| Citation: | DUAN L J,YUAN Y,WANG W J,et al. Zero-shot object detection based on multi-modal joint semantic perception[J]. Journal of Beijing University of Aeronautics and Astronautics,2024,50(2):368-375 (in Chinese) doi: 10.13700/j.bh.1001-5965.2022.0392

|
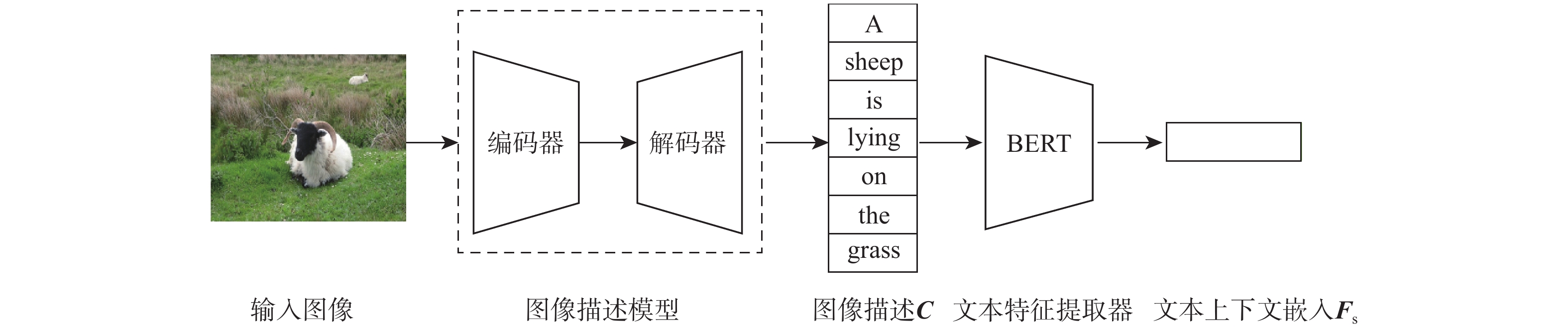
Existing zero-shot object detection maps visual features and category semantic embeddings of unseen items to the same space using semantic embeddings as guiding information, and then classifies the objects based on how close together the visual features and semantic embeddings are in the mapped space. However, due to the singleness of semantic information acquisition, the lack of reliable representation of visual information can easily confuse background information and unseen object information, making it difficult to indiscriminately align visual and semantic information. In order to effectively achieve zero-shot object detection, this paper uses the visual context module to capture the context information of visual features and the semantic optimization module to interactively fuse the text context and visual context information. By increasing the diversity of visual expressions, the model is able to perceive the discriminative semantics of the foreground. Experiments were conducted on two divided datasets of MS-COCO, and a certain improvement was achieved in the accuracy and recall rate of zero-shot target detection and generalized zero-shot target detection. The results proved the effectiveness of the proposed method.

| [1] |
TAN C, XU X, SHEN F. A survey of zero shot detection: Methods and applications[J]. Cognitive Robotics, 2021, 1: 159-167. doi: 10.1016/j.cogr.2021.08.001
|
| [2] |
BANSAL A, SIKKA K, SHARMA G, et al. Zero-shot object detection[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 384-400.
|
| [3] |
ZHANG L, WANG X, YAO L, et al. Zero-shot object detection via learning an embedding from semantic space to visual space[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence and 17th Pacific Rim International Conference on Artificial Intelligence. [S. l.]: IJCAI, 2020: 906-912.
|
| [4] |
GUPTA D, ANANTHARAMAN A, MAMGAIN N, et al. A multi-space approach to zero-shot object detection[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2020: 1209-1217.
|
| [5] |
LI Z, YAO L, ZHANG X, et al. Zero-shot object detection with textual descriptions[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto : AAAI Press, 2019: 8690-8697.
|
| [6] |
YANG X, TANG K, ZHANG H, et al. Auto-encoding scene graphs for image captioning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 10685-10694.
|
| [7] |
FENG Y, MA L, LIU W, et al. Unsupervised image captioning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 4125-4134.
|
| [8] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
|
| [9] |
WANG W, ZHENG V W, YU H, et al. A survey of zero-shot learning: Settings, methods, and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019, 10(2): 1-37.
|
| [10] |
ZHU P, WANG H, SALIGRAMA V. Don’t even look once: Synthesizing features for zero-shot detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 11693-11702.
|
| [11] |
RAHMAN S, KHAN S, BARNES N. Polarity loss for zero-shot object detection[EB/OL]. (2020-04-02)[2022-05-01]. https://arxiv.org/abs/1811.08982v2.
|
| [12] |
RAHMAN S, KHAN S, BARNES N. Improved visual-semantic alignment for zero-shot object detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 11932-11939.
|
| [13] |
ZHENG Y, HUANG R, HAN C, et al. Background learnable cascade for zero-shot object detection[C]//Proceedings of the Asian Conference on Computer Vision. Berlin: Springer, 2020: 107-123.
|
| [14] |
CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6154-6162.
|
| [15] |
GU X, LIN T Y, KUO W, et al. Zero-shot detection via vision and language knowledge distillation[EB/OL]. (2022-05-12)[2022-05-15]. https://arxiv.org/abs/2104.13921v1.
|
| [16] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]//Proceedings of the International Conference on Machine Learning. [S. l.]: PMLR, 2021: 8748-8763.
|
| [17] |
LI Y, SHAO Y, WANG D. Context-guided super-class inference for zero-shot detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 944-945.
|
| [18] |
GU Z, ZHOU S, NIU L, et al. Context-aware feature generation for zero-shot semantic segmentation[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1921-1929.
|
| [19] |
YANG Z, WANG Y, CHEN X, et al. Context-Transformer: Tackling object confusion for few-shot detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 12653-12660.
|
| [20] |
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. (2016-04-30)[2022-05-01]. https://arxiv.org/abs/1511.07122.
|
| [21] |
XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//Proceedings of the International Conference on Machine Learning. [S. l. ]: PMLR, 2015: 2048-2057.
|
| [22] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2022-05-01]. https://arxiv.org/abs/1409.1556.
|
| [23] |
BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[EB/OL]. (2016-05-19)[2022-05-01]. https://arxiv.org/abs/1409.0473v5.
|
| [24] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. doi: 10.1162/neco.1997.9.8.1735
|
| [25] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24)[2022-05-01]. https://arxiv.org/abs/1810.04805v2.
|
| [26] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010.
|
| [27] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
|
| [28] |
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 2117-2125.
|
| [29] |
MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. New York: ACM, 2013: 3111-3119.
|

Figures(3) / Tables(6)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@buaa.edu.cn
Supported by:
Beijing Renhe Information Technology Co., Ltd.






 DownLoad:
DownLoad: