| Citation: | TONG Junchao, WU Xilin, DING Dandanet al. Video multi-frame quality enhancement method via spatial-temporal context learning[J]. Journal of Beijing University of Aeronautics and Astronautics, 2019, 45(12): 2506-2513. doi: 10.13700/j.bh.1001-5965.2019.0374(in Chinese)

|
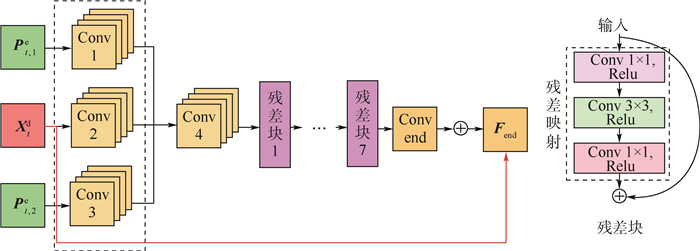
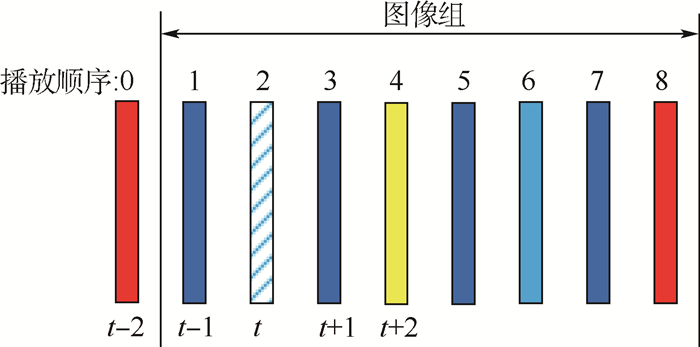
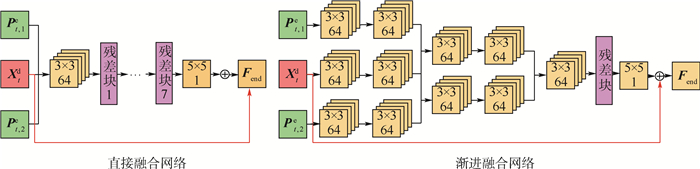
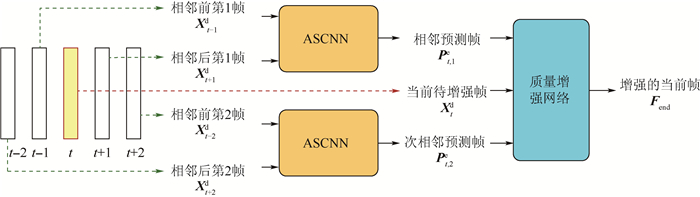
Convolutional neural network (CNN) has achieved great success in the field of video enhancement. The existing video enhancement methods mainly explore the pixel correlations in spatial domain of an image, which ignores the temporal similarity between consecutive frames. To address the above issue, this paper proposes a multi-frame quality enhancement method, namely spatial-temporal multi-frame video enhancement (STMVE), through learning the spatial-temporal context of current frame. The basic idea of STMVE is utilizing the adjacent frames of current frame to help enhance the quality of current frame. To this end, the virtual frames of current frame are first predicted from its neighbouring frames and then current frame is enhanced by its virtual frames. And the adaptive separable convolutional neural network (ASCNN) is employed to generate the virtual frame. In the subsequent enhancement stage, a multi-frame CNN (MFCNN) is designed. An early-fusion CNN structure is developed to extract both temporal and spatial correlation between the current and virtual frames and output the enhanced current frame. The experimental results show that the proposed STMVE method obtains 0.47 dB, 0.43 dB, 0.38 dB and 0.28 dB PSNR gains compared with H.265/HEVC at quantized parameter values 37, 32, 27 and 22 respectively. Compared to the multi-frame quality enhancement (MFQE) method, an average 0.17 dB PSNR gain is obtained.

| [1] |
CISCO.Cisco visual networking index: Global mobile data traffic forecast update[EB/OL]. (2019-02-18)[2019-07-08]. https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/white-paper-c11-738429.html.
|
| [2] |
DONG C, DENG Y, CHANGE LOY C, et al.Compression artifacts reduction by a deep convolutional network[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2015: 576-584.
|
| [3] |
ZHANG K, ZUO W, CHEN Y, et al.Beyond a Gaussian denoiser:Residual learning of deep CNN for image denoising[J]. IEEE Transactions on Image Processing, 2017, 26(7):3142-3155. doi: 10.1109/TIP.2017.2662206
|
| [4] |
YANG R, XU M, WANG Z.Decoder-side HEVC quality enhancement with scalable convolutional neural network[C]//2017 IEEE International Conference on Multimedia and Expo(ICME).Piscataway, NJ: IEEE Press, 2017: 817-822.
|
| [5] |
YANG R, XU M, WANG Z, et al.Multi-frame quality enhancement for compressed video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 6664-6673.
|
| [6] |
NIKLAUS S, MAI L, LIU F.Video frame interpolation via adaptive separable convolution[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 261-270.
|
| [7] |
PARK W S, KIM M.CNN-based in-loop filtering for coding efficiency improvement[C]//2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop(IVMSP), 2016: 1-5.
|
| [8] |
JUNG C, JIAO L, QI H, et al.Image deblocking via sparse representation[J]. Signal Processing:Image Communication, 2012, 27(6):663-677. doi: 10.1016/j.image.2012.03.002
|
| [9] |
WANG Z, LIU D, CHANG S, et al.D3: Deep dual-domain based fast restoration of jpeg-compressed images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 2764-2772.
|
| [10] |
LI K, BARE B, YAN B.An efficient deep convolutional neural networks model for compressed image deblocking[C]//2017 IEEE International Conference on Multimedia and Expo (ICME).Piscataway, NJ: IEEE Press, 2017: 1320-1325.
|
| [11] |
LU G, OUYANG W, XU D, et al.Deep Kalman filtering network for video compression artifact reduction[C]//Proceedings of the European Conference on Computer Vision (ECCV).Berlin: Springer, 2018: 568-584.
|
| [12] |
DAI Y, LIU D, WU F.A convolutional neural network approach for post-processing in HEVC intra coding[C]//International Conference on Multimedia Modeling.Berlin: Springer, 2017: 28-39.
|
| [13] |
TSAI R.Multiframe image restoration and registration[J]. Advance Computer Visual and Image Processing, 1984, 11(2):317-339. http://d.old.wanfangdata.com.cn/Periodical/dbch201411011
|
| [14] |
PARK S C, PARK M K, KANG M G.Super-resolution image reconstruction:A technical overview[J]. IEEE Signal Processing Magazine, 2003, 20(3):21-36. doi: 10.1109/MSP.2003.1203207
|
| [15] |
HUANG Y, WANG W, WANG L.Video super-resolution via bidirectional recurrent convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):1015-1028. doi: 10.1109/TPAMI.2017.2701380
|
| [16] |
LI D, WANG Z.Video superresolution via motion compensation and deep residual learning[J]. IEEE Transactions on Computational Imaging, 2017, 3(4):749-762. doi: 10.1109/TCI.2017.2671360
|
| [17] |
ILG E, MAYER N, SAIKIA T, et al.FlowNet 2.0: Evolution of optical flow estimation with deep networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 2462-2470.
|
| [18] |
HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 770-778.
|
Figures(6) / Tables(6)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: