



-
摘要:
航空发动机的结构完整性关乎飞行安全。目前基于孔探技术的航空发动机缺陷检测以人工操作为主。为提高检测精度和效率,提出一种融合注意力和多尺度特征的航空发动机缺陷智能检测算法,以辅助孔探工作。针对原始孔探图像中缺陷样本的类别不平衡问题,采用了一种基于几何变换和泊松图像编辑的多样本融合数据增强方法,丰富小样本图像并构建缺陷数据集。在基准网络YOLOv5中融入协调注意力模块(CA),以强调缺陷特征的提取,增强网络对缺陷目标和复杂背景的区分。在颈部网络中构建加权双向特征金字塔结构(BiFPN),以完成更高层次的特征融合,提升对多尺度目标的表达能力。将边界框回归损失函数定义为EIOU损失,实现对缺陷目标快速、准确的定位和识别。实验结果表明:所提算法检测缺陷的平均精确度达到了89.7%,较基准网络提升了6.3%,训练后的模型大小仅为14.0 M。因此,所提算法可以有效地检测航空发动机的主要缺陷。
Abstract:The structural integrity of the aero-engine is related to flight safety. Currently, the detection of aero-engine defects based on borescope technology is mainly manually operated. In order to improve detection accuracy and efficiency, an intelligent aero-engine defect detection algorithm by fusing attention and multi-scale features was proposed to assist the borescope detection. In view of the imbalanced distribution of defect classes in original borescope images, a multi-sample fusion data augmentation method based on geometric transformation and Poisson image editing was used to enrich the small sample images, and the defect dataset was constructed. The coordination attention (CA) mechanism was integrated into the baseline network YOLOv5 to emphasize the extraction of defect features and enhance the network’s distinction between defect targets and complex backgrounds. The weighted bidirectional feature pyramid network structure (BiFPN) was constructed in the neck network to achieve a higher level of feature fusion and improve the expression ability for multi-scale targets. The bounding box regression loss function was defined as the efficient intersection over union (EIOU) loss. The fast and accurate location and recognition of defects were realized. The experimental results show that the average precision of the proposed algorithm in detecting defects is 89.7%, 6.3% higher than that of the baseline network. The size of the trained model is only 14.0 M. Therefore, the proposed algorithm can effectively detect the main defects of aero-engines.
-
Key words:
- aero-engine /
- defect detection /
- deep learning /
- YOLOv5 /
- attention mechanism
-
航空发动机作为飞行器的核心,为飞行器供应动力,其结构完整性将直接影响飞行安全。发动机叶片等航空发动机的核心部件,长期工作于恶劣环境,有造成发动机故障的隐患。因此,对航空发动机的定期检修、突发性排故检测和故障监控是保证飞行器适航的必要任务。目前对于航空发动机的检测主要是基于孔探技术,由专业人员观察和判断发动机内部的损伤状况[1-3]。虽然传统的孔探方法已经成为实际工作中不可或缺的检测手段,但受限于技术人员的经验和疲劳程度,检测排故的效率不高。因此,有必要发展一些其他的检测方法辅助孔探技术,以降低检测误差、保证飞行安全。
近年来,随着计算机硬件的发展,以卷积神经网络为代表的深度学习算法发展迅速。由于卷积神经网络良好的数据挖掘性和可移植性,已有学者开始尝试将深度学习方法应用到飞机机身和航空发动机的缺陷检测任务。Malekzadeh等[4]首次提出一种基于深度神经网络的飞机缺陷自动识别方法,使用拍摄到的飞机机身直视图作为数据集,利用在ImageNet上预训练的卷积神经网络作为特征提取器,支持向量机(support vector machine,SVM)作为分类器,实现了对飞机机身缺陷的检测。Kim和Lee[5]开发了一种航空发动机叶片损伤识别算法,首先,使用多种图像处理技术对发动机孔探图像进行预处理,从中选择疑似损伤区域,然后,通过卷积神经网络将疑似区域进一步分类为损伤区域或正常区域,实现了对发动机叶片缺陷的识别。Li等[6]研究了一种基于粗到细的深度学习框架以自动检测发动机叶片表面的缺陷,利用提出的粗分类器模块滤除大部分背景,细检测器模块定位和分类缺陷目标,对于5种发动机叶片的常见缺陷实现了较好的检测效果。李龙浦[7]针对航空发动机缺陷的特征提出改进的YOLOv3模型和Faster R-CNN模型,对比并选择了最优模型进行缺陷的识别和定位,同时实现了对掉块类缺陷的尺寸测量。李彬等[8]在YOLOv4的基础上做出改进,所提算法将深层特征与浅层特征融合,同时去除颈部结构中自底向上的增强路径,并应用改进Focal loss作为分类损失函数,实现了对自建数据集中4类缺陷目标的检测。陈为和梁晨江[9]针对航空发动机缺陷目标小、检测难度大的问题提出改进的SSD模型,通过对原始网络的特征提取结构进行改进,提升了对航空发动机内部凸台缺陷的检测效果。樊玮等[10]提出基于Mask R-CNN的二分类到多分类的检测网络,首先,对航空发动机缺陷图像进行二分类并优化回归坐标;然后,进一步实现缺陷的多分类检测;最后,根据多分类检测的结果完成了对航空发动机缺陷的实例分割。
目前,在使用深度学习方法进行航空发动机缺陷检测的任务中,仍存在一些困难和挑战。如航空发动机原始孔探图像难以获得,即使收集到真实的孔探图像,其中缺陷样本少,大量无缺陷样本冗余且缺陷样本分布不平衡,导致数据集构建困难。同时,孔探图像中的缺陷目标尺度变化较大,小目标居多,背景区域的纹理复杂、易与缺陷目标混淆,在检测时可能出现漏检、误检的情况。在实际的孔探检测中,数据是以视频的形式传出供技术人员检查,对于匹配的深度学习算法,需具有较快的检测速度,满足实时性要求。综上所述,当前仍然缺乏针对缺陷图像的快速、准确的检测算法。
为解决上述问题,本文提出一种融合注意力和多尺度特征的航空发动机缺陷检测算法,以实现对氧化、裂纹和缺失类缺陷的有效识别。采用多样本融合的策略,利用几何变换和泊松图像编辑技术,扩充了小样本缺陷,平衡了数据集样本分布。在YOLOv5的主干网络中融合协调注意力机制以关注目标特征,为后续连接提供更多有用的特征信息,提升对真实缺陷目标的辨别能力。构建加权双向特征金字塔结构,实现了多尺度特征融合,尽可能多地聚合并传递提取到的特征,改善对多尺度目标尤其是小目标的检测效果。使用EIOU 损失作为边界框回归损失函数,快速准确地定位缺陷目标。
1. 数据预处理和数据集准备
本文收集的原始数据来源于当地某航空公司提供的2018—2021年CFM56-7B航空发动机真实的孔探图像,其中包括343张氧化、102张裂纹、282张缺失类缺陷和大量无缺陷的背景图像,图像的像素均为752×576。缺陷主要存在于燃烧室、涡轮等热部件,也有部分裂纹和缺失缺陷产生于压气机部件。每张图像都包含至少一个缺陷目标,少数图像可能同时包含缺失和裂纹类目标。氧化、裂纹和缺失类缺陷的原始图像如图1所示。
在深度学习领域,卷积神经网络需要足够的训练样本来避免过拟合现象。我们注意到3类缺陷样本的数量不平衡,最多类和最少类的样本比例超过了3∶1,这将导致网络对它们的表达效果差异较大,影响模型的整体检测能力。因此,在最终构建数据集之前,需要对小样本的数据做针对性的增强处理,使整体样本分布更均衡。
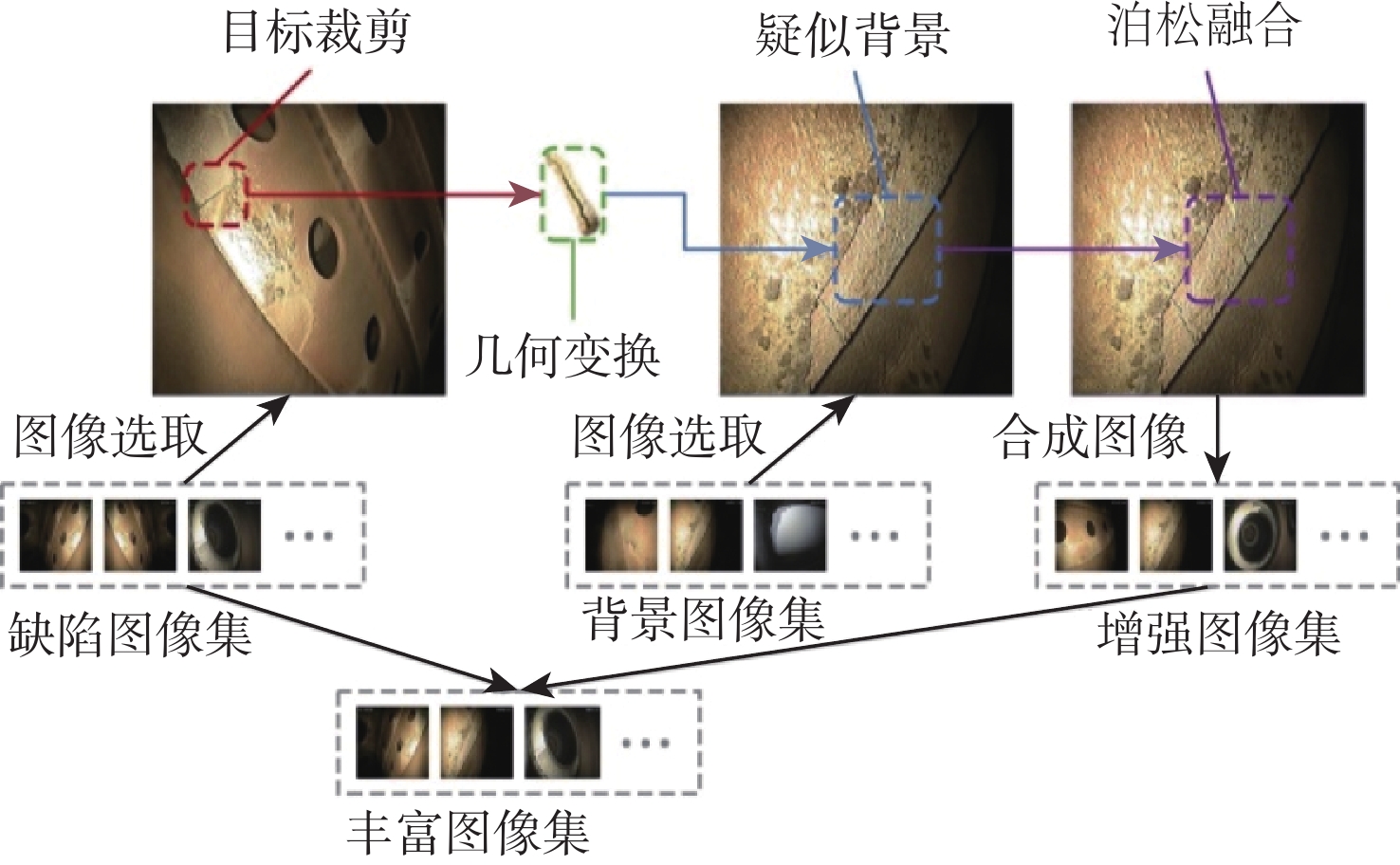
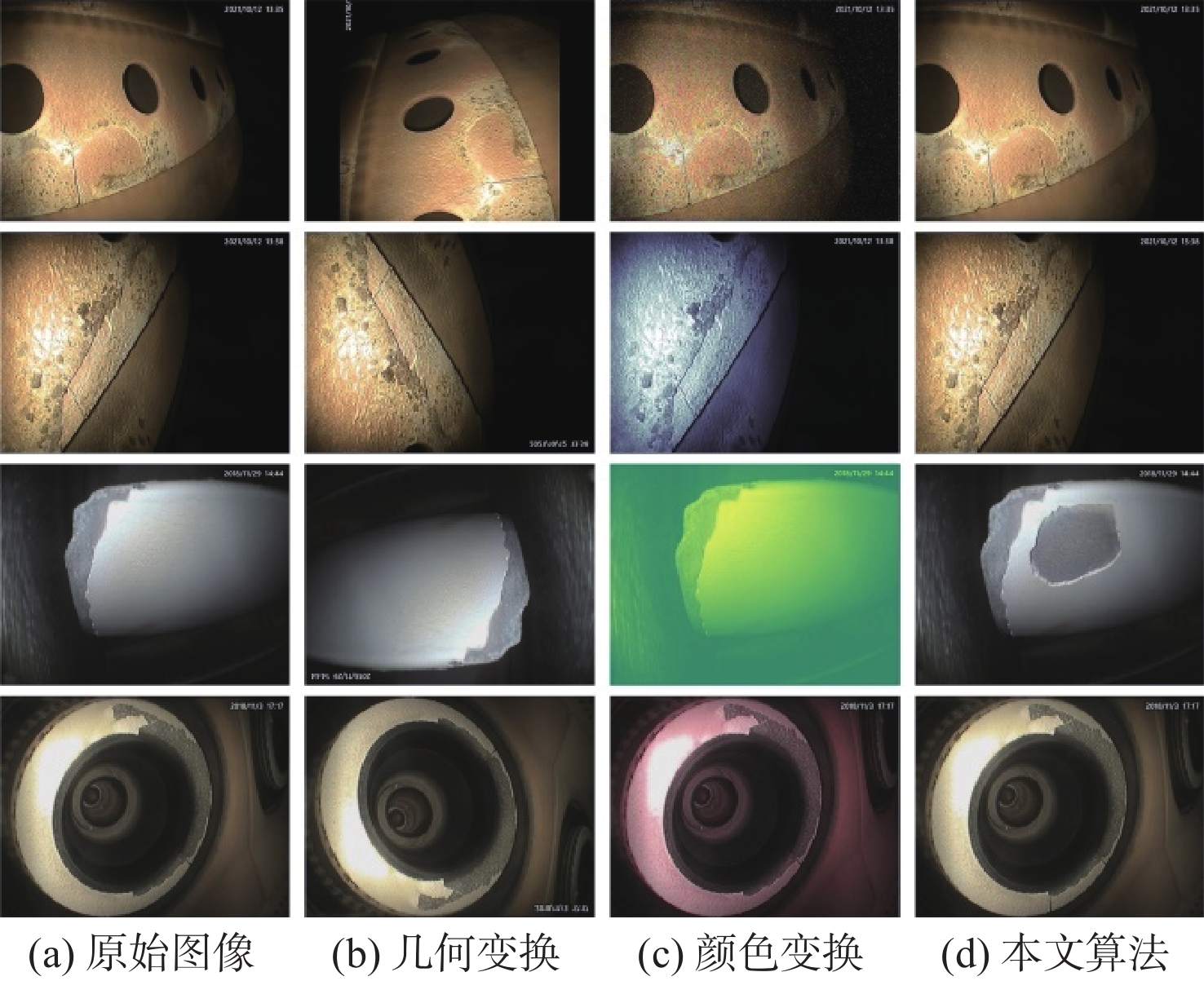
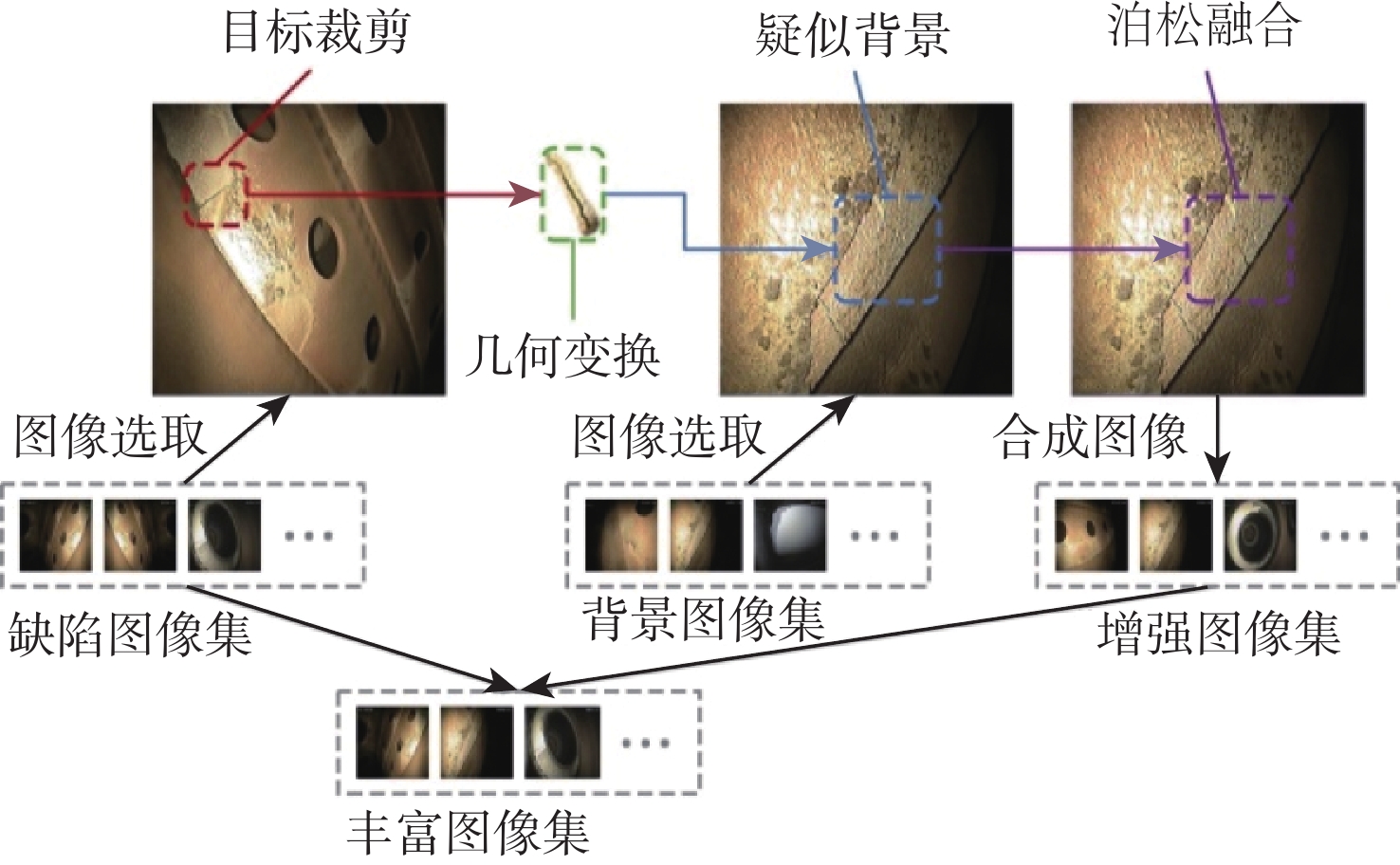
传统基于单样本的数据增强方法,如几何变换、颜色变换等,仅改变了图像的表现形式而没有实质地改变图像内容,并未达到真正意义上的丰富小样本数据,从而限制了卷积神经网络对小样本数据特征的学习和表示能力[11]。因此,本文采用多样本融合的数据增强方法,基于几何变换和泊松图像编辑技术,通过人工合成新样本来处理样本不平衡的问题。首先,对收集到的原始孔探图像进行初步筛选,在全部的缺陷图像中找到合适的小样本缺陷类别图像,在无缺陷的背景图像中选取可能发生该类缺陷的疑似背景图像,分别整理为缺陷图像集和背景图像集。然后,对小样本的缺陷目标进行裁剪,并运用几何变换手段如旋转、缩放等调整至合适的角度位置。最后,利用泊松图像编辑将缺陷目标和背景图像融合,使合成后图像更为接近真实采集的孔探图像。由于原始孔探图像中裂纹类缺陷所占的比例最低、缺失类次之,因此,通过多样本融合数据增强方法对这2类缺陷进行扩充,图2为小样本缺陷的数据增强过程。最终将裂纹类图像扩充至306张,缺失类图像340张,丰富后的数据集图像达到989张,按照6∶2∶2的比例划分为训练集、验证集和测试集。图3为应用不同数据增强方法后的直观化结果。
 图 3 应用不同数据增强方法的直观化结果Figure 3. Visualization results using different data augmentation methods
图 3 应用不同数据增强方法的直观化结果Figure 3. Visualization results using different data augmentation methods2. 航空发动机缺陷检测算法
2.1 基准网络YOLOv5
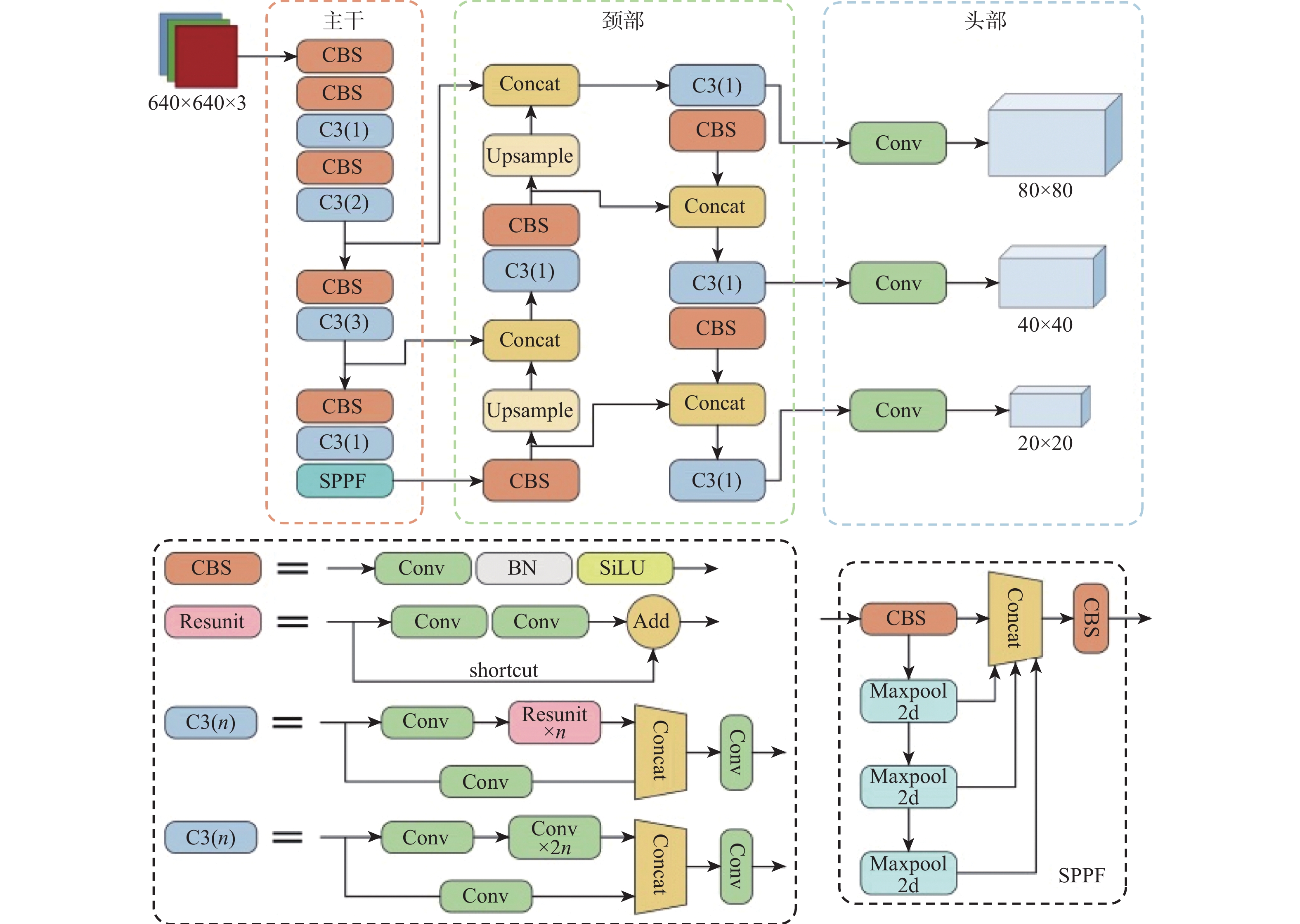
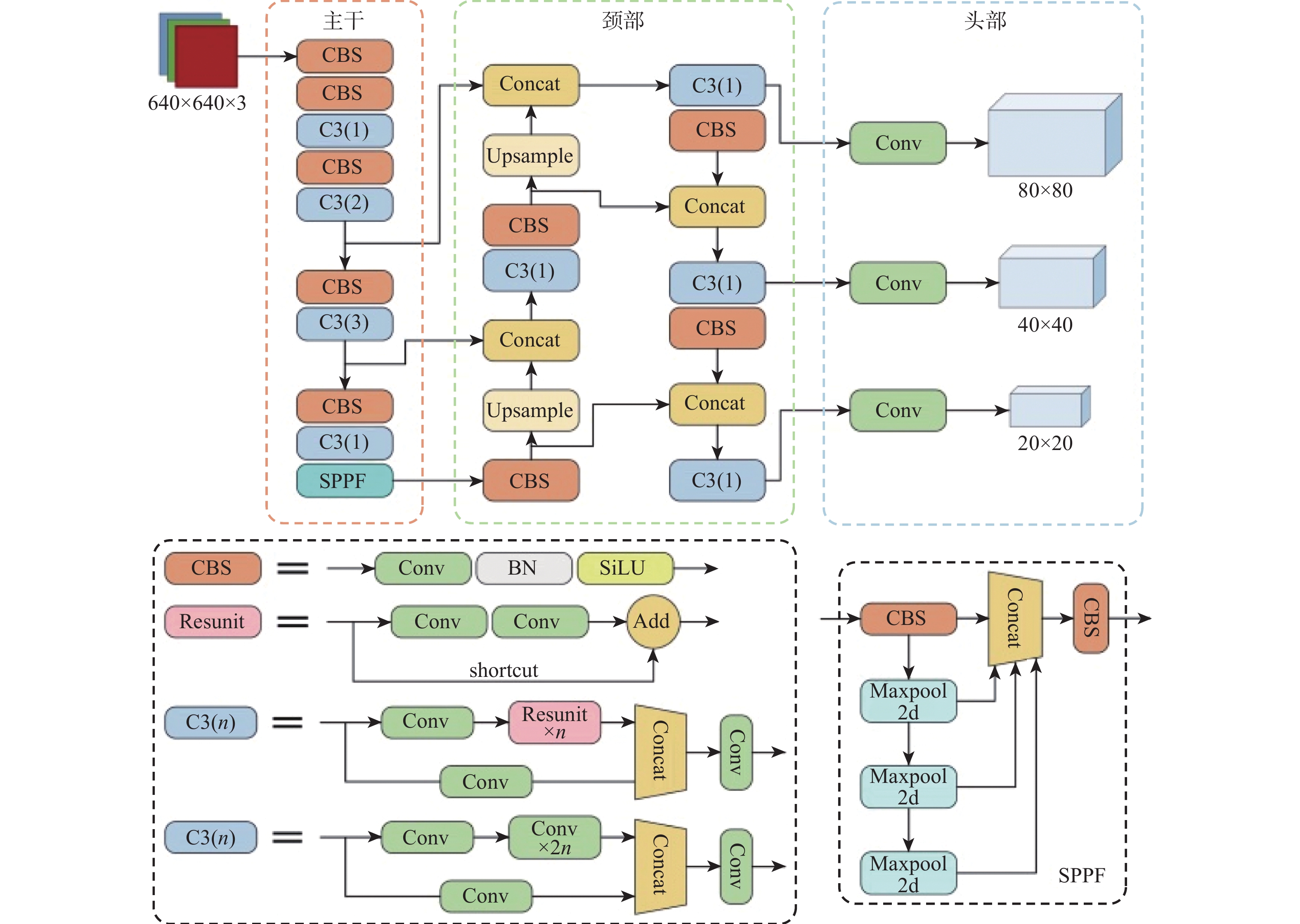
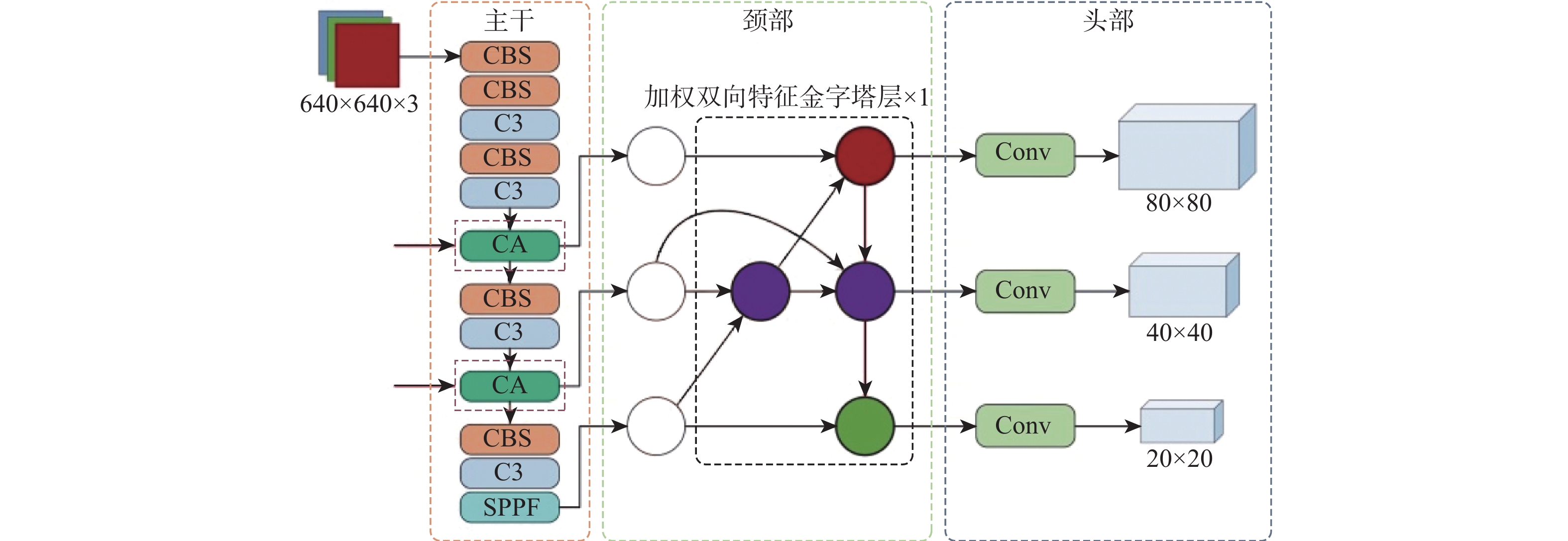
YOLOv5是由Glenn Jocher提出的一阶段目标检测网络,融合了之前YOLO系列算法的优点,检测精度和速度都表现得更为强大。YOLOv5模型有4种尺寸,分别是s、m、l和x,它们的结构深度和宽度逐次增加。本文以YOLOv5s作为基准网络,原因是它更小更快。图4为YOLOv5s网络的整体框架和各个组件的详细结构,YOLOv5主要由特征提取主干、颈部特征金字塔结构和预测头部3个部分组成,其中,颈部和头部也可以结合起来共同看作预测头部。
YOLOv5的主干部分使用了跨阶段局部网络(cross stage partial network, CSPNet)[12],网络的学习能力得以增强,既能保持精确性又足够轻量化,主干网络主要由(convolutional-batch normalization-SiLU)模块、C3模块和(spatial pyramid pooling-fast)模块组成。CBS模块包括一个卷积层(convolutional, Conv)、一个批量归一化层(batch normalization, BN)和一个SiLU激活函数,用于提取不同层次图像的信息特征。C3模块包含了3个卷积层及多个残差组件,优化了梯度反向传播的路径,提升网络学习能力的同时降低了计算成本和内存开销。SPPF模块借鉴了空间金字塔池化(spatial pyramid pooling,SPP)的思想[13],增大感受野并提取出最重要的上下文特征,同时具有更快的检测速度。YOLOv5的颈部结构由特征金字塔网络(feature pyramid network,FPN)[14]和路径聚合网络(path aggregation network,PAN)[15]组成,在不同尺度的图像上生成不同尺度的特征,能够实现对多尺度目标的检测。由于结合了FPN自顶向下传达的语义信息和PAN自底向上的位置信息,YOLOv5网络具有很强的特征融合能力。头部用于完成最终的检测,在3个大小不同的特征图上预测不同尺度的目标,其中最大的特征图负责检测小目标。
2.2 本文算法
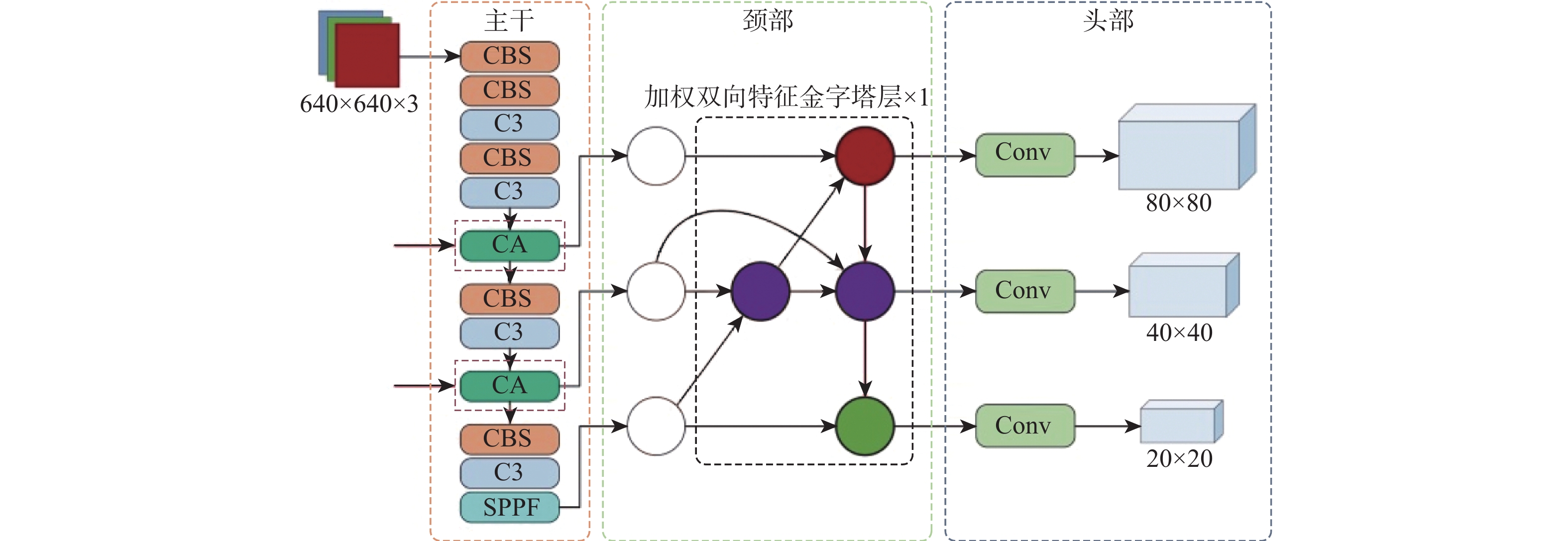
由于航空发动机内部结构复杂,缺陷目标和背景容易混淆,如裂纹类缺陷和纹理复杂的背景特征相似难以区分。大量缺陷(如氧化类和部分裂纹类缺陷)以小目标的形式存在,不容易被检测。同时,缺陷之间的尺寸大小不一,即使是同类缺陷(如裂纹类缺陷和部分缺失类缺陷)也有较大的尺寸差异,导致构建的数据集中存在着更为突出的目标多尺度变化问题。原始的YOLOv5无法很好地解决这些问题,为此提出本文算法,其整体框架如图5所示。首先,在基准网络主干特征提取的第3次和第4次下采样层之后融入协调注意力模块,由于网络的浅层中保留了足够的边缘特征,这些边缘信息对于缺陷目标的识别十分重要[16],因此,利用注意力机制对相应的特征信息加以关注。然后,在颈部构建单层加权双向特征金字塔结构,对各特征层之间的连接赋予可学习权重参数,在特征融合部分的第3次拼接操作中增加额外的路径,将相同尺度的特征图进行拼接,进而充分完成特征信息的聚合。最后,将边界框回归损失函数设计为EIOU损失,加快检测框的回归并且使目标定位更精确。
2.2.1 协调注意力模块
注意力机制对模型性能的提升已经被证明,在计算机视觉任务中应用广泛。对于轻量级网络的研究表明,通道注意力如挤压和激励(squeeze and excitation,SE)机制的应用是有效的[17],可以建立起各个特征通道之间的关联,使得各通道的特征响应能够被自动调整。然而以往的这些机制通常忽略了位置信息,这对于空间选择性注意力图的生成十分重要[18]。考虑到航空发动机孔探图像的复杂背景和计算开销,本文算法融合了一种高效轻量级的协调注意力机制,同时考虑通道间信息的编码和位置关系,以较低的计算量增强了网络对缺陷目标的特征表示,强调有效特征的同时抑制了无关特征。图6为协调注意力模块的整体结构。
协调注意力机制首先会沿水平方向和垂直方向,对输入特征图分别进行一维特征编码,获得图像宽、高方向上的注意力,并且保留了精确的位置信息,公式表示为
zwc(w)=1H∑0⩽i<Hxc(i,w) (1) zhc(h)=1W∑0⩽j<Wxc(h,j) (2) 式中:zwc(w)表示宽度w处的第c通道的输出;H为输入X的高度;zhc(h)表示高度为h的第c通道的输出;W为输入X的宽度。
将水平和垂直方向的特征图拼接,此时2个方向的特征图均具有全局感受野,接着对它们作用一个1×1卷积变换函数F1,将通道数降低为C/r。然后将经过BN处理的特征图送入非线性激活函数得到1×(W+H)×C/r大小的特征图f,通过较为简单的转换即可充分利用位置信息。表示为
f=δ(F1([zh,zw])) (3) 式中:f包含2个方向的编码信息;δ为非线性激活函数;[.,.]表示沿空间维度的拼接操作。
将特征图f切分为二,得到独立张量 {\boldsymbol{f}}^{w}\in {\bf{R}}^{C/r\times W} 和 {{\boldsymbol{f}}}^{h}\in {\bf{R}}^{C/r\times H} 。然后,对 {{\boldsymbol{f}}}^{w} 和 {{\boldsymbol{f}}}^{h} 应用2个1×1卷积函数 {F}_{w} 和 {F}_{{h}} 复原通道数。经由sigmoid激活函数 \sigma 作用之后,特征图水平、垂直方向的注意力权重 {g}^{w} 和 {g}^{h} 即可得到。最终得到在2个方向上带有注意力权重的特征图Y可表示为
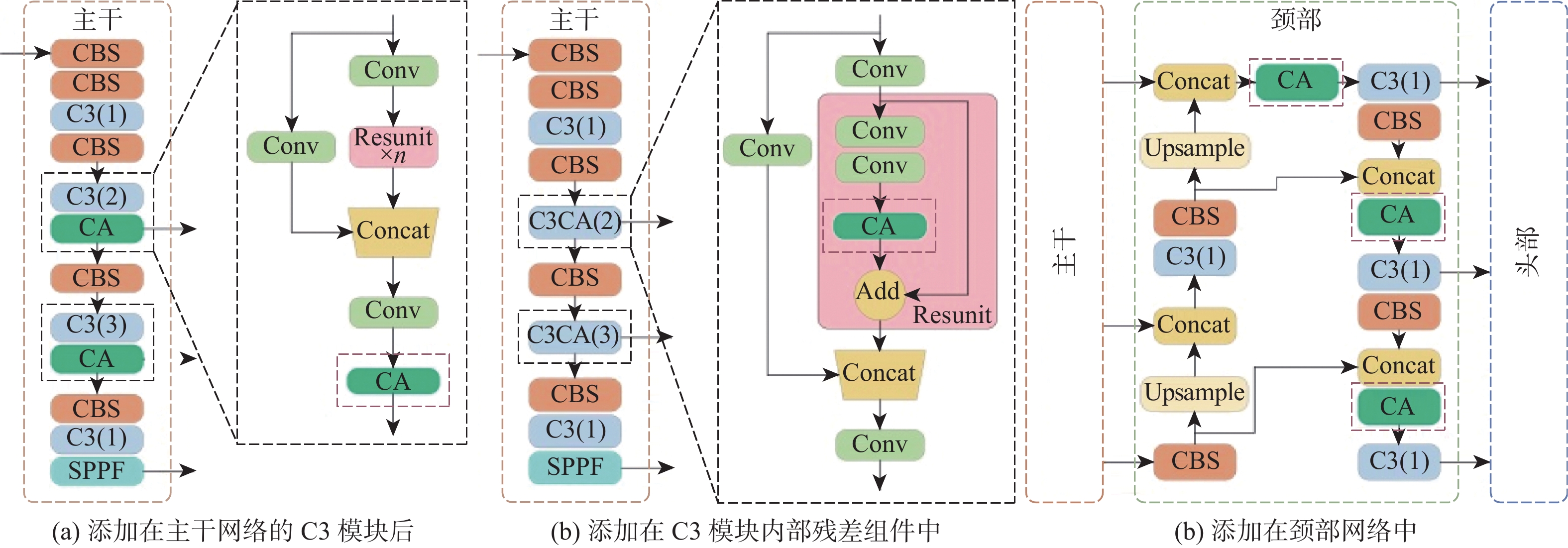
{y}_{c}\left(i,j\right)={x}_{c}\left(i,j\right)\times {g}_{c}^{w}\left(i\right)\times {g}_{c}^{h}\left(j\right) (4) 本文将协调注意力机制融入原始网络,更加关注有用的特征信息。根据放置位置的不同提出3种协调注意力模块的融合方案,位置1、位置2和位置3,如图7所示。位置1和位置2是将注意力机制融合于主干网络中,位置3是添加在颈部网络。其中,位置1是直接将协调注意力模块添加在第3次和第4次下采样之后的C3模块末端,位置2是添加到对应C3模块内部的残差组件中。
 图 7 协调注意力模块的不同融入位置Figure 7. Different integration positions of coordination attention module
图 7 协调注意力模块的不同融入位置Figure 7. Different integration positions of coordination attention module2.2.2 加权双向特征金字塔结构
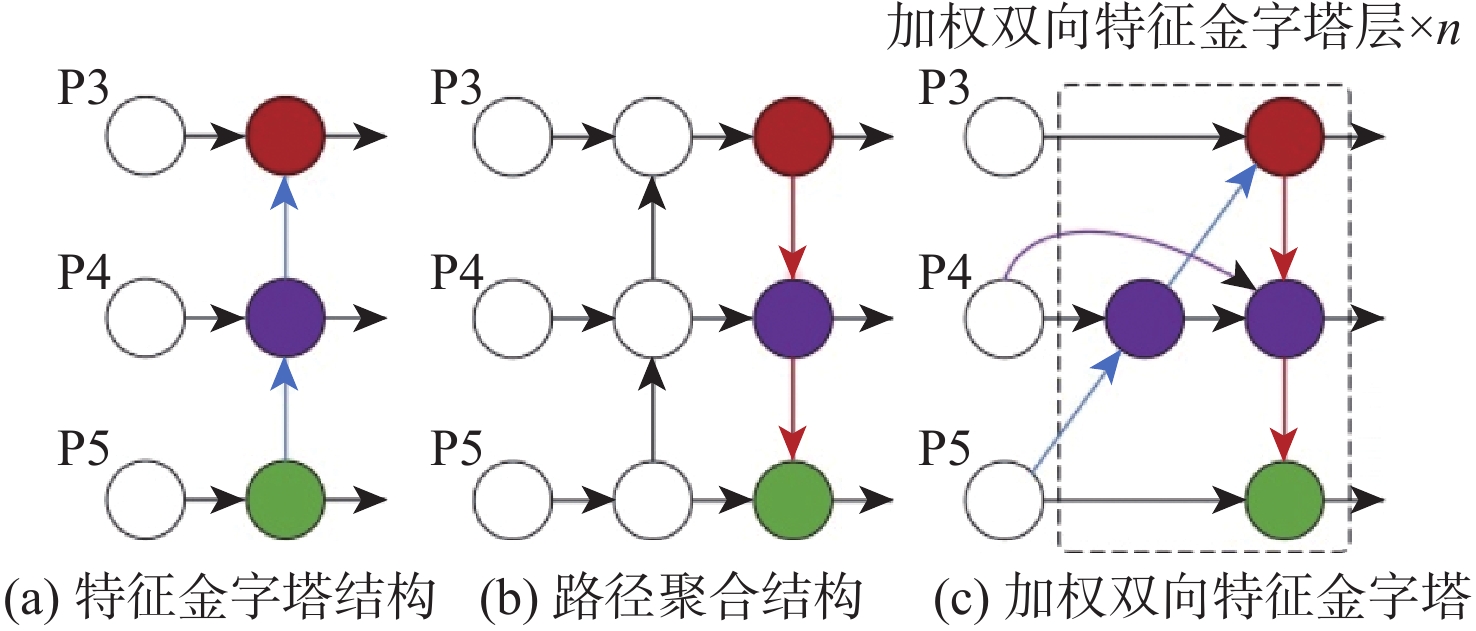
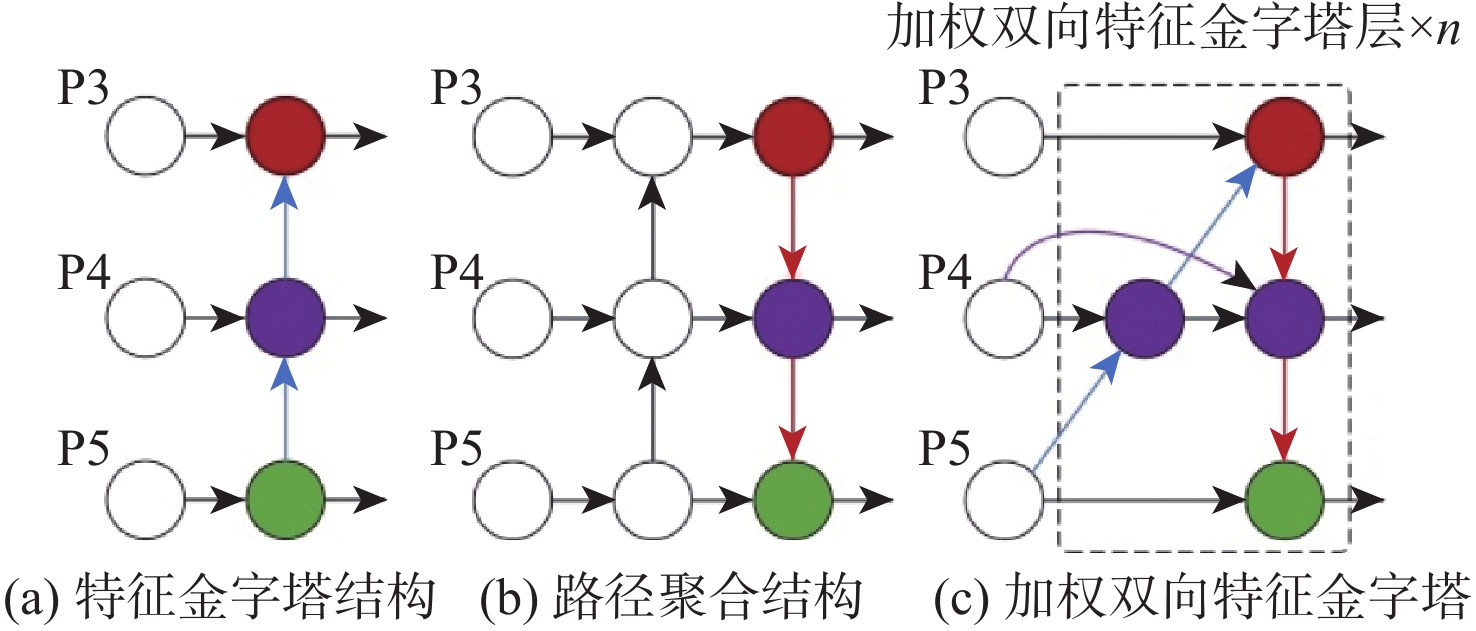
颈部网络是目标检测器承前启后的重要架构,它对主干部分提取到的特征进行聚合及合理利用,传递到预测头部以进行具体的分类和回归任务。在颈部构建特征金字塔是目标检测器常用的一种方式。传统的FPN结构本质上受到单向信息流的限制,因此,YOLOv5的颈部网络采用了PAN架构,在FPN的后续又添加了一条路径,自底向上将高层的语义特征和低层的定位信息结合,进一步提高了特征提取和融合的能力。由于航空发动机缺陷本身尺度不一,检测时孔探镜头与缺陷之间又存在位置变化,导致传递出的孔探图像存在大量多尺度目标。因此,为更好地解决航空发动机孔探图像缺陷目标的多尺度检测,防止小目标信息特征的丢失,构建了一种更高层次的特征融合结构,即加权双向特征金字塔网络[19]。该结构以简单、快速的复合缩放方法融合多尺度特征,提升模型对缺陷在不同尺度下的检测精度。图8为特征金字塔网络、路径聚合网络和加权双向特征金字塔网络结构的示意图。
与YOLOv5网络原始的特征金字塔和路径聚合网络结构相比,加权双向特征金字塔结构采用了双向跨尺度连接方法,并为各连接赋予权重,实现高效的特征融合。从图8(c)可以看出,为提高效率,加权特征金字塔结构将只有一条输入边的节点移除(如P3右边的节点),并对相同级别的输入输出节点增加一条额外的边(如P4增加的紫色边)。同时,不同于特征金字塔和路径聚合网络,加权双向特征金字塔网络采用快速归一化融合的方法为每个输入增加权重,并让网络自适应学习不同特征之间的贡献差异,公式表示为
O=\sum _{i}\frac{{w}_{i}}{\epsilon +\displaystyle\sum _{j}{w}_{j}} {I}_{i} (5) 式中: {w}_{i} 为一个可学习权重参数,ReLU激活函数置于每个参数之后,以保证 {w}_{i} \geqslant 0 ; \epsilon =0.000\;1 为一个很小的值以防止训练过程的振荡,每个归一化权重的值控制在0和1之间。这种方式由于没有使用softmax操作,效率更高。本文使用了单层加权双向特征金字塔结构改进原始的颈部网络,提高了模型的训练效率,提升了对多尺度目标的特征表示能力。
2.2.3 边界框回归损失函数
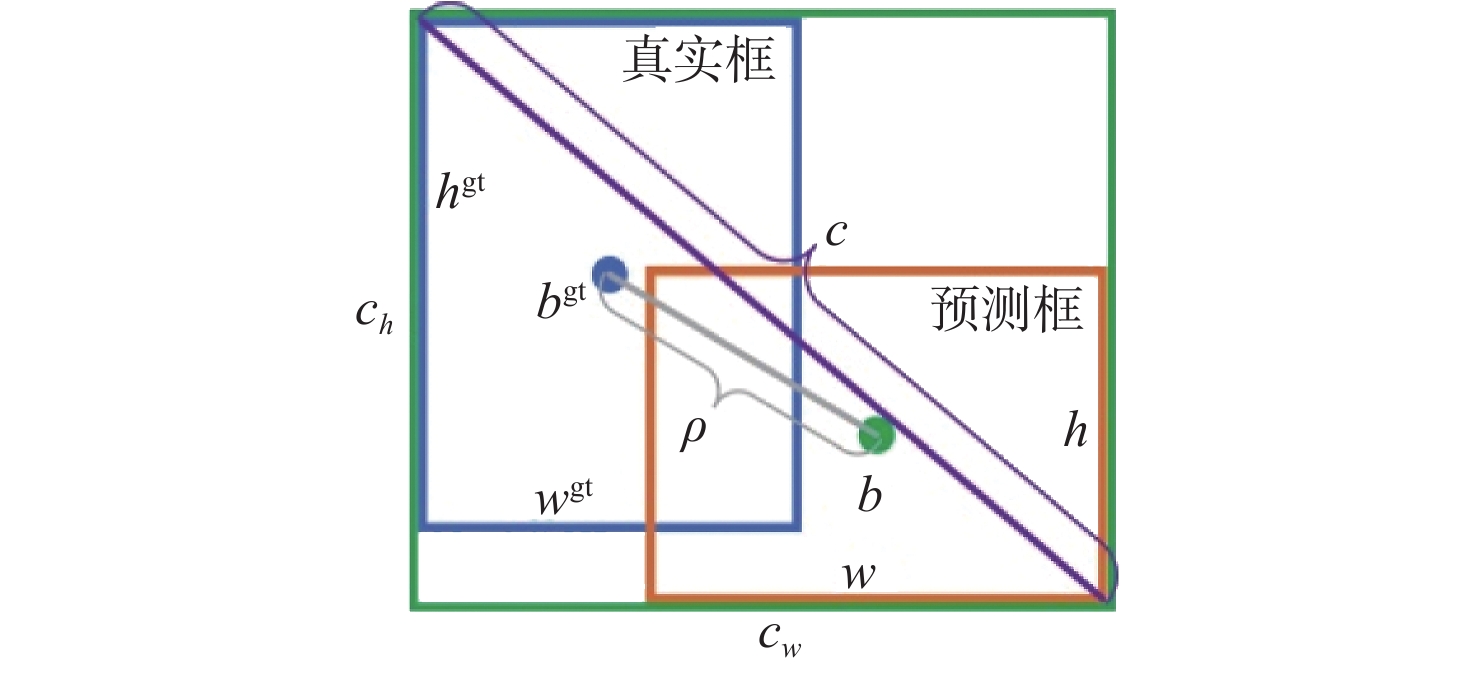
在深度学习领域,损失函数是衡量网络输出与标签真值之间差别的依据,即模型预测效果的好坏。YOLOv5的整体损失函数计算包括3个方面:边界框回归、分类和置信度损失,其中,前两方面损失由BCE Loss函数计算,而边界框回归损失由CIOU损失函数计算。边界框回归是目标检测中的一种主流技术,用于解决目标在图像中的定位问题并细化预测框的位置。基于IOU系列的损失函数是常用的边界框回归损失函数,通过计算预测框和真实框之间的交集与并集之比作为损失值,使预测框回归快速准确地收敛。随着IOU系列损失函数的发展,YOLOv5中使用的CIOU损失函数兼顾了预测框和目标框的重叠面积、中心点之间的距离和长宽比,公式如下:
{L}_{\mathrm{C}\mathrm{I}\mathrm{O}\mathrm{U}}=1-\left(I-\frac{{\rho }^{2}\left(b,{b}^{\mathrm{g}\mathrm{t}}\right)}{{c}^{2}}-\alpha v\right) (6) 式中:I为预测框和真实框之间的交并比; b 和 {b}^{\mathrm{g}\mathrm{t}} 为预测框中点和目标框中点, \rho (\cdot)={\left\|b-{b}^{\mathrm{g}\mathrm{t}}\right\|}_{2} 表示它们之间的距离,由2个框的位置关系定义,恰好覆盖它们的框为最小包围框,其对角线长度为 c 。 v=\dfrac{4}{{\text{π}}^{2}}{\left(\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\dfrac{{w}^{\mathrm{g}\mathrm{t}}}{{h}^{\mathrm{g}\mathrm{t}}}-\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\dfrac{w}{h}\right)}^{2} 反映了2个框之间的宽高比相似性, \alpha =\dfrac{v}{\left(1-\mathrm{I}\mathrm{O}\mathrm{U}\right)+v} 是 v 的影响因子。虽然CIOU在回归效果上提升明显,但它依然存在一些问题,对于式(6)中的 v 并没有很好的定义。当2个框的宽高之间满足 w=k{w}^{\mathrm{g}\mathrm{t}} 和 h=k{h}^{\mathrm{g}\mathrm{t}} 时,有 v=0 ,这是不合理的。而且CIOU未能有效减少预测框和真实框的宽和高之间的差异。计算得到 v 关于 w 和 h 的梯度如下:
\frac{\partial v}{\partial w}=\frac{8}{{\text{π}}^{2}}{\left(\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\frac{{w}^{\rm{gt}}}{{h}^{\rm{gt}}}-\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\frac{w}{h}\right)}^{2} \frac{h}{{w}^{2}+{h}^{2}} (7) \frac{\partial v}{\partial h}=-\frac{8}{{\text{π}}^{2}}{\left(\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\frac{{w}^{\rm{gt}}}{{h}^{\rm{gt}}}-\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\frac{w}{h}\right)}^{2} \frac{w}{{w}^{2}+{h}^{2}} (8) 可以发现 \dfrac{\partial v}{\partial w}=-\dfrac{{h}}{w} \cdot \dfrac{\partial v}{\partial {h}} , \dfrac{\partial v}{\partial w} 和 \dfrac{\partial v}{\partial {h}} 有相反的迹象,当 w 和 h 有一个增加时,另一个就会减小,这减缓了CIOU的收敛速度。
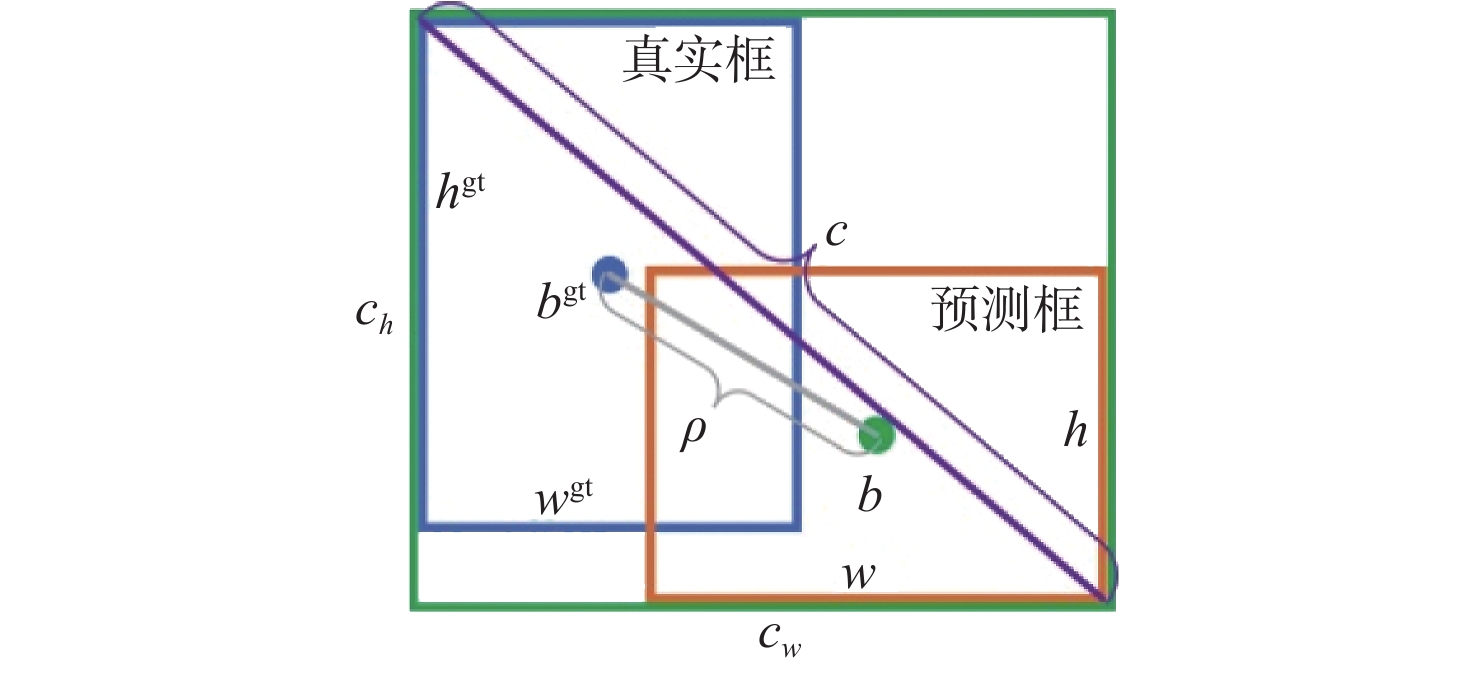
为解决CIOU存在的问题,实现航空发动机缺陷目标预测框回归的快速准,在此任务中引入了EIOU损失函数,其示意图如图9所示。EIOU损失函数表示如下:
{L}_{\mathrm{E}\mathrm{I}\mathrm{O}\mathrm{U}}=1-\left(I-\frac{{\rho }^{2}\left(b,{b}^{\rm{gt}}\right)}{{c}^{2}}-\frac{{\rho }^{2}\left(w,{w}^{\rm{gt}}\right)}{{C}_{w}^{2}}-\frac{{\rho }^{2}\left(h,{h}^{\rm{gt}}\right)}{{C}_{h}^{2}}\right) (9) 式中:I为预测框和真实框之间的交并比; b 和 {b}^{\mathrm{g}\mathrm{t}} 为预测框中点和目标框中点; {C}_{w} 为最小包围框的宽度; {C}_{h} 为最小包围框的高度。EIOU损失可以有效减小预测框和目标框 (w,h) 和 ({w}^{\rm{gt}},{h}^{\rm{gt}}) 之间的差异,加快收敛速度并得到更好的定位结果[20]。
本文算法融合了协调注意力机制、单层加权双向特征金字塔结构和EIOU 损失,根据协调注意力模块放置位置的不同区别为3种改进方案,改进1、改进2和改进3。最终的改进后模型可以有效地检测航空发动机的主要缺陷,能更好地区分缺陷目标和易混淆的背景,对多尺度目标的检测能力更强,尤其体现在对小目标的检测,对于缺陷的定位和识别快速准确。具体的定量化结果和直观化效果在实验部分详细描述。
3. 实验和结果分析
本节描述实验设计的流程并分析实验结果。首先,介绍实验环境和评价指标。然后,对改进模型和基线模型的性能进行比较,并设计消融实验以评估最终的改进后模型,分析各改进部分对基准网络性能提升的贡献。还对采用不同方法的各个模块进行对比。最后,将本文模型与其他优秀的检测模型进行比较,证明本文算法在检测精度和速度上的优越性。
3.1 实验环境和评价指标
本文所有实验都是在一台配置有NVIDIA GeForce RTX
3070 Ti GPU的计算机上进行的,在PyTorch框架下利用CUDA并行计算架构实现检测模型的构建。另外,Python和OpenCV用于实现数据增强。详细环境配置如表1所示。模型训练使用SGD优化器,初始学习率为0.01,最终学习率为0.0001 ,动量为0.9,权值衰减为0.0005 ,轮次为300,批样本数量为16,输入图像调整为640×640。表 1 环境配置细节Table 1. Environment configuration details配置 类型 Operating System Windows 10 CPU Intel Core i5-12400 GPU NVIDIA GeForce RTX 3070 Ti, 8 GB Pytorch Version 1.10.1 CUDA Version 11.3 cuDNN Version 8.2.0 PyThon Version 3.18.13 OpenCV Version 4.6.0.66 在深度学习目标检测领域,对模型性能的评价主要集中于检测精确度、推理速度和模型大小,因此本文采用以下目标检测中常用的评价指标全方位衡量模型:①精确率P(precision);②召回率R(recall);③单一类别平均精确率(average precision,AP);④整体平均精确率均值(mean average precision,mAP);⑤检测帧率(frames per second,FPS);⑥已训练的模型权重大小,单位为MB。
3.2 消融实验
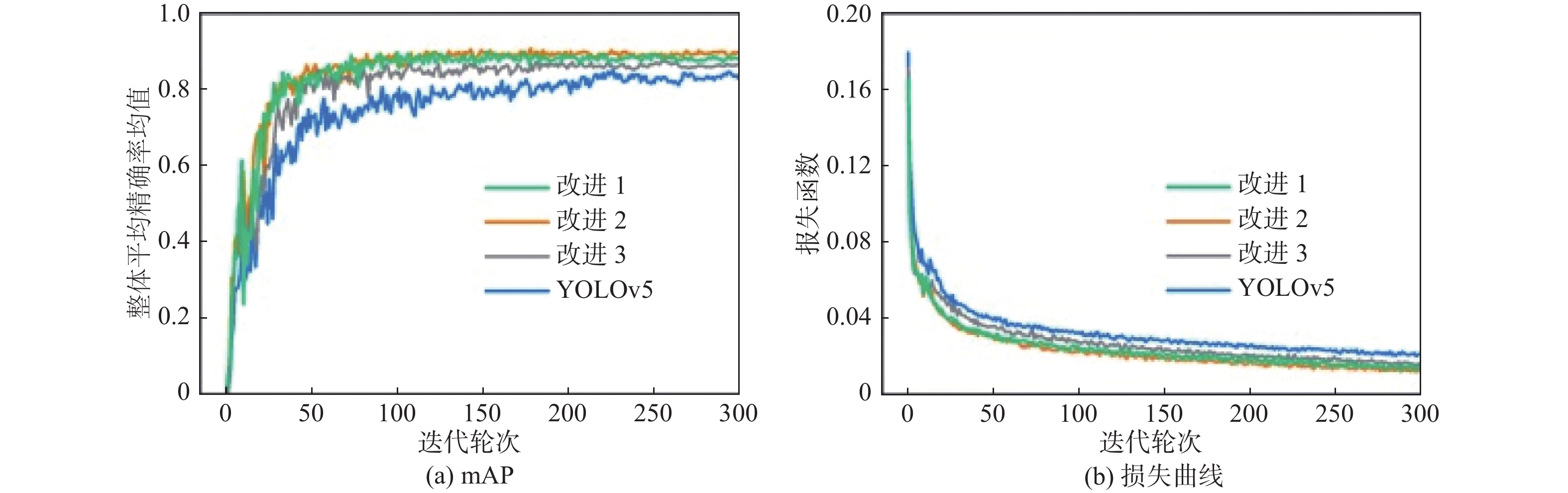
首先,对改进模型进行评估,原始模型、改进1、改进2和改进3模型的mAP和损失曲线如图10所示。损失函数的值能够评估模型的预测效果好坏,通过损失曲线的变化可以呈现出网络训练的动态趋势。可以看出,在训练的过程中,3个改进模型的损失收敛速度更快并且损失值更小,随着训练轮次的增加而达到稳定收敛的状态,损失曲线没有发生明显的振荡现象,并且mAP也始终高于原始模型,因此,可以证明改进模型具有更好的检测精确度。同时可以发现,由于协调注意力模块放置位置的差异,3个改进模型的性能也有所不同,具体的检测结果如表2所示。通过对比可以看到改进2模型的整体表现最优,因此,本文将改进2模型作为最终的改进后模型。
 图 10 改进后模型和原始模型的mAP和损失曲线比较Figure 10. Comparison of mAP and loss curves between improved model and original model表 2 改进后模型和原始模型的检测性能结果Table 2. Test performance results of improved model and original model
图 10 改进后模型和原始模型的mAP和损失曲线比较Figure 10. Comparison of mAP and loss curves between improved model and original model表 2 改进后模型和原始模型的检测性能结果Table 2. Test performance results of improved model and original model模型 P/% R/% mAP/% YOLOv5 79.6 86.5 83.4 改进 1 86.8 89.3 89.1 改进 2 87.9 89.6 89.7 改进 3 85.5 88.8 88.0 为验证最终的改进后模型对于航空发动机缺陷检测的有效性,针对基准网络所提出的改进部分的必要性,评估各个模块对网络性能提升的贡献程度,设计了消融实验以定量地衡量数据增强、协调注意力模块、加权双向特征金字塔结构和EIOU损失函数带来的效果。基线模型由原始未经任何预处理的数据集训练得到,表3为消融实验的结果。可以看出,基线模型对航空发动机3类主要缺陷检测的mAP为83.4%,检测帧率达到了169.5帧/s。当对小样本缺陷进行数据增强,使缺陷样本分布更均衡之后,YOLOv5模型的mAP达到了86.1%,其对裂纹类缺陷的检测效果提升明显,AP增加了6.2%,缺失类缺陷的AP提升了2.1%。这证明本文针对小样本的数据增强方法是有效的。在YOLOv5的主干部分融合了协调注意力模块后,网络对缺陷目标的关注度和特征表示能力提高,尤其体现在部分小目标的氧化类缺陷和容易与背景混淆的裂纹类缺陷,此时的模型对这2类缺陷的AP分别提升了2.3%和2.0%,整体的mAP达到了87.8%。由于并没有增加过多的计算开销,因此,检测帧率仍然达到了166.7 帧/s。在此基础上,构建了加权双向特征金字塔结构,进一步聚合主干部分提取到的特征,更高级别的跳层连接对于多尺度的缺陷的检测更为有利,对于尺度变化较大的缺失类缺陷和部分裂纹类缺陷的检测结果得到了提升,整体缺陷检测的mAP达到了89.0%。由于增加了额外的参数量,模型的计算开销变大,此时检测帧率下降至156.3 帧/s。最后,将模型的边界框回归损失函数替换为EIOU损失,对于缺陷的定位更快更准,使模型的性能达到了最优。最终改进后模型的mAP达到了89.7%,相较于基线模型提高了6.3%。对于3类缺陷检测的AP都达到了最高水平,分别为92.2%,86.2%和90.8%。模型的检测速度不及基线模型,但依然处于较高水平,能够满足实时检测要求。改进后模型以牺牲较小检测速度的代价换来检测性能的较大提升。在航空发动机缺陷检测任务上检测精度是放在首位的,因为它关乎着安全性。因此,本文算法对于航空发动机主要缺陷的检测是有效的,各部分改进是必要的。
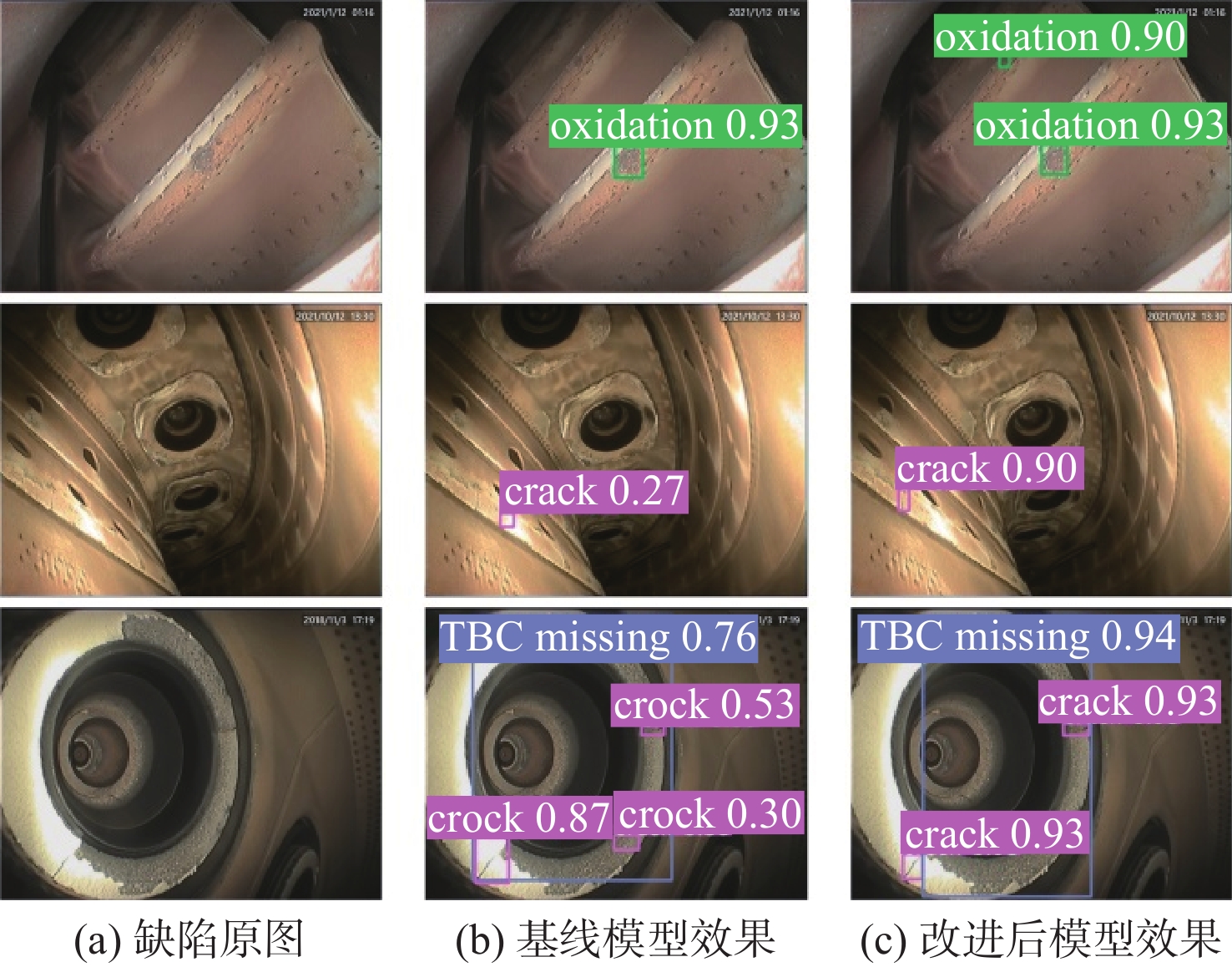
表 3 消融实验结果Table 3. Results of ablation experiment数据增强 CA BiFPN EIOU AP/% mAP/% 检测帧率/(帧·s−1) 氧化 裂纹 缺失 88.5 75.6 86.0 83.4 169.5 √ 88.4 81.8 88.1 86.1 169.5 √ √ 90.7 83.8 88.8 87.8 166.7 √ √ √ 91.7 85.3 89.9 89.0 156.3 √ √ √ √ 92.2 86.2 90.8 89.7 156.3 为直观地比较改进后模型和基线模型的实际检测效果,图11展示了它们对3类缺陷的检测结果示例。可以看出,改进后模型的实际检测效果比基线模型更好。在对第1行氧化类缺陷的检测中,基线模型忽略了更小的目标,改进后模型则准确地检测到该处缺陷。对于第2行裂纹类缺陷,基线模型将背景误检为缺陷并漏检了真正的目标,改进后模型纠正了这个错误,正确地检测到了裂纹。对第3行同时存在缺失类和裂纹类缺陷的检测,基线模型将缺失部分误检为裂纹,并且对于缺陷的定位不够准确。然而改进后模型正确区分了2类缺陷,对于缺陷的定位非常准确,并且提升了检测的置信度。
 图 11 改进后模型和基线模型的实际检测效果Figure 11. Comparison of actual detection effects between improved model and baseline model
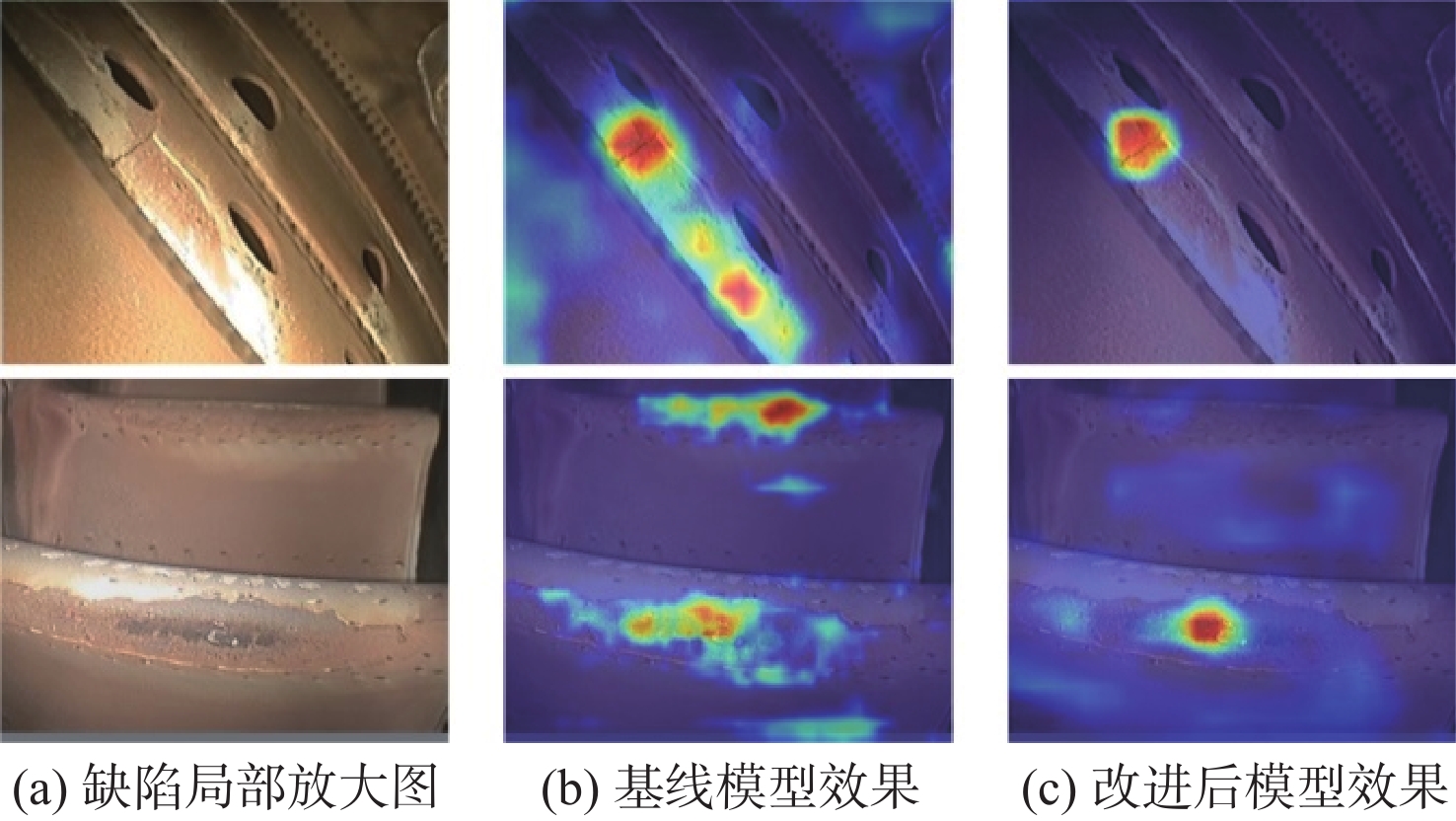
图 11 改进后模型和基线模型的实际检测效果Figure 11. Comparison of actual detection effects between improved model and baseline model基线模型在检测时容易产生漏检和误检的情况,尤其是漏检,这在航空发动机的缺陷检测上是不可接受的。为此,本文提出融合注意力和多尺度特征的处理方案,最大限度地避免漏检和误检现象。为了清楚地看到本文算法对缺陷目标检测效果的提升,使用Grad-CAM方法[21]对基线模型和改进后模型进行热力图可视化,如图12所示。Grad-CAM是一种卷积神经网络可解释性的经典方法,无须对模型进行改动就可生成热力图,可直观展示图像各区域对类别分类的贡献程度,以热力图呈现出来的区域颜色分布即可做出判断,红色部分表示的贡献较大,蓝色部分贡献较小。可以看出,在对2个小目标的氧化和裂纹缺陷的检测中,改进后模型对缺陷部分的关注增加,对于目标和背景的辨别效果提升显著。
 图 12 改进后模型和基线模型的热力图可视化结果Figure 12. Visualization results of heat map of improved model and baseline model
图 12 改进后模型和基线模型的热力图可视化结果Figure 12. Visualization results of heat map of improved model and baseline model3.3 各改进部分使用不同方法的对比
对协调注意力机制的不同融合位置进行了实验,比较了在主干部分和颈部网络添加注意力机制对模型性能的影响,使用最终的数据增强后数据集进行测试。对基准网络不添加注意力机制,以及在位置1、位置2和位置3处融合协调注意力模块的准确性测试结果如表4所示。可以看到与不添加注意力机制的基准网络相比,在主干部分(位置1、位置2)融合协调注意力机制具有更好的检测结果,而在颈部网络(位置3)融入注意力机制效果不佳。由于处在较低层的特征图具有更小的感受野,主干网络中又保留了足够的局部和细节信息,这些条件有助于对小目标缺陷的检测,而颈部部分特征图的较大感受野和冗余的特征信息则不利于缺陷目标的识别。在位置2融合协调注意力机制的mAP达到了87.8%,比位置1的检测结果略好。协调注意力模块的数量同残差组件一起随着网络的加深而增加,多层堆叠的协调注意力模块对提取缺陷的特征起到了更好的效果。因此,在主干网络融合注意力机制有助于模型提高对于缺陷目标的表达能力。
表 4 注意力机制不同融入位置的准确性结果Table 4. Accuracy results of different integration positions of attention mechanism位置 P/% R/% mAP/% 无注意力 82.7 86.7 86.1 位置 1 85.0 87.9 87.3 位置 2 85.4 88.1 87.8 位置 3 82.5 87.2 85.8 对原始YOLOv5的颈部网络采用不同结构后的检测结果如表5所示。原始的颈部网络采用特征金字塔和路径聚合网络结构,本文构建了加权双向特征金字塔结构。对于这一部分的跳层连接还有一种常见的改进方法,即增加目标预测头,额外添加一个输出尺寸更大的特征图用于检测小目标。比较了这3种颈部结构对于航空发动机缺陷检测的结果。可以看到,采用加权双向特征金字塔结构的模型的mAP最高,达到了87.5%,比原始模型提高了1.4%。采用4个预测头对于缺陷的检测也有一些提升,但同时增加了额外的参数量,推理速度也有所下降。综合考虑,采用加权双向特征金字塔结构作为颈部部分进而预测缺陷目标是最佳选择。
表 5 颈部网络不同结构的检测结果Table 5. Detection results of different structures of neck network结构 mAP/% 权重大小/MB 检测帧率/(帧·s−1) FPN+PAN 86.1 13.7 169.5 4尺度预测头 87.2 14.6 143.2 BiFPN 87.5 13.9 162.6 表6为不同损失函数对基准网络检测结果的影响。原始的YOLOv5使用的边界框回归损失函数是CIOU损失,本文使用的是EIOU损失,作为比较的GIOU和DIOU损失都是IOU系列先进的损失函数。可以看到,使用EIOU损失的模型对3类缺陷的AP都达到了最优,mAP达到了87.3%,比原始使用CIOU的模型高了1.2%。证明EIOU损失可以更准确地定位和识别缺陷目标。同时本文EIOU损失的收敛更快速,事实证明EIOU损失对航空发动机缺陷的检测更具优势。通过对各个改进部分应用不同方法的实验对比,进一步说明本文算法在航空发动机缺陷检测方面的优越性。
表 6 不同损失函数的测试结果Table 6. Test results of different loss functions损失函数 AP/% mAP/% 氧化 裂纹 缺失 GIOU 87.7 80.8 87.1 85.2 DIOU 88.6 81.1 87.2 85.7 CIOU 88.4 81.8 88.1 86.1 EIOU 89.5 83.6 88.8 87.3 3.4 对比实验
将最终的改进后模型与其他几种优秀的目标检测模型SSD[22]、Faster R-CNN[23]和RetinaNet[24]进行比较,以验证本文模型相较于同类模型的检测优势。对比实验中各模型在相同的实验环境下进行训练和测试,其中,SSD和Faster R-CNN使用的主干网络是VGG16,RetinaNet使用的主干网络为ResNet50。图13为各模型对小目标的裂纹类缺陷的检测效果。可以看出,本文模型的检测效果最好,精准地定位和识别出了图像中存在的2条裂纹,并取得了很高的置信度得分,证明本文针对性的改进方案对小目标的检测是有效的。SSD模型漏检了一个目标,同时对另外一个缺陷目标的定位不准确。Faster R-CNN模型将一条裂纹识别成了2条,没有完全区分开真实目标和相似背景。RetinaNet模型也没有精准的对缺陷定位,检测框没有恰当的包围裂纹目标。
 图 13 不同模型的实际检测效果Figure 13. Comparison of actual detection effects of different models
图 13 不同模型的实际检测效果Figure 13. Comparison of actual detection effects of different models各模型具体的测试结果如表7所示,以mAP、检测帧率和已训练模型的权重大小作为评价指标来评估它们的检测精度、速度和模型大小。可以看到本文模型的mAP达到了89.7%,优于其他模型,能够最精确地检测目标。检测帧率达到了156.3 帧/s,检测速度仅逊于基线模型。在取得最高精度的同时,改进后模型的大小仅为14.0 MB,证明本文模型足够轻量化并便于部署,可以应用于实际的检测场景。
表 7 不同模型的测试结果Table 7. Test results of different models模型 mAP/% 检测帧率/(帧·s−1) 权重大小/MB SSD 78.0 119.3 91.6 Faster R-CNN 82.5 29.8 521.6 RetinaNet 83.6 45.1 139.1 YOLOv5 86.1 169.5 13.7 本文模型 89.7 156.3 14.0 4. 结 论
本文针对现有深度学习算法在航空发动机缺陷检测任务中,存在缺陷样本分布不均衡、背景特征干扰性强和目标多尺度变化的问题展开了研究,得出以下结论:
1) 为解决缺陷样本的类别不平衡问题,采用多样本融合的数据增强方法,基于几何变换和泊松图像编辑技术,有效丰富了小样本缺陷,平衡了数据集中的各类样本分布。
2) 提出融合注意力和多尺度特征的检测算法,以实现对航空发动机缺陷的有效识别,本文算法在保证高精确度的同时兼顾了检测速度,轻量化方便部署,可以满足航空发动机主要缺陷的检测需要。
3) 全面的实验验证表明,本文算法对于航空发动机缺陷的检测效果优于其他方法,虽然推理速度不及基线模型,但依然处于较高水平,在定量化结果和可视化效果上均达到预期。
本文算法在实际的航空发动机缺陷检测中具有应用前景,能够作为孔探检测的辅助技术手段,未来可以容纳更多缺陷类型并进一步优化,对于提高孔探工作的效率、降低误检率、减轻工作人员的疲劳强度等方面具有实用价值。
-
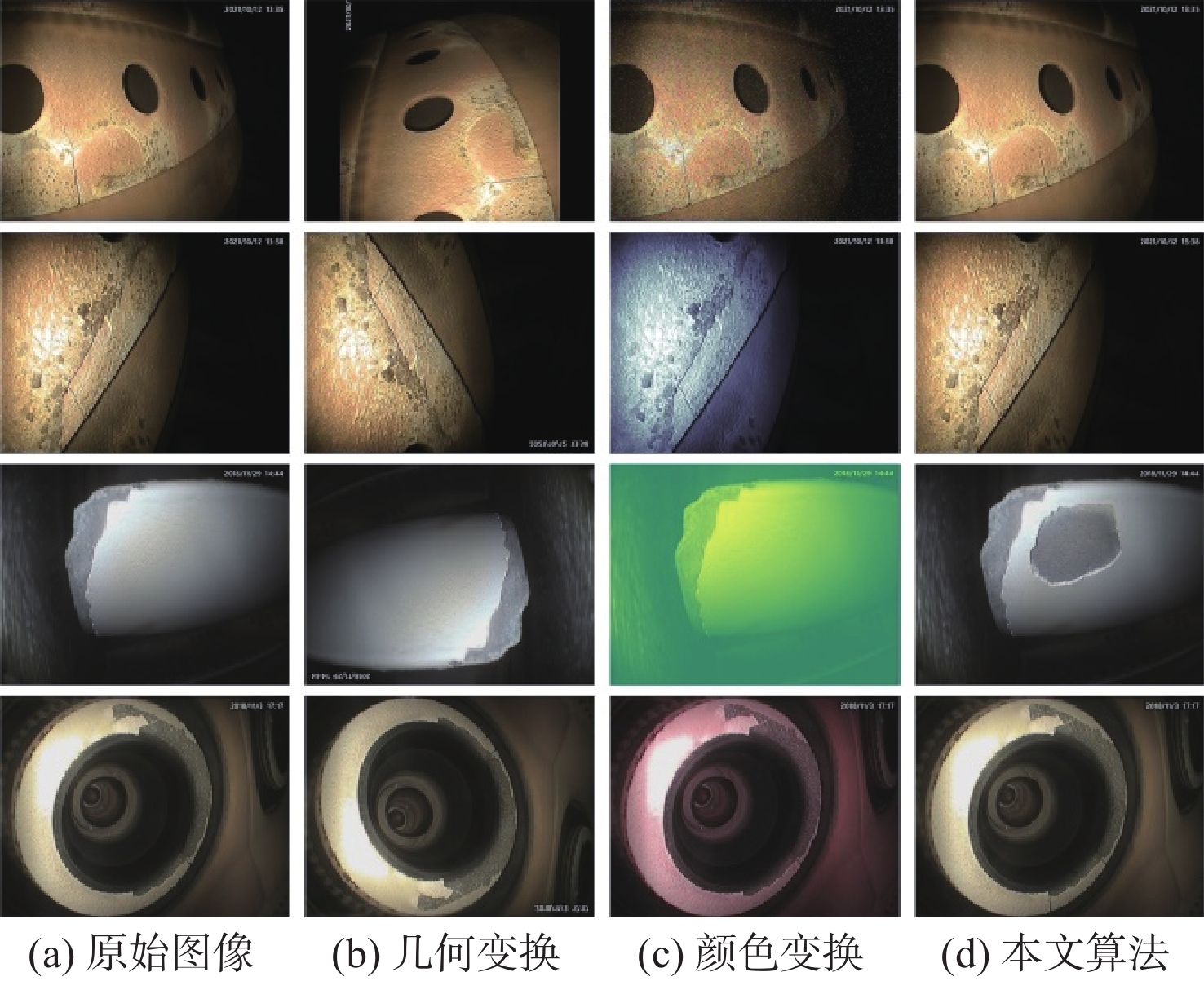
图 3 应用不同数据增强方法的直观化结果
Figure 3. Visualization results using different data augmentation methods
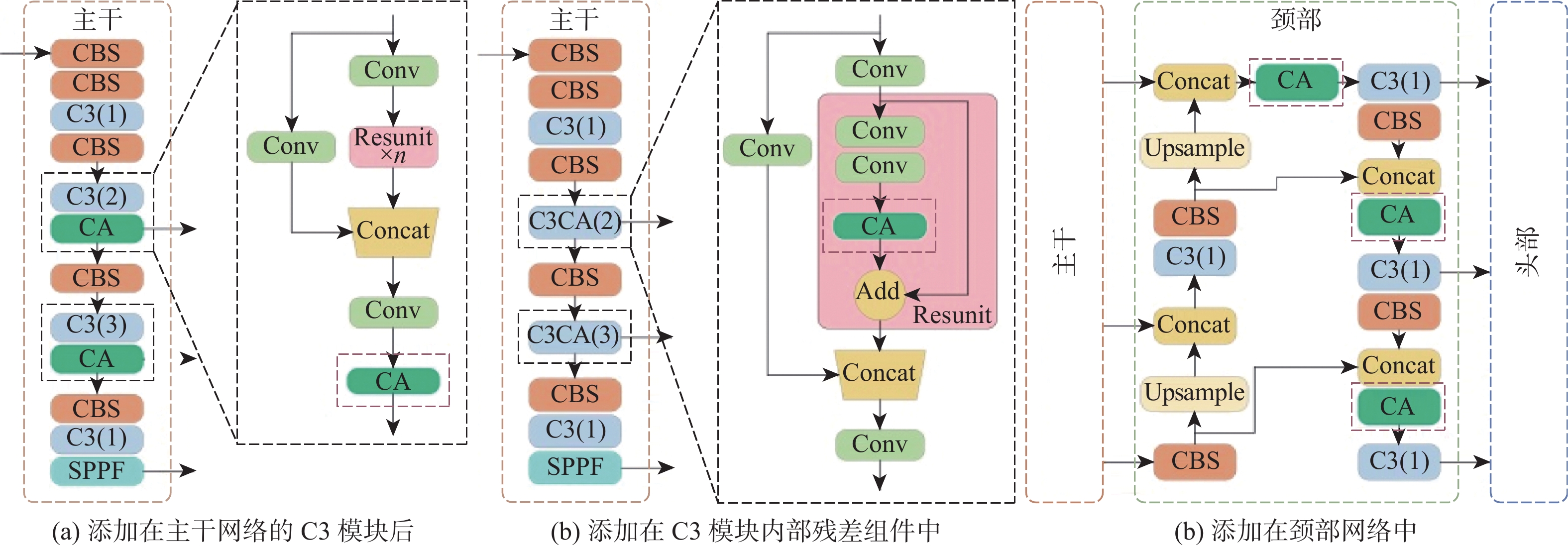
图 7 协调注意力模块的不同融入位置
Figure 7. Different integration positions of coordination attention module
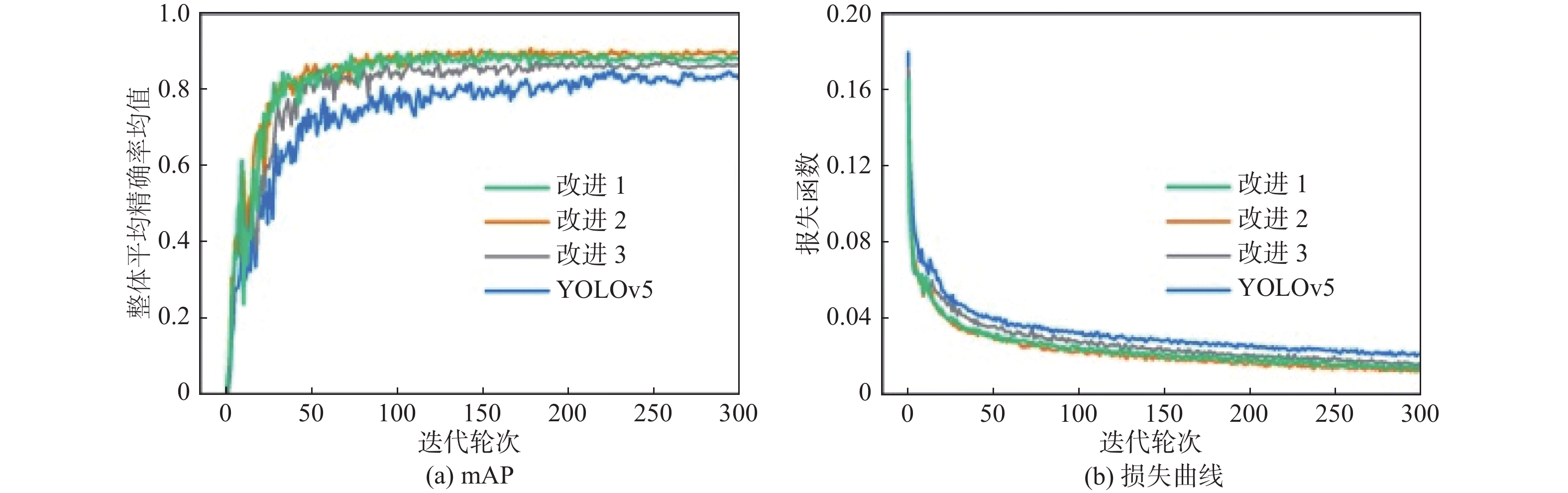
图 10 改进后模型和原始模型的mAP和损失曲线比较
Figure 10. Comparison of mAP and loss curves between improved model and original model

图 11 改进后模型和基线模型的实际检测效果
Figure 11. Comparison of actual detection effects between improved model and baseline model
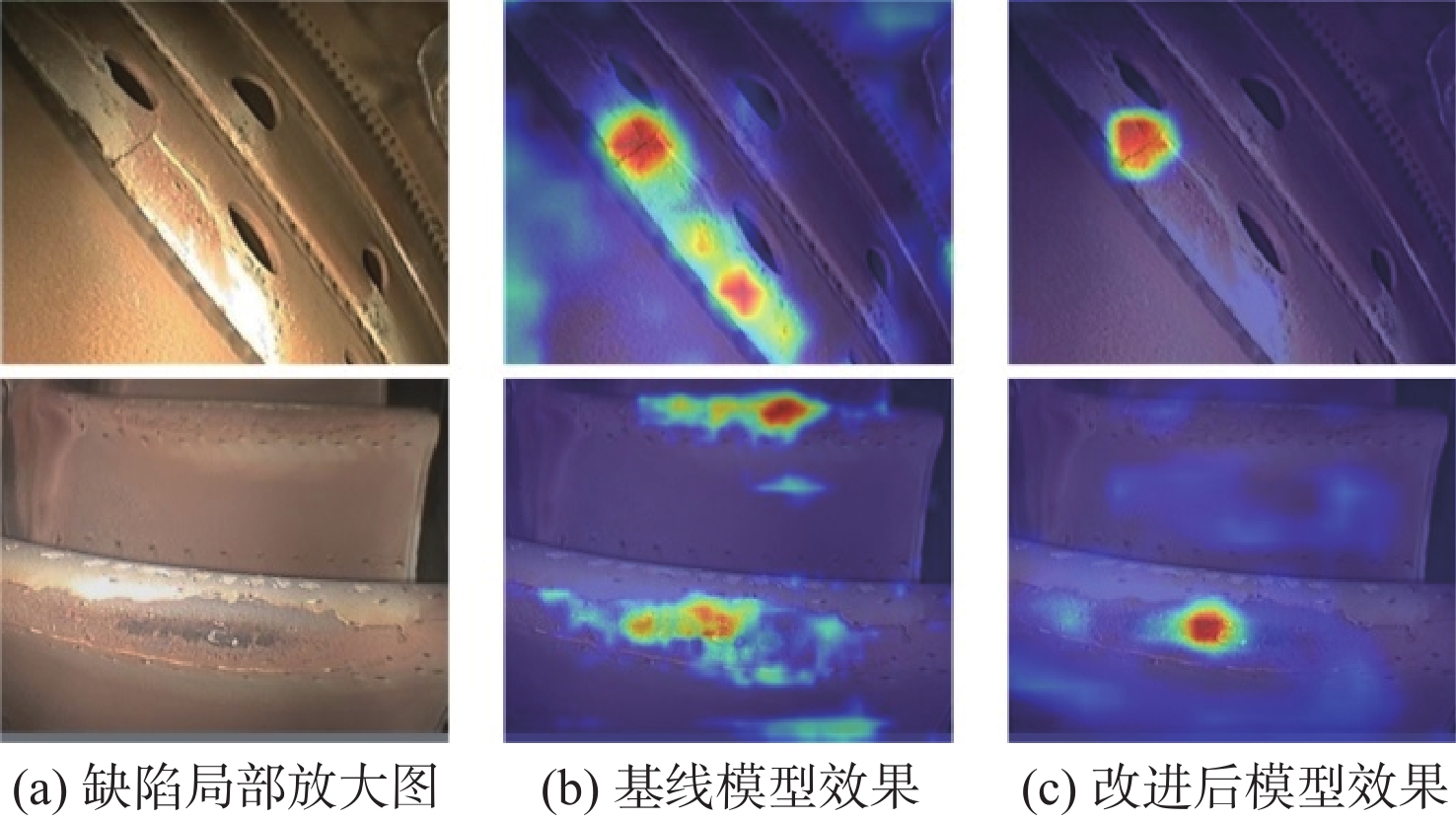
图 12 改进后模型和基线模型的热力图可视化结果
Figure 12. Visualization results of heat map of improved model and baseline model

图 13 不同模型的实际检测效果
Figure 13. Comparison of actual detection effects of different models
表 1 环境配置细节
Table 1. Environment configuration details
配置 类型 Operating System Windows 10 CPU Intel Core i5-12400 GPU NVIDIA GeForce RTX 3070 Ti, 8 GB Pytorch Version 1.10.1 CUDA Version 11.3 cuDNN Version 8.2.0 PyThon Version 3.18.13 OpenCV Version 4.6.0.66  下载: 导出CSV
下载: 导出CSV
表 2 改进后模型和原始模型的检测性能结果
Table 2. Test performance results of improved model and original model
模型 P/% R/% mAP/% YOLOv5 79.6 86.5 83.4 改进 1 86.8 89.3 89.1 改进 2 87.9 89.6 89.7 改进 3 85.5 88.8 88.0
下载: 导出CSV
表 3 消融实验结果
Table 3. Results of ablation experiment
数据增强 CA BiFPN EIOU AP/% mAP/% 检测帧率/(帧·s−1) 氧化 裂纹 缺失 88.5 75.6 86.0 83.4 169.5 √ 88.4 81.8 88.1 86.1 169.5 √ √ 90.7 83.8 88.8 87.8 166.7 √ √ √ 91.7 85.3 89.9 89.0 156.3 √ √ √ √ 92.2 86.2 90.8 89.7 156.3
下载: 导出CSV
表 4 注意力机制不同融入位置的准确性结果
Table 4. Accuracy results of different integration positions of attention mechanism
位置 P/% R/% mAP/% 无注意力 82.7 86.7 86.1 位置 1 85.0 87.9 87.3 位置 2 85.4 88.1 87.8 位置 3 82.5 87.2 85.8
下载: 导出CSV
表 5 颈部网络不同结构的检测结果
Table 5. Detection results of different structures of neck network
结构 mAP/% 权重大小/MB 检测帧率/(帧·s−1) FPN+PAN 86.1 13.7 169.5 4尺度预测头 87.2 14.6 143.2 BiFPN 87.5 13.9 162.6
下载: 导出CSV
表 6 不同损失函数的测试结果
Table 6. Test results of different loss functions
损失函数 AP/% mAP/% 氧化 裂纹 缺失 GIOU 87.7 80.8 87.1 85.2 DIOU 88.6 81.1 87.2 85.7 CIOU 88.4 81.8 88.1 86.1 EIOU 89.5 83.6 88.8 87.3
下载: 导出CSV
表 7 不同模型的测试结果
Table 7. Test results of different models
模型 mAP/% 检测帧率/(帧·s−1) 权重大小/MB SSD 78.0 119.3 91.6 Faster R-CNN 82.5 29.8 521.6 RetinaNet 83.6 45.1 139.1 YOLOv5 86.1 169.5 13.7 本文模型 89.7 156.3 14.0
下载: 导出CSV
-
[1] PITKÄNEN J, HAKKARAINEN T, JESKANEN H, et al. NDT methods for revealing anomalies and defects in gas turbine blades[J]. Insight, 2001, 43: 601-604. [2] ZOU F Q. Review of aero-engine defect detection technology[C]//Proceedings of the IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference. Piscataway: IEEE Press, 2020: 1524-1527. [3] 旷可嘉. 深度学习及其在航空发动机缺陷检测中的应用研究[D]. 广州:华南理工大学, 2017.KUANG K J. Research on deep learning and its application on the defects detection for aero engine[D]. Guangzhou: South China University of Technology, 2017(in Chinese). [4] MALEKZADEH T, ABDOLLAHZADEH M, NEJATI H, et al. Aircraft fuselage defect detection using deep neural networks[J]. ArXiv e-Prints, 2017: arXiv: 1712.09213. [5] KIM Y H, LEE J R. Videoscope-based inspection of turbofan engine blades using convolutional neural networks and image processing[J]. Structural Health Monitoring, 2019, 18(5-6): 2020-2039. doi: 10.1177/1475921719830328 [6] LI D W, LI Y D, XIE Q, et al. Tiny defect detection in high-resolution aero-engine blade images via a coarse-to-fine framework[J]. IEEE Transactions on Instrumentation Measurement, 2021, 70: 3062175. [7] 李龙浦. 基于孔探数据的航空发动机叶片损伤识别研究[D]. 天津:中国民航大学, 2020.LI L P. Research on damage identification of aeroengine blades based on borescope data[D]. Tianjin: Civil Aviation University of China, 2020(in Chinese). [8] 李彬, 汪诚, 丁相玉, 等. 改进YOLOv4的表面缺陷检测算法[J]. 北京航空航天大学学报, 2023, 49(3): 710-717.LI B, WANG C, DING X Y, et al. Surface defect detection algorithm based on improved YOLOv4[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(3): 710-717(in Chinese). [9] 陈为, 梁晨红. 基于改进SSD的航空发动机目标缺陷检测[J]. 控制工程, 2021, 28(12): 2329-2335.CHEN W, LIANG C H. Aeroengine target defect detection based on improved SSD[J]. Control Engineering of China, 2021, 28(12): 2329-2335(in Chinese). [10] 樊玮, 李晨炫, 邢艳, 等. 航空发动机损伤图像的二分类到多分类递进式检测网络[J]. 计算机应用, 2021, 41(8): 2352-2357.FAN W, LI C X, XING Y, et al. Binary classification to multiple classification progressive detection network for aero-engine damage images[J]. Journal of Computer Applications, 2021, 41(8): 2352-2357(in Chinese). [11] HUANG R, DUAN B K, ZHANG Y X, et al. Prior-guided GAN-based interactive airplane engine damage image augmentation method[J]. Chinese Journal of Aeronautics, 2022, 35(10): 222-232. doi: 10.1016/j.cja.2021.11.021 [12] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2020: 1571-1580. [13] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence. Piscataway: IEEE Press, 2015: 1904-1916. [14] LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 936-944. [15] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768. [16] YING Z P, LIN Z T, WU Z Y, et al. A modified-YOLOv5s model for detection of wire braided hose defects[J]. Measurement, 2022, 190: 110683. doi: 10.1016/j.measurement.2021.110683 [17] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141. [18] HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13708-13717. [19] TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020. [20] ZHANG Y F, REN W Q, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression[J]. Neurocomputing, 2022, 506146-157. [21] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 618-626. [22] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[M]// Lecture Notes in Computer Science. Cham: Springer International Publishing, 2016: 21-37. [23] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence. Piscataway: IEEE Press, 2017: 1137-1149. [24] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the 16th IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 2999-3007. 期刊类型引用(0)
其他类型引用(2)
-


 下载:
下载:


 下载:
下载:


 点击查看大图
点击查看大图

计量
- 文章访问数: 833
- HTML全文浏览量: 133
- PDF下载量: 54
- 被引次数: 2
