| Citation: | XIA J W,LIU Z K,ZHU X F,et al. A coordinated rendezvous method for unmanned surface vehicle swarms based on multi-agent reinforcement learning[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(12):3365-3376 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0088

|
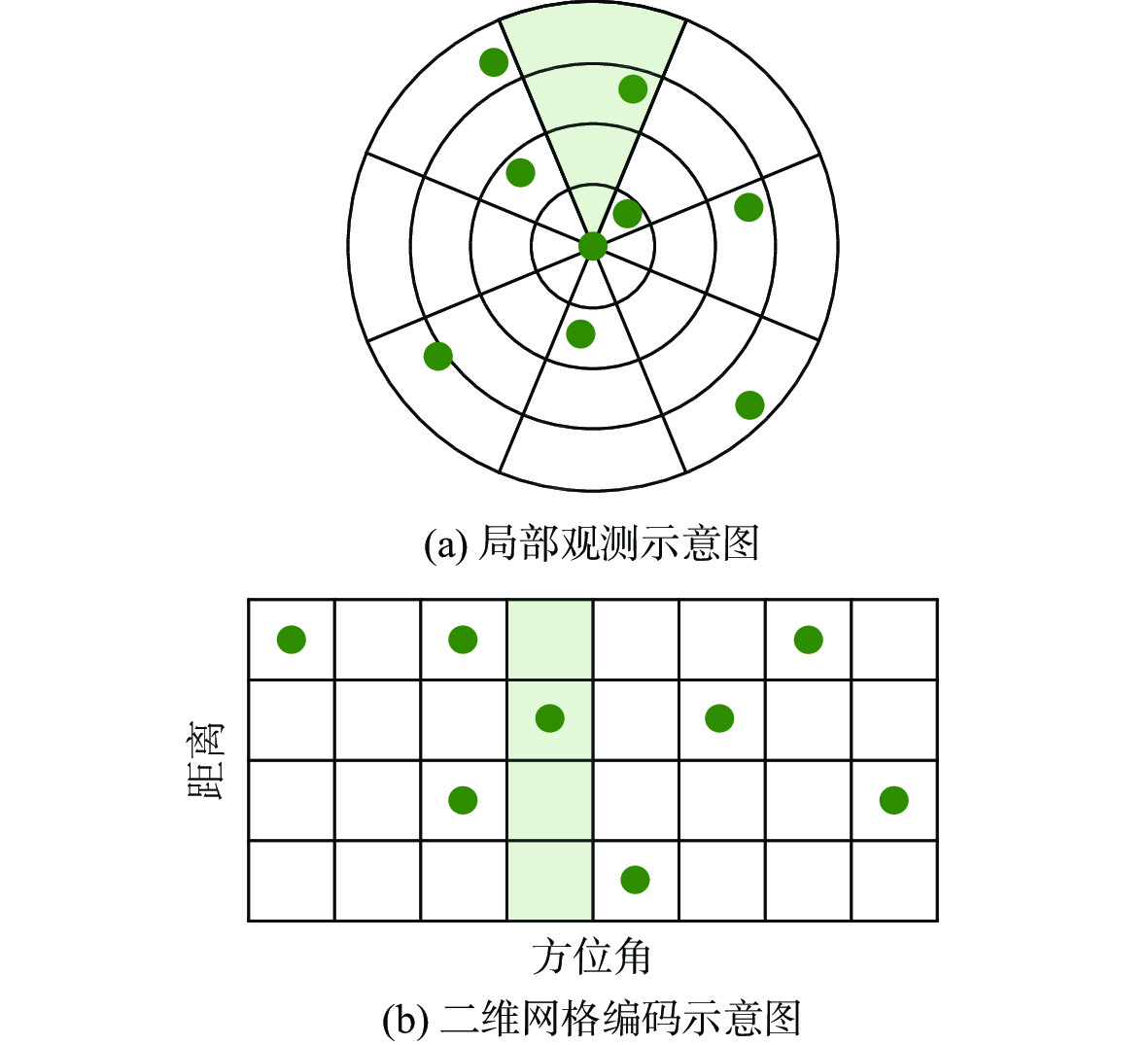
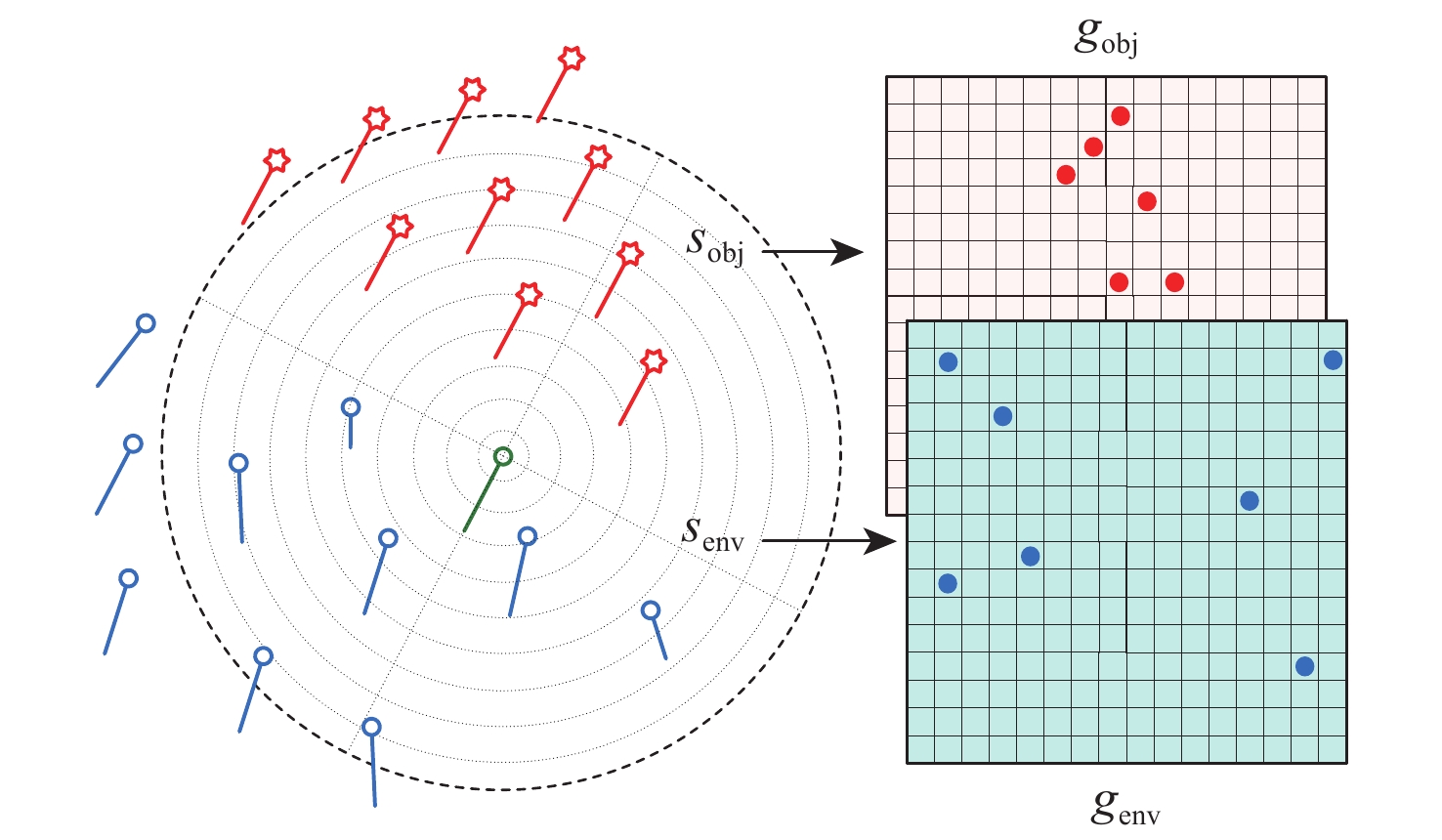
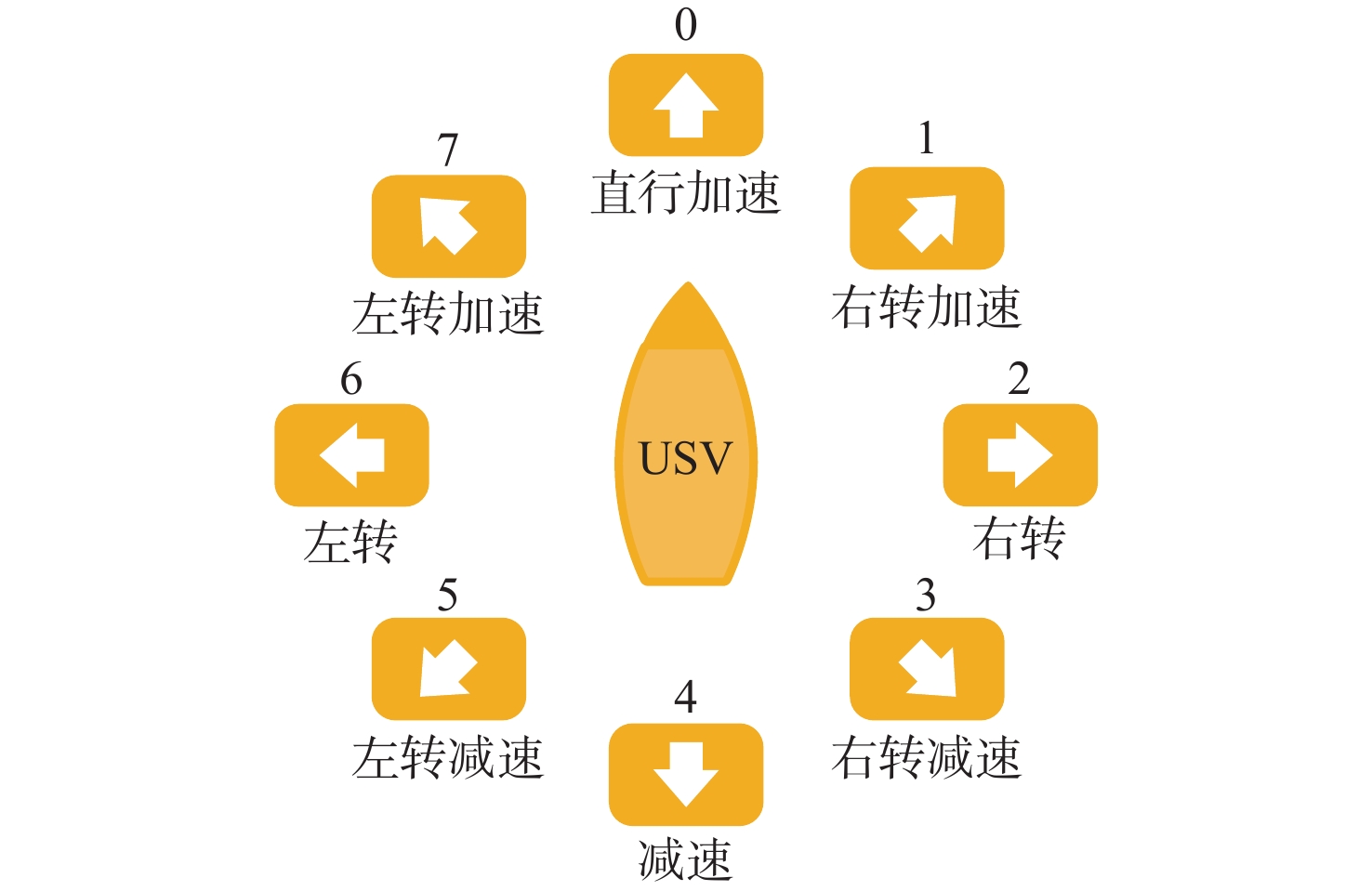
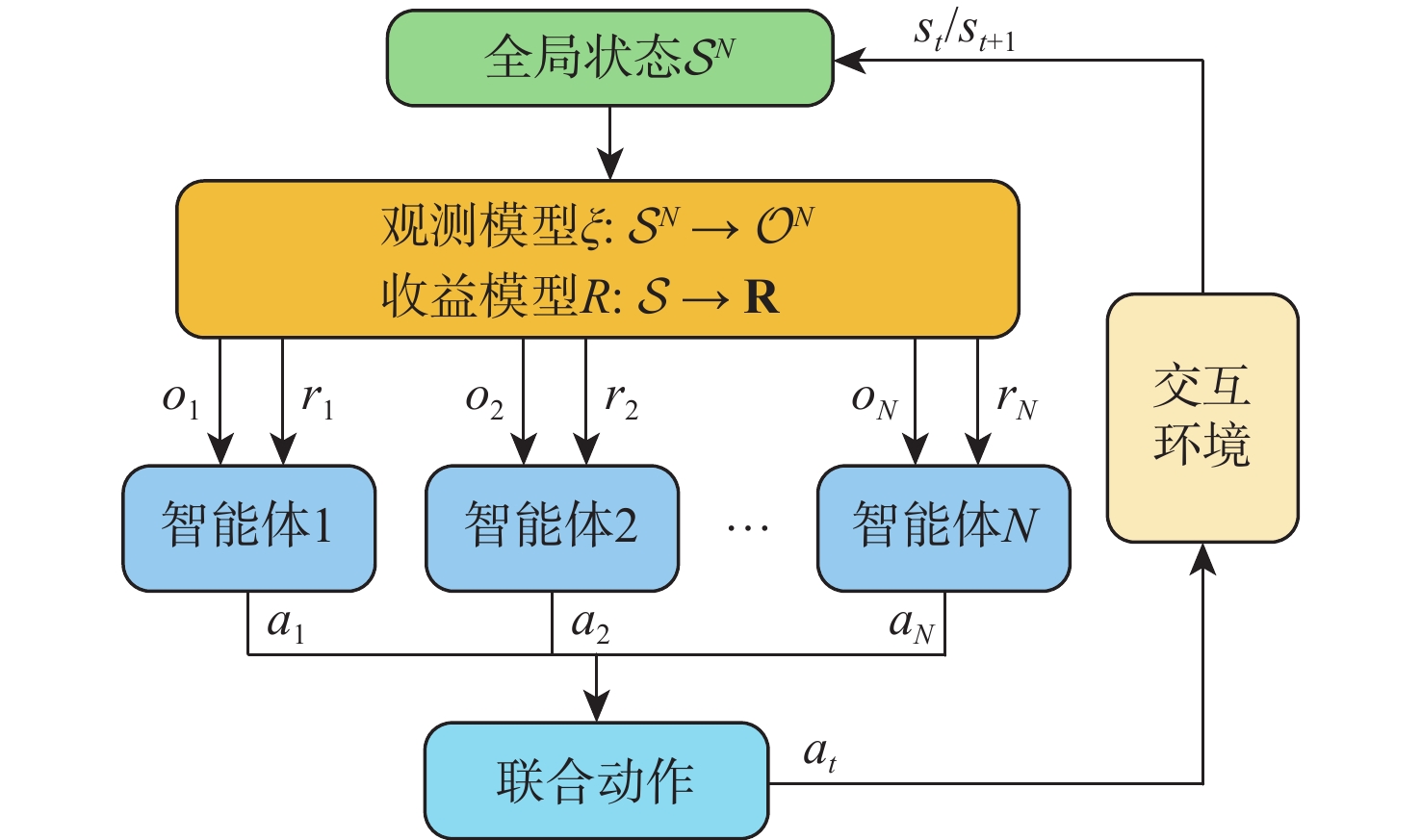
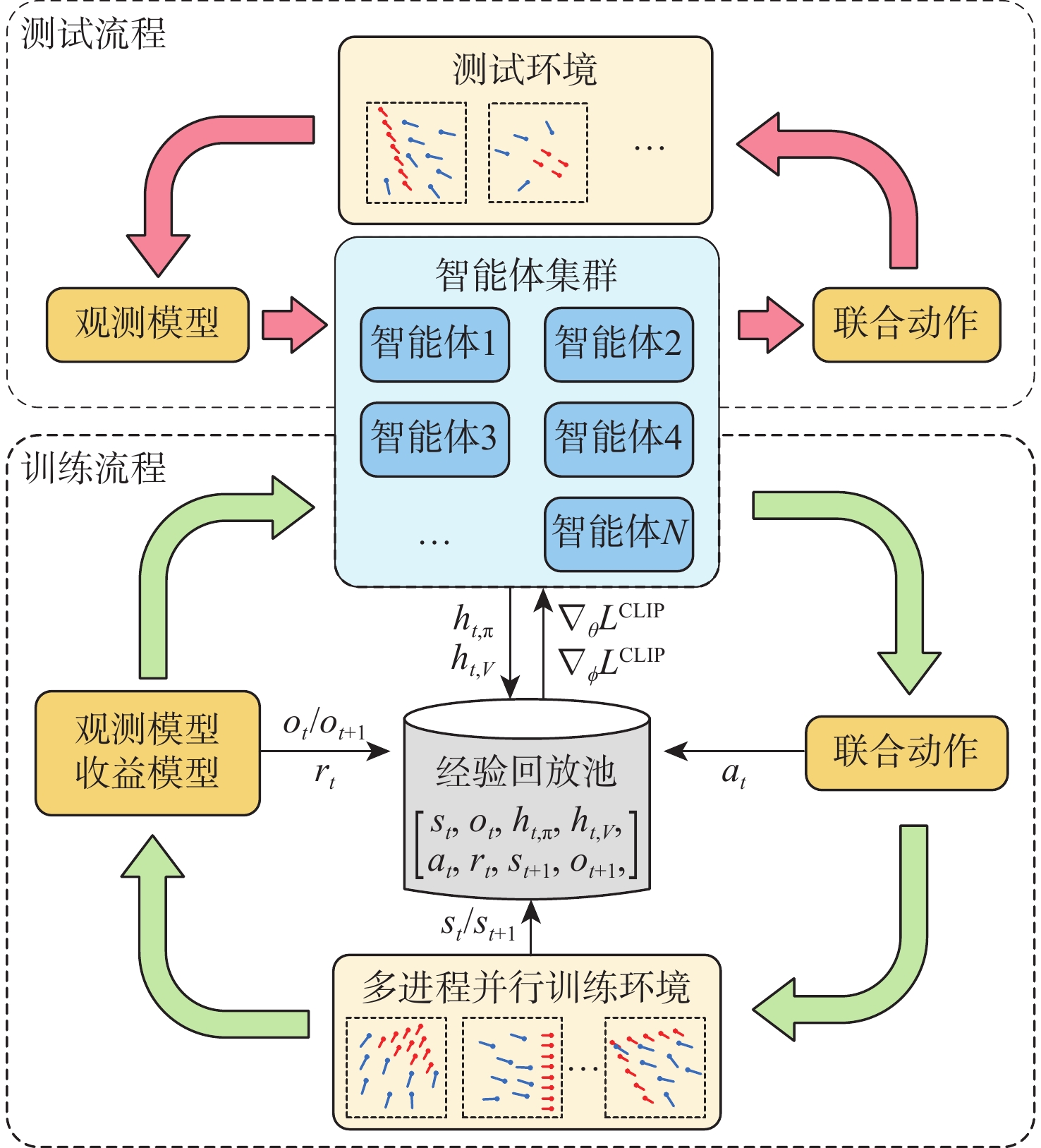
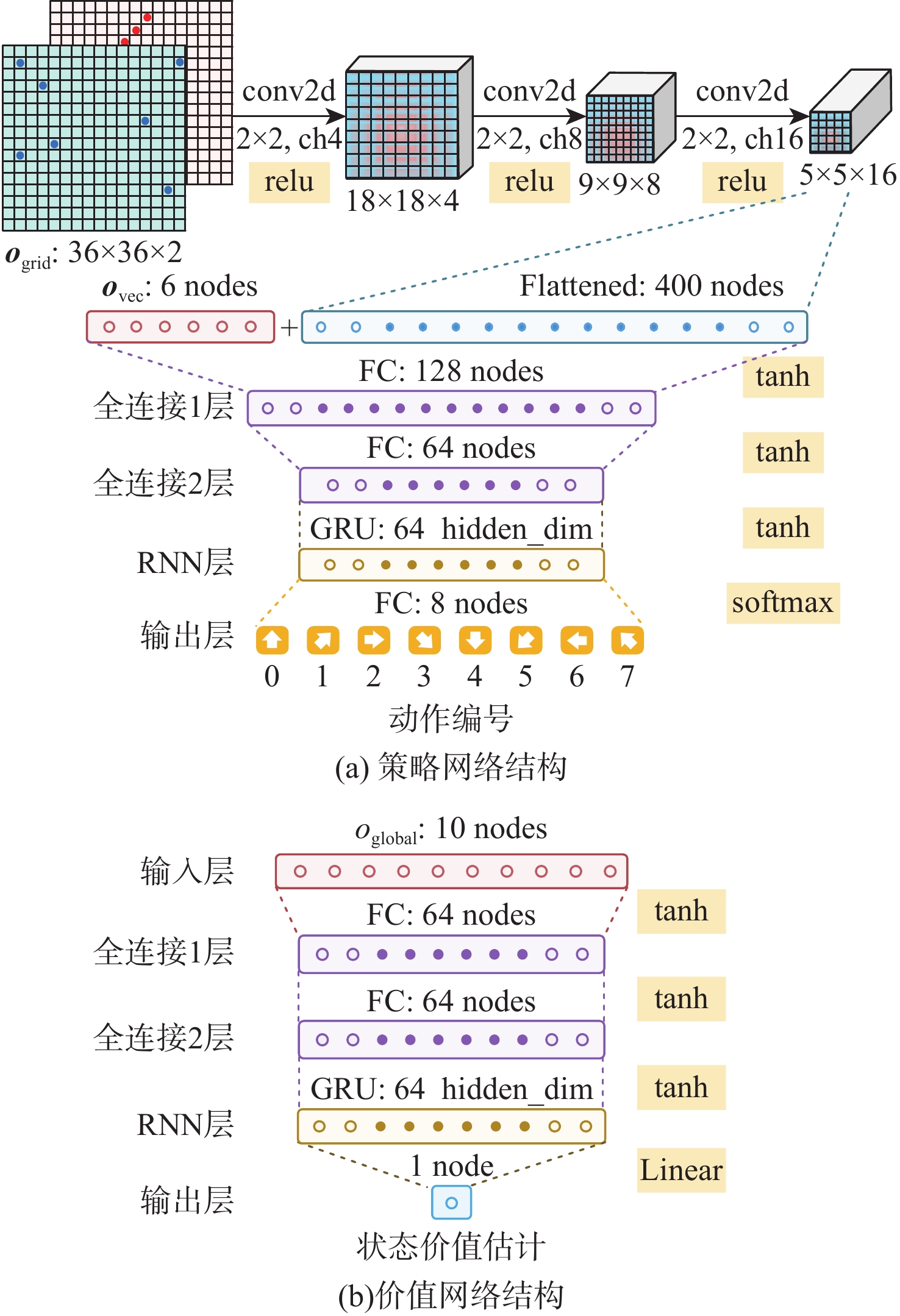
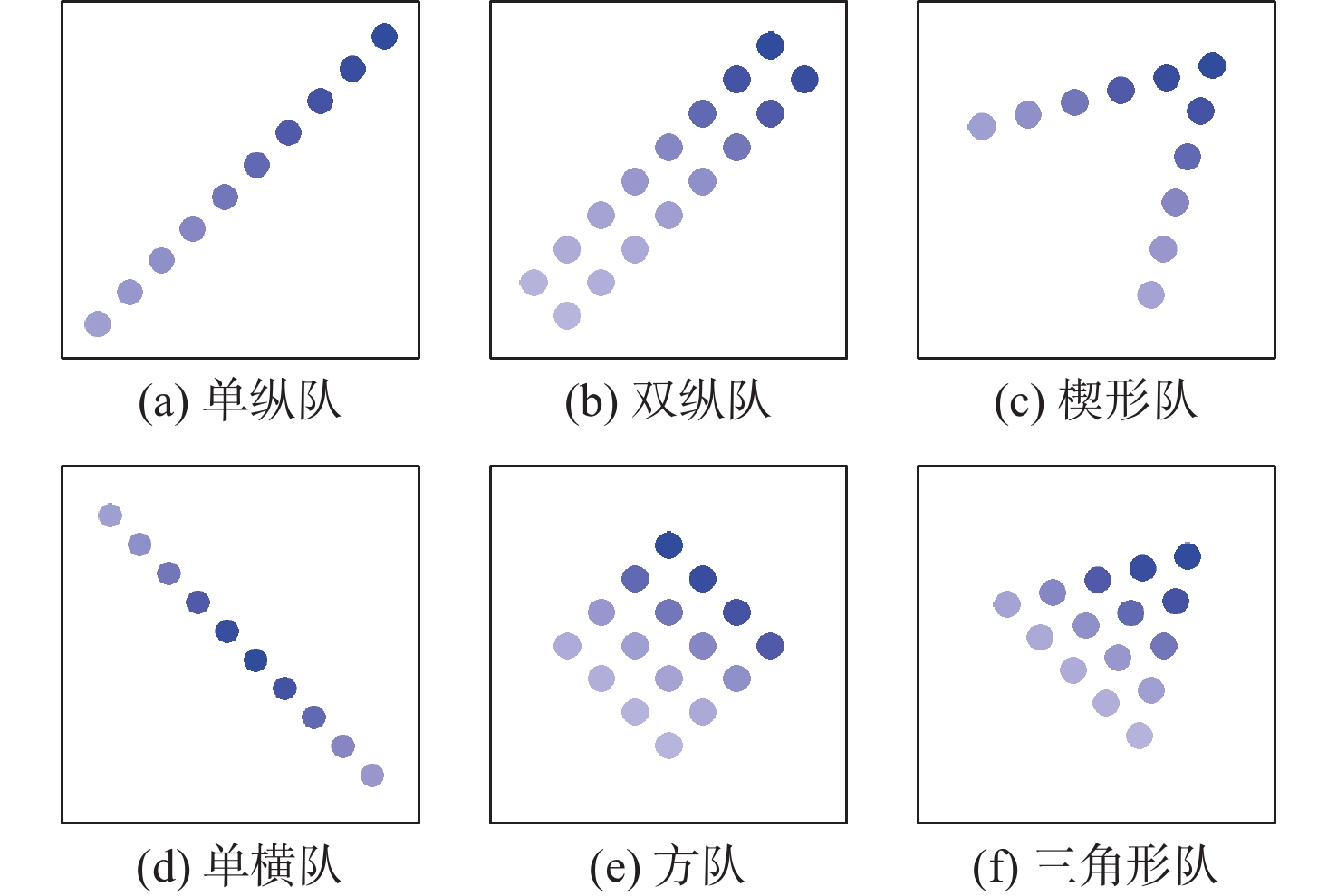
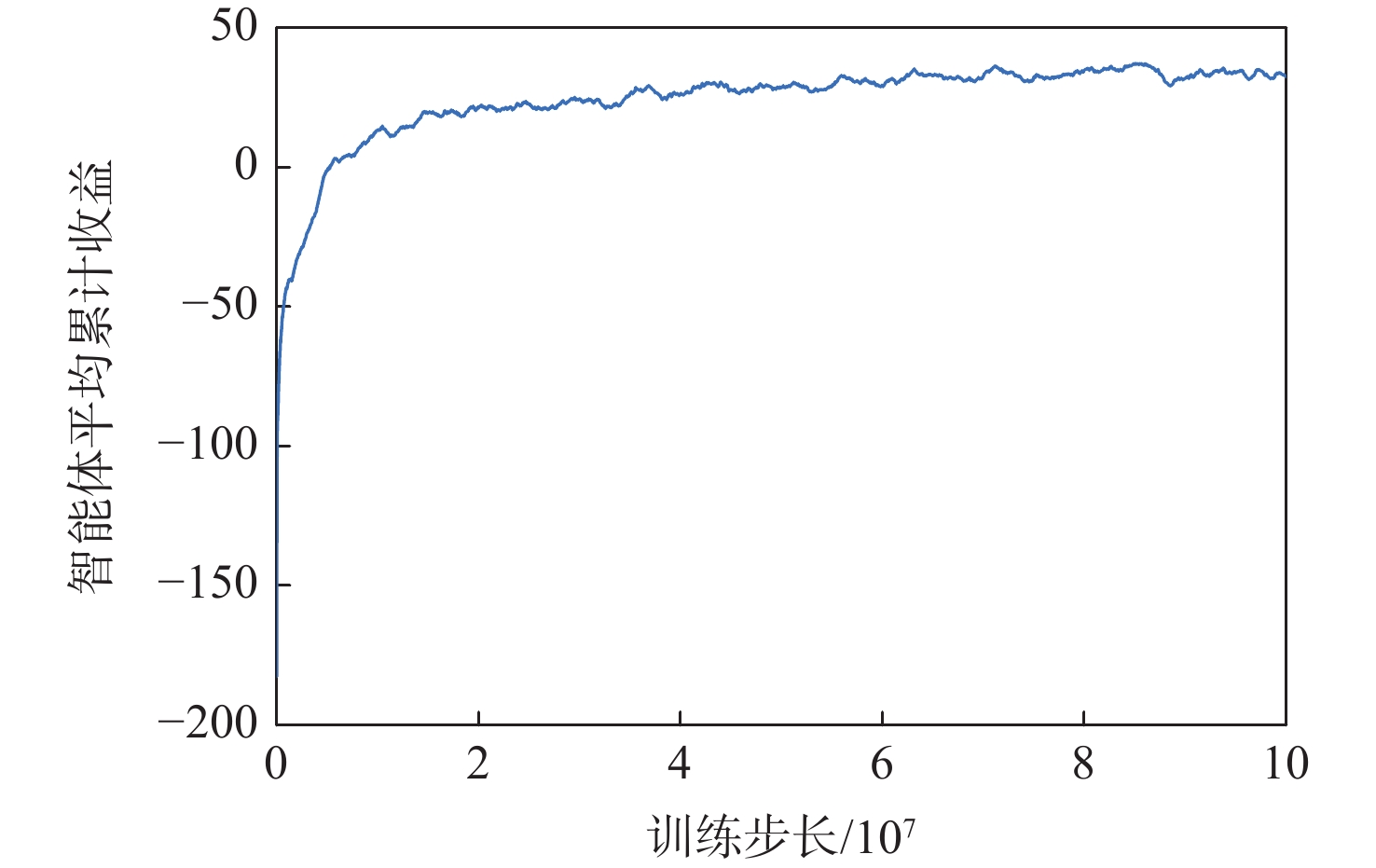
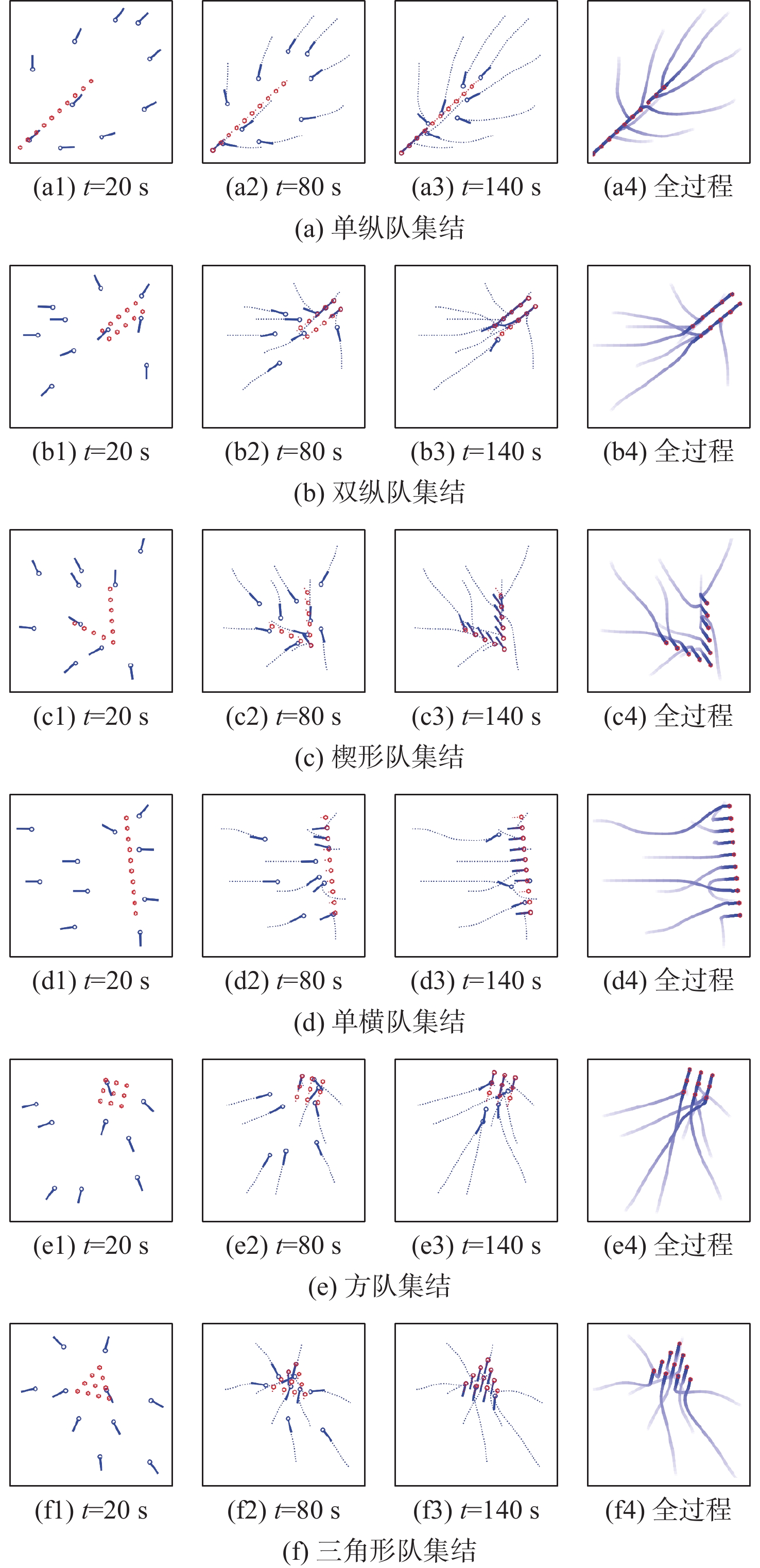
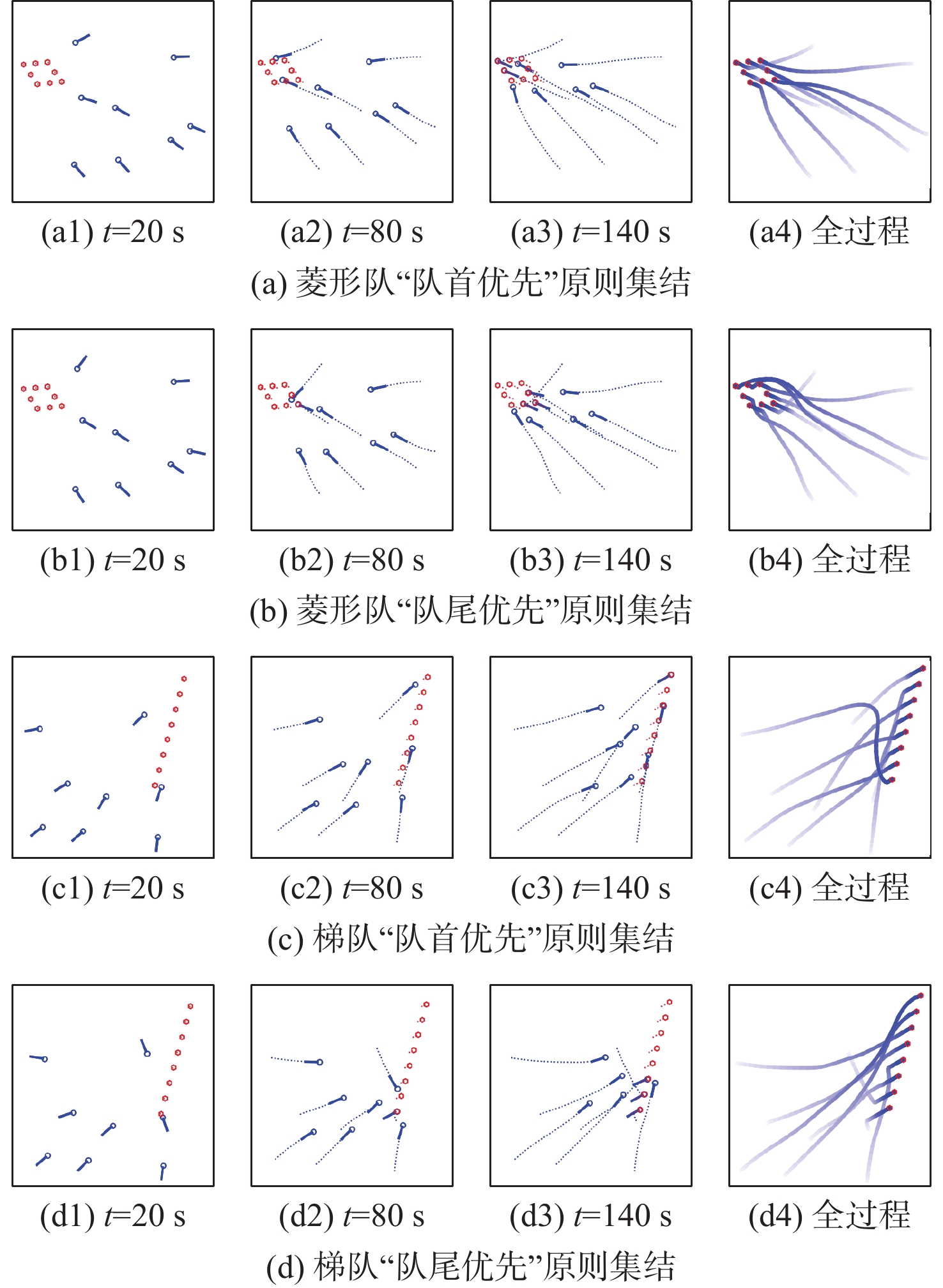
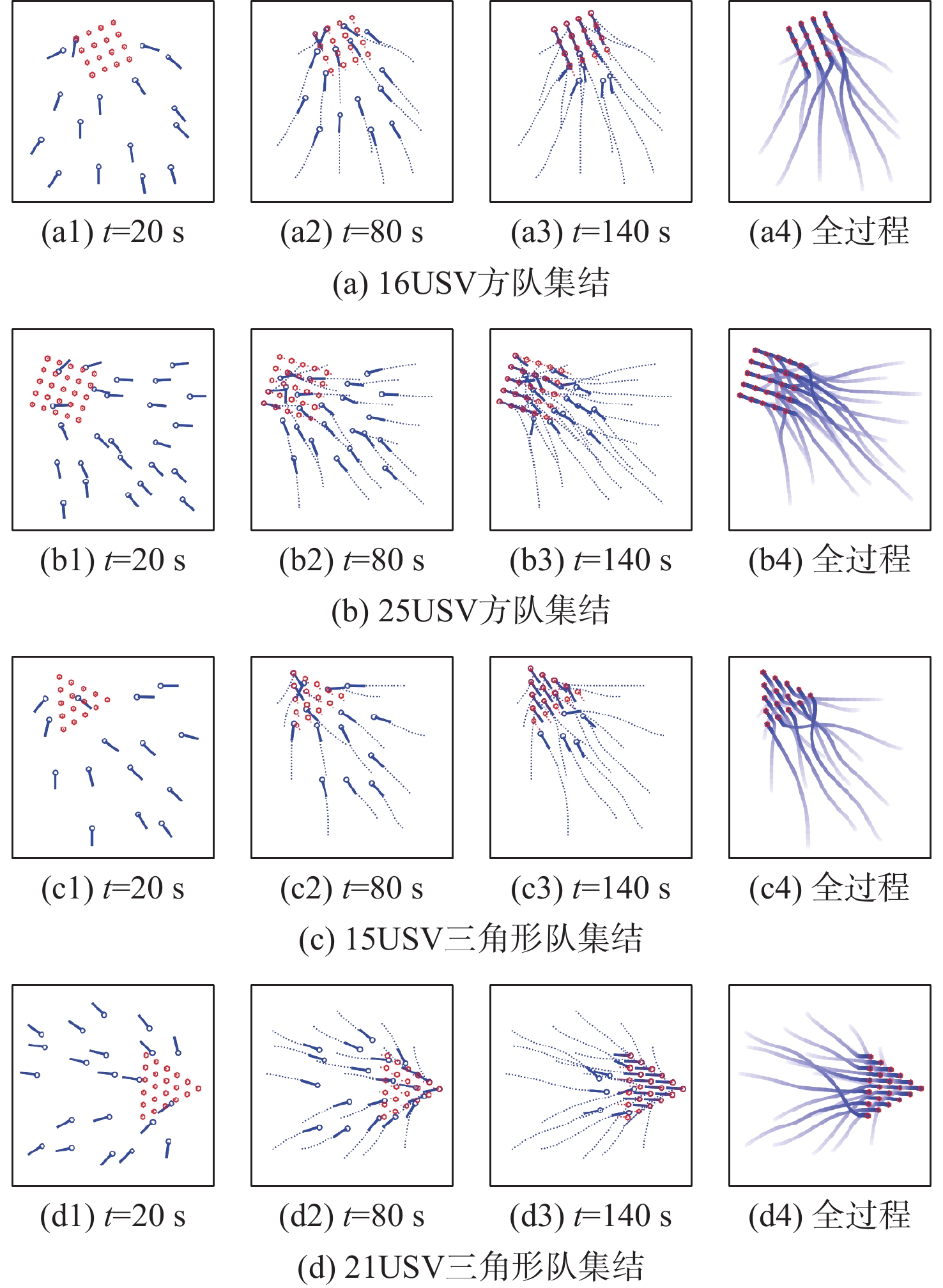
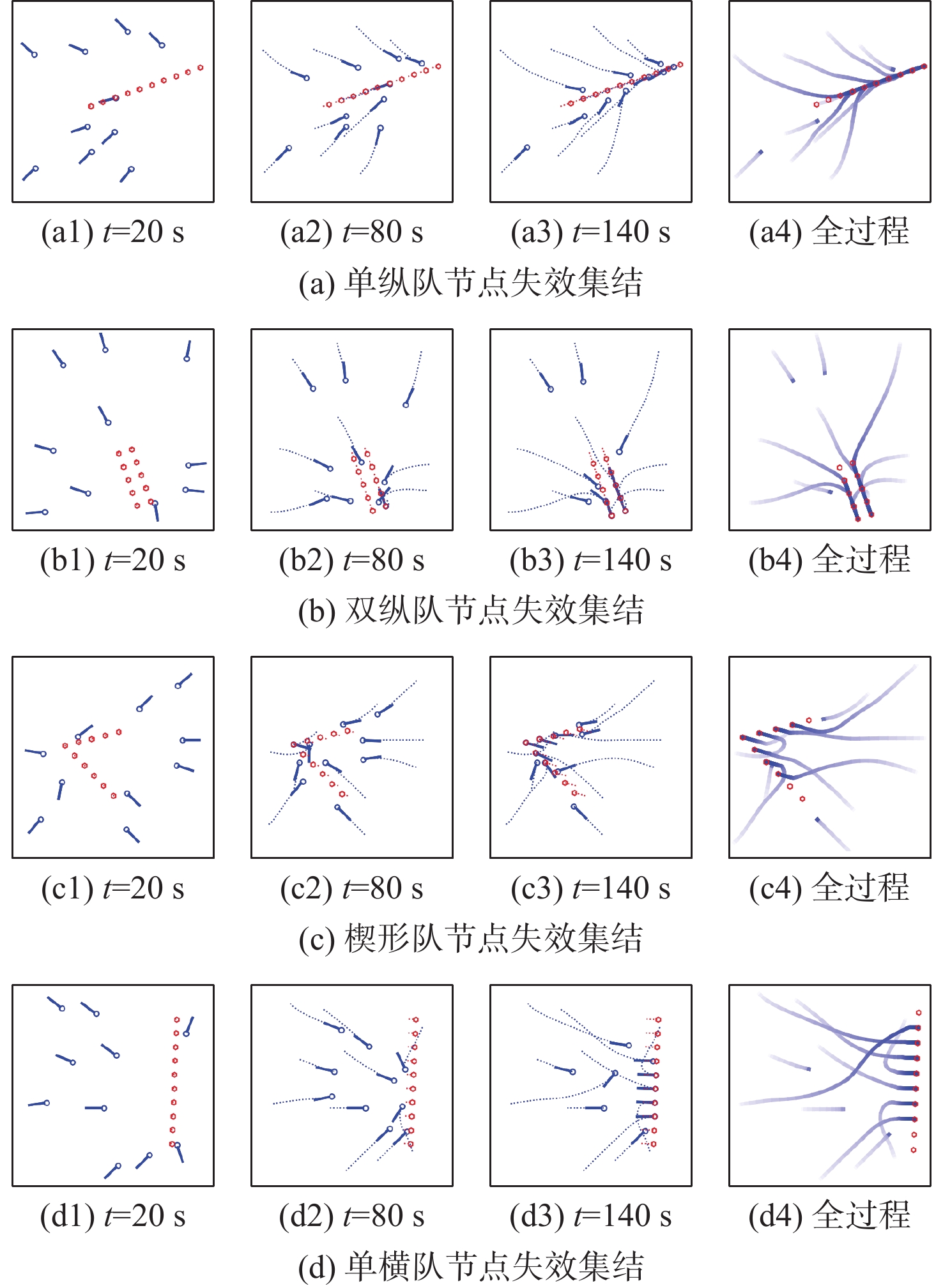
To address the challenge of rendezvousing an indeterminate number of homogeneous unmanned surface vehicles (USV) into desired formations, a distributed rendezvousing control method is introduced, leveraging multi-agent reinforcement learning (MARL). Recognizing the communication and perception constraints inherent to USVs, a dynamic interaction graph for the swarm is crafted. By adopting a two-dimensional grid encoding methodology, a consistent-dimensional observation space for each agent is generated. Within the multi-agent proximal policy optimization (MAPPO) framework, which incorporates centralized training and distributed execution, the state and action spaces for both the policy and value networks are distinctly designed, and a reward function is articulated. Upon the construction of a simulated environment for USV swarm rendezvous, it is highlighted in our results that the method achieves effective convergence post-training. In scenarios encompassing varying desired formations, differing swarm sizes, and partial agent failures, swift rendezvous is consistently ensured by proposed method, underlining its flexibility and robustness.

| [1] |
王石, 张建强, 杨舒卉, 等. 国内外无人艇发展现状及典型作战应用研究[J]. 火力与指挥控制, 2019, 44(2): 11-15.
WANG S, ZHANG J Q, YANG S H, et al. Research on development status and combat applications of USVs in worldwide[J]. Fire Control & Command Control, 2019, 44(2): 11-15(in Chinese).
|
| [2] |
李伟, 李天伟. 各国无人艇技术的军事化应用与智能化升级[J]. 飞航导弹, 2020(10): 60-62.
LI W, LI T W. Military application and intelligent upgrade of unmanned boat technology in various countries[J]. Aerodynamic Missile Journal, 2020(10): 60-62(in Chinese).
|
| [3] |
王泊涵, 吴婷钰, 李文浩, 等. 基于多智能体强化学习的大规模无人机集群对抗[J]. 系统仿真学报, 2021, 33(8): 1739-1753.
WANG B H, WU T Y, LI W H, et al. Large-scale UAVs confrontation based on multi-agent reinforcement learningrevoke[J]. Journal of System Simulation, 2021, 33(8): 1739-1753(in Chinese).
|
| [4] |
Unmanned systems integrated roadmap 2017-2042[EB/OL]. (2021-08-19)[2022-01-15]. https://s3.documentcloud.org/documents/4801652/UAS-2018-Roadmap-1.pdf.
|
| [5] |
TAN K H, LEWIS M A. Virtual structures for high-precision cooperative mobile robotic control[C]//Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE Press, 2002: 132-139.
|
| [6] |
KUPPAN CHETTY R M, SINGAPERUMAL M, NAGARAJAN T. Behavior based multi robot formations with active obstacle avoidance based on switching control strategy[J]. Advanced Materials Research, 2012, 433-440: 6630-6635. doi: 10.4028/www.scientific.net/AMR.433-440.6630
|
| [7] |
HE L L, LOU X C. Study on the formation control methods for multi-agent based on geometric characteristics[J]. Advanced Materials Research, 2013, 765-767: 1928-1931. doi: 10.4028/www.scientific.net/AMR.765-767.1928
|
| [8] |
XU D D, ZHANG X N, ZHU Z Q, et al. Behavior-based formation control of swarm robots[J]. Mathematical Problems in Engineering, 2014, 2014: 1-13.
|
| [9] |
徐林, 陈云, 桂志芳, 等. 基于有限时间同步的无人艇集结控制研究[J]. 四川兵工学报, 2015, 36(10): 154-160.
XU L, CHEN Y, GUI Z F, et al. Research on rendezvous control of unmanned vessels based on finite-time synchronization[J]. Journal of Sichuan Ordnance, 2015, 36(10): 154-160(in Chinese).
|
| [10] |
陈云, 叶清, 周大伟, 等. 无人艇集结控制模型研究[J]. 海军工程大学学报, 2016, 28(6): 23-27.
CHEN Y, YE Q, ZHOU D W, et al. On rendezvous control model of unmanned vessels[J]. Journal of Naval University of Engineering, 2016, 28(6): 23-27(in Chinese).
|
| [11] |
LIU Y C, BUCKNALL R. A survey of formation control and motion planning of multiple unmanned vehicles[J]. Robotica, 2018, 36(7): 1019-1047. doi: 10.1017/S0263574718000218
|
| [12] |
XIE J J, ZHOU R, LIU Y A, et al. Reinforcement-learning-based asynchronous formation control scheme for multiple unmanned surface vehicles[J]. Applied Sciences, 2021, 11(2): 546. doi: 10.3390/app11020546
|
| [13] |
WANG S W, MA F, YAN X P, et al. Adaptive and extendable control of unmanned surface vehicle formations using distributed deep reinforcement learning[J]. Applied Ocean Research, 2021, 110: 102590. doi: 10.1016/j.apor.2021.102590
|
| [14] |
ZHAO Y J, MA Y, HU S L. USV formation and path-following control via deep reinforcement learning with random braking[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(12): 5468-5478. doi: 10.1109/TNNLS.2021.3068762
|
| [15] |
XIAO Y B, ZHANG Y Z, SUN Y X, et al. Multi-UAV formation transformation based on improved heuristically-accelerated reinforcement learning[C]//2019 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery. Piscataway: IEEE Press, 2020: 341-347.
|
| [16] |
JIN K F, WANG J, WANG H D, et al. Soft formation control for unmanned surface vehicles under environmental disturbance using multi-task reinforcement learning[J]. Ocean Engineering, 2022, 260: 112035. doi: 10.1016/j.oceaneng.2022.112035
|
| [17] |
LEE K, AHN K, PARK J. End-to-End control of USV swarm using graph centric Multi-Agent Reinforcement Learning[C]//2021 21st International Conference on Control, Automation and Systems. Piscataway: IEEE Press, 2021: 925-929.
|
| [18] |
LI R Y, WANG R, HU X H, et al. Multi-USVs coordinated detection in marine environment with deep reinforcement learning[C]//International Symposium on Benchmarking, Measuring and Optimization. Berlin: Springer, 2019: 202-214.
|
| [19] |
KRISHNAMURTHY P, KHORRAMI F, FUJIKAWA S. A modeling framework for six degree-of-freedom control of unmanned sea surface vehicles[C]//Proceedings of the 44th IEEE Conference on Decision and Control. Piscataway: IEEE Press, 2005: 2676-2681.
|
| [20] |
ŠOŠIĆ A, KHUDABUKHSH W R, ZOUBIR A M, et al. Inverse reinforcement learning in swarm systems[EB/OL]. (2016-02-17) [2022-01-11]. https://arxiv.org/abs/1602.05450.pdf.
|
| [21] |
OURY DIALLO E A, SUGAWARA T. Multi-agent pattern formation: A distributed model-free deep reinforcement learning approach[C]//2020 International Joint Conference on Neural Networks. Piscataway: IEEE Press, 2020: 1-8.
|
| [22] |
LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[EB/OL]. (2017-06-07) [2022-01-12]. https://arxiv.org/abs/1706.02275.pdf.
|
| [23] |
SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning[EB/OL]. (2017-06-) [2022-01-12]. https://arxiv.or16g/abs/1706.05296.pdf.
|
| [24] |
HÜTTENRAUCH M, SOSIC A, NEUMANN G. Deep reinforcement learning for swarm systems[EB/OL]. (2018-07-17)[2022-01-12]. https://arxiv.org/abs/1807.06613.
|
| [25] |
HÜTTENRAUCH M, ŠOŠIĆ A, NEUMANN G. Local communication protocols for learning complex swarm behaviors with deep reinforcement learning[C]//International Conference on Swarm Intelligence. Berlin: Springer, 2018: 71-83.
|
| [26] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-07-20)[2022-01-12]. https://arxiv.org/abs/1707.06347.pdf.
|
| [27] |
SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization[EB/OL]. (2015-02-19)[2022-01-12]. https://arxiv.org/abs/1502.05477.pdf.
|
| [28] |
YU C, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative, multi-agent games[EB/OL]. (2021-03-02) [2022-01-12]. https://arxiv.org/abs/2103.01955.pdf.
|
Figures(14) / Tables(2)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: