| Citation: | WU H L,LIU H,SUN Y C. Vision Transformer-based pilot pose estimation[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(10):3100-3110 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0811

|
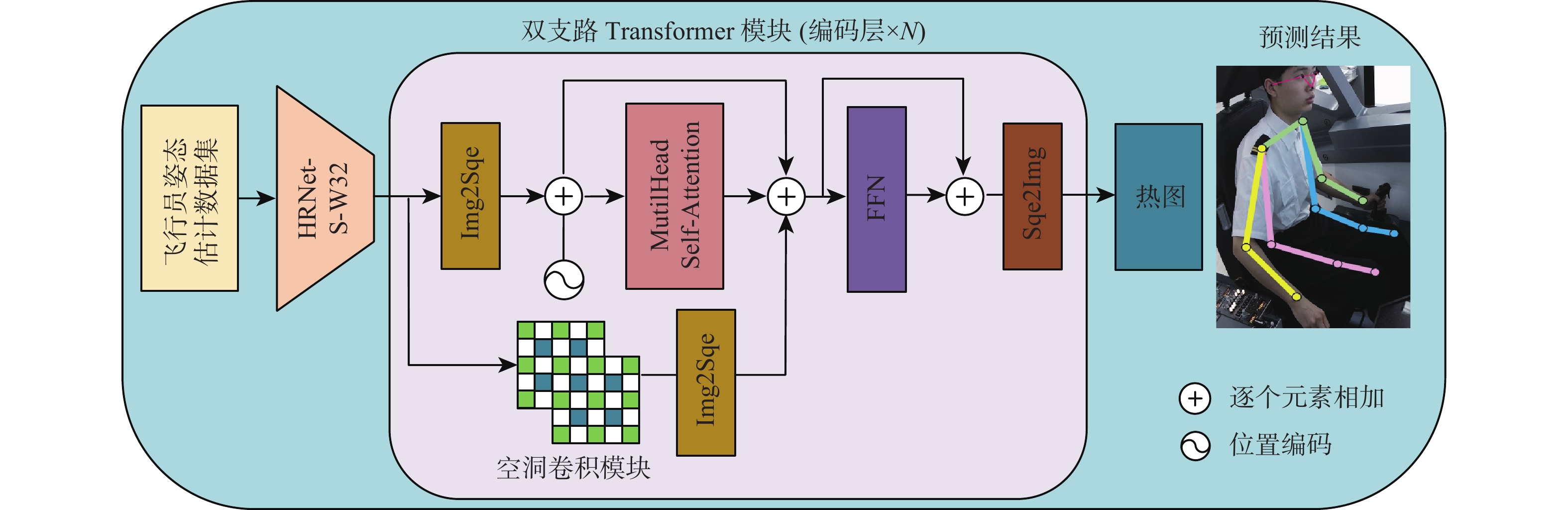
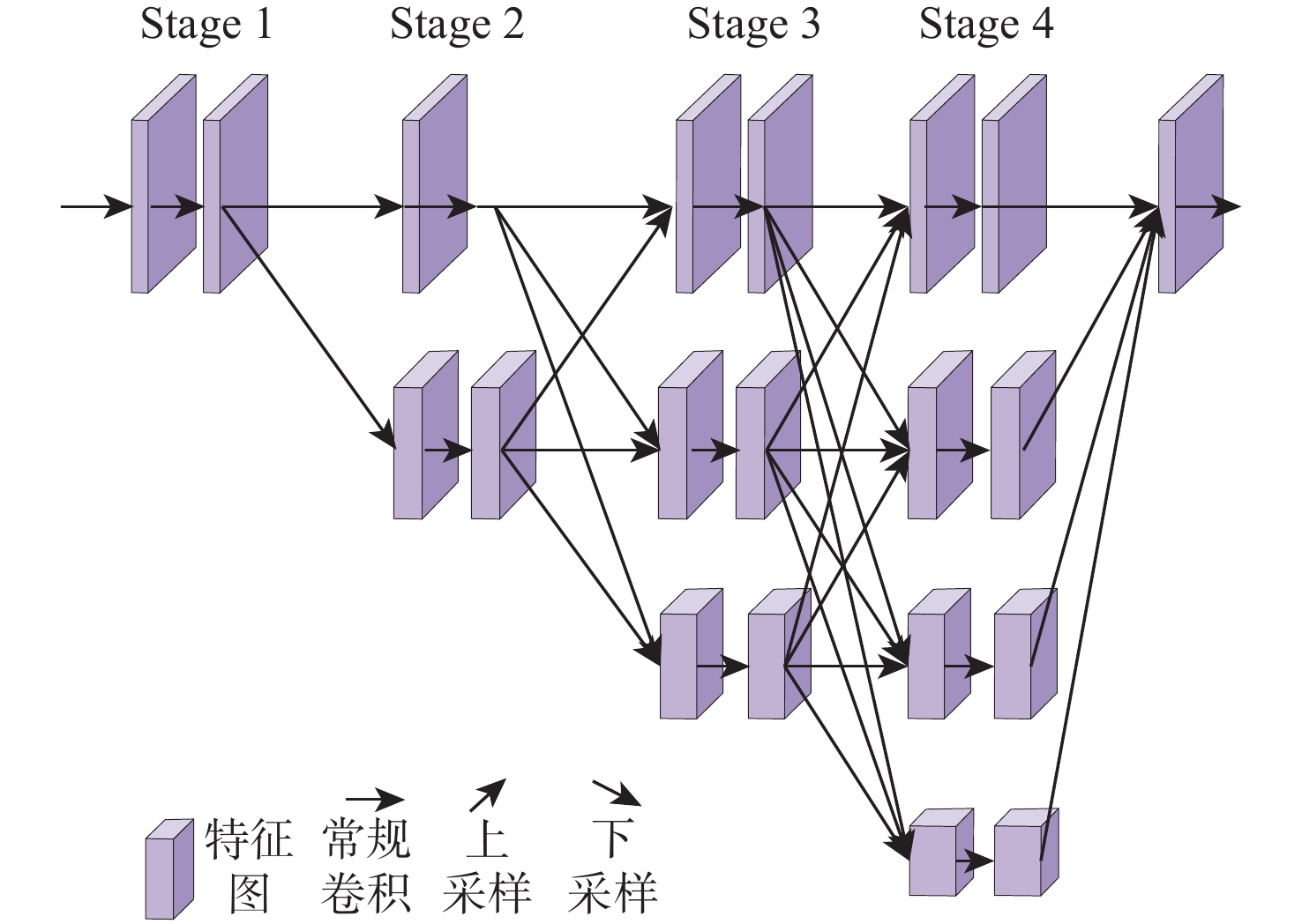
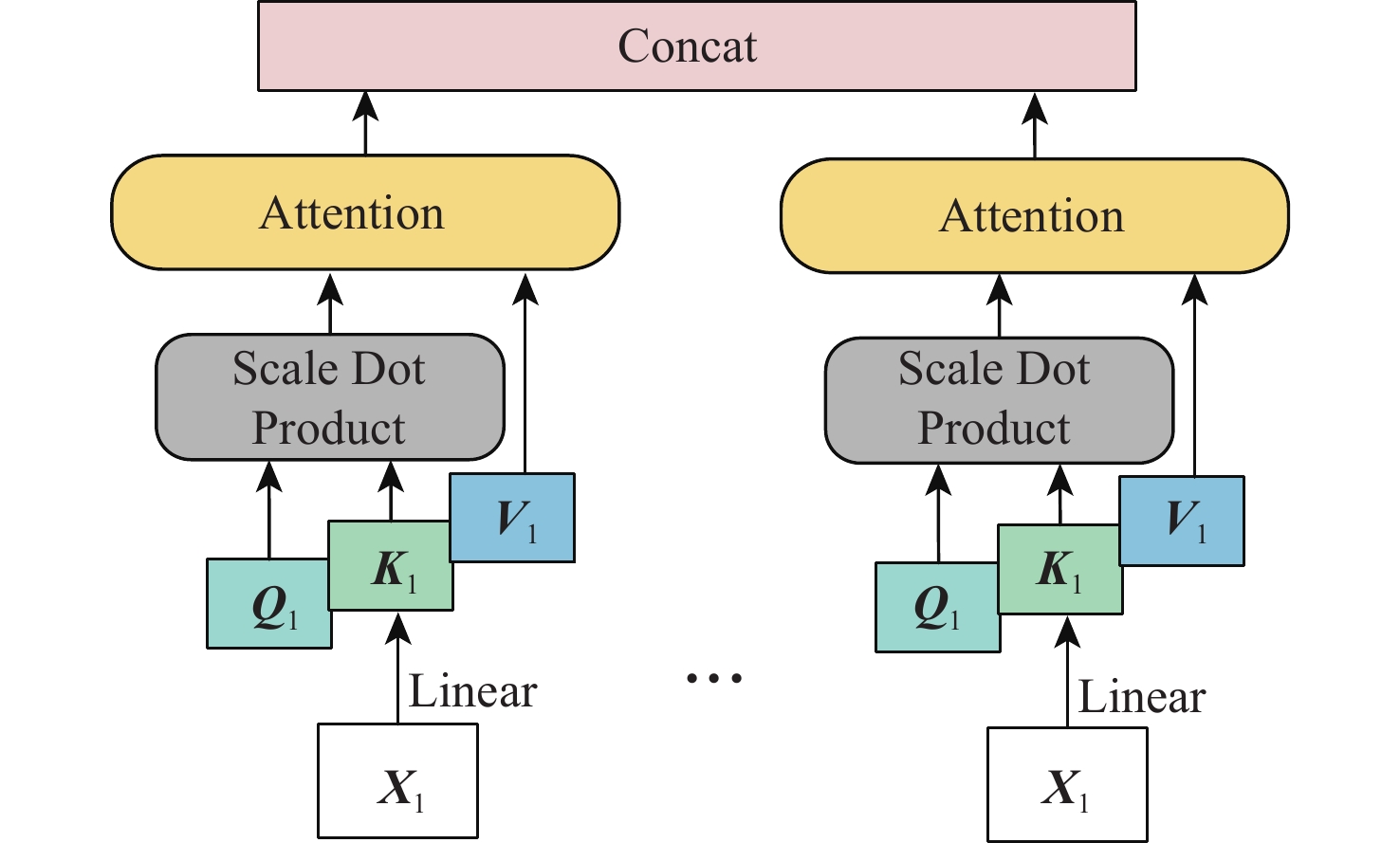
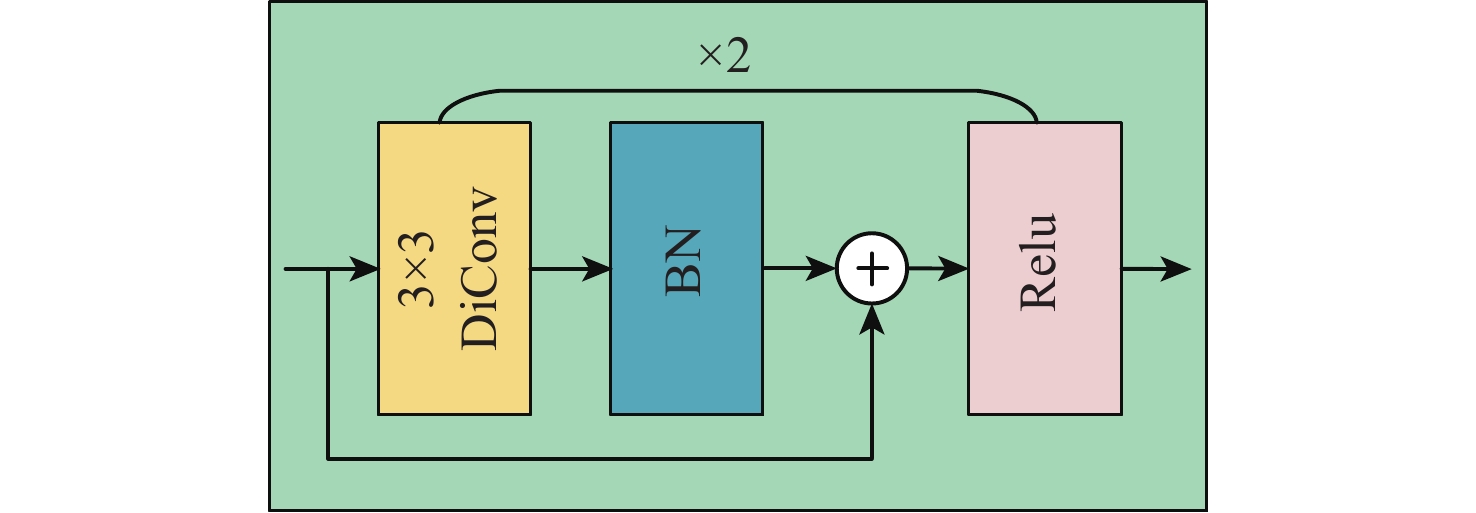
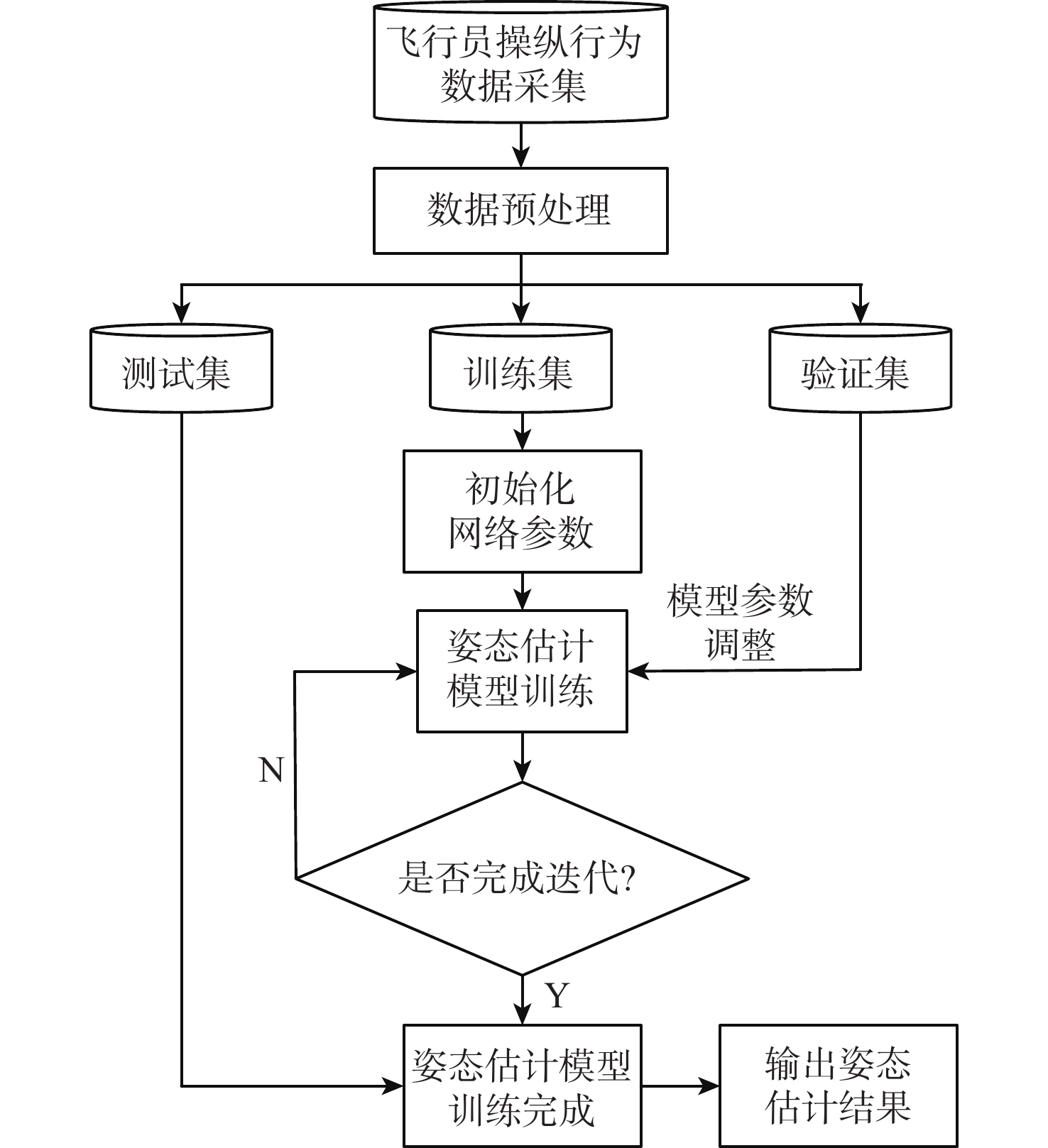
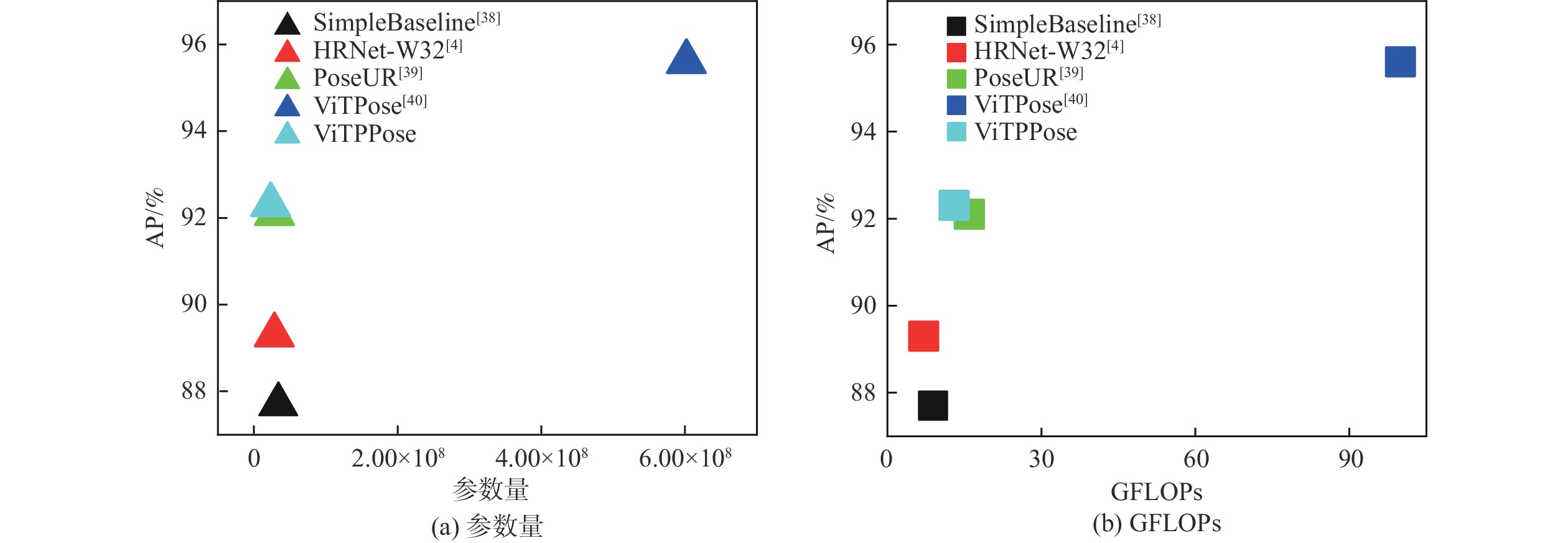
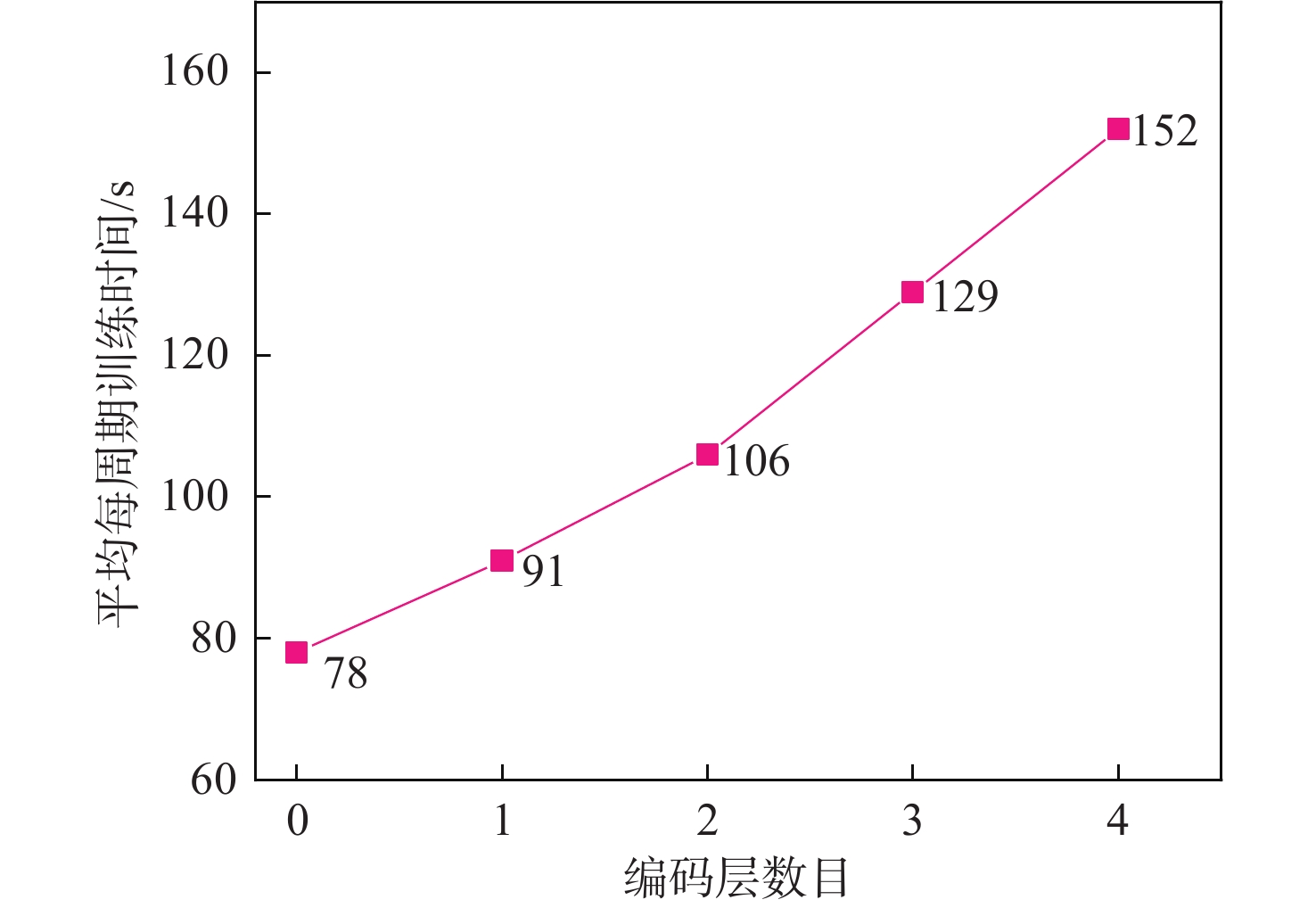
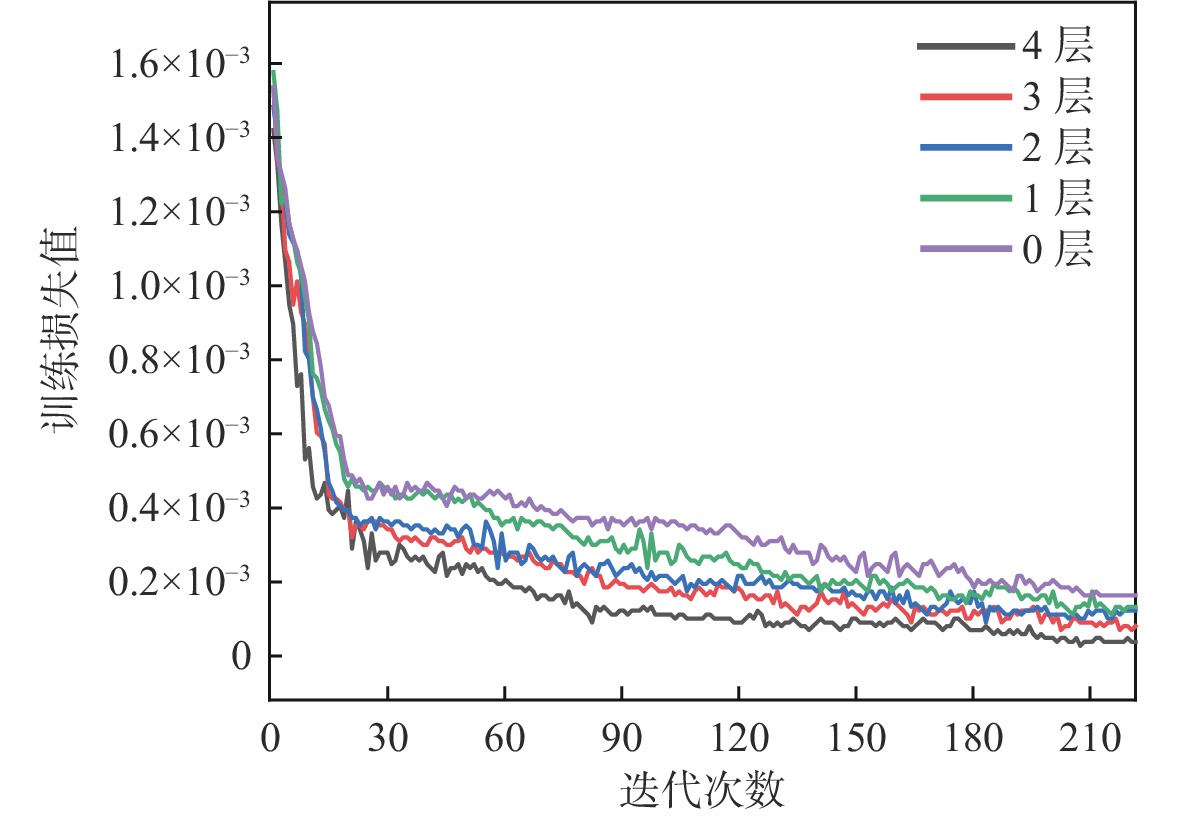
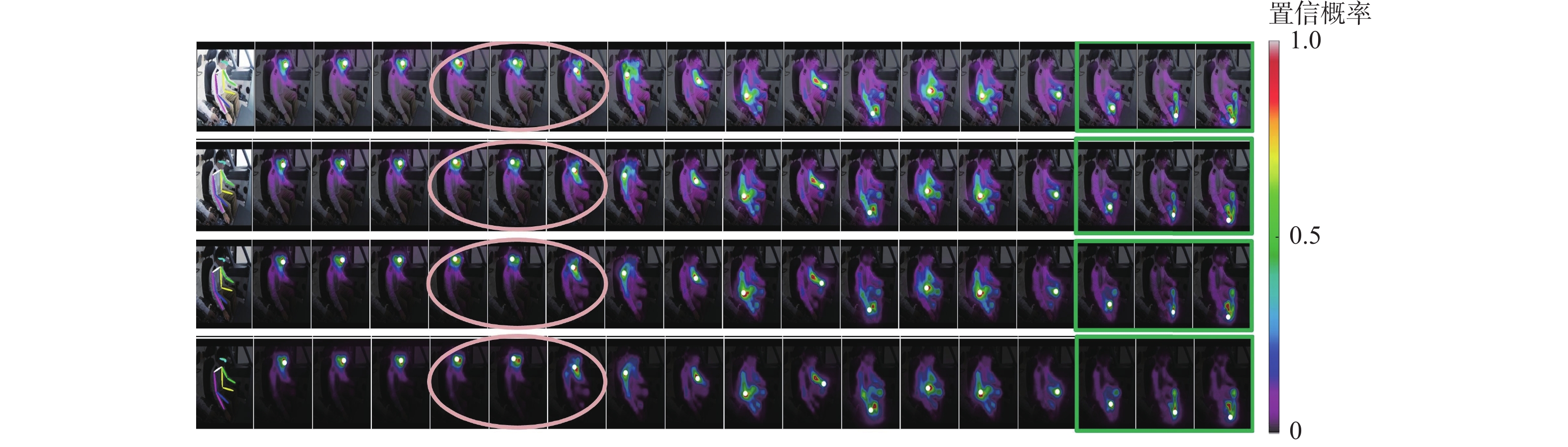
Human pose estimation is an important aspect in the field of behavioral perception and a key technology in the way of intelligent interaction in the cockpit of civil aircraft. To establish an explainable link between the complex lighting environment in the cockpit of civil aircraft and the performance of the pilot pose estimation model, the visual Transformer-based pilot pose (ViTPPose) estimation model is proposed. In order to capture the global correlation of subsequent higher-order features while expanding the perceptual field, this model employs a two-branch Transformer module with several coding layers at the end of the convolutional neural networks (CNN)backbone network. The coding layers combine the Transformer and the dilated convolution. Based on the flight crew’s standard operating procedures, a pilot maneuvering behavior keypoint detection dataset is established for flight simulation scenarios. ViTPPose estimation model completes the pilot seating estimation on this dataset and verifies its validity by comparing it with the benchmark model. The seating estimation heatmap is created in the context of the cockpit’s complicated lighting to examine the model’s preferred lighting intensity, evaluate the ViTPPose estimation model’s performance under various lighting conditions, and highlight the model’s reliance on various lighting intensities.

| [1] |
中华人民共和国国务院. “十三五”国家战略性新兴产业发展规划67号[R]. 北京: 中华人民共和国国务院, 2016.
The State Council of the People’s Republic of China. “13th Five-Year”national strategic emerging industry development plan No 67[R]. Bejing: State Council of the People’s Republic of China, 2016(in Chinese).
|
| [2] |
中华人民共和国国务院. 中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要[R]. 北京: 中华人民共和国国务院, 2021.
The State Council of the People’s Republic of China. Outline of the People’s Republic of China 14th five-year plan for national economic and social development and long-range objectives for 2035[R]. Bejing: State Council of the People’s Republic of China, 2021(in Chinese).
|
| [3] |
杨志刚, 张炯, 李博, 等, 民用飞机智能飞行技术综述[J]. 航空学报, 2021, 42 (4): 525198.
YANG Z G, ZHANG J, LI B, et al. Reviews on intelligent flight technology of civil aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): 525198(in Chinese).
|
| [4] |
TOSHEV A, SZEGEDY C. DeepPose: Human pose estimation via deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 1653-1660.
|
| [5] |
CHEN Y P, DAI X Y, LIU M C, et al. Dynamic ReLU[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2020: 351-367.
|
| [6] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
|
| [7] |
HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 386-397. doi: 10.1109/TPAMI.2018.2844175
|
| [8] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 618-626.
|
| [9] |
ZHANG Q L, YANG Y B. Group-CAM: Group score-weighted visual explanations for deep convolutional networks[EB/OL]. (2021-03-25)[2022-08-19]. http://arxiv.org/abs/2103.13859.
|
| [10] |
LIU Z, MAO H Z, WU C Y, et al. A ConvNet for the 2020s[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 11966-11976.
|
| [11] |
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 5686-5696.
|
| [12] |
CHENG B W, XIAO B, WANG J D, et al. HigherHRNet: Scale-aware representation learning for bottom-up human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 5385-5394.
|
| [13] |
ANDRILUKA M, PISHCHULIN L, GEHLER P, et al. 2D human pose estimation: New benchmark and state of the art analysis[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 3686-3693.
|
| [14] |
JOHNSON S, EVERINGHAM M. Clustered pose and nonlinear appearance models for human pose estimation[C]//Proceedings of the British Machine Vision Conference 2010. London: British Machine Vision Association, 2010: 1-11.
|
| [15] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
|
| [16] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. (2020-10-22)[2022-08-20]. https://arxiv.org/abs/2010.11929.
|
| [17] |
DENG J, DONG W, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2009: 248-255.
|
| [18] |
TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention[EB/OL]. (2020-12-23)[2022-08-20]. https://arxiv.org/abs/2012.12877.
|
| [19] |
TOUVRON H, CORD M, SABLAYROLLES A, et al. Going deeper with Image Transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 32-42.
|
| [20] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010.
|
| [21] |
XIAO T T, SINGH M, MINTUN E, et al. Early convolutions help transformers see better[EB/OL]. (2021-06-28)[2022-08-21]. https://arxiv.org/abs/2106.14881.
|
| [22] |
NEWELL A, YANG K Y, DENG J. Stacked hourglass networks for human pose estimation[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2016: 483-499.
|
| [23] |
CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7103-7112.
|
| [24] |
NEWELL A, HUANG Z A, DENG J. Associative embedding: end-to-end learning for joint detection and grouping[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 2274–2284.
|
| [25] |
CAO Z, SIMON T, WEI S H, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 1302-1310.
|
| [26] |
WEI S H, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 4724-4732.
|
| [27] |
LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 9992-10002.
|
| [28] |
王静, 李沛橦, 赵容锋, 等. 融合卷积注意力和Transformer架构的行人重识别方法[J]. 北京航空航天大学学报, 2024, 50(2): 466-476.
WANG J, LI P T, ZHAO R F, et al. A person re-identification method for fusing convolutional attention and Transformer architecture[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(2): 466-476 (in Chinese).
|
| [29] |
YUAN Y H, FU R, HUANG L, et al. HRFormer: High-resolution transformer for dense prediction[EB/OL]. (2021-10-18)[2022-08-21]. https://arxiv.org/abs/2110.09408.
|
| [30] |
XIONG Z N, WANG C X, LI Y, et al. Swin-Pose: Swin transformer based human pose estimation[C]//Proceedings of the IEEE 5th International Conference on Multimedia Information Processing and Retrieval. Piscataway: IEEE Press, 2022: 228-233.
|
| [31] |
YANG S, QUAN Z B, NIE M, et al. TransPose: Keypoint localization via transformer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 11782-11792.
|
| [32] |
SAMEK W, MONTAVON G, LAPUSCHKIN S, et al. Explaining deep neural networks and beyond: A review of methods and applications[J]. Proceedings of the IEEE, 2021, 109(3): 247-278. doi: 10.1109/JPROC.2021.3060483
|
| [33] |
KOH P W, LIANG P. Understanding black-box predictions via influence functions[EB/OL]. (2020-12-29)[2022-08-22]. http://arxiv.org/abs/1703.04730.
|
| [34] |
ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2014: 818-833.
|
| [35] |
ZHANG S S, YANG J, SCHIELE B. Occluded pedestrian detection through guided attention in CNNs[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6995-7003.
|
| [36] |
ZHOU B L, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 2921-2929.
|
| [37] |
WANG H F, WANG Z F, DU M N, et al. Score-CAM: Score-weighted visual explanations for convolutional neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2020: 111-119.
|
| [38] |
XIAO B, WU H P, WEI Y C. Simple baselines for human pose estimation and tracking[EB/OL]. (2018-08-21)[2022-08-22]. http://arxiv.org/abs/1804.06208.
|
| [39] |
MAO W A, GE Y T, SHEN C H, et al. PoseUR: Direct human pose regression with transformers[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2022: 72-88.
|
| [40] |
XU Y F, ZHANG J, ZHANG Q M, et al. ViTPose: Simple vision transformer baselines for human pose estimation[EB/OL]. (2022-04-26)[2022-08-22]. http://arxiv.org/abs/2204.12484.
|

Figures(14) / Tables(4)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: