



-
摘要:
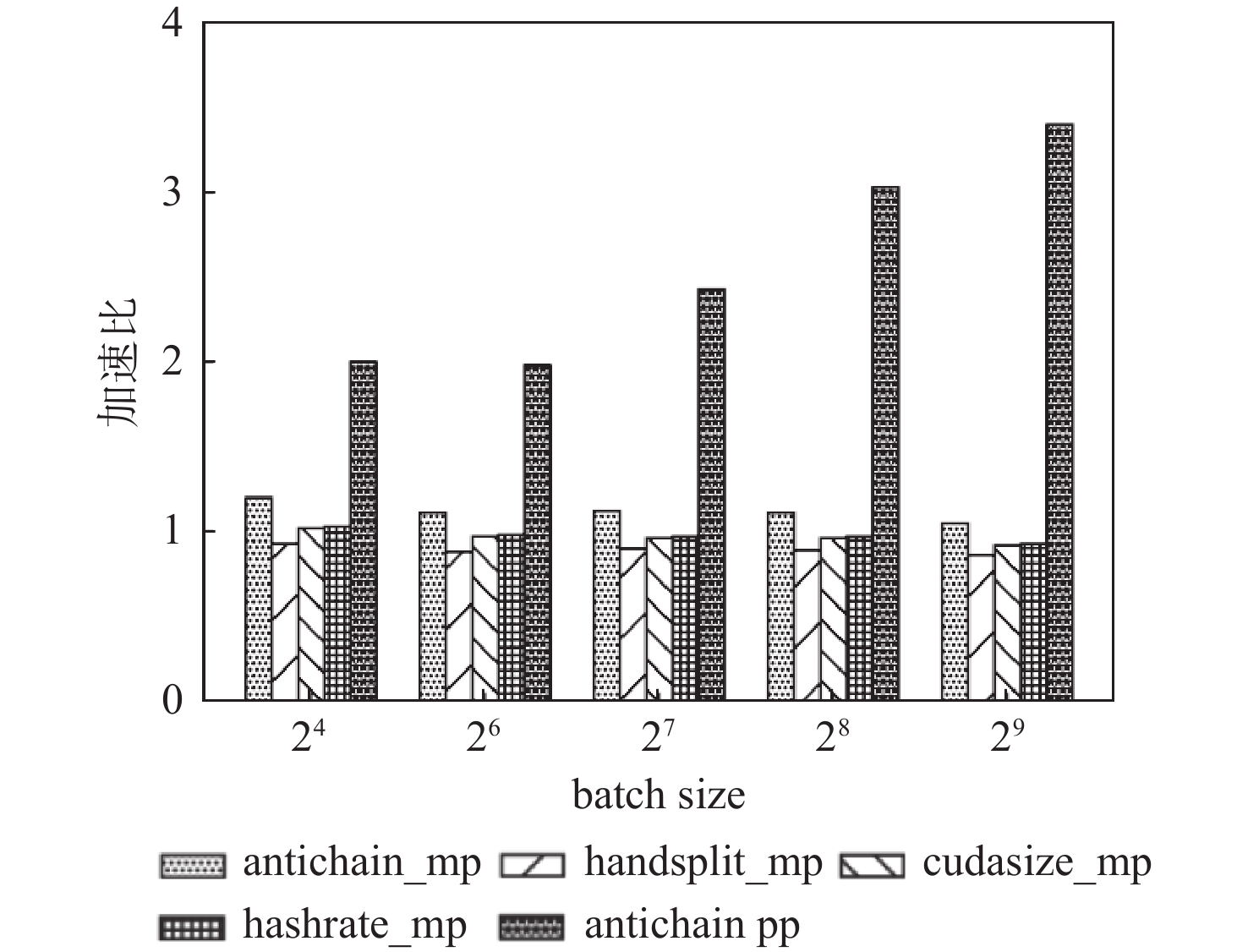
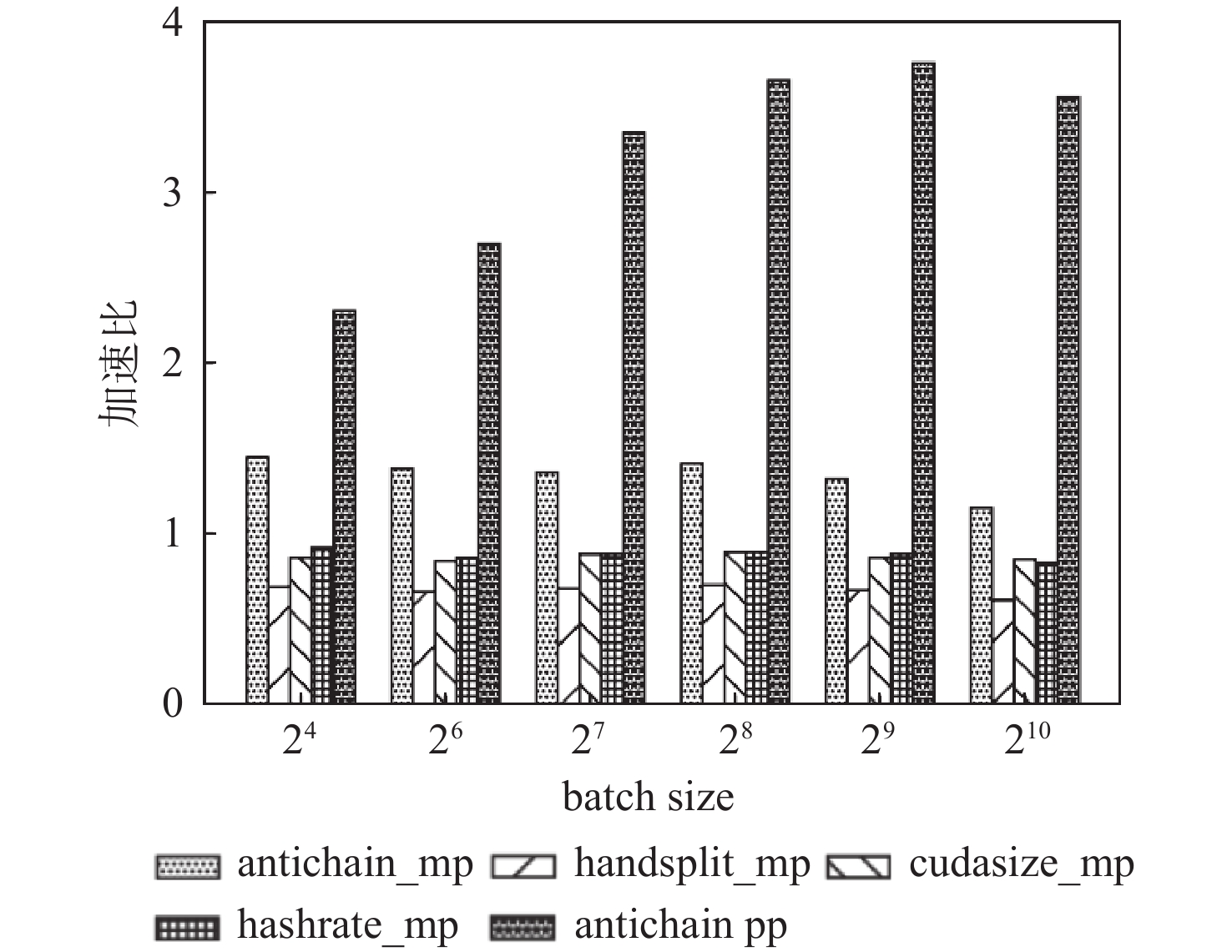
为解决传统手工切分神经网络模型计算任务并行化方法面临的并行化难度大、训练耗时长、设备利用率低等问题,提出了一种基于深度神经网络(DNN)模型特性感知的任务切分及并行优化方法。结合硬件计算环境,对模型计算特性进行动态分析,获取模型内部相关性和各类参数属性,构建原始计算任务有向无环图(DAG);利用增强反链,构建DAG节点间可分区聚类的拓扑关系,将原始DAG转换为易于切分的反链DAG;通过拓扑排序生成反链DAG状态序列,并使用动态规划将状态序列切分为不同执行阶段,分析最佳分割点进行模型切分,实现模型分区与各GPU间动态匹配;对批量进行微处理,通过引入流水线并行实现多迭代密集训练,提高GPU利用率,减少训练耗时。实验结果表明:与已有模型切分方法相比,在CIFAR-10数据集上,所提模型切分及并行优化方法可实现各GPU间训练任务负载均衡,在保证模型训练精度的同时,4 GPU加速比达到3.4,8 GPU加速比为3.76。
-
关键词:
- 深度神经网络模型并行 /
- 模型切分 /
- 流水线并行 /
- 反链 /
- 并行优化
Abstract:In order to solve the problems of difficult parallelization, long training time, and low equipment utilization in the traditional parallelization method of manually partitioning computing tasks of the neural network model, a task segmentation and parallel optimization method based on feature perception of deep neural network (DNN) model was proposed.Firstly, in the hardware computing environment, the computing characteristics of the model were dynamically analyzed to obtain the internal correlation and various parameter attributes of the model, and the directed acyclic graph (DAG) of original computing tasks was constructed. Secondly, the topological relationship of DAG nodes that could be partitioned into clusters was constructed by using augmented antichain, and the original DAG was transformed into an antichain DAG for easy partition. Thirdly, the antichain DAG state sequence was generated by topological sorting, and the state sequence was divided into different execution stages by dynamic programming.The optimal segmentation points were analyzed to divide the model and achieve dynamic matching between the model partition and each GPU. Finally, micro-processing in batches was carried out, and multi-iteration intensive training was realized by introducing pipeline parallelization, which improved GPU utilization and reduced training time. The experimental results show that on the CIFAR-10 dataset, compared with the existing model segmentation methods, the proposed model segmentation and parallel optimization method can balance the training task load among GPUs. The 4 GPU speedup reaches 3.4, and the 8 GPU speedup reaches 3.76 while ensuring the model training accuracy.
-
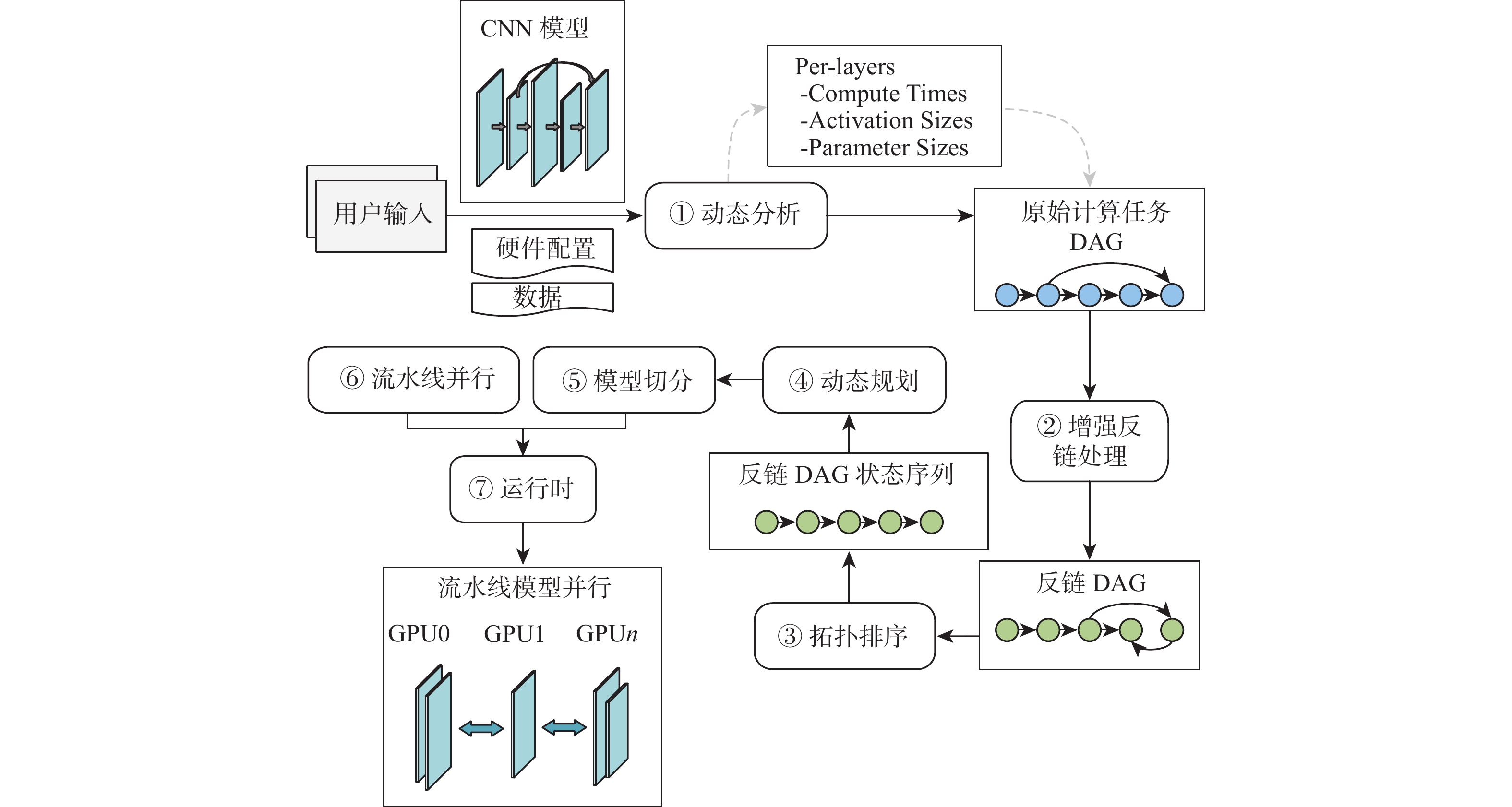
图 1 深度神经网络模型切分及并行优化计算框架
Figure 1. Deep neural network model segmentation and parallel optimization computation framework
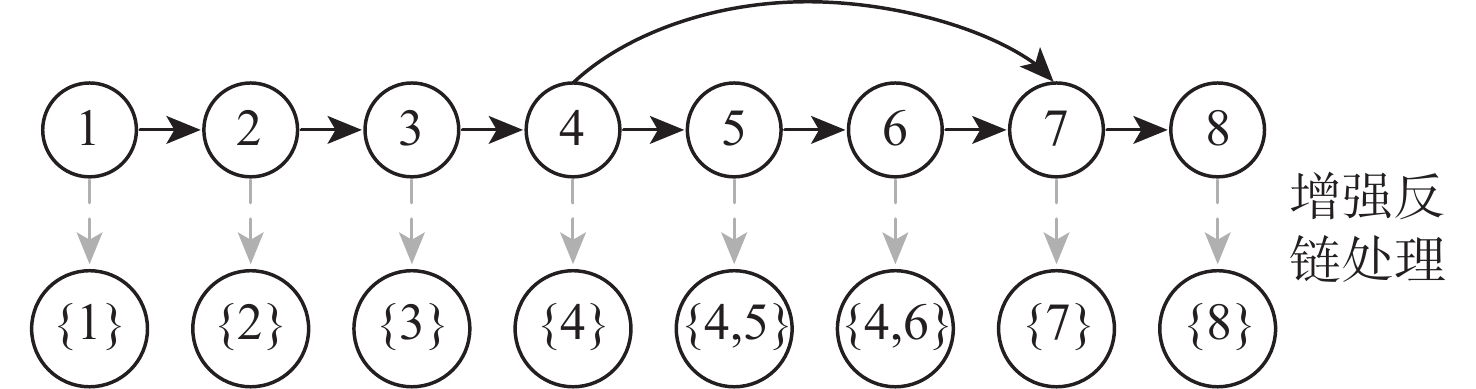
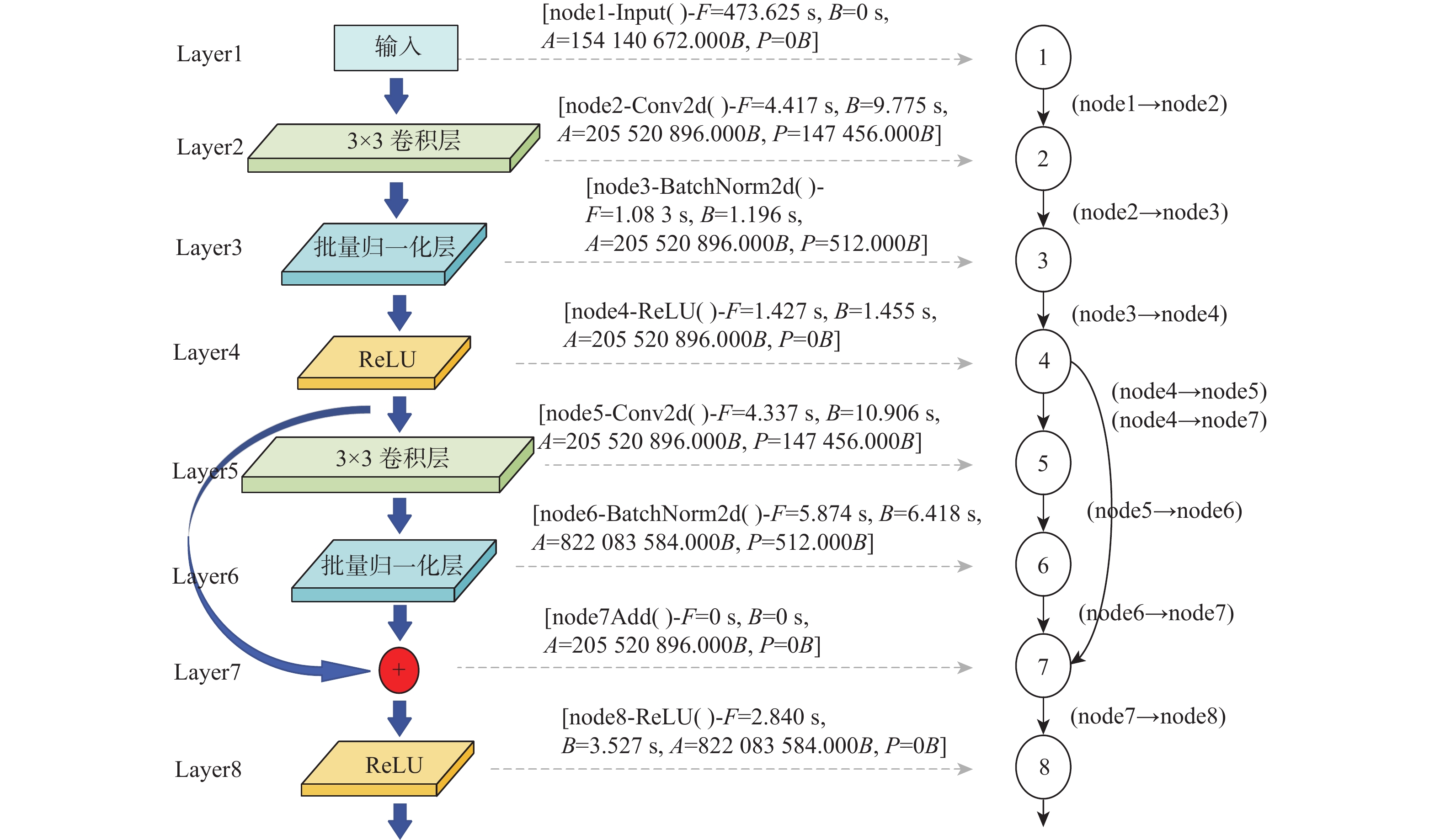
图 3 原始DAG和各节点对应的增强反链
Figure 3. Original DAG and corresponding augmented antichain of each node
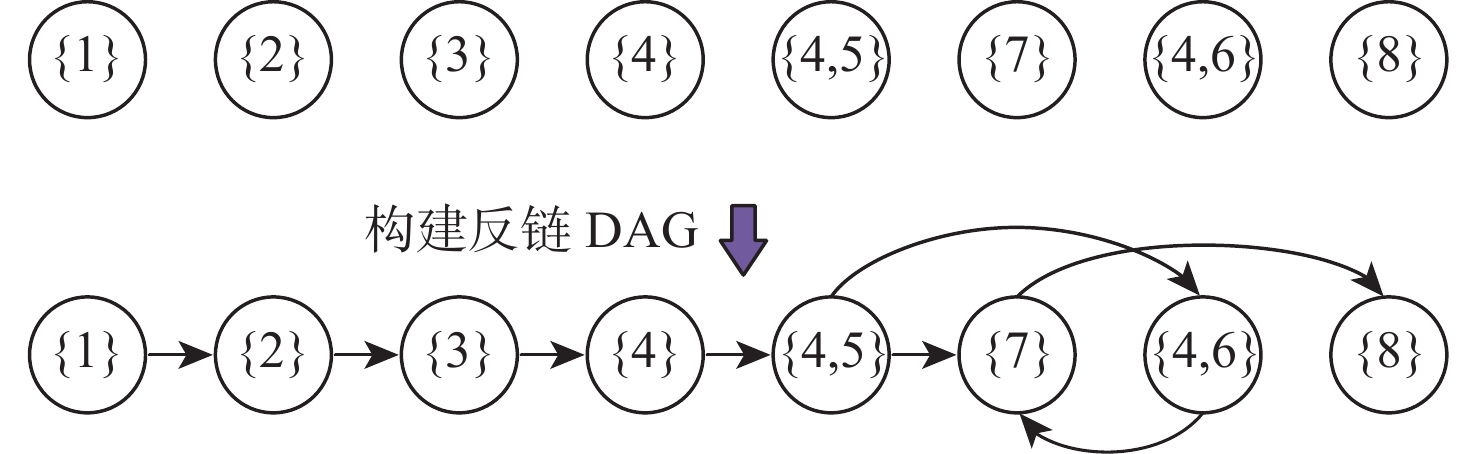
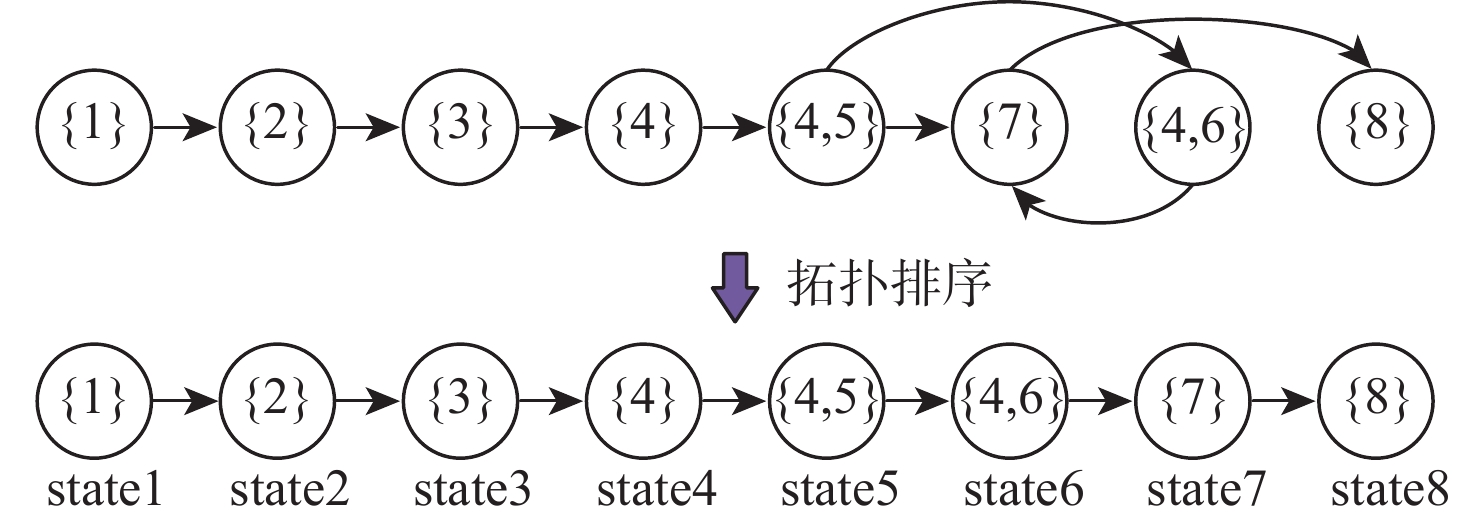
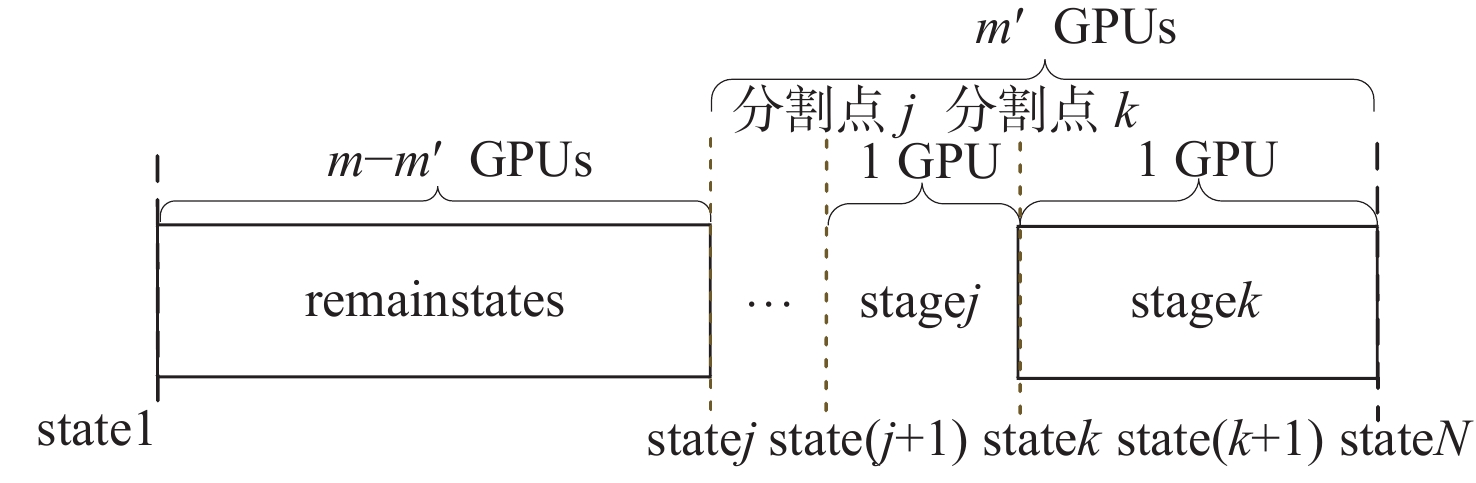
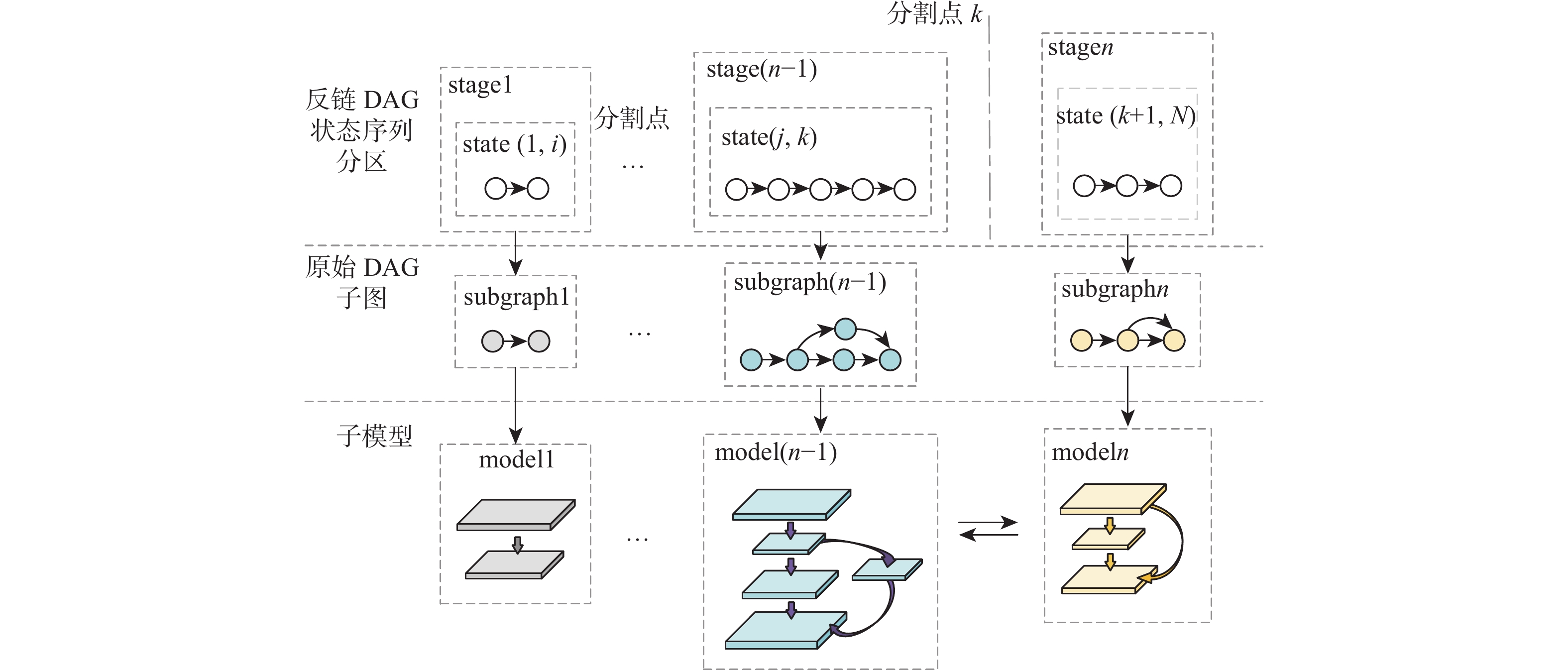
图 4 原始DAG各节点增强反链及构建反链DAG
Figure 4. Augmented antichain of each node of original DAG and construction of antichain DAG
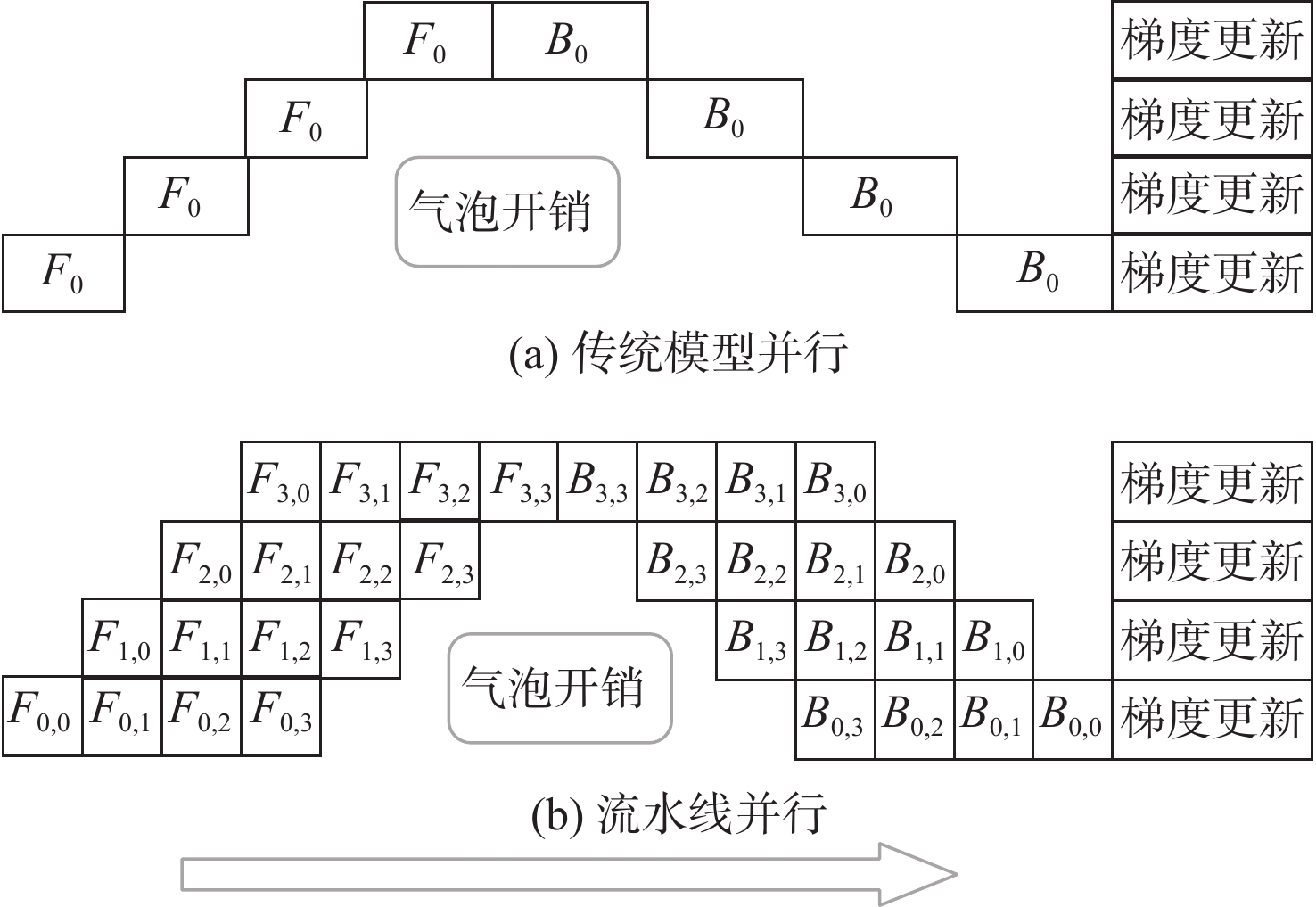
图 6 传统模型并行和流水线并行
Figure 6. Traditional model parallelization andpipeline parallelization
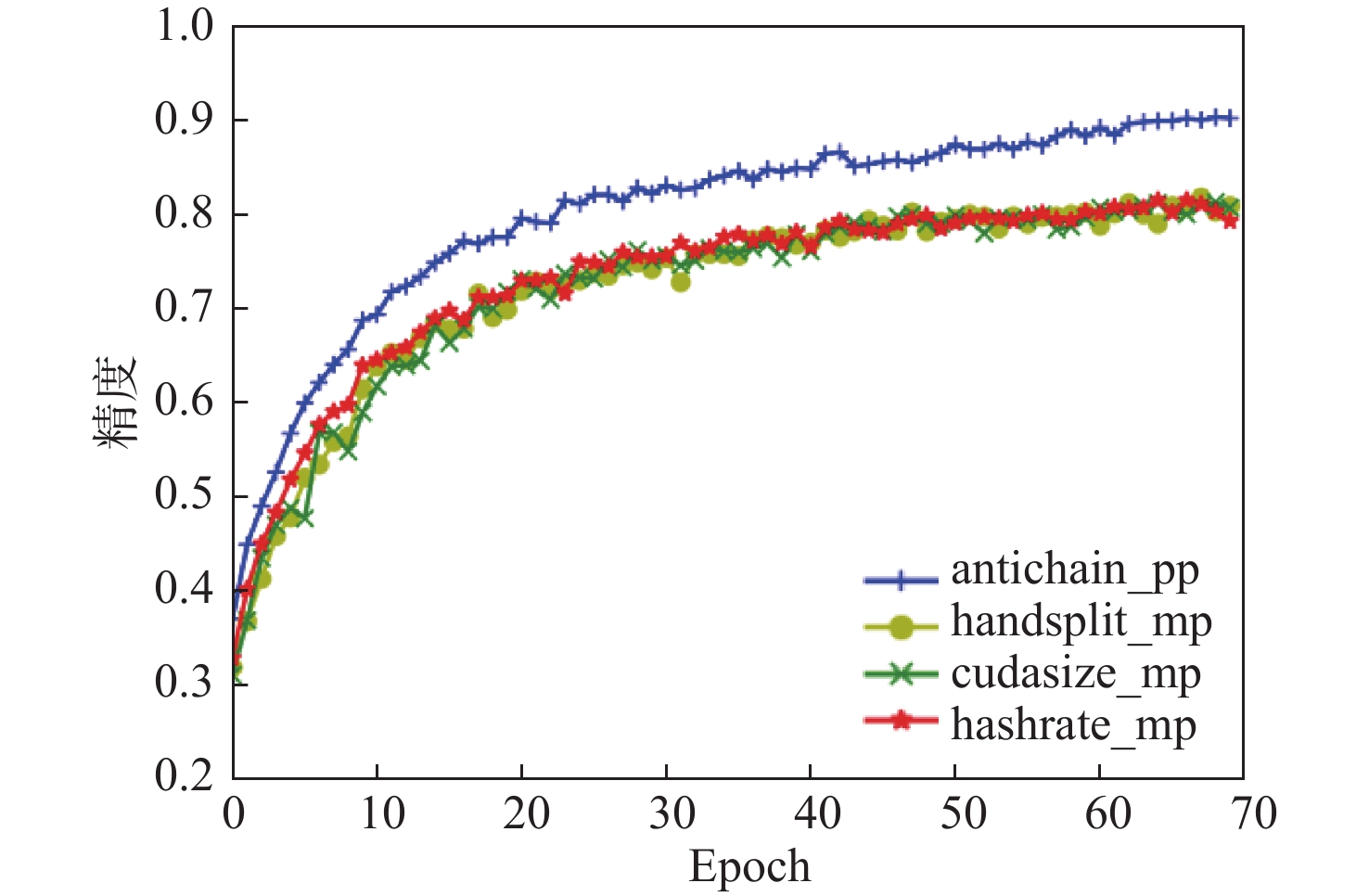
图 13 4 GPU不同切分方法并行训练精度
Figure 13. Parallel training accuracy of 4 GPU with different segmentation methods
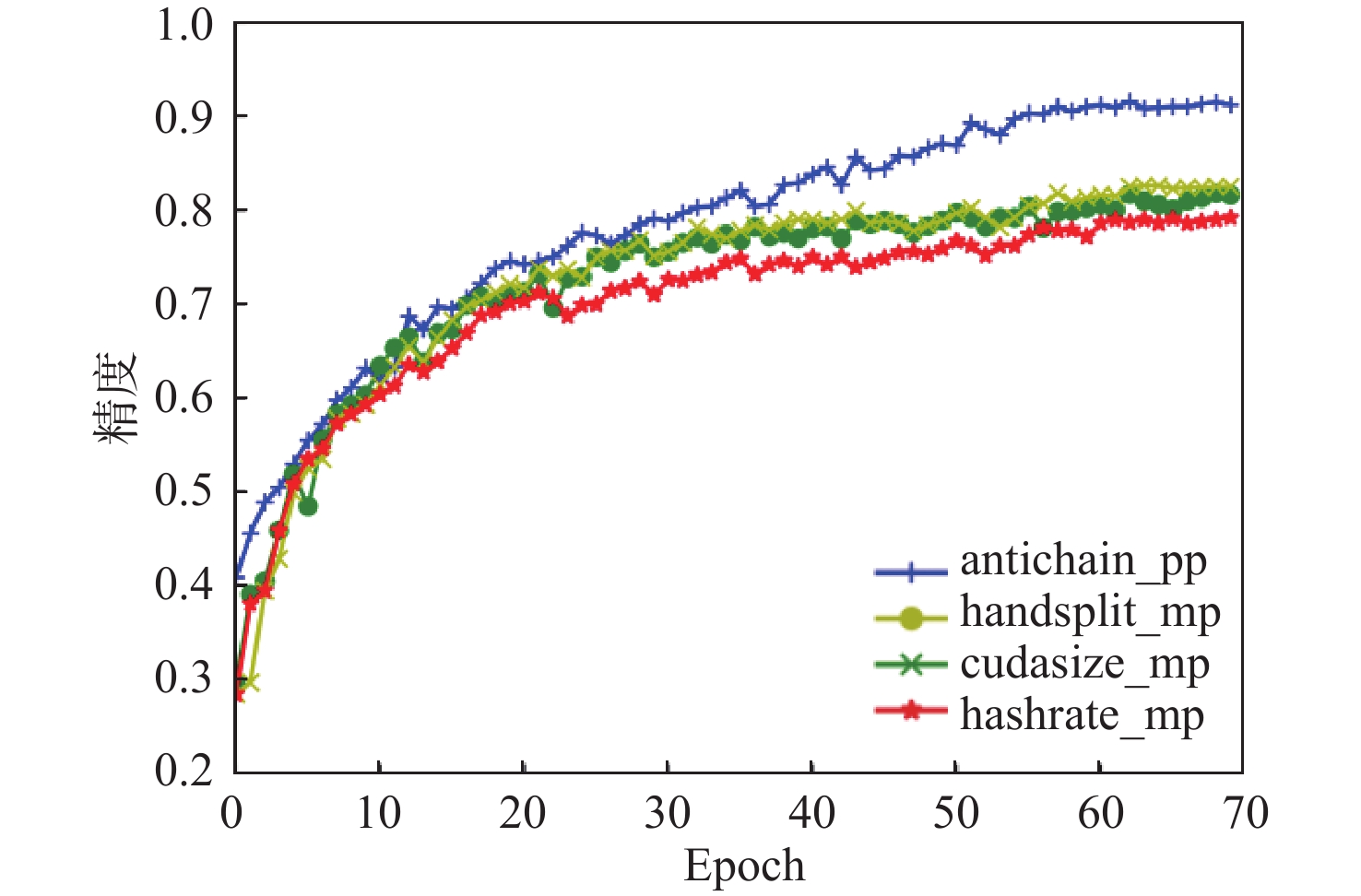
图 14 8 GPU不同切分方法并行训练精度
Figure 14. Parallel training accuracy of 8 GPU with different segmentation methods
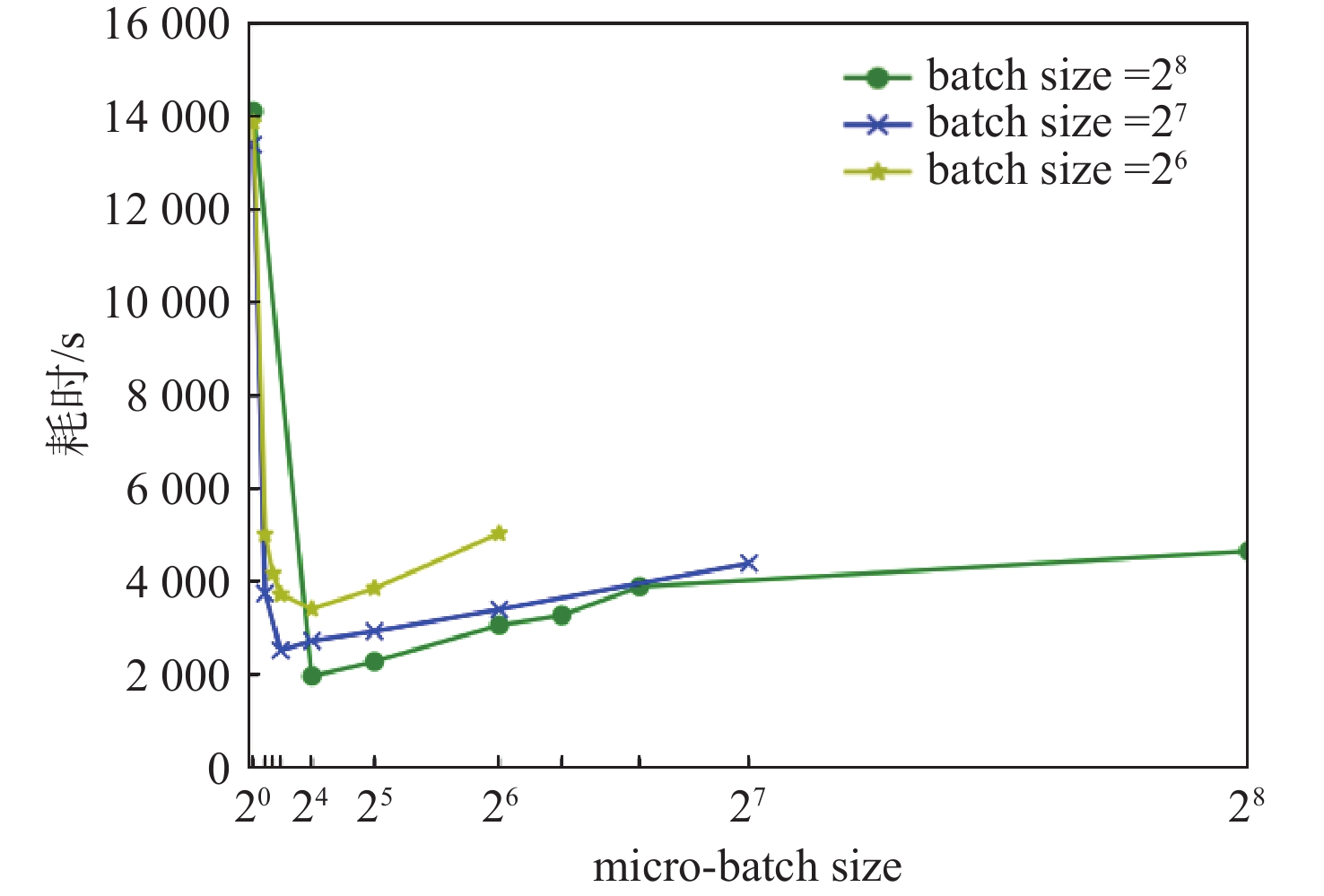
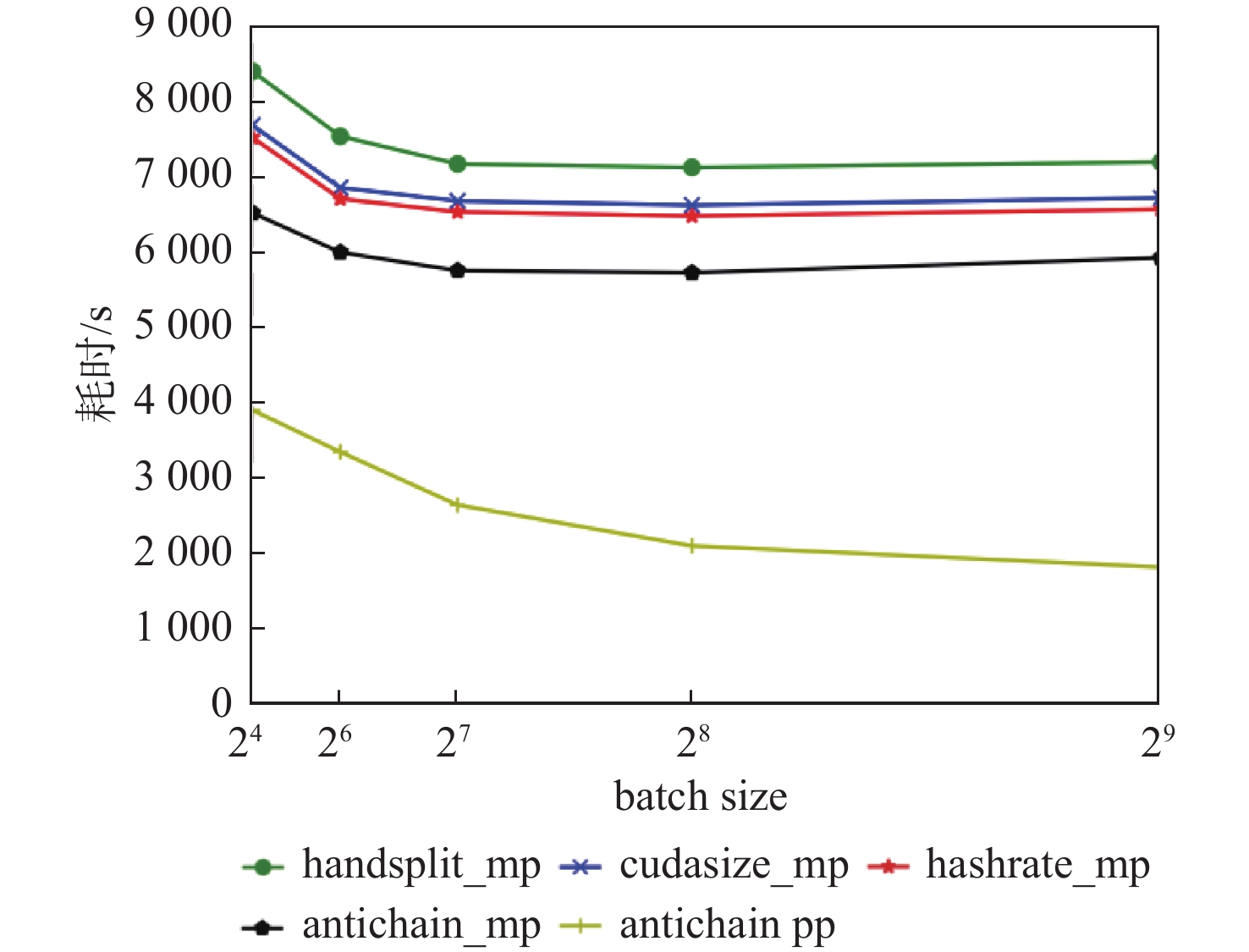
图 15 4 GPU不同微批量大小流水线并行训练耗时
Figure 15. Parallel training time of 4 GPU pipeline with different micro-batch sizes
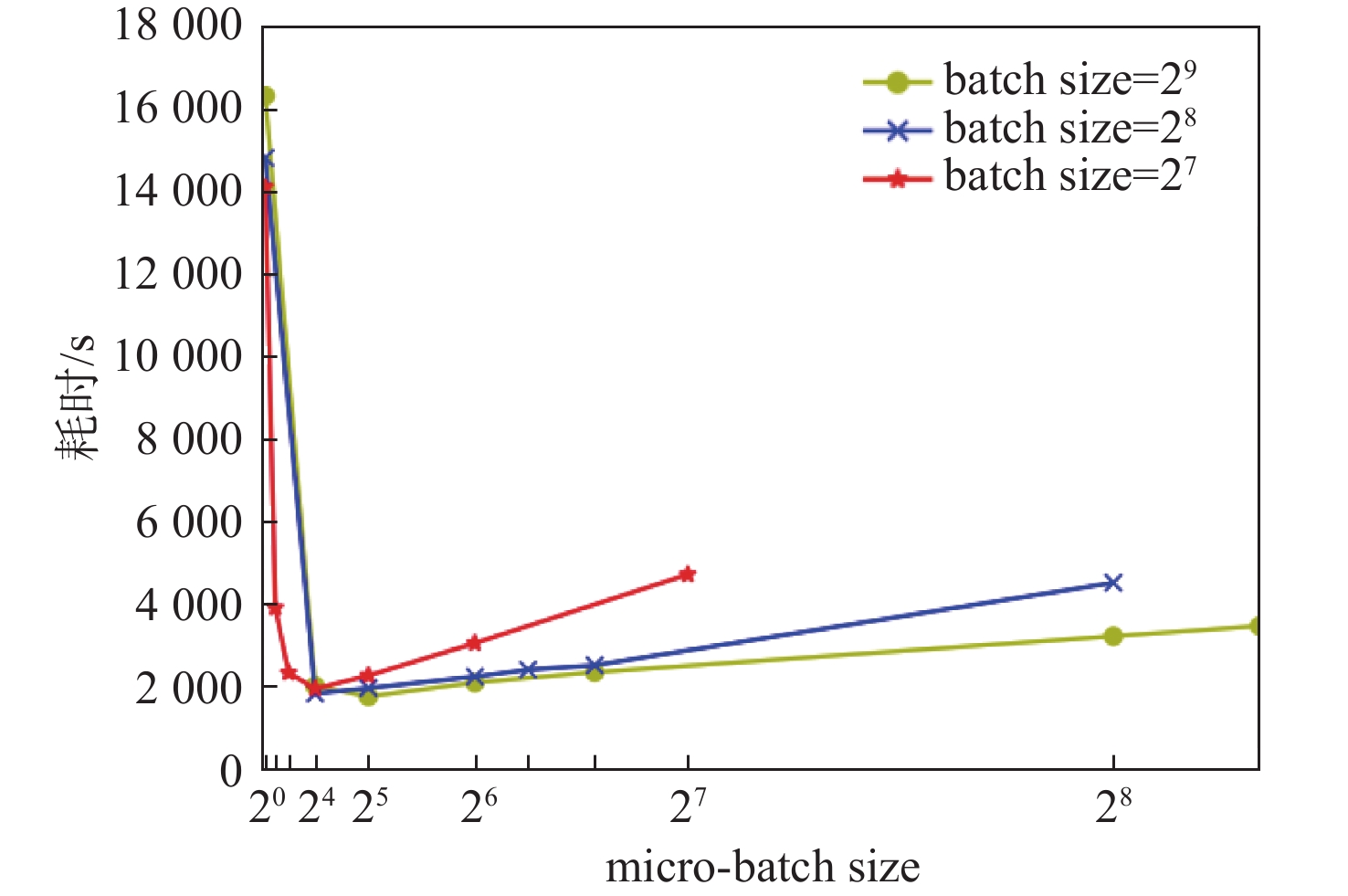
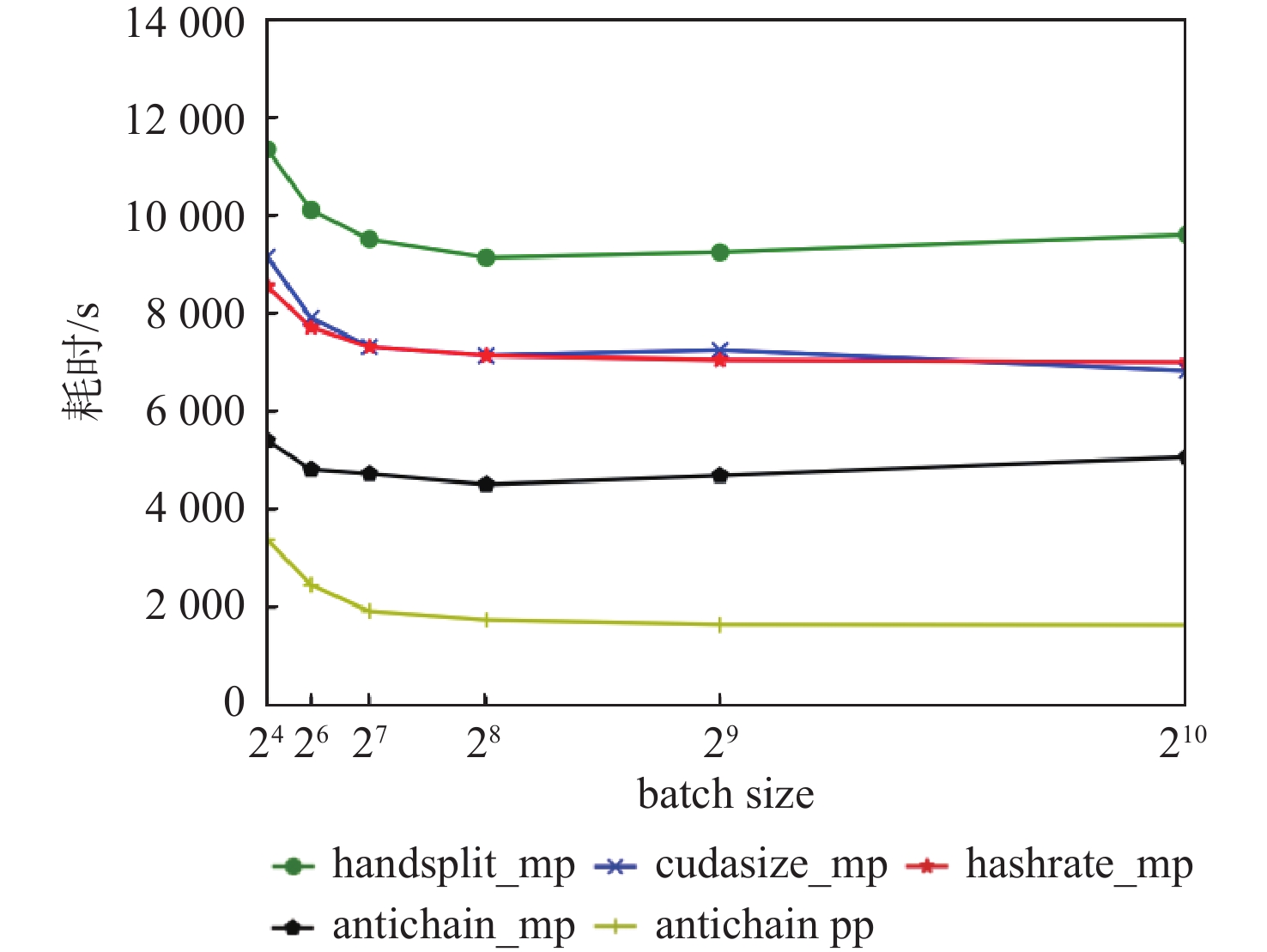
图 16 8 GPU不同微批量大小流水线并行训练耗时
Figure 16. Parallel training timeof 8 GPU pipeline with different micro-batch sizes
表 1 不同模型切分方法在4 GPU和8 GPU上的耗时对比
Table 1. Time consumption comparison of different model segmentation methods on 4 GPU and 8 GPU
模型 GPU数 handsplit_mp 耗时/min cudasize_mp 耗时/s hashrate_mp 耗时/s 本文方法耗时/s VGG-16[33] 4 30 6.76 8.72 0.01 8 >60 7.84 9.34 0.03 ResNet-18[34] 4 35 1.98 2.14 0.07 8 >60 3.02 4.11 0.21 ResNet-50 4 45[36] 2.76 3.56 0.38 8 >60 3.80 6.31 1.17 ResNet-101 4 >60 4.12 5.78 1.20 8 >60 5.89 9.24 3.69 AlexNet 4 >60 7.12 8.45 0.02 8 >60 8.94 10.26 0.01 ResNext-50 4 >60 2.79 3.72 0.41 8 >60 4.97 8.11 1.17 ResNext-101 4 >60 4.53 6.01 1.21 8 >60 6.12 8.37 3.58 Inception-v3[35] 4 >60 2.64 12.25 3.07 8 >60 3.76 6.23 4.12 DenseNet-121[37] 4 >60 1.28 1.59 1.29 8 >60 3.86 4.11 3.73 SqueezeNet1_0[38] 4 >60 2.73 3.59 0.06 8 >60 8.46 4.27 0.20  下载: 导出CSV
下载: 导出CSV
-
[1] KIM Y, CHOI H, LEE J, et al. Efficient large-scale deep learning framework for heterogeneous multi-GPU cluster[C]//Proceedings of the IEEE 4th International Workshops on Foundations and Applications of Self Systems. Piscataway: IEEE Press, 2019: 176-181. [2] NARAYANAN D, PHANISHAYEE A, SHI K, et al. Memory-efficient pipeline-parallel dnn training[C]//Proceedings of the International Conference on Machine Learning. New York: PMLR Press, 2021: 7937-7947. [3] 朱泓睿, 元国军, 姚成吉, 等. 分布式深度学习训练网络综述[J]. 计算机研究与发展, 2021, 58(1): 98-115. doi: 10.7544/issn1000-1239.2021.20190881ZHU H R, YUAN G J, YAO C J, et al. Survey on network of distributed deep learning training[J]. Journal of Computer Research and Development, 2021, 58(1): 98-115(in Chinese). doi: 10.7544/issn1000-1239.2021.20190881 [4] TAN M, LE Q. EfficientNet: Rethinking model scaling for convolutional neural networks[C]//Proceedings of the International Conference on Machine Learning. New York: PMLR Press, 2019: 6105-6114. [5] LEE S, KIM J K, ZHENG X, et al. On model parallelization and scheduling strategies for distributed machine learning[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. New York: ACM, 2014: 2834-2842. [6] KIM J K, HO Q, LEE S, et al. STRADS: A distributed framework for scheduled model parallel machine learning[C]//Proceedings of the 11th European Conference on Computer Systems. New York: ACM, 2016: 1-16. [7] 朱虎明, 李佩, 焦李成, 等. 深度神经网络并行化研究综述[J]. 计算机学报, 2018, 41(8): 1861-1881. doi: 10.11897/SP.J.1016.2018.01861ZHU H M, LI P, JIAO L C, et al. Review of parallel deep neural network[J]. Chinese Journal of Computers, 2018, 41(8): 1861-1881(in Chinese). doi: 10.11897/SP.J.1016.2018.01861 [8] KRIZHEVSKY A. One weird trick for parallelizing convolutional neural networks[EB/OL]. (2014-04-26)[2022-08-15]. [9] BÁRÁNY I, GRINBERG V S. Block partitions of sequences[J]. Israel Journal of Mathematics, 2015, 206(1): 155-164. doi: 10.1007/s11856-014-1137-5 [10] MIRHOSEINI A, PHAM H, LE Q V, et al. Device placement optimization with reinforcement learning[C]//Proceedings of the International Conference on Machine Learning. New York: PMLR Press, 2017: 2430-2439. [11] DING Z X, CHEN Y R, LI N N, et al. Device placement optimization for deep neural networks via one-shot model and reinforcement learning[C]//Proceedings of the IEEE Symposium Series on Computational Intelligence. Piscataway: IEEE Press, 2020: 1478-1484. [12] JIA Z, ZAHARIA M, AIKEN A. Beyond data and model parallelism for deep neural networks[EB/OL]. (2018-07-14)[2022-08-15]. [13] KIM C, LEE H, JEONG M, et al. Torchgpipe: On-the-fly pipeline parallelism for training giant models[EB/OL]. (2020-04-21)[2022-08-15]. [14] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [15] ZOPH B, VASUDEVAN V, SHLENS J, et al. Learning transferable architectures for scalable image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8697-8710. [16] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24)[2022-08-15]. [17] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. New York: ACM, 2020: 1877-1901. [18] SHOEYBI M, PATWARY M, PURI R, et al. Megatron-LM: Training multi-billion parameter language models using model parallelism[EB/OL]. (2020-03-13)[2022-08-15]. [19] NARAYANAN D, SHOEYBI M, CASPER J, et al. Efficient large-scale language model training on GPU clusters using megatron-LM[C]//Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2021: 1-15. [20] YUAN K, LI Q Q, SHAO J, et al. Learning connectivity of neural networks from a topological perspective[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2020: 737-753. [21] FORTUNATO S. Community detection in graphs[J]. Physics Reports, 2010, 486(3-5): 75-174. doi: 10.1016/j.physrep.2009.11.002 [22] VASILIAUSKAITE V, EVANS T S. Making communities show respect for order[J]. Applied Network Science, 2020, 5(1): 15. doi: 10.1007/s41109-020-00255-5 [23] VASILIAUSKAITE V, EVANS T S, EXPERT P. Cycle analysis of directed acyclic graphs[J]. Physica A: Statistical Mechanics and its Applications, 2022, 596: 127097. doi: 10.1016/j.physa.2022.127097 [24] HUANG Y, CHENG Y, BAPNA A, et al. GPipe: Efficient training of giant neural networks using pipeline parallelism[C]//Proceedings of the 33rd Internatioanl Conference on Neural Information Processing Systems. New York: ACM, 2019: 103-112. [25] GENG J K, LI D, WANG S. ElasticPipe: An efficient and dynamic model-parallel solution to DNN training[C]//Proceedings of the 10th Workshop on Scientific Cloud Computing. New York: ACM, 2019: 5-9. [26] HARLAP A, NARAYANAN D, PHANISHAYEE A, et al. PipeDream: Fast and efficient pipeline parallel DNN training[EB/OL]. (2018-06-08)[2022-08-15]. [27] RASLEY J, RAJBHANDARI S, RUWASE O, et al. DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2020: 3505-3506. [28] YANG B, ZHANG J, LI J, et al. PipeMare: Asynchronous pipeline parallel DNN training[EB/OL]. (2020-02-09) [2022-08-15]. [29] NARAYANAN D, HARLAP A, PHANISHAYEE A, et al. PipeDream: Generalized pipeline parallelism for DNN training[C]//Proceedings of the 27th ACM Symposium on Operating Systems Principles. New York: ACM, 2019: 1-15. [30] GUAN L, YIN W, LI D, et al. XPipe: Efficient pipeline model parallelism for multi-GPU DNN training[EB/OL]. (2020-11-09)[2022-08-15]. [31] FAN S Q, RONG Y, MENG C, et al. DAPPLE: A pipelined data parallel approach for training large models[C]//Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. New York: ACM, 2021: 431-445. [32] RAJBHANDARI S, RASLEY J, RUWASE O, et al. ZeRO: Memory optimizations toward training trillion parameter models[C]//Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Piscataway: IEEE Press, 2020: 1-16. [33] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2022-08-15]. [34] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [35] ZAREMBA W, SUTSKEVER I, VINYALS O. Recurrent neural network regularization[EB/OL]. (2015-02-19)[2022-08-15]. [36] 王丽, 郭振华, 曹芳, 等. 面向模型并行训练的模型拆分策略自动生成方法[J]. 计算机工程与科学, 2020, 42(9): 1529-1537. doi: 10.3969/j.issn.1007-130X.2020.09.002WANG L, GUO Z H, CAO F, et al. An automatic model splitting strategy generation method for model parallel training[J]. Computer Engineering & Science, 2020, 42(9): 1529-1537(in Chinese). doi: 10.3969/j.issn.1007-130X.2020.09.002 [37] HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 4700-4708. [38] IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB modelsize[EB/OL]. (2016-11-04)[2022-08-15]. 期刊类型引用(1)
1. 巨涛,刘帅,火久元,张学军. 深度神经网络模型并行自适应计算任务调度方法. 吉林大学学报(工学版). 2024(12): 3601-3613 .  百度学术
百度学术其他类型引用(1)
-

 下载:
下载:
 百度学术
百度学术
 点击查看大图
点击查看大图
计量
- 文章访问数: 413
- HTML全文浏览量: 137
- PDF下载量: 39
- 被引次数: 2
