| Citation: | GUO R P,WANG H R,WANG D. Multilevel relation analysis and mining method of image-text[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):684-694 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0599

|
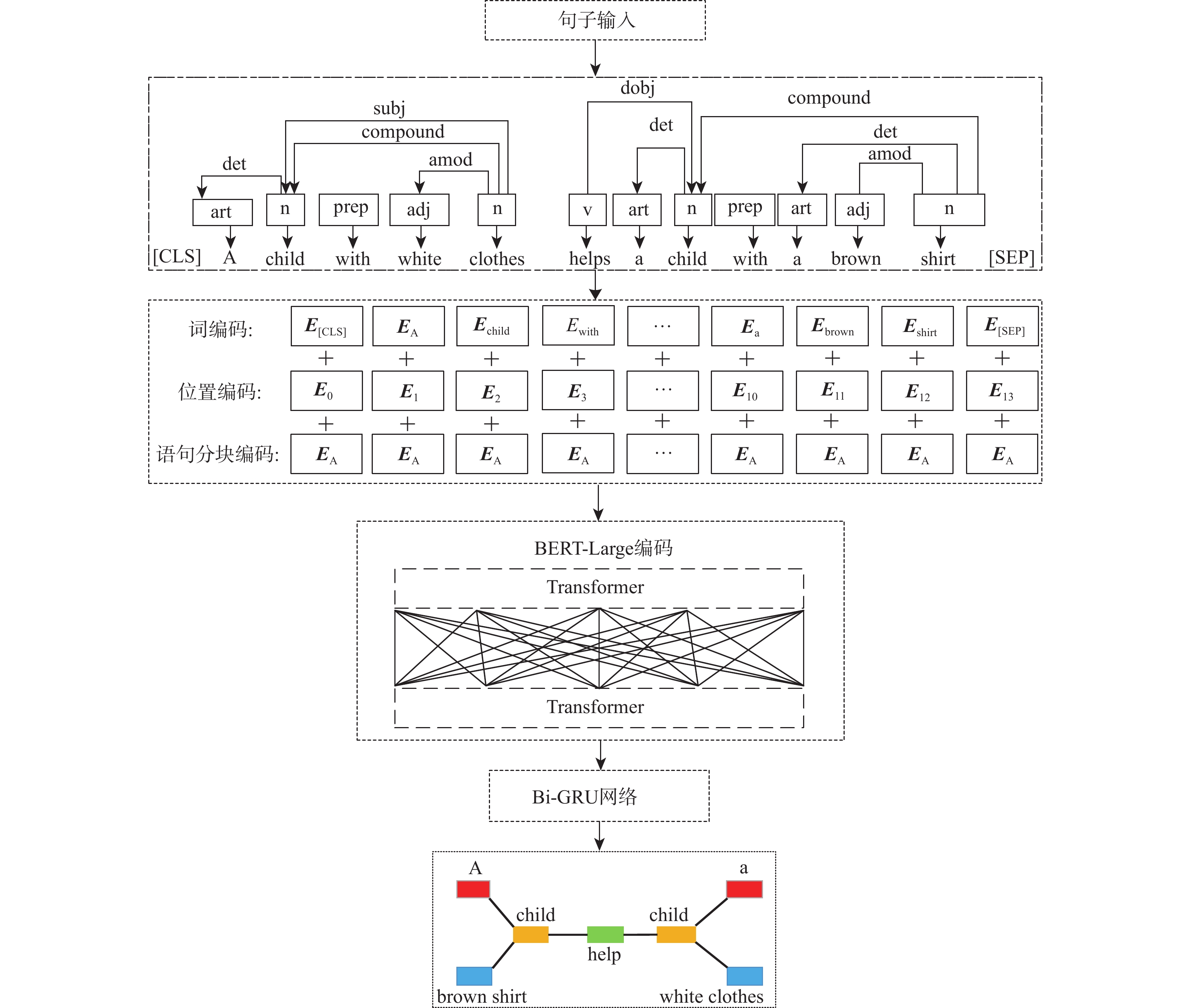
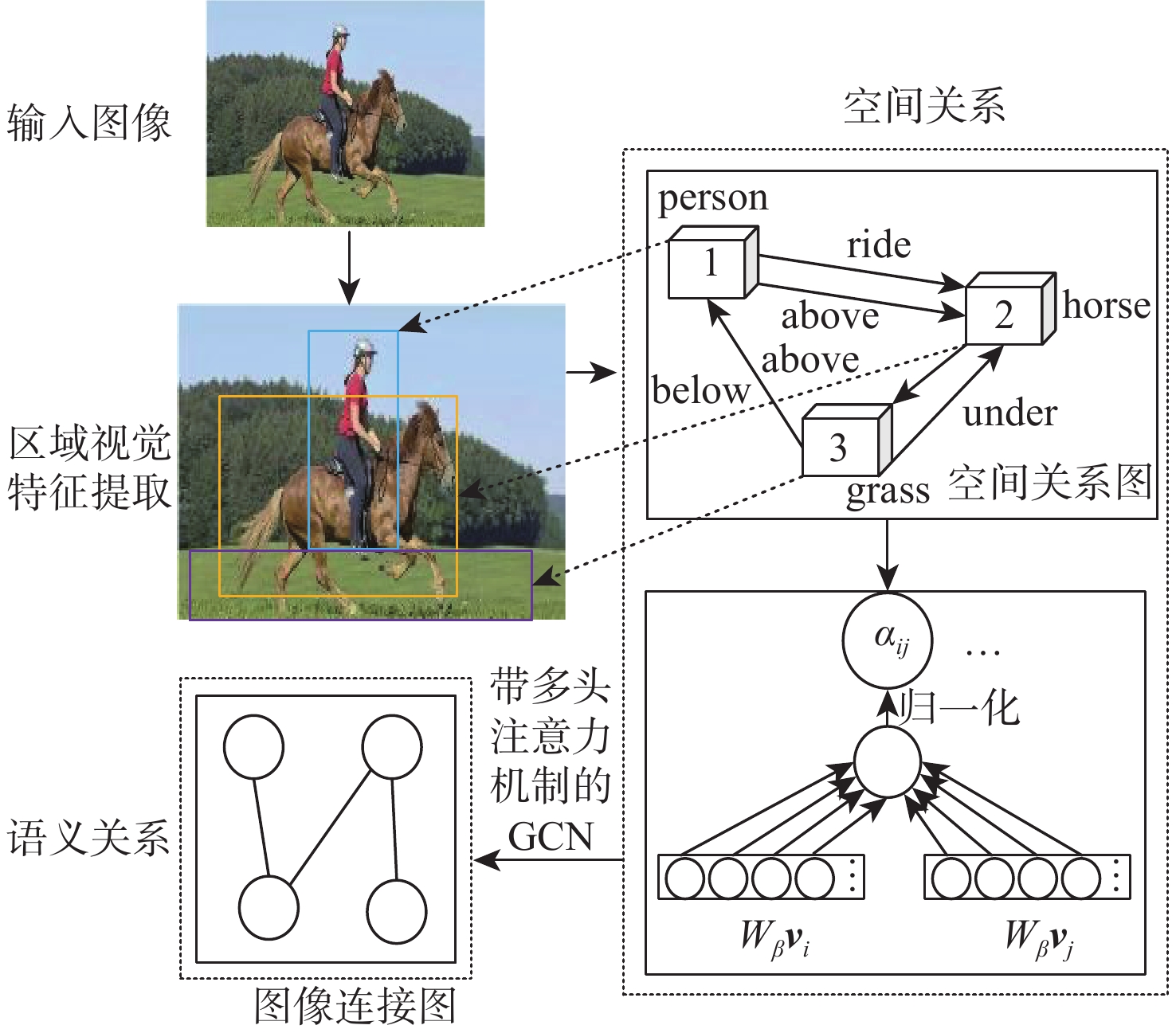
How to efficiently mine the hidden semantic association between multi-modal data is one of the key tasks of multi-modal knowledge extraction. In order to mine fine-grained relation between image and text, multilevel relation analysis and mining method of image-text (MRAM) was proposed. BERT-Large (bidirectional encoder representation from transformers-large) extracted text feature and constructed text connection graphs, while the Faster-RCNN network extracted image feature to learn spatial position relation and semantic relation, then constructed image connection graphs, so as to complete the calculation of single-modal internal semantic relation. The node segmentation method and graph convolutional network with multi-head attention (GCN-MA) fused local and global relation of text and image. To improve the efficiency of relation mining, edge weight pruning strategy based on the attention mechanism strengthened the representation of important branches, and reduced the interference of redundant information. The proposed method was tested on Flickr30K, MSCOCO-1K and MSCOCO-5K datasets, and was compared with 11 methods. The average recall rate on Flickr30K was increased by 0.97% and 0.57%, the average recall rate on MSCOCO-1K was increased by 0.93% and 0.63%, and the average recall rate on MSCOCO-5K was increased by 0.37% and 0.93%. Experimental results verify the effectiveness of the proposed method.

| [1] |
FROME A, CORRADO G S, SHLENS J, et al. Devise: A deep visual-semantic embedding model//Proceeding of the 26th International Conference on Advances in Neural Information Proceeding Systems. New York: ACM, 2013, 26: 2121-2129.
|
| [2] |
MA L, LU Z D, SHANG L F, et al. Multimodal convolutional neural networks for matching image and sentence[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2015: 2623-2631.
|
| [3] |
WEHRMANN J, BARROS R C. Bidirectional retrieval made simple[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7718-7726.
|
| [4] |
WANG T, XU X, YANG Y, et al. Matching images and text with multi-modal tensor fusion and re-ranking[C]//Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 12-20.
|
| [5] |
WANG P, WU Q, CAO J W, et al. Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 1960-1968.
|
| [6] |
MAFLA A, DEY S, BITEN A F, et al. Multi-modal reasoning graph for scene-text based fine-grained image classification and retrieval[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2021: 4022-4032.
|
| [7] |
LIU S, QIAN S S, GUAN Y, et al. Joint-modal distribution-based similarity hashing for large-scale unsupervised deep cross-modal retrieval[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 1379-1388.
|
| [8] |
DONG X F, ZHANG H X, DONG X, et al. Iterative graph attention memory network for cross-modal retrieval[J]. Knowledge-Based Systems, 2021, 226: 107138.
|
| [9] |
KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 3128-3137.
|
| [10] |
LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]//Proceedings of the European Conference on Computer Vision. Berkin: Springer, 2018: 212-228.
|
| [11] |
HUANG Y, WANG W, WANG L. Instance-aware image and sentence matching with selective multimodal LSTM[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 7254-7262.
|
| [12] |
YAO T, PAN Y W, LI Y H, et al. Exploring visual relationship for image captioning[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 711-727.
|
| [13] |
HOU J Y, WU X X, QI Y Y, et al. Relational reasoning using prior knowledge for visual captioning [EB/OL]. (2019-06-04)[2022-08-20]. http://arxiv.org/abs/1906.01290.
|
| [14] |
WANG Y X, YANG H, QIAN X M, et al. Position focused attention network for image-text matching [EB/OL]. (2019-07-23)[2022-08-20]. http://arxiv.org/abs/1907.09748.
|
| [15] |
CHEN H, DING G G, LIU X D, et al. IMRAM: Iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscatawa: IEEE Press, 2020: 12652-12660.
|
| [16] |
LI K P, ZHANG Y L, Li K, et al. Visual semantic reasoning for image-text matching[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 4653-4661.
|
| [17] |
WANG Z H, LIU X H, LI H S, et al. CAMP: Cross-modal adaptive message passing for text-image retrieval[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 5764-5773.
|
| [18] |
YANG Z Q, QIN Z C, YU J, et al. Scene graph reasoning with prior visual relationship for visual question answering[EB/OL]. (2019-08-21)[2020-08-20]. http://arxiv.org/abs/1812.09681.
|
| [19] |
SONG Y, SOLEYMANI M. Polysemous visual-semantic embedding for cross-modal retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 1979-1988.
|
| [20] |
ZHANG Q, LEI Z, ZHANG Z, et al. Context-aware attention network for image-text retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 3533-3542.
|
| [21] |
WANG S J, WANG R P, YAO Z W, et al. Cross-modal scene graph matching for relationship-aware image-text retrieval[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2020: 1497-1506.
|
| [22] |
ZHENG Z D, ZHENG L, GARRETT M, et al. Dual-path convolutional image-text embeddings with instance loss[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2020, 16(2): 51.
|
| [23] |
LI Y, ZHANG D, MU Y. Visual-semantic matching by exploring high-order attention and distraction[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 12783-12792.
|
| [24] |
DONG X Z, LONG C J, XU W J, et al. Dual graph convolutional networks with transformer and curriculum learning for image captioning[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 2615-2624.
|
| [25] |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24)[2022-08-20]. http://arxiv.org/abs/1810.04805.
|
| [26] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
|
| [27] |
KRISHNA R, ZHU Y K, GROTH O, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. doi: 10.1007/s11263-016-0981-7
|
| [28] |
LI L J, GAN Z, CHENG Y, et al. Relation-aware graph attention network for visual question answering[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 10312-10321.
|
| [29] |
YOUNG P, LAI A, HODOSH M, et al. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67-78. doi: 10.1162/tacl_a_00166
|
| [30] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
|
| [31] |
FAGHRI F, FLEET D J, KIROS J R, et al. Vse++: Improving visual-semantic embeddings with hard negatives[EB/OL]. (2017-07-18)[2022-08-20]. http://arxiv.org/abs/1707.05612.
|
| [32] |
GU J X, CAI J F, JOTY S R, et al. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7181-7189.
|
| [33] |
HUANG Y, WU Q, SONG C F, et al. Learning semantic concepts and order for image and sentence matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6163-6171.
|
| [34] |
WEI X, ZHANG T Z, LI Y, et al. Multi-modality cross attention network for image and sentence matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10938-10947.
|
| [35] |
杜锦丰, 王海荣, 李明亮, 等. 多层语义对齐的跨模态检索方法研究[J]. 郑州大学学报(理学版), 2021, 53(4): 83-88.
DU J F, WANG H R, LI M L, et al. Research on cross-modal retrieval method based on multi-layer semantic alignment[J]. Journal of Zhengzhou University (Natural Science Edition), 2021, 53(4): 83-88(in Chinese).
|

Figures(3) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: