



-
摘要:
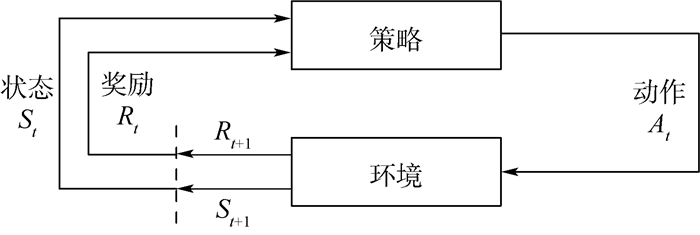
未来航空电子系统中将会更广泛地选择基于时间触发的通信机制进行信息传输,以保证信息交互的确定性。如何合理地进行时间触发通信调度设计是时间触发应用于航空电子互连系统的关键。针对时间触发调度的周期性任务,提出了一种基于强化学习的周期调度时刻表生成方法。首先,将流量调度任务转换为树搜索问题,使之具有强化学习所需要的马尔可夫特性;随后,利用基于神经网络的强化学习算法对调度表进行探索,不断缩短延迟时间以优化调度表,且在训练完成后,可以直接使用到消息分布相近的任务中。与使用Yices等可满足模理论(SMT)形式化求解时间触发调度表方法相比,所提方法不会出现无法判定的问题,能够保证时间触发调度设计结果的正确性和优化性。对于包含1 000条消息的大型网络,所提方法的计算速度为SMT方法的数十倍以上,并且调度生成消息的端到端延迟在SMT方法的1%以下,大大提高了消息传输的及时性。
Abstract:In the future, time-triggered communication mechanism will be more widely selected for information transmission to ensure the certainty of information interaction in avionics system. How to reasonably implement time-triggered communication scheduling design is the key to time-triggered application to avionics interconnection systems. For the periodic task of time-triggered scheduling, we proposed a method for generating periodic scheduling timetable based on reinforcement learning. Firstly, the traffic scheduling task is transformed into a tree search problem, which has the Markov characteristics needed for reinforcement learning. Then, the reinforcement learning algorithm based on neural network is used to explore the schedule, and the waiting time is shortened to optimize the schedule. As the training is completed, the model can be directly used in tasks with similar message distribution. Compared with the method, e.g. Yices, which uses the satisfiability modulo theories (SMT) to solve the time-triggered schedule, the proposed method does not cause undetermined problem, and can guarantee the correctness and optimization of the time-triggered scheduling design results. For a large network with 1 000 messages, the calculation speed of the proposed method is dozens of times faster than that of the SMT, and meanwhile, the end-to-end delay of the generated message by scheduling is less than 1% of that of the SMT, which greatly improves the timeliness of message transmission.
-
Key words:
- time-triggered /
- scheduling method /
- reinforcement learning /
- tree search /
- offset time
-

图 5 各项变化的平均端到端延迟收敛情况
Figure 5. Average end-to-end delay until convergence for each change

图 6 增加6,60,120条消息的平均端到端延迟收敛情况
Figure 6. Average end-to-end delay until convergence of adding 6, 60, 120 frames
表 1 各方法调度结果
Table 1. Each method scheduling results
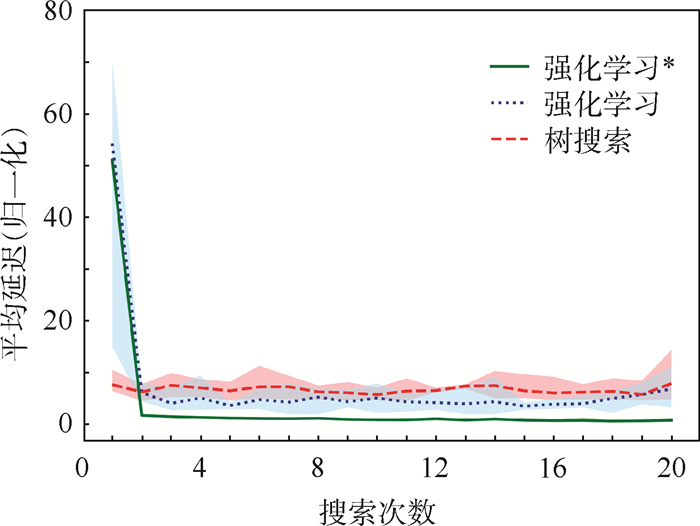
方法 单次计算时间/s 平均延迟(归一化) SMT 265.00 1355.30 树搜索 2.17 4.10 强化学习 5.03 1.70 强化学习* 4.29 0.75 注:*表示使用模仿学习进行预训练。  下载: 导出CSV
下载: 导出CSV
表 2 4种变化详细操作
Table 2. Detailed operation of four change methods
编号倍数 变化1 变化2 变化3 变化4 2 1.1 1.1 0.8 0.8 3 1.1 1.2 1.2 1.2 5 0.9 1.1 1.1 1.3 7 1.1 1.1 0.9 0.9 11 0.9 1.2 1.2 1.2
下载: 导出CSV
表 3 4种变化后端到端延迟结果
Table 3. End-to-end delay results of four variations
方法 变化1 变化2 变化3 变化4 SMT 1360.2 1365.6 1284.2 1324.1 树搜索 4.4 5.5 4.5 4.4 强化学习 2.3 2.1 2.1 2.1 强化学习* 0.74 0.65 0.61 0.71
下载: 导出CSV
表 4 4种变化后收敛速度
Table 4. Convergence speed of four variations
方法 收敛速度/s 变化1 变化2 变化3 变化4 SMT 树搜索 强化学习 36 58 33 44 强化学习* 43 63 40 56
下载: 导出CSV
表 5 4种变化后单次运行速度
Table 5. One-time running speed of four variations
方法 运行速度/s 变化1 变化2 变化3 变化4 SMT 281 287 267 274 树搜索 2.85 3.21 2.45 2.87 强化学习 5.12 6.45 5.58 6.25 强化学习* 4.32 5.26 4.97 5.07
下载: 导出CSV
表 6 3种增加消息详细操作
Table 6. Detailed operation of three adding methods
操作 增加1 增加2 增加3 增加信息条数 6 60 120 总技术延时 8019000 8478000 8988000
下载: 导出CSV
表 7 增加消息后端到端延迟结果
Table 7. End-to-end delay results after adding frames
方法 增加1 增加2 增加3 SMT 1352.3 1586.7 1324.6 树搜索 2.5 2.9 4.5 强化学习 1.7 1.6 1.4 强化学习* 0.68 0.86 0.85
下载: 导出CSV
表 8 增加消息后收敛速度
Table 8. Convergence speed after adding frames
方法 收敛速度/s 增加1 增加2 增加3 SMT 树搜索 强化学习 35 50 58 强化学习* 32 41 48
下载: 导出CSV
表 9 增加消息后单次运行速度
Table 9. One-time running speed after adding frames
方法 运行速度/s 增加1 增加2 增加3 SMT 268 358 731 树搜索 2.24 2.34 2.52 强化学习 5.05 5.87 6.43 强化学习* 4.56 5.15 6.37
下载: 导出CSV
-
[1] 王国庆, 谷青范, 王淼, 等.新一代综合化航空电子系统构架技术研究[J].航空学报, 2014, 35(6):1473-1486. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=hkxb201406002WANG G Q, GU Q F, WANG M, et al.Research on architecture technology for new generation integrated avionics system[J].Acta Aeronautica et Aastronautica Sinica, 2014, 35(6):1473-1486(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=hkxb201406002 [2] 熊华钢, 王中华.先进航空电子综合技术[M].北京:国防工业出版社, 2009:2-13.XIONG H G, WANG Z H.Advanced avionics integration techniques[M].Beijing:National Defense Industry Press, 2009:2-13(in Chinese). [3] STEINER W.An evaluation of SMT-based schedule synthesis for time-triggered multi-hop networks[C]//Real-Time Systems Symposium.Piscataway, NJ: IEEE Press, 2011: 375-384. [4] 孔韵雯, 李峭, 熊华钢, 等.片间综合化互连时间触发通信调度方法[J].航空学报, 2018, 39(2):321590. http://d.old.wanfangdata.com.cn/Periodical/hkxb201802023KONG Y W, LI Q, XIONG H G, et al.Time-triggered communication scheduling method for off-chip integrated interconnection[J].Acta Aeronautica et Astronautica Sinica, 2018, 39(2):321590(in Chinese). http://d.old.wanfangdata.com.cn/Periodical/hkxb201802023 [5] 李炳乾, 王勇, 谭小虎, 等.基于混合遗传算法的TTE静态调度表生成设计[J].电子技术应用, 2016, 42(10):96-99. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=dzjsyy201610029LI B Q, WANG Y, TAN X H, et al.Hybrid-GA based static schedule generation for time-triggered Ethernet[J].Application of Electronic Technique, 2016, 42(10):96-99(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=dzjsyy201610029 [6] RUMELHART D E, HINTON G E, WILLIAMS R J.Learning representations by back-propagating errors[J].Nature, 1986, 323:533-536. doi: 10.1038/323533a0 [7] KHALIL E B, DAI H, ZHANG Y, et al.Learning combinatorial optimization algorithms over graphs[C]//Neural Information Processing Systems, 2017: 6348-6358. [8] SILVER D, SCHRITTWIESER J, SIMONYAN K, et al.Mastering the game of Go without human knowledge[J].Nature, 2017, 550(7676):354-359. doi: 10.1038/nature24270 [9] GAL D, KRISHNAMURTHY D, MATEJ V, et al.Safe exploration in continuous action spaces[EB/OL].(2018-01-26)[2019-01-01].https://arxiv.org/abs/1801.08757. [10] KOCSIS L, SZEPESVARI C.Bandit based monte-carlo planning[C]//European Conference on Machine Learning, 2006: 282-293. [11] CRACIUNAS S S, OLIVER R S.SMT-based task-and network-level static schedule generation for time-triggered networked systems[C]//International Conference on Real-Time Networks and Systems, 2014: 45-54. [12] SCHULMAN J, LEVINE S, ABBEEL P, et al.Trust region policy optimization[EB/OL].(2015-02-19)[2019-01-01].https://arxiv.org/ahs/1502.05477. [13] SILVER D, LEVER G, HEESS N, et al.Deterministic policy gradient algorithms[C]//International Conference on Machine Learning, 2014: 387-395. [14] SCHULMAN J, WOLSKI F, DHARIWAL P, et al.Proximal policy optimization algorithms[EB/OL].(2017-07-20)[2019-01-01].https://arxiv.org/abs/1707.06347. [15] KORF R E.Depth-first iterative-deepening:An optimal admissible tree search[J].Artificial Intelligence, 1985, 27(1):97-109. [16] ARINC.Aircraft data network, Part 7.Avionics full-duplex switched ethernet network: ARINC 664P7[R].Washington, D.C.: ARINC, 2005. -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 865
- HTML全文浏览量: 206
- PDF下载量: 393
- 被引次数: 0
