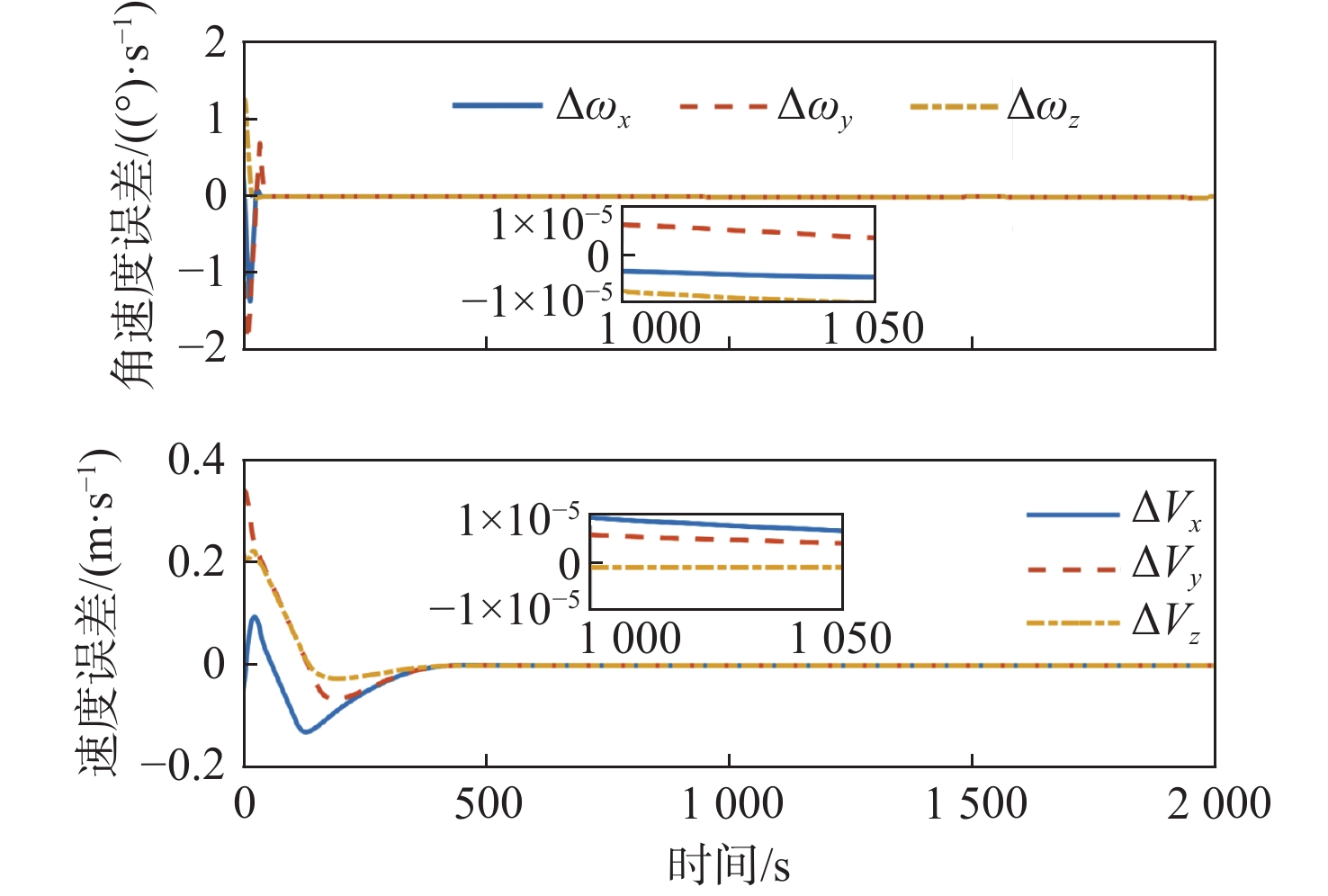
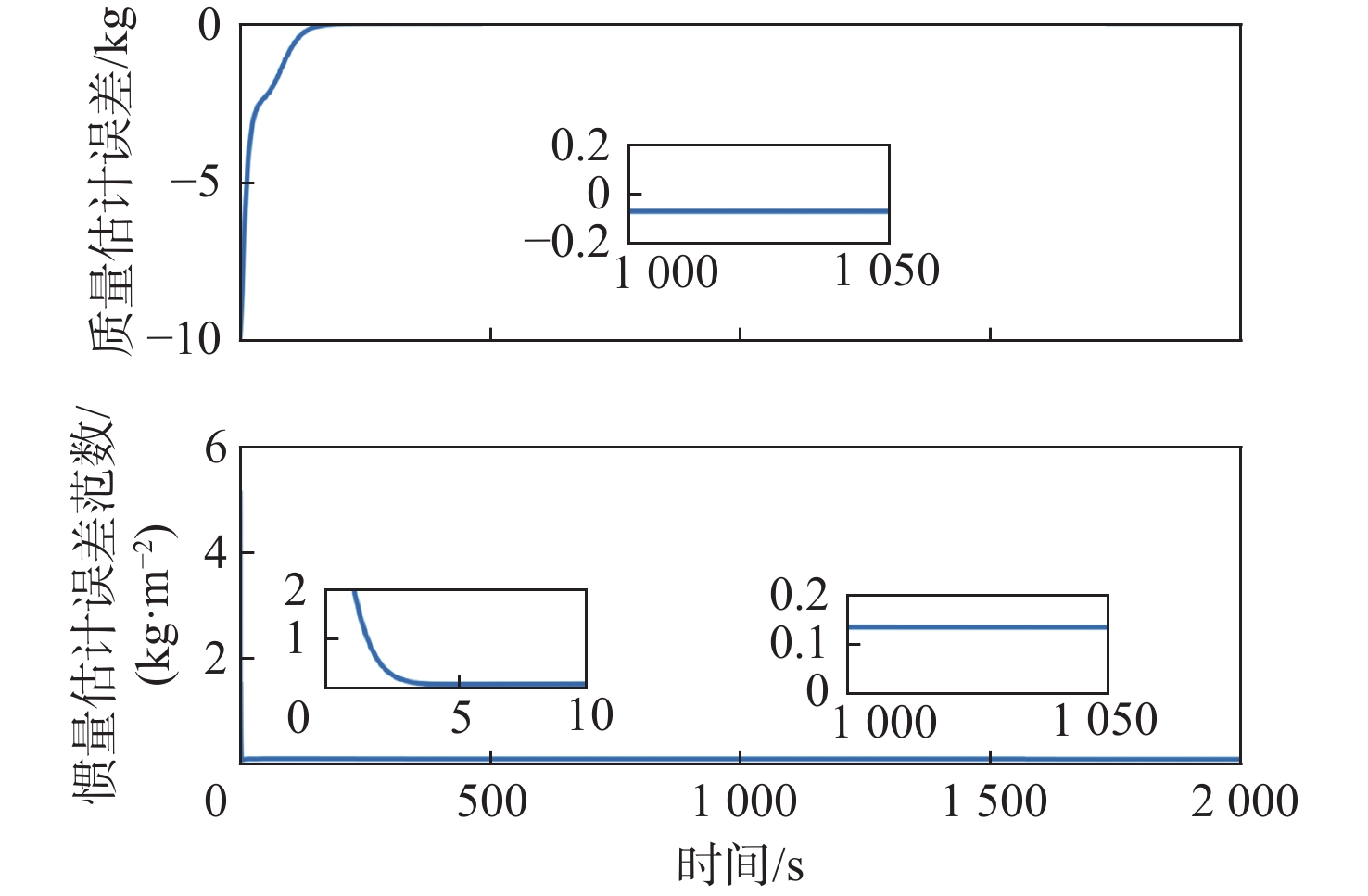
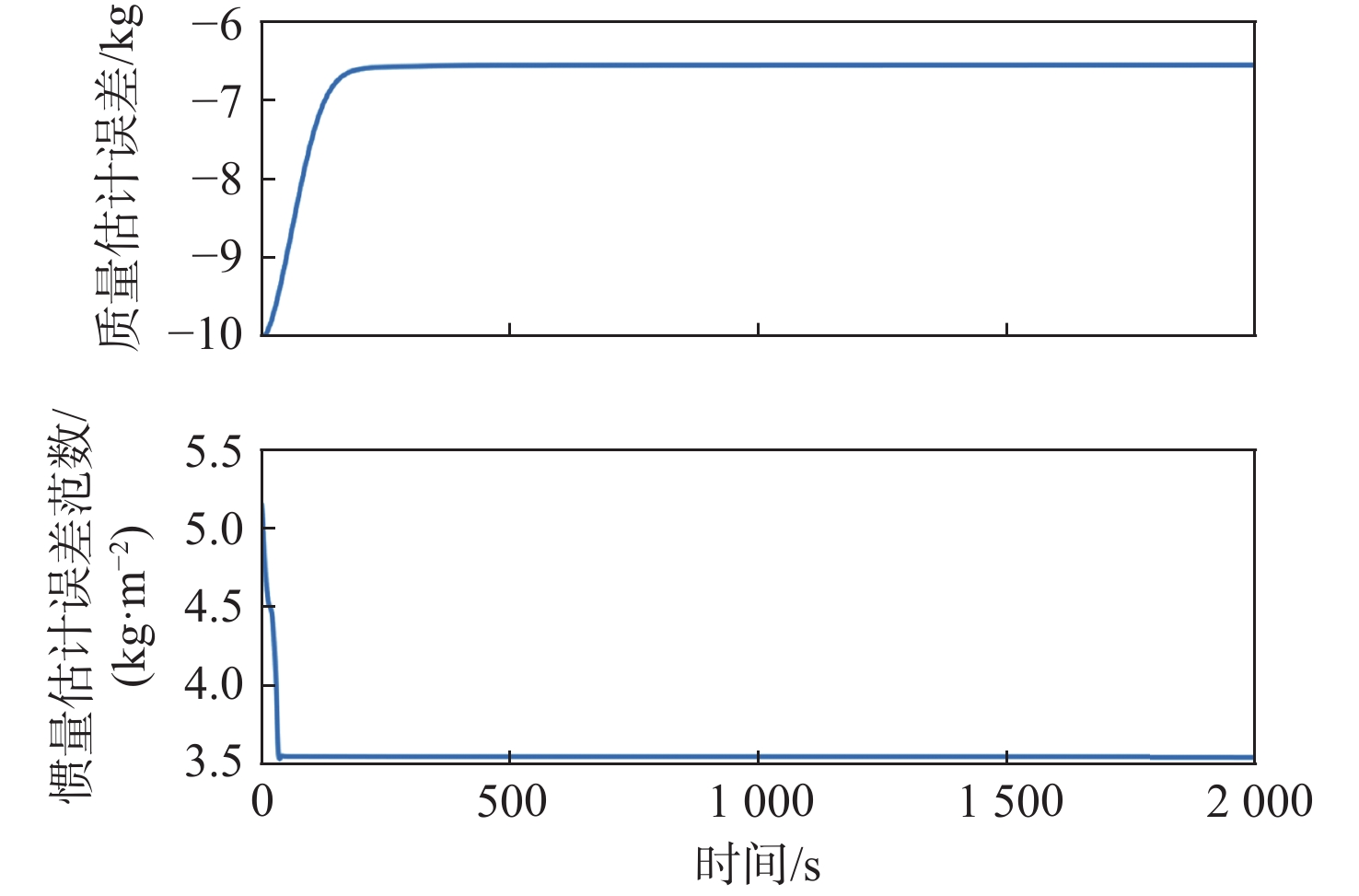
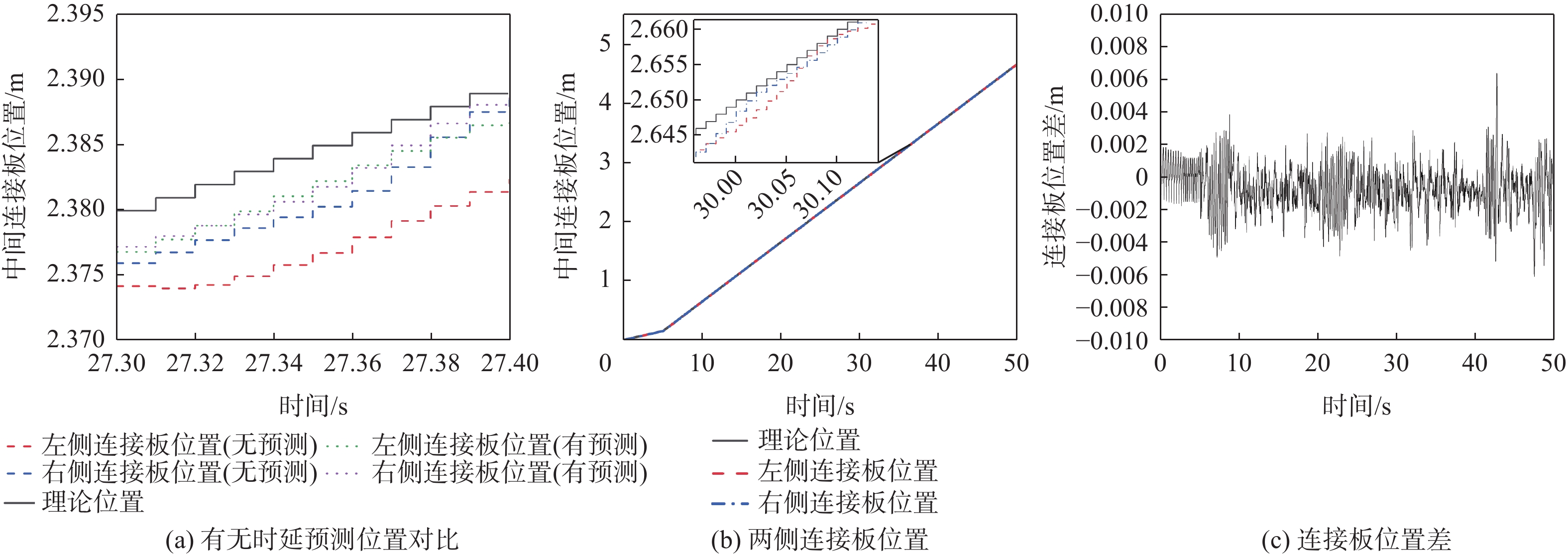
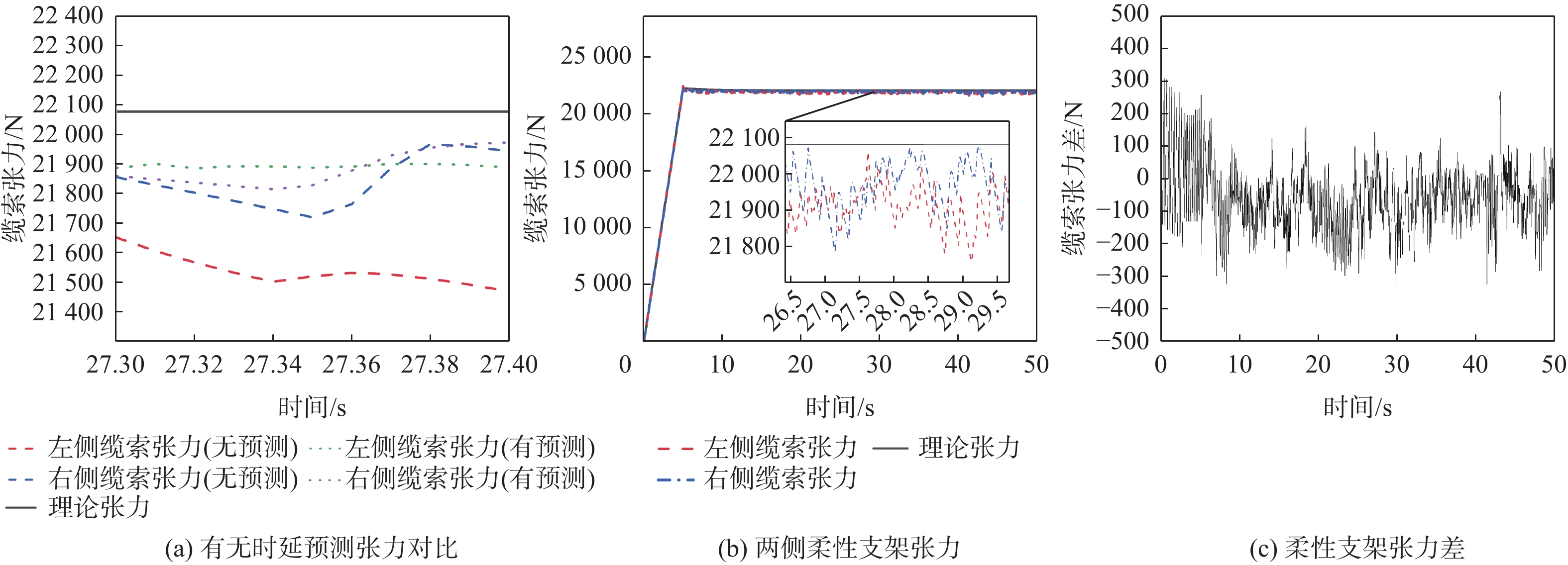
Gravity-aided inertial navigation is an important technology for enabling long-term autonomous navigation of underwater vehicles. However, the gravity anomaly observation is coupled with inertial navigation state parameters in a complex manner, and improper selection of estimated parameters may lead to reduced filtering accuracy or even filter divergence. To clarify the real-time estimation effectiveness of different navigation state parameters, this paper conducts modeling, analysis, and verification of the observabal degree of state parameters in a gravity-aided inertial navigation system. First, an error-state filtering model for gravity-aided inertial navigation is established. A 13-dimensional state vector is selected, including attitude errors, velocity errors, position errors, gyroscope biases, and accelerometer biases. The gravity anomaly observation equation and its partial derivatives with respect to each state parameter are derived, thereby clarifying the relationship between the observability matrix and the estimability of navigation parameters. Second, observabal degree analysis models based on the covariance matrix, observability matrix, and Lie derivatives are constructed, respectively, and the applicability and consistency of different methods are compared. Based on a simulated underwater vehicle trajectory in a certain sea area, the variation patterns of the observabal degree of different state parameters with navigation time, gravity field characteristics, and maneuvering conditions are analyzed. The experimental results show that longitude, latitude, eastward velocity, and northward velocity have relatively high observabal degrees and constitute a preferable combination of estimated states for gravity-aided inertial navigation. In contrast, gyroscope and accelerometer biases have relatively low observabal degrees and are not suitable to be directly used as the main feedback correction parameters. On this basis, fixed parameter combinations and a dynamic parameter combination based on an observabal degree threshold are further designed for filtering verification. The results indicate that joint estimation of position and horizontal velocity improves navigation positioning accuracy by 42%, while dynamically adjusting the state parameter combination further improves positioning accuracy by 5%. The research results provide a basis for filtering-state selection, equation-structure design, and feedback correction strategies under maneuvering conditions in gravity-aided inertial navigation.



 Download (39597)
Download (39597) 
 Views
Views  Cited by
Cited by 



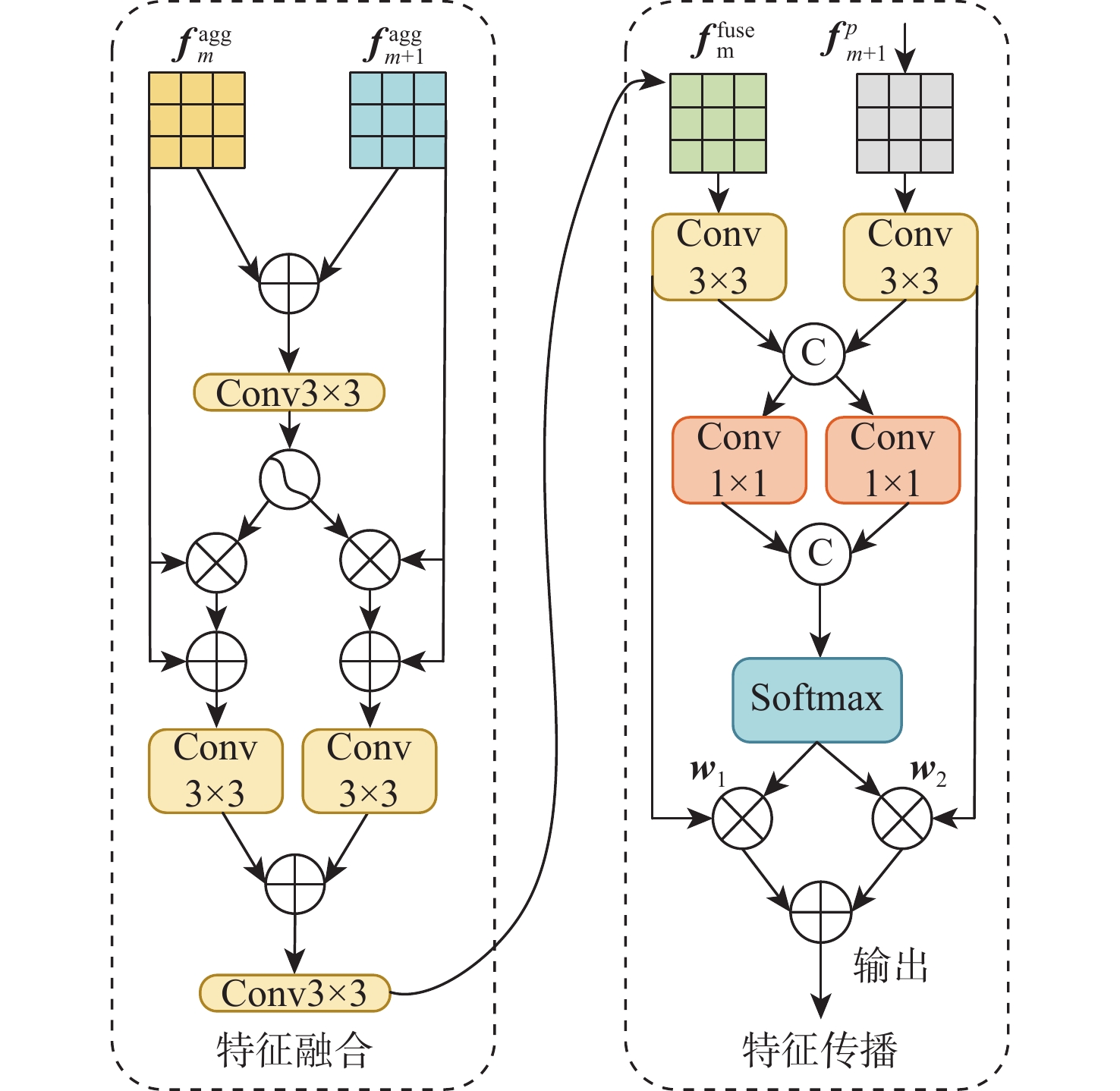
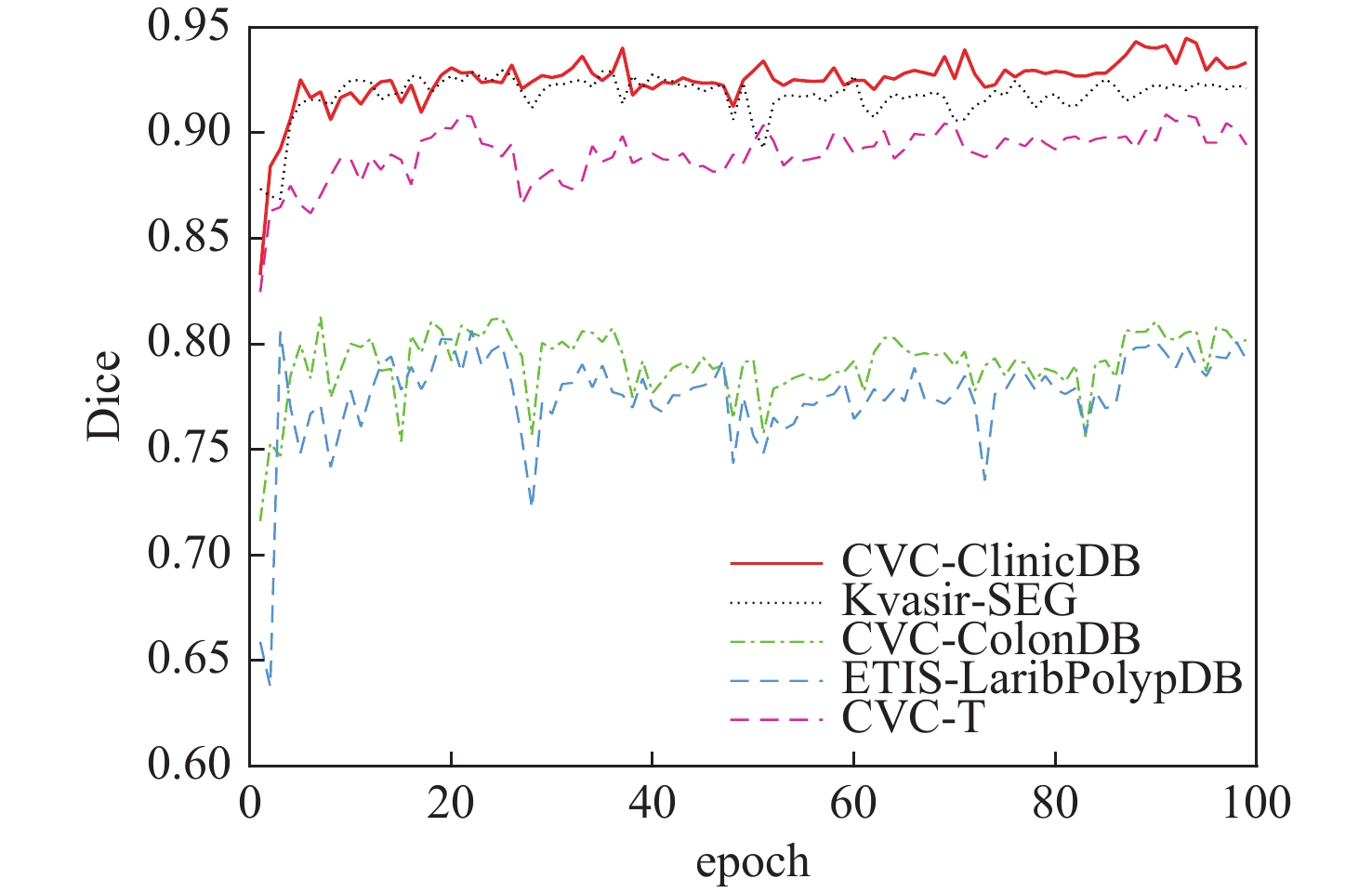
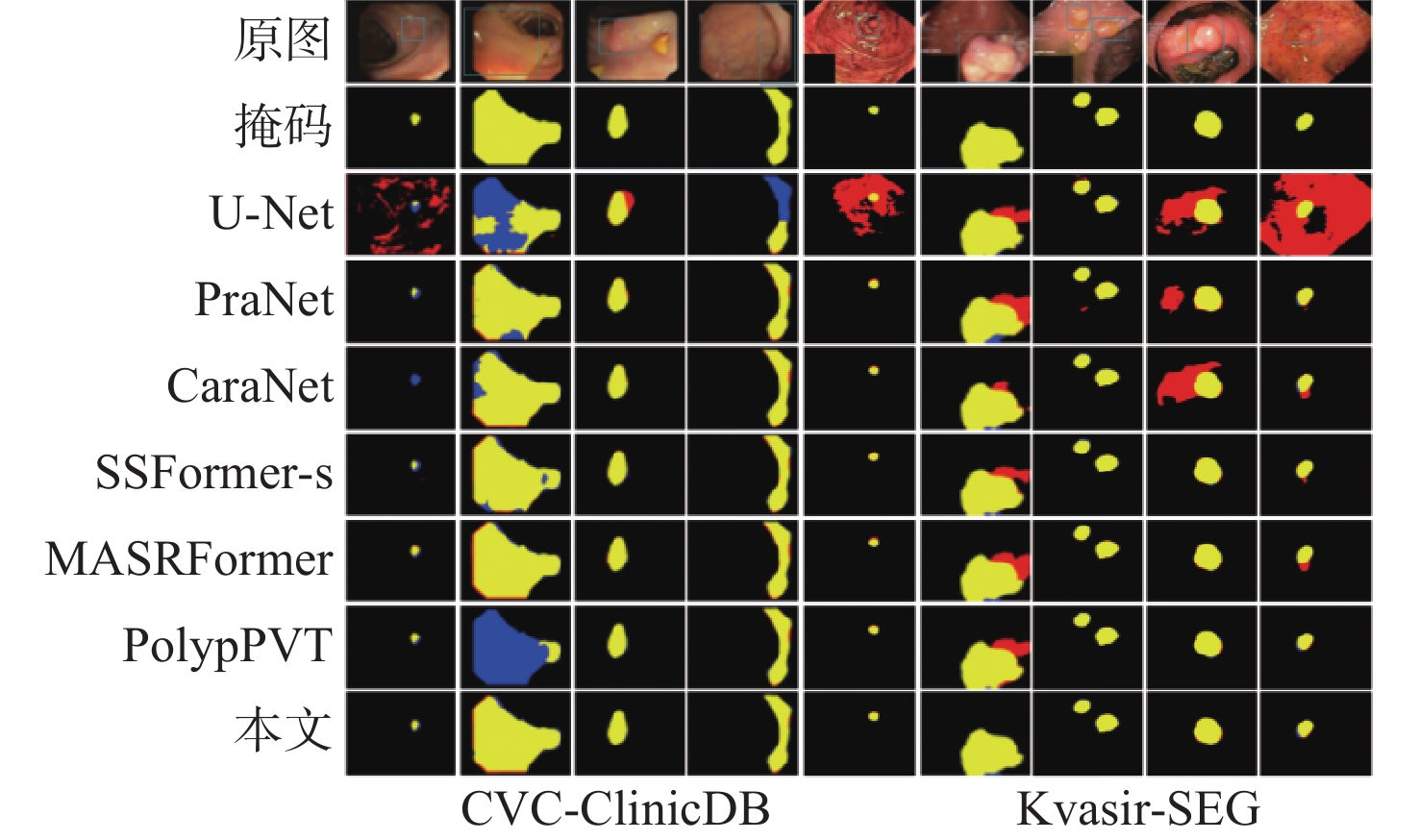
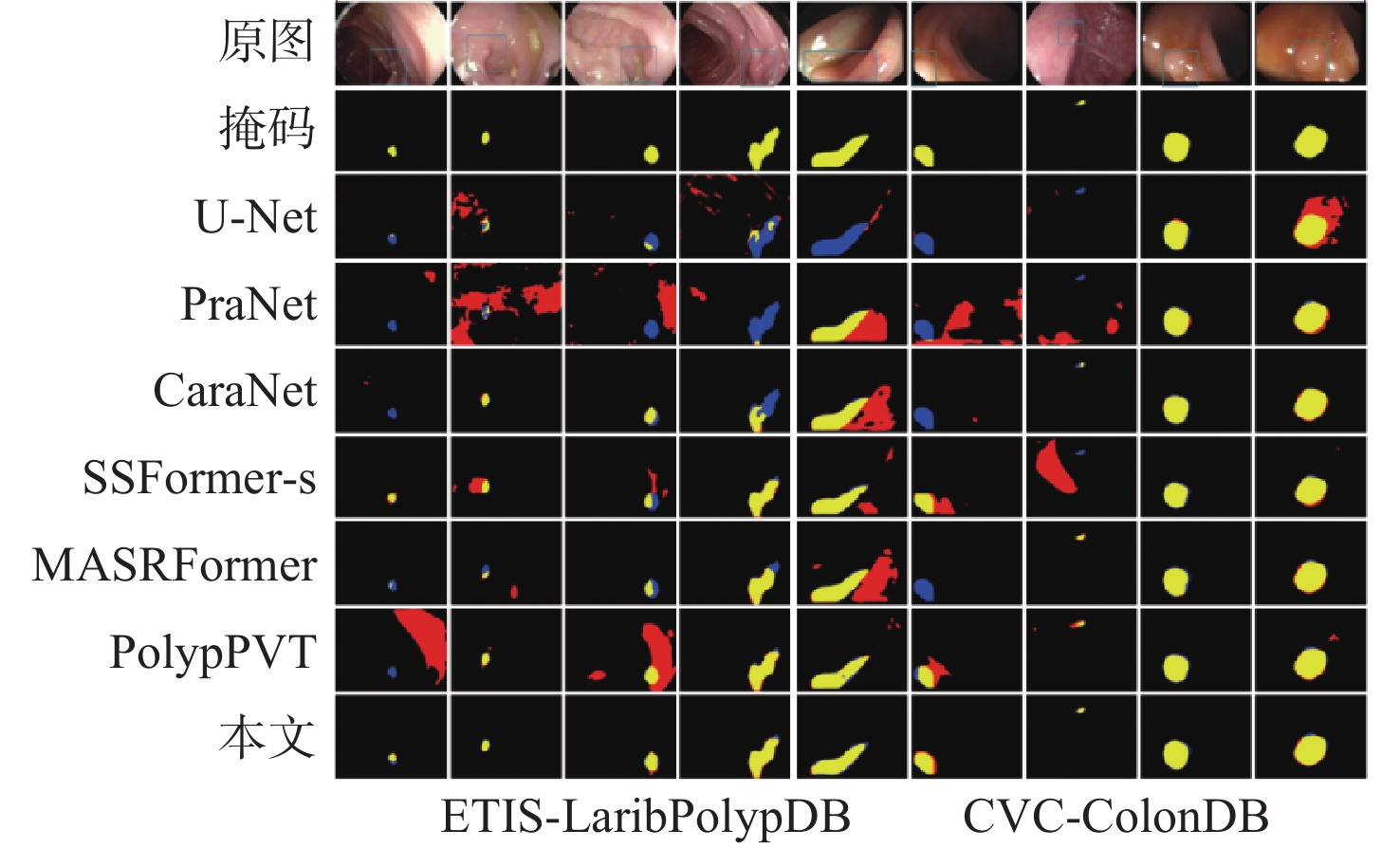






























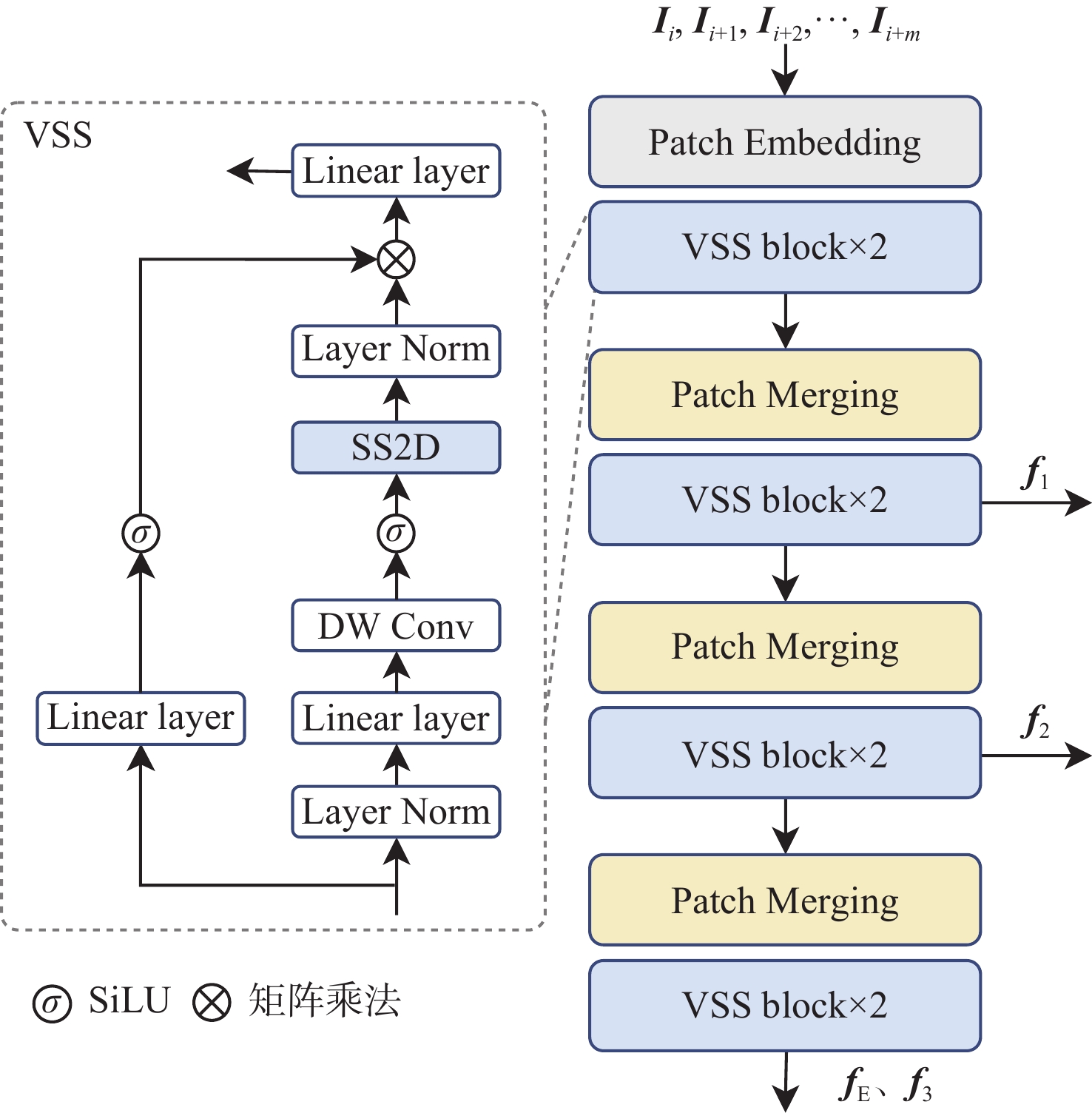

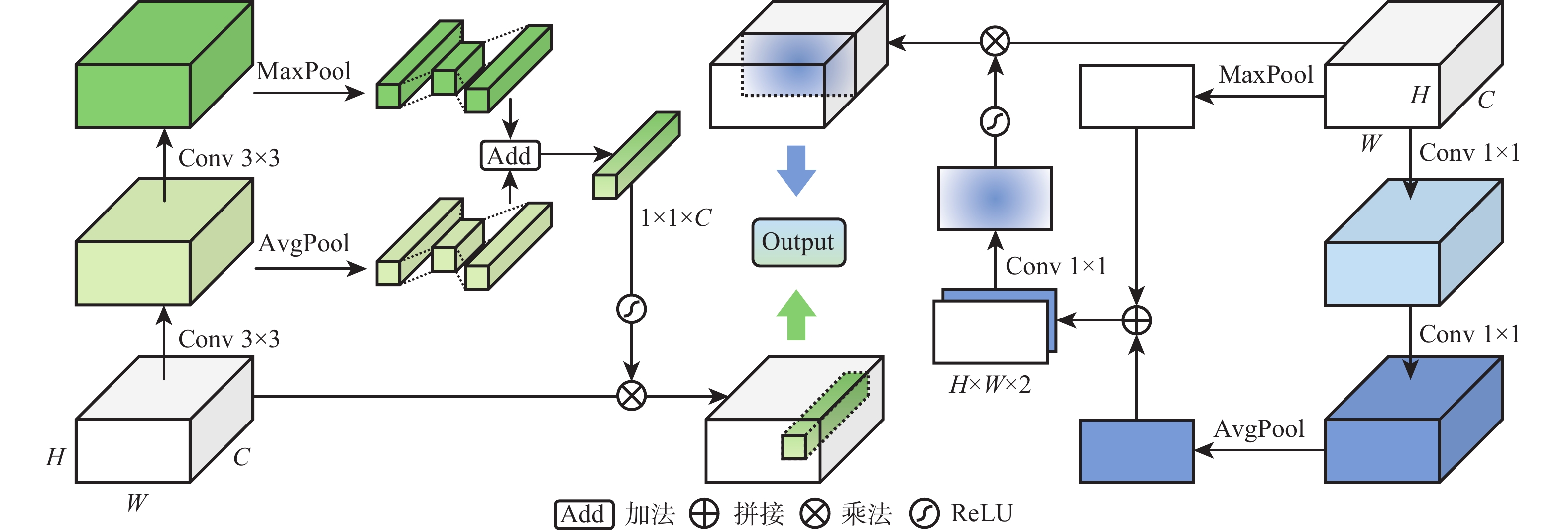
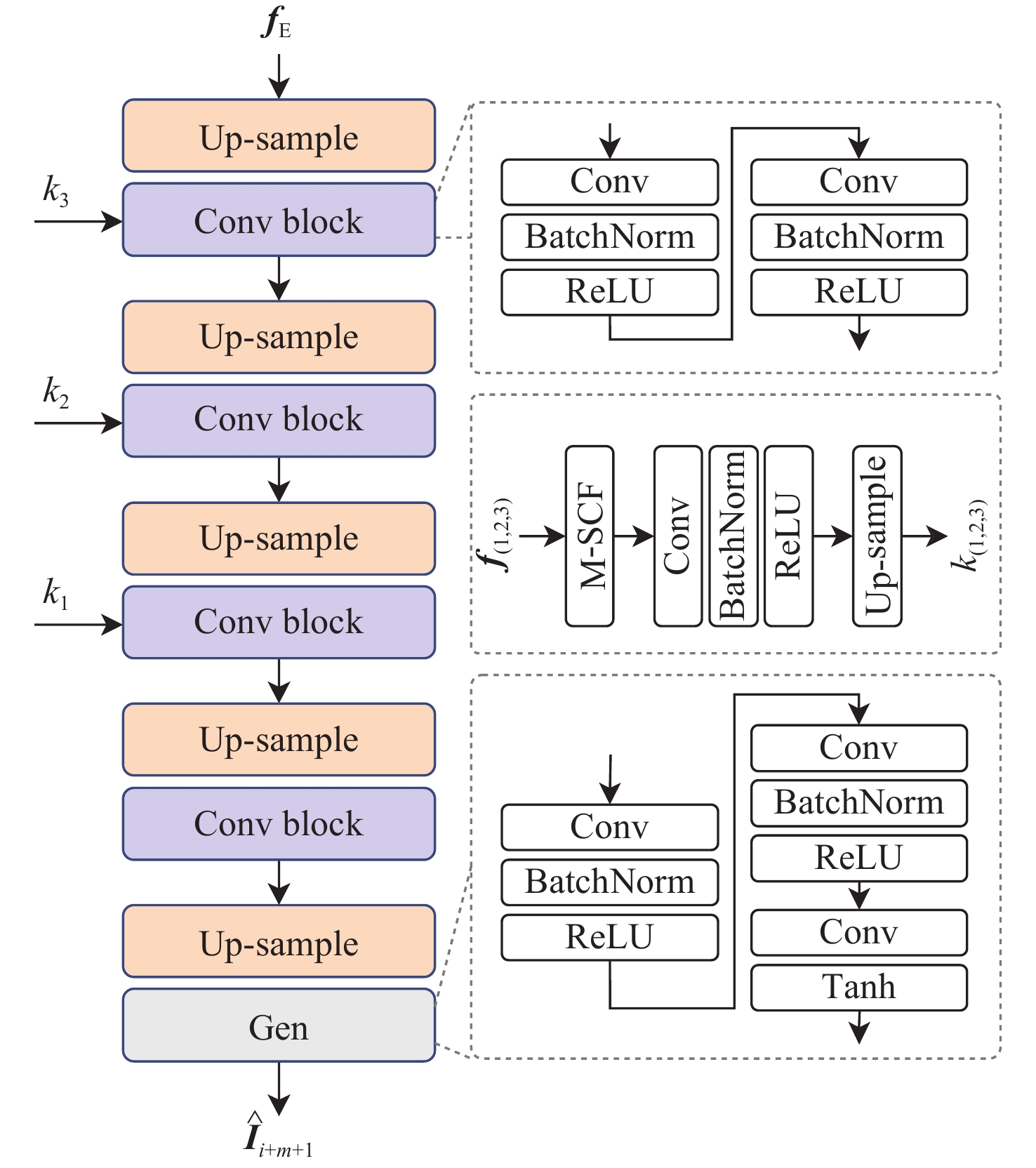

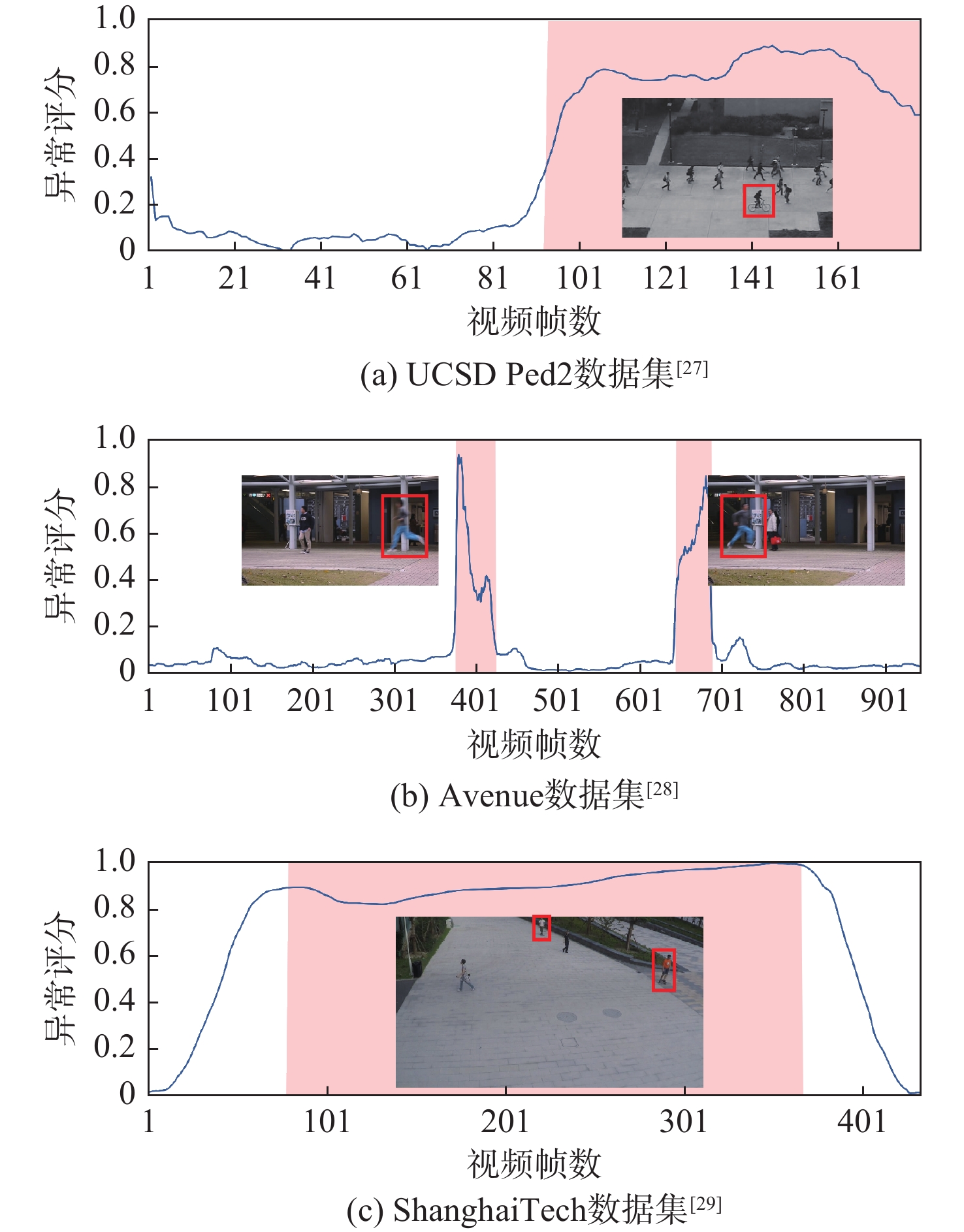




 XML Online Production Platform
XML Online Production Platform
