| Citation: | ZHAO Penghui, MENG Chunning, CHANG Shengjianget al. Single shot multibox detector based on asynchronous convolution factorization and shunt structure[J]. Journal of Beijing University of Aeronautics and Astronautics, 2019, 45(10): 2089-2098. doi: 10.13700/j.bh.1001-5965.2018.0564(in Chinese)

|
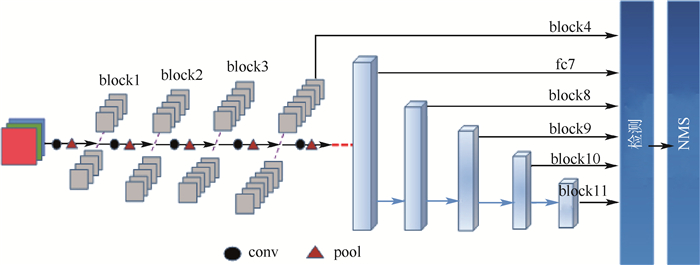
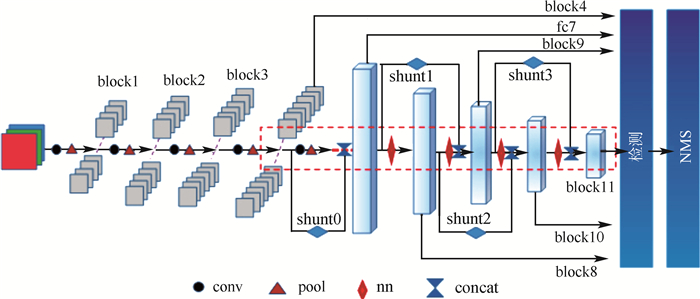
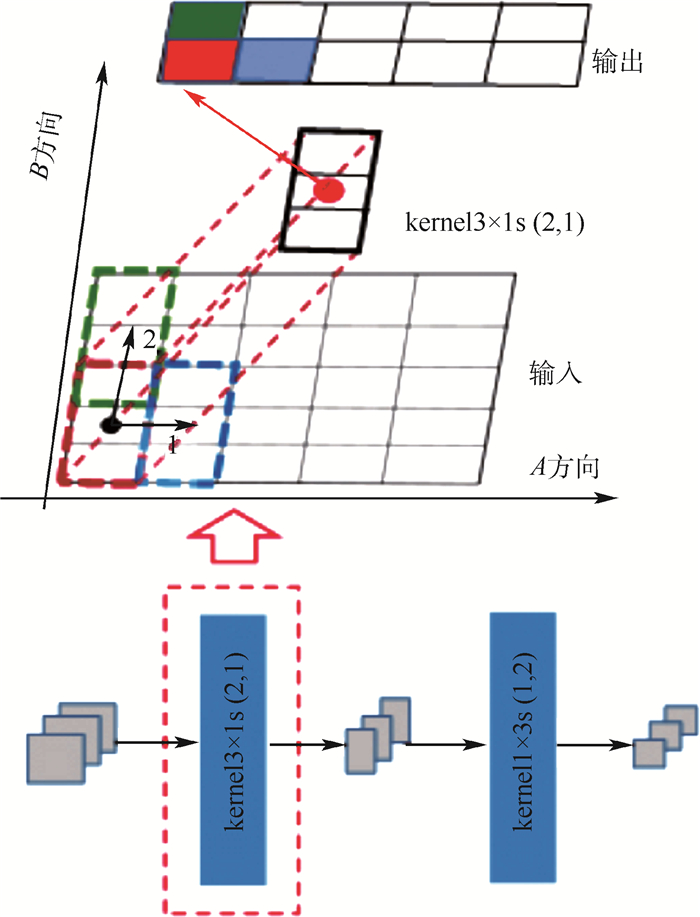
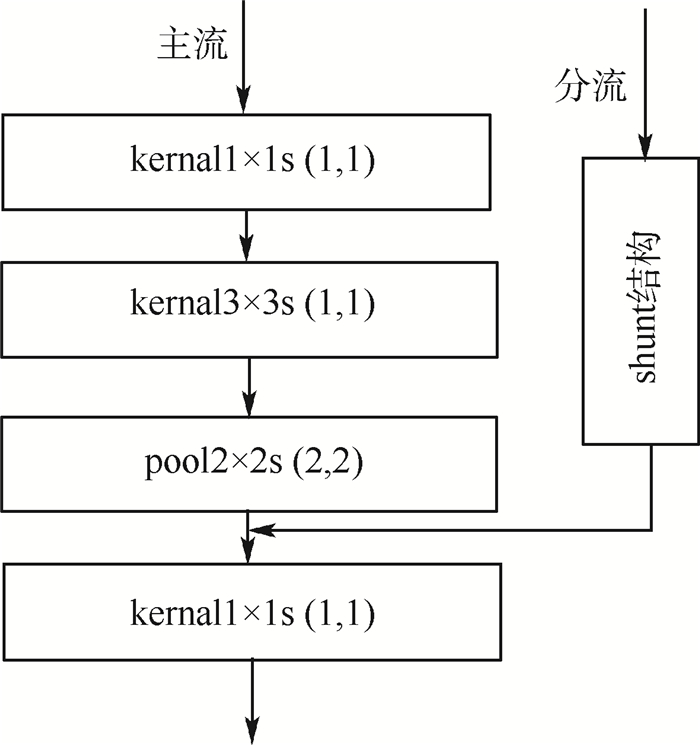
Single shot multibox detector (SSD) owns the relatively independent regression computations of multi-regressive feature maps, while the object detection algorithms based on SSD cannot make a tradeoff between detection accuracy and real-time speed. To solve the problems above, a single shot mutibox detector based on asynchronous convolution factorization and shunt structure (FA-SSD) is introduced based on asynchronous convolution factorization algorithm and shunt structure. The shunt structure, based on the proposed asynchronous convolution factorization algorithm, is designed to staggerly connect the layers of regression features, enhancing the unity and coordination between regression calculations. In order to optimize the mainstream of high-level structure, the asynchronous convolution factorization algorithm and max pooling are implemented to reduce the dimension of image features in the mainstream and shunt respectively, which can hold the spatial information while improving the diversity of features. According to the experimental results from VOC2007test, FA-SSD achieves a mean average precision of 80.5% after the training of VOC2007trainval and VOC2012trainval with nominal resolution of 300×300, while the detection speed exceeds 30 frames per second.
| [1] |
VIOLA P, JONES M.Rapid object detection using a boosted cascade of simple features[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2003: 511-518.
|
| [2] |
DALAL N, TRIGGS B.Histograms of oriented gradients for human detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2005: 886-893.
|
| [3] |
FELZENSZWALB P, MCALLESTER D, RAMANAN D.A discriminatively trained, multiscale, deformable part model[C]//IEEE Computer, Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2008: 1-8.
|
| [4] |
EVERINGHAM M, GOOL L V, WILLIAMS C K I, et al.The pascal, visual object classes (VOC) challenge[J].International Journal of Computer Vision, 2010, 88(2):303-338. doi: 10.2533-chimia.2011.925/
|
| [5] |
李旭冬, 叶茂, 李涛.基于卷积神经网络的目标检测研究综述[J].计算机应用研究, 2017, 34(10):2881-2886. doi: 10.3969/j.issn.1001-3695.2017.10.001
LI X D, YE M, LI T. Review of object detection based on convolutional neural networks[J].Application Research of Computers, 2017, 34(10):2881-2886(in Chinese). doi: 10.3969/j.issn.1001-3695.2017.10.001
|
| [6] |
GIRSHICK R, DONAHUE J, DARRELL T, et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2014: 580-587.
|
| [7] |
HE K, ZHANG X, REN S, et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 37(9):346-361.
|
| [8] |
GIRSHICK R.Fast R-CNN[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2015: 1440-1448.
|
| [9] |
REN S, HE K, GIRSHICK R, et al.Faster R-CNN: Towards real-time object detection with region proposal networks[C]//International Conference on Neural Information Processing Systems.Cambridge: MIT Press, 2015: 91-99.
|
| [10] |
LIN T Y, DOLLAR P, GIRSHICK R, et al.Feature pyramid networks for object detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 936-944.
|
| [11] |
REDMON J, DIVVALA S, GIRSHICK R, et al.You only look once: Unified, real-time object detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2015: 779-788.
|
| [12] |
REDMON J, FARHADI A.YOLO9000: Better, faster, stronger[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 6517-6525.
|
| [13] |
LIU W, ANGUELOV D, ERHAN D, et al.SSD: Single shot multibox detector[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 21-37.
|
| [14] |
REDMON J, FARHADI A.YOLOv3: An incremental improvement[EB/OL].(2018-04-08)[2018-09-21].
|
| [15] |
FU C Y, LIU W, RANGA A, et al.DSSD: Deconvolutional single shot detector[EB/OL].(2017-01-23)[2018-09-21].
|
| [16] |
SHEN Z, LIU Z, LI J, et al.DSOD: Learning deeply supervised object detectors from scratch[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 1937-1945.
|
| [17] |
SIMONYAN K, ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[EB/OL].(2015-03-10)[2018-09-21].
|
| [18] |
HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2015: 770-778.
|
| [19] |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al.Rethinking the inception architecture for computer vision[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 2818-2826.
|
| [20] |
IOFFE S, SZEGEDY C.Batch normalization: Accelerating deep network training by reducing internal covariate shift[EB/OL].(2015-03-02)[2018-09-26].
|
| [21] |
RUSSAKOVSKY O, DENG J, SU H, et al.ImageNet large scale visual recognition challenge[J].International Journal of Computer Vision, 2015, 115(3):211-252.
|
| [22] |
BELL S, ZITNICK C L, BALA K, et al.Inside-outside Net: Detecting objects in context with skip pooling and recurrent neural networks[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 2874-2883.
|
| [23] |
DAI J, LI Y, HE K, et al.R-FCN: Object detection via region-based fully convolutional networks[EB/OL].(2016-06-21)[2018-09-26].
|
| [24] |
HE K, GKIOXARI G, DOLLAR P, et al.Mask R-CNN[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 1-13.
|
| [1] | QI C,XIE J W,FEI T Y,et al. Research on target detection performance of PA-MIMO radar based on channel reciprocity[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(1):214-221 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.1014. |
| [2] | ZHENG J,HE Z H,YU X C. One-stage object detection based on adjacent feature fusion and feature decoupling[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(4):1205-1214 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0249. |
| [3] | MA S G,LI N B,HOU Z Q,et al. Object detection algorithm based on DSGIoU loss and dual branch coordinate attention[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(4):1085-1095 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0192. |
| [4] | LU S Q,GUAN F X,LAI H T,et al. Two-stage underwater image enhancement method based on convolutional neural networks[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(1):321-332 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.1003. |
| [5] | BAI C P,ZHANG S Y,ZHANG X,et al. Spaceborne particle identification platform and application based on convolutional neural network[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(4):1313-1323 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0171. |
| [6] | ZHANG Wenfei, ZHANG Huawei, MEI Yuan, XIAO Nan, ZHU Qiudong, LIAN Jing. A DINO remote sensing target detection algorithm combining efficient hybrid encoder and structural reparameterization[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0320 |
| [7] | LI H G,WANG Y F,YANG L C. Meta-learning-based few-shot object detection for remote sensing images[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(8):2503-2513 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0637. |
| [8] | CHEN Hong, YAN Jianguo, YANG Hua, ZHANG Jing, LI Wei, YANG Jing. Deep separable convolutional neural networks based on Structural Reparameterization[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0287 |
| [9] | LI H,ZHONG H P,ZHANG P,et al. Multi-shift interferometric phase filtering method based on convolutional neural network[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(6):2043-2050 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0805. |
| [10] | WANG J,LI P T,ZHAO R F,et al. A person re-identification method for fusing convolutional attention and Transformer architecture[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):466-476 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0456. |
| [11] | LI Y H,YU H K,MA D F,et al. Improved transfer learning based dual-branch convolutional neural network image dehazing[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(1):30-38 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0253. |
| [12] | CHEN C,ZHAO W. Remote sensing target detection based on dynanic feature selection[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(3):702-709 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0300. |
| [13] | LIU S D,LIU Y H,SUN Y M,et al. Small object detection in UAV aerial images based on inverted residual attention[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(3):514-524 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0362. |
| [14] | ZHANG Y Z,LI W B,ZHENG T T. Inverted residual target detection algorithm based on LGC[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(6):1287-1293 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0452. |
| [15] | DAI P Z,LIU X,ZHANG X,et al. An iterative pedestrian detection method sensitive to historical information features[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(9):2493-2500 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0665. |
| [16] | LI C X,LI T Y,LI Z Z,et al. Intelligent algorithm of warship’s vital parts detection, trajectory prediction and pose estimation[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(2):444-456 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0253. |
| [17] | CHEN S Z,LI D C,XIANG J W. Design optimization of tow-steered composite structure targeting on manufacturing cost[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(9):2423-2431 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0677. |
| [18] | ZHOU H,HOU Q Y,BIAN C J,et al. An infrared small target detection network under various complex backgrounds realized on FPGA[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(2):295-310 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0221. |
| [19] | LU H B,CAI Y J,LI S. Optimization method of thermo-elastic lattice structure based on surrogate models of microstructures[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(12):3432-3444 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0155. |
| [20] | CHENG Keyang, RONG Lan, JIANG Senlin, ZHAN Yongzhao. Double drive adaptive super-resolution reconstruction method of remote sensing images for object detection[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(8): 1343-1352. doi: 10.13700/j.bh.1001-5965.2021.0517 |
| 1. | 芦杉. 异步服务的以太网流量监测系统设计. 自动化与仪器仪表. 2022(02): 100-103 .  |


Figures(13) / Tables(2)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.

Liu Ruigang, Cheng Dan, Yang Qin, et al. Triangle mesh optimization based on DSI interpolation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2008, 34(02): 162-166. (in Chinese)





 DownLoad:
DownLoad: