| Citation: | NIU G C,WANG X N. A multi-task traffic scene detection model based on cross-attention[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(5):1491-1499 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0610

|
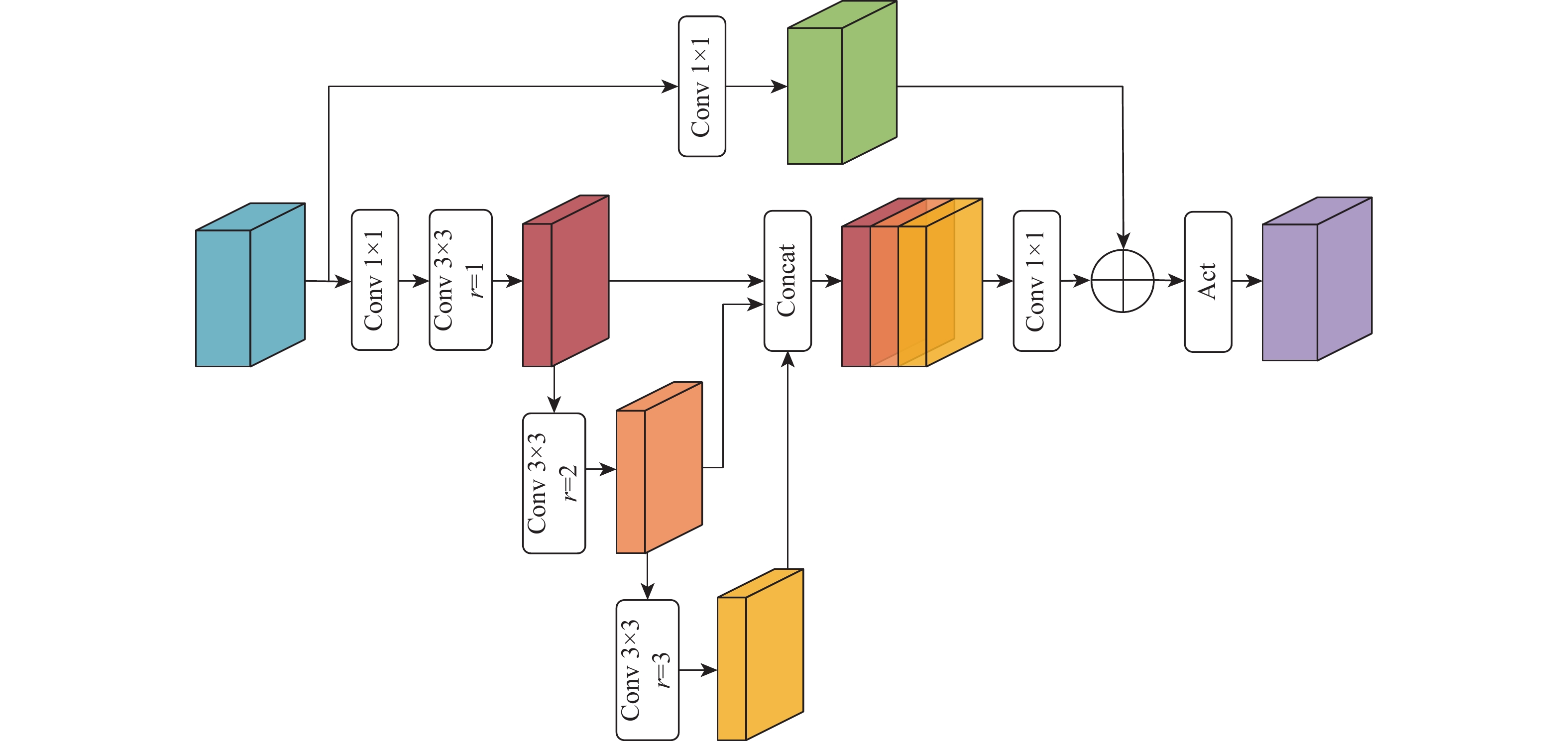
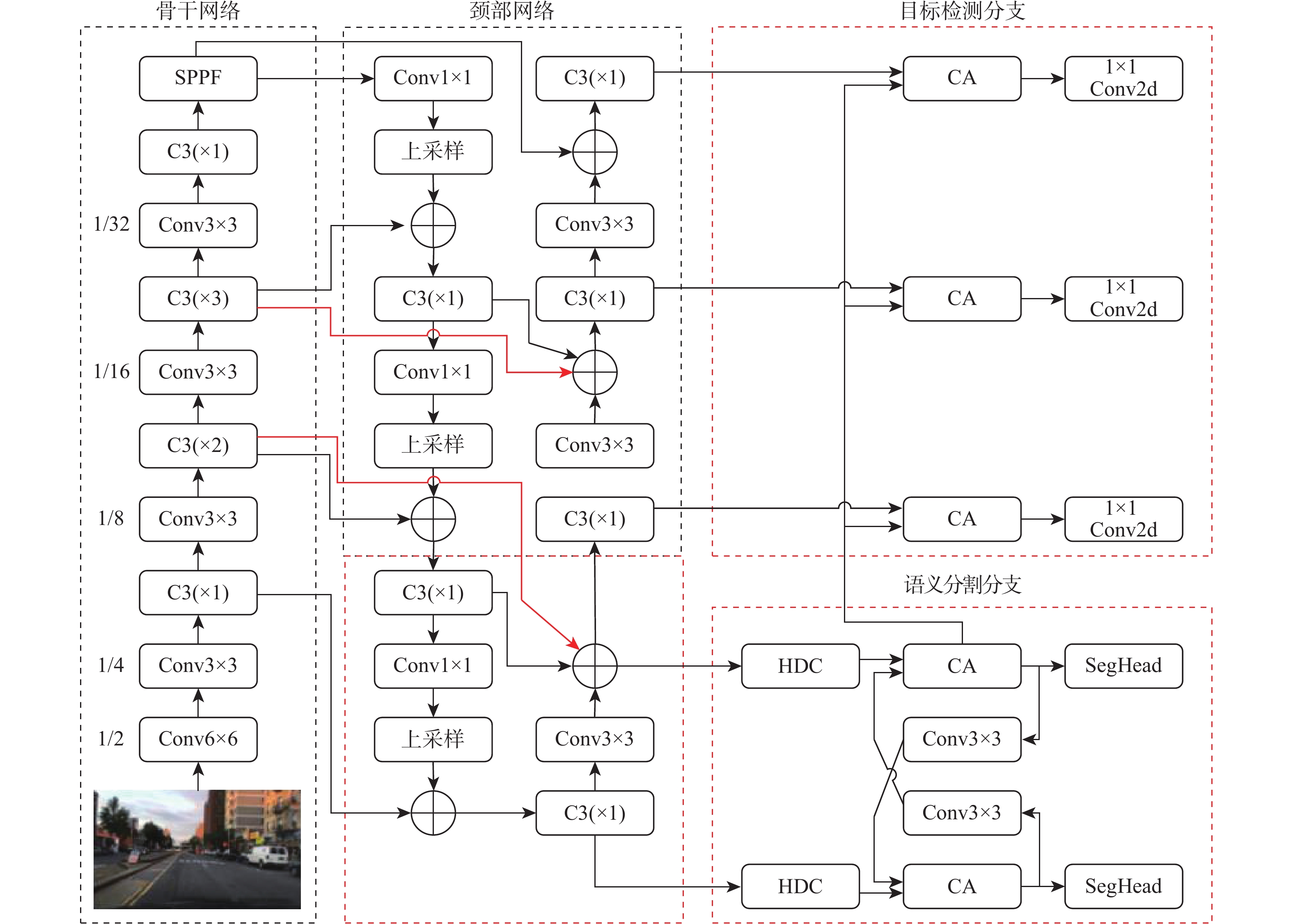
Perception is the foundation and key issue to autonomous driving, but most single models can’t simultaneously complete multiple detection tasks such as traffic objects, drivable areas, and lane lines. This paper proposes a multi-task traffic scene detection model based on cross-attention, which can detect traffic objects, drivable areas and lane lines simultaneously. Firstly, the encoder-decoder network is used to extract the initial feature maps. Subsequently, the cross-attention module obtains the segmentation and detection feature maps, and hybrid dilated convolution improves the original feature maps. Finally, the semantic segmentation is performed on the segmentation feature maps and object detection is performed on the detection feature maps. The experimental results demonstrate that, on the difficult BDD100K dataset, our model performs better than existing multi-task models in terms of task-wise accuracy and total computational efficiency.

| [1] |
ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6230-6239.
|
| [2] |
PAN X G, SHI J P, LUO P, et al. Spatial as deep: Spatial CNN for traffic scene understanding[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 12301.
|
| [3] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 580- 587.
|
| [4] |
GIRSHICK R. Fast R-CNN[C]// Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2015: 1440-1448.
|
| [5] |
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031
|
| [6] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
|
| [7] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788.
|
| [8] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 2980-2988.
|
| [9] |
TIAN Z, SHEN C H, CHEN H, et al. FCOS: Fully convolutional one-stage object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 9627-9636.
|
| [10] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 3431-3440.
|
| [11] |
ROMERA E, ÁLVAREZ J M, BERGASA L M, et al. ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(1): 263-272. doi: 10.1109/TITS.2017.2750080
|
| [12] |
YU C Q, WANG J B, PENG C, et al. BiSeNet: Bilateral segmentation network for real-time semantic segmentation[C]// Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 325-341.
|
| [13] |
HOU Y N, MA Z, LIU C X, et al. Learning lightweight lane detection CNNs by self attention distillation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 1013-1021.
|
| [14] |
TABELINI L, BERRIEL R, PAIXAO T M, et al. Keep your eyes on the lane: Real-time attention-guided lane detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 294-302.
|
| [15] |
QIN Z Q, WANG H Y, LI X. Ultra fast structure-aware deep lane detection[C]//European Conference on Computer Vision. Berlin: Springer, 2020: 276-291.
|
| [16] |
TEICHMANN M, WEBER M, ZOELLNER M, et al. MultiNet: Real-time joint semantic reasoning for autonomous driving[C]//Proceedings of the IEEE Intelligent Vehicles Symposium. Piscataway: IEEE Press, 2018: 1013-1020.
|
| [17] |
刘占文, 范颂华, 齐明远, 等. 基于时序融合的自动驾驶多任务感知算法[J]. 交通运输工程学报, 2021, 21(4): 223-234.
LIU Z W, FAN S H, QI M Y, et al. Multi-task perception algorithm of autonomous driving based on temporal fusion[J]. Journal of Traffic and Transportation Engineering, 2021, 21(4): 223-234(in Chinese).
|
| [18] |
刘军, 陈岚磊, 李汉冰. 基于类人视觉的多任务交通目标实时检测模型[J]. 汽车工程, 2021, 43(1): 50-58.
LIU J, CHEN L L, LI H B. A real-time detection model for multi-task traffic objects based on humanoid vision[J]. Automotive Engineering, 2021, 43(1): 50-58(in Chinese).
|
| [19] |
QIAN Y Q, DOLAN J M, YANG M. DLT-Net: Joint detection of drivable areas, lane lines, and traffic objects[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(11): 4670-4679.
|
| [20] |
WU D, LIAO M W, ZHANG W T, et al. YOLOP: You only look once for panoptic driving perception[EB/OL]. (2021-08-25) [2022-06-25]. https://arxiv.org/abs/2108.11250.
|
| [21] |
YU F, CHEN H F, WANG X, et al. BDD100K: A diverse driving dataset for heterogeneous multitask learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 2633-2642.
|
| [22] |
PASZKE A, CHAURASIA A, KIM S, et al. ENet: A deep neural network architecture for real-time semantic segmentation[EB/OL]. (2016-06-30)[2022-06-25]. https://arxiv.org/abs/1606.02147.
|

Figures(9) / Tables(5)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: