| Citation: | ZHANG Mengqin, MENG Quanling, ZHANG Weiganget al. Video thumbnail recommendation based on deep visual-semantic embedding[J]. Journal of Beijing University of Aeronautics and Astronautics, 2019, 45(12): 2479-2486. doi: 10.13700/j.bh.1001-5965.2019.0415(in Chinese)

|
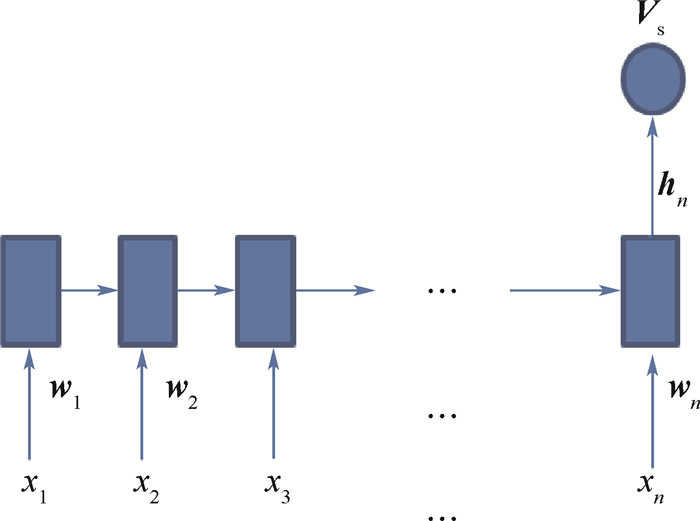
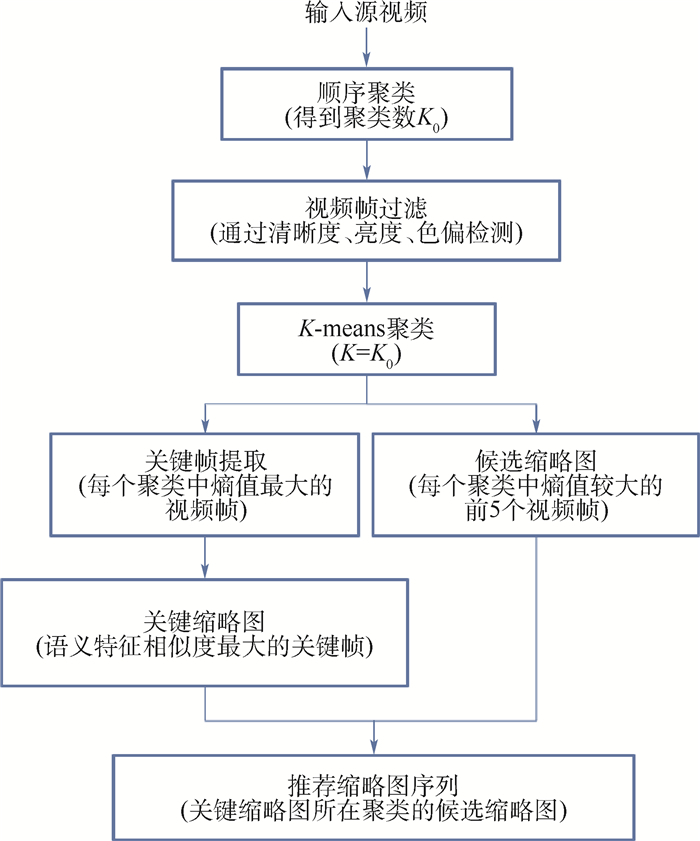
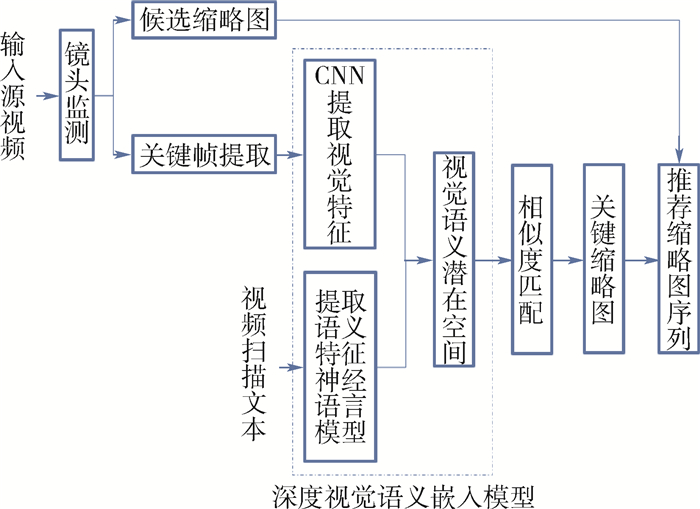
Video thumbnail, as the most intuitive form of video content, plays an important role in video sharing sites and is one of the key elements to attract users to click and watch the video. However, a descriptive statement related to video content with a video thumbnail associated with the content of the statement is often more attractive to user. Therefore, a complete video thumbnail recommendation framework with a deep visual-semantic embedding model is proposed in this paper. This model uses the convolutional neural network to extract the visual features of video keyframes, and uses recurrent neural network to extract the semantic features of description sentences. After embedding the visual features and the semantic features into the visual-semantic potential space of the same dimension, the key frames related to the content of the descriptive sentences are recommended as video thumbnails by comparing the correlation between the visual features and the semantic features. Experiments on different categories of web videos show that the proposed method can effectively recommend contented-related video thumbnail sequence from videos for given descriptive statements and enhance the user experience.
| [1] |
GAO Y L, ZHANG T, XIAO J.Thematic video thumbnail selection[C]//Proceedings of the 2009 IEEE International Conference on Image Processing (ICIP).Piscataway, NJ: IEEE Press, 2009: 4333-4336.
|
| [2] |
LIAN H C, LI X Q, SONG B.Automatic video thumbnail selection[C]//Proceedings of the 2011 IEEE International Conference on Multimedia Technology (ICMT).Piscataway, NJ: IEEE Press, 2011: 242-245.
|
| [3] |
JIANG J F, ZHANG X P.Video thumbnail extraction using video time density function and independent component analysis mixture model[C]//Proceedings of the 2011 IEEE International Conference on Acoustic, Speech, and Signal Processing (ICASSP).Piscataway, NJ: IEEE Press, 2011: 1417-142.
|
| [4] |
LIU C X, HUANG Q M, JIANG S Q.Query sensitive dynamic web video thumbnail generation[C]//Proceedings of the 2011 IEEE International Conference on Image Processing (ICIP).Piscataway, NJ: IEEE Press, 2011: 2449-2452.
|
| [5] |
ZHANG W G, LIU C X, WANG Z J, et al.Web video thumbnail recommendation with content-aware analysis and query-sensitive matching[J].Multimedia Tools and Applications, 2014, 73:547-571. doi: 10.1007/s11042-013-1607-5
|
| [6] |
ZHANG W G, LIU C X, HUANG Q M, et al.A novel framework for web video thumbnail generation[C]//Proceedings of the 8 th International Conference on Intelligent Information Hiding and Multimedia Signal Processing.Piscataway, NJ: IEEE Press, 2012: 343-346.
|
| [7] |
ZHAO B Q, LIN S J, QI X, et al.Automatic generation of visual-textual web video thumbnail[C]//Siggraph Asia Posters.New York: ACM, 2017: 41.
|
| [8] |
SONG Y L, REDI M, VAllMITJANA J, et al.To click or not to click: Automatic selection of beautiful thumbnails from videos[C]//Proceedings of the 25th ACM International on Conference on Information and Knowledge Management.New York: ACM, 2016: 659-668.
|
| [9] |
LIU W, MEI T, ZHANG Y D, et al.Multi-task deep visual-semantic embedding for video thumbnail selection[C]//Proceedings of IEEE Conference on Computer Vision an Pattern Recognition(CVPR).Piscataway, NJ: IEEE Press, 2015: 3707-3715.
|
| [10] |
ANDREA F, GREG S C, JON S, et al.Devise: A deep visual-semantic embedding model[C]//Proceedings of Neural Information Processing Systems Conference.Nevada: NIPS, 2013: 2121-2129.
|
| [11] |
CHUNG J, GULCEHRE C, CHO K H, et al.Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL].(2014-12-11)[2019-07-25].
|
| [12] |
HE K M, ZHANG X Y, REN S Q, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ: IEEE Press, 2016: 770-778.
|
| [13] |
金红, 周源华, 梅承力.用非监督式聚类进行视频镜头分割[J].红外与激光工程, 2000, 29(5):42-46. doi: 10.3969/j.issn.1007-2276.2000.05.010
JIN H, ZHOU Y H, MEI C L.Video shot segmentation using unsupervised clustering[J].Infrared and Laser Engineering, 2000, 29(5):42-46(in Chinese). doi: 10.3969/j.issn.1007-2276.2000.05.010
|
| [14] |
李祚林, 李晓辉, 马灵玲, 等.面向无参考图像的清晰度评价方法研究[J].遥感技术与应用, 2011, 26(2):239-246.
LI Z L, LI X H, MA L L, et al.Research of definition assessment based on no-reference digital image quality[J].Remote Sensing Technology and Application, 2011, 26(2):239-246(in Chinese).
|
| [15] |
徐晓昭, 蔡轶珩, 刘长江, 等.基于图像分析的偏色检测及颜色校正方法[J].测控技术, 2008, 27(5):10-12. doi: 10.3969/j.issn.1000-8829.2008.05.003
XU X Z, CAI Y H, LIU C J, et al.Color cast detection and color correction methods based on image analysis[J].Chinese Journal of Measurement and Control Technology, 2008, 27(5):10-12(in Chinese). doi: 10.3969/j.issn.1000-8829.2008.05.003
|
| [16] |
LIN T Y, MAIRE M, BELONGIE S, et al.Microsoft COCO: Common objects in context[C]//Proceedings of European Conference on Computer Vision.Berlin: Springer, 2014: 740-755.
|
| [17] |
XU J, MEI T, YAO T, et al.MSR-VTT: A large video description dataset for bridging video and language[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ: IEEE Press, 2016: 5288-5296.
|
| [1] | BAI C P,ZHANG S Y,ZHANG X,et al. Spaceborne particle identification platform and application based on convolutional neural network[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(4):1313-1323 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0171. |
| [2] | LIU C J,QIAO Z,YAN H W,et al. Semantic segmentation network of remote sensing images based on dual path supervision[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(3):732-741 (in Chinese). doi: 10.13700/j.bh.1001-5965.2023.0155. |
| [3] | REN Liqiang, WANG Haipeng, PAN Xinlong, WAN Bing, TANG Tiantian. A complex maneuver recognition method based on wavelet time-frequency image and lightweight CNN-Transformer hybrid neural network[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0745 |
| [4] | ZHANG Luyihang, YANG Yanming, CHEN Yongzhan, LI Junliang, DAI Haomin. Remaining Useful Life life prediction of variable-operating turbofan engine based on VMD-CNN-BiLSTM[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2021.0051 |
| [5] | SHI Yangyu, XIE Chengjie, ZHENG Diwen, LU Shuhua. Multi-scale anomaly behavior detection based on Mamba-CNN[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0416 |
| [6] | ZHANG Y T,LI Q Y,LIU S K. Tabular subordination relation extraction based on graph convolutional networks[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(4):1308-1315 (in Chinese). doi: 10.13700/j.bh.1001-5965.2022.0382. |
| [7] | ZHAO Minghua, HUANG Xuewen, DU Shuangli, LYU Jiahao, ZHI Rui, SHI Cheng. Spatio-temporal separated transform memory networks for video anomaly detection[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2024.0458 |
| [8] | JIANG Y,CHEN M Y,YUAN Q,et al. Departure flight delay prediction based on spatio-temporal graph convolutional networks[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(5):1044-1052 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0415. |
| [9] | WANG Hong-yong, MA Li-shu, XU Ping. Research on Identification Method of Key Aircraft Based on Temporal Networktime network[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0259 |
| [10] | WANG Zai-sheng, WANG Xiao-feng, SHEN Guo-dong, ZHANG Zeng-jie, QUAN Da-ying. Self-Supervised Learning for Community Detection Based on Deep Graph Convolutional Networks[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0408 |
| [11] | HOU Zhi-qiang, ZHAO Jia-xin, CHEN Yu, MA Su-gang, YU Wang-sheng, FAN Jiu-lun. Cascaded object drift determination network for long-term visual tracking[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0504 |
| [12] | ZHANG Dong-dong, WANG Chun-ping, FU Qiang. Camouflaged Object Detection Network Based on Human Visual Mechanisms[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0511 |
| [13] | LYU Z Y,NIE X Y,ZHAO A B. Prediction of wing aerodynamic coefficient based on CNN[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(3):674-680 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0276. |
| [14] | ZHANG H,YU Y Z,QIU X T. ORB-SLAM2 algorithm based on improved key frame selection[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(1):45-52 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0173. |
| [15] | YANG Jun, ZHANG Jin-ying. U-shaped semantic segmentation network of high-resolution remote sensing images embedded with the self-attention mechanism[J]. Journal of Beijing University of Aeronautics and Astronautics. doi: 10.13700/j.bh.1001-5965.2023.0269 |
| [16] | PU L,LI H L,HOU Z Q,et al. Siamese network tracking based on high level semantic embedding[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(4):792-803 (in Chinese). doi: 10.13700/j.bh.1001-5965.2021.0319. |
| [17] | LI Guoliang, LI Qiao, XU Yajun, XIONG Huagang. A DDQN-based mixed-criticality messages scheduling method for network-on-chip[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(7): 1233-1241. doi: 10.13700/j.bh.1001-5965.2021.0006 |
| [18] | LIU Hao, YANG Xiaoshan, XU Changsheng. Long-tail image captioning with dynamic semantic memory network[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(8): 1399-1408. doi: 10.13700/j.bh.1001-5965.2021.0518 |
| [19] | LI Zheyang, ZHANG Ruyi, TAN Wenming, REN Ye, LEI Ming, WU Hao. A graph convolution network based latency prediction algorithm for convolution neural network[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(12): 2450-2459. doi: 10.13700/j.bh.1001-5965.2021.0149 |
| [20] | TIAN Limei, GONG Mengtong, TANG Diyin, HAN Danyang, YU Jinsong, LI Chunwei. Degradation indicator extraction for aerospace CMG based on power consumption analysis[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(10): 1899-1905. doi: 10.13700/j.bh.1001-5965.2021.0060 |

Figures(5) / Tables(1)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.

Guo Yi, Liu Jinkun. Adaptive dynamic surface control for aircraft flight path angle[J]. Journal of Beijing University of Aeronautics and Astronautics, 2013, 39(2): 275-279. (in Chinese)





 DownLoad:
DownLoad: