



Comparison between EM algorithm and dynamical clustering algorithm for Dirichlet mixture samples
-
摘要:
Dirichlet分布是一类包含正参数向量的连续多元概率分布,在比例结构问题中具有广泛的应用。针对Dirichlet混合样本的聚类问题,进行了最大期望(EM)算法和动态聚类算法研究。首先,推导其数学过程,并给出算法迭代步骤。然后,利用数字仿真实验,比较了EM算法与动态聚类算法两种机器学习算法在Dirichlet混合样本中的聚类效果。最后,计算对数似然函数值、程序运行时间、收敛迭代次数、聚类正确率、真正率(TPR)和假正率(FPR)6个评价指标。仿真实验结果表明,EM算法聚类正确率更高但是运算效率相对较低,而动态聚类算法运算效率较高但是损失了部分聚类正确率。因此,实际应用中建议综合权衡聚类正确率与运算效率的相对需求后,再选取合适算法进行Dirichlet混合样本聚类。
-
关键词:
- Dirichlet分布 /
- 混合样本 /
- 最大期望(EM)算法 /
- 动态聚类 /
- 机器学习
Abstract:Dirichlet distribution is a kind of continuous multivariate probability distribution with positive parameter vectors, which is widely used in proportional structure problems. Expectation maximization (EM) algorithm and dynamical clustering algorithm of Dirichlet mixture samples are presented, their mathematical process is deduced, and the iteration steps of the algorithms are given. Then, using digital simulation experiments, the clustering effects of the two machine learning algorithms with Dirichlet samples are compared. By calculating six evaluation factors which are log-likelihood function value, program running time, convergence iteration times, clustering accuracy, true positive rate (TPR) and false positive rate (FPR), the simulation results show that EM algorithm has higher clustering accuracy but lower operational efficiency, while dynamical clustering algorithm has higher operational efficiency but loses some clustering accuracy. Therefore, in practical application, it is suggested to weigh the relative requirements of accuracy and operational efficiency before selecting a suitable algorithm to cluster Dirichlet samples.
-

图 1 EM算法与动态聚类算法在300次迭代过程中的对数似然函数曲线
Figure 1. Log-likelihood function curves of EM algorithm and dynamical clustering algorithm during 300 times of iteration

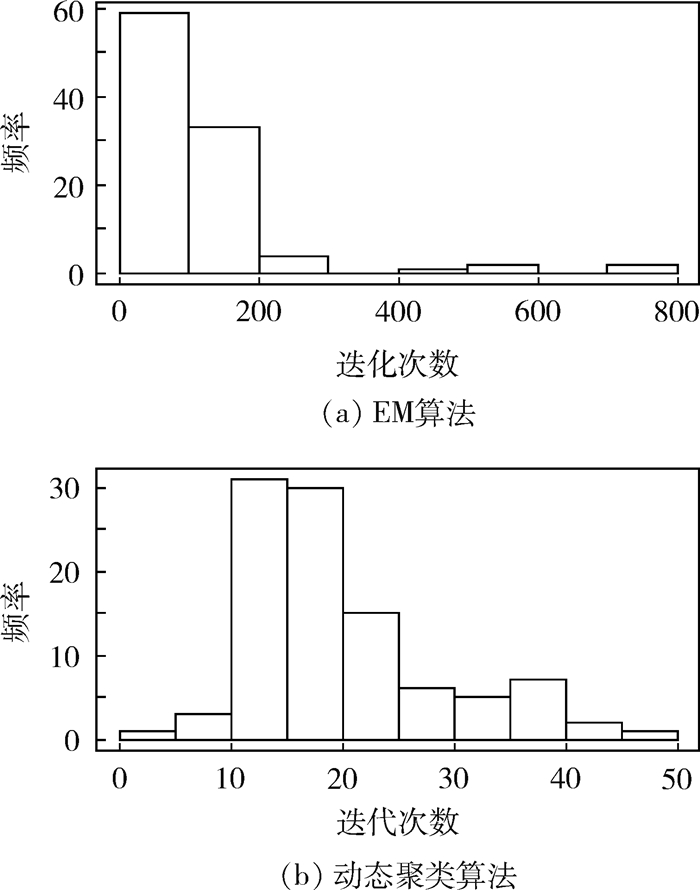
图 2 EM算法与动态聚类算法的迭代次数直方图
Figure 2. Histogram of iteration times for EM algorithm and dynamical clustering algorithm
表 1 2种算法的聚类结果
Table 1. Clustering results of two algorithms
算法 真实类别 仿真类别 1 2 EM算法 1 172 128 2 73 627 动态聚类算法 1 235 65 2 241 459  下载: 导出CSV
下载: 导出CSV
表 2 仿真实验二两种算法的结果比较
Table 2. Comparison of two algorithms' results for the second simulation experiment
评价指标 EM算法 动态聚类算法 程序运行时间/s 2.106 1.390 收敛迭代次数 121.51 20.25 聚类正确率/% 80.5 71.3 TPR/% 59.9 77.3 FPR/% 8.6 31.1
下载: 导出CSV
-
[1] FRALEY C, RAFTERY A E.Model-based clustering, discriminant analysis, and density estimation[J]. Publications of the American Statistical Association, 2002, 97(458):611-631. doi: 10.1198/016214502760047131 [2] DEMPSTER A P.Maximum likelihood from incomplete data via the EM algorithm[J].Journal of Royal Statistical Society B, 1977, 39(1):1-38. http://www.ams.org/mathscinet-getitem?mr=501537 [3] CELEUX G, GOVAERT G.Stochastic algorithms for clustering[M].Heidelberg:Physica-Verlag, 1990. [4] CELEUX G, GOVAERT G.A classification EM algorithm for clustering and two stochastic versions[J].Computational Statistics & Data Analysis, 1992, 14(3):315-332. http://dl.acm.org/citation.cfm?id=146608 [5] TANNER M A, WONG W H.The calculation of posterior distributions by data augmentation[J].Publications of the American Statistical Association, 1987, 82(398):528-540. doi: 10.1080/01621459.1987.10478458 [6] RENDER E.Mixture densities, maximum likelihood and the EM algorithm[J].SIAM Review, 1984, 26(2):195-239. doi: 10.1137/1026034 [7] PEEL D, MCLACHLAN G J.Robust mixture modelling using the t distribution[J].Statistics and Computing, 2000, 10(4):339-348. doi: 10.1023/A:1008981510081 [8] DIDAY E, SCHROEDER A, OK Y.The dynamic clusters method in pattern recognition[C]//Proceedings of International Federation for Information Processing Congress, 1974: 691-697. [9] SCOTT A J, SYMONS M J.Clustering methods based on likelihood ratio criteria[J].Biometrics, 1971, 27(1):387-397. doi: 10.2307-2529003/ [10] SYMONS M J.Clustering criteria and multivariate normal mixtures[J].Biometrics, 1981, 37(1):35-43. doi: 10.2307/2530520 [11] WONG M A, LANE T.A kTH nearest neighbour clustering procedure[J].Journal of the Royal Statistical Society, 1981, 45(3):362-368. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10.1111/j.2517-6161.1983.tb01262.x [12] BROSSIER G.Piecewise hierarchical clustering[J].Journal of Classification, 1990, 7(2):197-216. doi: 10.1007/BF01908716 [13] BISHOP C M.Neural networks for pattern recognition[M].Oxford:Oxford University Press, 1995. [14] BOCK H H.Clustering and neural networks[M]//RIZZI A, VICHI M, BOCK H H.Advances in data science and classification.Berlin: Springer, 1998: 265-277. [15] ARABIE P, CARROLL J D.Mapclus:A mathematical programming approach to fitting the adclus model[J].Psychometrika, 1980, 45(2):211-235. doi: 10.1007/BF02294077 [16] DIDAY E.An intuitive form of expression: Pyramids[D].Paris: INRIA, 1984. [17] JAMES G M, SUGAR C A.Clustering for sparsely sampled functional data[J].Publications of the American Statistical Association, 2003, 98(462):397-408. doi: 10.1198/016214503000189 [18] WINSBERG S, SOETE G D.Latent class models for time series analysis[J].Applied Stochastic Models in Business & Industry, 1999, 15(15):183-194. doi: 10.1002/(SICI)1526-4025(199907/09)15:3<183::AID-ASMB373>3.0.CO;2-T/full [19] VRAC M, BILLARD L, DIDAY E.Copula analysis of mixture models[J].Computational Statistics, 2012, 27(3):427-457. doi: 10.1007/s00180-011-0266-0 [20] KOSMIDIS I, KARLIS D.Model-based clustering using copulas with applications[J].Statistics and Computing, 2016, 26(5):1079-1099. doi: 10.1007/s11222-015-9590-5 [21] MARBAC M, BIERNACKI C, VANDEWALLE V.Model-based clustering of Gaussian copulas for mixed data[J].Communications in Statistics-Theory and Methods, 2017, 46(23):11635-11656. doi: 10.1080/03610926.2016.1277753 -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 587
- HTML全文浏览量: 56
- PDF下载量: 429
- 被引次数: 0
