| Citation: | WANG Xin, LI Zhe, ZHANG Hongliet al. High-resolution network Anchor-free object detection method based on iterative aggregation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(12): 2533-2541. doi: 10.13700/j.bh.1001-5965.2020.0484(in Chinese)

|
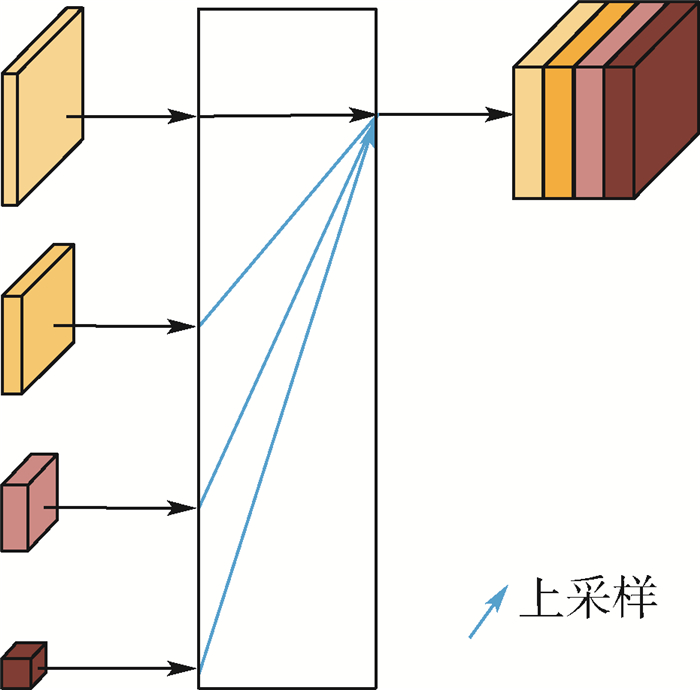
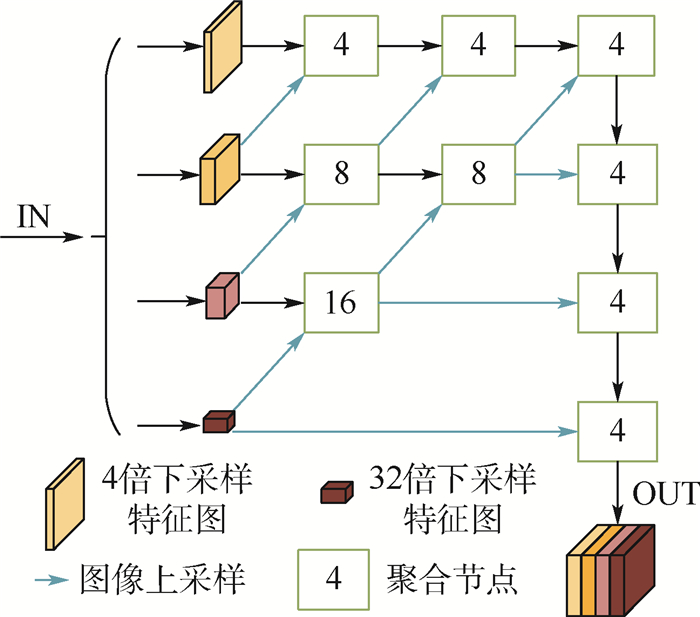
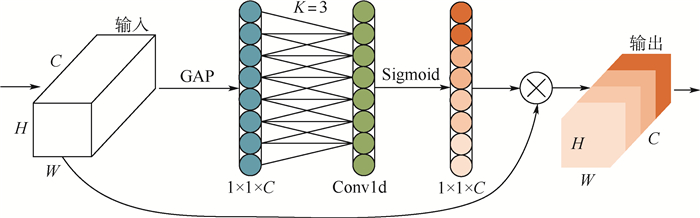
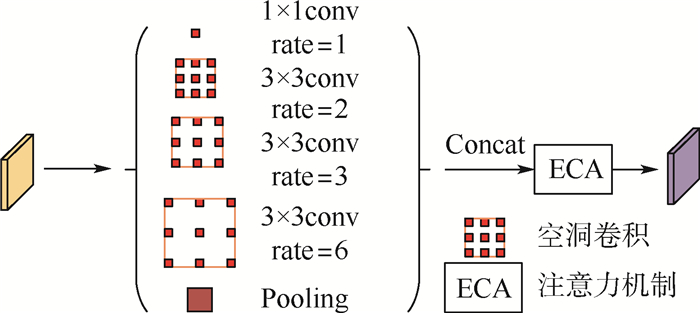
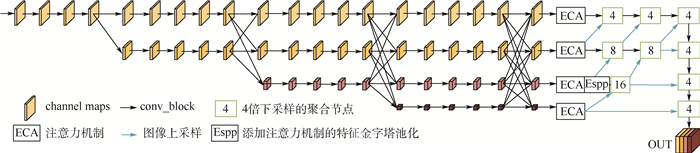
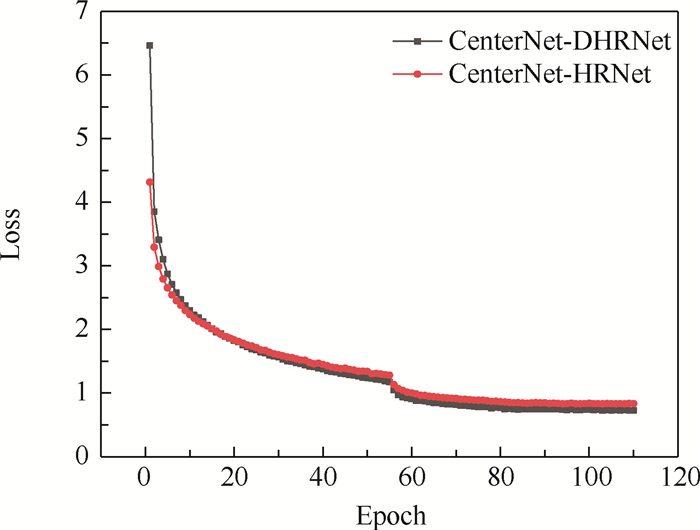
In order to solve the problems of inaccuracy in heat map generation and insufficient detection accuracy of anchor-free object detection method CenterNet (Objects as Points), a high-resolution representation network CenterNet-DHRNet based on feature iterative aggregation is proposed. First, for the purpose of improving the resolution of the network and reducing the spatial semantic information lost in the image downsampling process, a high-resolution representation backbone network is introduced and low-resolution features are fully fused by iterative deep aggregation. Then, an efficient attention mechanism is used to optimize the output of the high-resolution representation backbone network. Finally, the spatial pyramid pooling with dilated convolution is used to enhance the network's receptive field for objects of different scales. The experiment is carried out on PASCAL VOC dataset and KITTI dataset, and the experimental results show that CenterNet-DHRNet has higher accuracy, meets the performance requirements of real-time detection and has good robustness.
| [1] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. doi: 10.1023%2FB%3AVISI.0000029664.99615.94.pdf
|
| [2] |
蒋弘毅, 王永娟. 目标检测模型及其优化方法综述[J]. 自动化学报, 2021, 47(6): 1232-1255.
JIANG H Y, WANG Y J. A survey of object detection models and its optimization methods[J]. Acta Automatica Sinica, 2021, 47(6): 1232-1255(in Chinese).
|
| [3] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2014: 580-587.
|
| [4] |
GIRSHICK R. Fast R-CNN[C]//International Conference on Computer Vision. Piscataway: IEEE Press, 2015: 1440-1448.
|
| [5] |
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031
|
| [6] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2016: 779-788.
|
| [7] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
|
| [8] |
LAW H, DENG J. CornerNet: Detecting objects as paired keypoints[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 765-781.
|
| [9] |
TIAN Z, SHEN C, CHEN H, et al. FCOS: Fully convolutional one-stage object detection[C]//International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 9626-9635.
|
| [10] |
ZHOU X, ZHUO J, KRAHENBUHL P, et al. Bottom-up object detection by grouping extreme and center points[EB/OL]. (2019-04-25)[2020-08-20].
|
| [11] |
ZHOU X, WANG D, KRAHENBUHL P, et al. Objects as points[EB/OL]. (2019-04-25)[2020-08-20].
|
| [12] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2016: 770-778.
|
| [13] |
XIAO B, WU H, WEI Y, et al. Simple baselines for human pose estimation and tracking[EB/OL]. (2018-08-21)[2020-08-20].
|
| [14] |
YU F, WANG D, SHELHAMER E, et al. Deep layer aggregation[EB/OL]. (2019-01-04)[2020-08-20].
|
| [15] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2020-08-20].
|
| [16] |
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[EB/OL]. [2020-08-20].
|
| [17] |
WANG Q, WU B, ZHU P, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2019: 11534-11542.
|
| [18] |
HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2019: 7132-7141.
|
| [19] |
CHEN L, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[EB/OL]. (2018-03-08)[2020-08-20].
|
| [20] |
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. (2016-04-30)[2020-08-20].
|
| [21] |
LIN T, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[EB/OL]. (2018-03-07)[2020-08-20].
|
| [22] |
FU C, LIU W, RANGA A, et al. DSSD: Deconvolutional single shot detector[EB/OL]. [2020-08-20].
|
| [23] |
DAI J, LI Y, HE K, et al. R-FCN: Object detection via region-based fully convolutional networks[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems December. New York: ACM, 2016: 379-387.
|
| 1. | 侯志强,郭浩,马素刚,程环环,白玉,范九伦. 基于双分支特征融合的无锚框目标检测算法. 电子与信息学报. 2022(06): 2175-2183 .  | |
| 2. | 于方程,张小俊,张明路,赵天亮. 基于改进CenterNet的自动驾驶小目标检测. 电子测量技术. 2022(15): 115-122 . | |
| 3. | 李晨瑄,顾佼佼,王磊,钱坤,冯泽钦. 多尺度特征融合的Anchor-Free轻量化舰船要害部位检测算法. 北京航空航天大学学报. 2022(10): 2006-2019 .  本站查看 本站查看 |


Figures(10) / Tables(6)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.

Xie Yu, Liu Luhua, Tang Guojian, et al. Design and analysis of interception project for multiple kill vehicle interceptor[J]. Journal of Beijing University of Aeronautics and Astronautics, 2012, (3): 303-308. (in Chinese)





 DownLoad:
DownLoad: