


当期目录
2026年 第52卷 第7期

 下载 (39597)
下载 (39597) 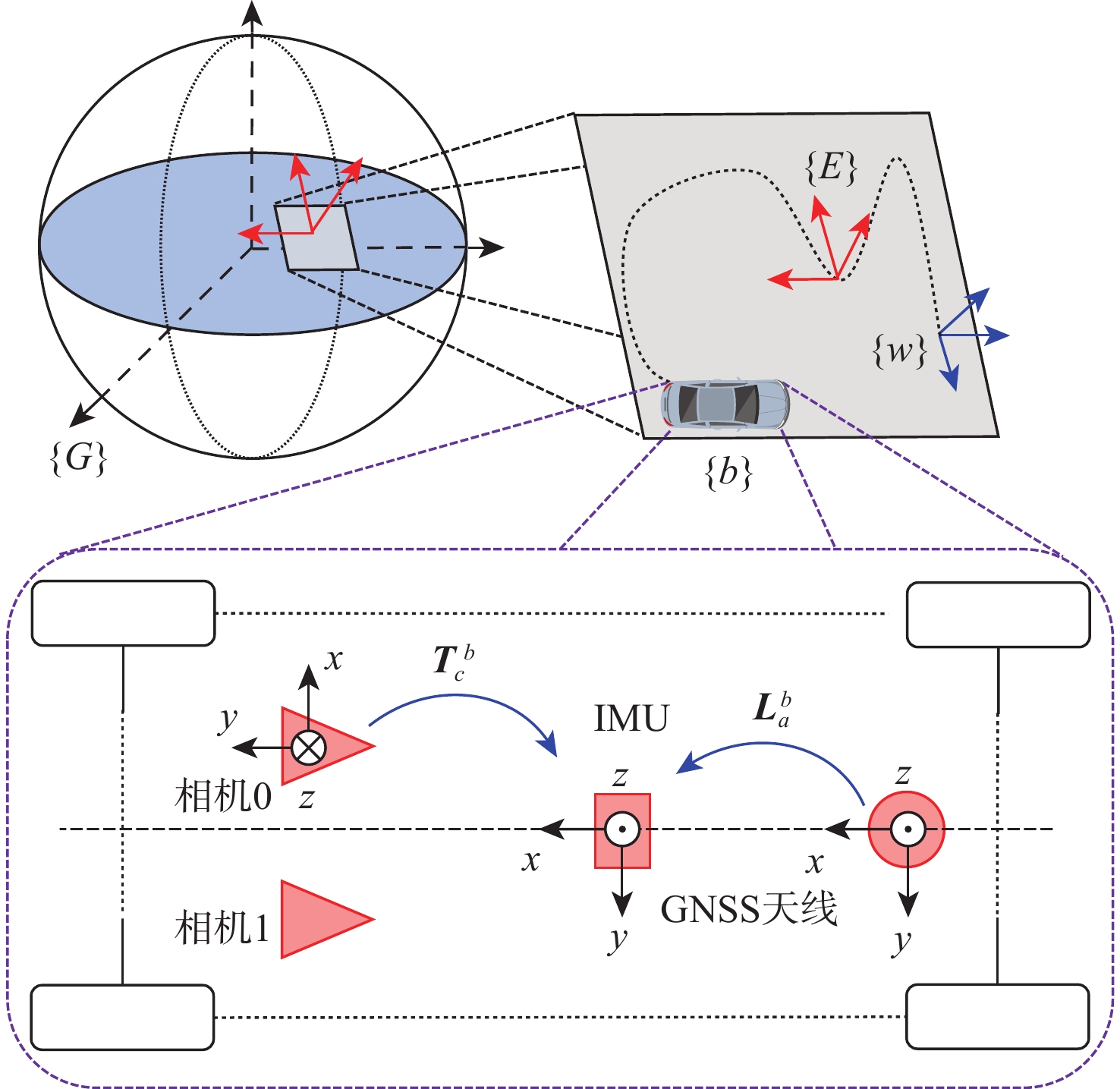
2026,
52(7): 2229-2238. doi: 10.13700/j.bh.1001-5965.2024.0363
 浏览量
浏览量  施引文献
施引文献
摘要:










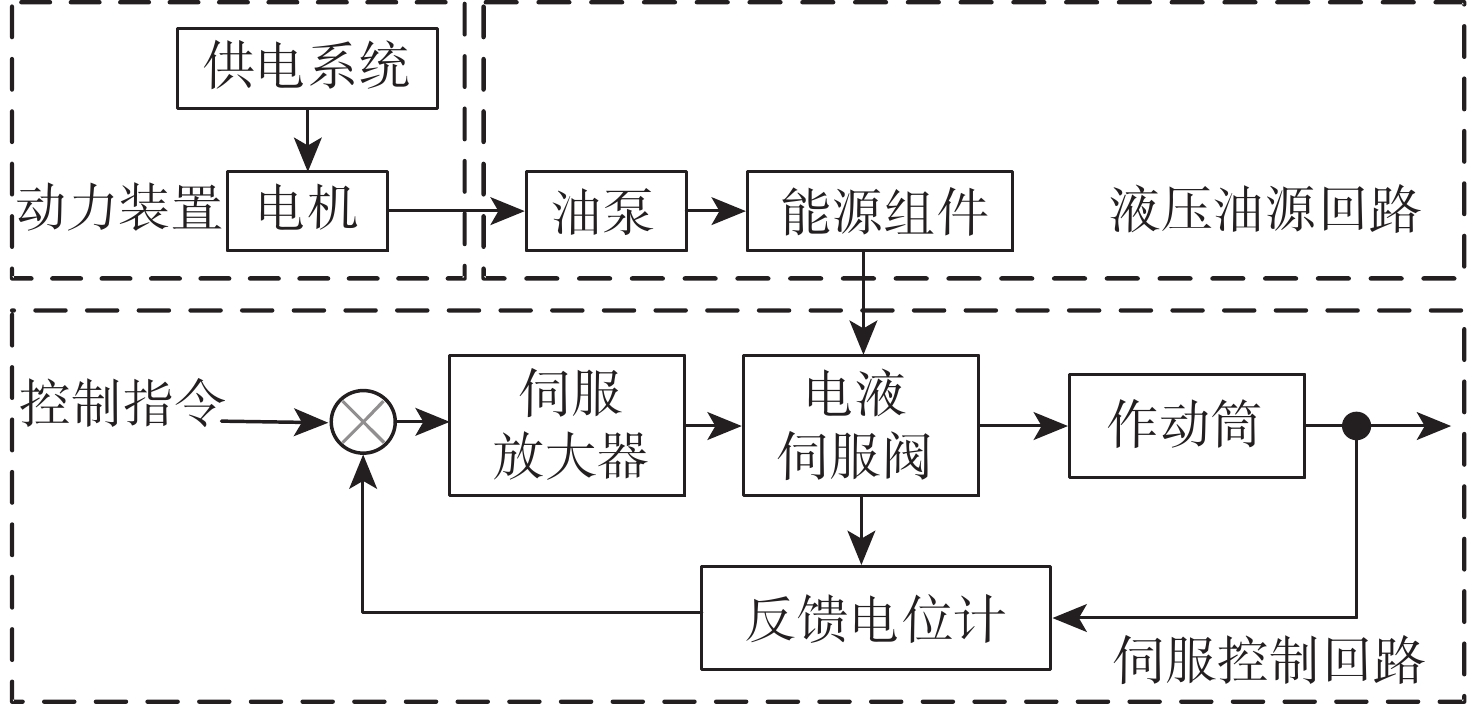
2026,
52(7): 2239-2250. doi: 10.13700/j.bh.1001-5965.2024.0317
摘要:












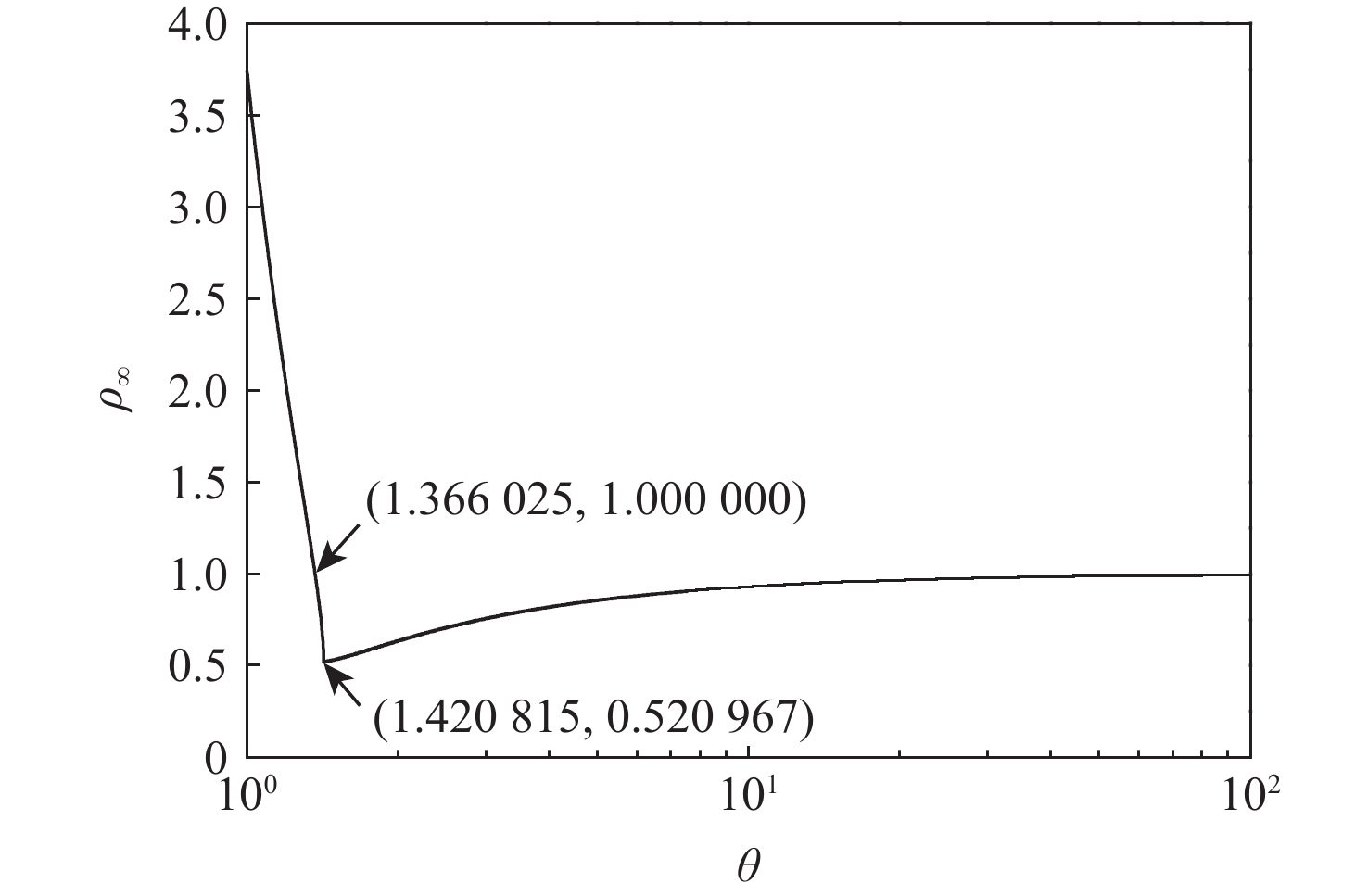
2026,
52(7): 2251-2259. doi: 10.13700/j.bh.1001-5965.2024.0382
摘要:





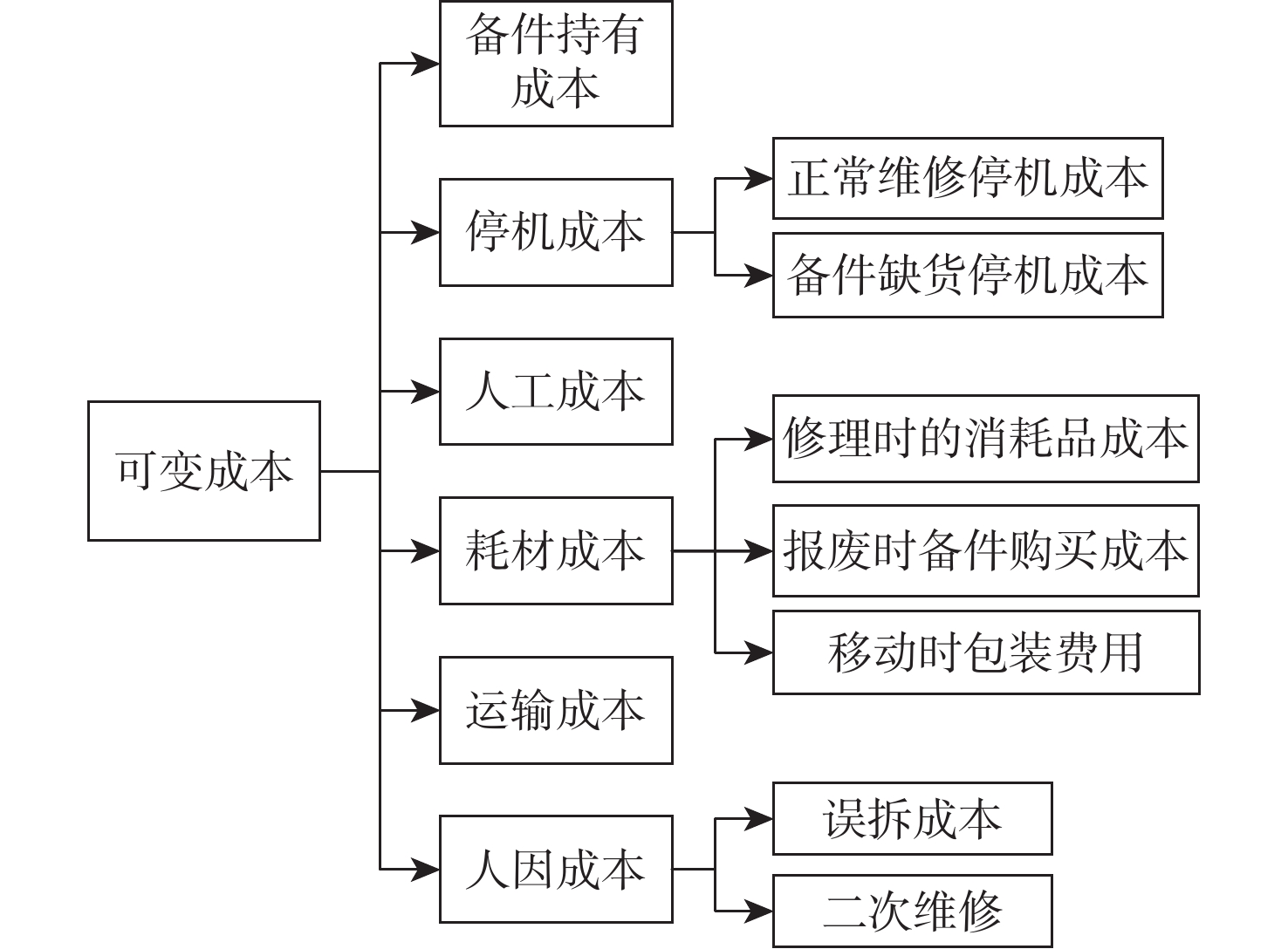
2026,
52(7): 2260-2268. doi: 10.13700/j.bh.1001-5965.2024.0359
摘要:


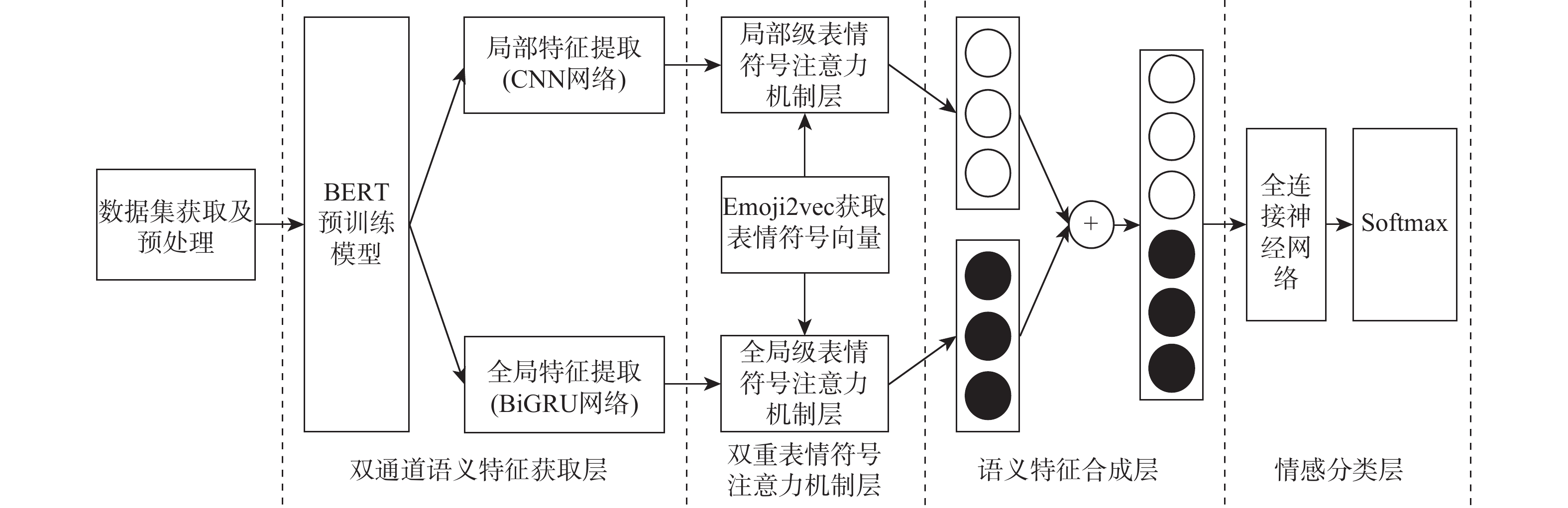
2026,
52(7): 2269-2280. doi: 10.13700/j.bh.1001-5965.2024.0318
摘要:








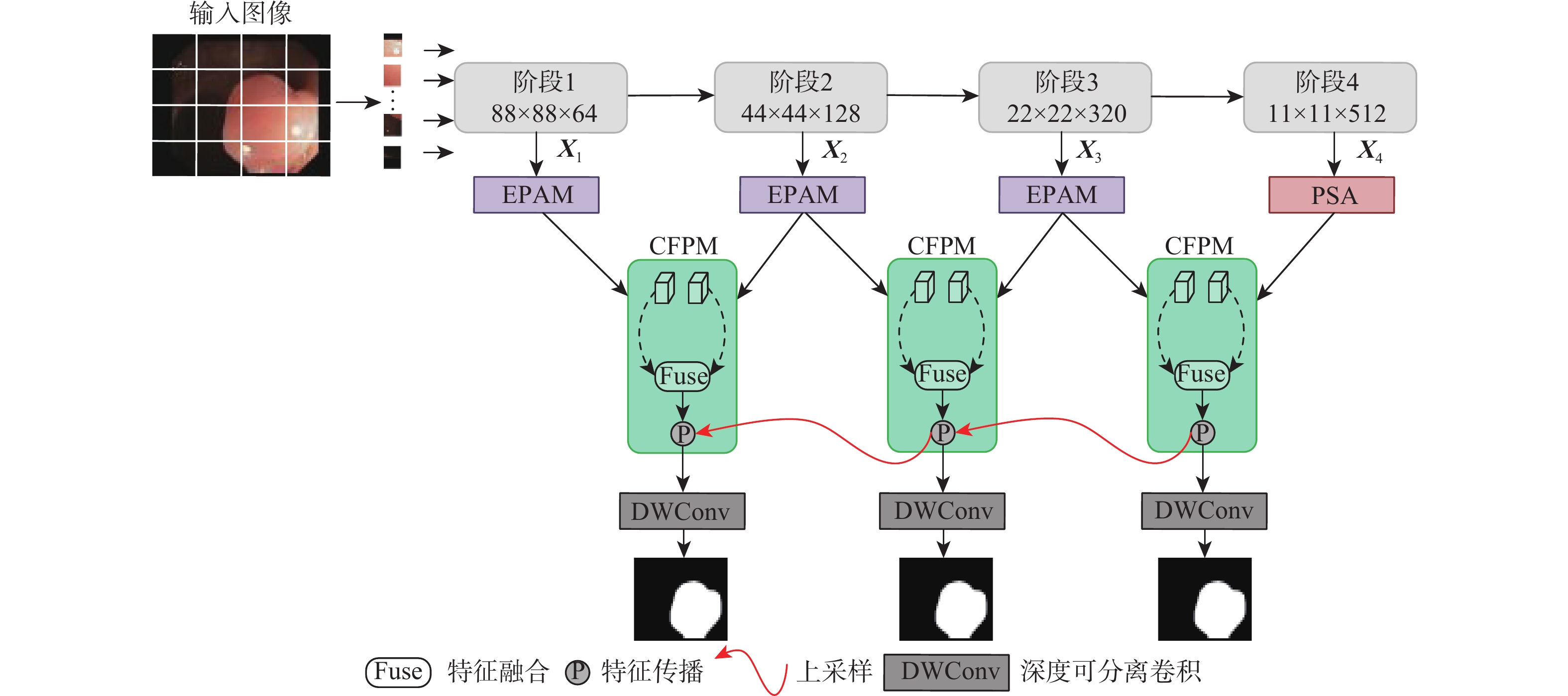
2026,
52(7): 2281-2292. doi: 10.13700/j.bh.1001-5965.2024.0331
摘要:

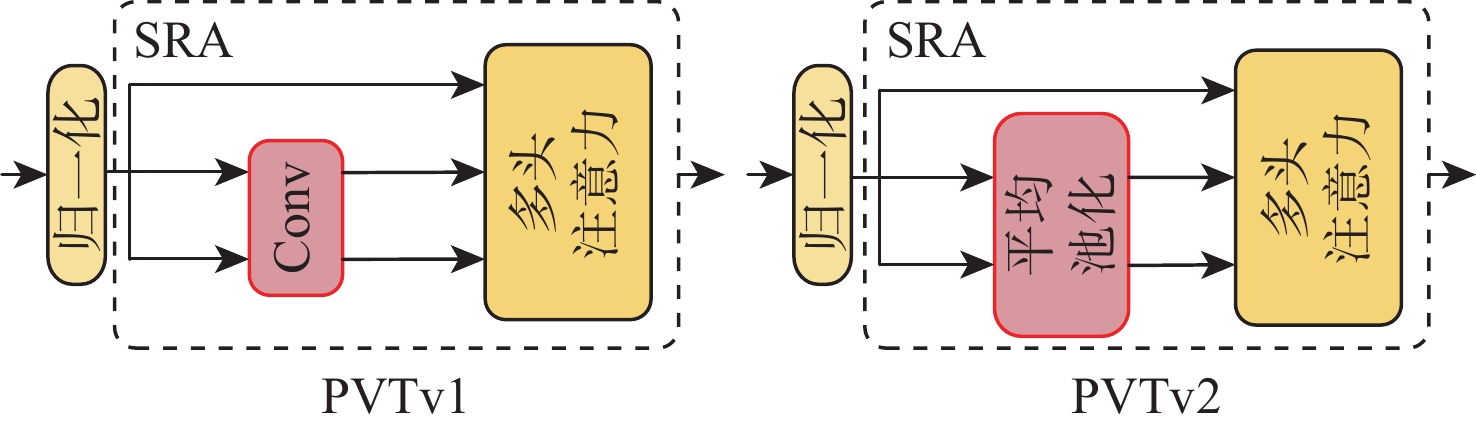
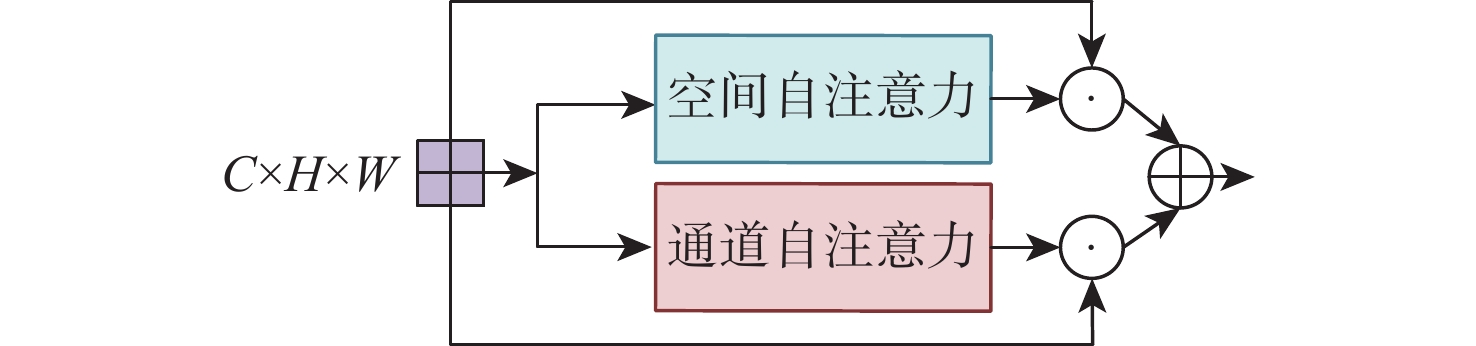
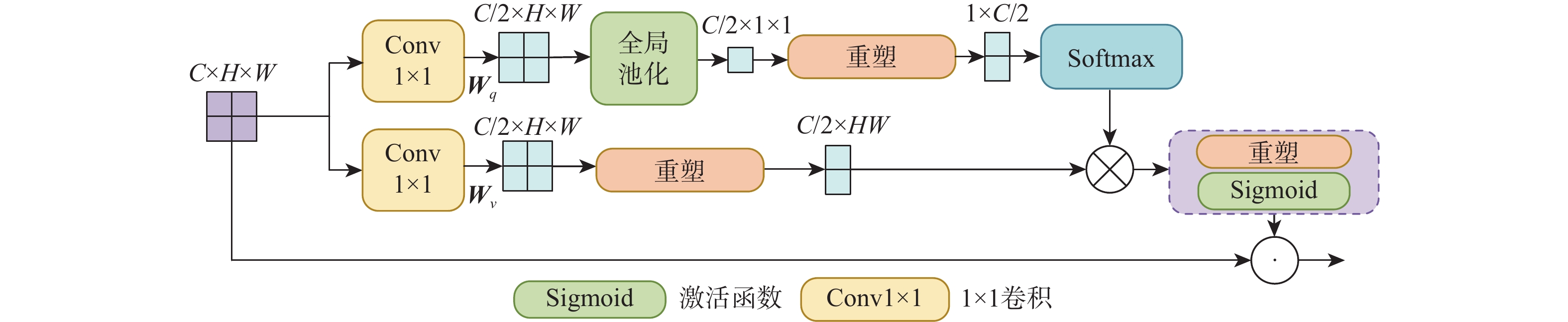
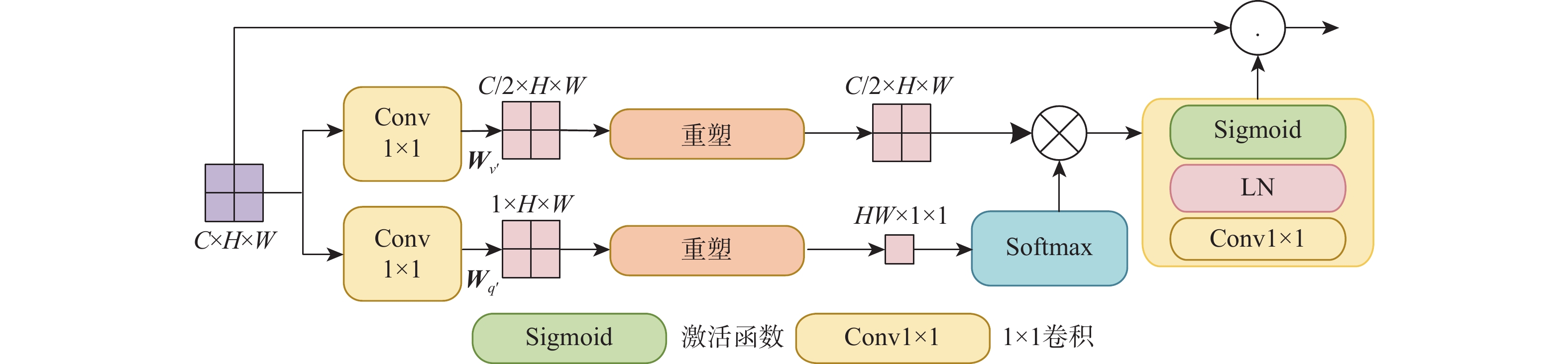
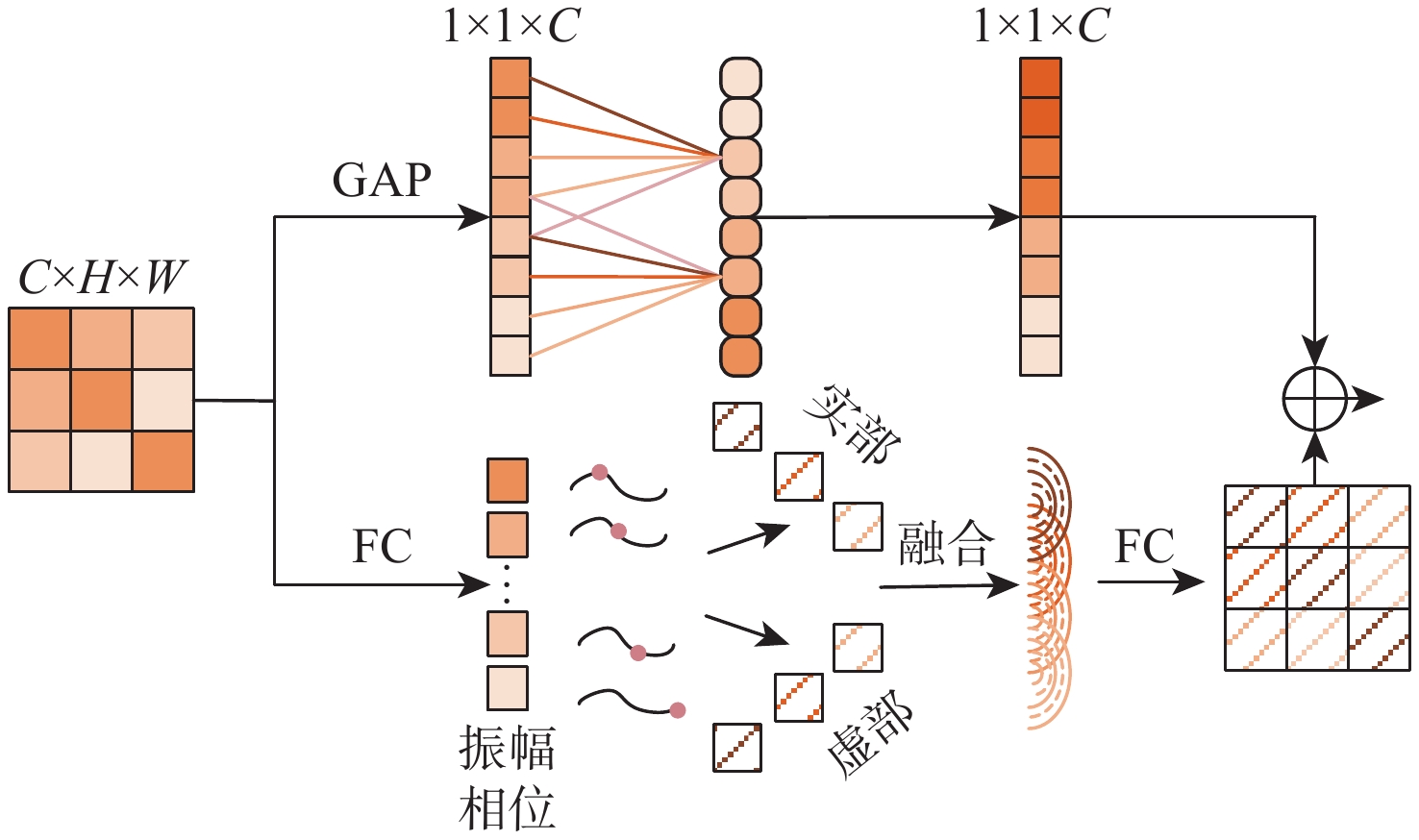
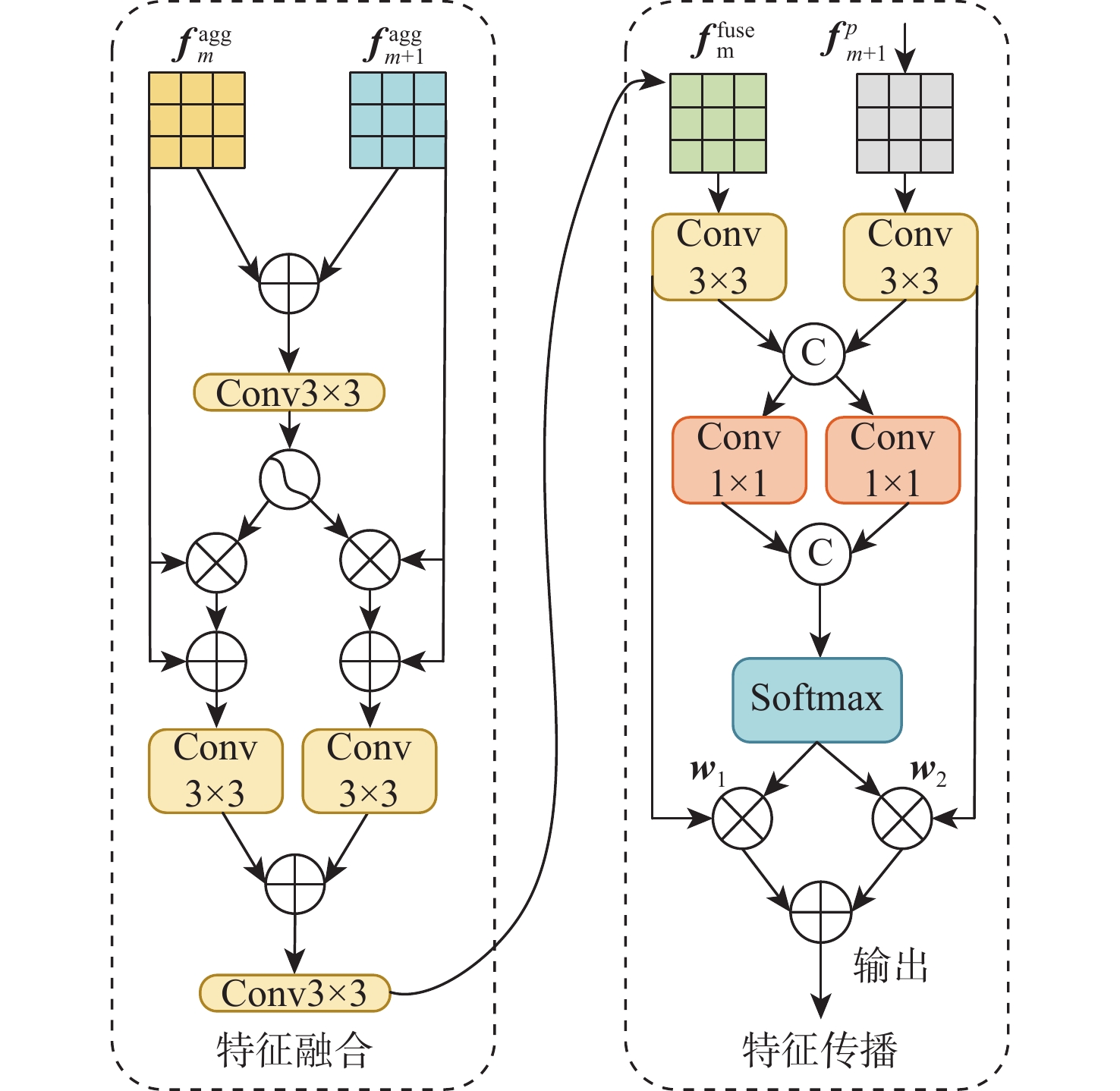
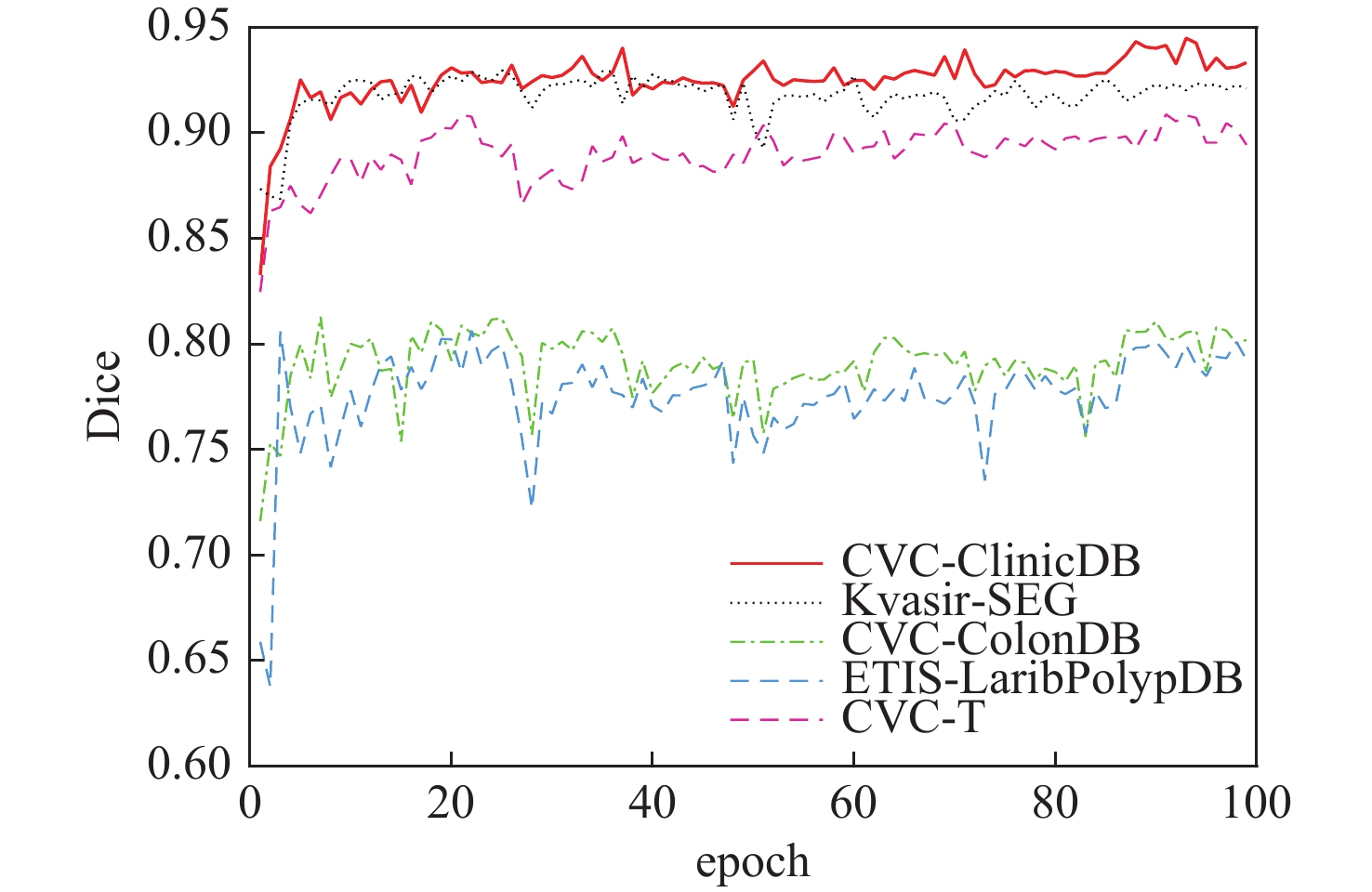
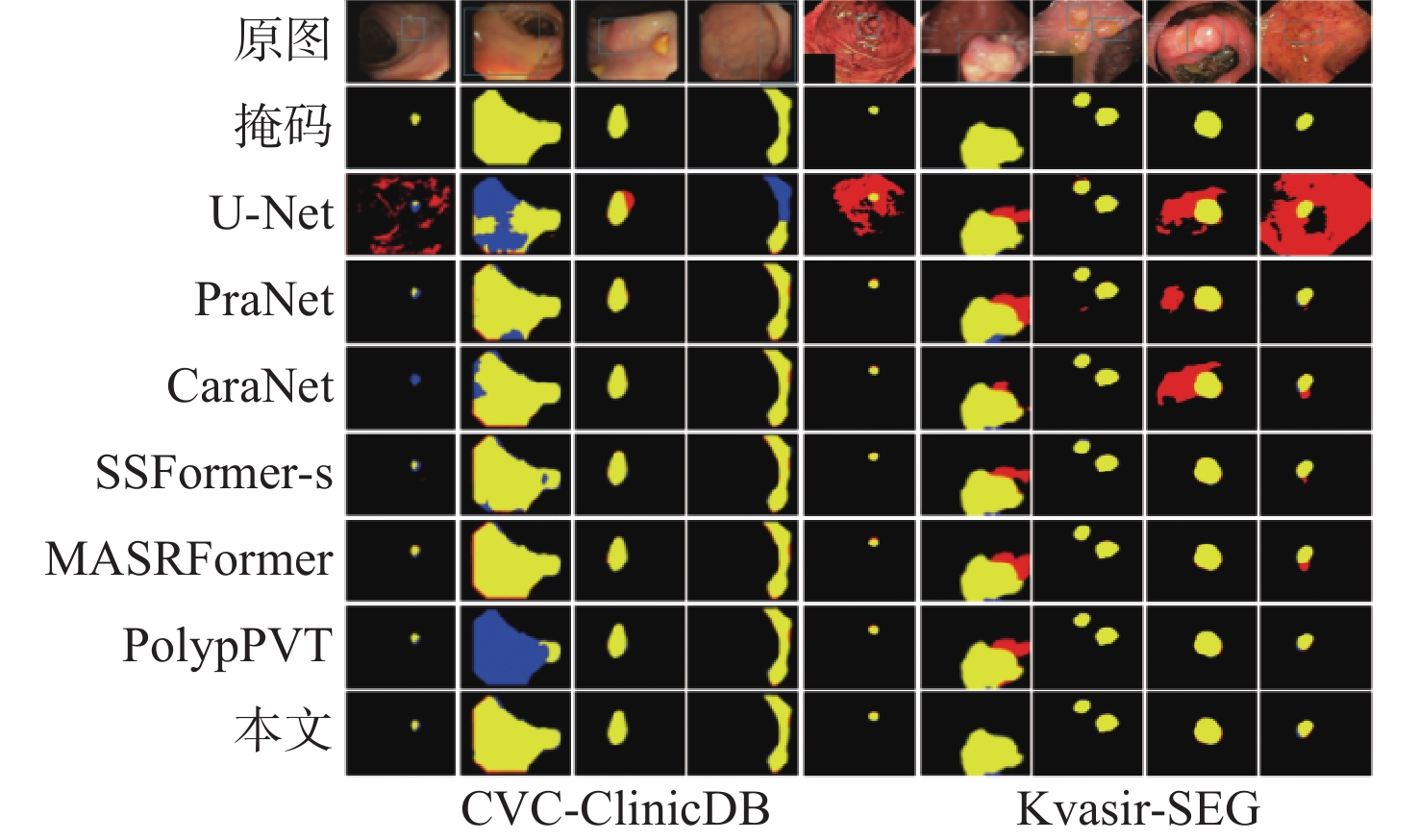
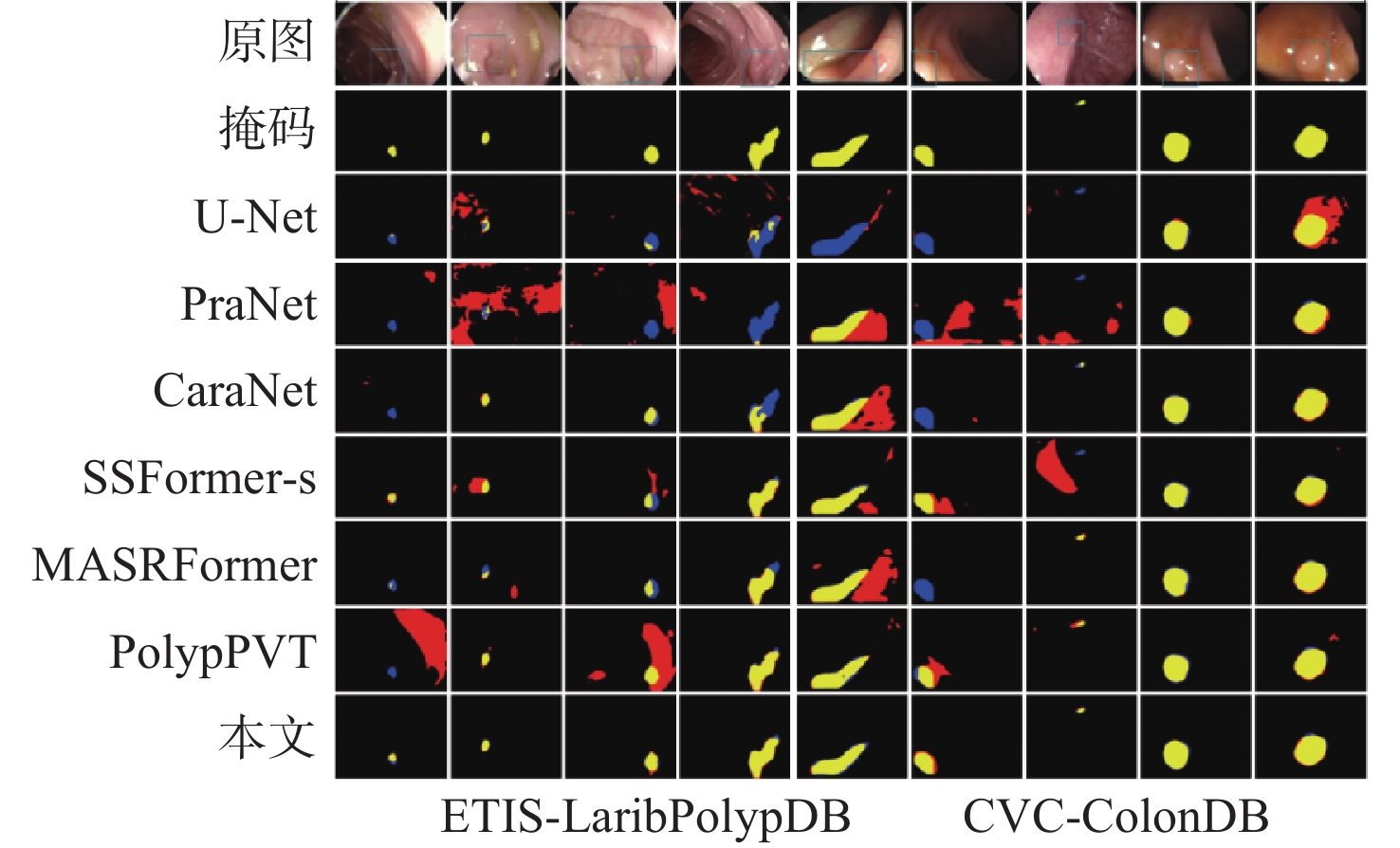

2026,
52(7): 2293-2302. doi: 10.13700/j.bh.1001-5965.2024.0350
摘要:









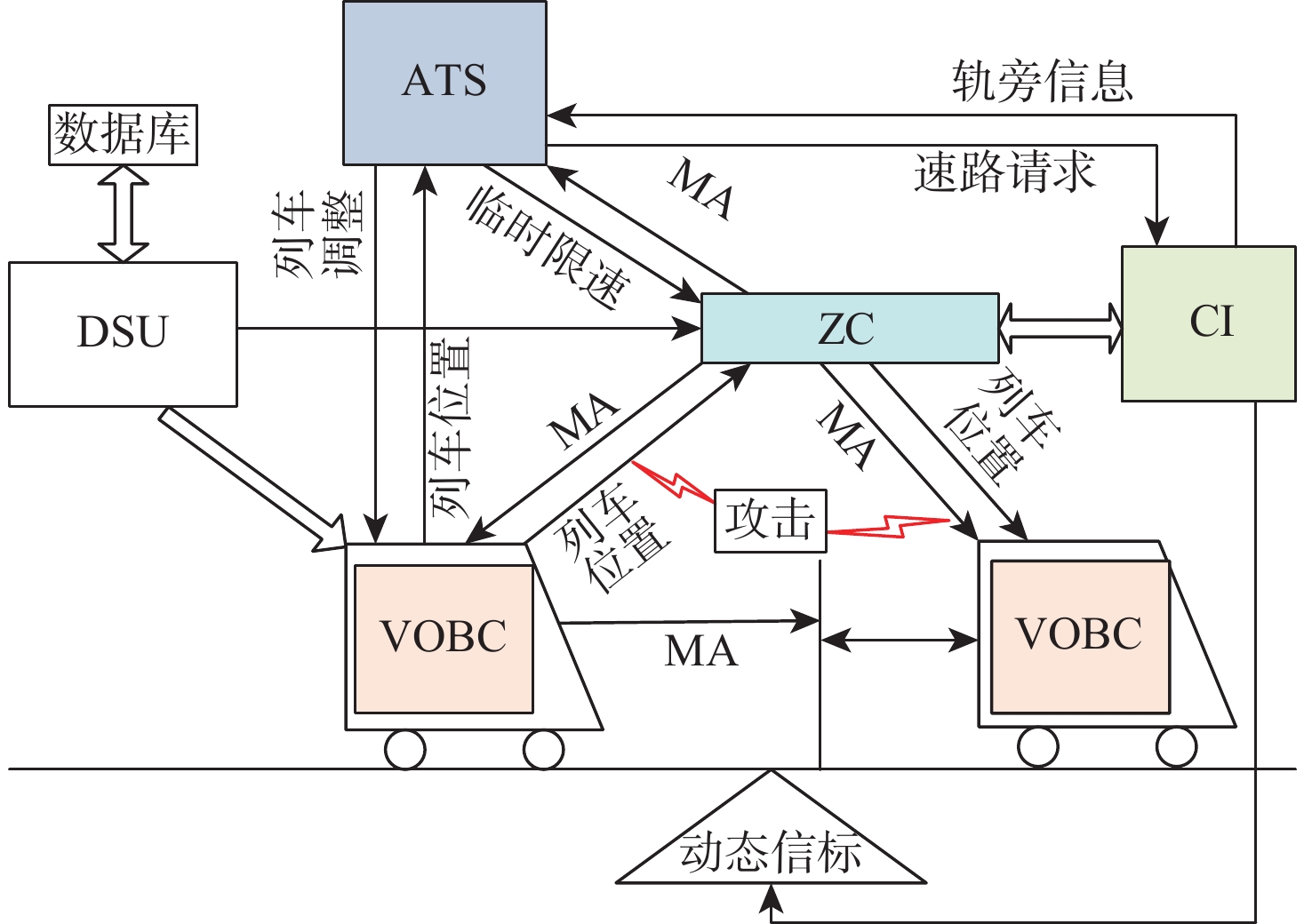
2026,
52(7): 2303-2315. doi: 10.13700/j.bh.1001-5965.2025.0546
摘要:









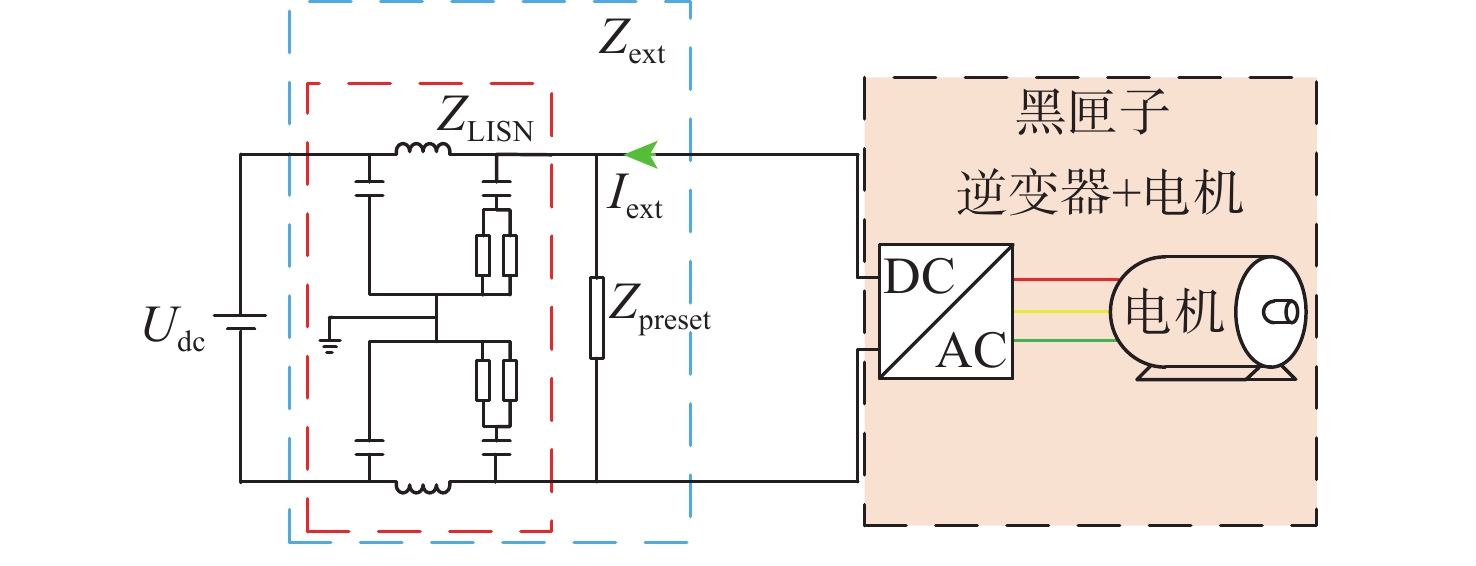
2026,
52(7): 2316-2326. doi: 10.13700/j.bh.1001-5965.2024.0342
摘要:



















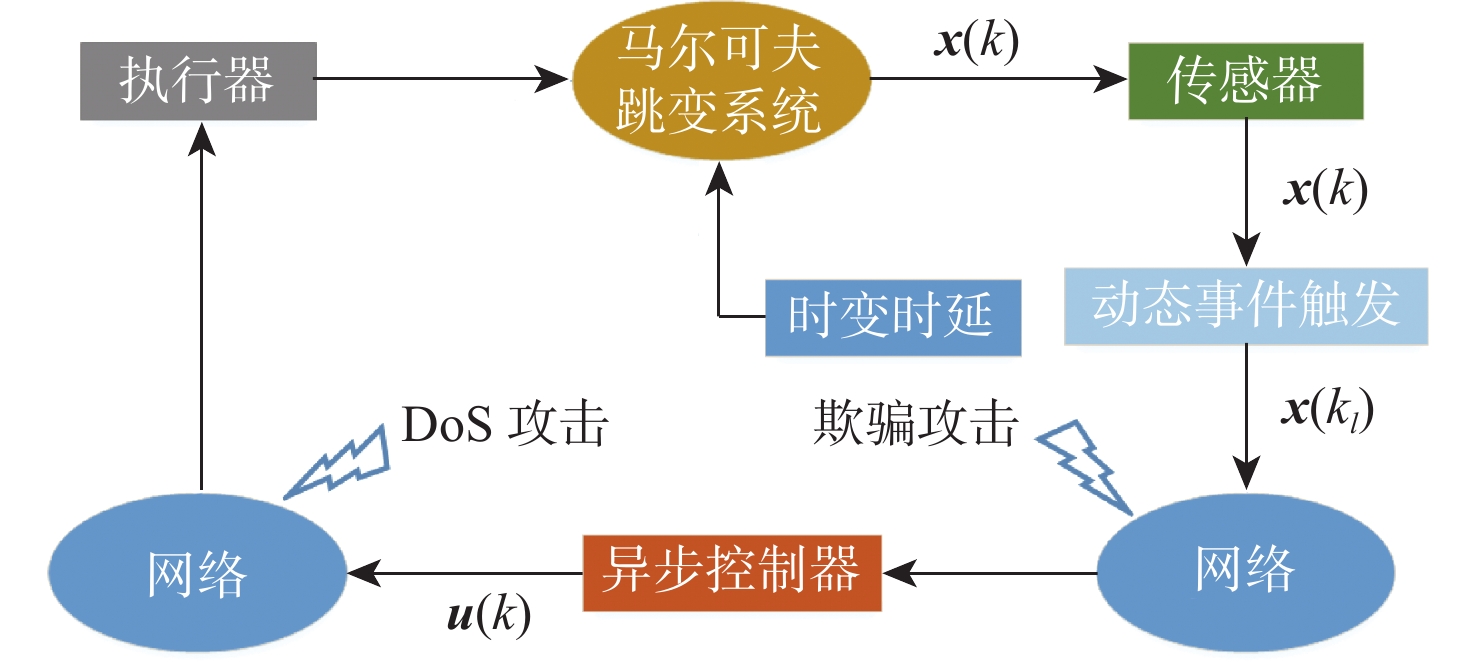
2026,
52(7): 2327-2338. doi: 10.13700/j.bh.1001-5965.2024.0349
摘要:








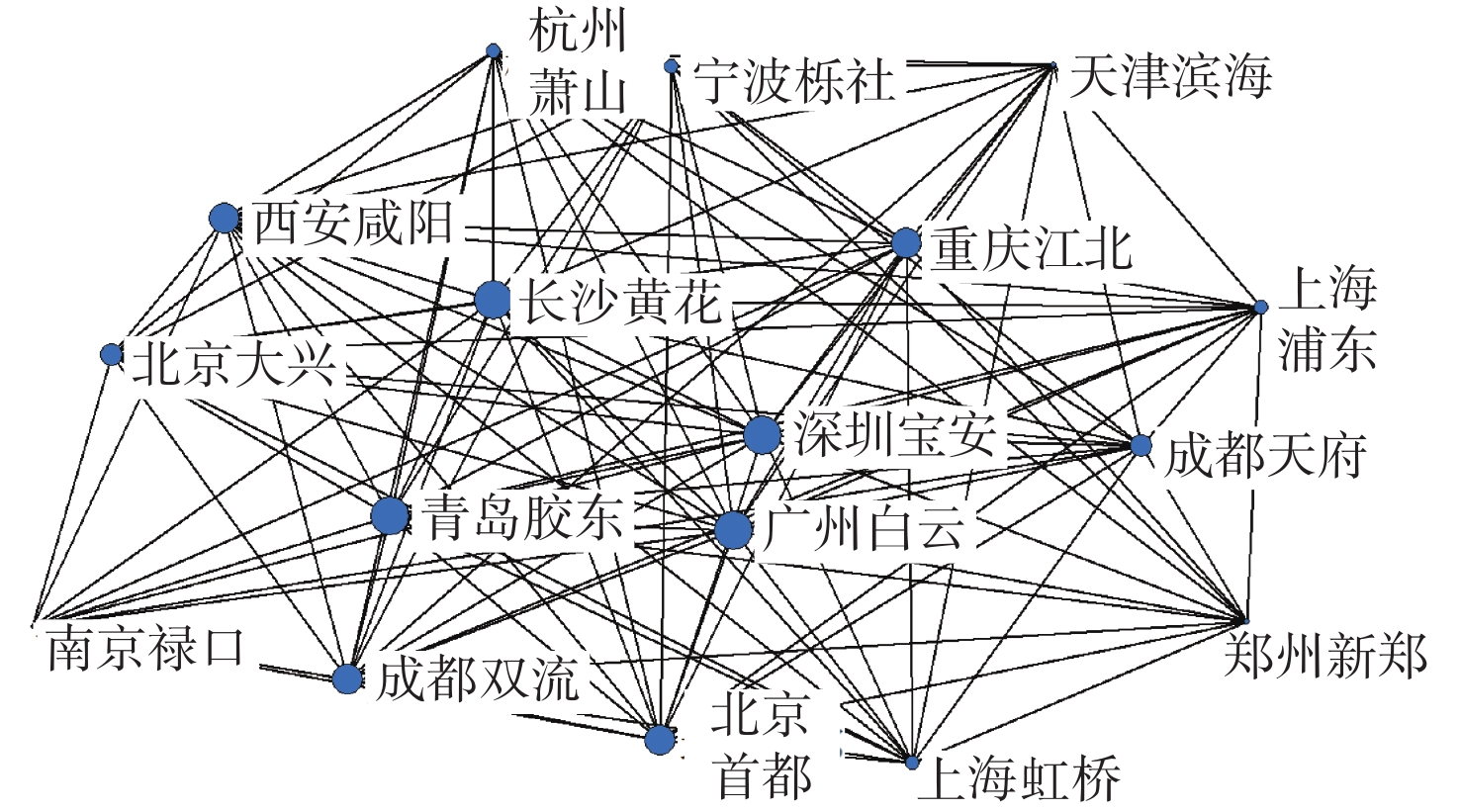
2026,
52(7): 2339-2351. doi: 10.13700/j.bh.1001-5965.2024.0396
摘要:














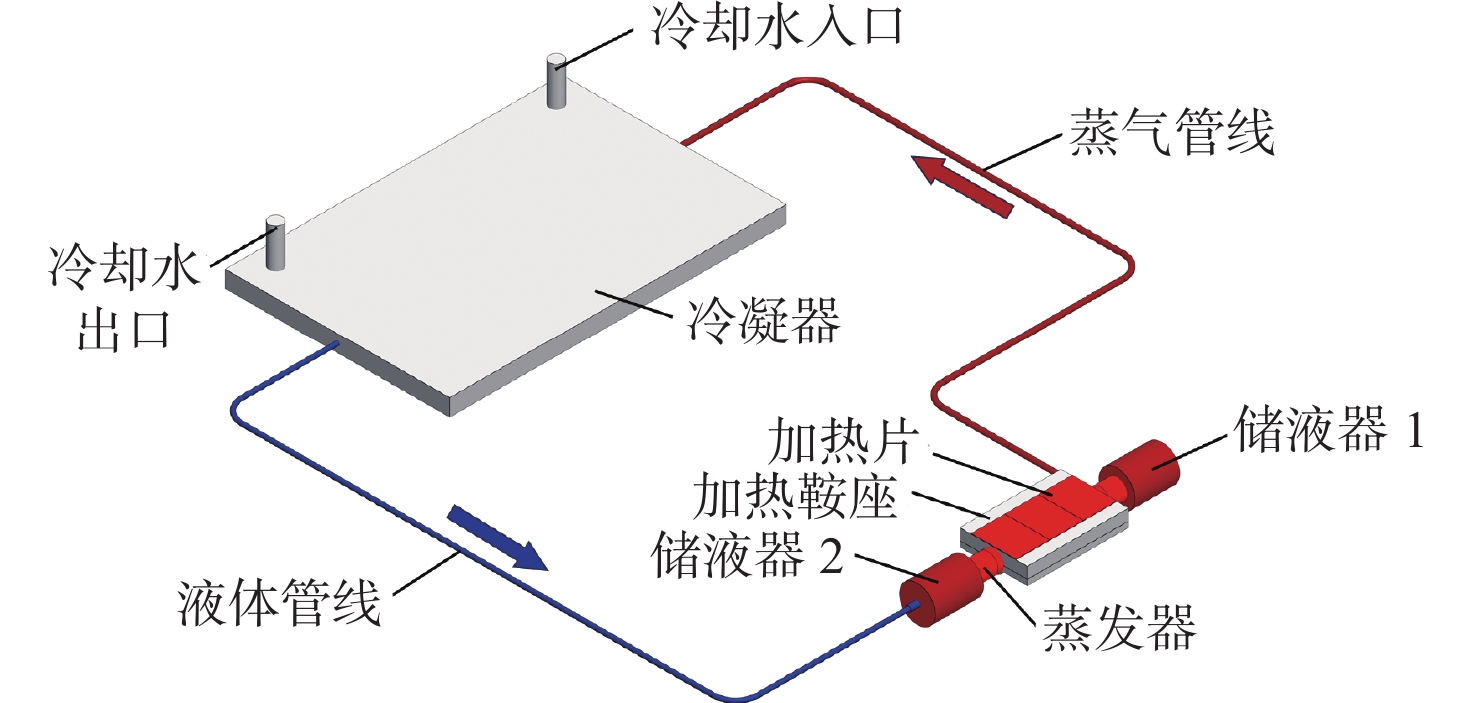
2026,
52(7): 2352-2358. doi: 10.13700/j.bh.1001-5965.2024.0397
摘要:












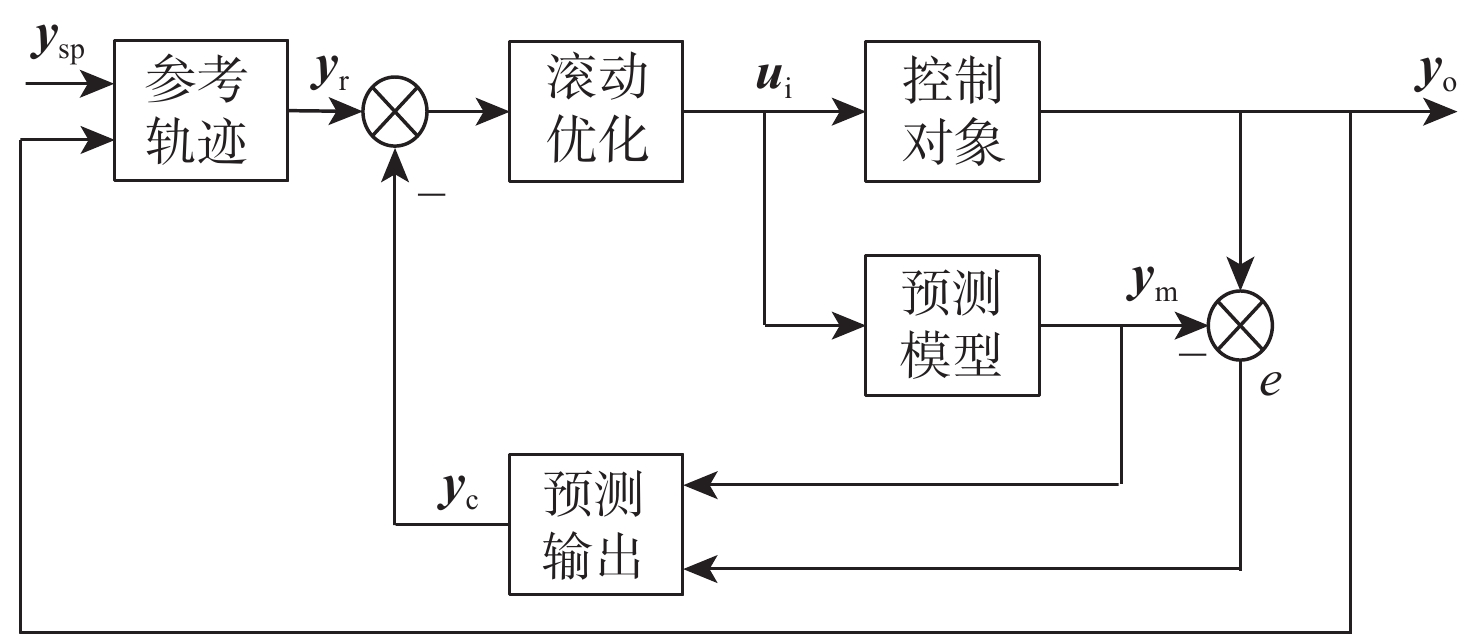
2026,
52(7): 2359-2370. doi: 10.13700/j.bh.1001-5965.2025.0443
摘要:

















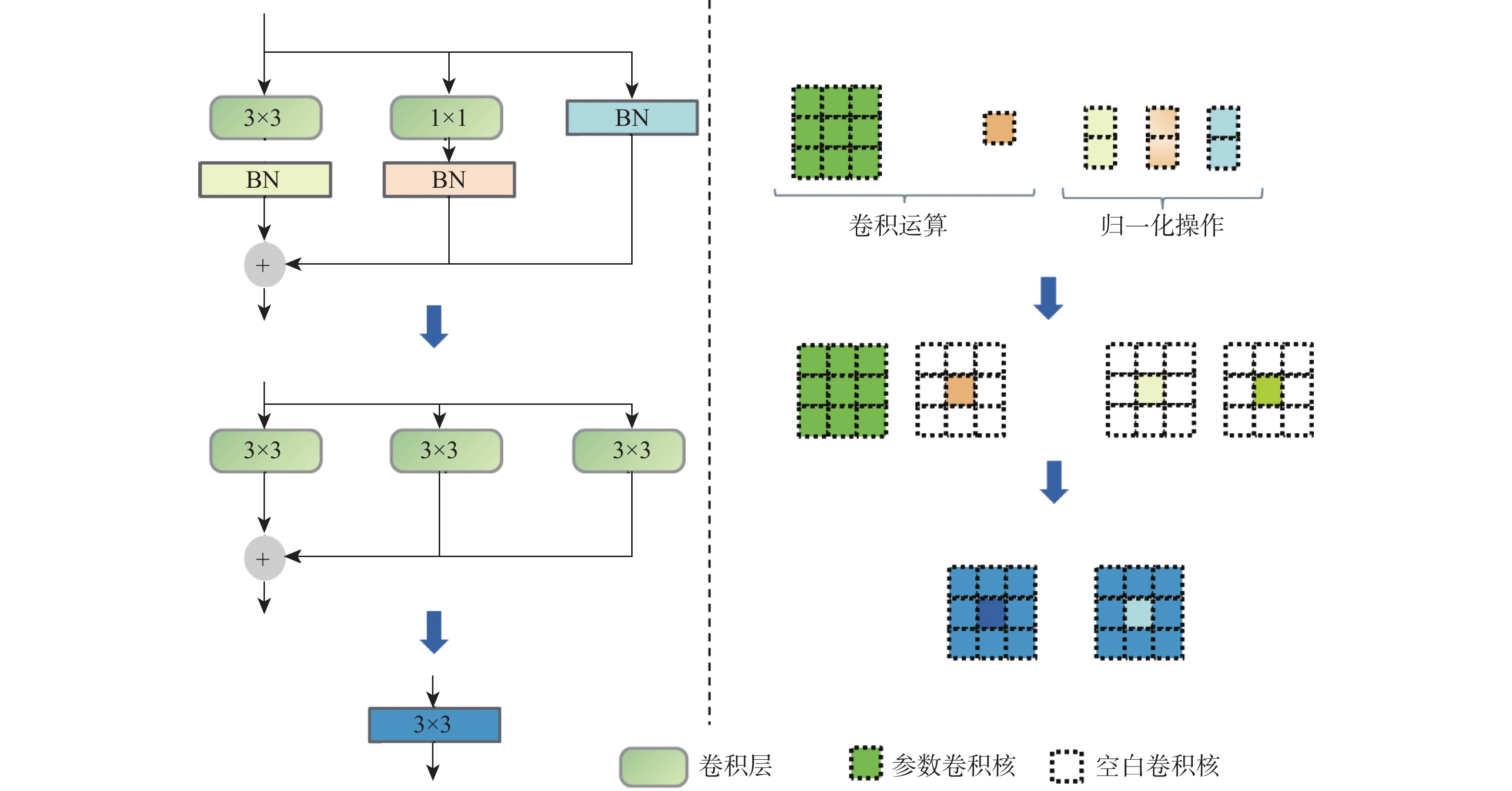
2026,
52(7): 2371-2382. doi: 10.13700/j.bh.1001-5965.2024.0320
摘要:








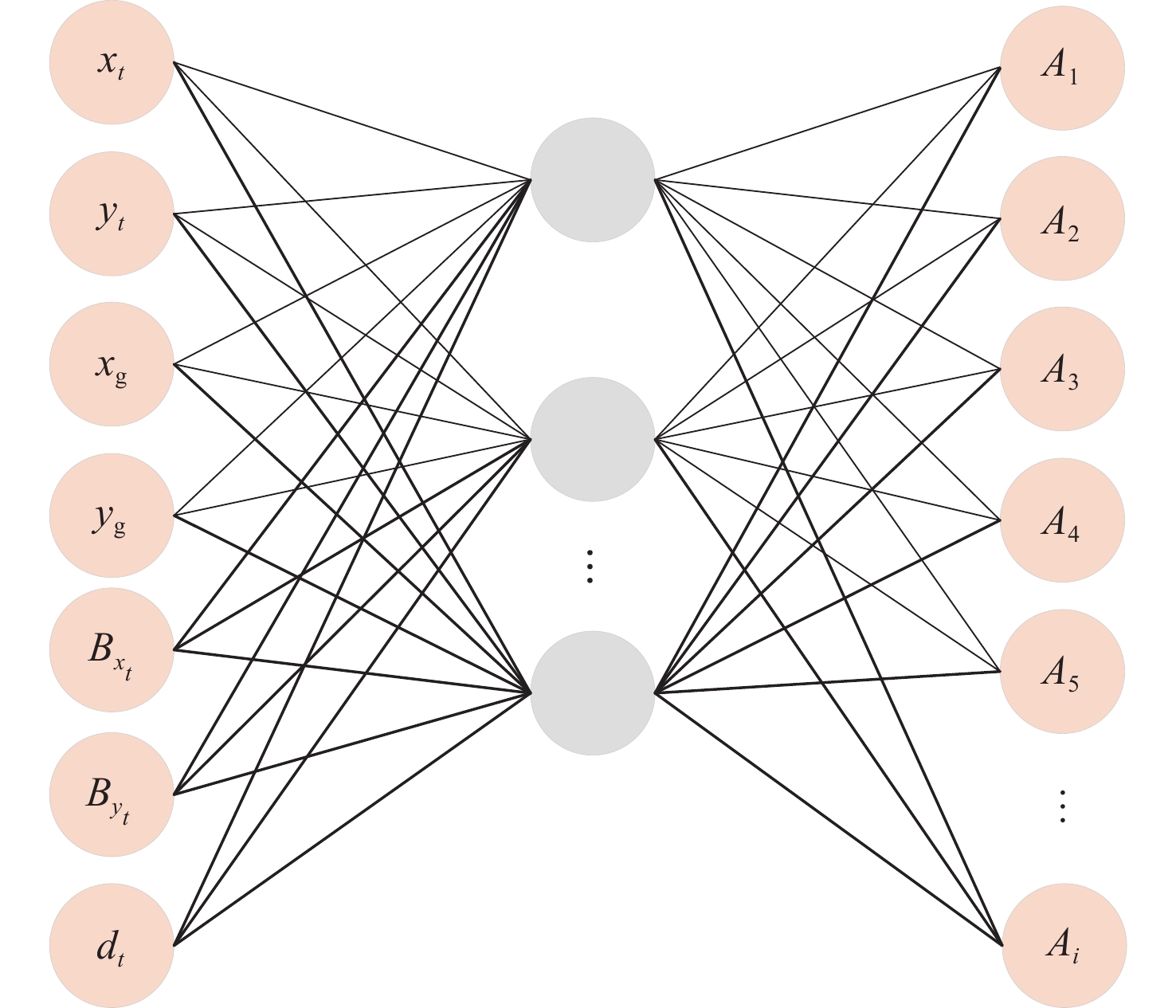
2026,
52(7): 2383-2392. doi: 10.13700/j.bh.1001-5965.2024.0340
摘要:










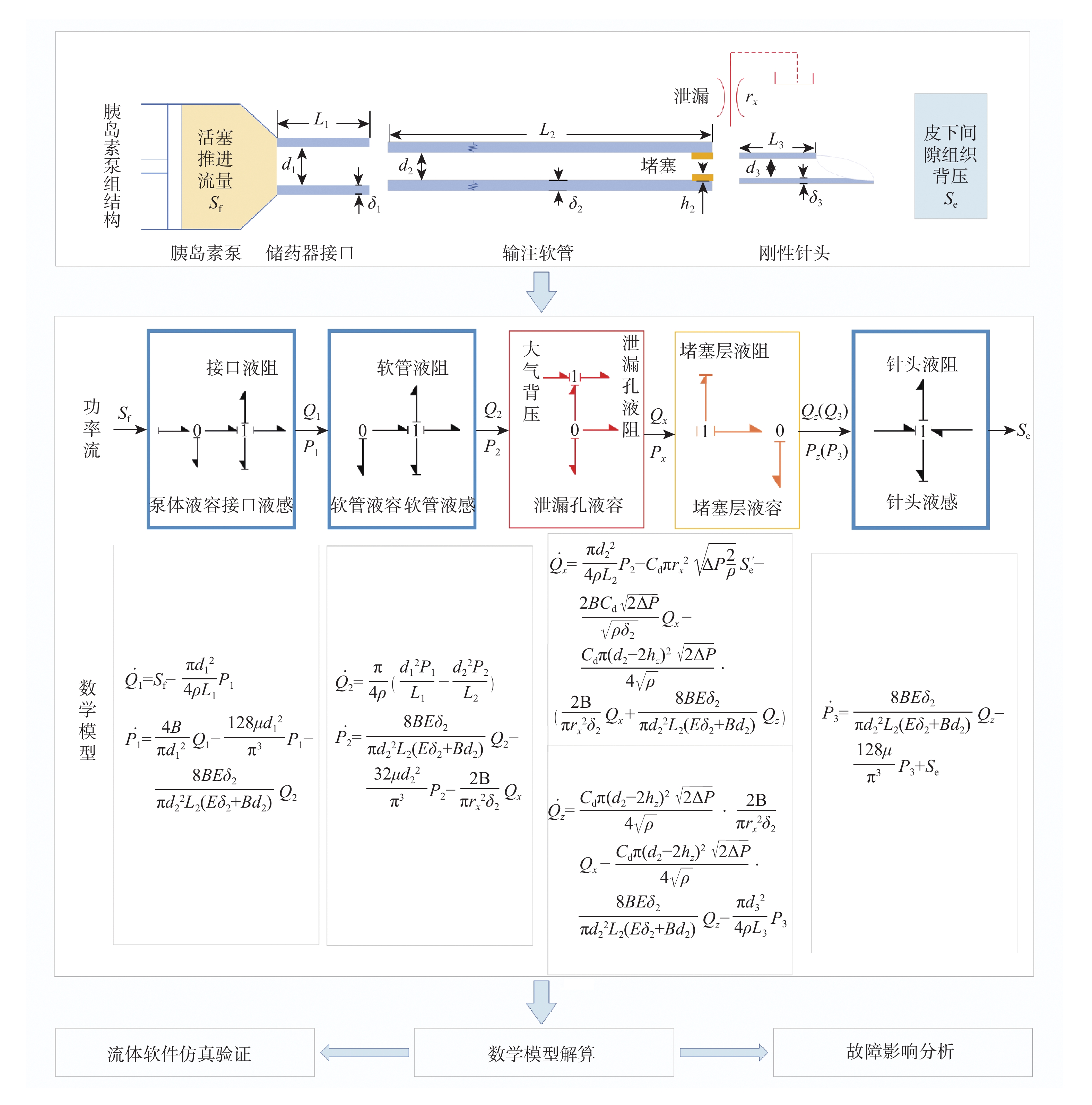
2026,
52(7): 2393-2402. doi: 10.13700/j.bh.1001-5965.2024.0394
摘要:
















2026,
52(7): 2403-2413. doi: 10.13700/j.bh.1001-5965.2024.0299
摘要:














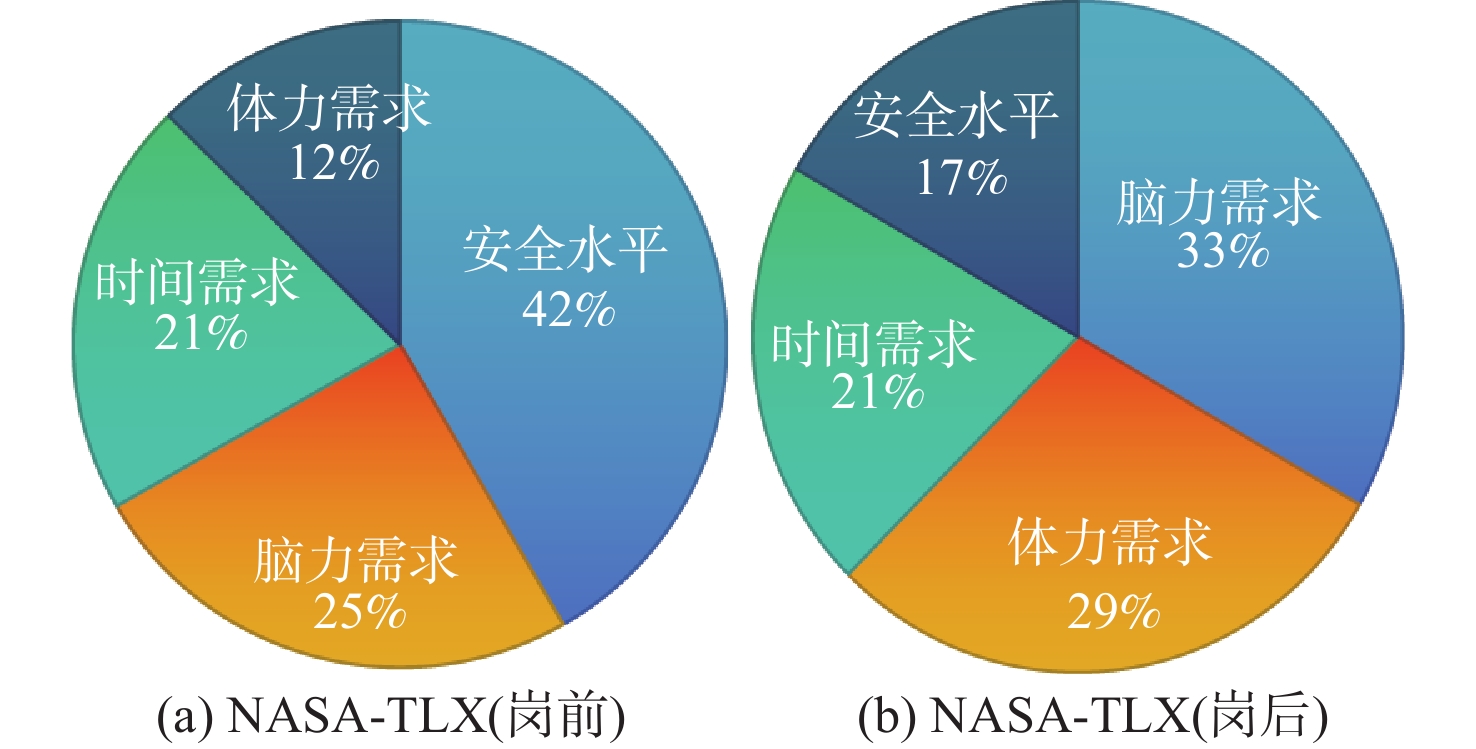
2026,
52(7): 2414-2424. doi: 10.13700/j.bh.1001-5965.2024.0351
摘要:






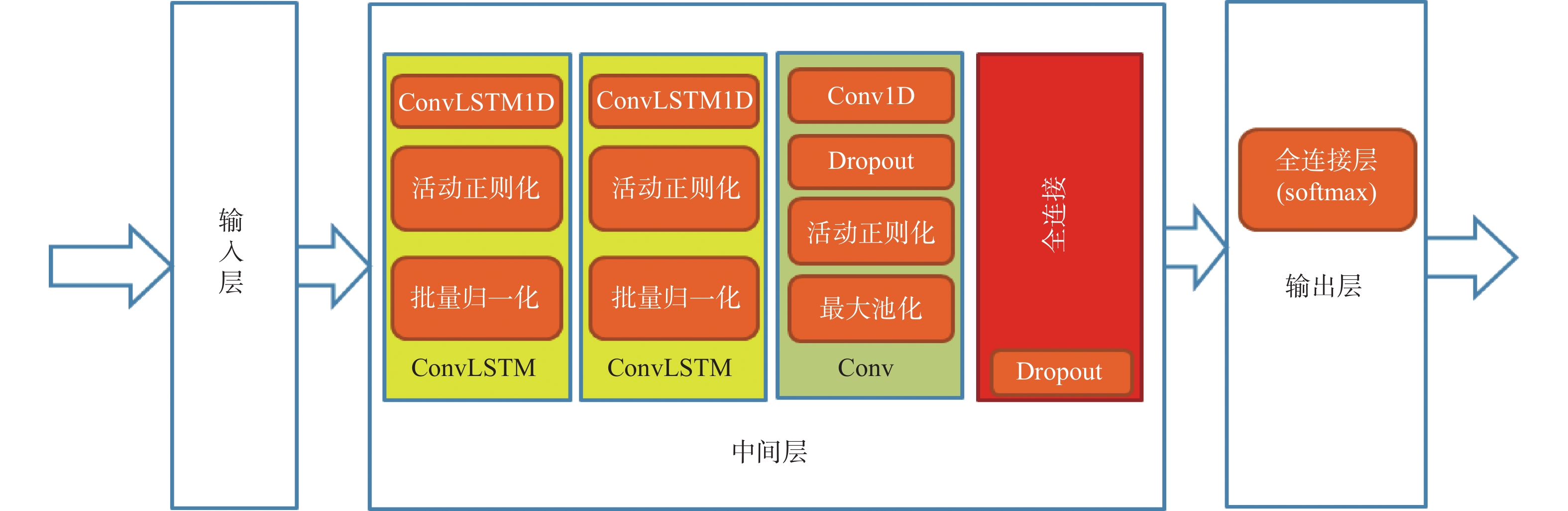
2026,
52(7): 2425-2433. doi: 10.13700/j.bh.1001-5965.2024.0319
摘要:







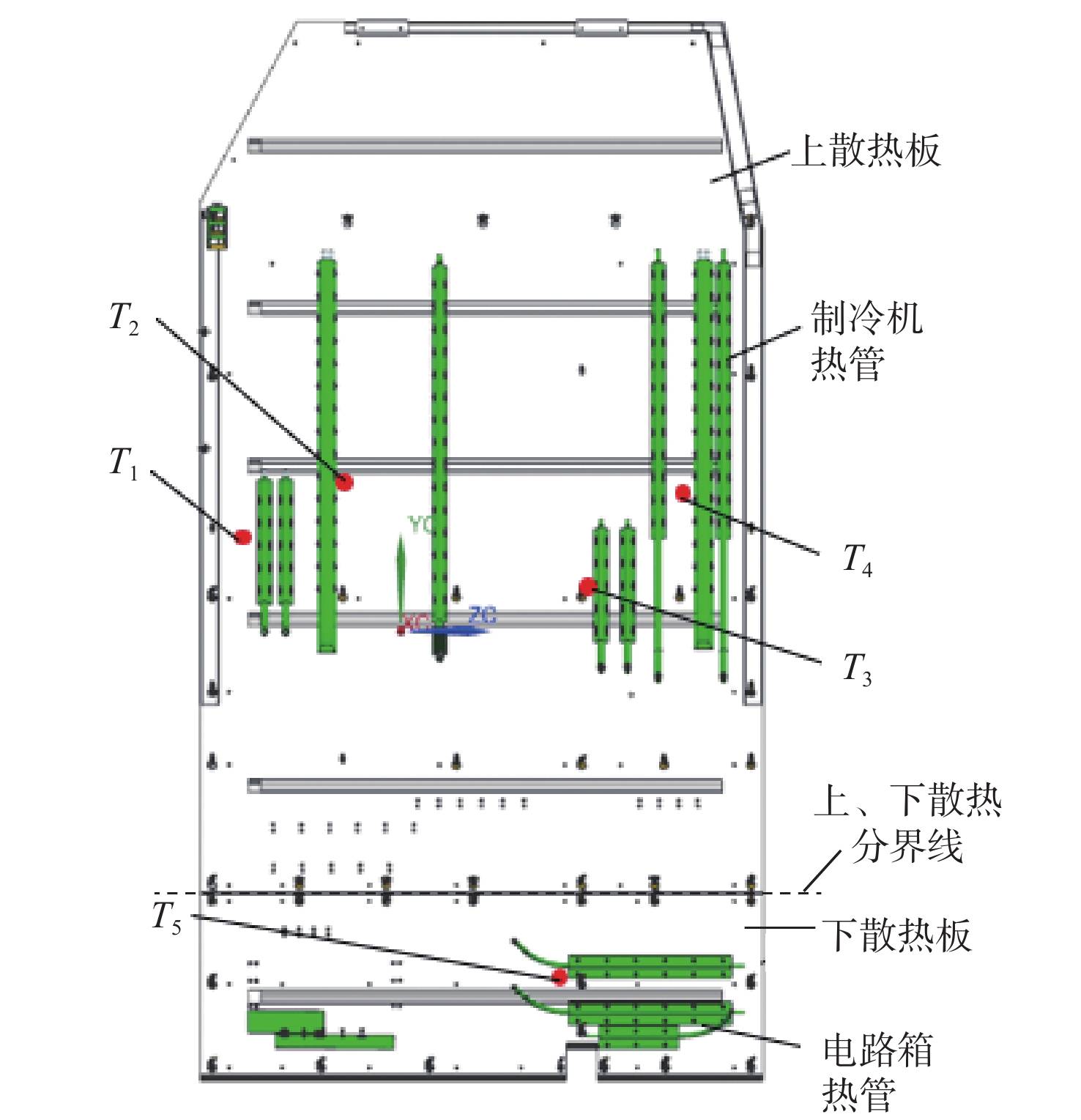
2026,
52(7): 2434-2439. doi: 10.13700/j.bh.1001-5965.2024.0334
摘要:



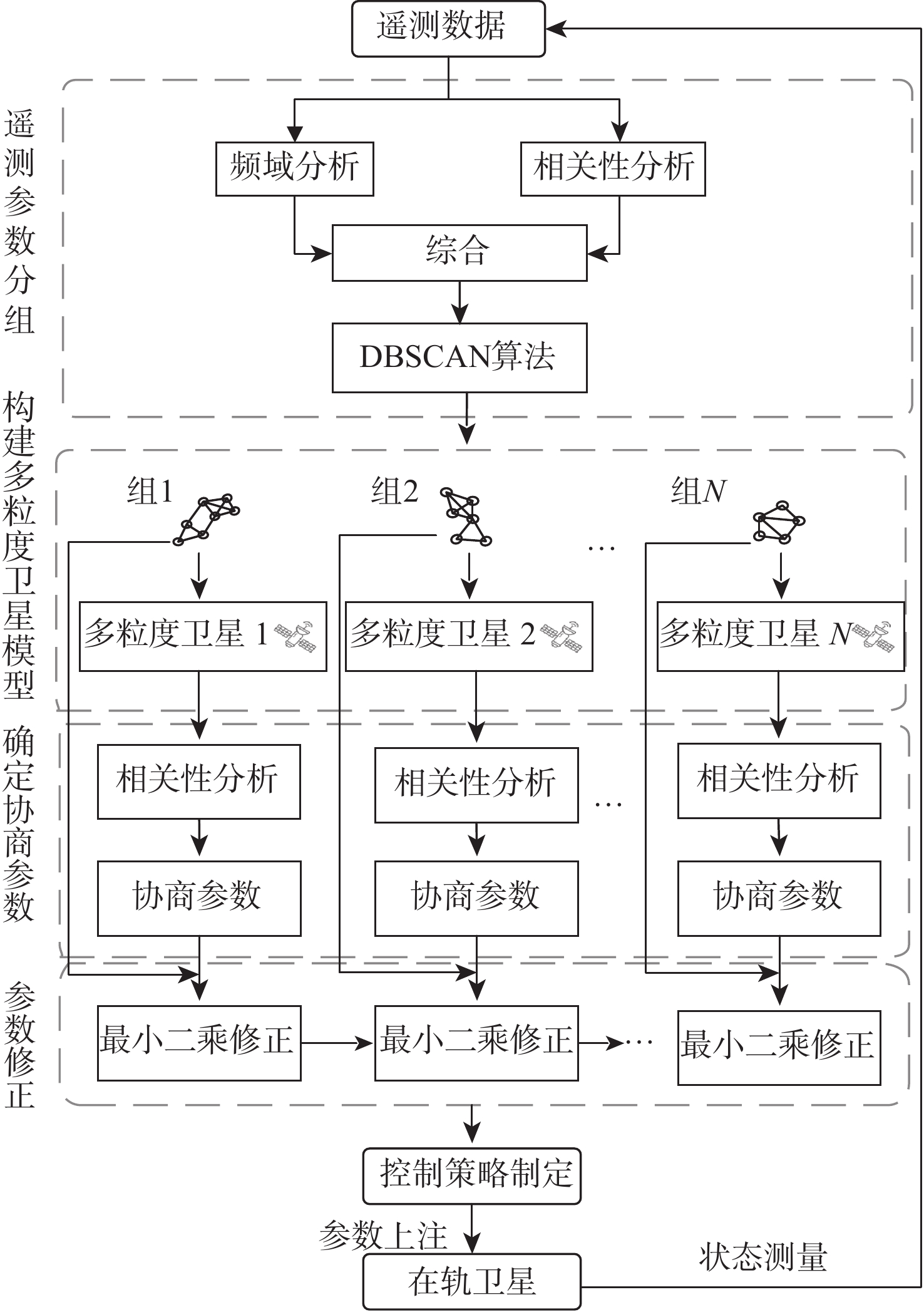
2026,
52(7): 2440-2453. doi: 10.13700/j.bh.1001-5965.2024.0325
摘要:












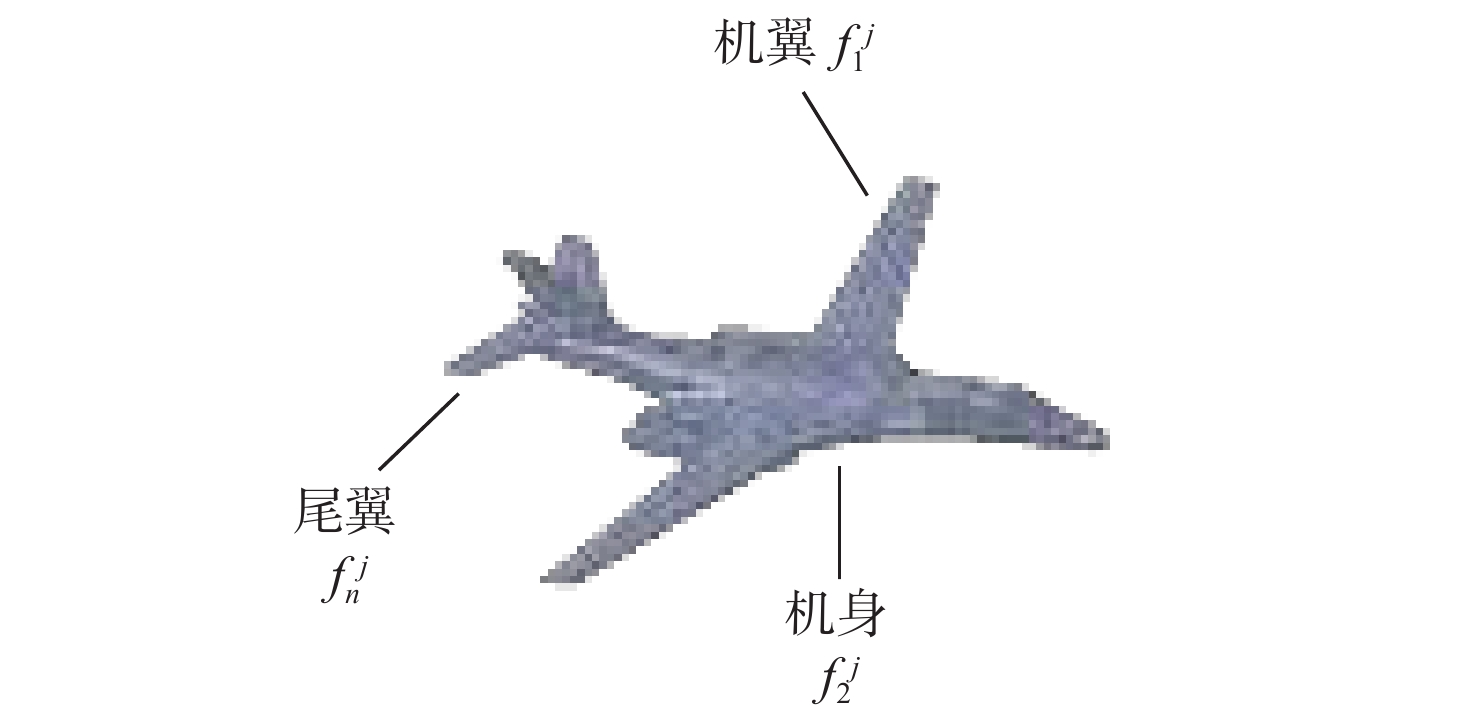
2026,
52(7): 2454-2465. doi: 10.13700/j.bh.1001-5965.2024.0339
摘要:















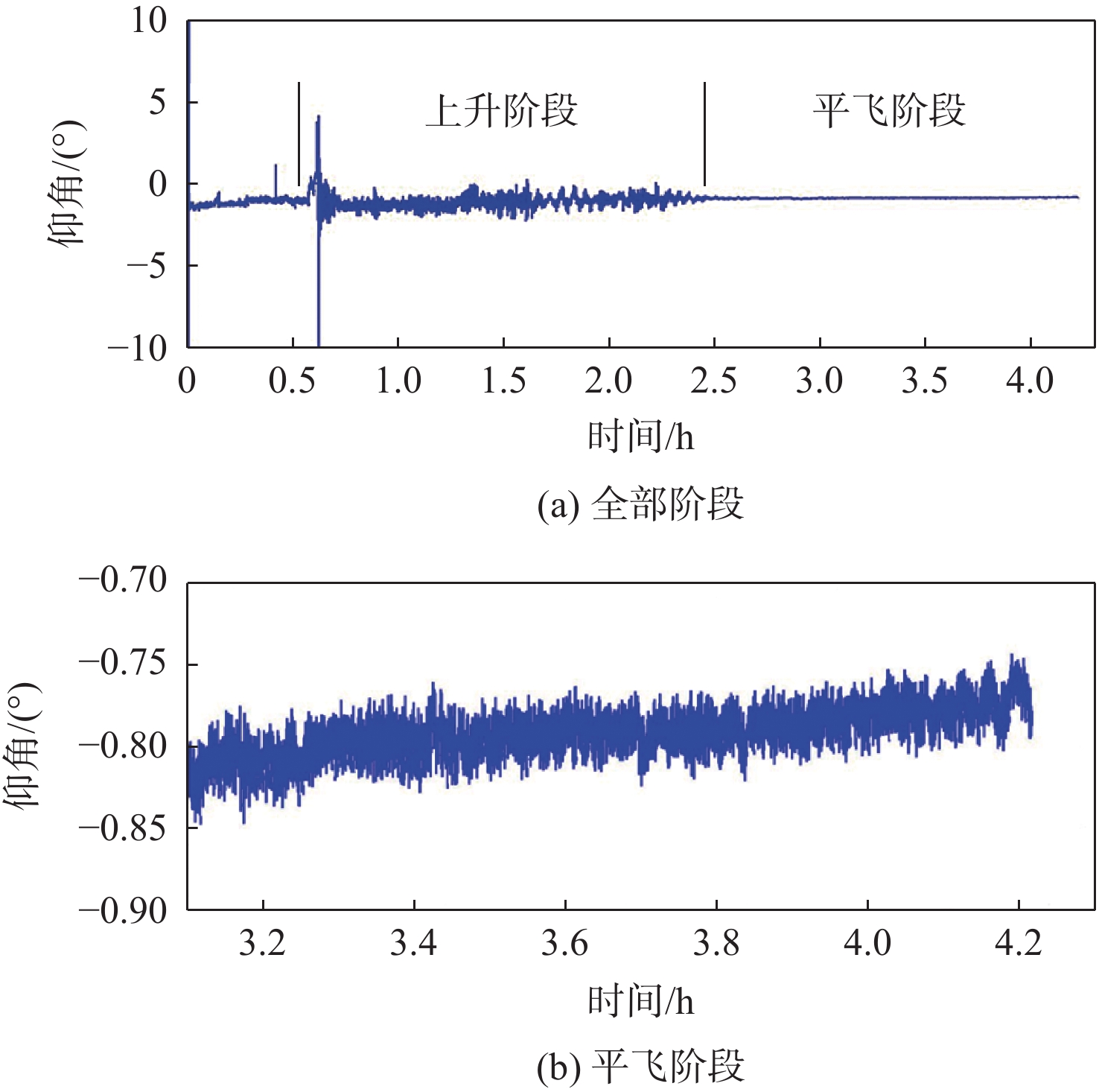
2026,
52(7): 2466-2476. doi: 10.13700/j.bh.1001-5965.2024.0356
摘要:
















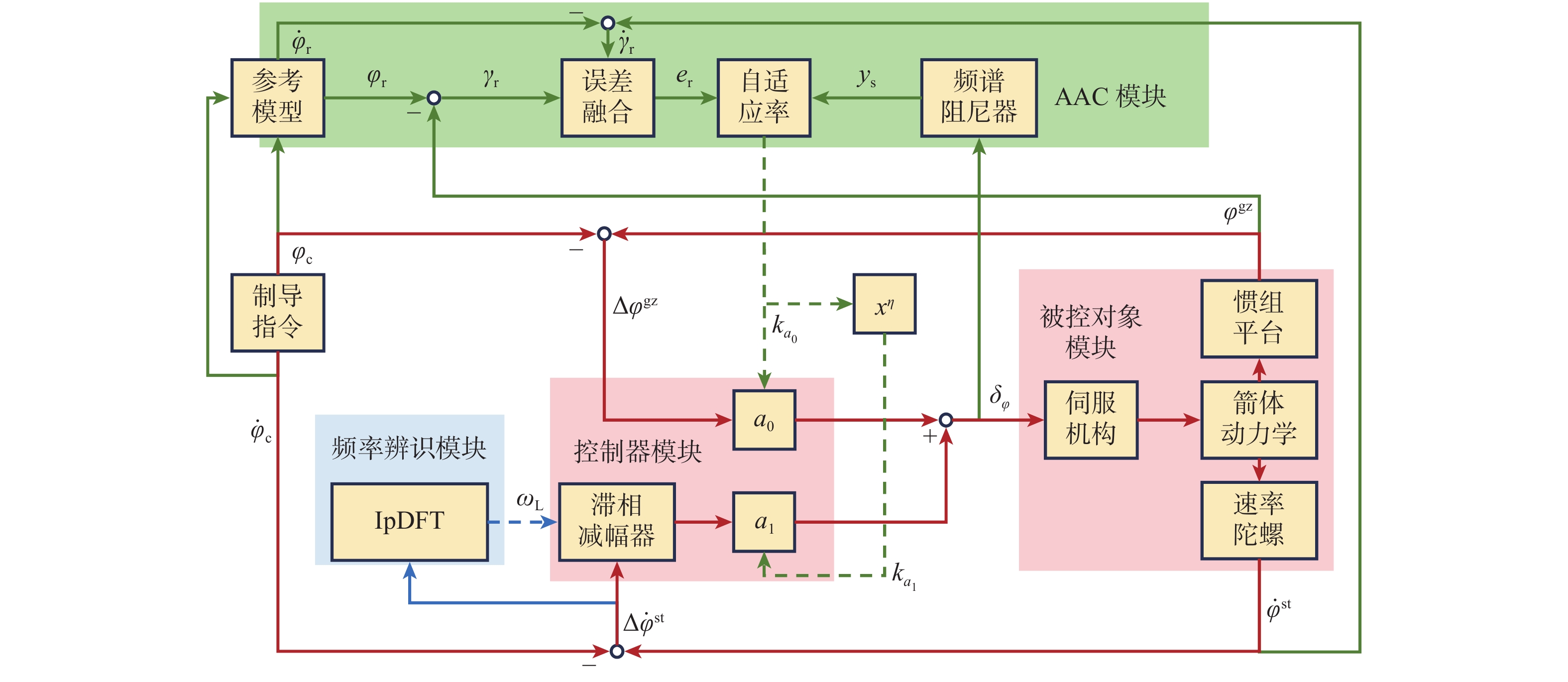
2026,
52(7): 2477-2486. doi: 10.13700/j.bh.1001-5965.2024.0383
摘要:








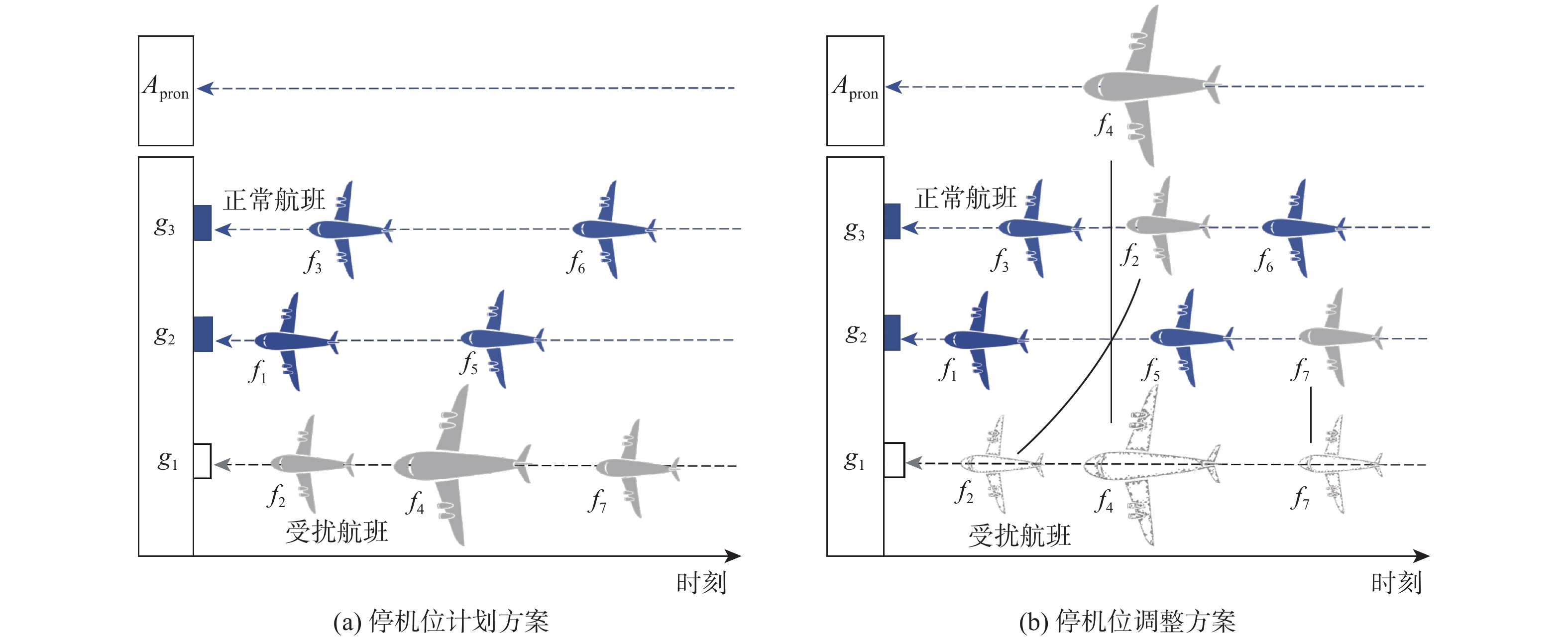
2026,
52(7): 2487-2495. doi: 10.13700/j.bh.1001-5965.2024.0419
摘要:







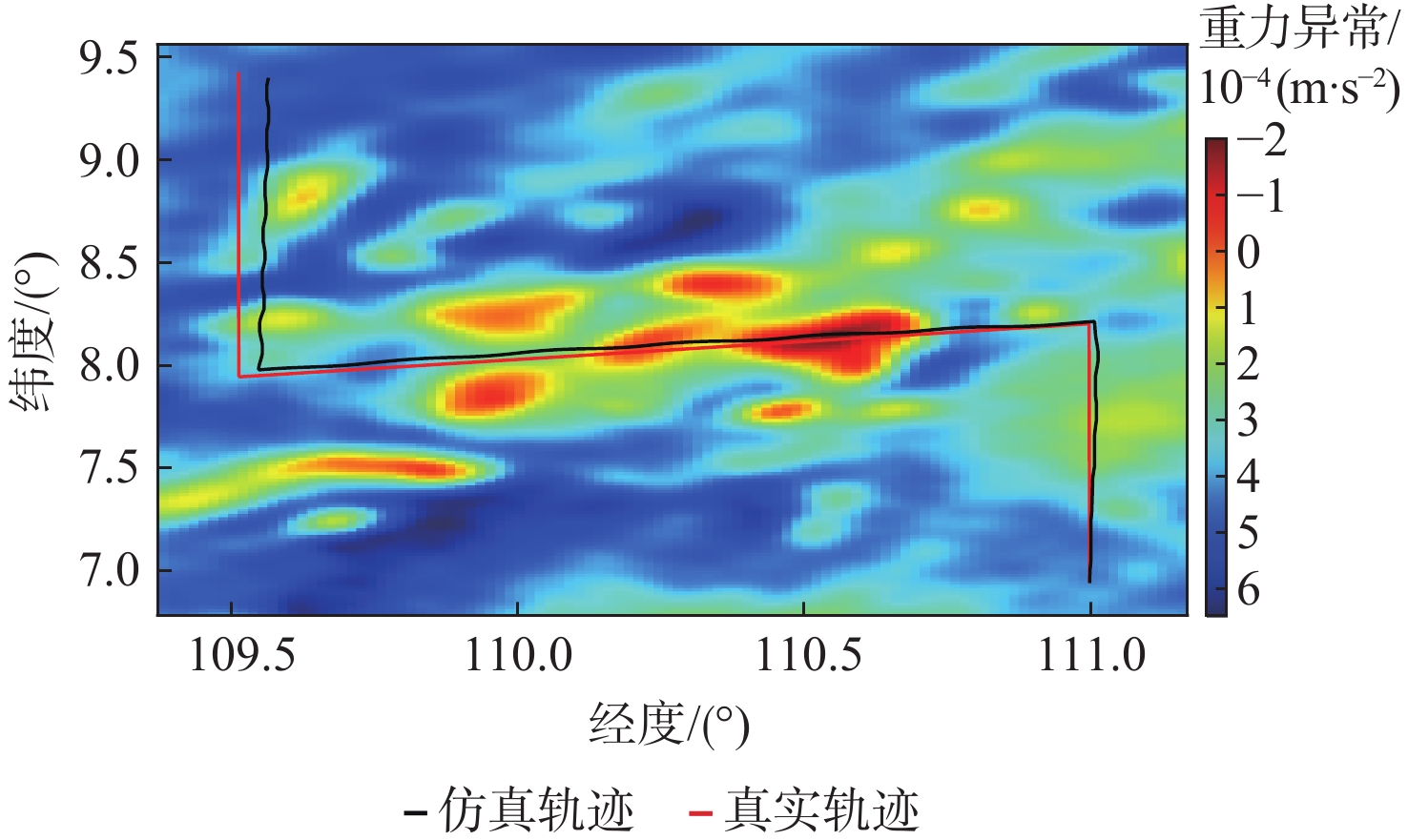
2026,
52(7): 2496-2508. doi: 10.13700/j.bh.1001-5965.2024.0308
摘要:




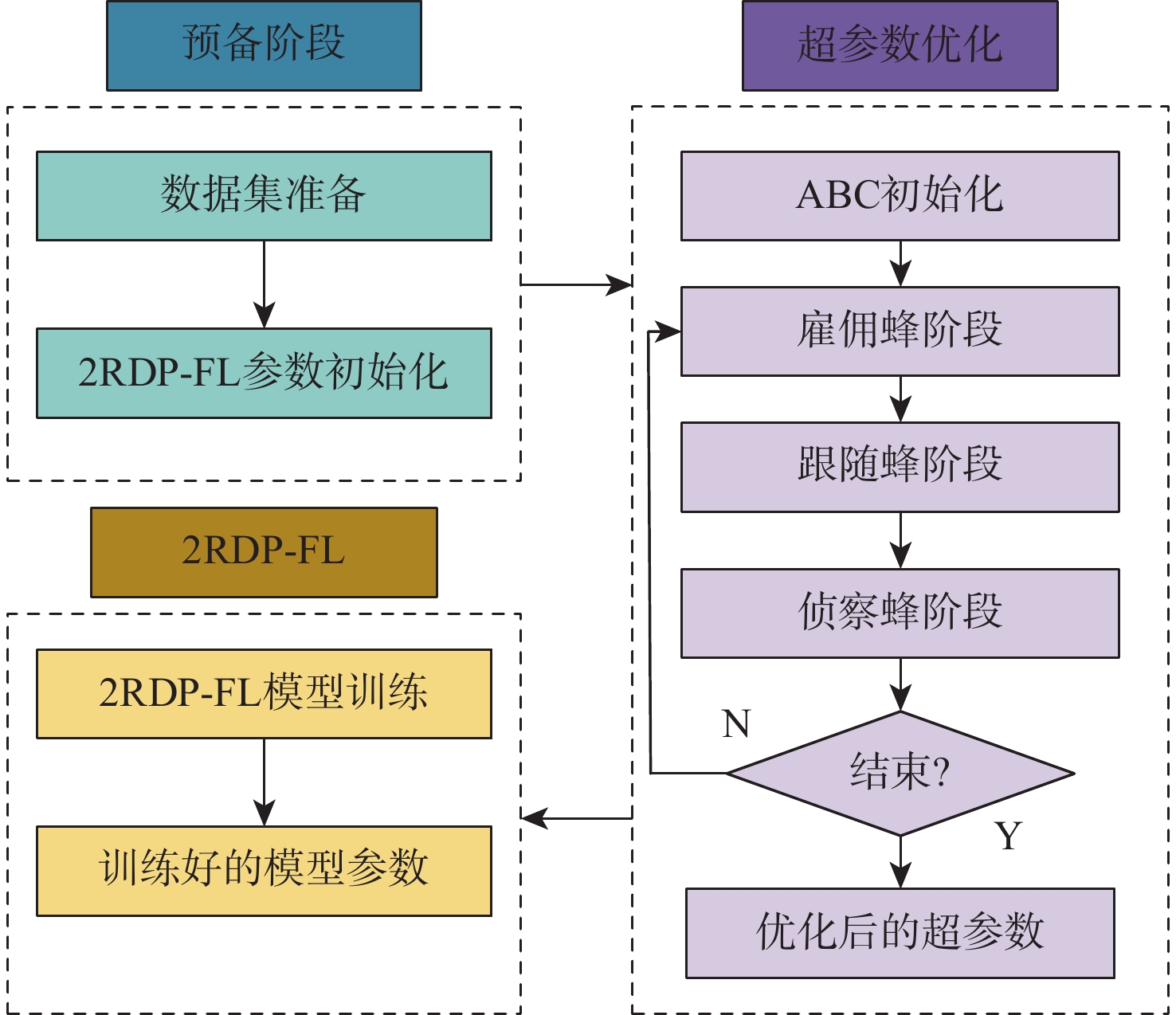
2026,
52(7): 2509-2518. doi: 10.13700/j.bh.1001-5965.2024.0413
摘要:




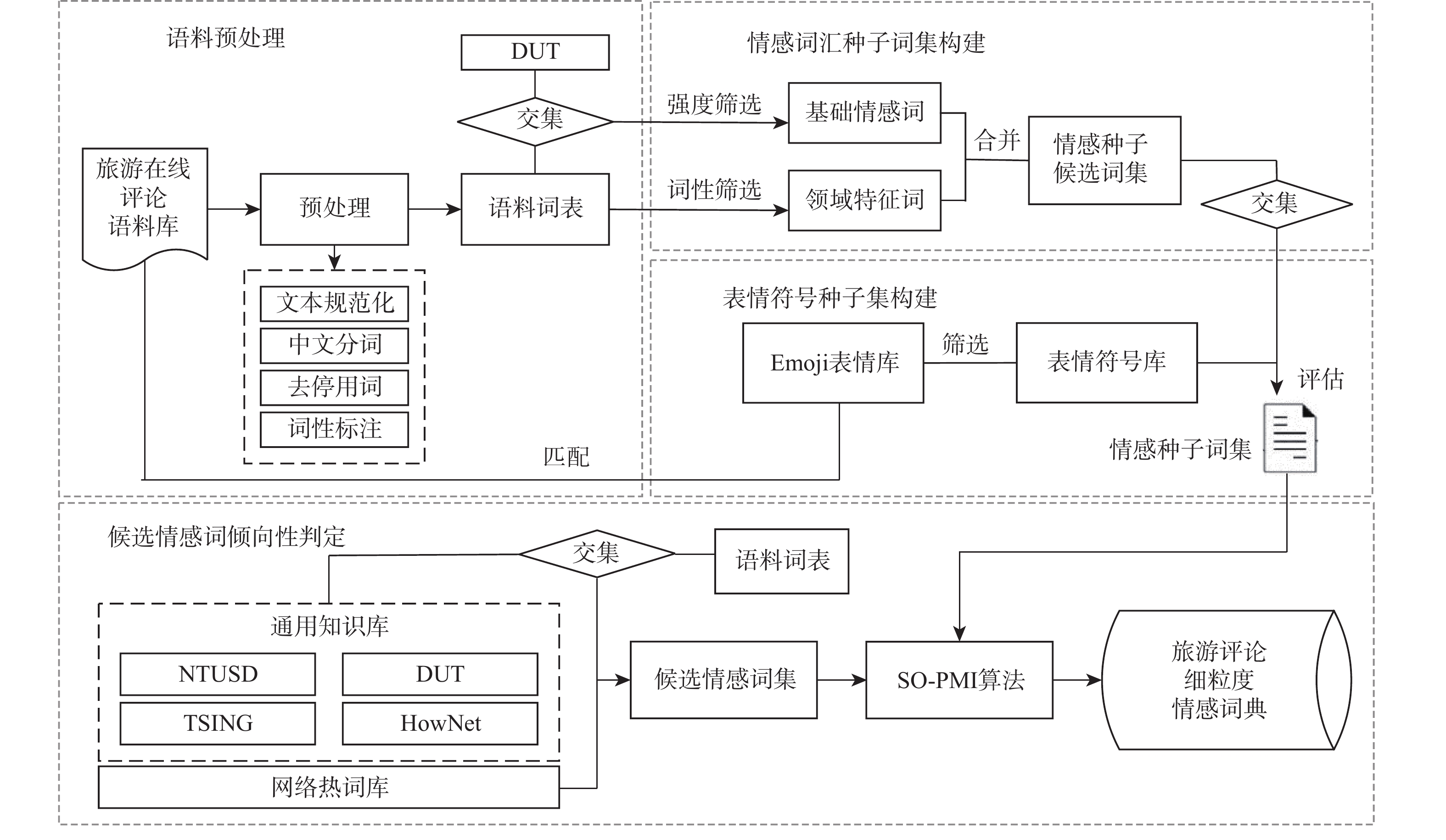
2026,
52(7): 2519-2528. doi: 10.13700/j.bh.1001-5965.2024.0323
摘要:



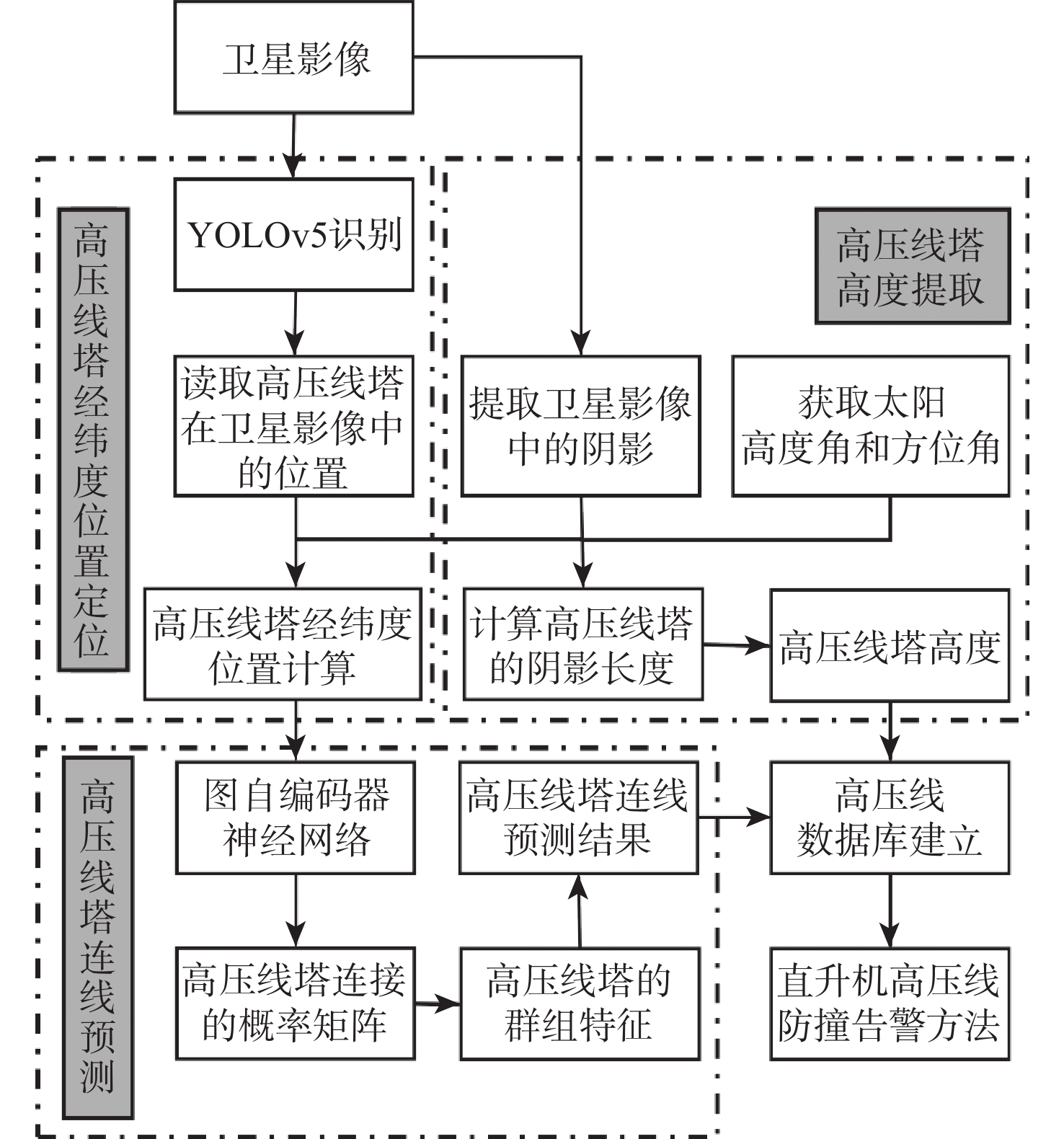
2026,
52(7): 2529-2539. doi: 10.13700/j.bh.1001-5965.2024.0311
摘要:













2026,
52(7): 2540-2553. doi: 10.13700/j.bh.1001-5965.2024.0370
摘要:






























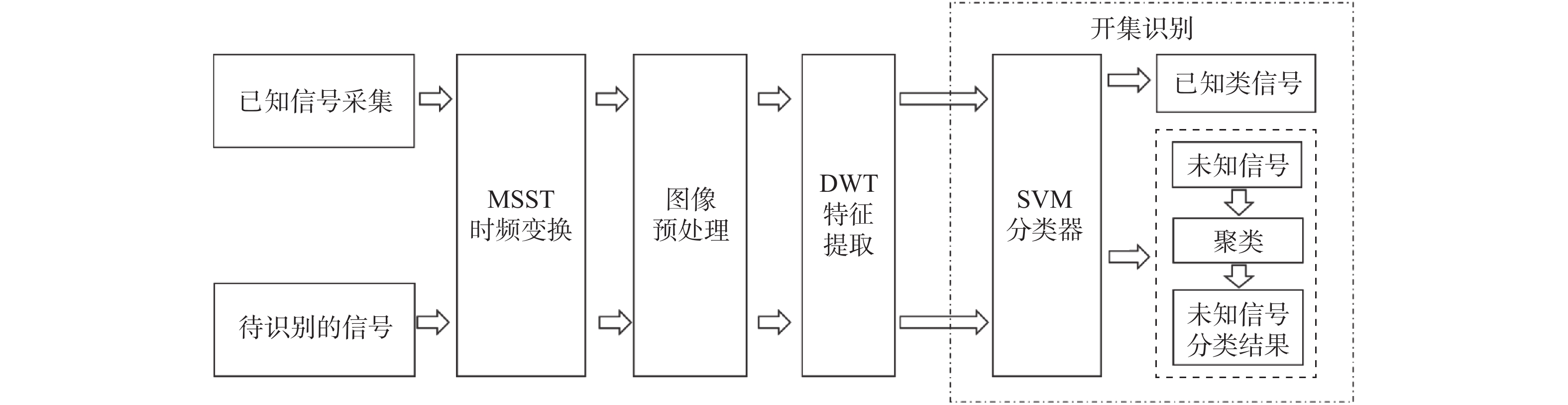
2026,
52(7): 2554-2562. doi: 10.13700/j.bh.1001-5965.2024.0369
摘要:









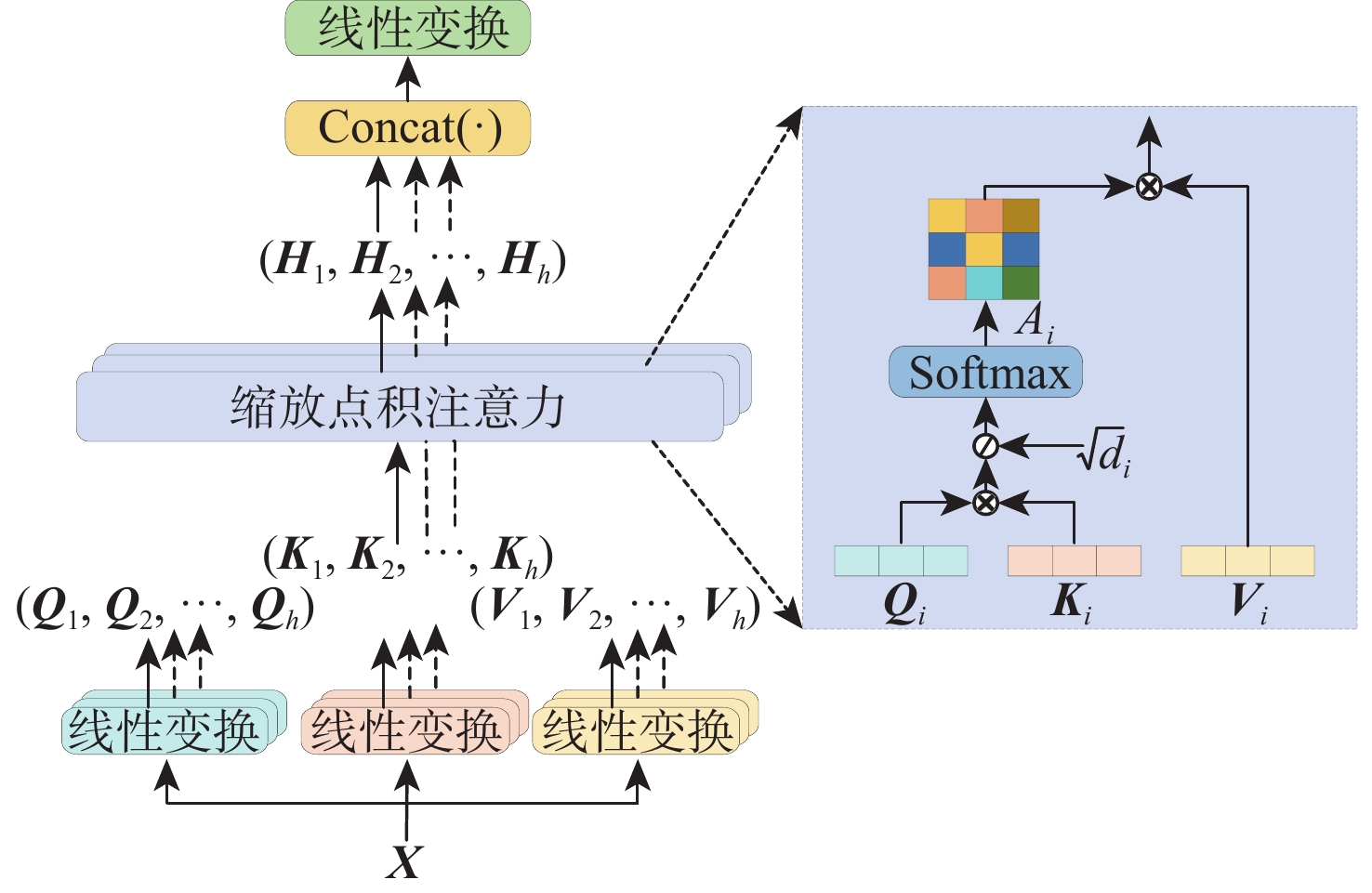
2026,
52(7): 2563-2579. doi: 10.13700/j.bh.1001-5965.2024.0366
摘要:















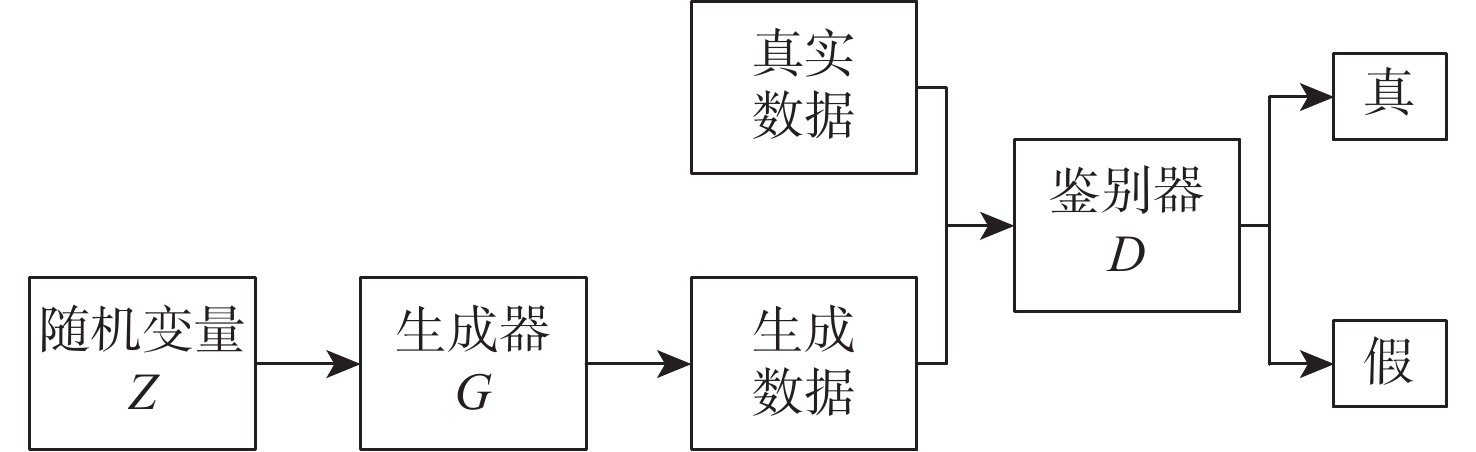
2026,
52(7): 2580-2588. doi: 10.13700/j.bh.1001-5965.2024.0365
摘要:






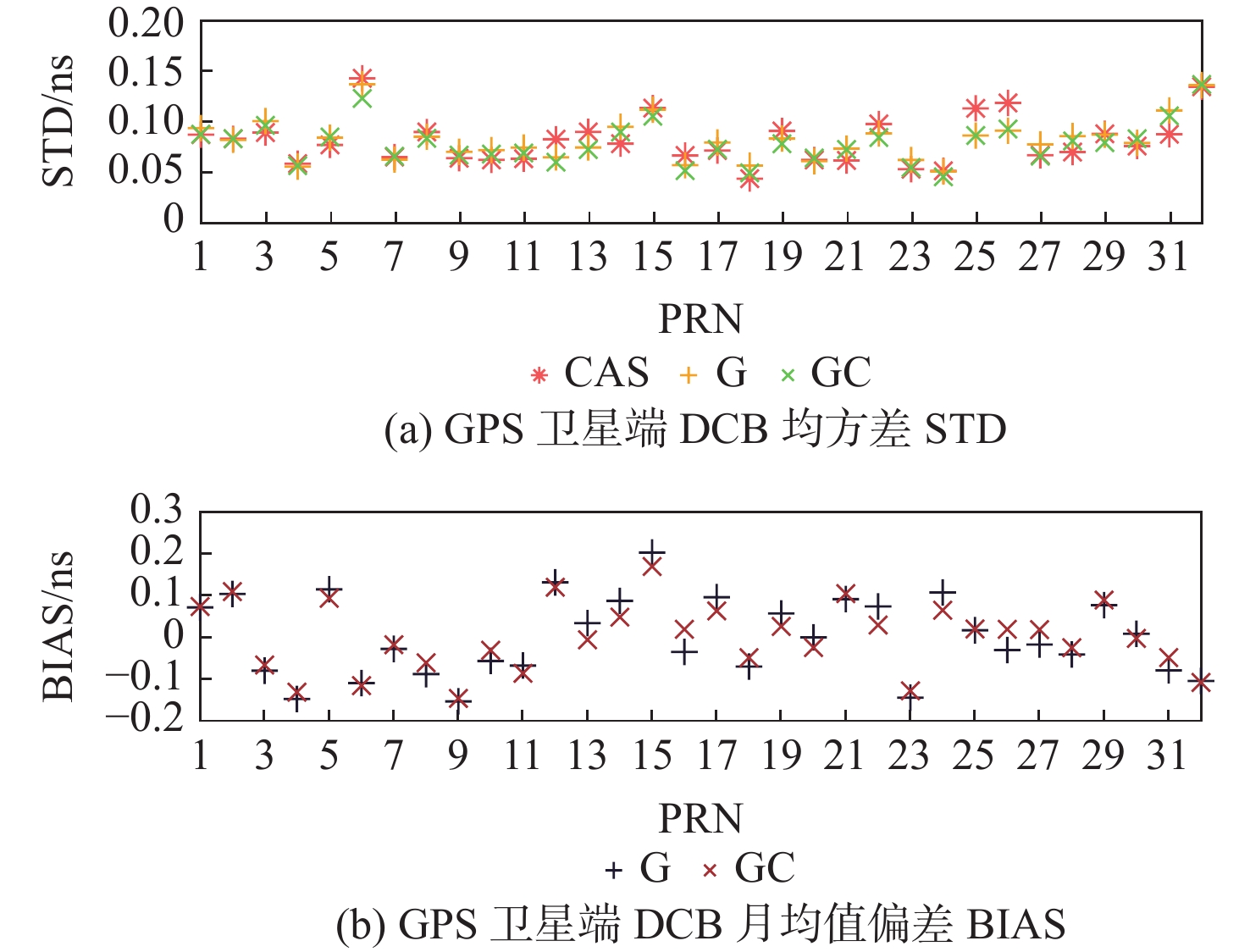
2026,
52(7): 2589-2600. doi: 10.13700/j.bh.1001-5965.2024.0353
摘要:










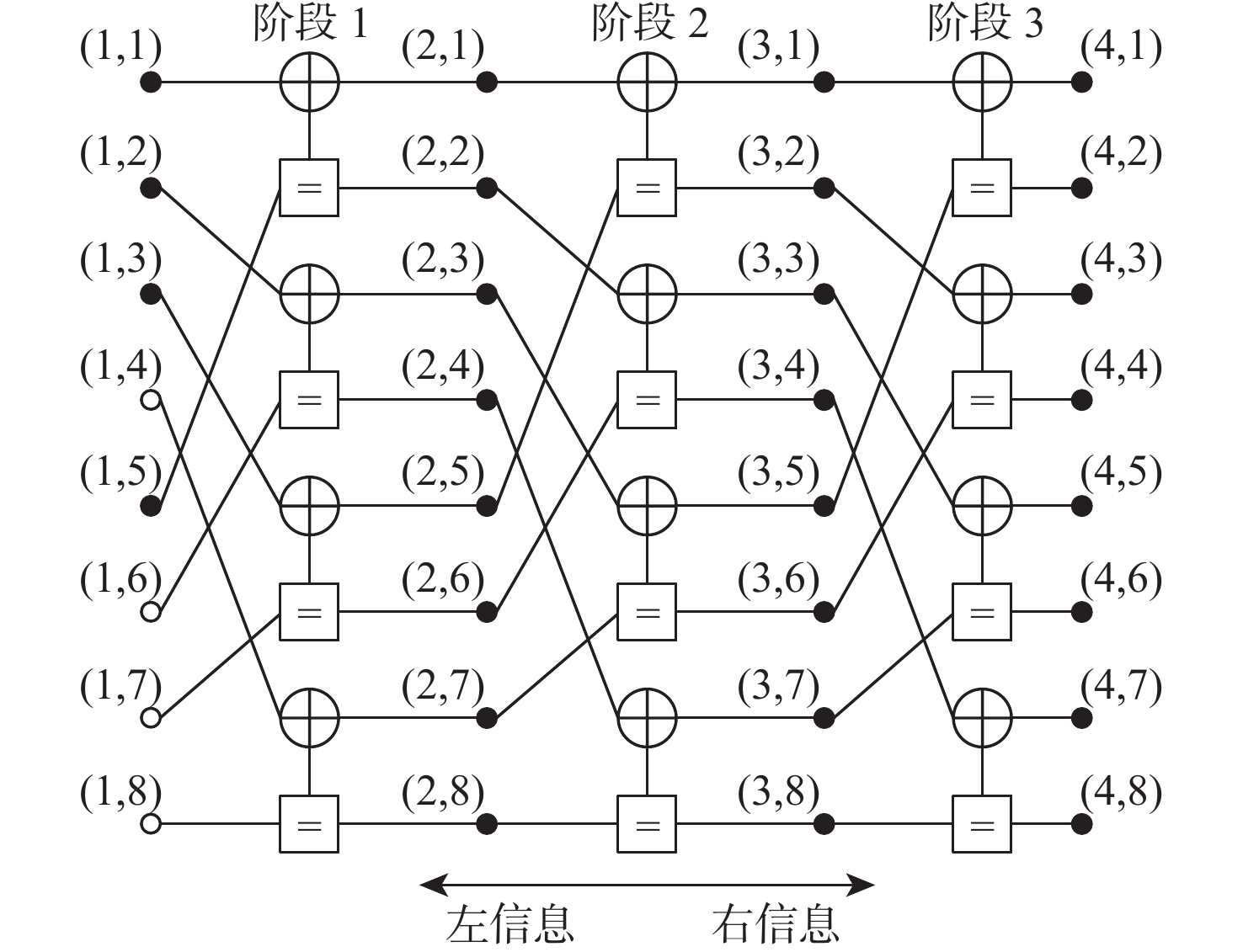
2026,
52(7): 2601-2609. doi: 10.13700/j.bh.1001-5965.2024.0407
摘要:













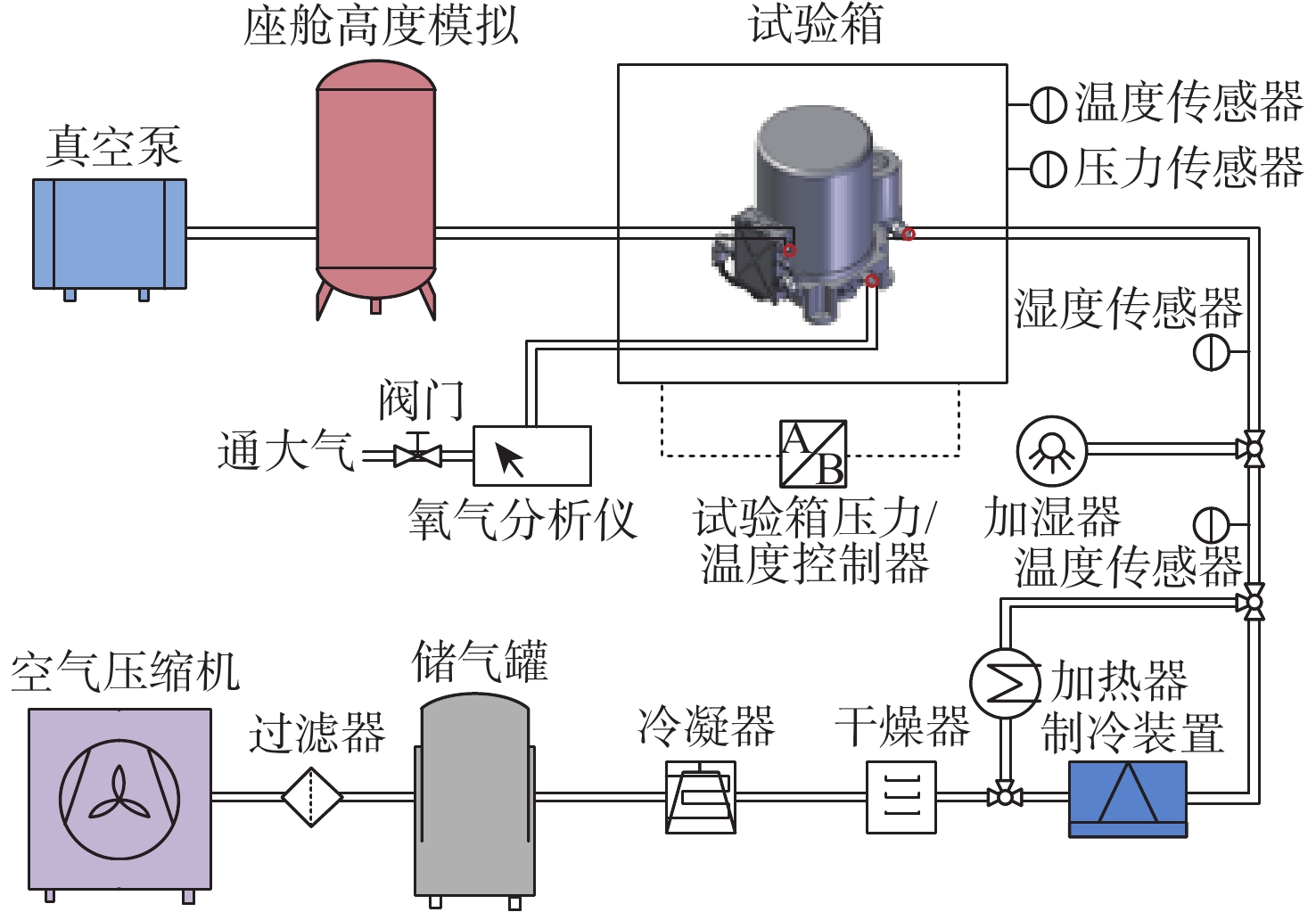
2026,
52(7): 2610-2620. doi: 10.13700/j.bh.1001-5965.2024.0418
摘要:














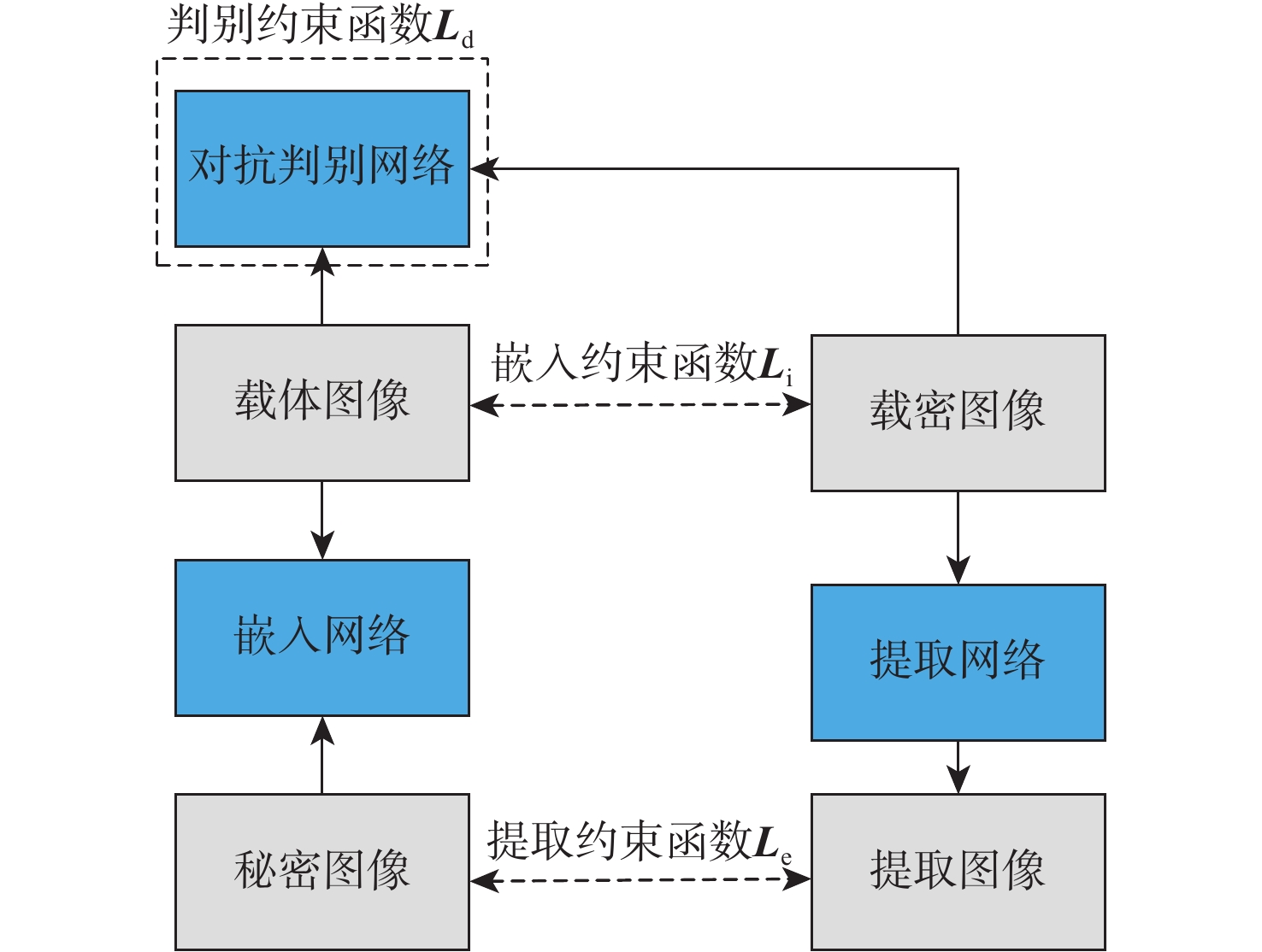
2026,
52(7): 2621-2629. doi: 10.13700/j.bh.1001-5965.2024.0302
摘要:







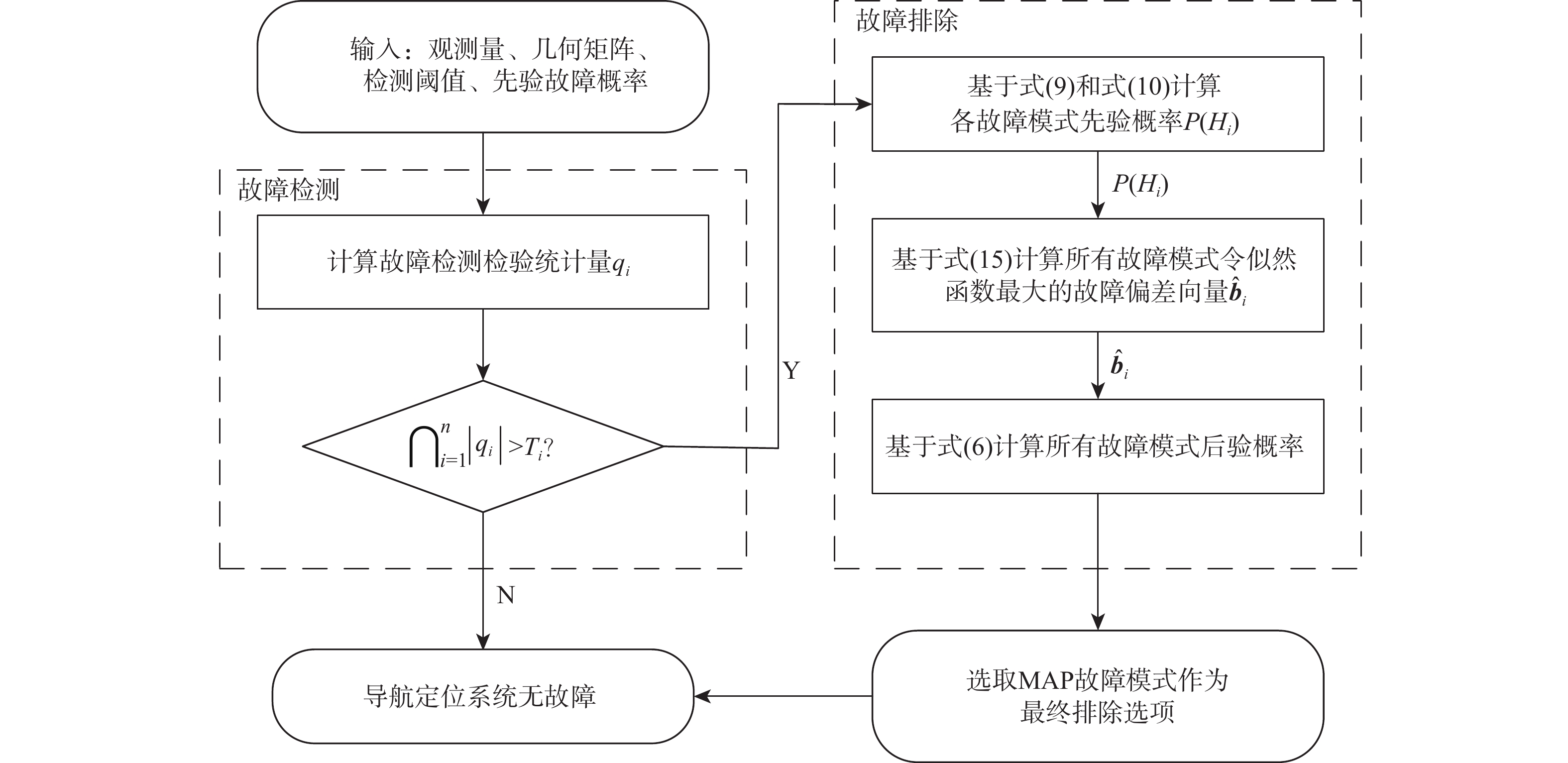
2026,
52(7): 2630-2638. doi: 10.13700/j.bh.1001-5965.2024.0414
摘要:











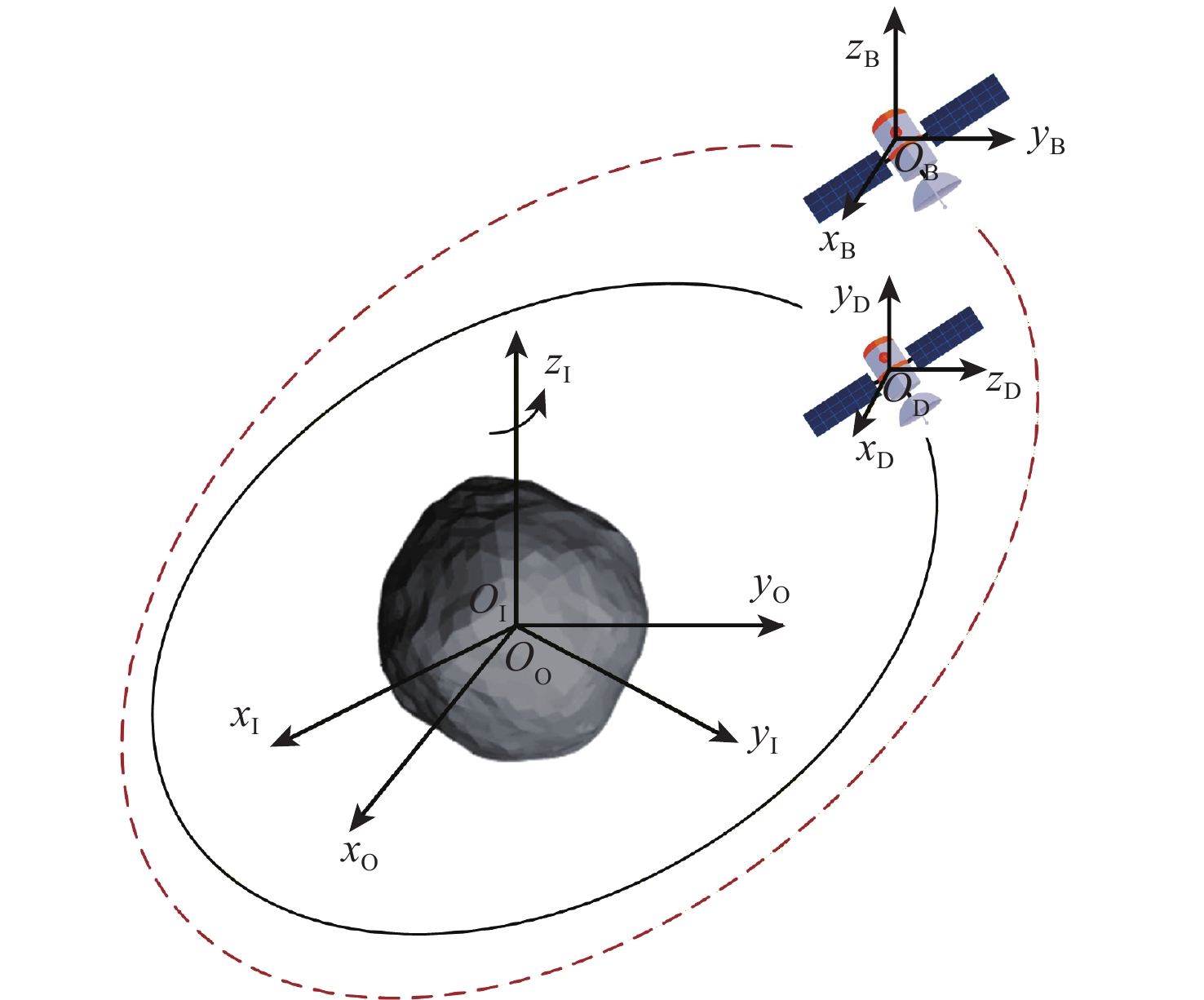
2026,
52(7): 2639-2650. doi: 10.13700/j.bh.1001-5965.2024.0333
摘要:










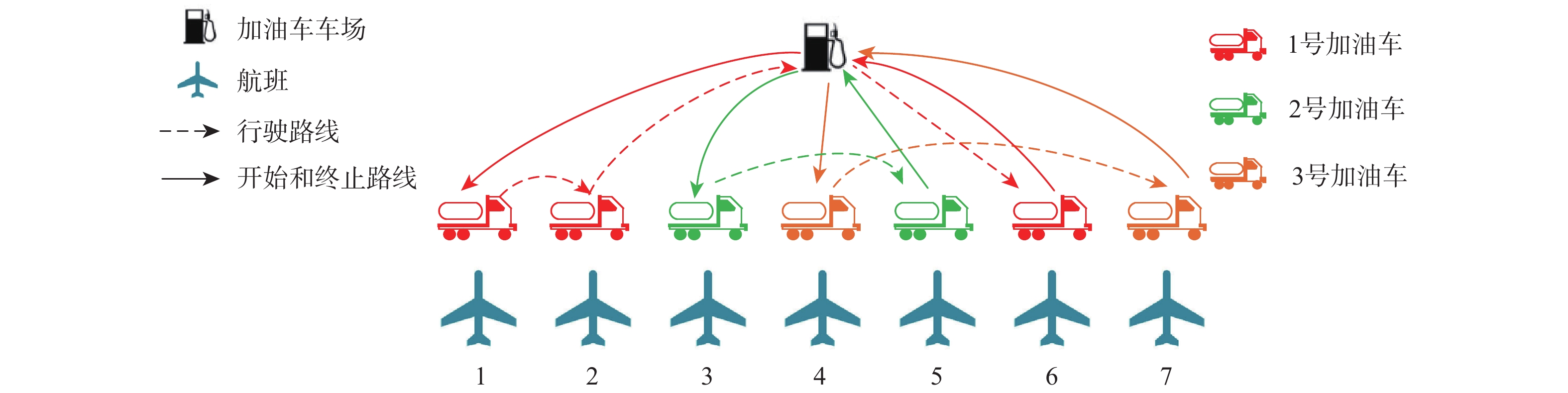
2026,
52(7): 2651-2659. doi: 10.13700/j.bh.1001-5965.2024.0332
摘要:










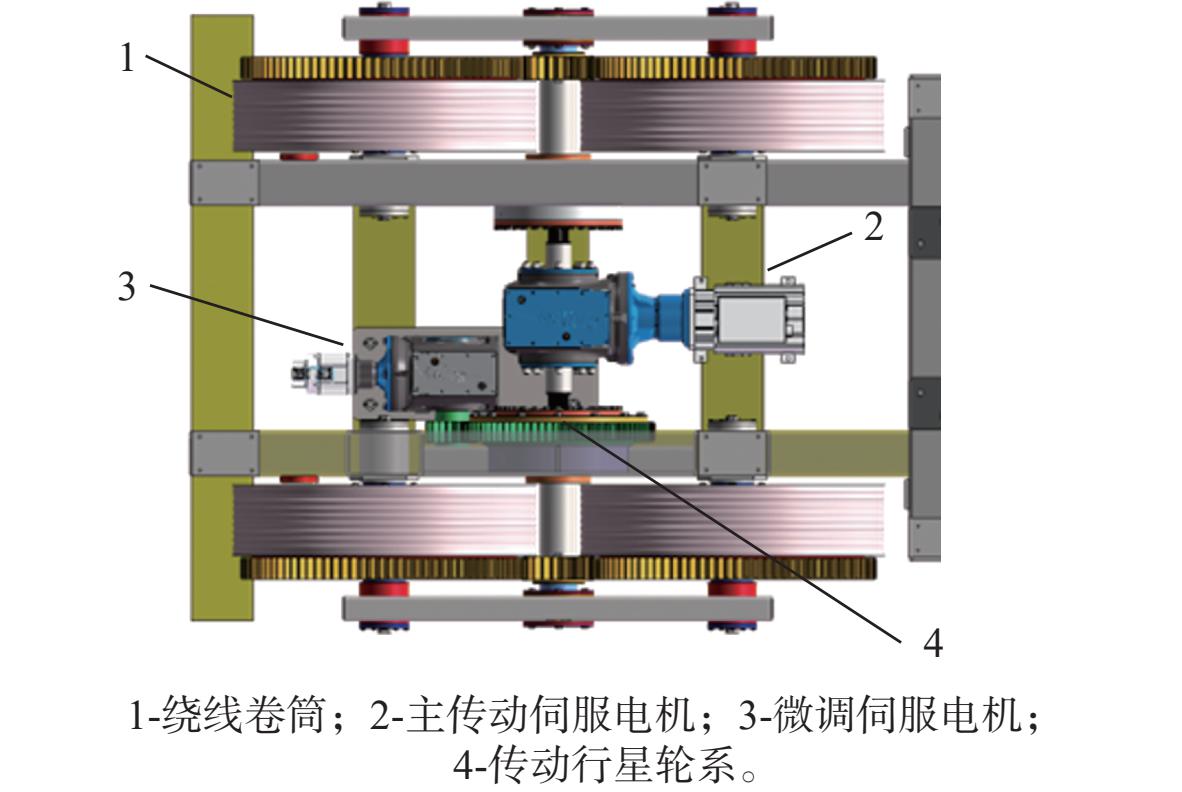
2026,
52(7): 2660-2671. doi: 10.13700/j.bh.1001-5965.2024.0371
摘要:














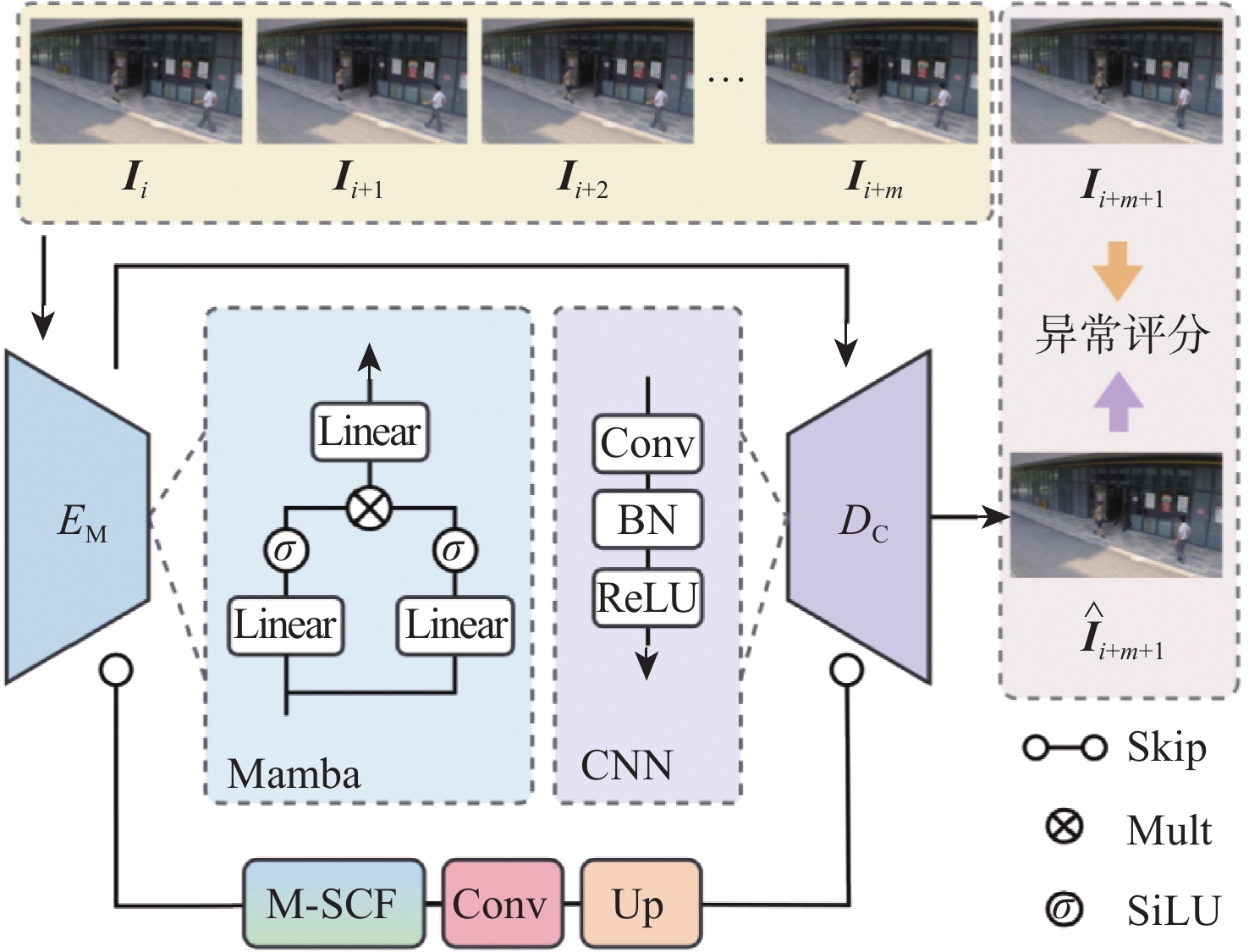
2026,
52(7): 2672-2680. doi: 10.13700/j.bh.1001-5965.2024.0416
摘要:











 XML在线生产平台
XML在线生产平台






