| Citation: | TIAN Yang, YAN Haihua. A computing framework for massive scientific data based on auto-partitioning algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(6): 1004-1012. doi: 10.13700/j.bh.1001-5965.2020.0704(in Chinese)

|
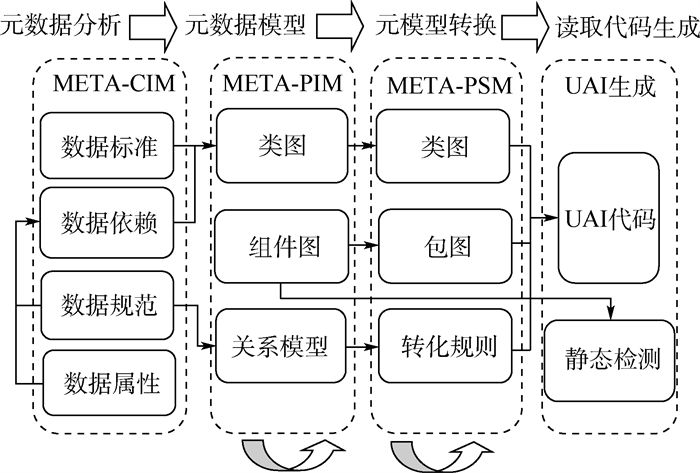
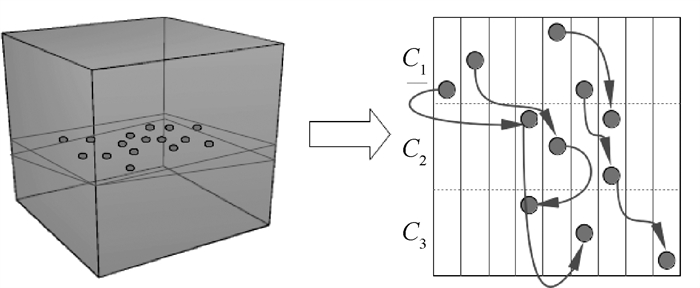
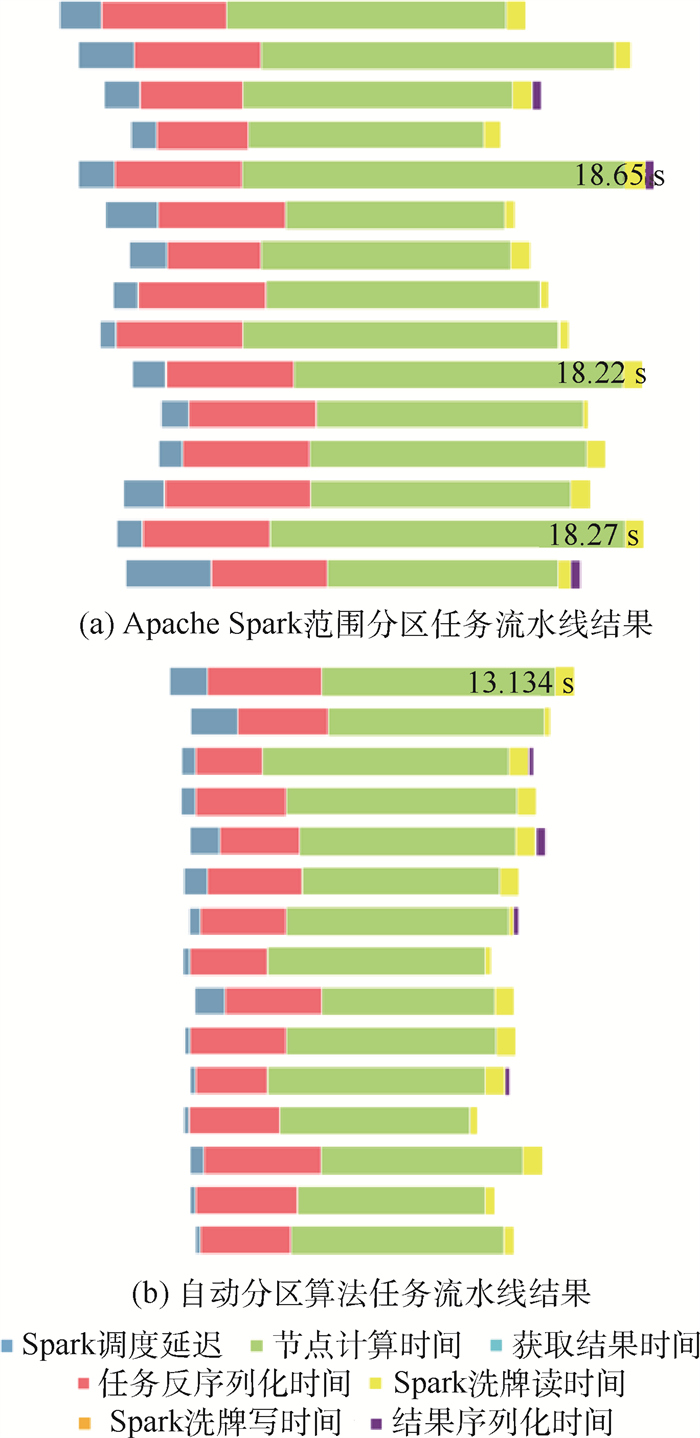
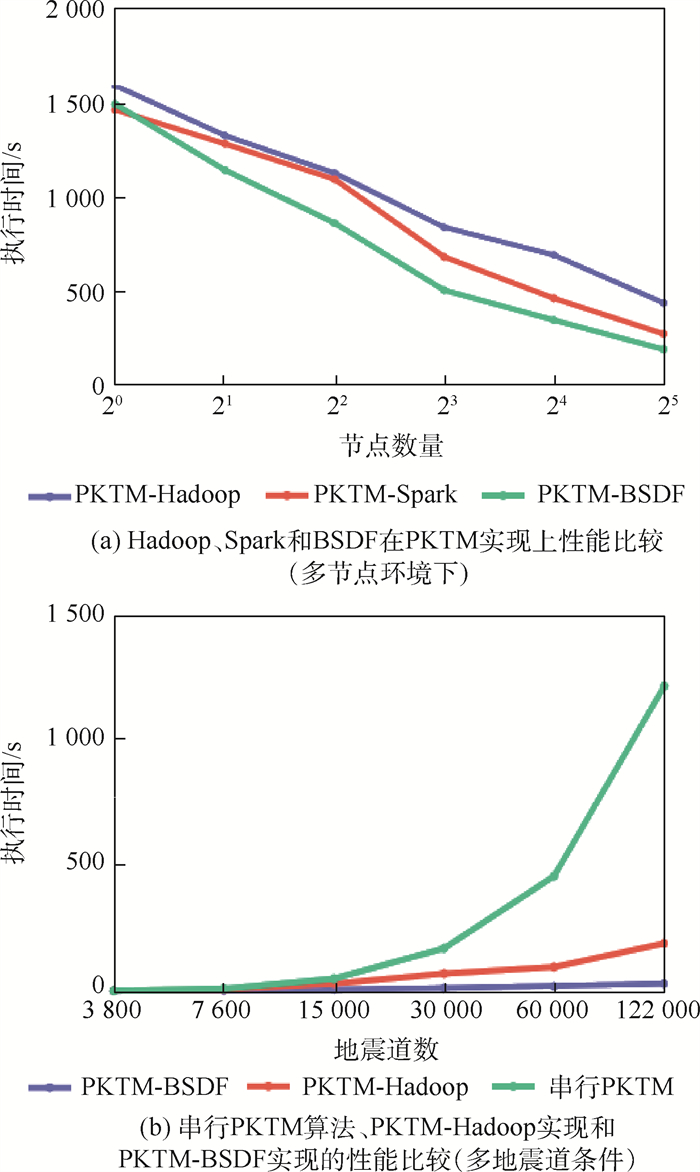
In the scientific research field, storage capacity, processing efficiency and analysis accuracy cannot keep pace with the exponential growth rate of scientific data. Thus, a massive scientific data calculation framework named BSDF is proposed based on scientific data structure and standards. A unified data interface based on model-driving is integrated to implement indiscriminate access to heterogeneous scientific data. Then an auto-partitioning algorithm based on scientific metadata is proposed, which determines task granularities through parameter prefetching and hyperplane dimension calculation. Experimental results show that compared with the performance of the H5Spark framework, that of the BSDF is increased by 39%-68% in nine benchmark tests. In the optimization of the domain-specific PKTM algorithm, a speedup ratio is increased by 41.62 times.

| [1] |
GRAY J, LIU D T, NIETO-SANTISTEBAN M, et al. Scientific data management in the coming decade[J]. ACM SIGMOD Record, 2005, 34(4): 34-41. doi: 10.1145/1107499.1107503
|
| [2] |
The HDF Group. Hierarchical data format. Version 5[EB/OL]. [2020-12-01]. http://www.hdfgroup.org/HDF5.
|
| [3] |
UCAR Community Programs. Network common data form (NetCDF)[EB/OL]. [2020-12-01]. https://www.unidata.ucar.edu/software/netcdf.
|
| [4] |
ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: Cluster computing with working sets[C]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing. New York: ACM, 2010: 1-10.
|
| [5] |
SUTTON J, AUSTIN Z. Qualitative research: Data collection, analysis, and management[J]. The Canadian Journal of Hospital Pharmacy, 2015, 68(3): 226-231.
|
| [6] |
MIKAEL N, AMBJÖRN N, ERIK D, et al. Harmonization methodology for metadata models[EB/OL]. [2020-12-01]. https://hal.archives-ouvertes.fr/hal-00591548.
|
| [7] |
DPLA. Metadata application profile. Version 4.0[EB/OL]. [2020-12-01]. http://dp.la/info/wpcontent/uploads/2015/03/MAPv4.pdf.
|
| [8] |
DIAMANTOPOULOS N, SGOUROPOULOU C, KASTRANTAS K, et al. Developing a metadata application profile for sharing agricultural scientific and scholarly research resources[C]//Research Conference on Metadata and Semantic Research. Berlin: Springer, 2011: 453-466.
|
| [9] |
RILEY J. Understanding metadata: What is metadata, and what is it for [M]//WOOLCOTT L. Baltimore: National information standards organization. Oxford: Taylor, 2017: 669-670.
|
| [10] |
BARGMEYER B E, GILLMAN D W. Metadata standards and metadata registries: An overview[EB/OL]. [2020-12-01]. https://www.bls.gov/osmr/research-papers/2000/pdf/st000010.pdf.
|
| [11] |
JONES M B, BERKLEY C, BOJILOVA J, et al. Managing scientific metadata[J]. IEEE Internet Computing, 2001, 5(5): 59-68. doi: 10.1109/4236.957896
|
| [12] |
HANISCH R J, FARRIS A, GREISEN E W, et al. Definition of the flexible image transport system (FITS)[J]. Astronomy & Astrophysics, 2001, 376(1): 359-380.
|
| [13] |
PARK J K. Improving the performance of HDFS by reducing I/O using adaptable I/O system[C]//2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT). Piscataway: IEEE Press, 2016: 3139-3144.
|
| [14] |
SEG Technical Standards Committee. SEG-Y_r2.0: SEG-Y revision 2.0 data exchange format[S]. [S. l. ]: Society of Exploration Geophysicists, 2017.
|
| [15] |
DEAN J, GHEMAWAT S. MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113. doi: 10.1145/1327452.1327492
|
| [16] |
YUN H, YU H F, HSIEH C J, et al. NOMAD: Non-locking, stochastic multi-machine algorithm for asynchronous and decentralized matrix completion[J]. Proceedings of the VLDB Endowment, 2013, 7(11): 975-986.
|
| [17] |
LIU J, RACAH E, KOZIOL Q, et al. H5Spark: Bridging the I/O gap between Spark and scientific data formats on HPC systems[C]//Proceedings of the Cray Users Group, 2016.
|
| [18] |
AGARWAL A, CHAPELLE O, DUDÍK M, et al. A reliable effective tera scale linear learning system[J]. Journal of Machine Learning Research, 2014, 15(1): 1111-1133.
|
| [19] |
TIAN Y, LIU C, YAN H H. Accelerate large-scale seismic data Kirchhoff time migration in spark[C]//2018 4th International Conference on Information Management (ICIM). Piscataway: IEEE Press, 2018: 41-45.
|

Figures(8) / Tables(2)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: