| Citation: | JIANG W H,CHEN Z L,CHENG Y B,et al. Image captioning model based on divergence-based and spatial consistency constraints[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):456-465 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0400

|
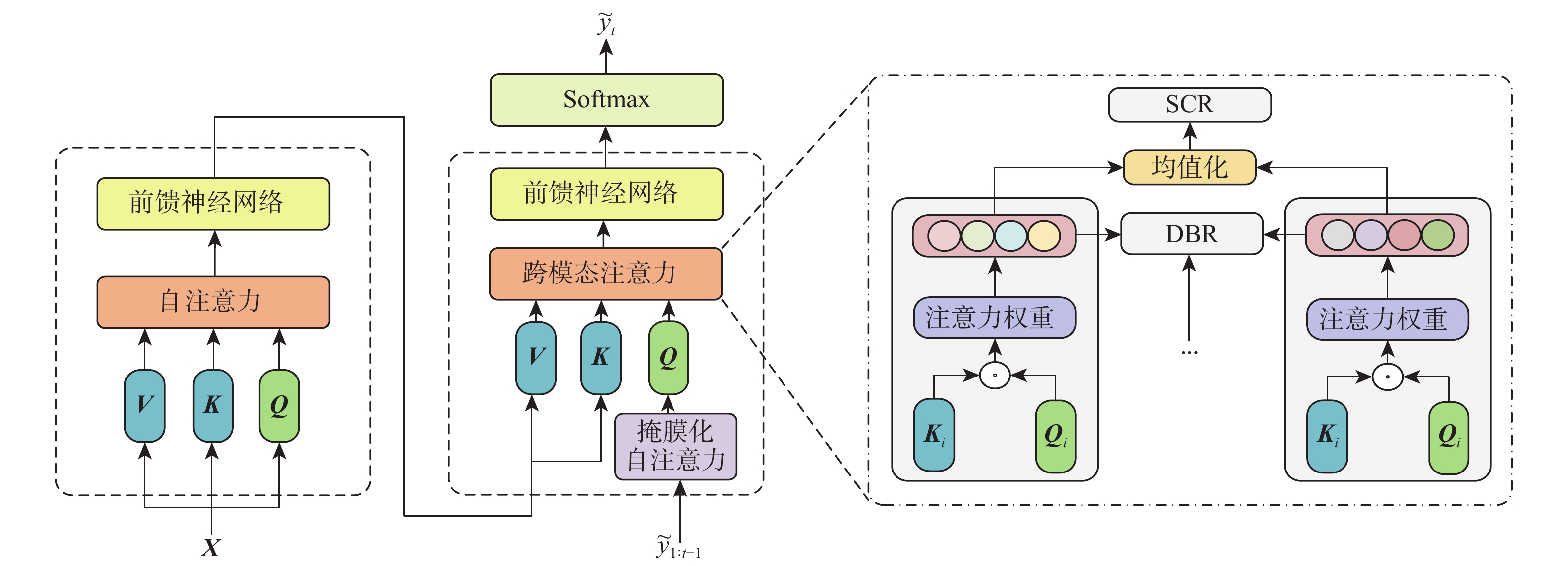
The multi-head attention mechanism has been widely adopted in image captioning. It is appealing for the ability to jointly attend to information from different representation subspaces. However, as each head captures distinct properties of the input individually, the diversity between heads’ representations is not guaranteed. In the meanwhile, most existing attention models encounter the problem of “attention defocus”, i.e., they fail to concentrate on correct image regions when generating the target words. Consequently, the generated sentences are not accurate enough. To address these problems, we propose a novel training objective that serves as an auxiliary regularization function to improve the diversity and accuracy of the multi-head attention mechanism. In the beginning, we present a divergence-based regularization that encourages each brain to concentrate on various areas of the goal. Partial representations are aggregated to produce distinct representations of the target. Secondly, we introduce a spatial consistency regularization that builds the spatial relationship among the attended regions. By encouraging the attended regions to be focussed, it enhances image captioning. We proposed a method for the joint action of divergence-based regularization and spatial consistency regularization. We compare the performance of the proposed method with state-of-the-art methods on challenging MS COCO datasets. The experimental results demonstrate the superior performance of the proposed method.

| [1] |
WAN B Y, JIANG W H, FANG Y M, et al. Revisiting image captioning via maximum discrepancy competition[J]. Pattern Recognition, 2022, 122: 108358. doi: 10.1016/j.patcog.2021.108358
|
| [2] |
谭云兰, 汤鹏杰, 张丽, 等. 从图像到语言: 图像标题生成与描述[J]. 中国图象图形学报, 2021, 26(4): 727-750. doi: 10.11834/jig.200177
TAN Y L, TANG P J, ZHANG L, et al. From image to language: Image captioning and description[J]. Journal of Image and Graphics, 2021, 26(4): 727-750 (in Chinese). doi: 10.11834/jig.200177
|
| [3] |
石义乐, 杨文忠, 杜慧祥, 等. 基于深度学习的图像描述综述[J]. 电子学报, 2021, 49(10): 2048-2060. doi: 10.12263/DZXB.20200669
SHI Y L, YANG W Z, DU H X, et al. Overview of image captions based on deep learning[J]. Acta Electronica Sinica, 2021, 49(10): 2048-2060 (in Chinese). doi: 10.12263/DZXB.20200669
|
| [4] |
XU K, BA J L, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37. New York: ACM, 2015: 2048-2057.
|
| [5] |
ANDERSON P, HE X D, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6077-6086.
|
| [6] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010.
|
| [7] |
VOITA E, TALBOT D, MOISEEV F, et al. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2019: 5797-5808.
|
| [8] |
YANG B S, LI J A, WONG D F, et al. Context-aware self-attention networks[J]. Computer Science, 2019, 33(1): 387-394. doi: 10.1609/aaai.v33i01.3301387
|
| [9] |
LI J A, TU Z P, YANG B S, et al. Multi-head attention with disagreement regularization[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2018: 2897-2903.
|
| [10] |
LIU C X, MAO J H, SHA F, et al. Attention correctness in neural image captioning[J]. Computer Science, 2017, 31(1): 4176-4182.
|
| [11] |
ROHRBACH A, HENDRICKS L A, BURNS K, et al. Object hallucination in image captioning[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2018: 4035-4045.
|
| [12] |
ZHOU Y E, WANG M, LIU D Q, et al. More grounded image captioning by distilling image-text matching model[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 4777-4786.
|
| [13] |
MA C Y, KALANTIDIS Y, ALREGIB G, et al. Learning to generate grounded visual captions without localization supervision[C]// Proceedings of the 16th European Conference, Glasgow. New York: ACM, 2020: 353-370.
|
| [14] |
PAPANDREOU G, ZHU T, CHEN L C, et al. PersonLab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model[C]//Computer Vision – ECCV 2018. Berlin: Springer, 2018: 282-299.
|
| [15] |
HE S, TAVAKOLI H R, BORJI A, et al. Human attention in image captioning: dataset and analysis[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 8528-8537.
|
| [16] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
|
| [17] |
毕健旗, 刘茂福, 胡慧君, 等. 基于依存句法的图像描述文本生成[J]. 北京航空航天大学学报, 2021, 47(3): 431-440. doi: 10.13700/j.bh.1001-5965.2020.0443
BI J Q, LIU M F, HU H J, et al. Image captioning based on dependency syntax[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(3): 431-440 (in Chinese). doi: 10.13700/j.bh.1001-5965.2020.0443
|
| [18] |
JI J Z, XU C, ZHANG X D, et al. Spatio-temporal memory attention for image captioning[J]. IEEE Transactions on Image Processing, 2020, 29: 7615-7628. doi: 10.1109/TIP.2020.3004729
|
| [19] |
ZHA Z J, LIU D Q, ZHANG H W, et al. Context-aware visual policy network for fine-grained image captioning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(2): 710-722. doi: 10.1109/TPAMI.2019.2909864
|
| [20] |
ZHANG W Q, SHI H C, TANG S L, et al. Consensus graph representation learning for better grounded image captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(4): 3394-3402. doi: 10.1609/aaai.v35i4.16452
|
| [21] |
YANG X, ZHANG H W, CAI J F. Deconfounded image captioning: A causal retrospect[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 12996-13010.
|
| [22] |
PAN Y W, YAO T, LI Y H, et al. X-linear attention networks for image captioning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10968-10977.
|
| [23] |
JI J Y, LUO Y P, SUN X S, et al. Improving image captioning by leveraging intra-and inter-layer global representation in transformer network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(2): 1655-1663. doi: 10.1609/aaai.v35i2.16258
|
| [24] |
GUO L T, LIU J, LU S C, et al. Show, tell, and polish: Ruminant decoding for image captioning[J]. IEEE Transactions on Multimedia, 2020, 22(8): 2149-2162. doi: 10.1109/TMM.2019.2951226
|
| [25] |
NGUYEN K, TRIPATHI S, DU B, et al. In defense of scene graphs for image captioning[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2022: 1387-1396.
|
| [26] |
SHEN T, ZHOU T Y, LONG G D, et al. DiSAN: Directional self-attention network for RNN/CNN-free language understanding[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 5446-5455.
|
| [27] |
STRUBELL E, VERGA P, ANDOR D, et al. Linguistically-informed self-attention for semantic role labeling[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2018: 5027–5038.
|
| [28] |
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 1179-1195.
|
| [29] |
KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 3128-3137.
|
| [30] |
JIANG H Z, MISRA I, ROHRBACH M, et al. In defense of grid features for visual question answering[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10264-10273.
|
| [31] |
CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10575-10584.
|
| [32] |
BANSAL N, CHEN X H, WANG Z Y. Can we gain more from orthogonality regularizations in training deep CNNs? [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. New York: ACM, 2018: 4266-4276.
|
| [33] |
HUANG L, WANG W M, XIA Y X, et al. Adaptively aligned image captioning via adaptive attention time[C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems. New York: ACM,2019: 8942-8951.
|
| [34] |
HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: Transforming objects into words[C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems. New York: ACM, 2019: 11137-11147.
|
| [35] |
YANG L Y, WANG H L, TANG P J, et al. CaptionNet: A tailor-made recurrent neural network for generating image descriptions[J]. IEEE Transactions on Multimedia, 2021, 23: 835-845. doi: 10.1109/TMM.2020.2990074
|
| [36] |
YAN C G, HAO Y M, LI L, et al. Task-adaptive attention for image captioning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(1): 43-51. doi: 10.1109/TCSVT.2021.3067449
|

Figures(4) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: