



Text-to-image synthesis based on modified deep convolutional generative adversarial network
-
摘要:
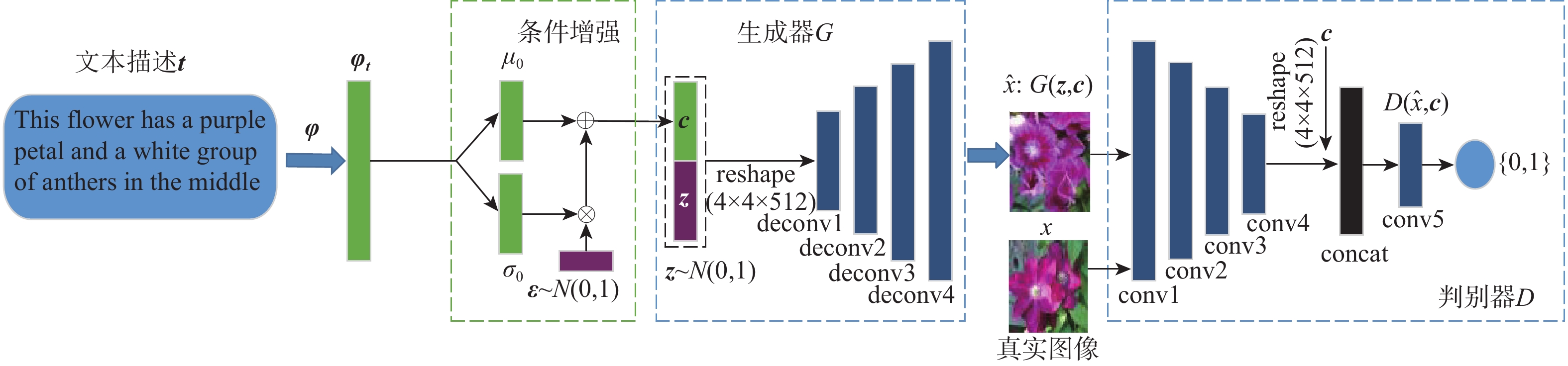
针对深度卷积生成式对抗网络(DCGAN) 模型高维文本输入表示的稀疏性导致以文本为条件生成的图像结构缺失和图像不真实的问题,提出了一种改进深度卷积生成式对抗网络模型CA-DCGAN。采用深度卷积网络和循环文本编码器对输入的文本进行编码,得到文本的特征向量表示。引入条件增强(CA)模型,通过文本特征向量的均值和协方差矩阵产生附加的条件变量,代替原来的高维文本特征向量。将条件变量与随机噪声结合作为生成器的输入,并在生成器的损失中额外加入KL损失正则化项,避免模型训练过拟合,使模型可以更好的收敛,在判别器中使用谱约束(SN)层,防止其梯度下降太快造成生成器与判别器不平衡训练而发生模式崩溃的问题。实验验证结果表明:所提模型在Oxford-102-flowers和CUB-200数据集上生成的图像质量较alignDRAW、GAN-CLS、GAN-INT-CLS、StackGAN(64×64)、StackGAN-v1(64×64)模型更好且接近于真实样本,初始得分值最低分别提高了10.9%和5.6%,最高分别提高了41.4%和37.5%,FID值最低分别降低了11.4%和8.4%,最高分别降低了43.9%和42.5%,进一步表明了所提模型的有效性。
-
关键词:
- 深度卷积生成式对抗网络 /
- 文本生成图像 /
- 文本特征表示 /
- 条件增强 /
- KL正则化
Abstract:When high-dimensional texts are adopted as input,images generated by the previously proposed deep convolutional generative adversarial network (DCGAN) model usually suffer from distortions and structure degradation due to the sparsity of texts, which seriously poses a negative impact on the generative performance. To address this issue, an improved deep convolutional generative adversarial network model, CA-DCGAN is proposed. Technically, a deep convolutional network and a recurrent text encoder are simultaneously employed to encode the input text so that the corresponding text embedding representation can be obtained. Then, a conditional augmentation (CA) model is introduced to generate an additional condition variable to replace the original high-dimensional text feature. Finally, the conditional variable and random noise are combined as the input of the generator. Meanwhile, to avoid over-fitting and promote the convergence,we introduce a KL regularization term into the generator’s loss. Moreover, we adopt a spectral normalization (SN) layer in the discriminator to prevent the mode collapse caused by the unbalanced training due to the fast gradient descent of the discriminator. The experimental verification results show that the proposed model on the Oxford-102-flowers and CUB-200 datasets is better than that of alignDRAW, GAN-CLS, GAN-INT-CLS, StackGAN (64×64), StackGAN-vl (64×64) in terms of the quality of generated images. The results show that the lowest inception score increased by 10.9% and 5.6% respectively, the highest inception score increased by 41.4% and 37.5% respectively, while the lowest FID index value decreased by 11.4% and 8.4% respectively,the highest FID index value decreased by 43.9% and 42.5% respectively,which further validate the effectiveness of the proposed method.
-

图 5 alignDRAW、GAN-CLS、GAN-INT-CLS、CA-DCGAN在Oxford-102-flowers数据集上生成结果比较
Figure 5. Comparison of generated results by alignDRAW, GAN-CLS,GAN-INT-CLS,CA-DCGAN models on Oxford-102-flowers dataset

图 6 alignDRAW、GAN-CLS、GAN-INT-CLS、CA-DCGAN在CUB-200数据集上生成结果比较
Figure 6. Comparison of generated results by alignDRAW,GAN-CLS,GAN-INT-CLS,CA-DCGAN models on CUB-200 dataset

图 7 StackGAN(64×64)、StackGAN-v1(64×64)与CA-DCGAN模型在Oxford-102-flowers和CUB-200数据集上生成结果比较
Figure 7. Comparison of generated results by StackGAN(64×64), StackGAN-v1(64×64) and CA-DCGAN models on Oxford-102-flowers dataset and CUB-200 dataset

图 8 GAN-CLS、GAN-INT-CLS、CA-DCGAN在Oxford-102-flowers数据集上生成图像多样性对比
Figure 8. Comparison of image diversity generated by GAN-CLS,GAN-INT-CLS and CA-DCGAN on Oxford-102-flowers dataset

图 9 GAN-CLS、GAN-INT-CLS、CA-DCGAN在CUB-200数据集上生成图像多样性对比
Figure 9. Comparison of image diversity generated by GAN-CLS,GAN-INT-CLS and CA-DCGAN on CUB-200 dataset
表 1 实验数据集
Table 1. Experimental datasets
数据集 图像数量 文本描述/图像 类别 Oxford-102-flowers 训练集 7034 10 102 测试集 1155 10 102 CUB-200 训练集 8855 10 200 测试集 2933 10 200  下载: 导出CSV
下载: 导出CSV
表 2 不同模型在Oxford-102-flowers和CUB-200数据集上GIS值比较
Table 2. GIS comparison of different models on Oxford-102-flowers and CUB-200 datasets
下载: 导出CSV
表 3 不同模型在Oxford-102-flowers和CUB-200数据集上GFID值比较
Table 3. GFID comparison of different models on Oxford-102-flowers and CUB-200 datasets
下载: 导出CSV
表 4 KL引入后指标变化对比
Table 4. Comparison of index change on KL’s introduction
模型 GIS GFID Oxford-102-flowers CUB-200 Oxford-102-flowers CUB-200 Baseline 2.91 3.12 69.75 60.24 Baseline +KL,=1 2.95 3.14 63.34 54.56 Baseline +KL,=2 3.04 3.19 54.36 50.92 Baseline +KL,=5 2.92 3.11 65.49 59.51 Baseline +KL,=10 2.89 3.06 68.47 63.89
下载: 导出CSV
-
[1] ZHOU K Y, YANG Y X, HOSPEDALES T, et al. Deep domain-adversarial image generation for domain generalisation[C]//34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI, 2020, 34: 13025-13032. [2] 陆婷婷, 李潇, 张尧, 等. 基于三维点云模型的空间目标光学图像生成技术[J]. 北京航空航天大学学报, 2020, 46(2): 274-286.LU T T, LI X, ZHANG Y, et al. A technology for generation of space object optical image based on 3D point cloud model[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(2): 274-286(in Chinese). [3] ZHANG Z, XIE Y, YANG L. Photographic text-to-image synthesis with a hierarchically-nested adversarial network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6199-6208. [4] 牛蒙蒙, 沈明瑞, 秦波, 等. 基于GAN的刀具状态监测数据集增强方法[J]. 组合机床与自动化加工技术, 2021(4): 113-115. doi: 10.13462/j.cnki.mmtamt.2021.04.027NIU M M, SHEN M R, QIN B, et al. A data augmentation method based on GAN in tool condition monitoring[J]. Combined Machine Tool and Automatic Machining Technology, 2021(4): 113-115(in Chinese). doi: 10.13462/j.cnki.mmtamt.2021.04.027 [5] VENDROV I, KIROS R, FIDLER S, et al. Order-embeddings of images and language[EB/OL]. (2016-03-01)[2021-09-01]. [6] MANSIMOV E, PARISOTTO E, BA J L, et al. Generating images from captions with attention[EB/OL]. (2016-02-29)[2021-09-01]. [7] GREGOR K, DANIHELKA I, GRAVES A, et al. DRAW: A recurrent neural network for image generation[C]//Proceedings of the 32nd International Conference on Machine Learning. New York: ACM, 2015: 1462-1471. [8] REED S, VAN DEN OORD A, KALCHBRENNER N, et al. Generating interpretable images with controllable structure[C]//5th International Conference on Learning Representations, Appleton, WI: ICLR, 2016. [9] NGUYEN A, CLUNE J, BENGIO Y, et al. Plug & play generative networks: Conditional iterative generation of images in latent space[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 17355648. [10] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2672-2680. [11] MIRZA M, OSINDERO S. Conditional generative adversarial nets[EB/OL]. (2014-10-06)[2021-09-01]. [12] SCHUSTER M, PALIWAL K K. Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing, 2002, 45(11): 2673-2681. [13] RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[C]//4th International Conference on Learning Representations, Appleton, WI: ICLR, 2016. [14] REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis[C]//Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 1060-1069. [15] REED S, AKATA Z, LEE H, et al. Learning deep representations of fine-grained visual descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 49-58. [16] NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes[C]//Proceedings of the IEEE Conference on Computer Vision, Graphics and Image Processing. Piscataway: IEEE Press, 2008: 722-729. [17] WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD birds-200-2011 dataset: CNS-TR-2011-001[R]. Pasadena: California Institute of Technology, 2011. [18] SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs[C]//30th Conference on Neural Information Processing Systems, Cambridge: MIT Press, 2016: 2234-2242. [19] HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2017: 6626-6637. [20] ZHANG H, XU T, LI H, et al. StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 5907-5915. [21] ZHANG H, XU T, LI H, et al. StackGAN++: Realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 1947-1962. doi: 10.1109/TPAMI.2018.2856256 期刊类型引用(1)
1. 赵宏,李文改. 基于扩散生成对抗网络的文本生成图像模型研究. 电子与信息学报. 2023(12): 4371-4381 .  百度学术
百度学术其他类型引用(4)
-

 下载:
下载:


 百度学术
百度学术
 点击查看大图
点击查看大图
计量
- 文章访问数: 581
- HTML全文浏览量: 186
- PDF下载量: 113
- 被引次数: 5
