| Citation: | ZHANG Tingting, LAN Yushi, SONG Aiguoet al. Behavioral decision learning reward mechanism of unmanned swarm system[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(12): 2442-2451. doi: 10.13700/j.bh.1001-5965.2020.0600(in Chinese)

|
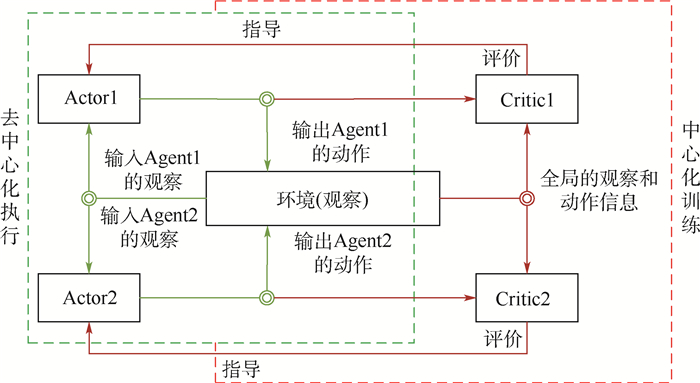
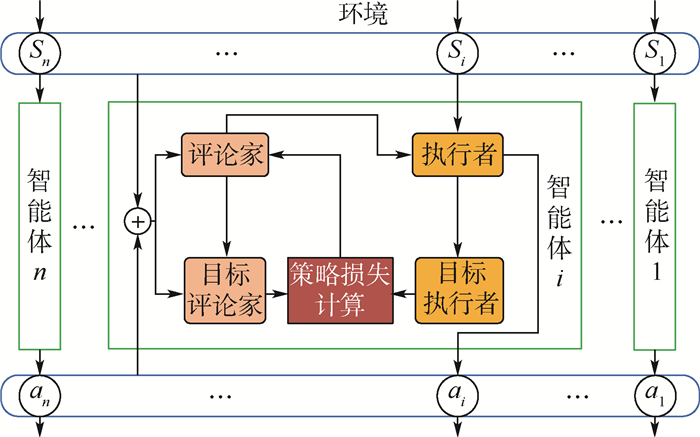
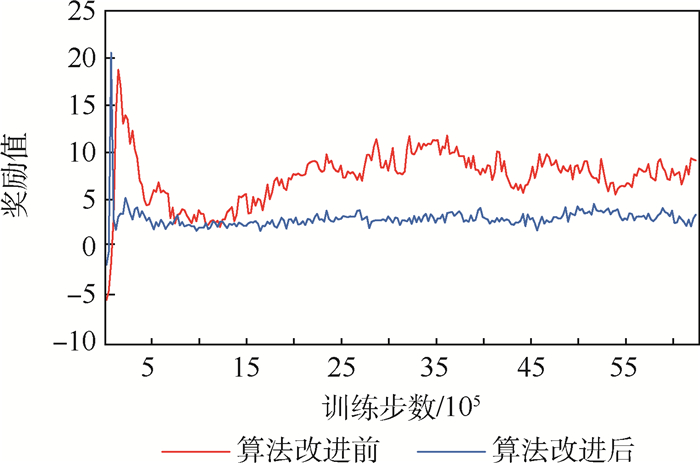
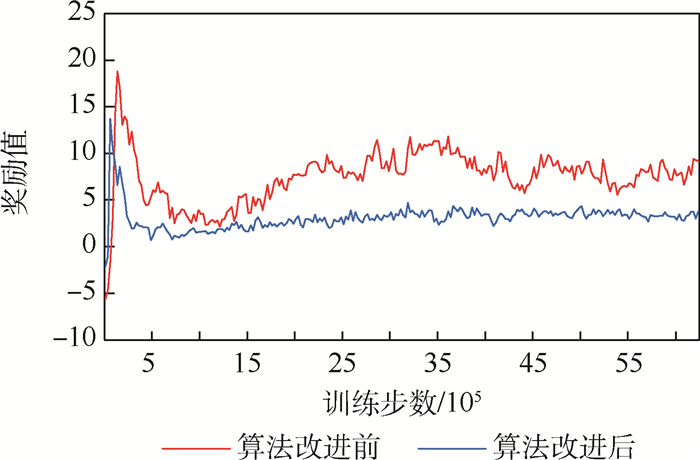
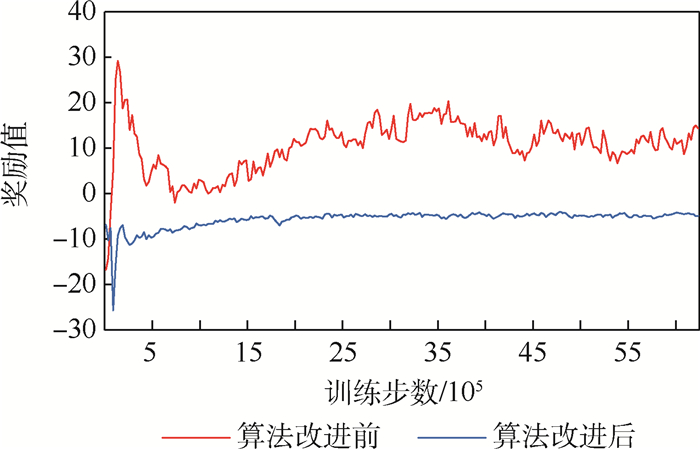
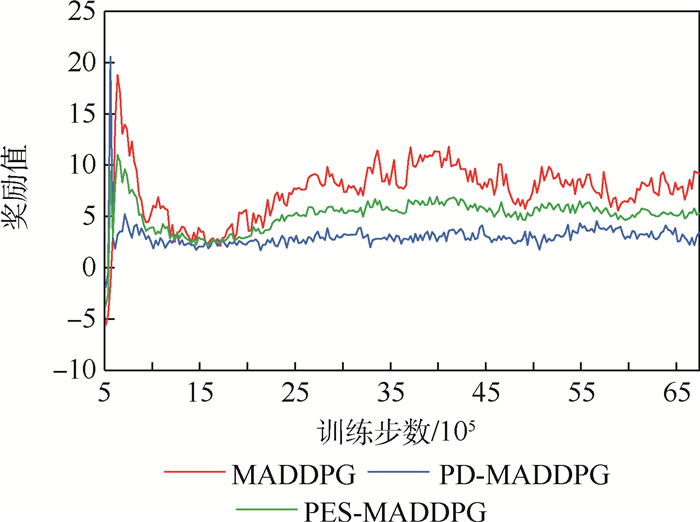
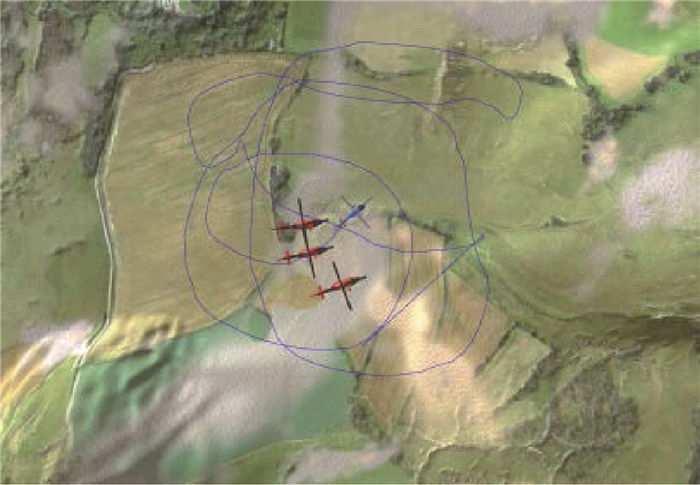
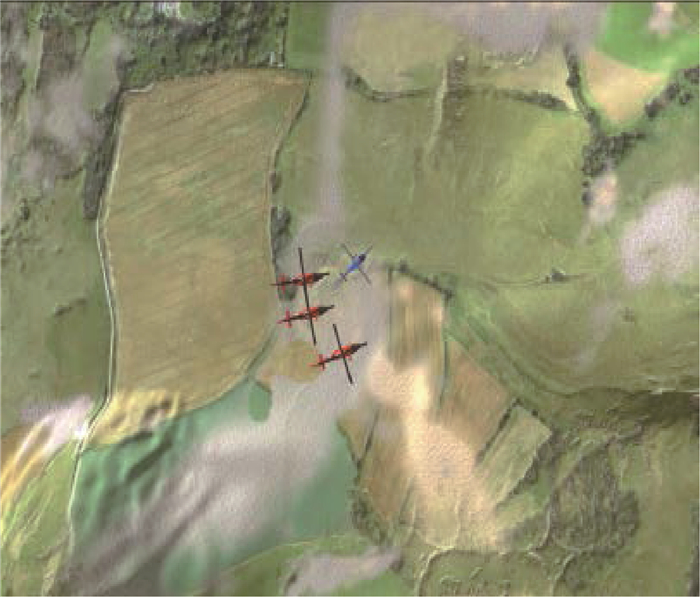
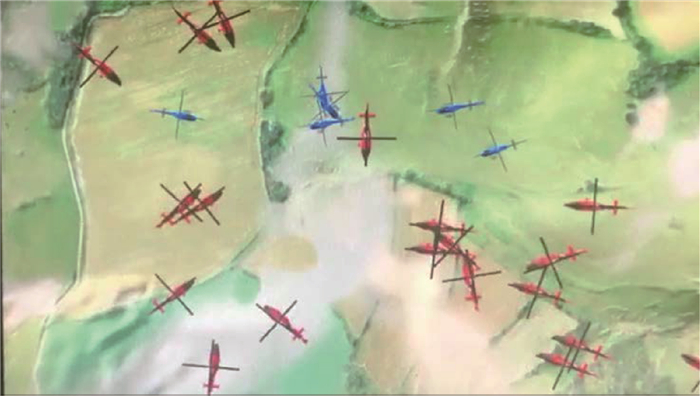
Unmanned swarm system is composed of a multi-agent system, which can meet task requirements through autonomous and cooperative behavior. The instability of agent training is increased because agents adopt behavior and change states autonomously. In this paper, the prior constraints and the isomorphism between agents are used to enhance the real-time performance of reward signals and improve the efficiency of training and the stability of learning. Specifically, it includes the punishment of action space boundary collision and the reward for the satisfaction degree of the space-time distance constraint between agents. At the same time, through the relationship characteristics of agents in the group, experience sharing among agents is increased to further optimize the learning efficiency. In the experiment, the prior enhanced reward mechanism and experience sharing are applied to the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm to verify its effectiveness. It is observed that the learning convergence and stability are greatly improved, and thus the behavior learning efficiency of unmanned swarm system is enhanced.
| [1] |
张婷婷, 宋爱国, 蓝羽石. 集群无人系统自适应结构建模与预测[J]. 中国科学: 信息科学, 2020, 50(1): 347-362.
ZHANG T T, SONG A G, LAN Y S. Adaptive structure modeling and prediction of cluster unmanned system[J]. Chinese Science: Information Science, 2020, 50(1): 347-362(in Chinese).
|
| [2] |
孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46(7): 1301-1309.
SUN C Y, MU C X. Important scientific problems of multi-agent deep reinforcement learning [J]. Journal of Automatica Sinica, 2020, 46(7): 1301-1309(in Chinese).
|
| [3] |
陈杰. 多智能体系统中的几个问题[J]. 中国科学人, 2019, 12(1): 40-43.
CHEN J. Several problems in multi-agent system [J]. Scientific Chinese, 2019, 12(1): 40-43(in Chinese).
|
| [4] |
LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[EB/OL]. (2020-03-14)[2020-03-22].
|
| [5] |
许诺, 杨振伟. 稀疏奖励下基于MADDPG算法的多智能体协同[J]. 现代计算机, 2020(15): 47-51.
XU N, YANG Z W. Multi-agent collaboration based on MADDPG algorithm under sparse reward[J]. Modern Computer, 2020(15): 47-51(in Chinese).
|
| [6] |
杨慧慧, 黄万荣, 敖富江. 基于强化学习的鱼群自组织行为模拟[J]. 国防科技大学学报, 2020, 42(1): 194-202.
YANG H H, HUANG W R, AO F J. Simulation on self-organization behaviors of fish school based on reinforcement learning[J]. Journal of National University of Defense Technology, 2020, 42(1): 194-202(in Chinese).
|
| [7] |
王毅然, 经小川, 贾福凯, 等. 基于多智能体协同强化学习的多目标追踪方法[J]. 计算机工程, 2020, 46(11): 90-96. doi: 10.3778/j.issn.1002-8331.1911-0132
WANG Y R, JING X C, JIA F K, et al. Multi-target tracking method based on multi-agent collaborative reinforcement learning[J]. Computer Engineering, 2020, 46(11): 90-96(in Chinese). doi: 10.3778/j.issn.1002-8331.1911-0132
|
| [8] |
邹长杰, 郑皎凌, 张中雷. 基于GAED-MADDPG多智能体强化学习的协作策略研究[J]. 计算机应用研究, 2020, 37(12): 3656-3661.
ZOU C J, ZHENG J L, ZHANG Z L. Research on collaborative strategy based on GAED-MADDPG multi-agent reinforcement learning[J]. Application Research of Computers, 2020, 37(12): 3656-3661(in Chinese).
|
| [9] |
高昂, 董志明, 李亮, 等. MADDPG算法并行优先经验回放机制[J]. 系统工程与电子技术, 2021, 43(2): 420-433.
GAO A, DONG Z M, LI L, et al. Parallel priority experience replay mechanism algorithm of MADDPG[J]. Systems Engineering and Electronics, 2021, 43(2): 420-433(in Chinese).
|
| [10] |
WEIREN K, DEYUN Z, ZHEN Y. Air combat strategies generation of CGF based on MADDPG and reward shaping[C]//2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL). Piscataway: IEEE Press, 2020: 651-655.
|
| [11] |
SUN Y, LAI J, CAO L, et al. A novel multi-agent parallel-critic network architecture for cooperative-competitive reinforcement learning[J]. IEEE Access, 2020, 8: 135605-135616. doi: 10.1109/ACCESS.2020.3011670
|
| [12] |
ZHU P, DAI W, YAO W, et al. Multi-robot flocking control based on deep reinforcement learning[J]. IEEE Access, 2020, 8: 150397-150406. doi: 10.1109/ACCESS.2020.3016951
|
| [13] |
VAN OTTERLO M, WIREING M. Reinforcement learning and Markov decision processes[M]//WIREING M, VAN OTTERLO M. Reinforcement learning. Berlin: Springer, 2012: 3-42.
|
| [14] |
陈亮, 梁宸, 张景异, 等. Actor-Critic框架下一种基于改进DDPG的多智能体强化学习算法[J]. 控制与决策, 2021, 36(1): 75-82.
CHEN L, LIANG C, ZHANG J Y, et al. A multi-agent reinforcement learning algorithm based on improved DDPG under actor critical framework[J]. Control and Decision, 2021, 36(1): 75-82(in Chinese).
|
| [15] |
孙彧, 曹雷, 陈希亮, 等. 多智能体深度强化学习研究综述[J]. 计算机工程与应用, 2020, 56(5): 13-24.
SUN Y, CAO L, CHEN X L, et al. A review of multi-agent deep reinforcement learning research[J]. Computer Engineering and Application, 2020, 56(5): 13-24(in Chinese).
|
| [1] | WANG Shiqi, LU Hui, ZHANG Yuxuan. Hexagonal grid sampling method for low-dimensional decision boundary identification[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0526 |
| [2] | ZHAO Guiling, WANG Jinbao, WANG Yuan. A SINS/GNSS fault detection and robustness adaptive algorithm based on maximum smooth bounded layer width[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0777 |
| [3] | Cao Yueyao, Xue Tao, He Shanshan, Ai Jianliang, Dong Yiqun. Calculation of Beyond Visual Range Air Combat All-Domain Fire Field and Application of Situation Threat Assessment and Assisted Decision Making[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0399 |
| [4] | CHANG Jiaming, LI Sulan, DUAN Xuechao, ZHANG Wei, WANG Chenyang. Anti-stochastic disturbance control of airship[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0489 |
| [5] | ZHU C C,TANG Z L,ZHAO X,et al. Multi-objective hybrid algorithm based on gradient search and evolution mechanism[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(6):1940-1951 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0544. |
| [6] | LIANG Zhen-feng, XIA Hai-ying, TAN Yu-mei, SONG Shu-xiang. Aerial Image Stitching Algorithm Based on Unsupervised Deep Learning[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0366 |
| [7] | HAN Y,SUN B B,WANG J G,et al. Target person analysis based on critical node recognition algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(7):2074-2082 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0588. |
| [8] | MAO Q H,WANG Y G,NIU X H. Improved mayfly optimization algorithm based on anti-attraction velocity update mechanism[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(6):1770-1783 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0550. |
| [9] | WANG Z K,HUANG X Y,ZHU D L,et al. Learning sparrow search algorithm of hybrids boundary processing mechanisms[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(1):286-298 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0195. |
| [10] | KE Y,LYU Z W,ZHOU W L,et al. Tightly-coupled GNSS/INS spoofing detection algorithm for LS-SVM and robust estimation[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(1):299-307 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0231. |
| [11] | HE Xiongfeng, LU Wei, XU Nuo, ZHOU Qixian, WANG Pengcheng, ZHANG Yonghe. Disturbance Rejection Model Predictive Control for Building Drag-free Steady State[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0380 |
| [12] | ZUO L,ZHANG X L,LI Z Y,et al. UAV control law design method based on active-disturbance rejection control[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(5):1512-1522 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0488. |
| [13] | SHENG Qi, SUN Rui, HE Yulin, ZHANG Hengyu. A robust adaptive positioning algorithm for GNSS/IMU based on 3D grid error modeling[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0169 |
| [14] | ZHAO Gui-ling, WANG Jin-bao, JIANG Zi-hao, GAO Shuai. A GNSS/SINS fault detection and robust adaptive algorithm based on two parameters[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0822 |
| [15] | PENG Yu-xiao, HE Zhen, CHOU Jing-wen. Active Deformation Decision-Making for a Four-wing Variable Sweep Aircraft based on LSTM-DDPG Algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0513 |
| [16] | ZHANG Dong-dong, WANG Chun-ping, FU Qiang. Camouflaged Object Detection Network Based on Human Visual Mechanisms[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0511 |
| [17] | JIANG Xun, XU Xing, SHEN Fu-min, WANG Guo-qing, YANG Yang. Efficient Weakly-Supervised Video Moment Retrieval without Multimodal Fusion[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0379 |
| [18] | ZHANG B H,CHAI D D,MENG L B,et al. Anti-occlusion target tracking algorithm of UAV based on multiple detection[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(9):2442-2454 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0693. |
| [19] | WANG Z Q,LI J,LI J,et al. UAV swarm decision methods under weak information interaction conditions[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(12):3489-3499 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0066. |
| [20] | ZHANG Libo, LI Yupeng, ZHU Deming, FU Yongling. Inverse kinematic solution of nursing robot based on genetic algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(10): 1925-1932. doi: 10.13700/j.bh.1001-5965.2021.0042 |


Figures(14) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.

Wang Wenwen, Diao Xungang, Wang Zheng, et al. Optical, electrical and infrared emissing properties of DC magnetron sputtered ZnO:Al thin films[J]. Journal of Beijing University of Aeronautics and Astronautics, 2005, 31(02): 236-241. (in Chinese)





 DownLoad:
DownLoad: