



-
摘要:
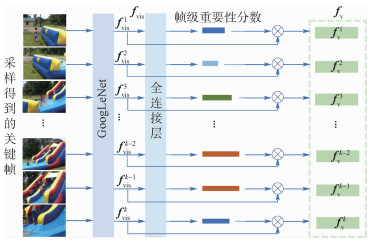
视频摘要任务旨在通过生成简短的视频片段来表示原视频的主要内容,针对现有方法缺乏对语义信息探索的问题,提出了一种融合语义信息的视频摘要生成模型,学习视频特征使其包含丰富的语义信息,进而同时生成描述原始视频内容的视频摘要和文本摘要。该模型分为3个模块:帧级分数加权模块、视觉-语义嵌入模块、视频文本描述生成模块。帧级分数加权模块结合卷积网络与全连接层以获取帧级重要性分数;视觉-语义嵌入模块将视觉特征与文本特征映射到同一空间,以使2种特征相互靠近;视频文本描述生成模块最小化视频摘要的生成描述与文本标注真值之间的距离,以生成带有语义信息的视频摘要。测试时,在获取视频摘要的同时,该模型获得简短的文本摘要作为副产品,可以帮助人们更直观地理解视频内容。在SumMe和TVSum数据集上的实验表明:该模型通过融合语义信息,比现有先进方法取得了更好的性能,在这2个数据集上
F -score指标分别提高了0.5%和1.6%。-
关键词:
- 视频摘要 /
- 视觉-语义嵌入空间 /
- 视频文本描述 /
- 视频关键帧 /
- 长短期记忆(LSTM)模型
Abstract:Video summarization aims to generate short and compact summary to represent original video. However, the existing methods focus more on representativeness and diversity of representation, but less on semantic information. In order to fully exploit semantic information of video content, we propose a novel video summarization model that learns a visual-semantic embedding space, so that the video features contain rich semantic information. It can generate video summaries and text summaries that describe the original video simultaneously. The model is mainly divided into three modules: frame-level score weighting module that combines convolutional layers and fully connected layers; visual-semantic embedding module that embeds the video and text in a common embedding space and make them lose to each other to achieve the purpose of mutual promotion of two features; video caption generation module that generates video summary with semantic information by minimizing the distance between the generated description of the video summary and the manually annotated text of the original video. During the test, while obtaining the video summary, we obtain a short text summary as a by-product, which can help people understand the video content more intuitively. Experiments on SumMe and TVSum datasets show that the proposed model achieves better performance than the existing advanced methods by fusing semantic information, and improves
F -score by 0.5% and 1.6%, respectively. -

图 1 融合语义信息的视频摘要生成流程
Figure 1. Flowchart of video summarization by learning semantic information
表 2 不同数据集生成的文本摘要评测
Table 2. Evaluation of text summaries generated by different datasets
数据集 BLEU-1/% ROUGE-L/% CIDEr/% SumMe 28.3 27.6 9.6 TVSum 32.8 29.9 12.7  下载: 导出CSV
下载: 导出CSV
表 3 TVSum数据集上的消融实验结果
Table 3. Results of ablation experiment on TVSum
实验编号 嵌入空间 描述生成 F-score/% 1 × × 50.4 2 √ × 51.5 3 × √ 58.3 4 √ √ 60.1
下载: 导出CSV
-
[1] 刘波. 视频摘要研究综述[J]. 南京信息工程大学学报, 2020, 12(3): 274-278. https://www.cnki.com.cn/Article/CJFDTOTAL-NJXZ202003003.htmLIU B. Survey of video summary[J]. Journal of Nanjing University of Information Science & Technology, 2020, 12(3): 274-278(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-NJXZ202003003.htm [2] RAV-ACHA A, PRITCH Y, PELEG S. Making a long video short: Dynamic video synopsis[C]//Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2006: 435-441. [3] ZHAO B, XING E P. Quasi real-time summarization for consumer videos[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 2513-2520. [4] ZHANG K, CHAO W, SHA F, et al. Video summarization with long short-term memory[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 766-782. [5] MAHASSENI B, LAM M, TODOROVIC S, et al. Unsupervised video summarization with adversarial LSTM networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 2982-2991. [6] ZHAO B, LI X, LU X, et al. HSA-RNN: Hierarchical structure-adaptive RNN for video summarization[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7405-7414. [7] 冀中, 江俊杰. 基于解码器注意力机制的视频摘要[J]. 天津大学学报, 2018, 51(10): 1023-1030. https://www.cnki.com.cn/Article/CJFDTOTAL-TJDX201810004.htmJI Z, JIANG J J. Video summarization based on decoder attention mechanism[J]. Transactions of Tianjin University, 2018, 51(10): 1023-1030(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-TJDX201810004.htm [8] 李依依, 王继龙. 自注意力机制的视频摘要模型[J]. 计算机辅助设计与图形学学报, 2020, 32(4): 652-659. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJF202004016.htmLI Y Y, WANG J L. Self-attention based video summarization[J]. Journal of Computer-Aided Design & Computer Graphics, 2020, 32(4): 652-659(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-JSJF202004016.htm [9] CHEN Y, TAO L, WANG X, et al. Weakly supervised video summarization by hierarchical reinforcement learning[C]//Proceedings of the ACM Multimedia Asia. New York: ACM Press, 2019: 1-6. [10] CHOI J, OH T, KWEON I S, et al. Contextually customized video summaries via natural language[C]//Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Piscataway: IEEE Press, 2018: 1718-1726. [11] WEI H, NI B, YAN Y, et al. Video summarization via semantic attended networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2018: 216-223. [12] SHARGHI A, BORJI A, LI C, et al. Improving sequential determinantal point processes for supervised video summarization[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 533-550. [13] ROCHAN M, YE L, WANG Y, et al. Video summarization using fully convolutional sequence networks[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 358-374. [14] ZHANG Y, KAMPFFMEYER M, LIANG X, et al. Query-conditioned three-player adversarial network for video summarization[C]//British Machine Vision Conference. Berlin: Springer, 2018. [15] YUAN L, TAY F E, LI P, et al. Cycle-sum: Cycle-consistent adversarial LSTM networks for unsupervised video summarization[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2019: 9143-9150. [16] ZHANG Y, KAMPFFMEYER M, ZHAO X, et al. DTR-GAN: Dilated temporal relational adversarial network for video summarization[C]//Proceedings of the ACM Turing Celebration Conference-China. New York: ACM Press, 2019: 1-6. [17] ZHOU K, QIAO Y, XIANG T. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2018: 7582-7589. [18] WANG L, ZHU Y, PAN H. Unsupervised reinforcement learning for video summarization reward function[C]//Proceedings of the 2019 International Conference on Image, Video and Signal Processing. New York: ACM Press, 2019: 40-44. [19] XU J, MEI T, YAO T, et al. Msr-VTT: A large video description dataset for bridging video and language[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 5288-5296. [20] POTAPOV D, DOUZE M, HARCHAOUI Z, et al. Category-specific video summarization[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 540-555. [21] GONG B, CHAO W L, GRAUMAN K, et al. Diverse sequential subset selection for supervised video summarization[C]//Advances in Neural Information Processing Systems. New York: Curran Associates, 2014: 2069-2077. [22] SONG Y, VALLMITJANA J, STENT A, et al. TVSum: Summarizing web videos using titles[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 5179-5187. [23] GYGLI M, GRABNER H, RIEMENSCHNEIDER H, et al. Creating summaries from user videos[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 505-520. [24] JUNG Y, CHO D, KIM D, et al. Discriminative feature learning for unsupervised video summarization[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2019: 8537-8544. -

 下载:
下载:



 点击查看大图
点击查看大图

计量
- 文章访问数: 732
- HTML全文浏览量: 111
- PDF下载量: 77
- 被引次数: 0
