| Citation: | YANG Bin, LI Heping, ZENG Huiet al. Three-dimensional human pose estimation based on video[J]. Journal of Beijing University of Aeronautics and Astronautics, 2019, 45(12): 2463-2469. doi: 10.13700/j.bh.1001-5965.2019.0384(in Chinese)

|
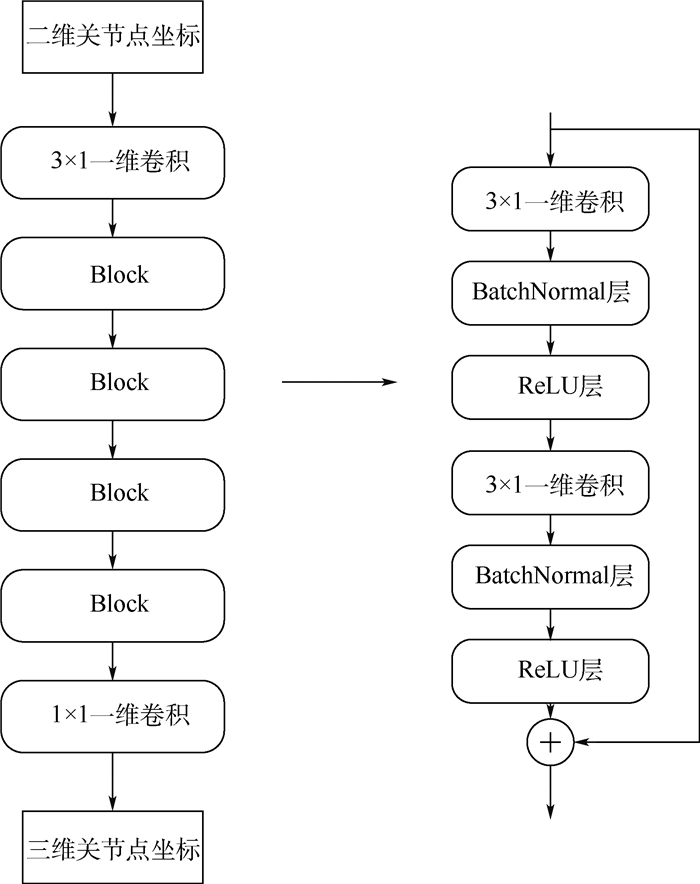
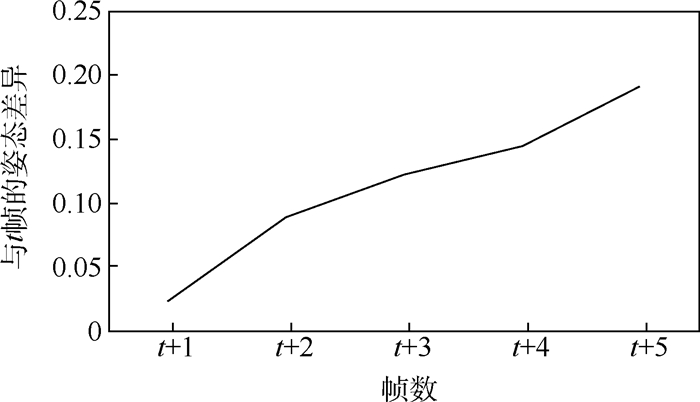
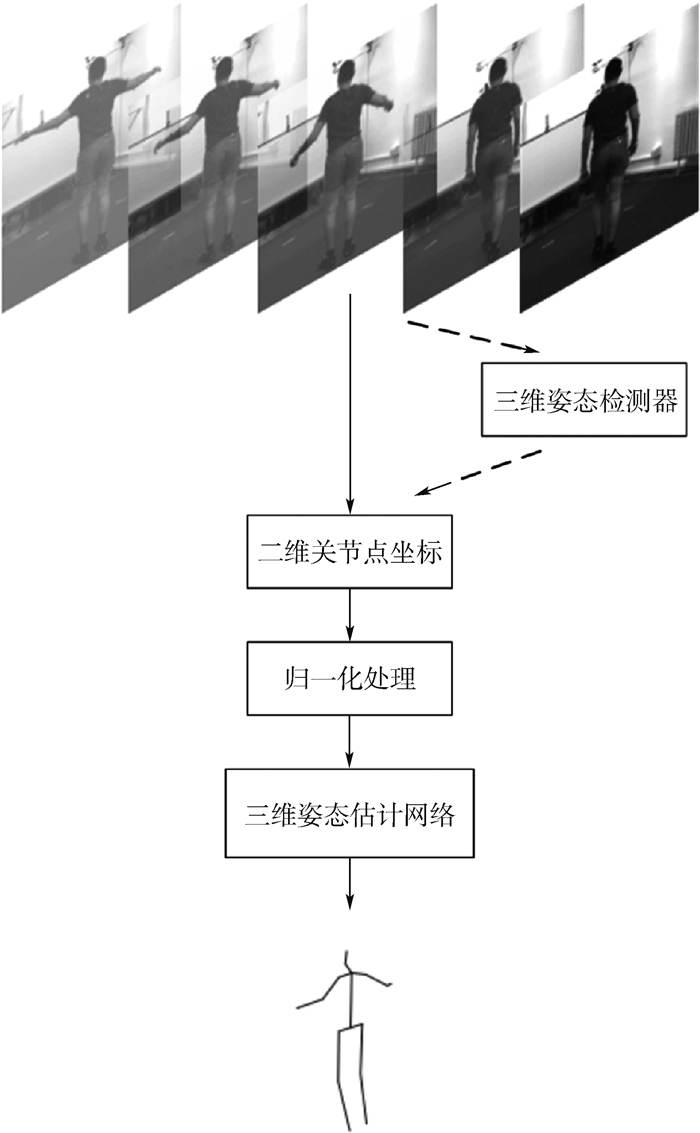
The existing 3D human pose estimation method focuses on estimating the 3D pose of the human body through a single frame image, while ignoring the correlation between the front and back frames in the video. Therefore, by investigating the information of the video in the time dimension, the accuracy of the 3D human pose estimation can be further improved. Based on this, the convolutional neural network structure that can fully extract the temporal information in the video is designed. It has the advantage of low computational resources and high precision. The complete 3D human pose can be restored only by using the coordinates of the 2D articulation point as input. Furthermore, a new loss function is proposed, which uses the continuity of human pose between adjacent frames to improve the smoothness of 3D pose estimation in video sequences, and also solves the problem of accuracy degradation due to lack of inter-frame information. By testing on the Human 3.6M dataset, the experimental results indicate that the average test error of the proposed method is 1.2 mm lower than that of the current standard 3D pose estimation algorithm, and the proposed method has a high accuracy for the 3D human pose estimation of video sequences.
| [1] |
BO L, SMINCHISESCU C.Twin gaussian processes for structured prediction[J].International Journal of Computer Vision, 2010, 87(1-2):28. doi: 10.1007/s11263-008-0204-y
|
| [2] |
RADWAN I, DHALL A, GOECKE R.Monocular image 3D human pose estimation under self-occlusion[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2013: 1888-1895.
|
| [3] |
ZHOU X, HUANG Q, SUN X, et al.Towards 3D human pose estimation in the wild: A weakly supervised approach[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 398-407.
|
| [4] |
PAVLAKOS G, ZHOU X, DERPANIS K G, et al.Coarse-to-fine volumetric prediction for single-image 3D human pose[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 7025-7034.
|
| [5] |
NEWELL A, YANG K, DENG J.Stacked hourglass networks for human pose estimation[C]//Proceedings of the European Conference on Computer Vision.Berlin: Springer, 2016: 483-499.
|
| [6] |
PAVLAKOS G, HU L, ZHOU X, et al.Learning to estimate 3D human pose and shape from a single color image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 459-468.
|
| [7] |
ROGEZ G, SCHMID C.Mocap-guided data augmentation for 3D pose estimation in the wild[C]//Advances in Neural Information Processing Systems, 2016: 3108-3116.
|
| [8] |
VAROL G, ROMERO J, MARTIN X, et al.Learning from synthetic humans[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 109-117.
|
| [9] |
CHEN C H, RAMANAN D.3D human pose estimation=2D pose estimation+matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 7035-7043.
|
| [10] |
BOGO F, KANAZAWA A, LASSNER C, et al.Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 561-578.
|
| [11] |
PISHCHULIN L, INSAFUTDINOV E, TANG S, et al.Deepcut: Joint subset partition and labeling for multiperson pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 4929-4937.
|
| [12] |
LOPER M, MAHMOOD N, ROMERO J, et al.SMPL:A skinned multi-person linear model[J].ACM Transactions on Graphics(TOG), 2015, 34(6):248.
|
| [13] |
LUVIZON D C, PICARD D, TABIA H.2D/3D pose estimation and action recognition using multitask deep learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 5137-5146.
|
| [14] |
MORENO-NOGUER F.3D human pose estimation from a single image via distance matrix regression[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 2823-2832.
|
| [15] |
ZHOU X, ZHU M, LEONARDOS S, et al.Sparseness meets deepness: 3D human pose estimation from monocular video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 4966-4975.
|
| [16] |
MARTINEZ J, HOSSAIN R, ROMERO J, et al.A simple yet effective baseline for 3D human pose estimation[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 2640-2649.
|
| [17] |
DROVER D, MV R, CHEN C H, et al.Can 3D pose be learned from 2D projections alone [C]//Proceedings of the European Conference on Computer Vision(ECCV).Berlin: Springer, 2018: 78-94.
|
| [18] |
OORD A, DIELEMAN S, ZEN H, et al.WaveNet: A generative model for raw audio[EB/OL].(2016-09-19)[2019-06-13].https: //arxiv.org/abs/1609.03499.
|
| [19] |
HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 770-778.
|
| [20] |
IONESCU C, PAPAVA D, OLARU V, et al.Human3.6 M:Large scale datasets and predictive methods for 3D human sensing in natural environments[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 36(7):1325-1339.
|
| [21] |
CHEN Y, WANG Z, PENG Y, et al.Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 7103-7112.
|
| [22] |
SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al.Dropout:A simple way to prevent neural networks from overfitting[J].The Journal of Machine Learning Research, 2014, 15(1):1929-1958.
|
| [1] | LU S Q,GUAN F X,LAI H T,et al. Two-stage underwater image enhancement method based on convolutional neural networks[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(1):321-332 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.1003. |
| [2] | BAI C P,ZHANG S Y,ZHANG X,et al. Spaceborne particle identification platform and application based on convolutional neural network[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(4):1313-1323 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0171. |
| [3] | MA S G,LI N B,HOU Z Q,et al. Object detection algorithm based on DSGIoU loss and dual branch coordinate attention[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(4):1085-1095 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0192. |
| [4] | MA J L,CUI Q L,MA Z P,et al. Self-adjusting graph convolution UNet method for 3D human pose estimation[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(1):63-74 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0969. |
| [5] | ZHAO Minghua, HUANG Xuewen, DU Shuangli, LYU Jiahao, ZHI Rui, SHI Cheng. Spatio-temporal separated transform memory networks for video anomaly detection[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0458 |
| [6] | GONG H,NI C,WANG P,et al. A smooth path planning method based on Dijkstra algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):535-541 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0377. |
| [7] | MA Qing-lu, DING Xue-qin, HUANG Xiao-xiao, ZOU Zheng. 3D point cloud segmentation method of road scene based on adaptive graph convolution[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0686 |
| [8] | WU H L,LIU H,SUN Y C. Vision Transformer-based pilot pose estimation[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(10):3100-3110 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0811. |
| [9] | LI H,ZHONG H P,ZHANG P,et al. Multi-shift interferometric phase filtering method based on convolutional neural network[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(6):2043-2050 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0805. |
| [10] | WANG J,LI P T,ZHAO R F,et al. A person re-identification method for fusing convolutional attention and Transformer architecture[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):466-476 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0456. |
| [11] | LI Y H,YU H K,MA D F,et al. Improved transfer learning based dual-branch convolutional neural network image dehazing[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(1):30-38 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0253. |
| [12] | LI M H,JIN S,DU Y. Adversarial attack method based on loss smoothing[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):663-670 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0478. |
| [13] | DAI P Z,LIU X,ZHANG X,et al. An iterative pedestrian detection method sensitive to historical information features[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(9):2493-2500 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0665. |
| [14] | CHEN C,ZHAO W. Remote sensing target detection based on dynanic feature selection[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(3):702-709 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0300. |
| [15] | LYU Z Y,NIE X Y,ZHAO A B. Prediction of wing aerodynamic coefficient based on CNN[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(3):674-680 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0276. |
| [16] | ZHOU H,HOU Q Y,BIAN C J,et al. An infrared small target detection network under various complex backgrounds realized on FPGA[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(2):295-310 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0221. |
| [17] | BAO Y T,LIU W,LI R S,et al. Semantic segmentation of remote sensing images based on U-shaped network combined with spatial enhance attention[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(7):1828-1837 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0544. |
| [18] | LI L,FU M H,ZHANG T,et al. A workpiece location algorithm based on improved SSD[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(6):1260-1269 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0442. |
| [19] | ZENG Sheng, ZHU Fengchao, YANG Jian. A new RF fingerprint identification method based on preamble of signal[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(12): 2566-2575. doi: 10.13700/j.bh.1001-5965.2021.0164 |
| [20] | XIE Xiangying, LAI Guangzhi, NA Zhixiong, LUO Xin, WANG Dong. Occlusion recognition algorithm based on multi-resolution feature auto-selection[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(7): 1154-1163. doi: 10.13700/j.bh.1001-5965.2021.0289 |
| 1. | 何建航,孙郡瑤,刘琼. 基于人体和场景上下文的多人3D姿态估计. 软件学报. 2024(04): 2039-2054 .  | |
| 2. | 陈曹阳,金灵. 神经网络在土木工程中的研究与应用. 山西建筑. 2022(06): 194-198 . | |
| 3. | 张宜春,黄一鸣,潘达. 基于人体姿态估计的京剧虚拟人物互动系统. 中国传媒大学学报(自然科学版). 2022(06): 43-49 . | |
| 4. | 龙涛. 基于移动机器人和单目视觉的姿态测量方法. 光学技术. 2021(02): 203-208 . | |
| 5. | 张华,陈来. 基于最近邻特定点的人体运动姿态特征点标定识别方法. 激光杂志. 2021(04): 183-186 . |

Figures(6) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.

Rui Shouzhen, Xing Yuming. Comparative studies of interior ballistic performance among several missile eject power systems[J]. Journal of Beijing University of Aeronautics and Astronautics, 2009, 35(6): 766-770. (in Chinese)





 DownLoad:
DownLoad: