| Citation: | LI Y R,YAO T,ZHANG L L,et al. Image-text matching algorithm based on multi-level semantic alignment[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):551-558 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0385

|
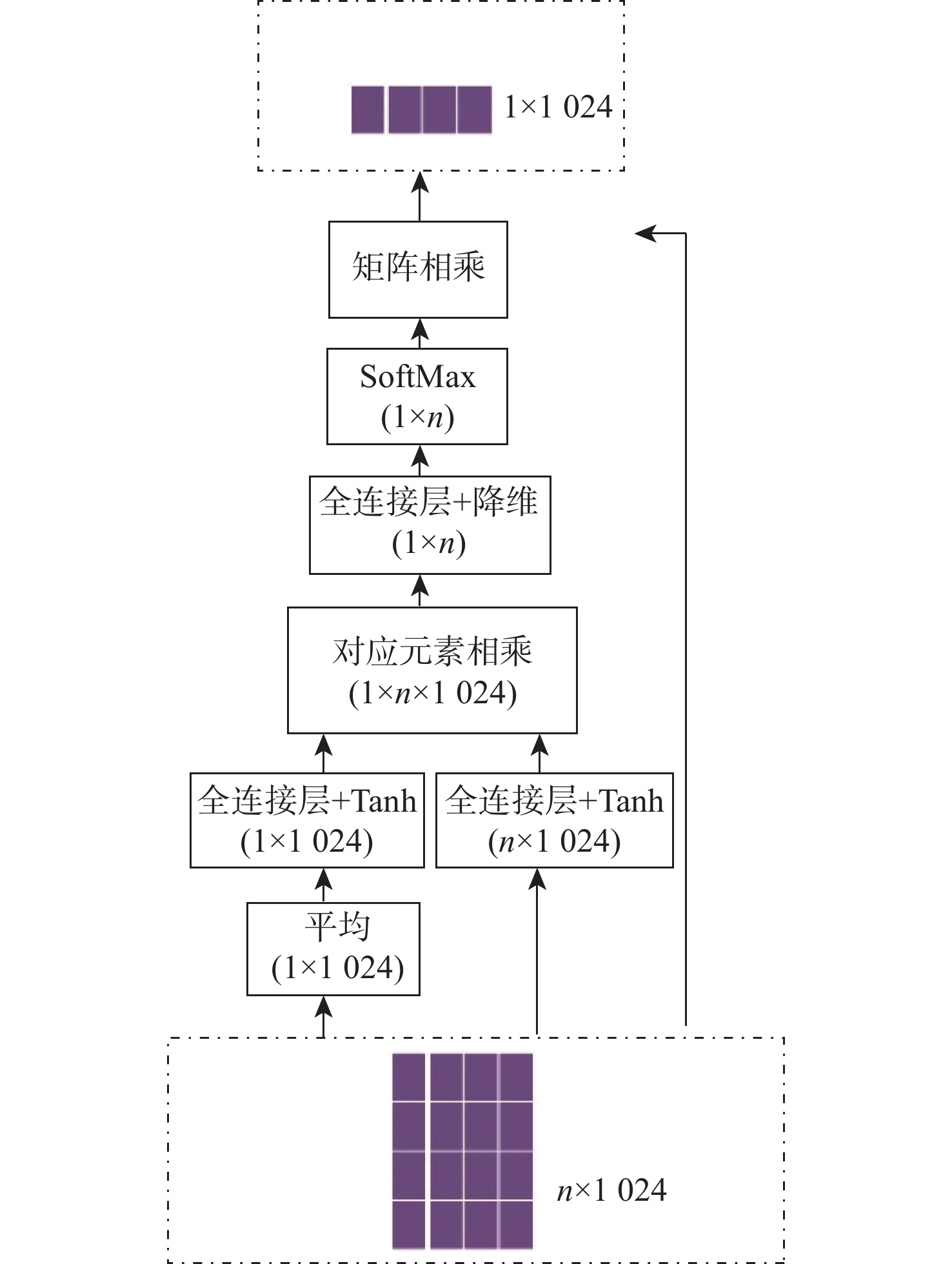
The regional features in the image tend to pay more attention to the regional features in the image, and the environmental information is often ignored. How to effectively combine local features and global features has not been fully studied. A image-text maxching algorthm based on multi-level semantic alignment is proposed as a solution to this problem and to improve the association between global concepts and local concepts to provide more accurate visual characteristics. In order to obtain different visual relationship levels and provide more information for the joint visual features, this paper first extracts the local image features to obtain the fine-grained information in the image. It then extracts the global image features to introduce the environmental information into the network learning. To provide a more precise similarity representation, the picture characteristics are next integrated, and finally the combined visual and text features are aligned. Through a lot of experiments and analysis, the effectiveness of the proposed algorithm on two public datasets is proven.

| [1] |
ZHANG C Y, SONG J Y, ZHU X F, et al. HCMSL: Hybrid cross-modal similarity learning for cross-modal retrieval[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2021, 17(1s): 1-22.
|
| [2] |
CHUN S, OH S J, DE REZENDE R S, et al. Probabilistic embeddings for cross-modal retrieval[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 8411-8420.
|
| [3] |
YU T, YANG Y, LI Y, et al. Heterogeneous attention network for effective and efficient cross-modal retrieval[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 1146-1156.
|
| [4] |
DONG J F, LONG Z Z, MAO X F, et al. Multi-level alignment network for domain adaptive cross-modal retrieval[J]. Neurocomputing, 2021, 440: 207-219. doi: 10.1016/j.neucom.2021.01.114
|
| [5] |
WANG X, HU P, ZHEN L L, et al. DRSL: Deep relational similarity learning for cross-modal retrieval[J]. Information Sciences, 2021, 546: 298-311. doi: 10.1016/j.ins.2020.08.009
|
| [6] |
ZHU L, ZHENG C Q, LU X, et al. Efficient multi-modal hashing with online query adaption for multimedia retrieval[J]. ACM Transactions on Information Systems, 2021, 40(2): 1-36.
|
| [7] |
WU J L, XIE X X, NIE L Q, et al. Reconstruction regularized low-rank subspace learning for cross-modal retrieval[J]. Pattern Recognition, 2021, 113: 107813. doi: 10.1016/j.patcog.2020.107813
|
| [8] |
JIAO F K, GUO Y Y, NIU Y L, et al. REPT: Bridging language models and machine reading comprehension via retrieval-based pre-training[C]//Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: Association for Computational Linguistics, 2021: 150-163.
|
| [9] |
LU X, ZHU L, LIU L, et al. Graph convolutional multi-modal hashing for flexible multimedia retrieval[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 1414-1422.
|
| [10] |
HU Y P, LIU M, SU X B, et al. Video moment localization via deep cross-modal hashing[J]. IEEE Transactions on Image Processing, 2021, 30: 4667-4677. doi: 10.1109/TIP.2021.3073867
|
| [11] |
LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 212-228.
|
| [12] |
WANG Y X, CHEN Z D, LUO X, et al. Fast cross-modal hashing with global and local similarity embedding[J]. IEEE Transactions on Cybernetics, 2022, 52(10): 10064-10077. doi: 10.1109/TCYB.2021.3059886
|
| [13] |
DIAO H W, ZHANG Y, MA L, et al. Similarity reasoning and filtration for image-text matching[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Washington, DC: AAAI, 2021, 35(2): 1218-1226.
|
| [14] |
ZOU X T, WANG X Z, BAKKER E M, et al. Multi-label semantics preserving based deep cross-modal hashing[J]. Signal Processing:Image Communication, 2021, 93: 116131. doi: 10.1016/j.image.2020.116131
|
| [15] |
WANG S J, WANG R P, YAO Z W, et al. Cross-modal scene graph matching for relationship-aware image-text retrieval[C]//2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2020: 1497-1506.
|
| [16] |
ZHAN Y W, WANG Y X, SUN Y, et al. Discrete online cross-modal hashing[J]. Pattern Recognition, 2022, 122: 108262. doi: 10.1016/j.patcog.2021.108262
|
| [17] |
ZHU L P, TIAN G Y, WANG B Y, et al. Multi-attention based semantic deep hashing for cross-modal retrieval[J]. Applied Intelligence, 2021, 51(8): 5927-5939. doi: 10.1007/s10489-020-02137-w
|
| [18] |
WEN H K, SONG X M, YANG X, et al. Comprehensive linguistic-visual composition network for image retrieval[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 1369-1378.
|
| [19] |
FAGHRI F, FLEET D J, KIROS J R, et al. VSE++: Improving visual-semantic embeddings with hard negatives[EB/OL]. (2017-07-08)[2022-01-25].https://arxiv.org/abs/1707.05612v4.
|
| [20] |
GU J X, CAI J F, JOTY S, et al. Look, imagine and match: improving textual-visual cross-modal retrieval with generative models[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7181-7189.
|
| [21] |
WANG H R, ZHANG Y, JI Z, et al. Consensus-aware visual-semantic embedding for image-text matching[C]//European Conference on Computer Vision. Berlin: Springer, 2020: 18-34.
|
| [22] |
WANG L W, LI Y, LAZEBNIK S. Learning deep structure-preserving image-text embeddings[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 5005-5013.
|
| [23] |
ANDREW G, ARORA R, BILMES J, et al. Deep canonical correlation analysis[J]. Journal of Machine Learning Research, 2013, 28: 1247-1255.
|
| [24] |
CHEN H, DING G G, LIU X D, et al. IMRAM: Iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 12652-12660.
|
| [25] |
YAO T, LI Y R, GUAN W L, et al. Discrete robust matrix factorization hashing for large-scale cross-media retrieval[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(2): 1391-1401.
|
| [26] |
YAO T, KONG X W, FU H Y, et al. Discrete semantic alignment hashing for cross-media retrieval[J]. IEEE Transactions on Cybernetics, 2020, 50(12): 4896-4907. doi: 10.1109/TCYB.2019.2912644
|
| [27] |
李志欣, 凌锋, 张灿龙, 等. 融合两级相似度的跨媒体图像文本检索[J]. 电子学报, 2021, 49(2): 268-274.
LI Z X, LING F, ZHANG C L, et al. Cross-media image-text retrieval with two level similarity[J]. Acta Electronica Sinica, 2021, 49(2): 268-274 (in Chinese).
|

Figures(2) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: