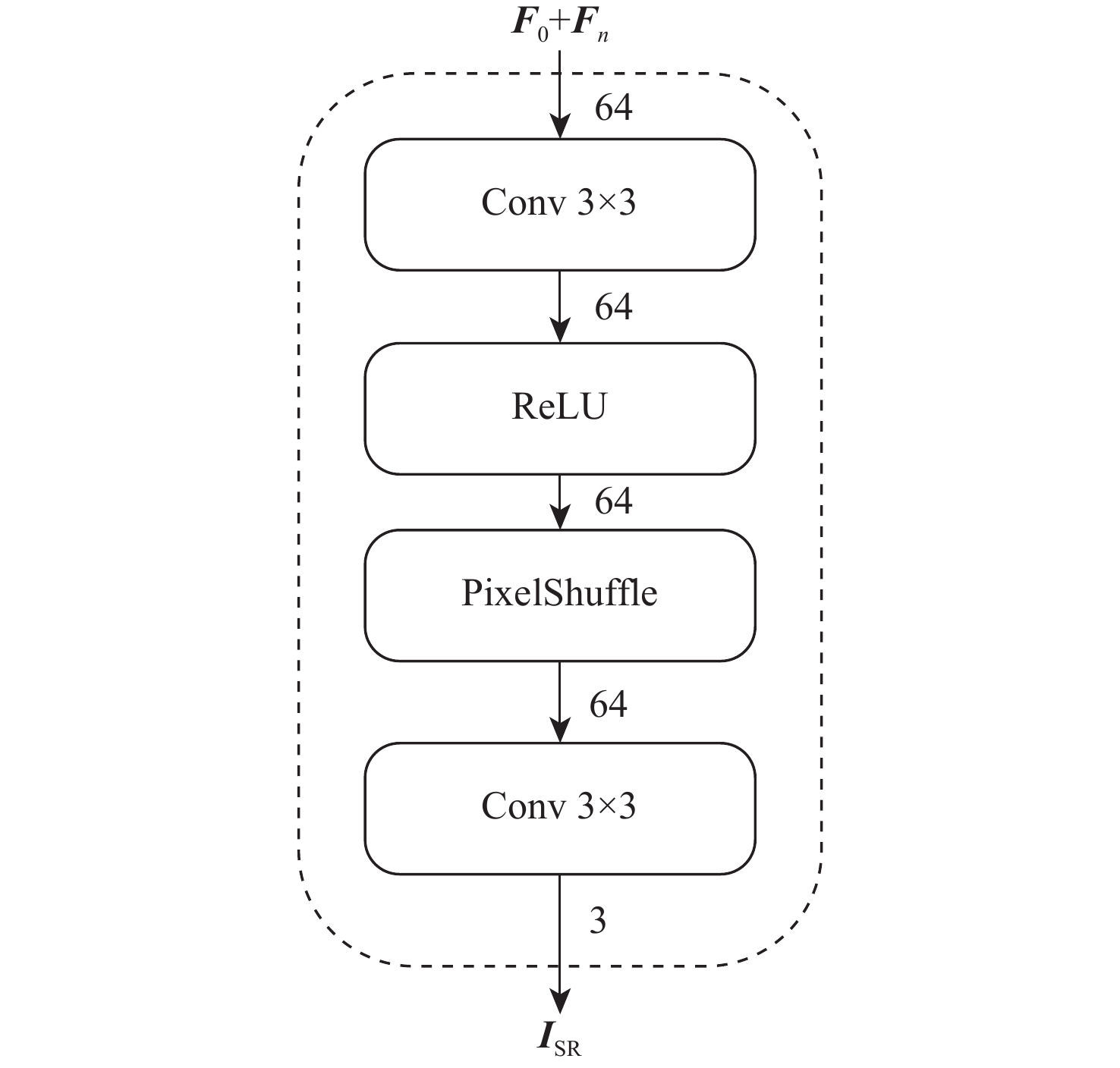
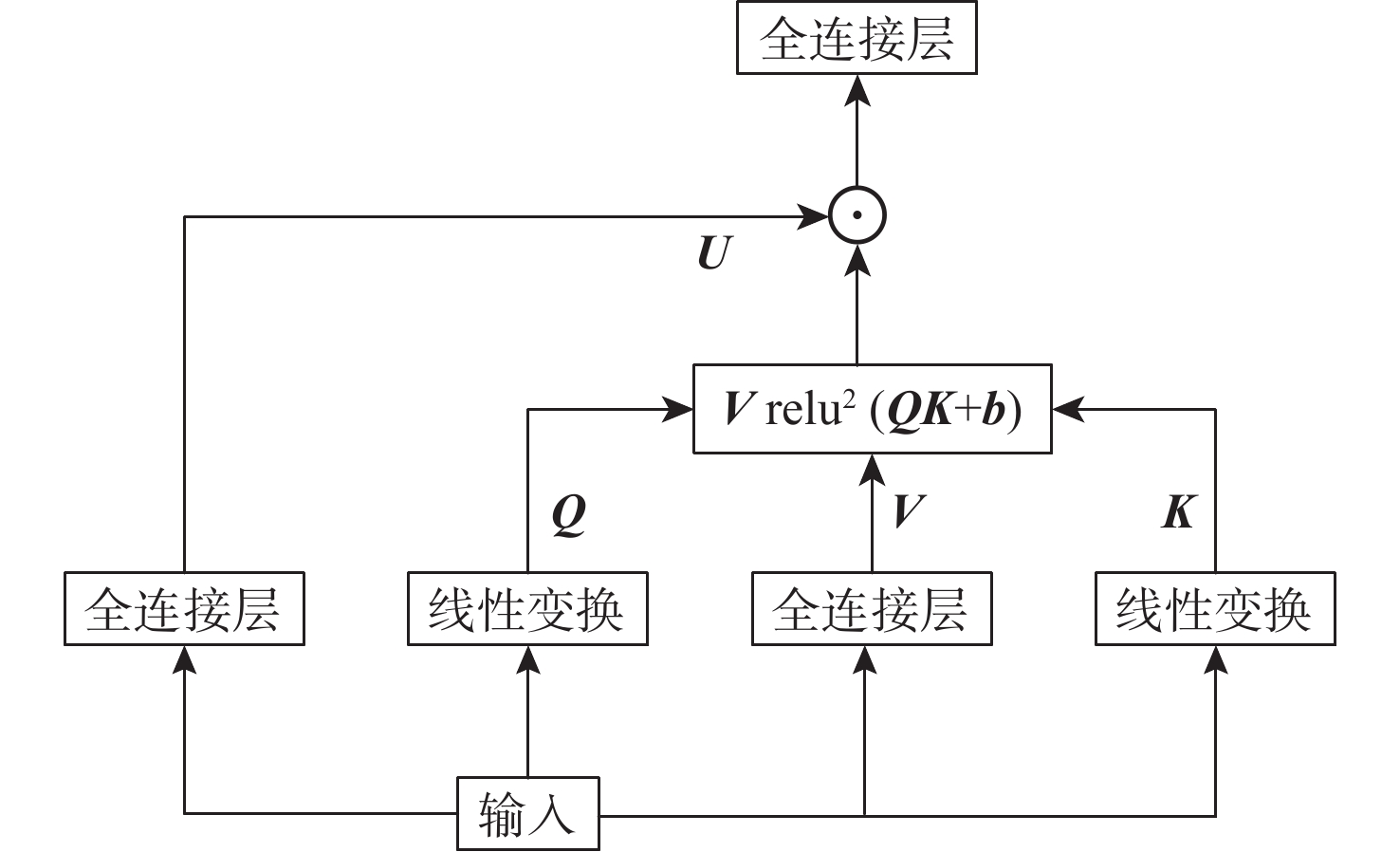
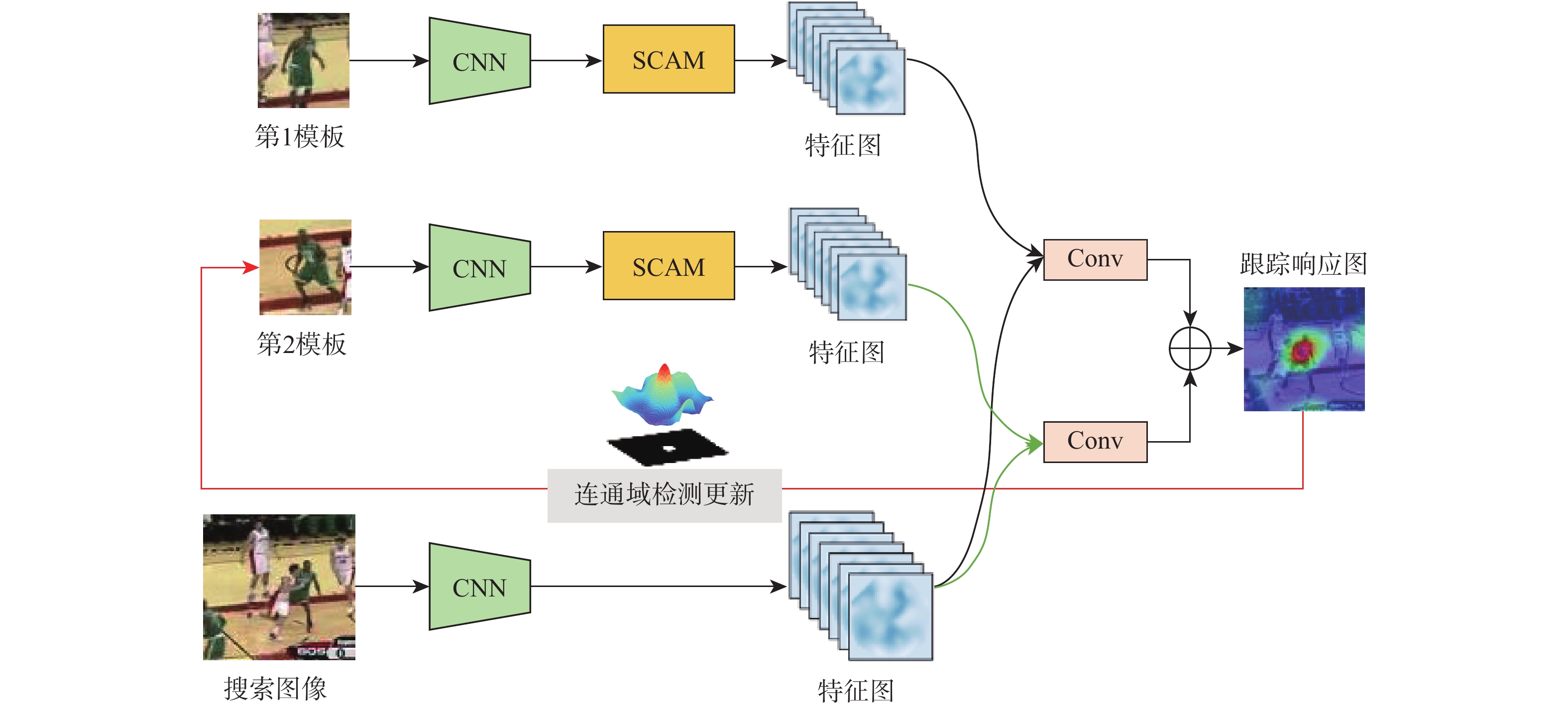
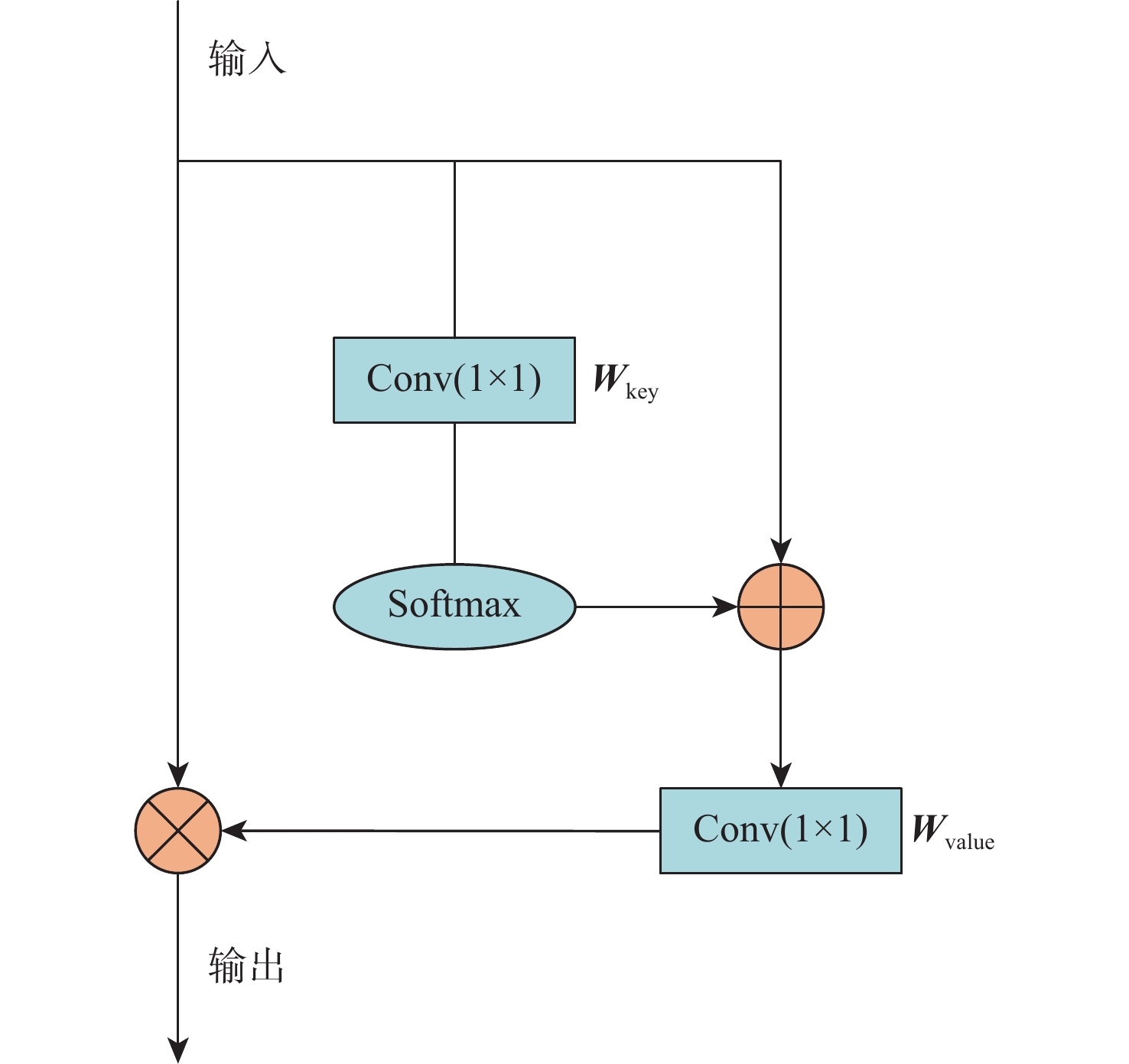
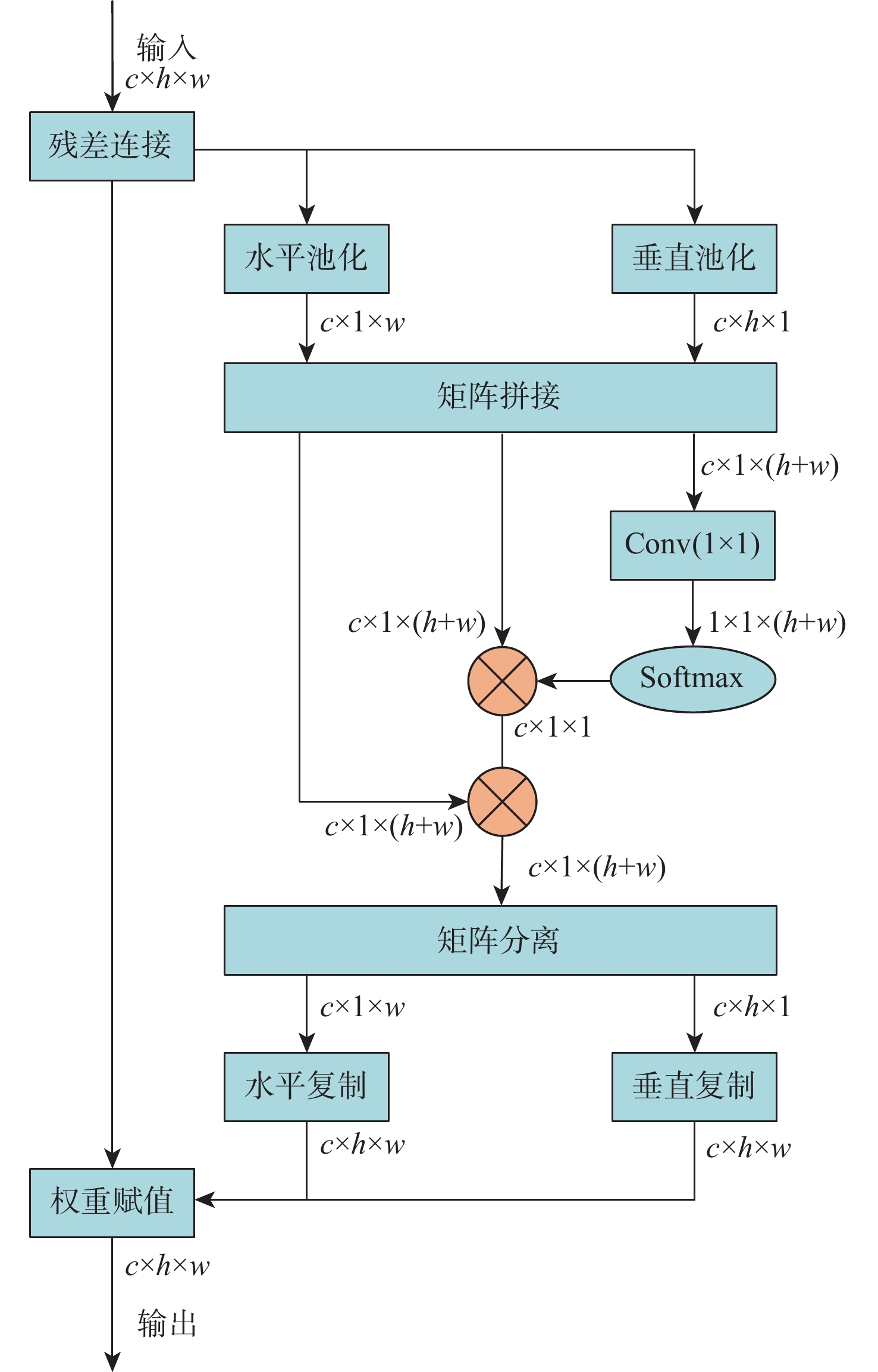
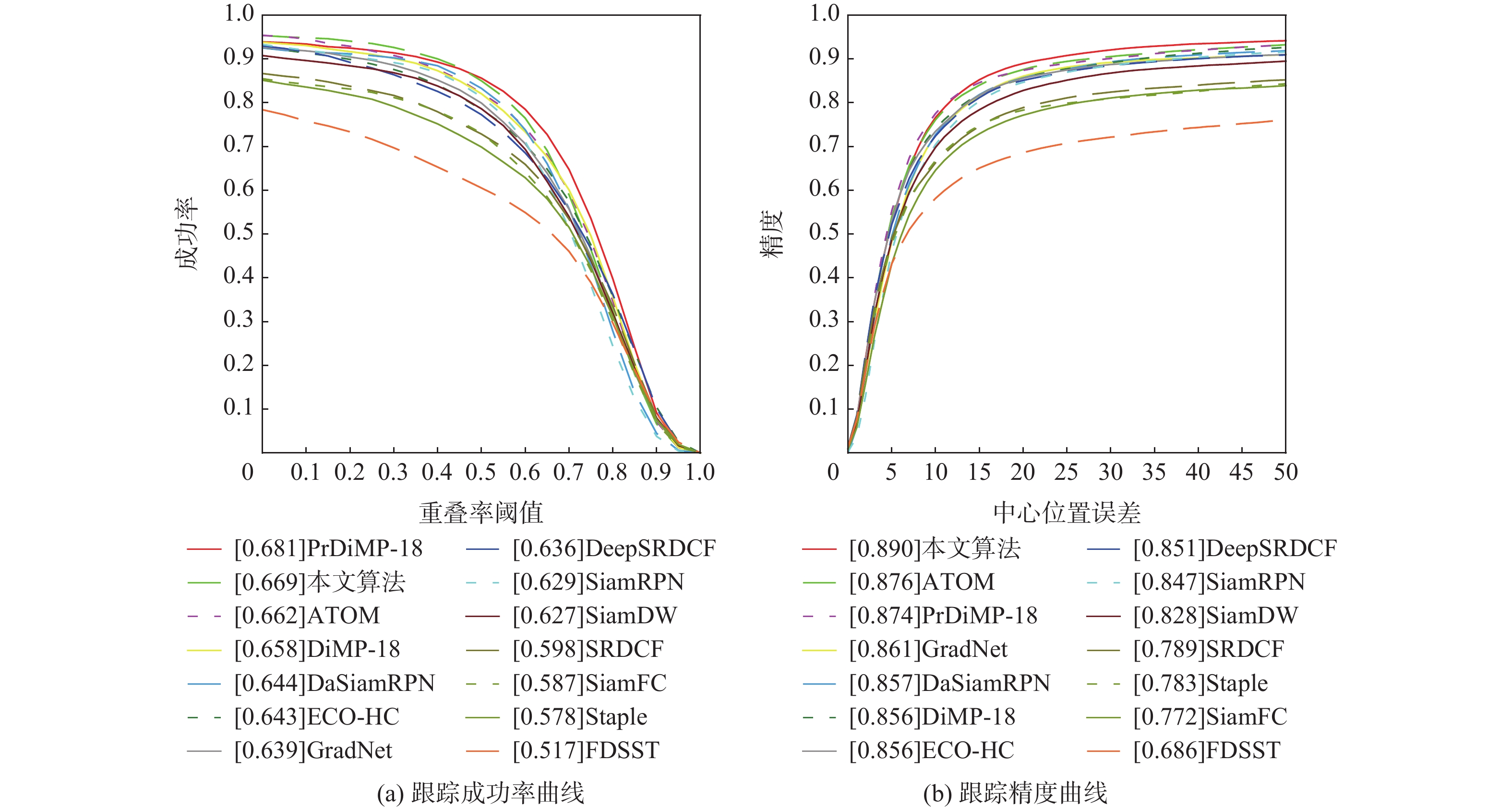
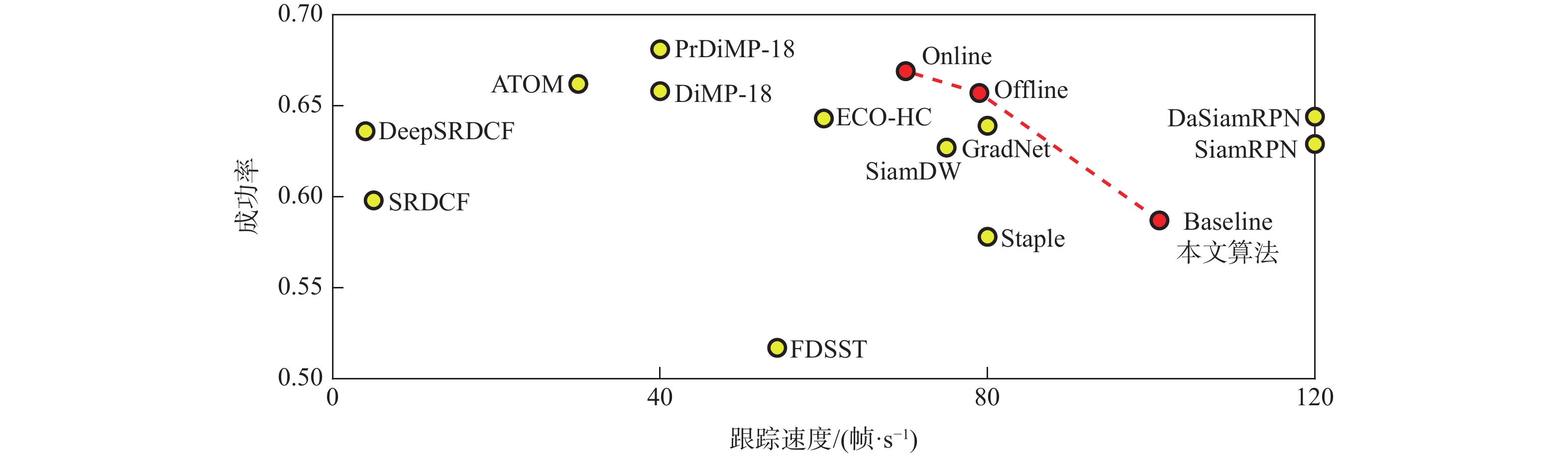
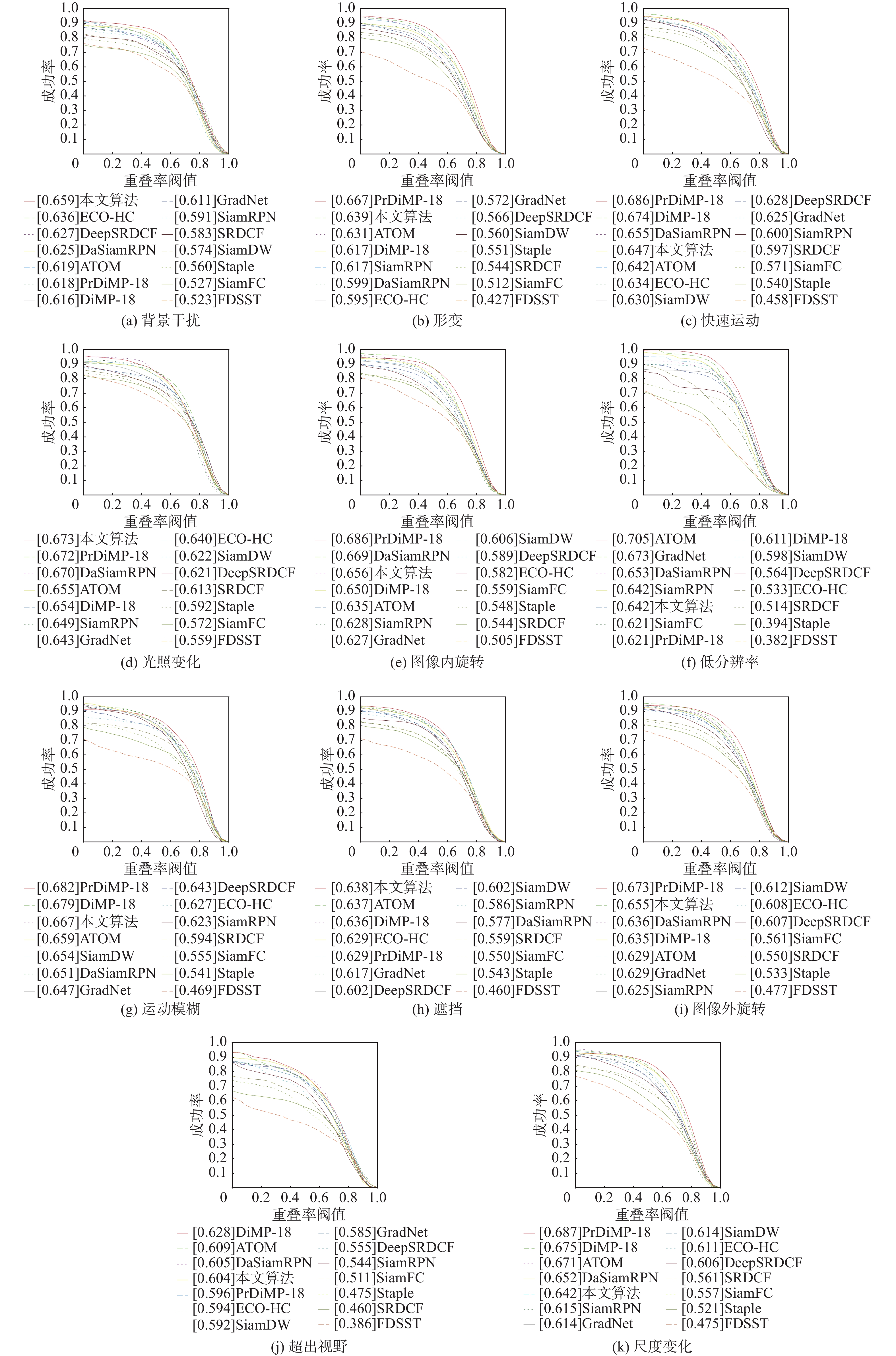
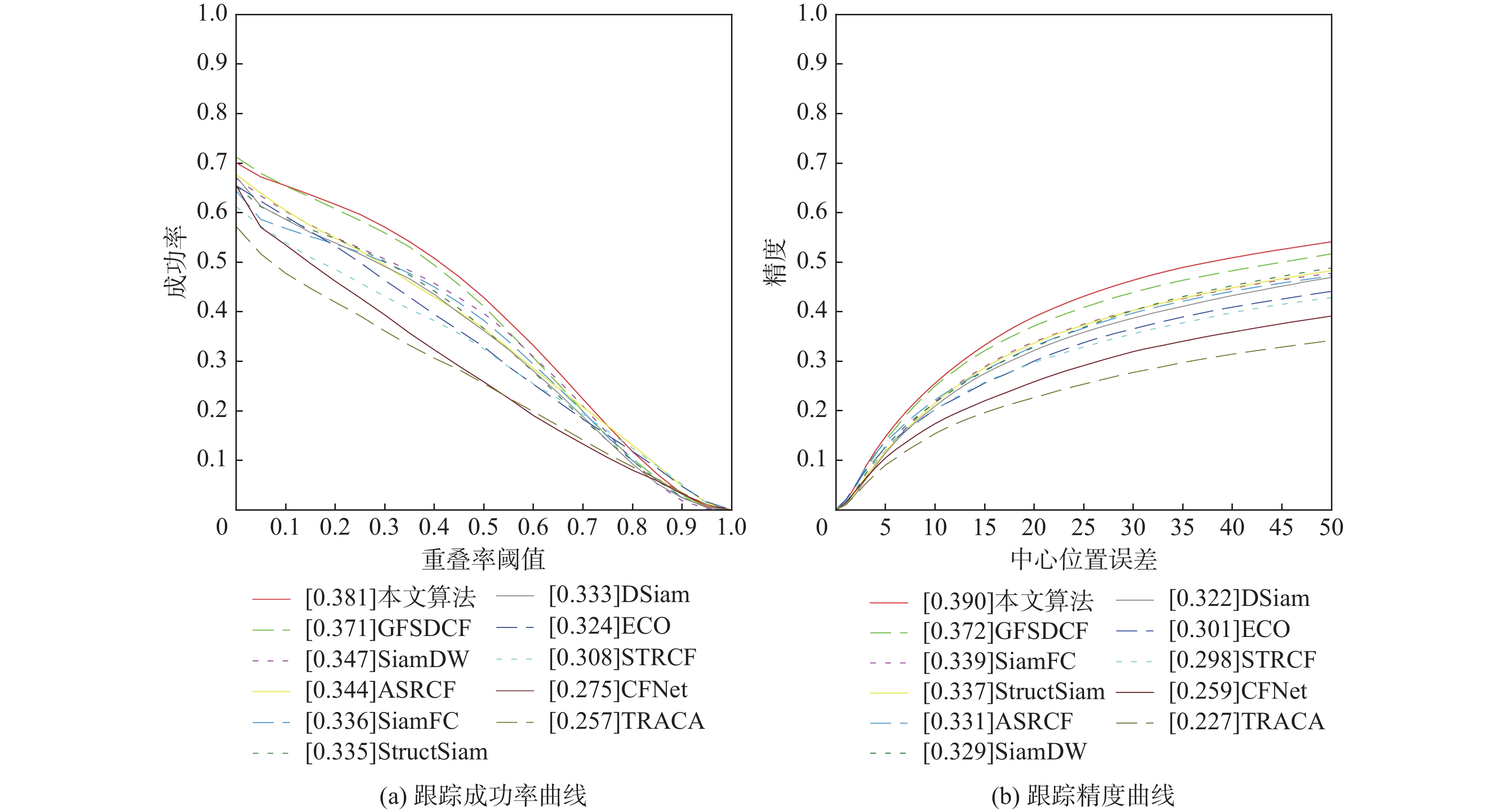
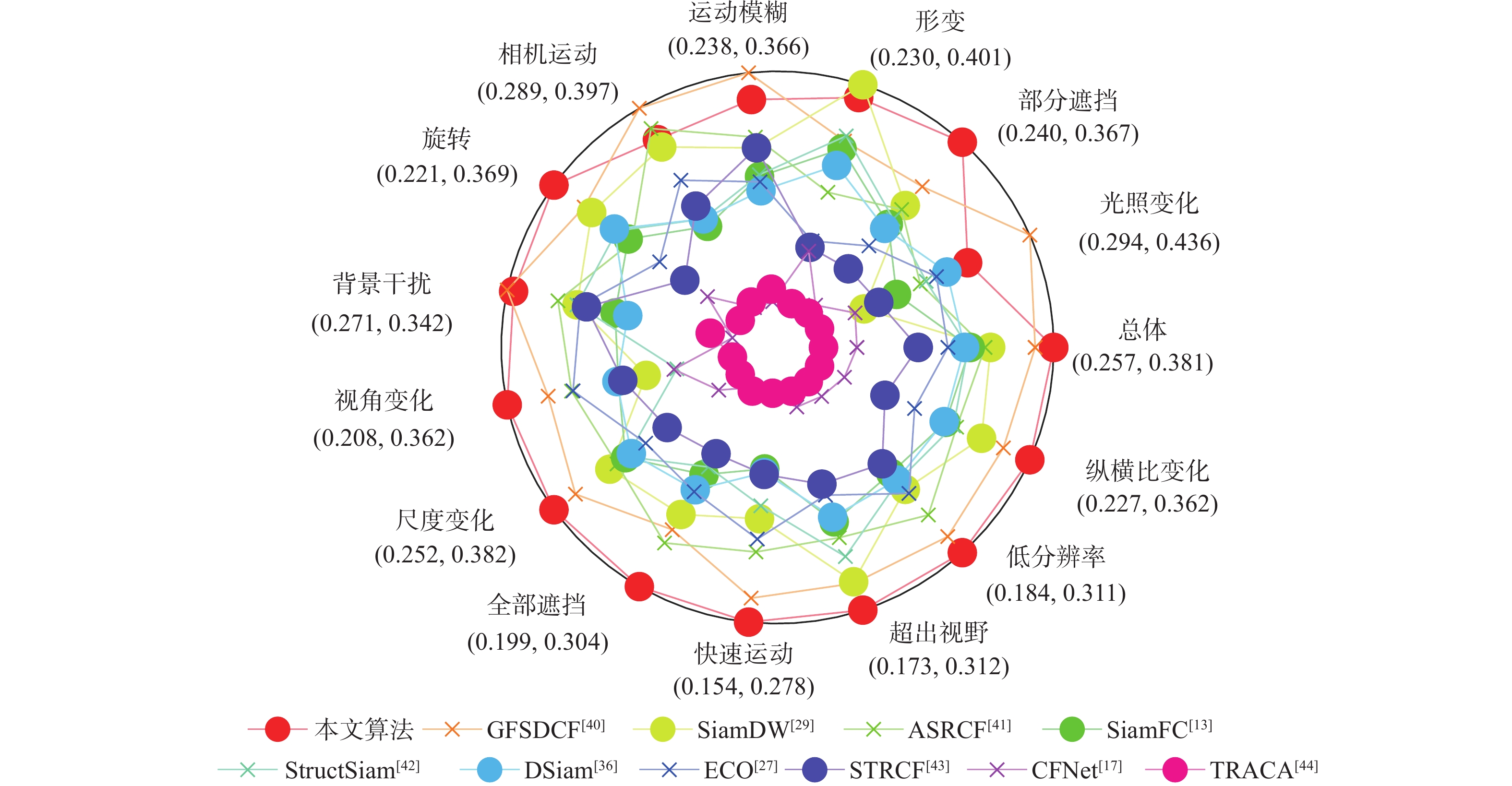
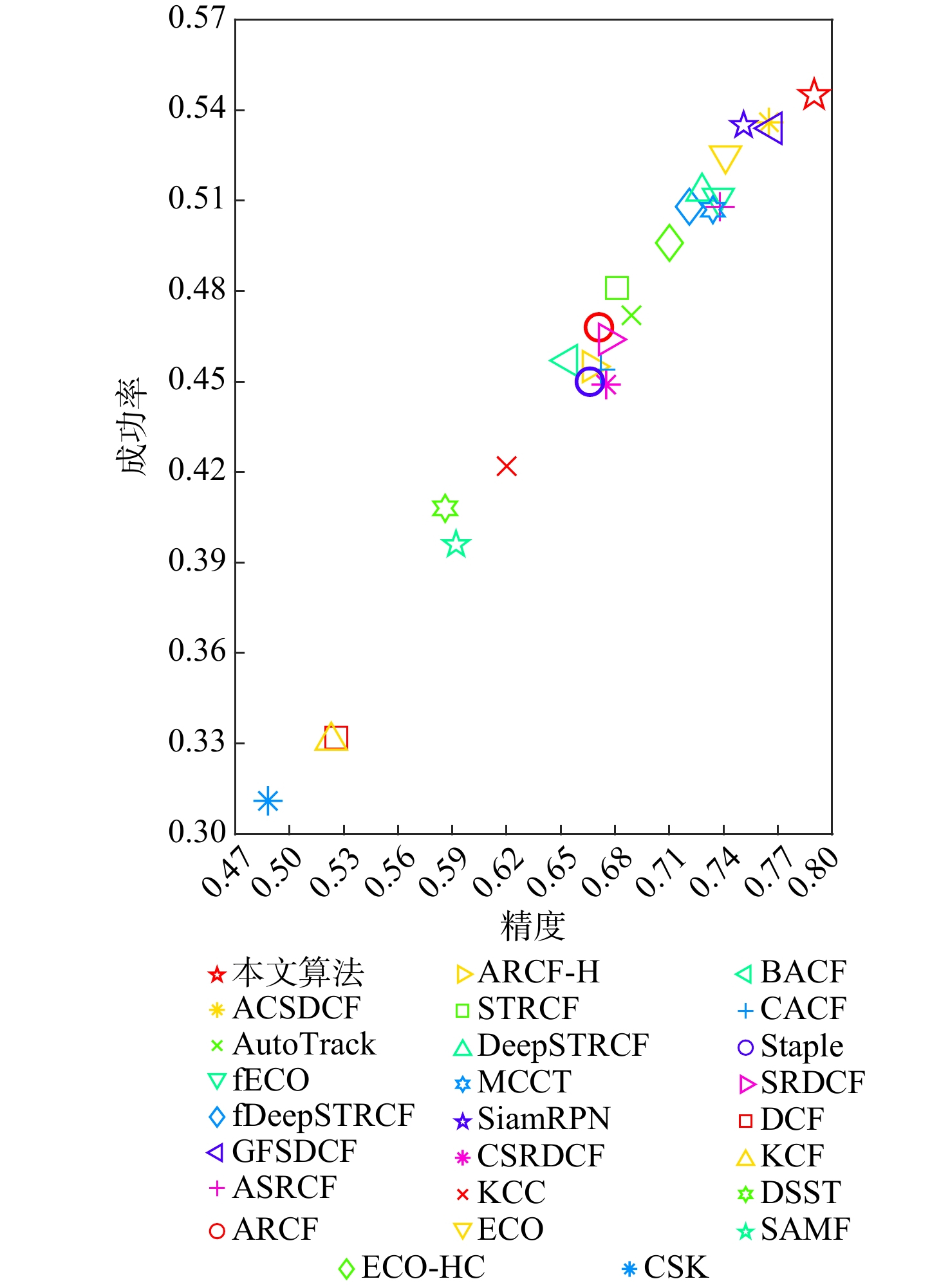
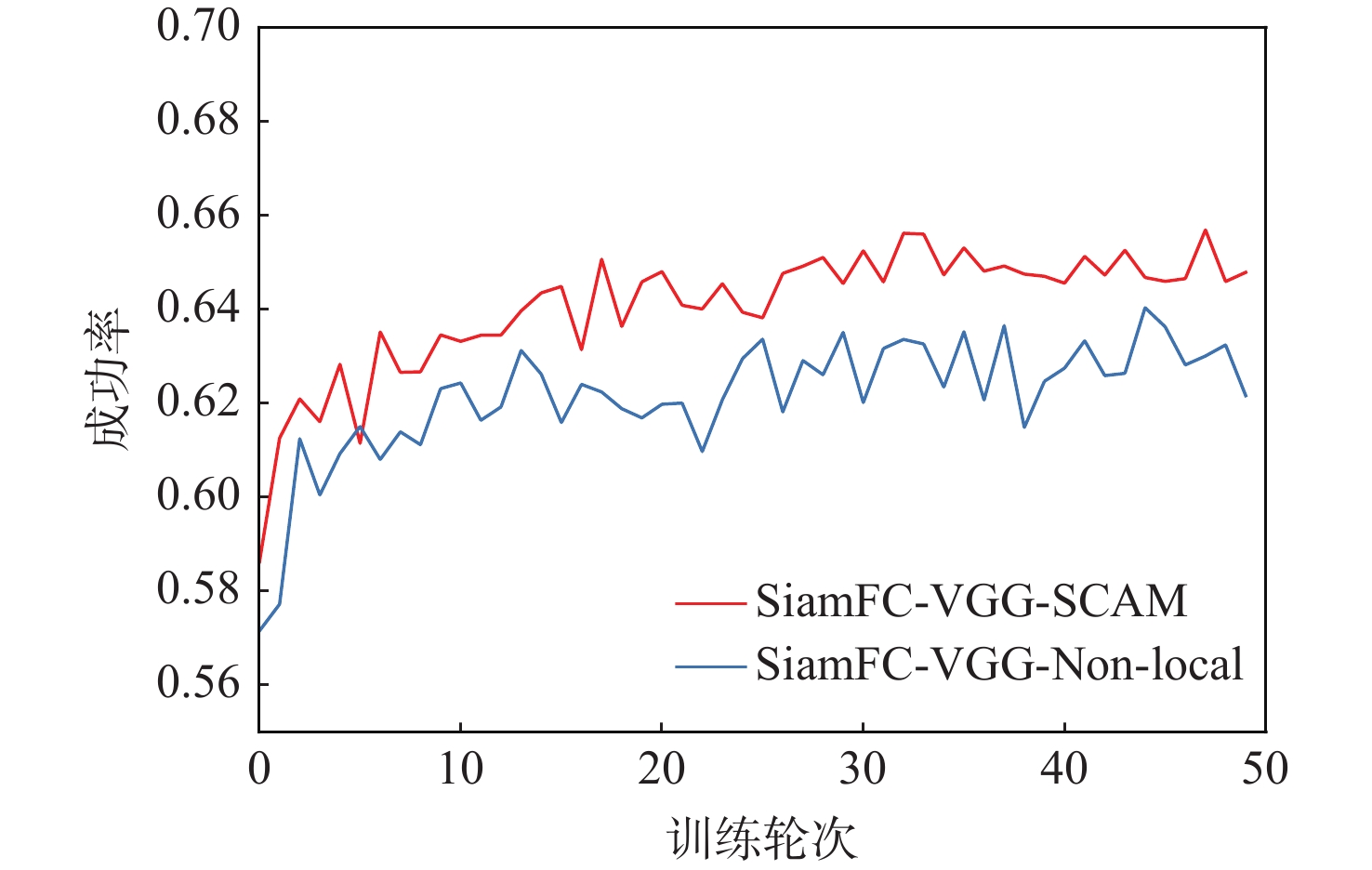
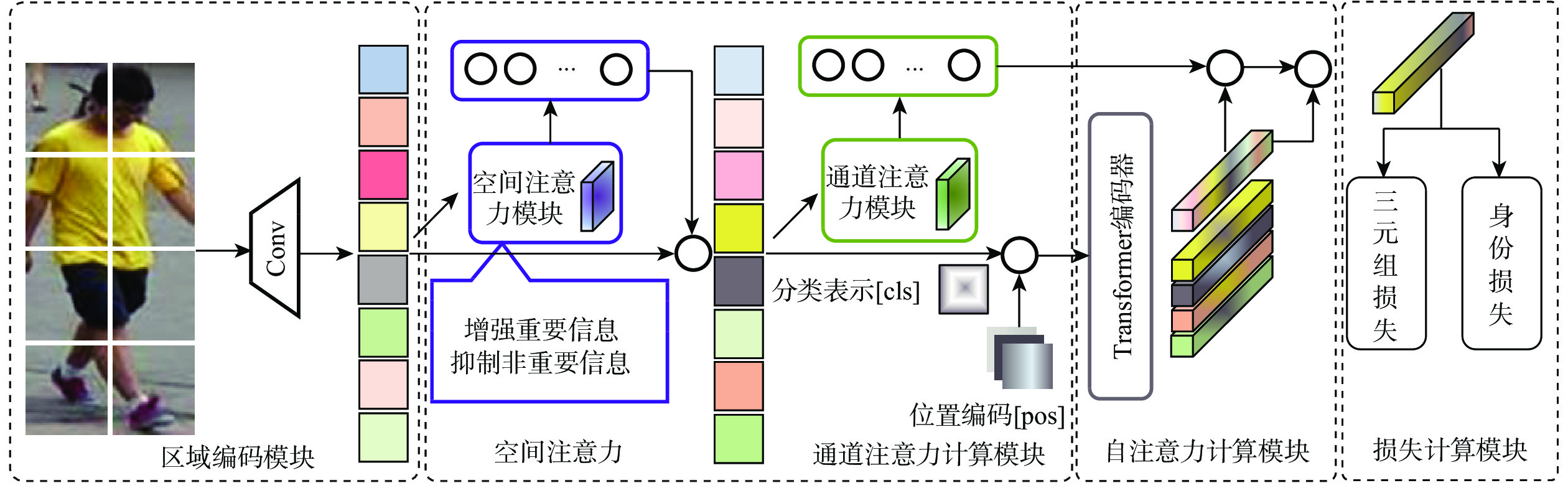
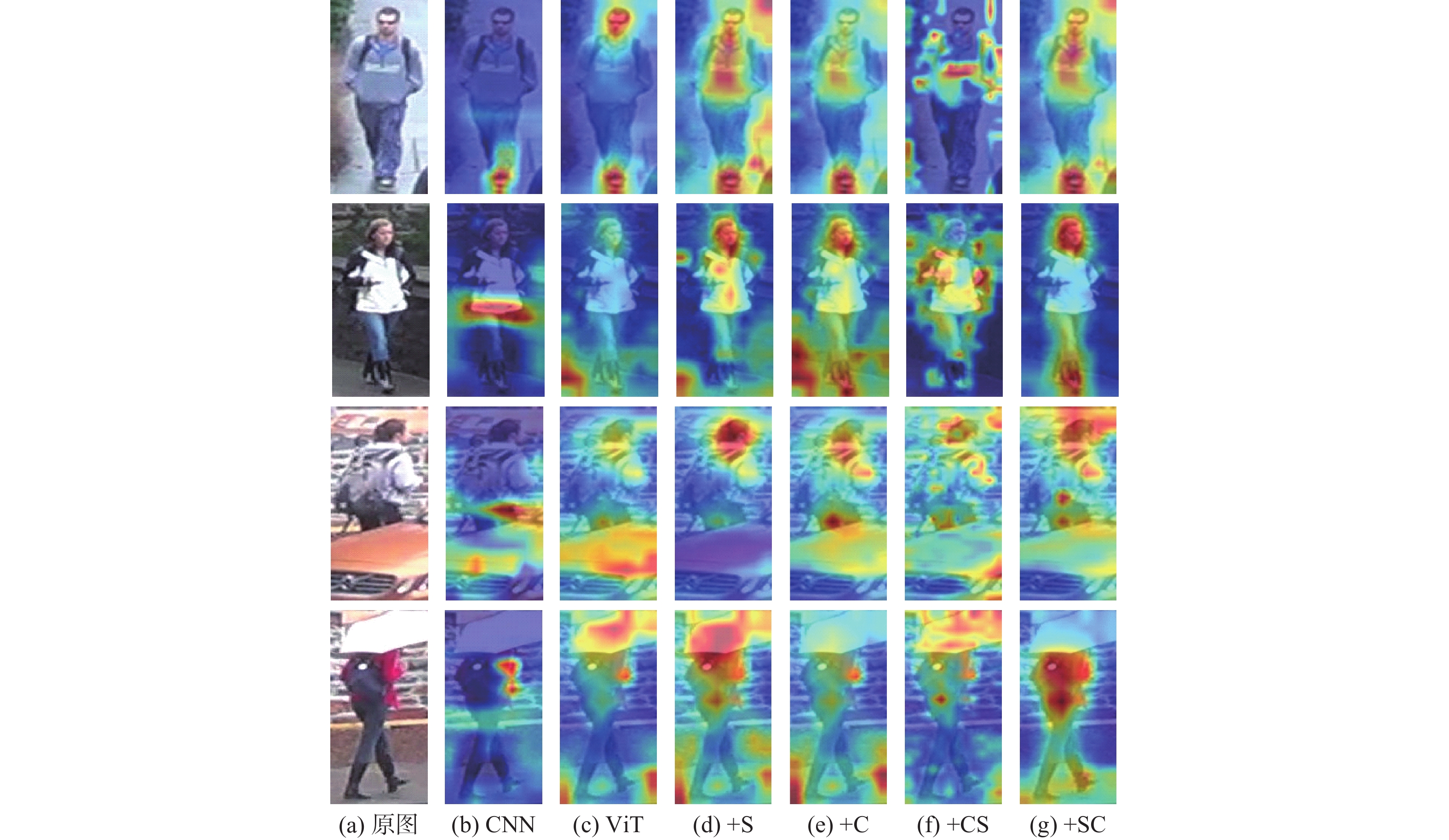
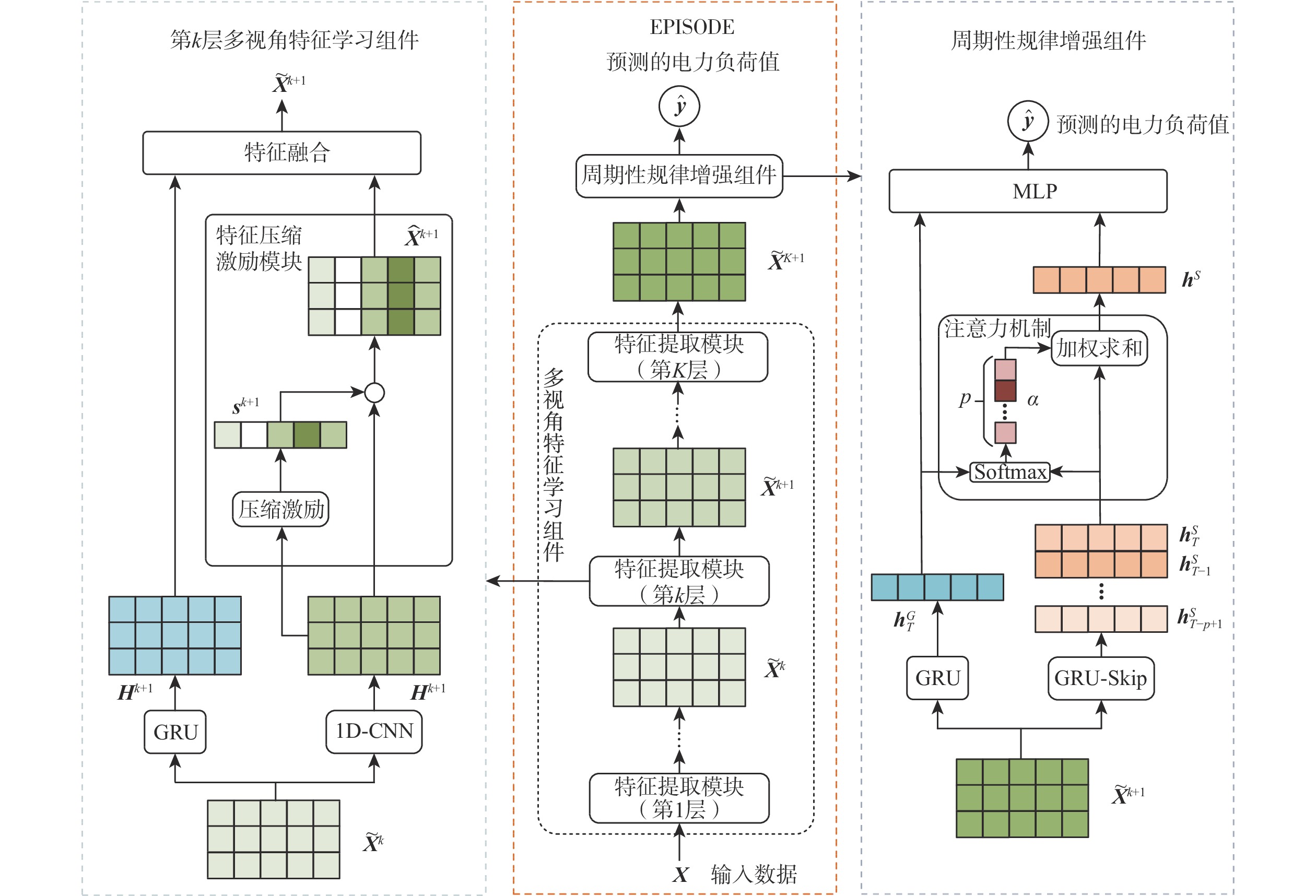
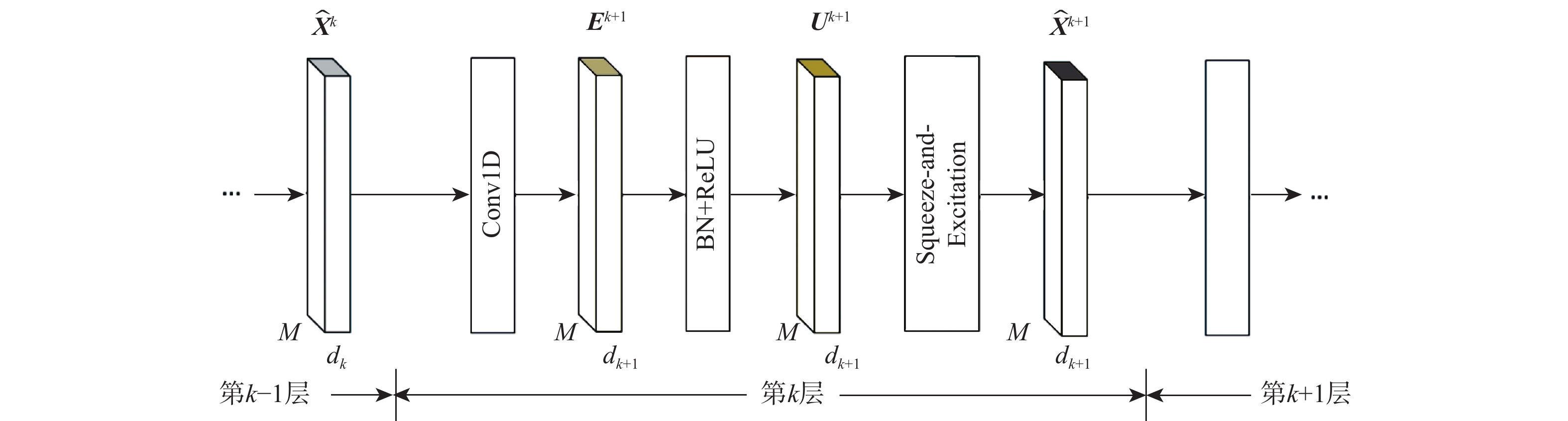
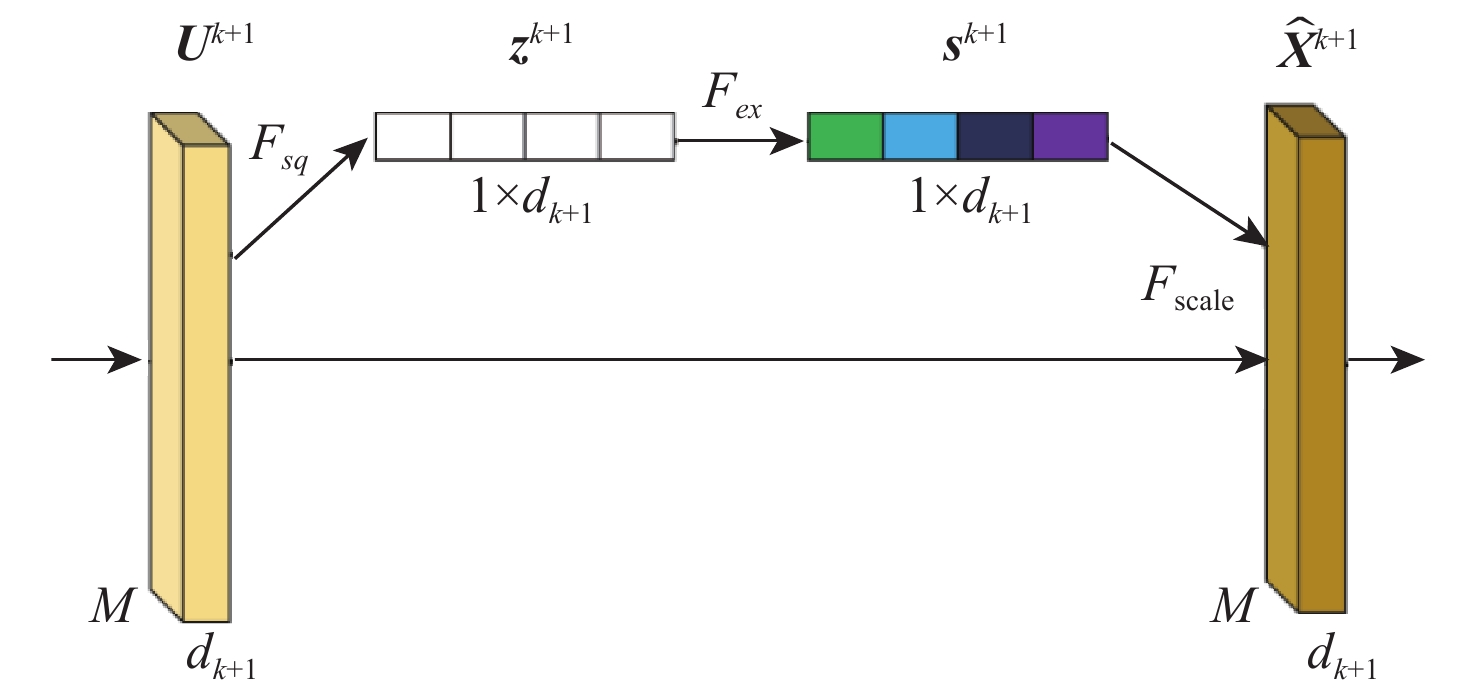
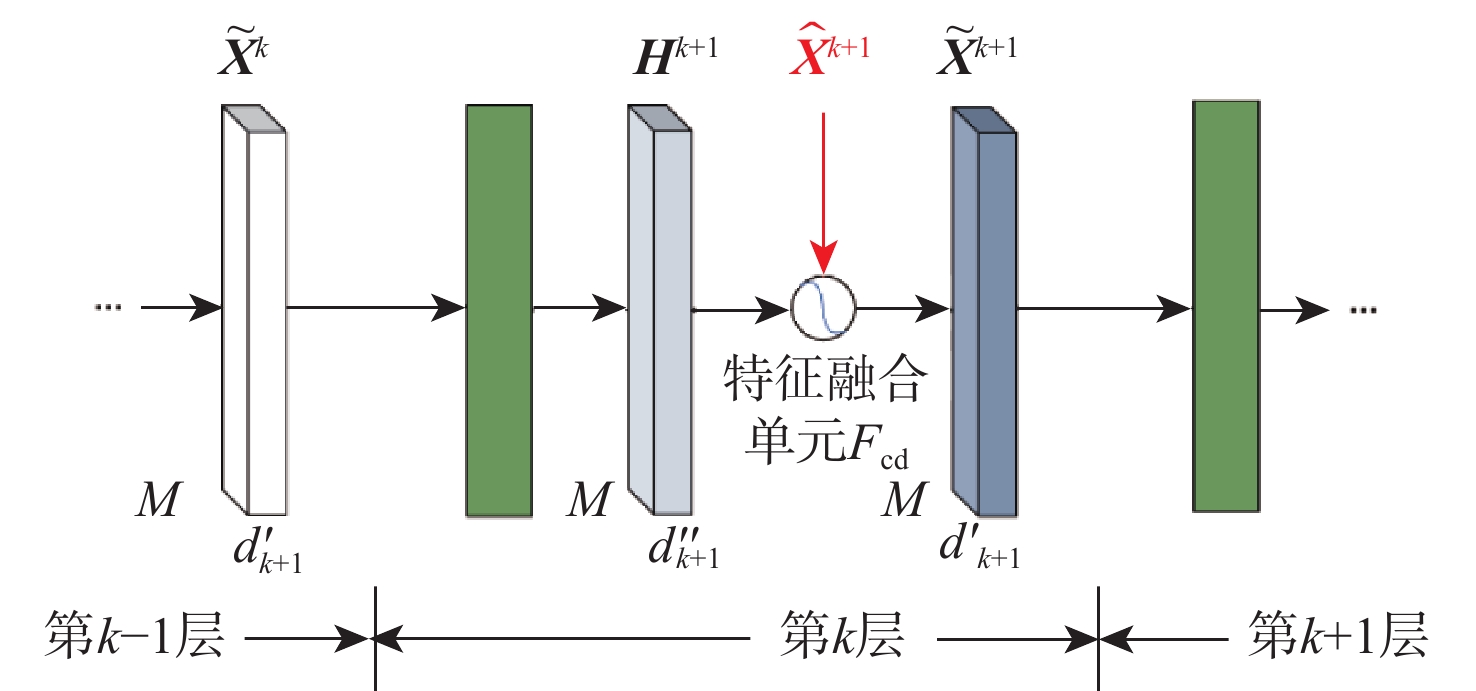
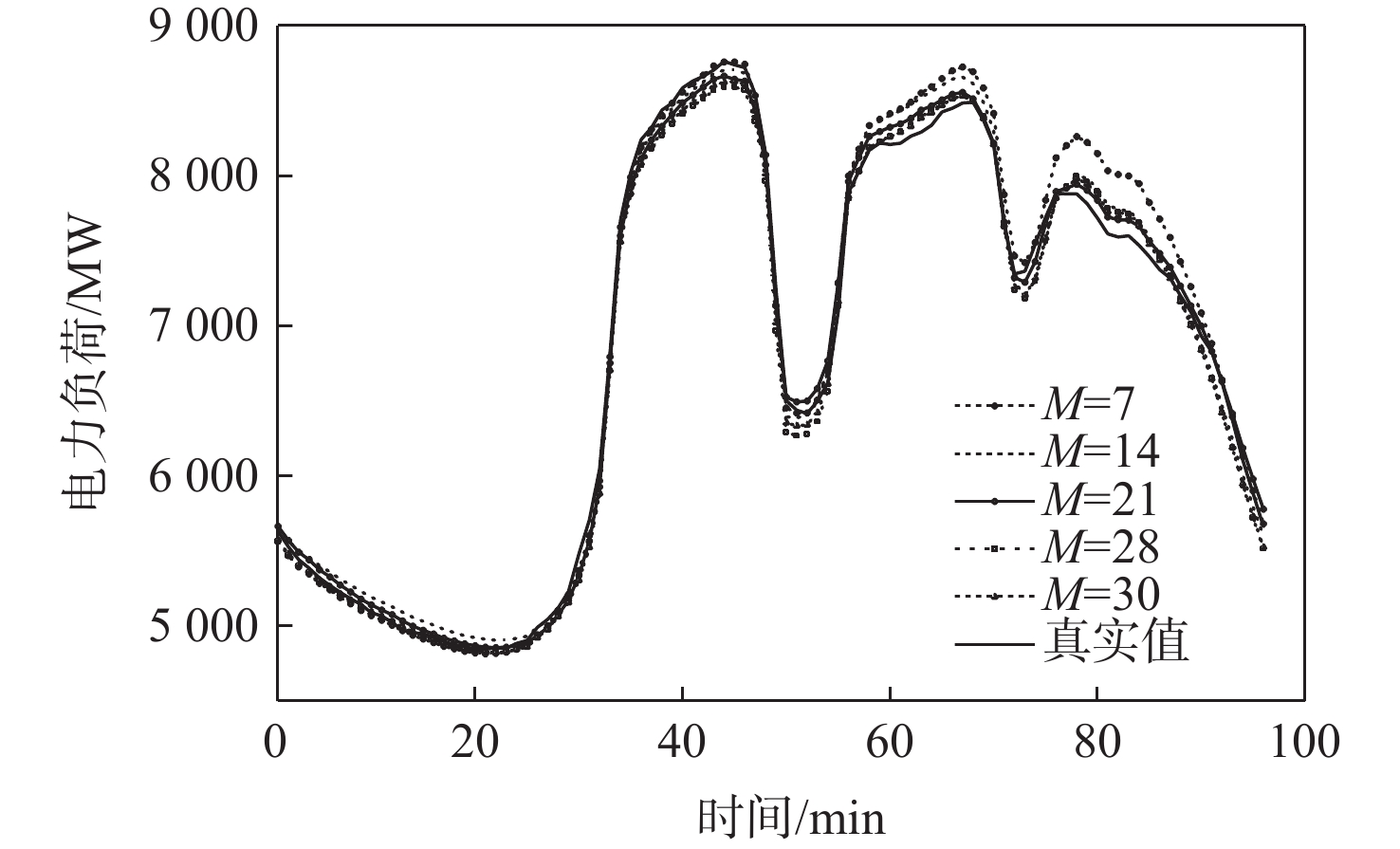
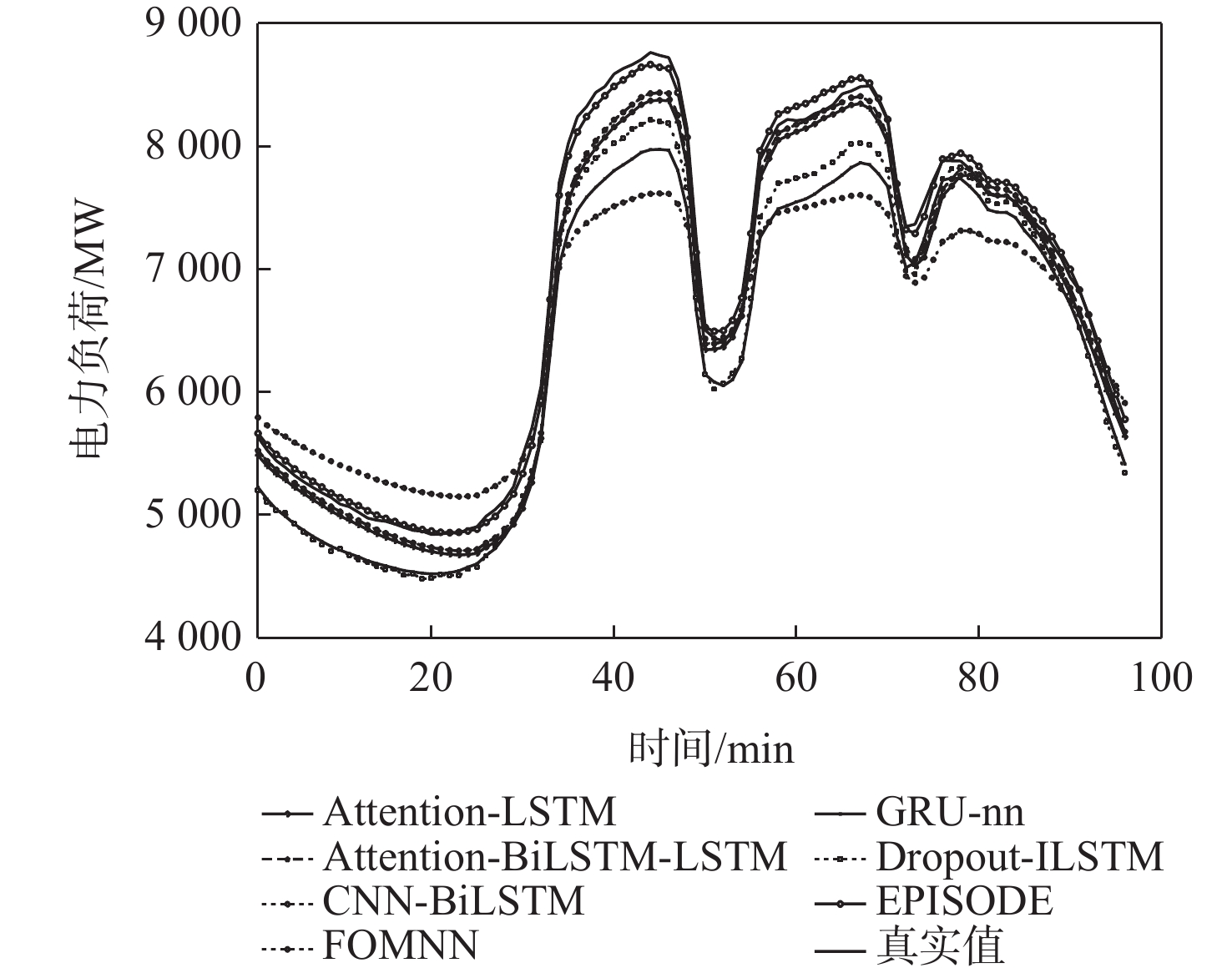
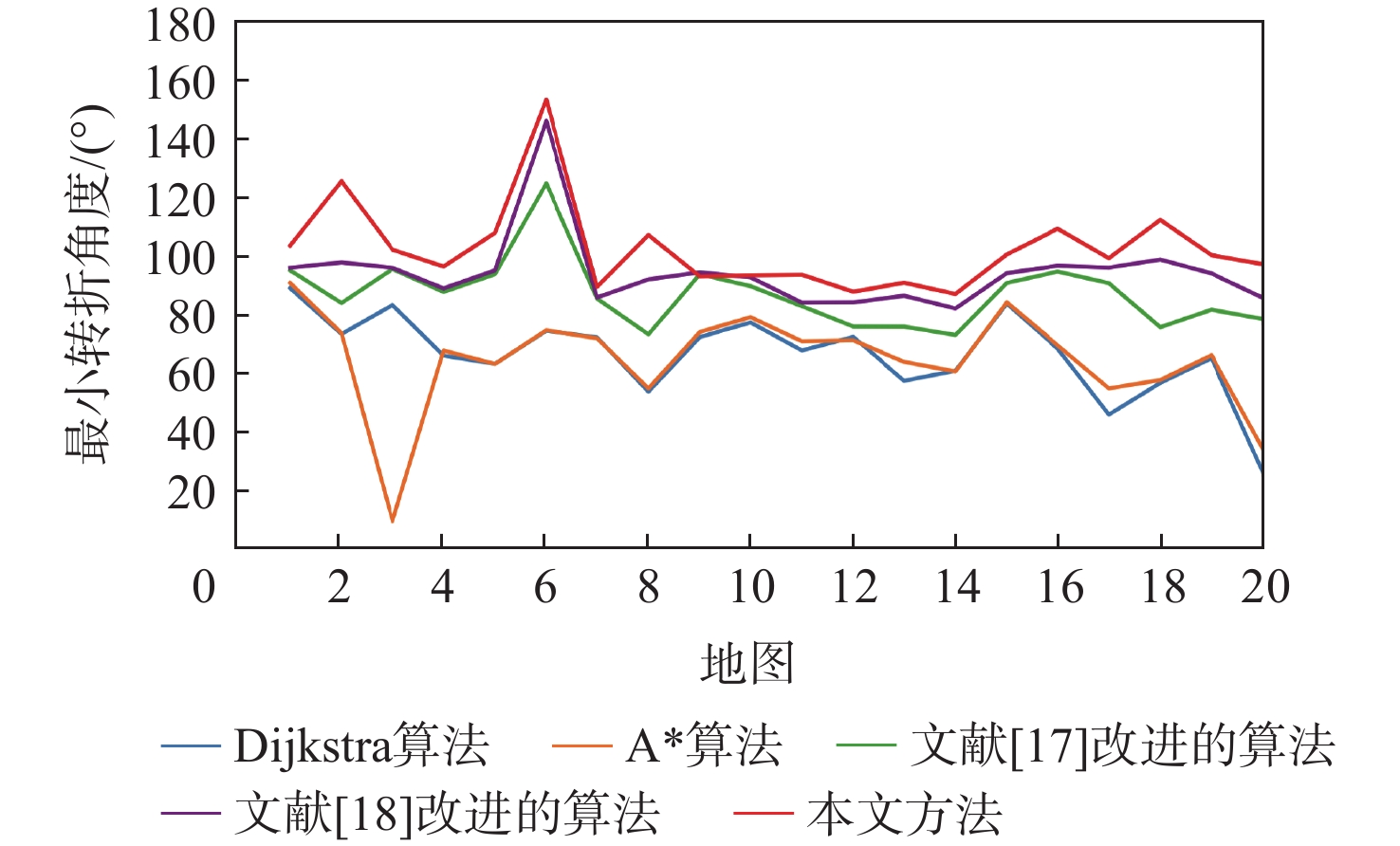
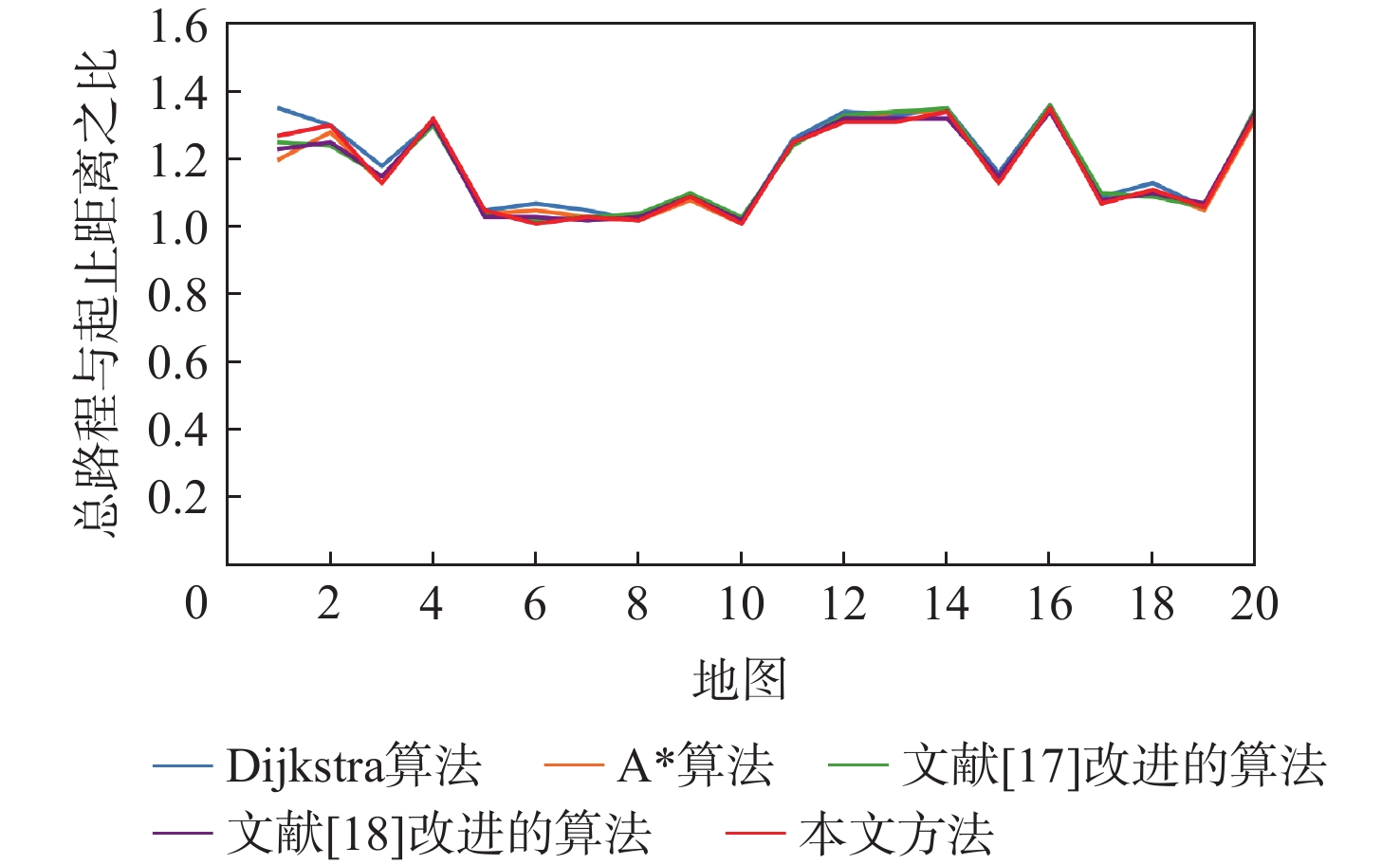
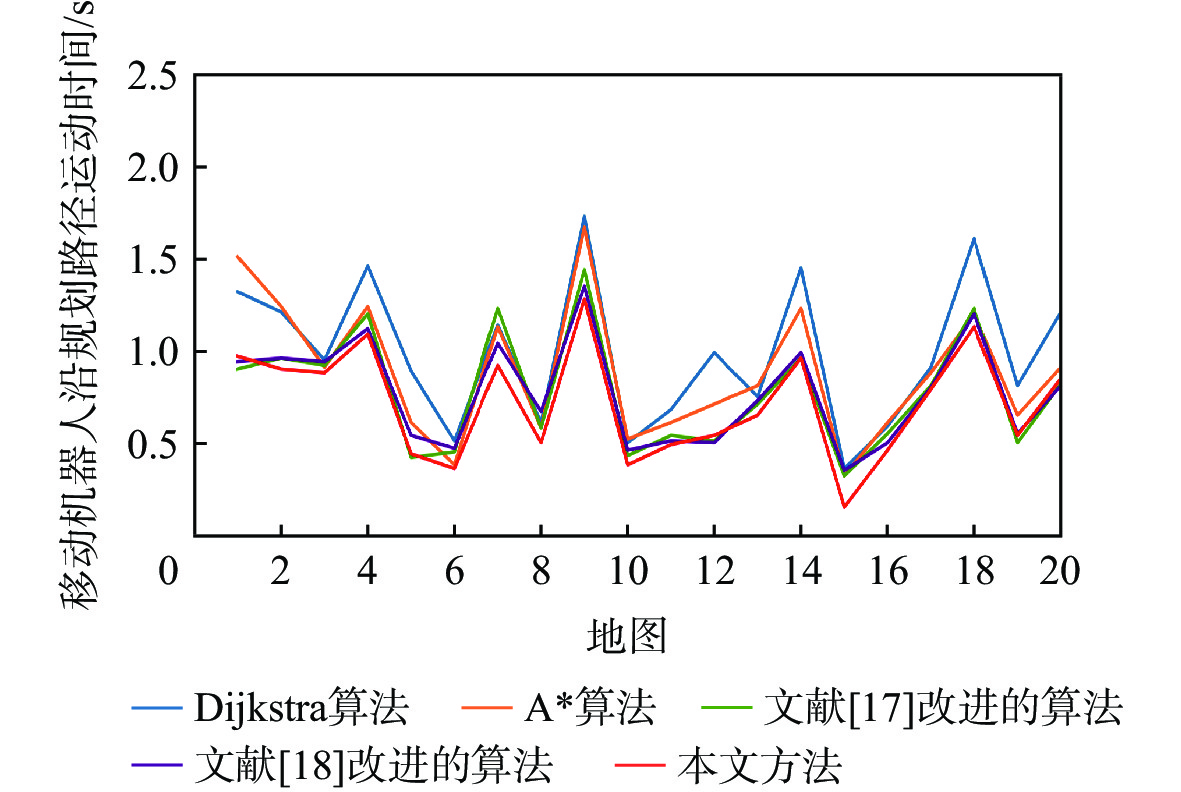
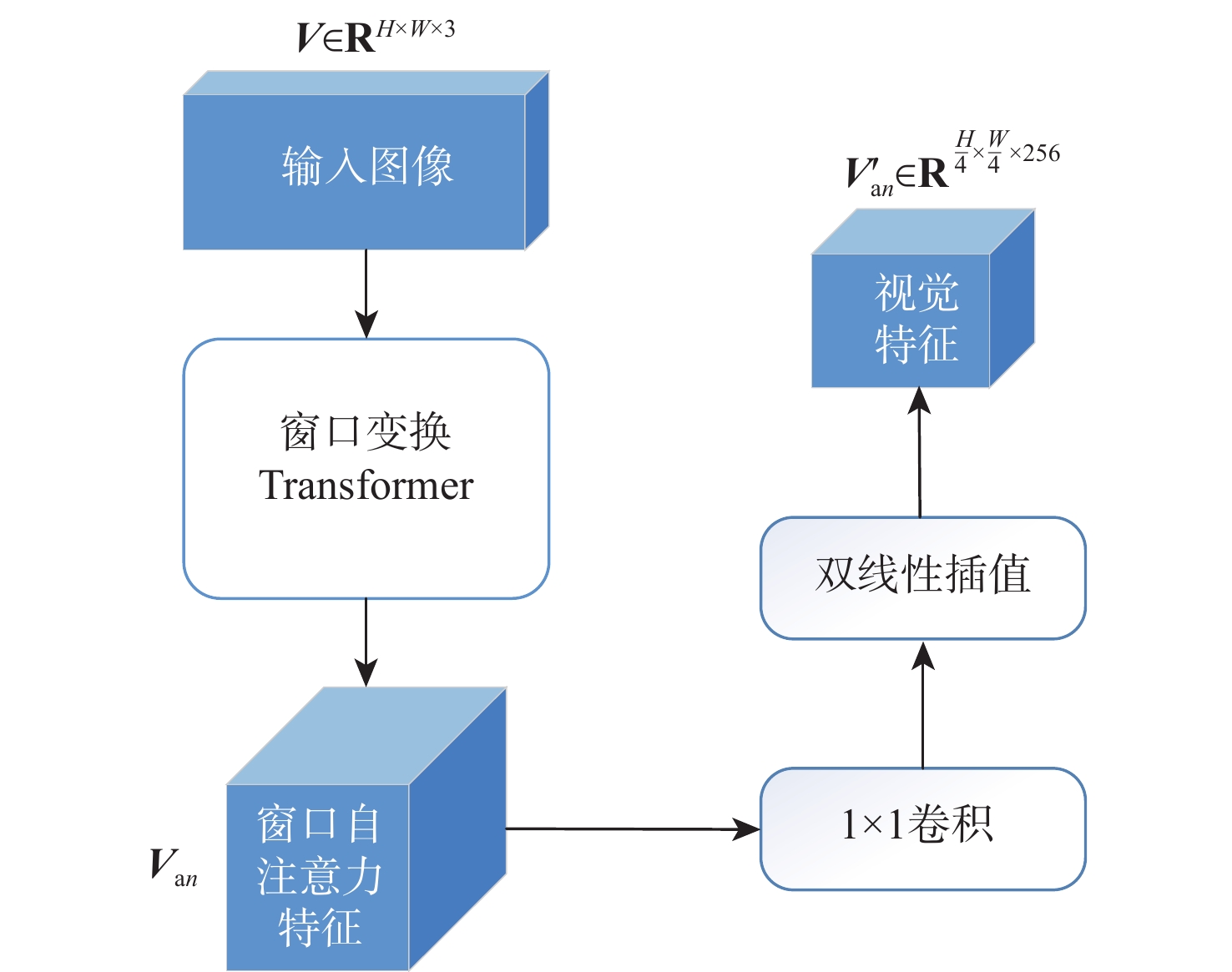
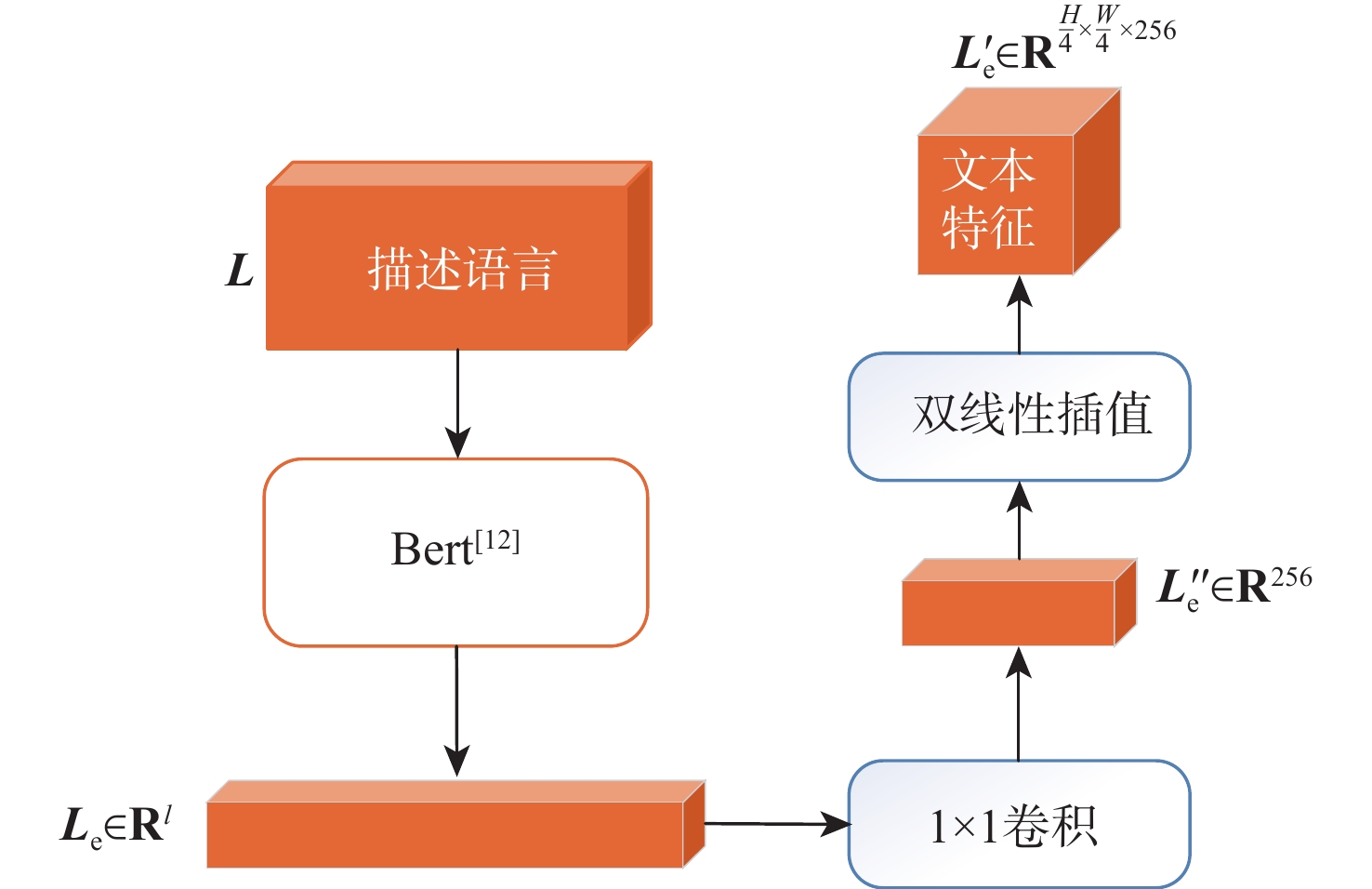
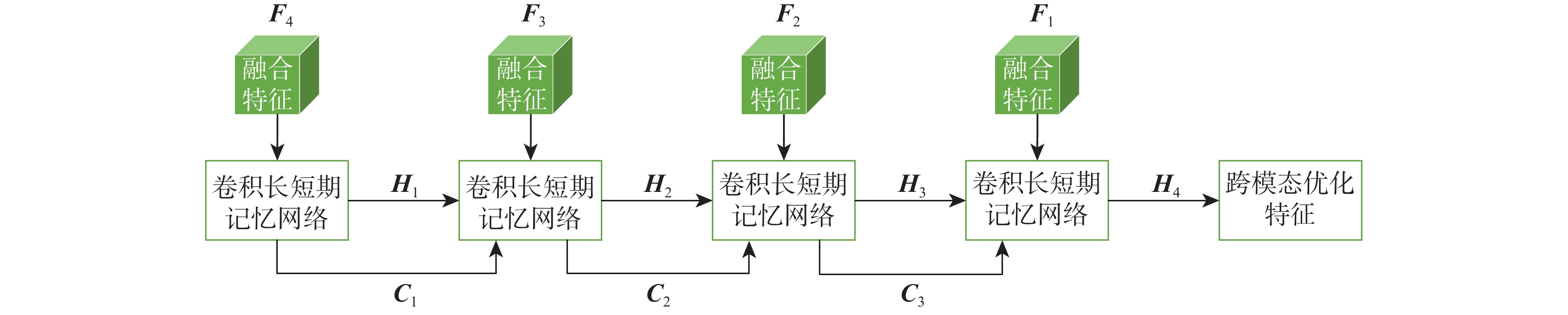
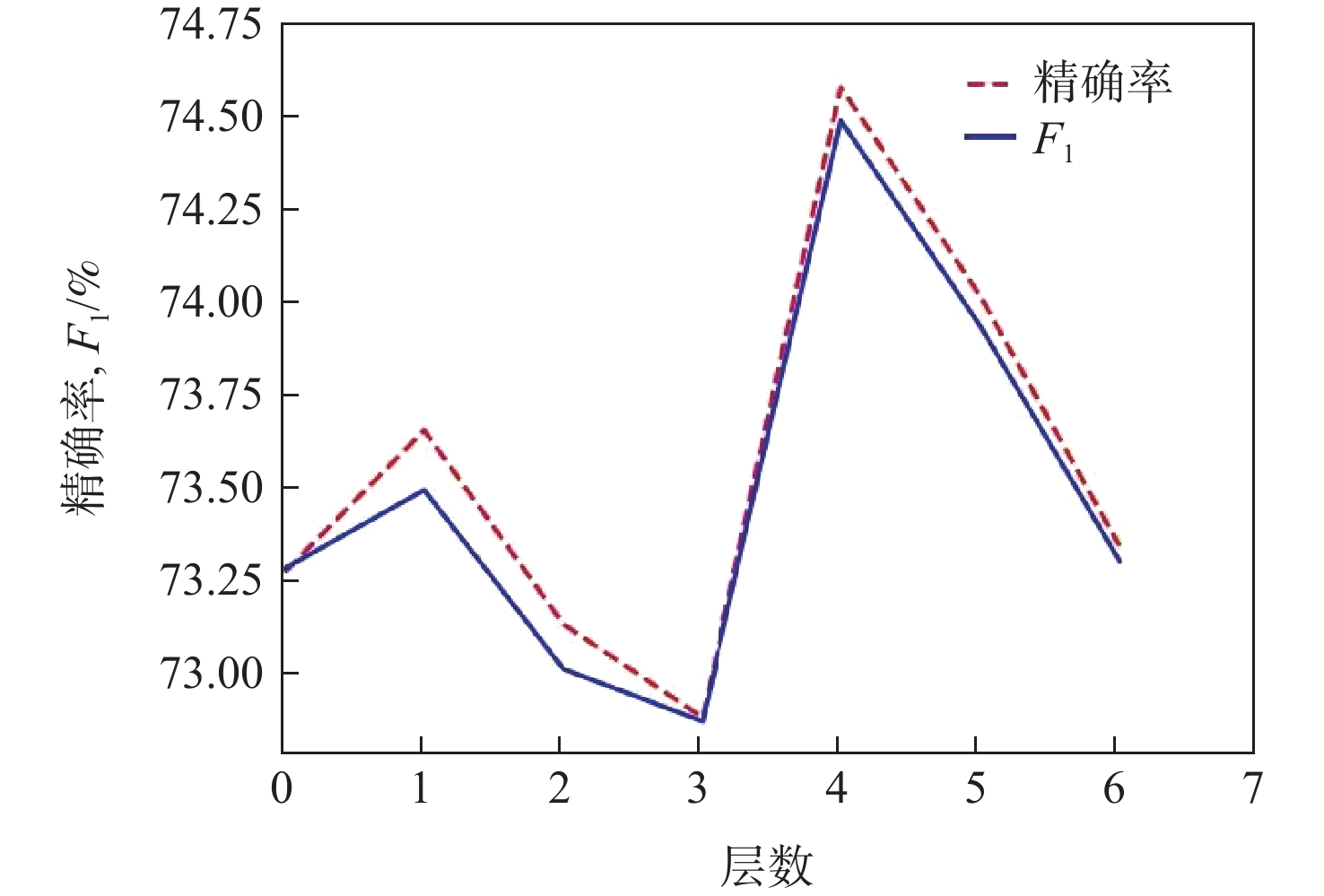
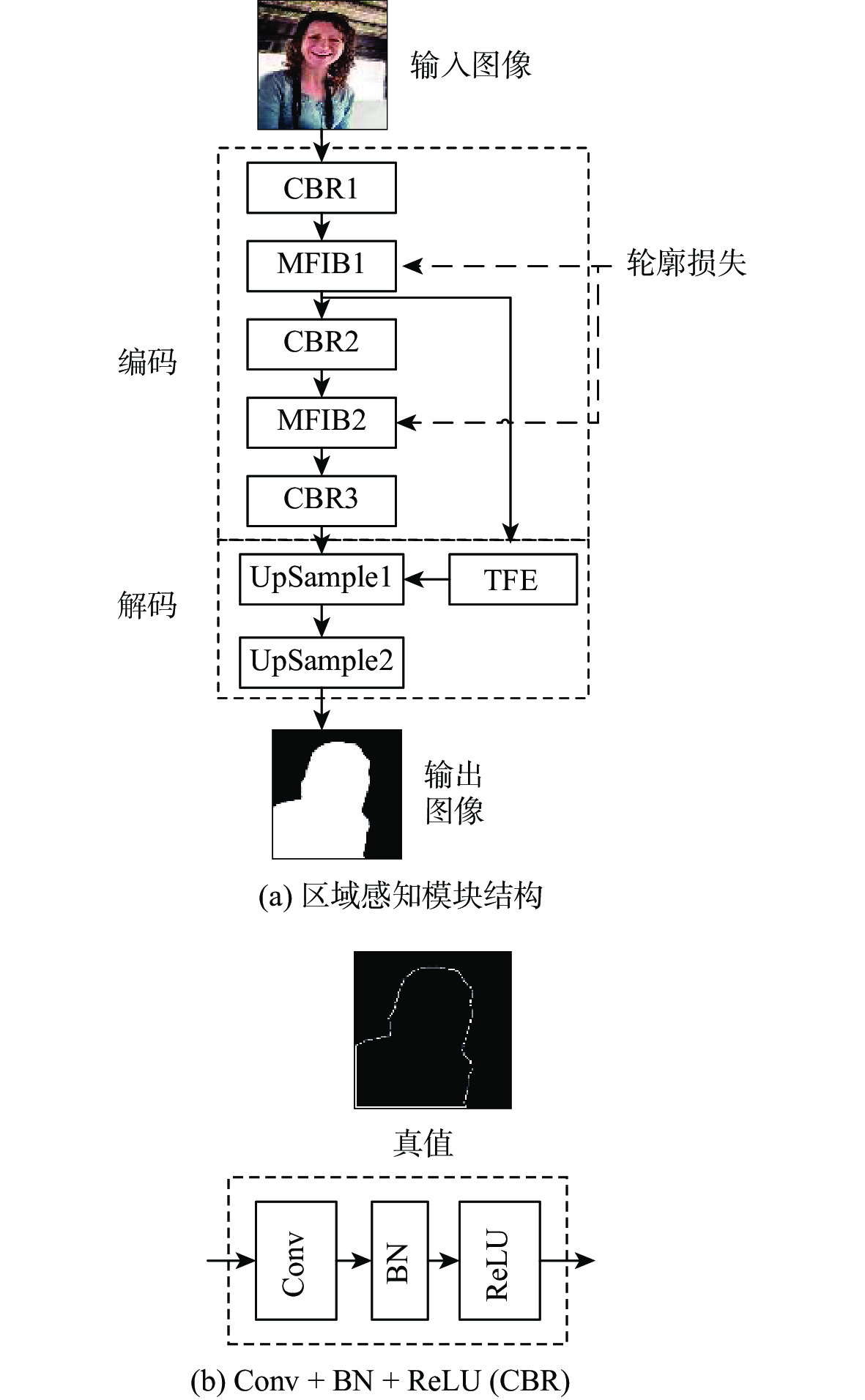
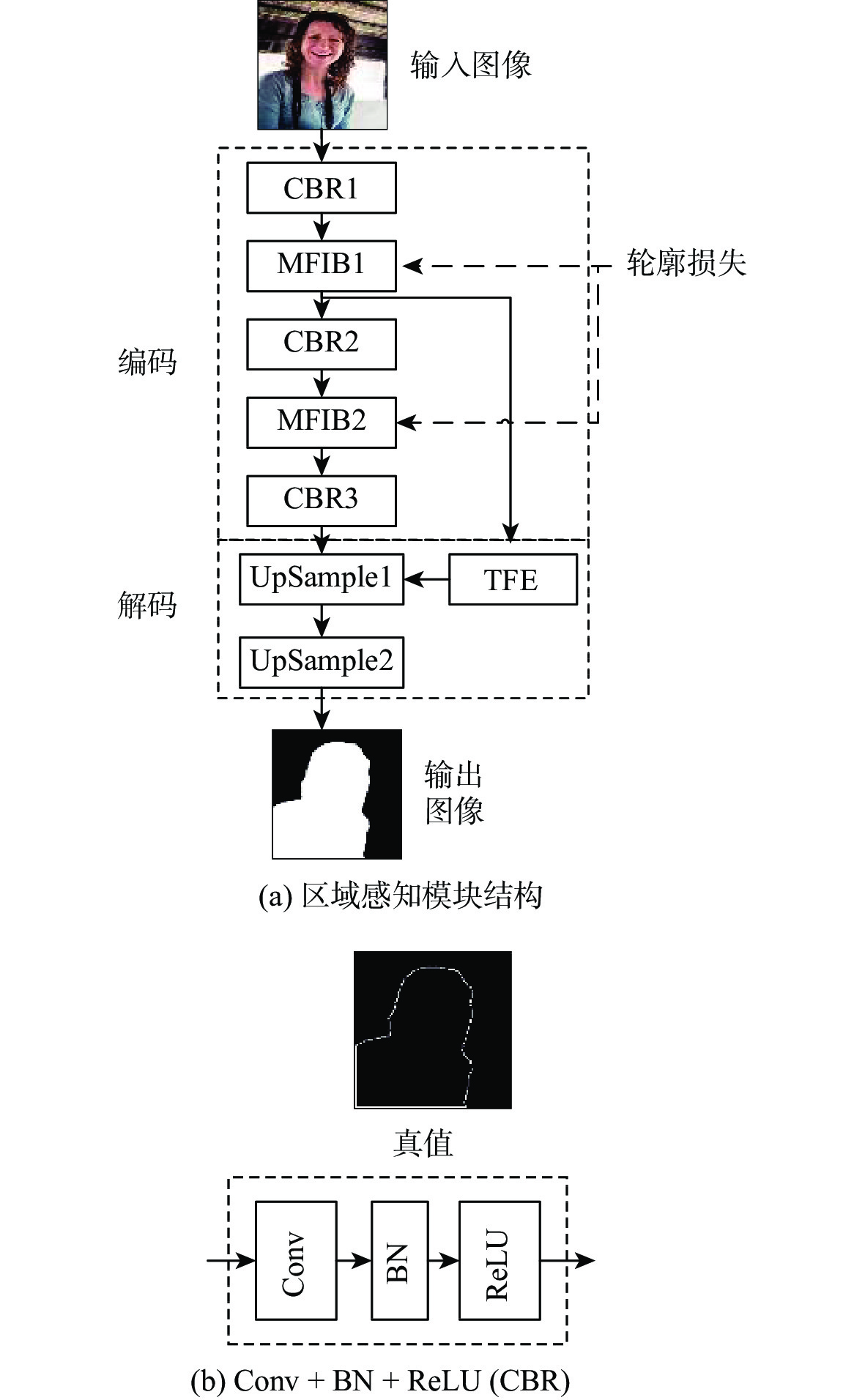
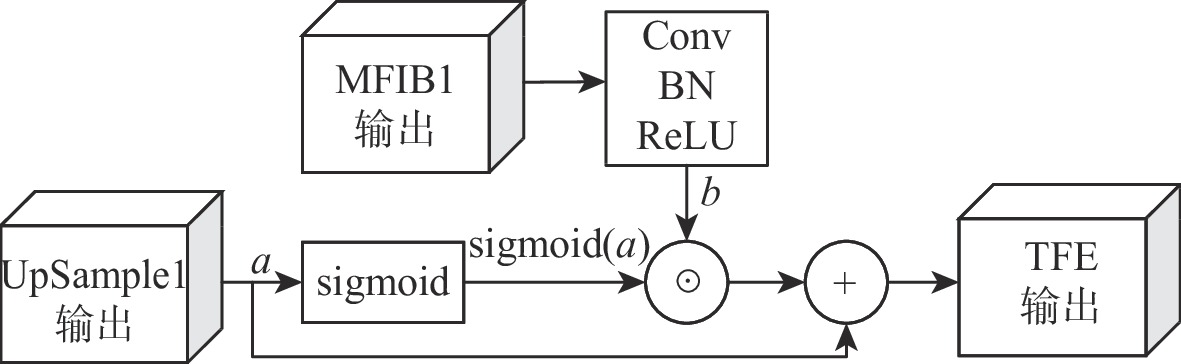
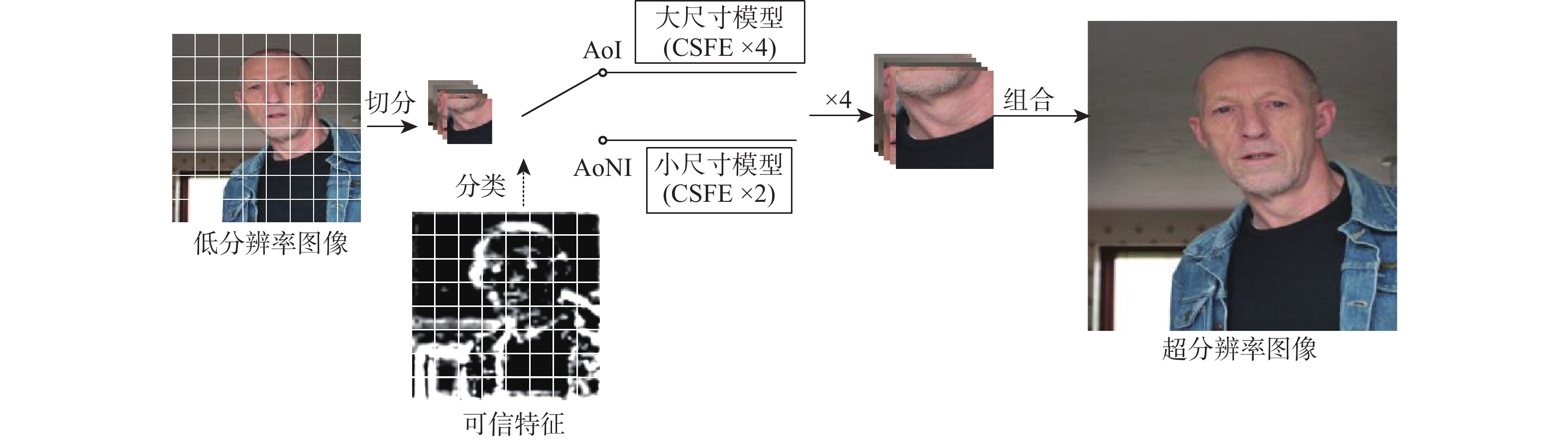
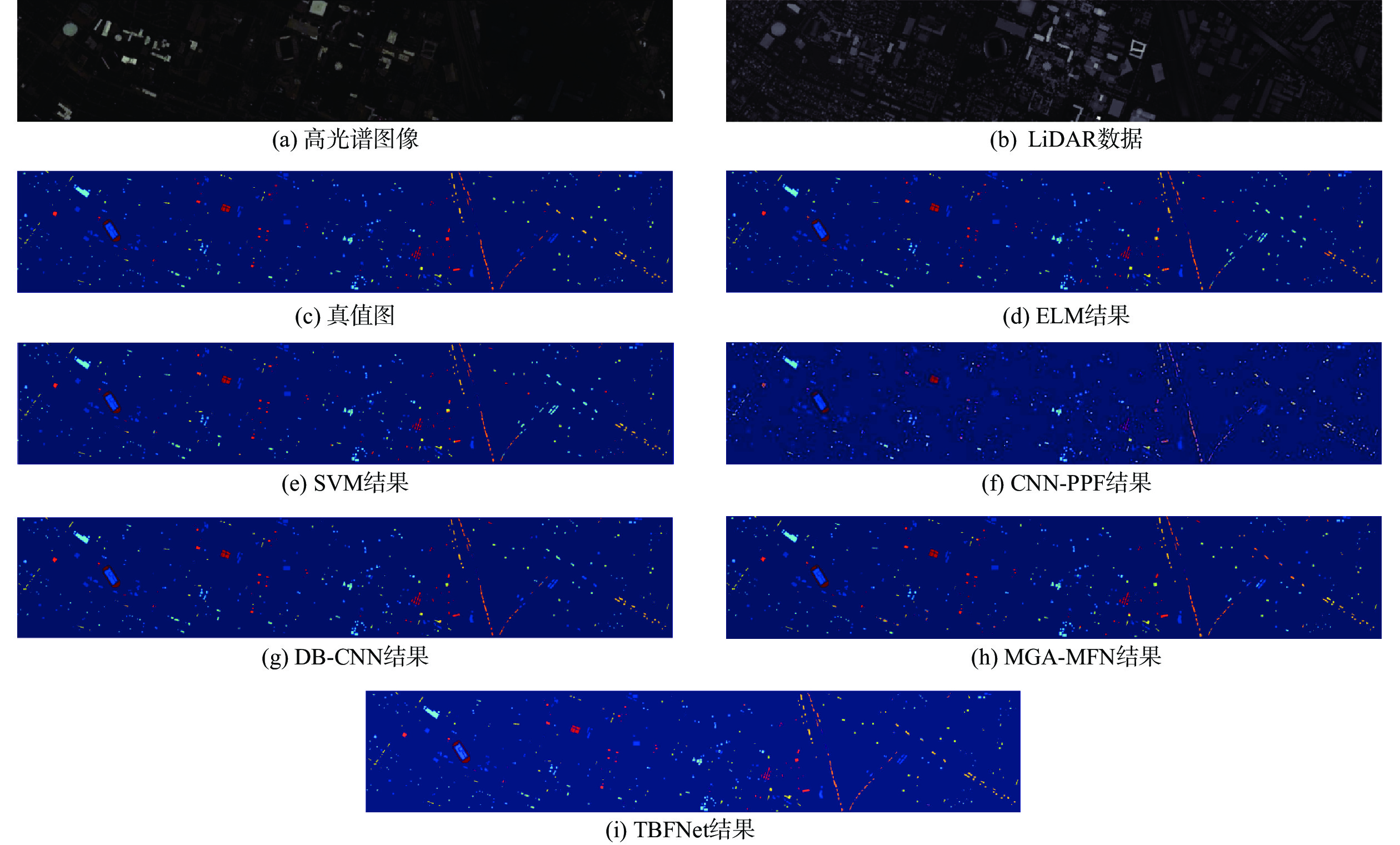
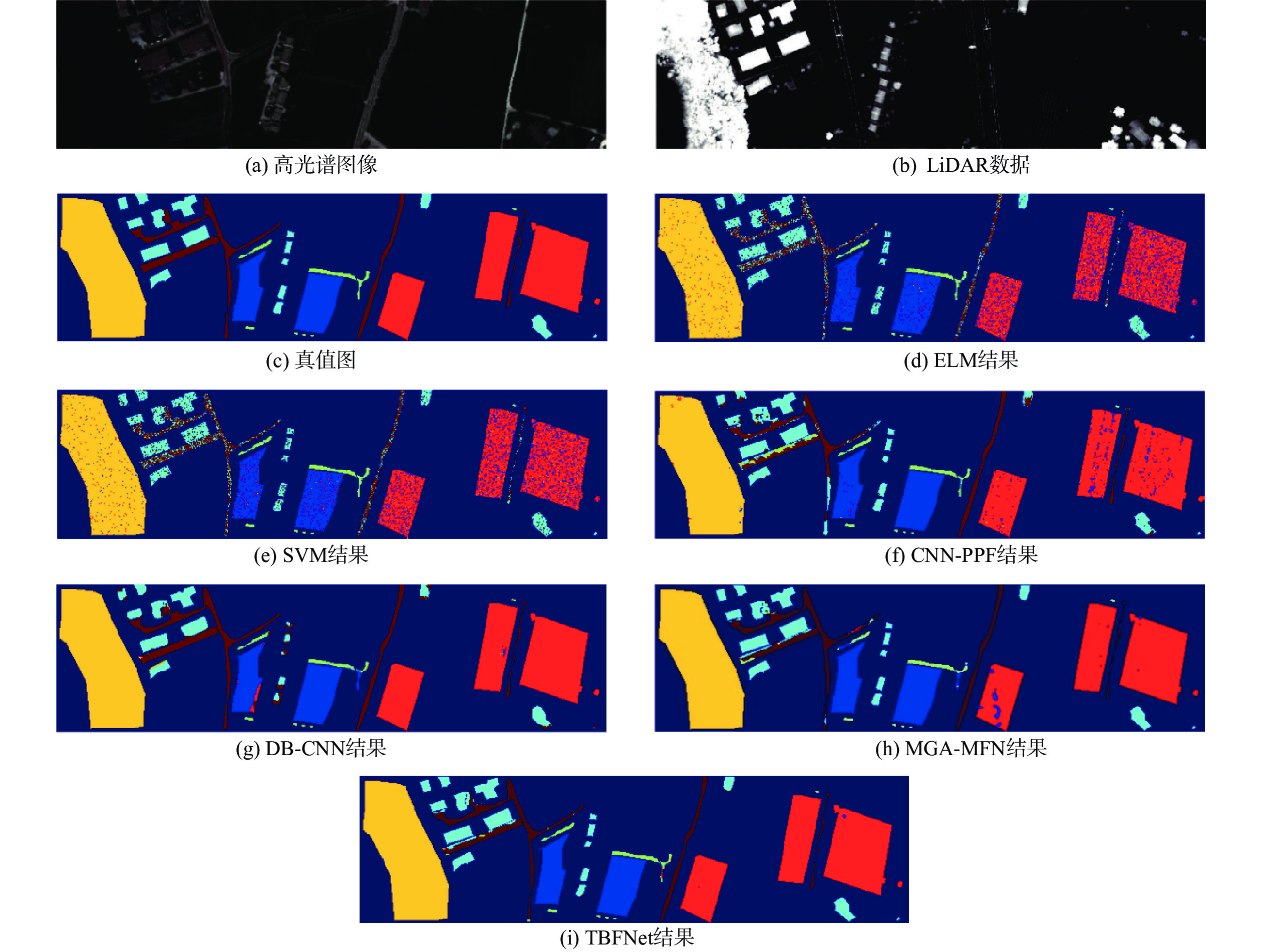
A real-time object tracking method coupled with a spatial attention mechanism is suggested in order to enhance the fully convolutional Siamese network (SiamFC) tracker’s tracking capability in complex settings and alleviate the target drift problem in the tracking process. The improved visual geometry group (VGG) network is used as the backbone network to enhance the modeling ability of the tracker for the target deep feature. The self-attention mechanism is optimized, and a lightweight single convolution attention module (SCAM) is proposed. The spatial attention is decomposed into two parallel one-dimensional feature coding processes to reduce the computational complexity of spatial attention. The initial target template in the tracking process is retained as the first template, and the second template is dynamically selected by analyzing the variation of the connected domain in the tracking response map. The target is located after fusing the two templates. The experimental results show that, compared with SiamFC, the success rate of the proposed algorithm on OTB100, LaSOT, and UAV123 datasets is increased respectively by 0.082, 0.045, and 0.045, and the tracking accuracy by 0.118,0.051, and 0.062. On the VOT2018 dataset, the proposed algorithm improves the tracking accuracy, robustness, and expected average overlap by 0.029, 0.276, and 0.134, respectively, compared with SiamFC. Real-time tracking requirements can be satisfied by the tracking speed, which can approach 70 frames per second.



 Download (49828)
Download (49828) 
 Views
Views  Cited by
Cited by 








































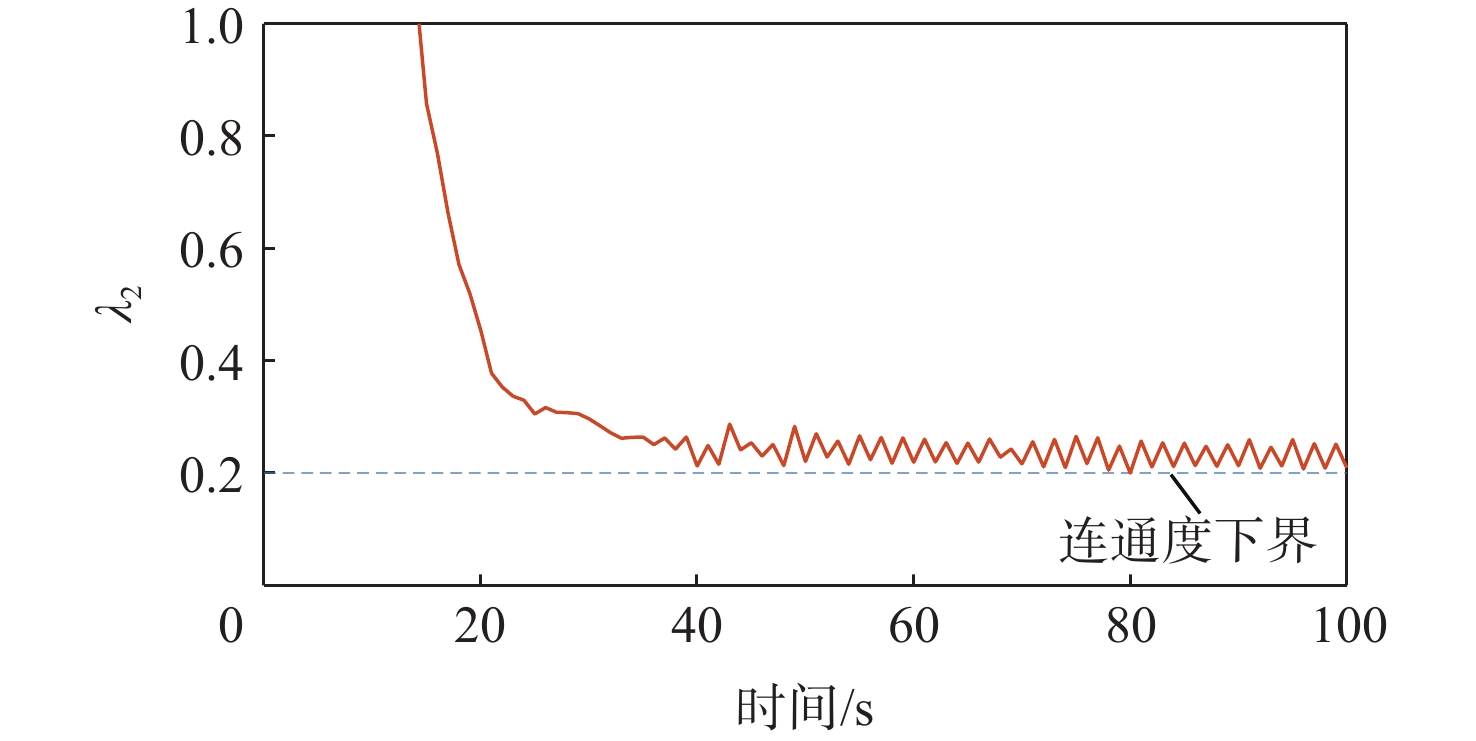
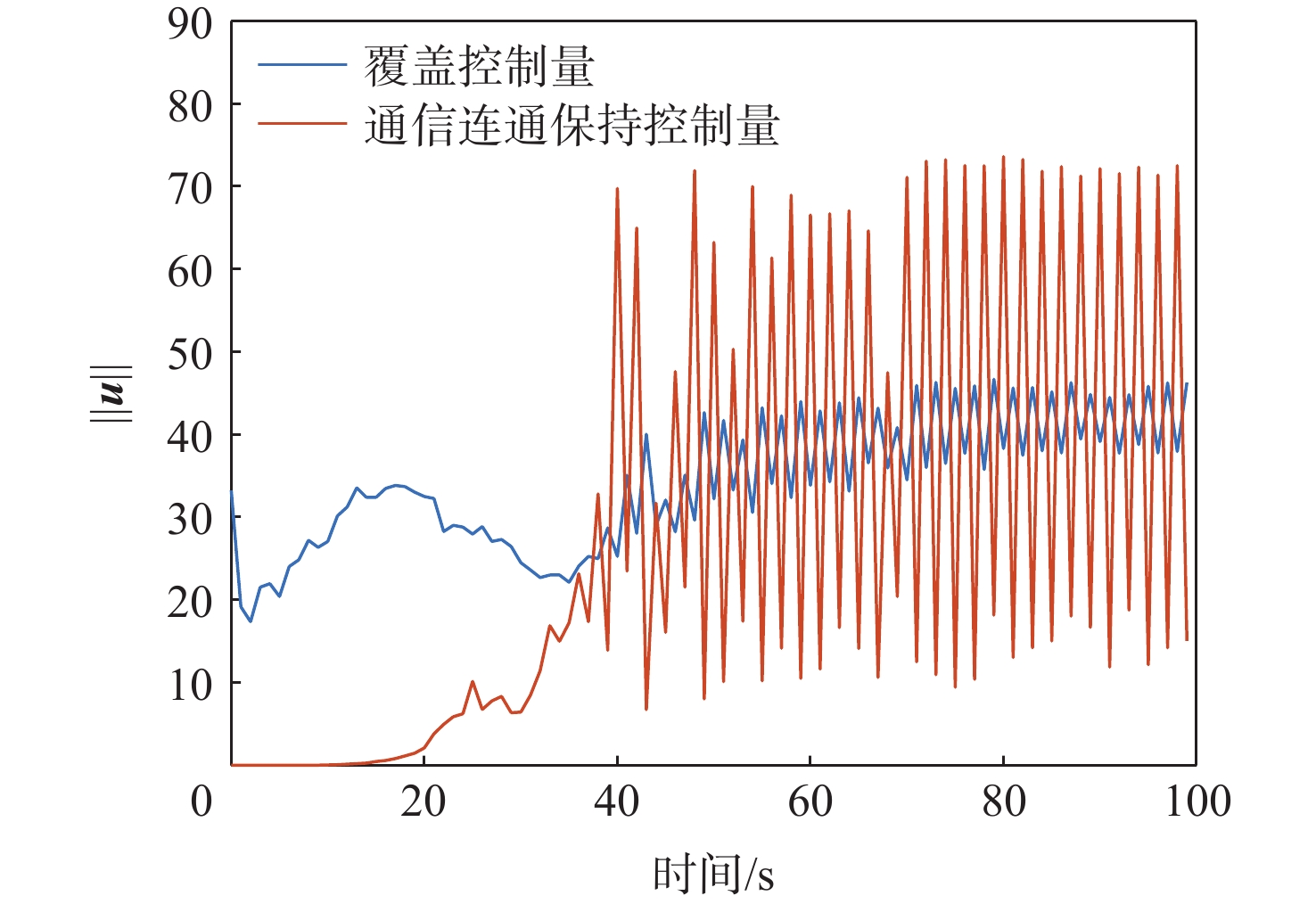
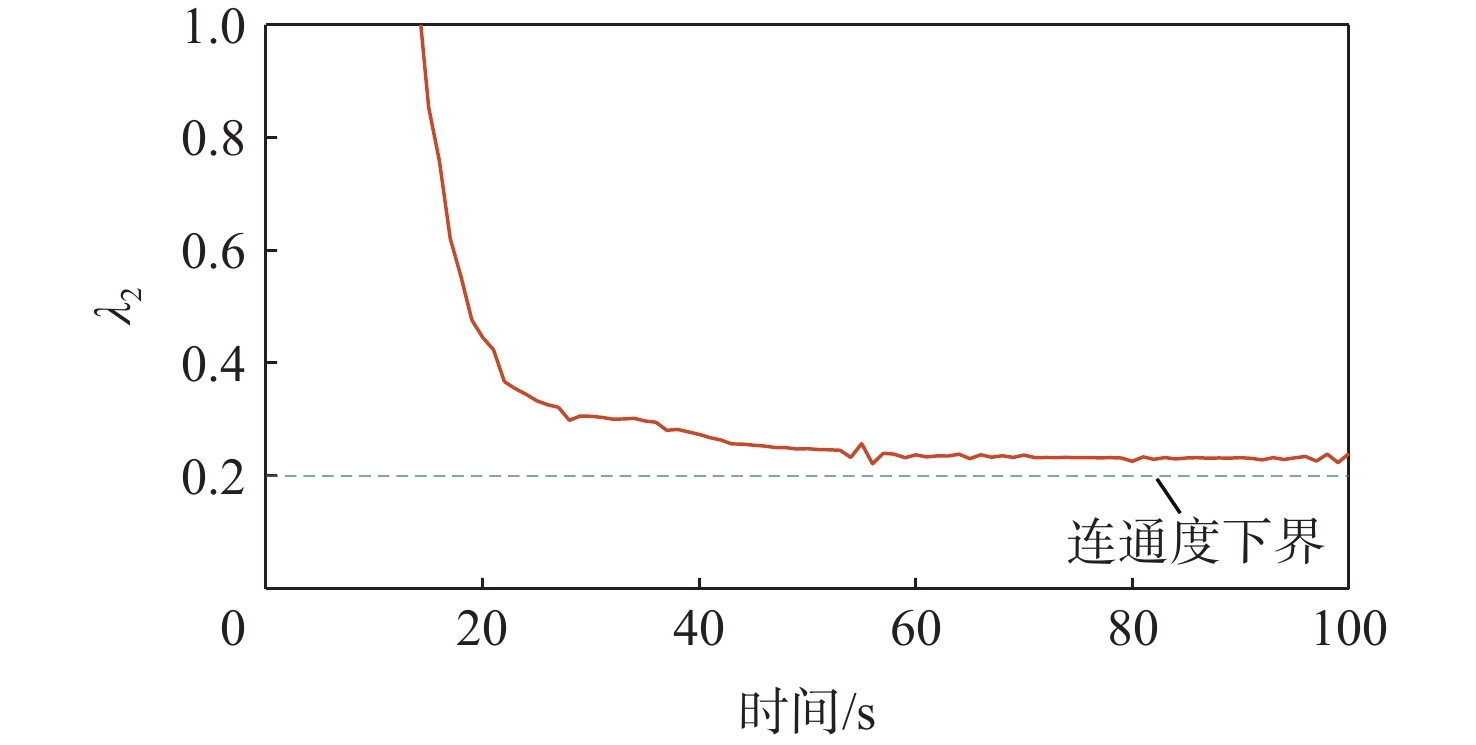
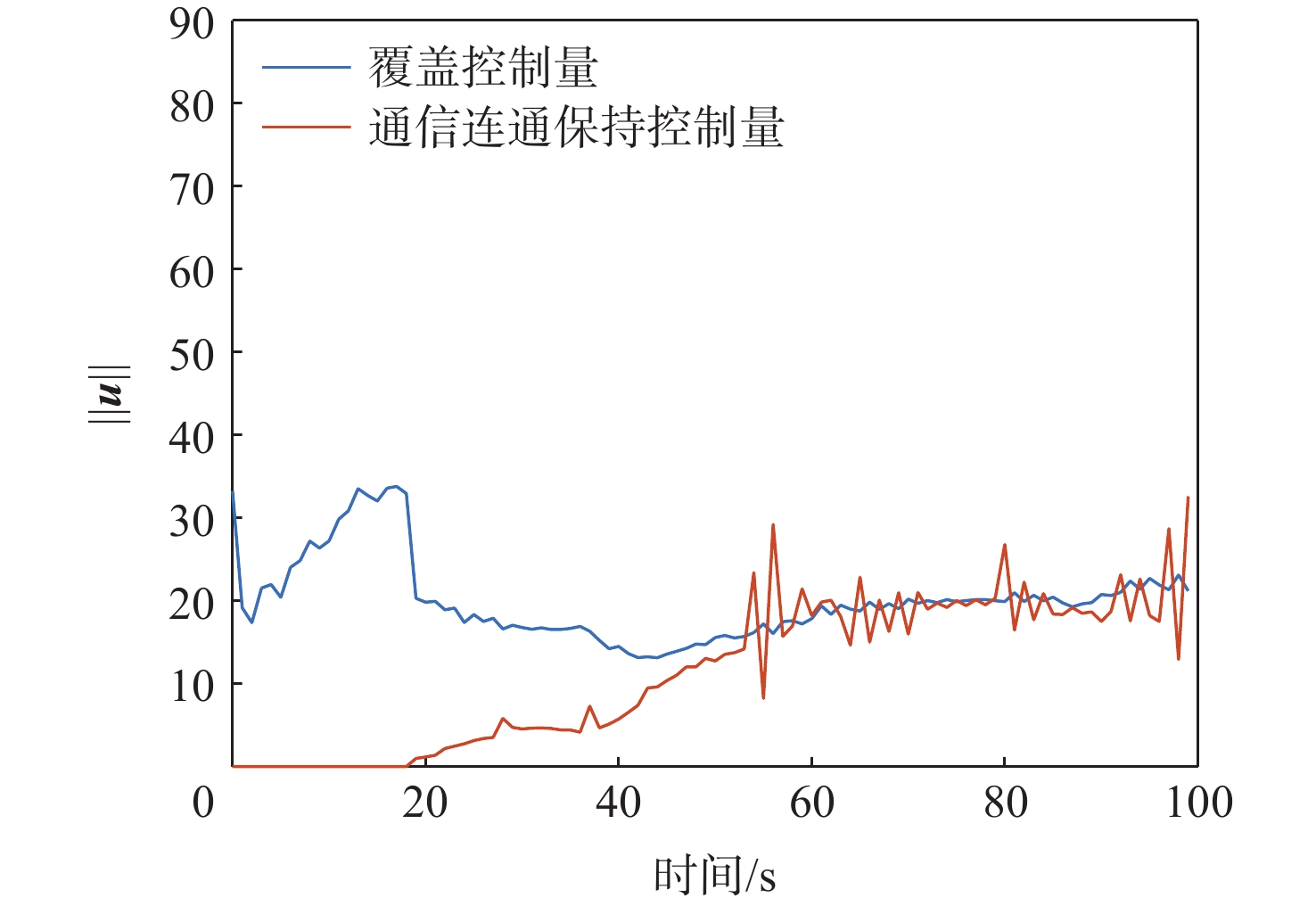






























 XML Online Production Platform
XML Online Production Platform
