

2019 Vol. 45, No. 12
 Download (14951)
Download (14951) 
 Views
Views  Cited by
Cited by 
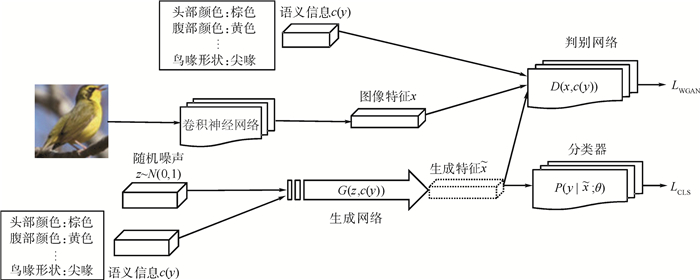






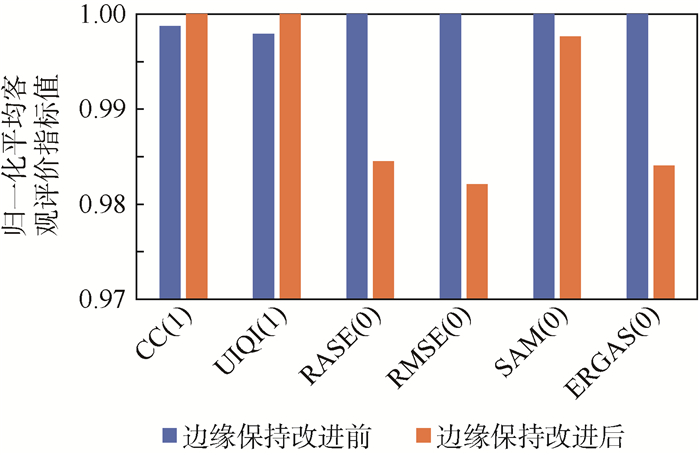






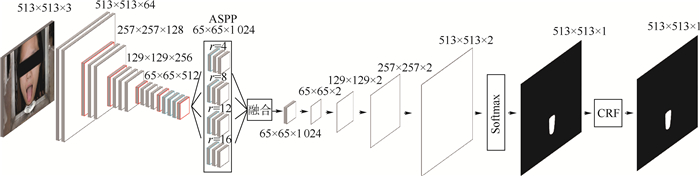





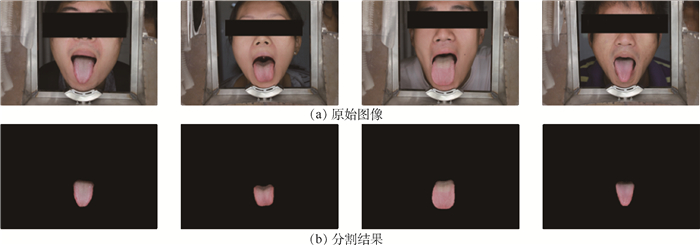



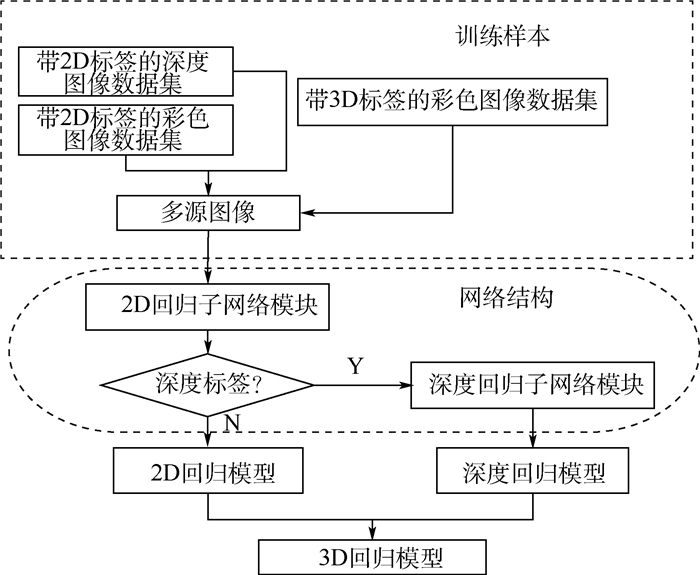


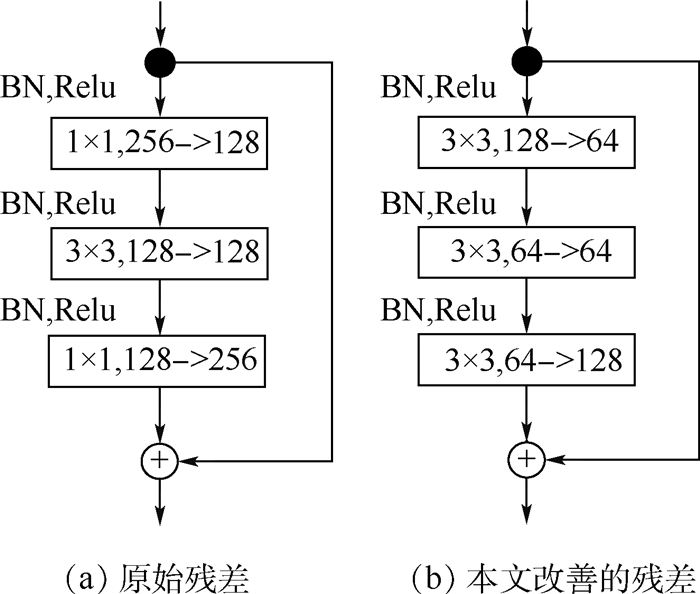

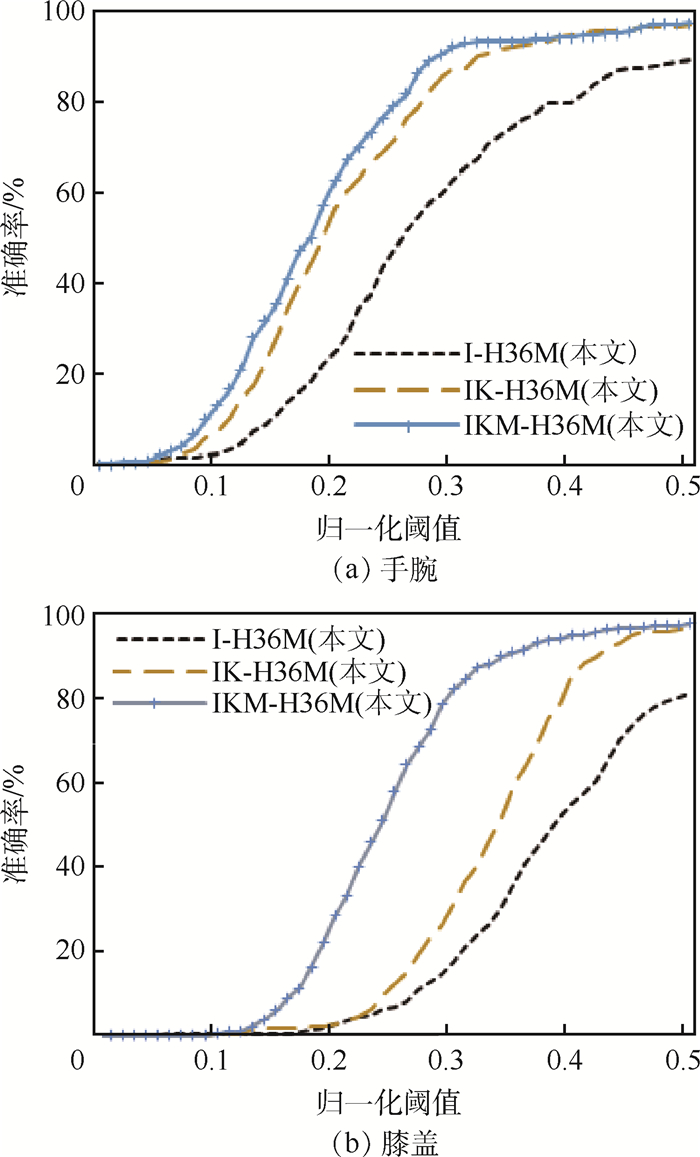








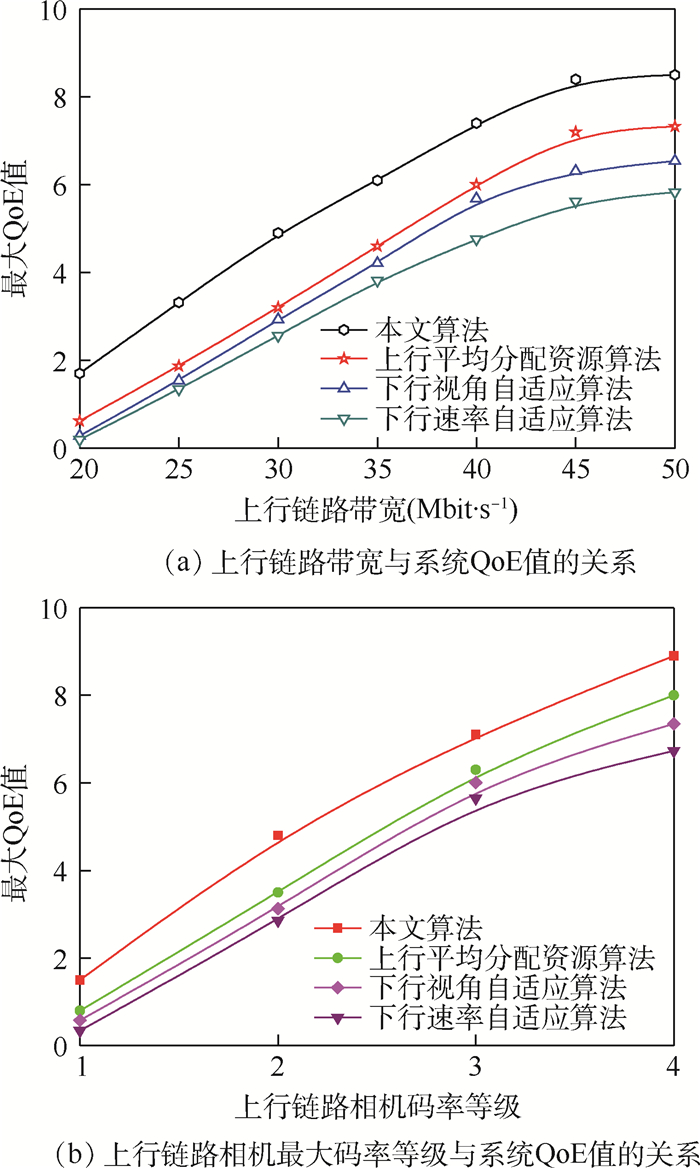


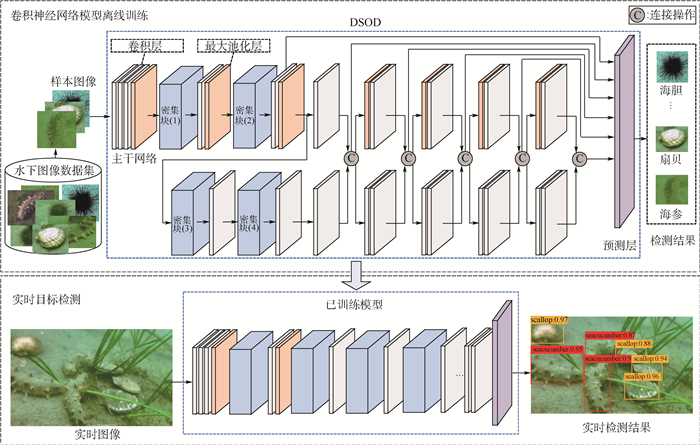
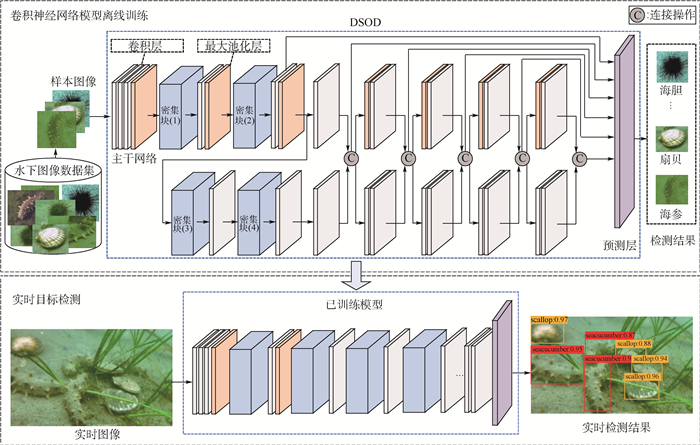


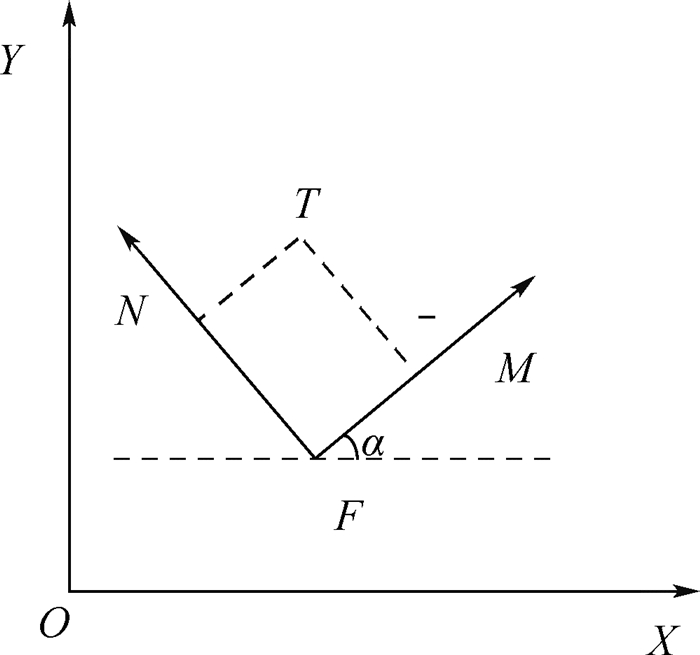

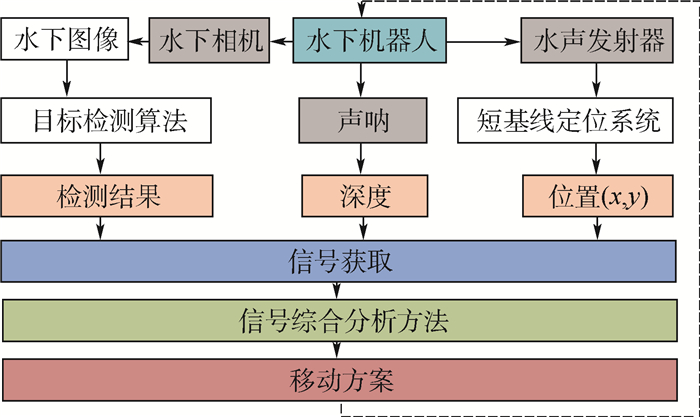












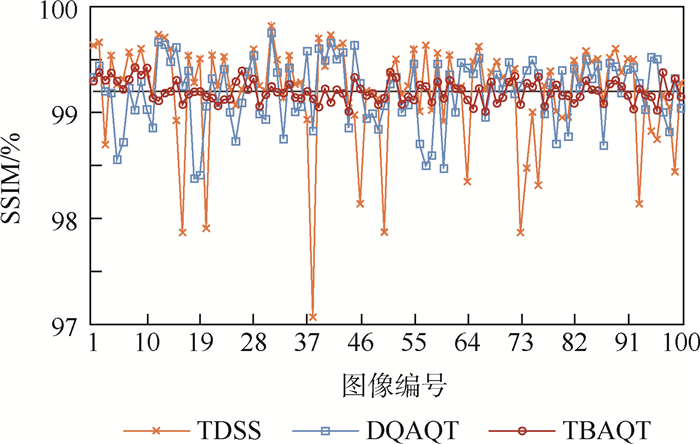
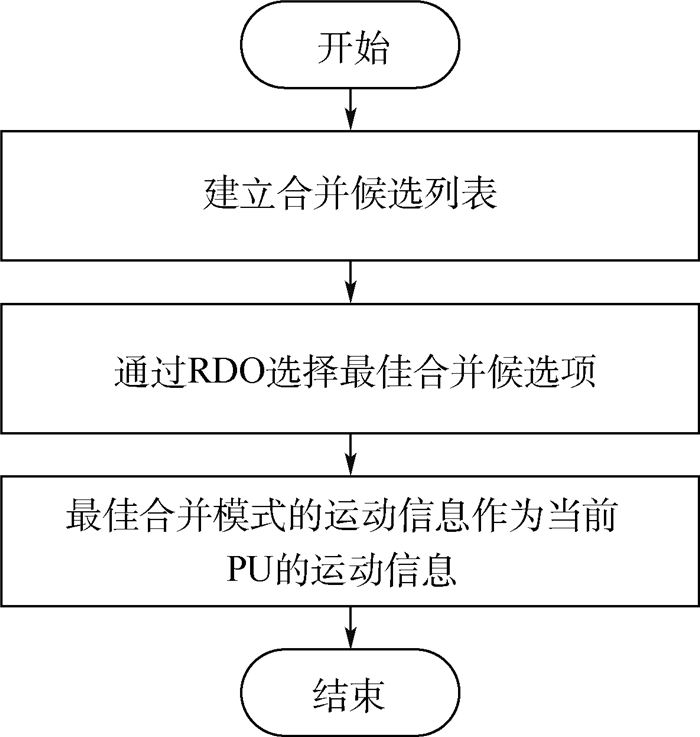
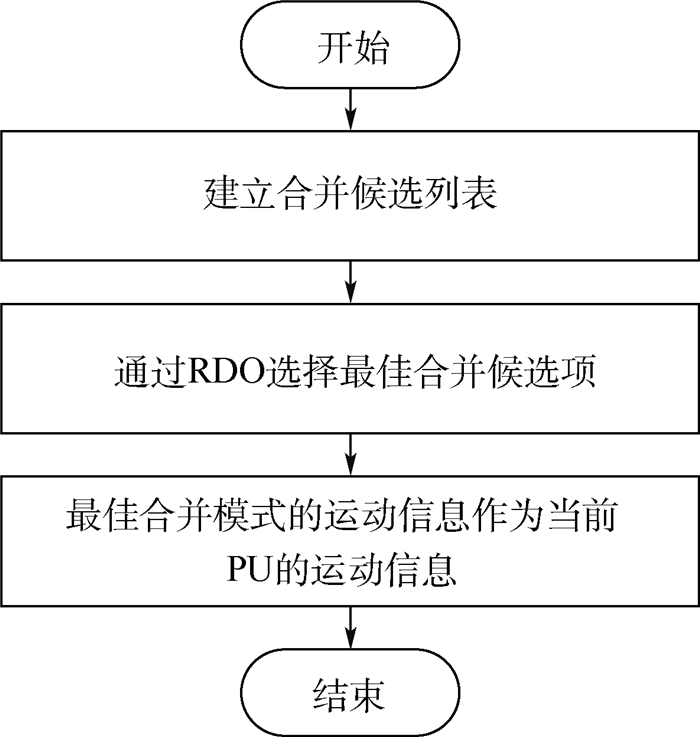

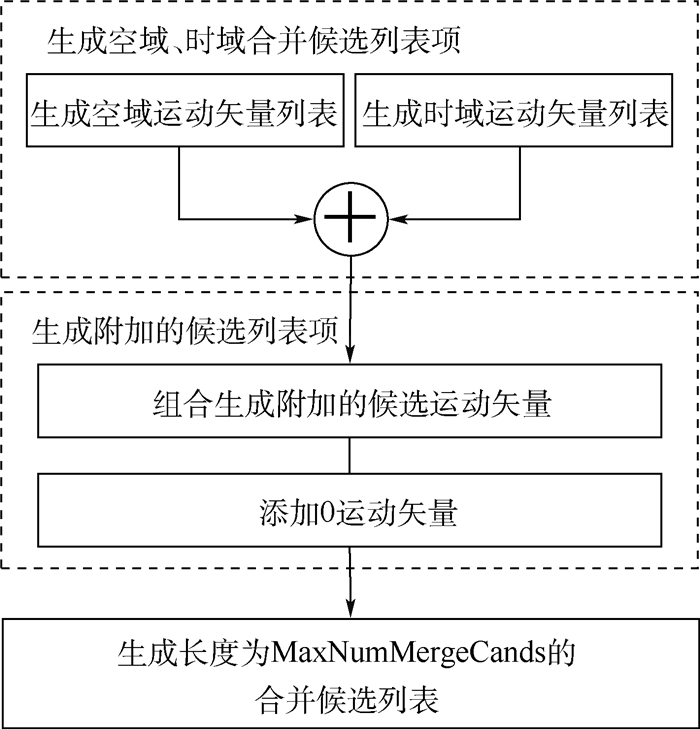



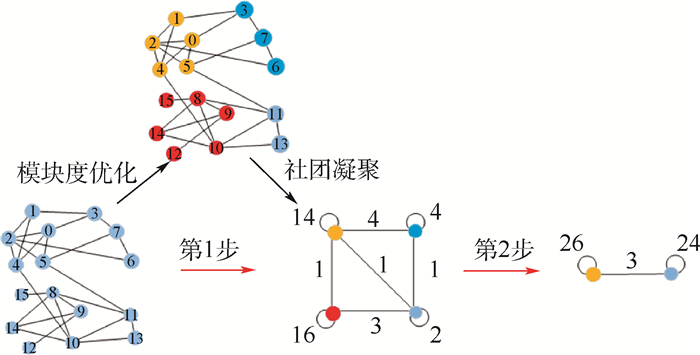


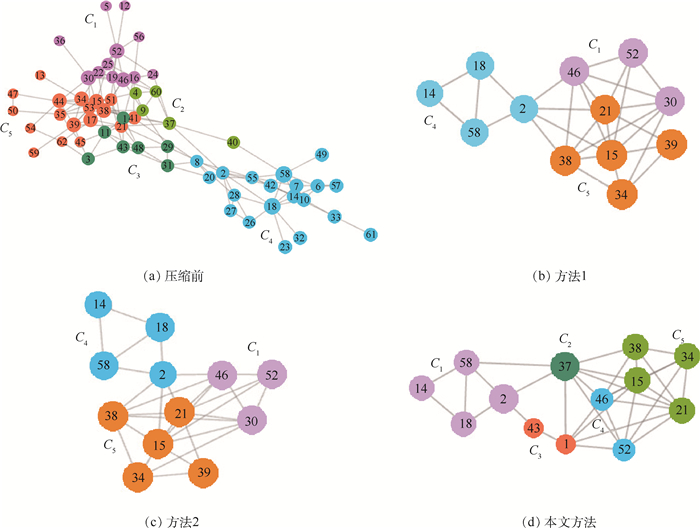

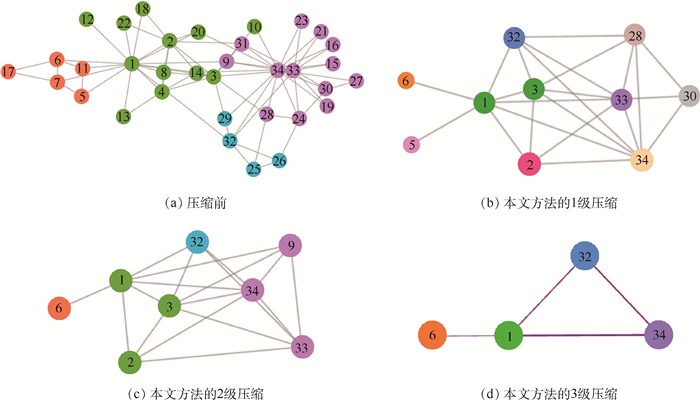
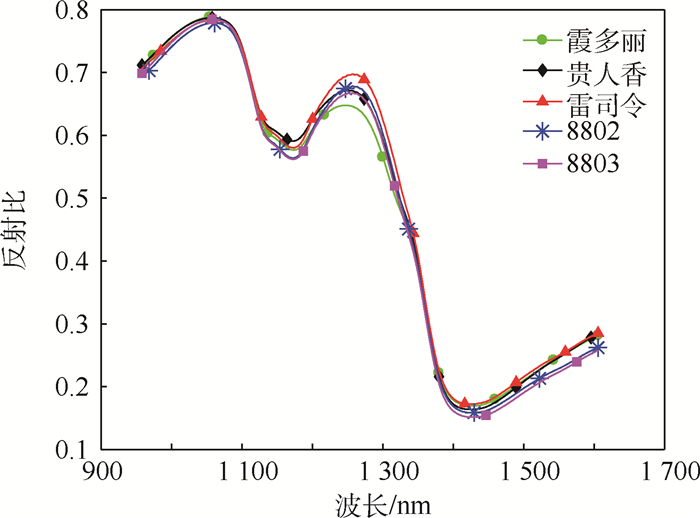

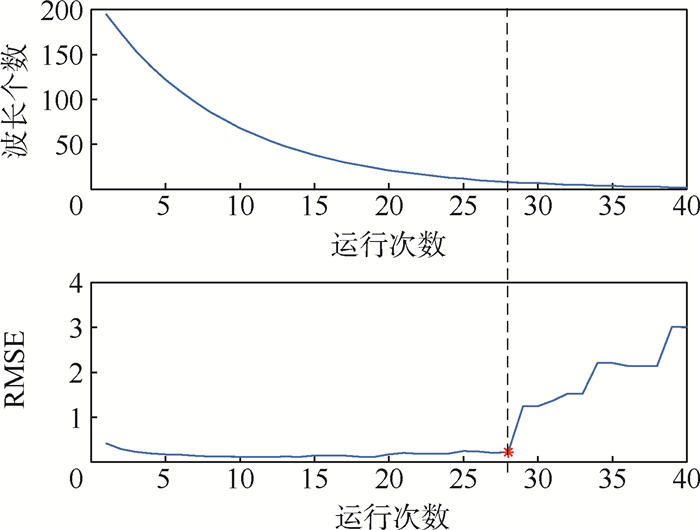

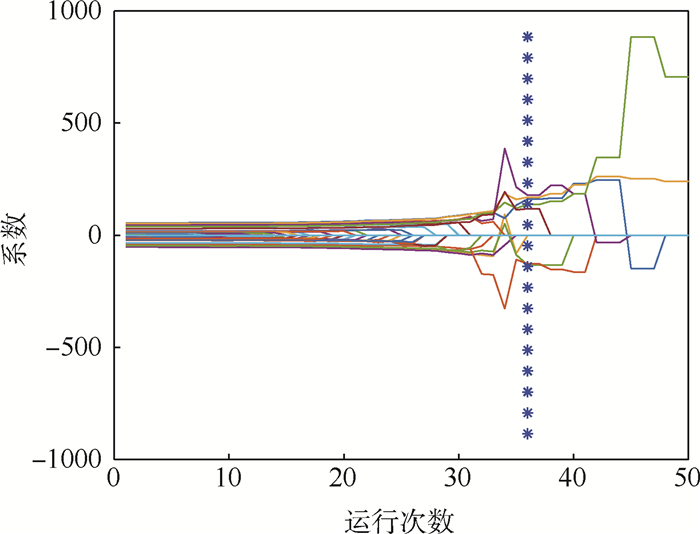


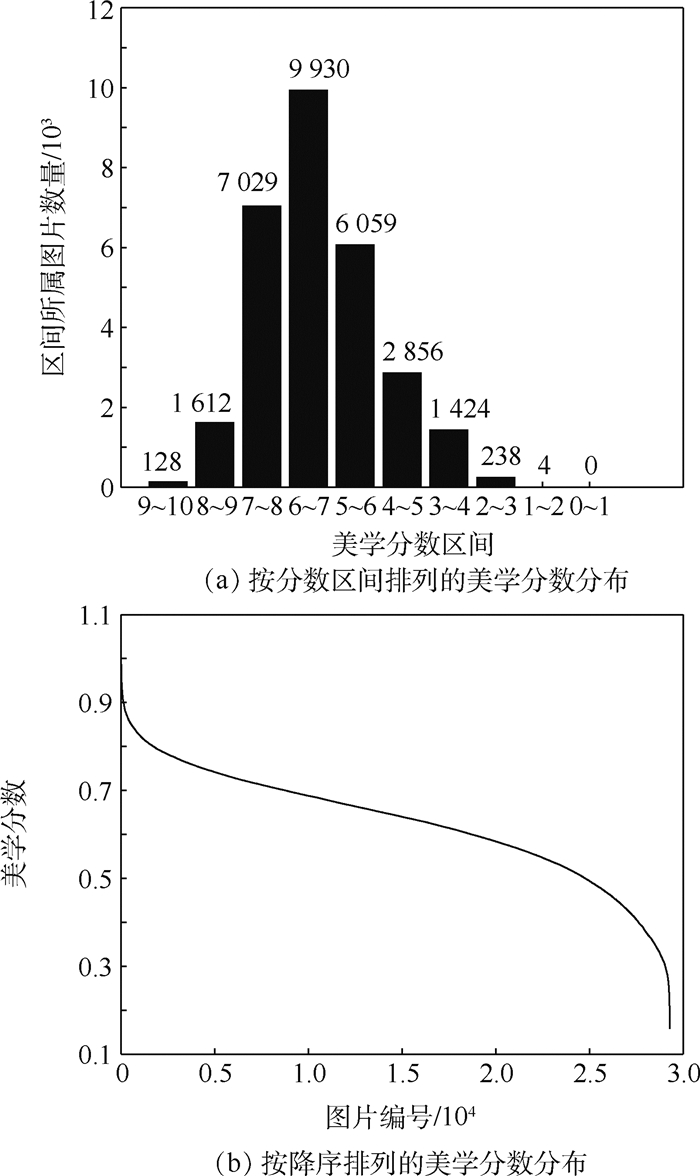



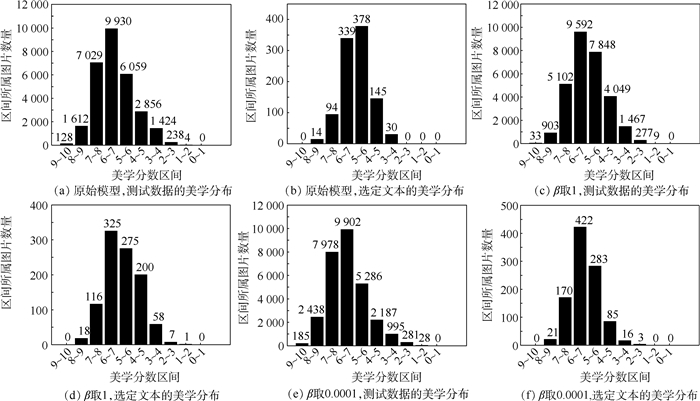





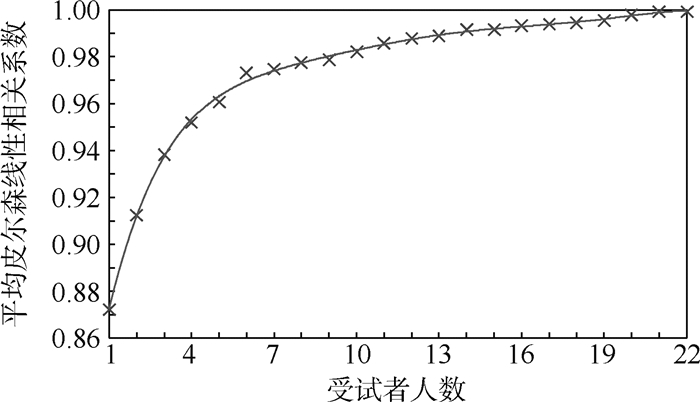
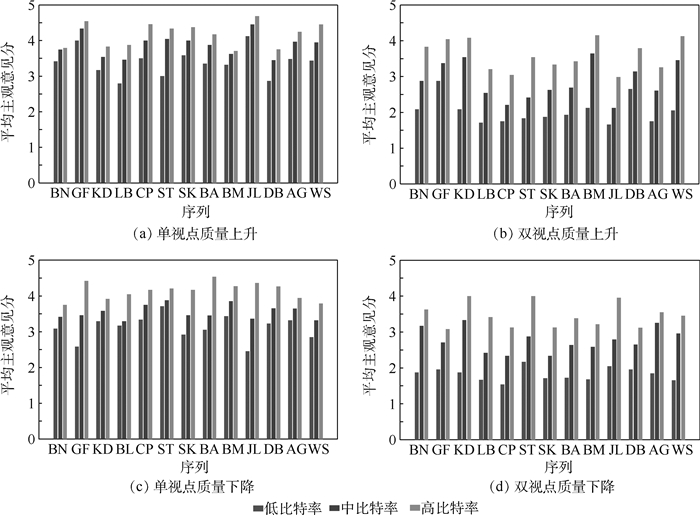

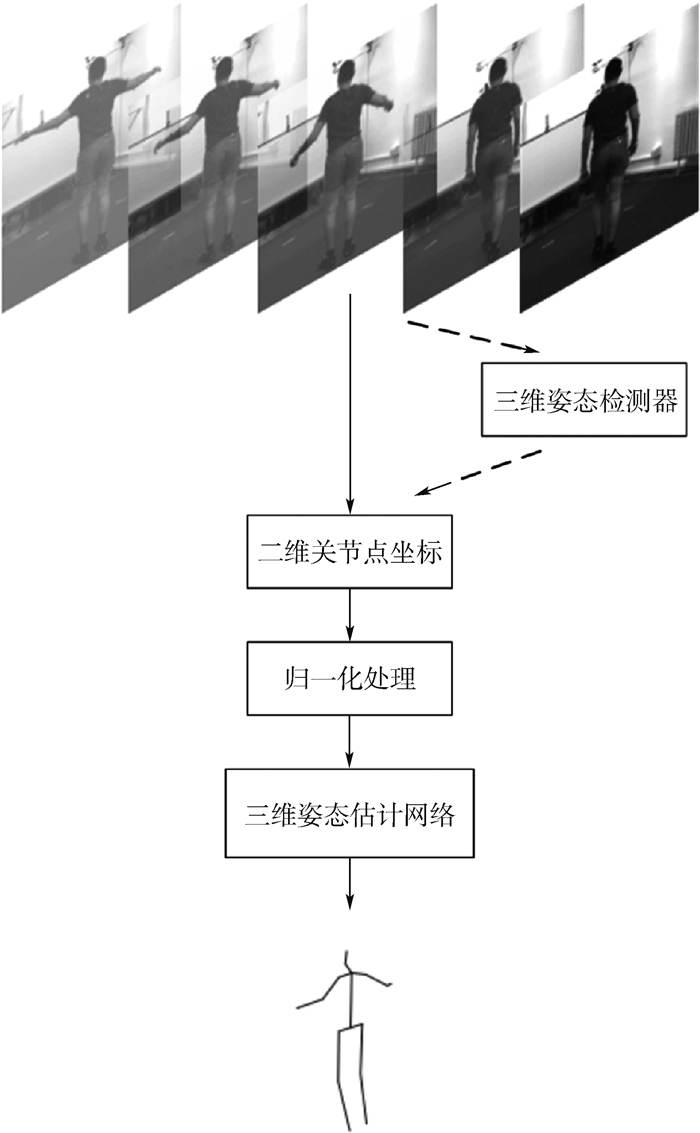
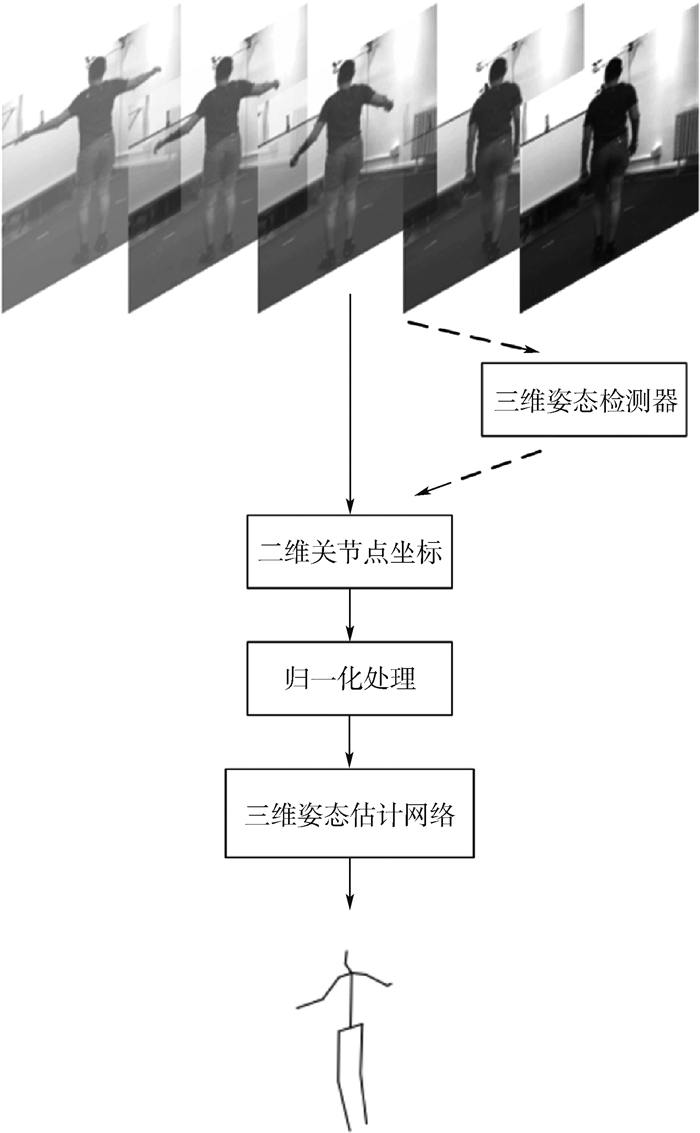
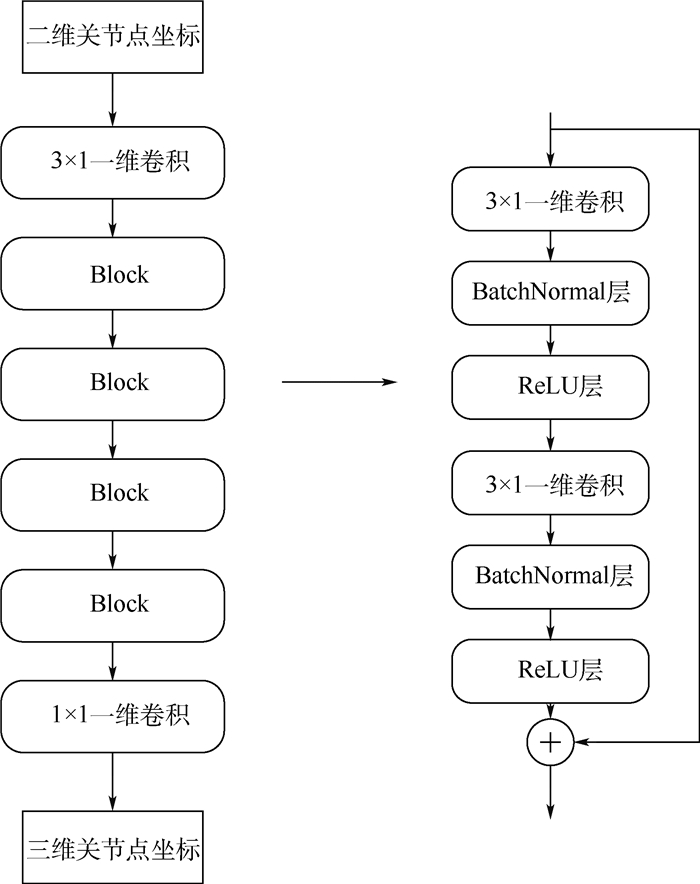








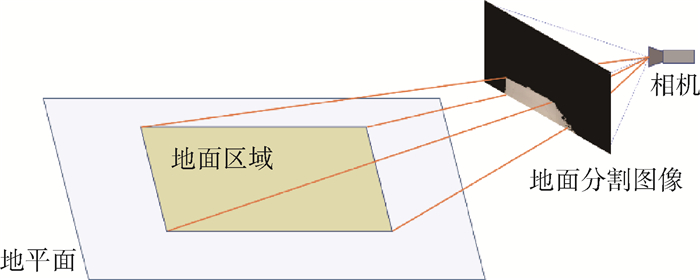











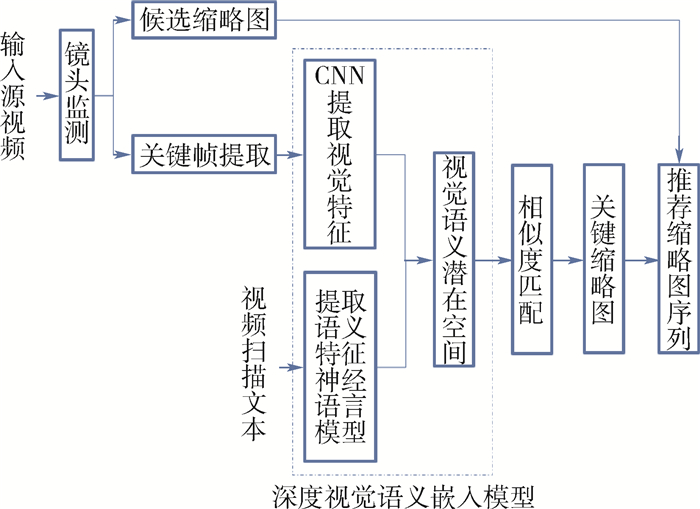


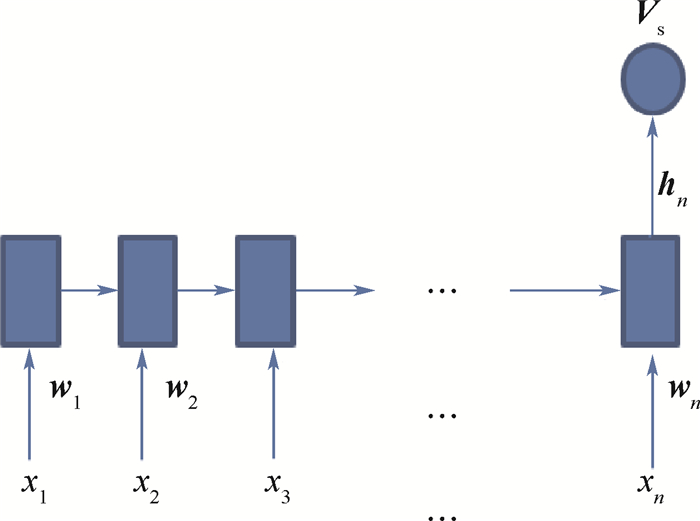


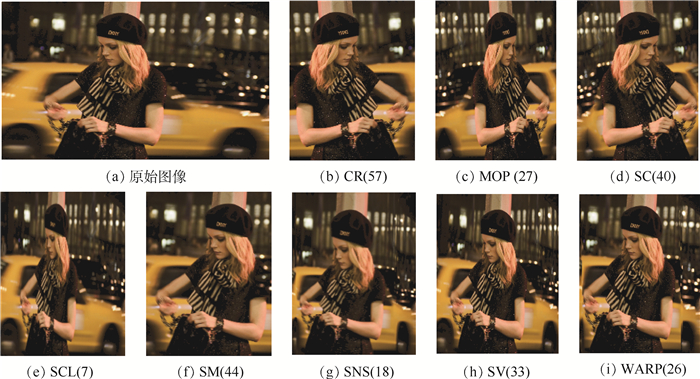








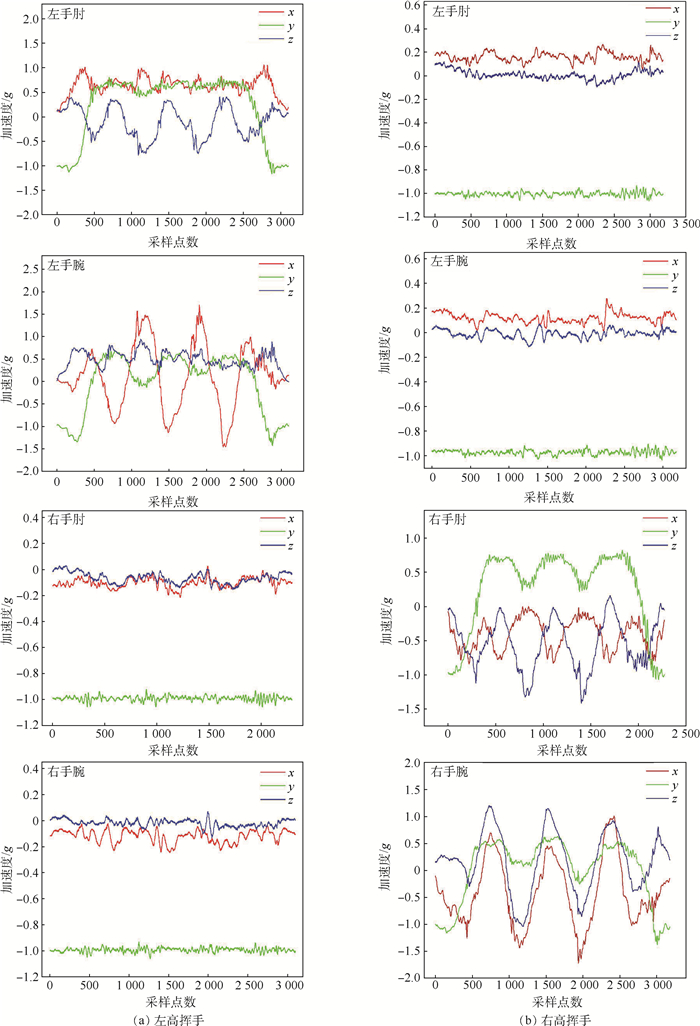






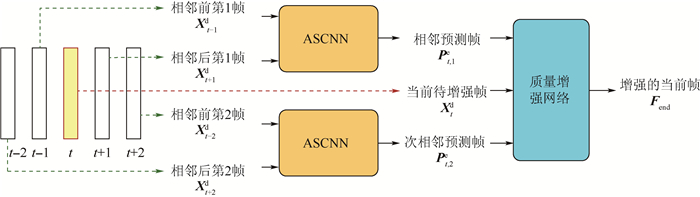









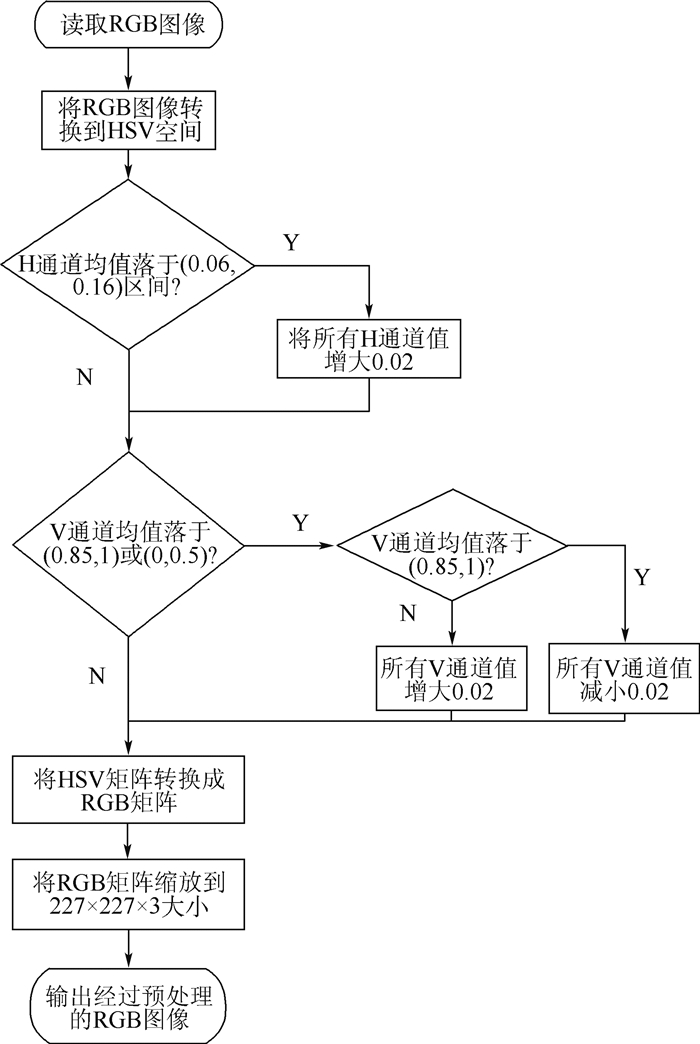














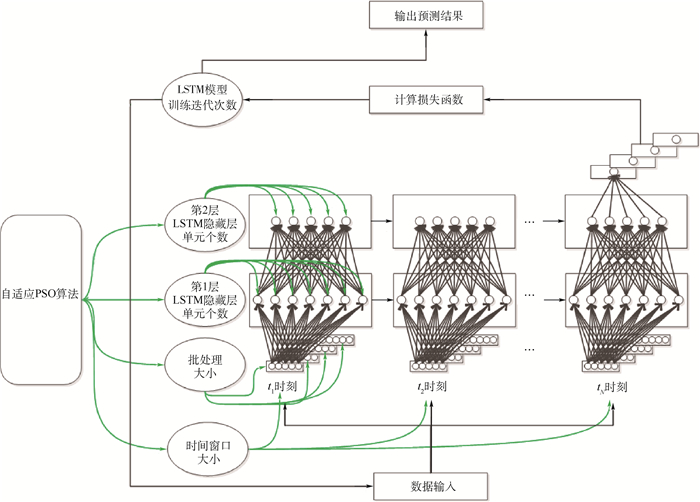
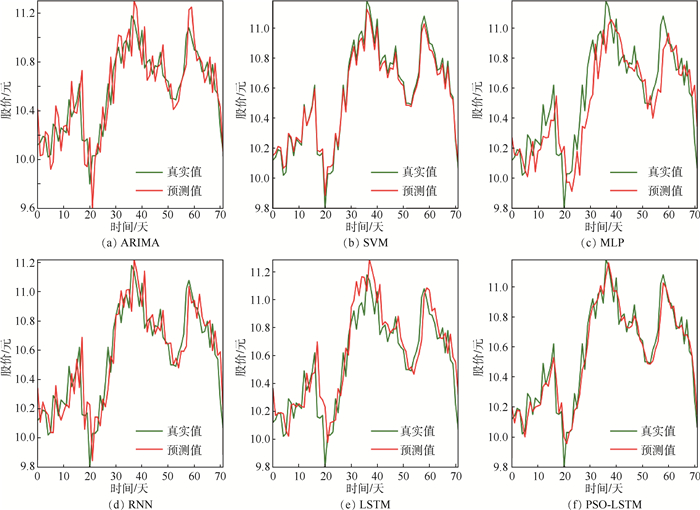



2019, 45(12): 2543-2561.
Abstract:
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 XML Online Production Platform
XML Online Production Platform
