



Real-time UAV image segmentation algorithm with enhanced contextual feature interaction
-
摘要:
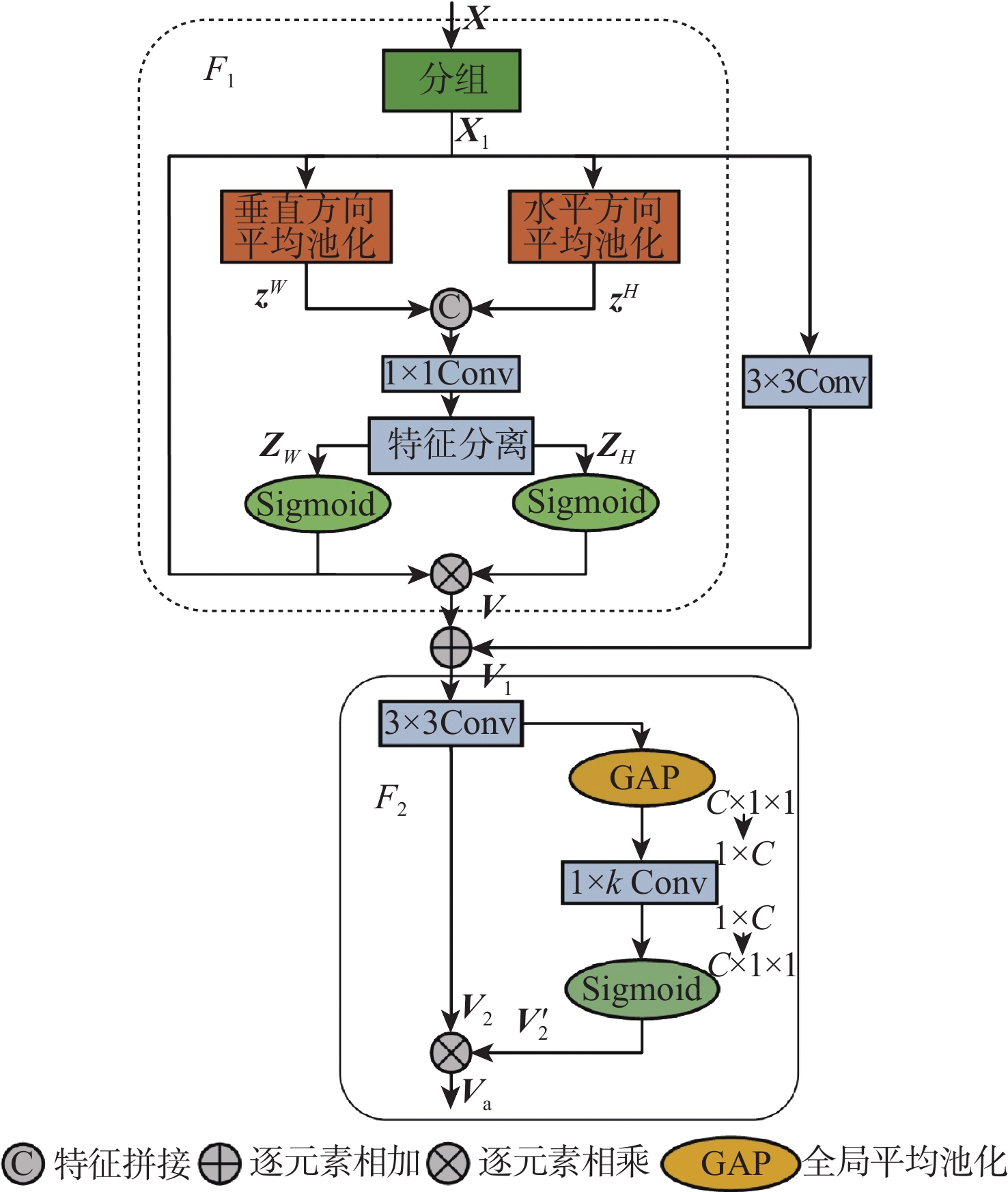
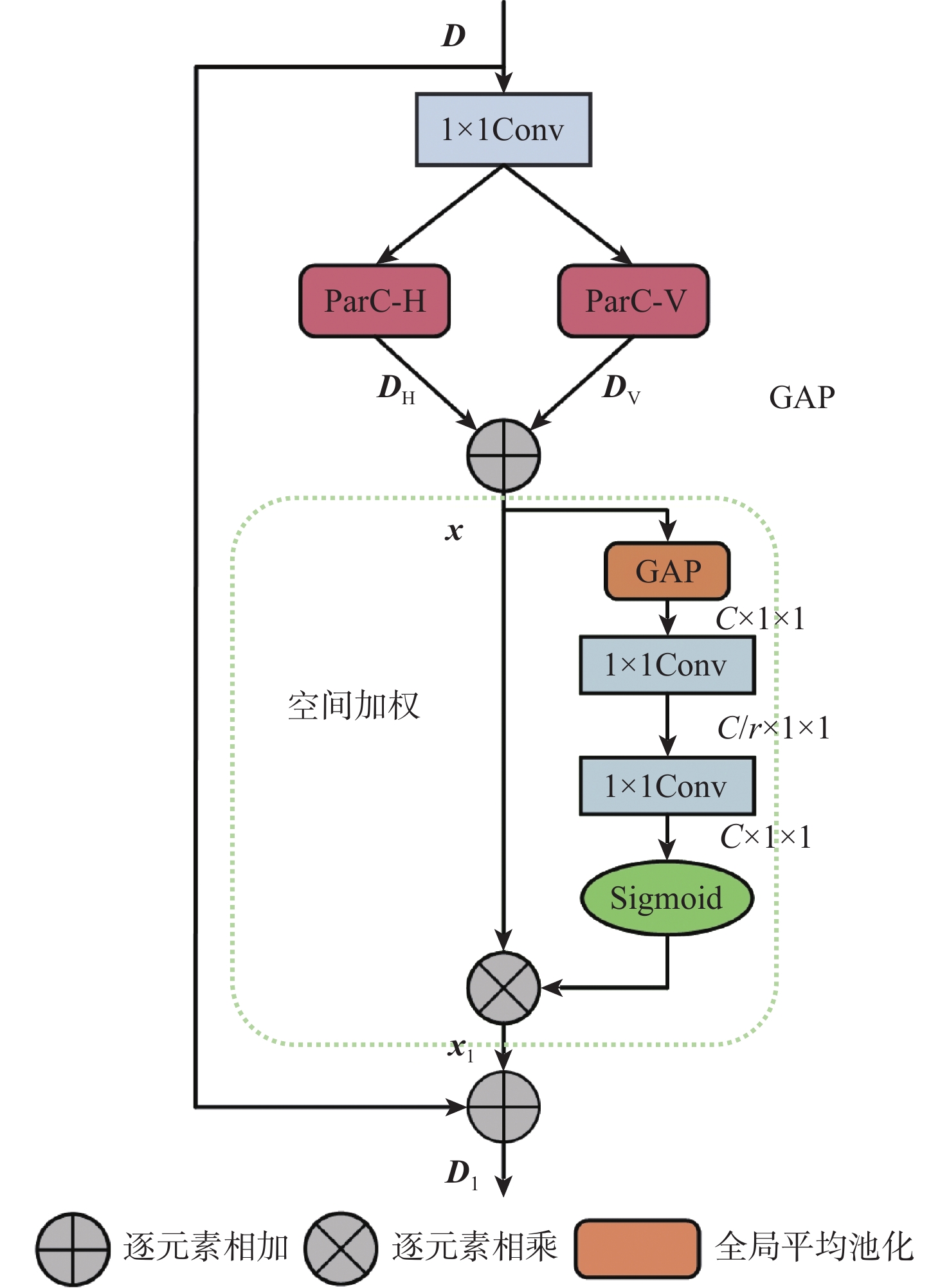
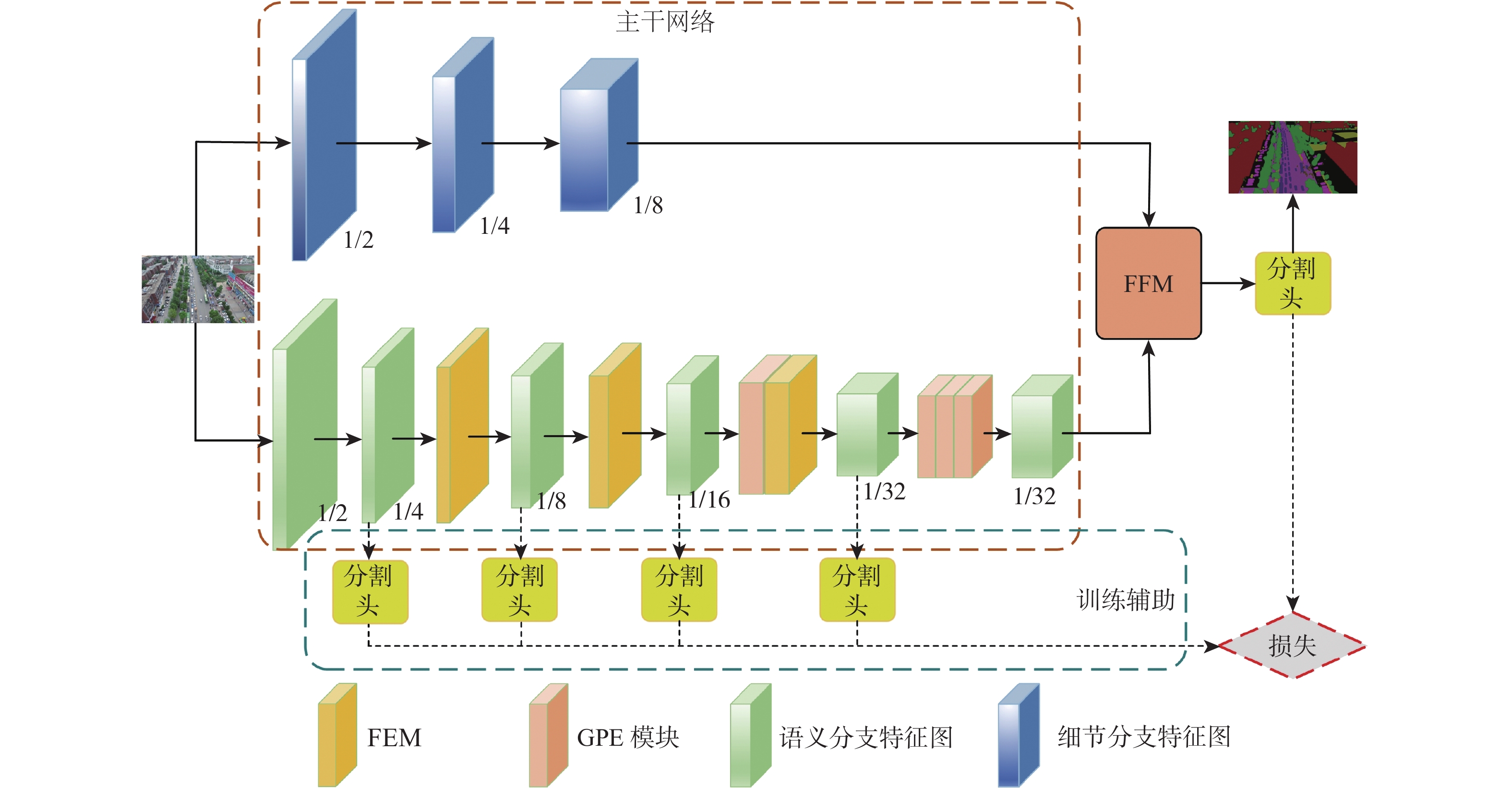
针对无人机影像语义分割任务中轻量级算法缺乏全局信息交互导致分割结果中目标漏检与不完整问题,提出了一种增强上下文特征交互的实时无人机影像分割算法。算法采用双分支结构,利用不同方向的全局平均池化对通道和空间信息进行编码,保留了精准的位置信息,并增强了对图像中局部细节信息的关注;利用位置感知循环卷积和空间加权构建全局感知提取模块,实现了全局上下文信息捕获;对不同尺度特征采用加权操作进行融合,降低了融合过程中的信息损失与算法的计算量。在UAVid 和AeroScapes数据集上对所提算法进行验证,结果显示:平均交并比(mIoU)分别达到66.5%和63.0%,相比BiSeNet V2提升了2.6%和2.2%,分割速度分别达到79.9帧/s和71.4帧/s,相比BiSeNet V2提升了8.3帧/s和6.9帧/s,在保证实时分割速度的同时取得了较好的分割精度。
Abstract:A real-time UAV image segmentation algorithm with enhanced contextual feature interaction is proposed to address the problem of target omission and incompleteness in segmentation results due to the lack of global information interaction in lightweight algorithms for semantic segmentation tasks of UAV images. The approach uses a two-branch structure. To encode the channel and spatial information, global average pooling in various directions was used. This preserves the correct position information and increases the attention to the local detail information in the image. Secondly, a global perceptual extraction module was constructed by using the position-aware circular convolution and spatial weighting, which achieves the global contextual information capture; Finally, the weighting operation is applied to the features of different scales for the fusion, which reduces the information loss in the fusion process and the computation of the algorithm. The UAVid and AeroScapes datasets are used to validate the algorithm. The results indicate that the mean intersection over union (mIoU) achieved 66.5% and 63.0%, respectively, marking a 2.6% and 2.2% improvement over BiSeNet V2. The segmentation speeds reached 79.9 and 71.4 frames per second, respectively, showing an increase of 8.3 and 6.9 frames per second compared to BiSeNet V2. This method ensures real-time segmentation speed while delivering satisfactory segmentation accuracy.
-
Key words:
- semantic segmentation /
- UAV image /
- convolutional neural network /
- context information /
- feature fusion
-
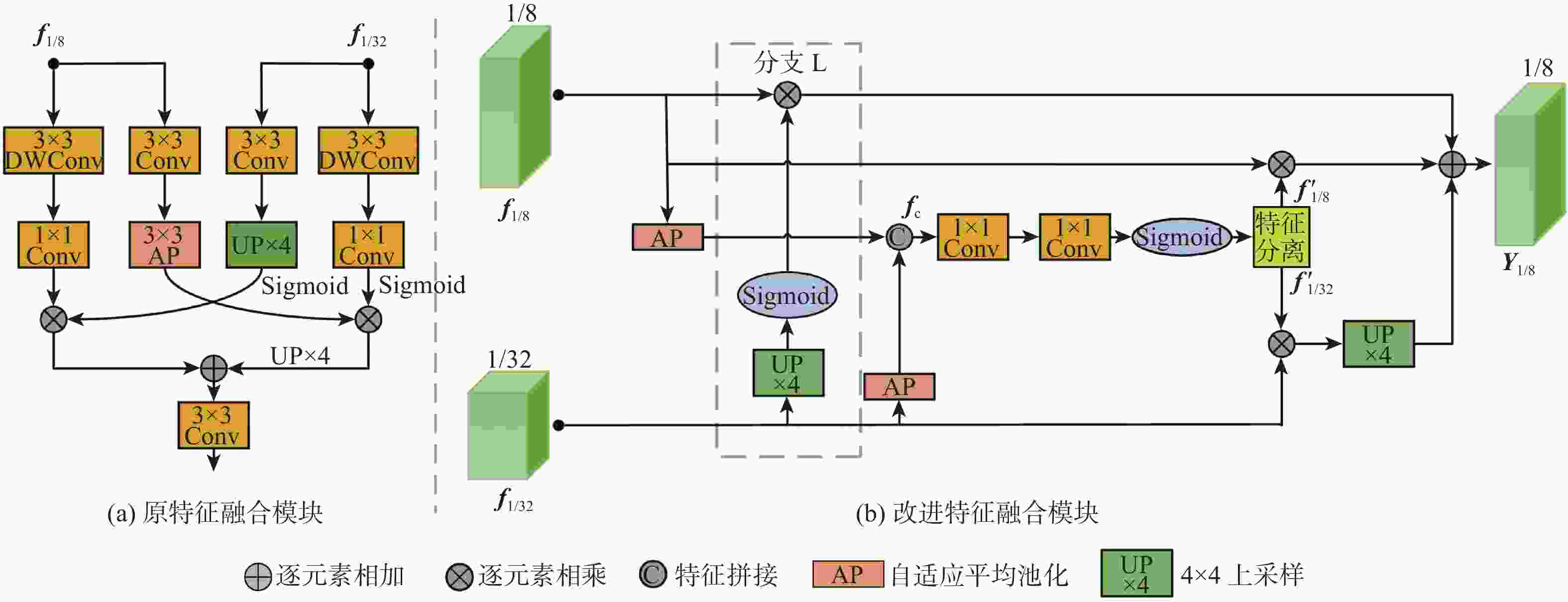
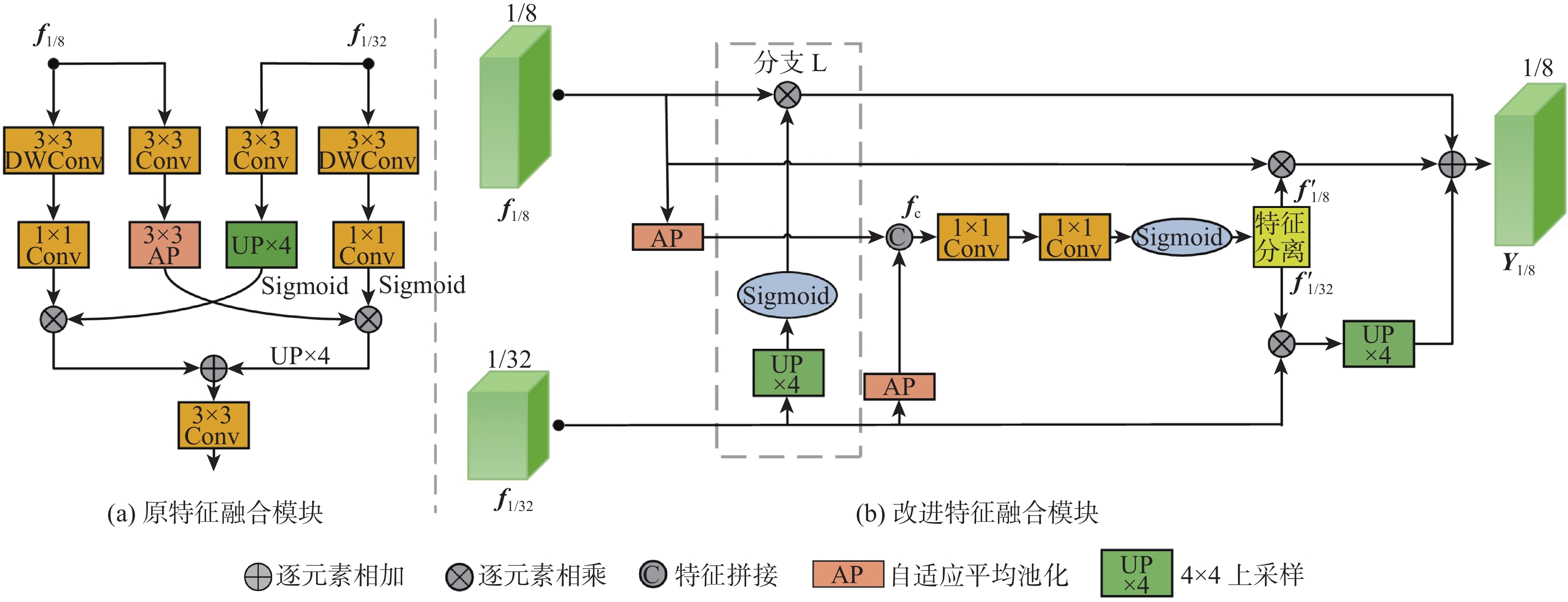
图 4 原特征融合模块和改进特征融合模块的对比
Figure 4. Comparison of original feature fusion module and improved feature fusion module
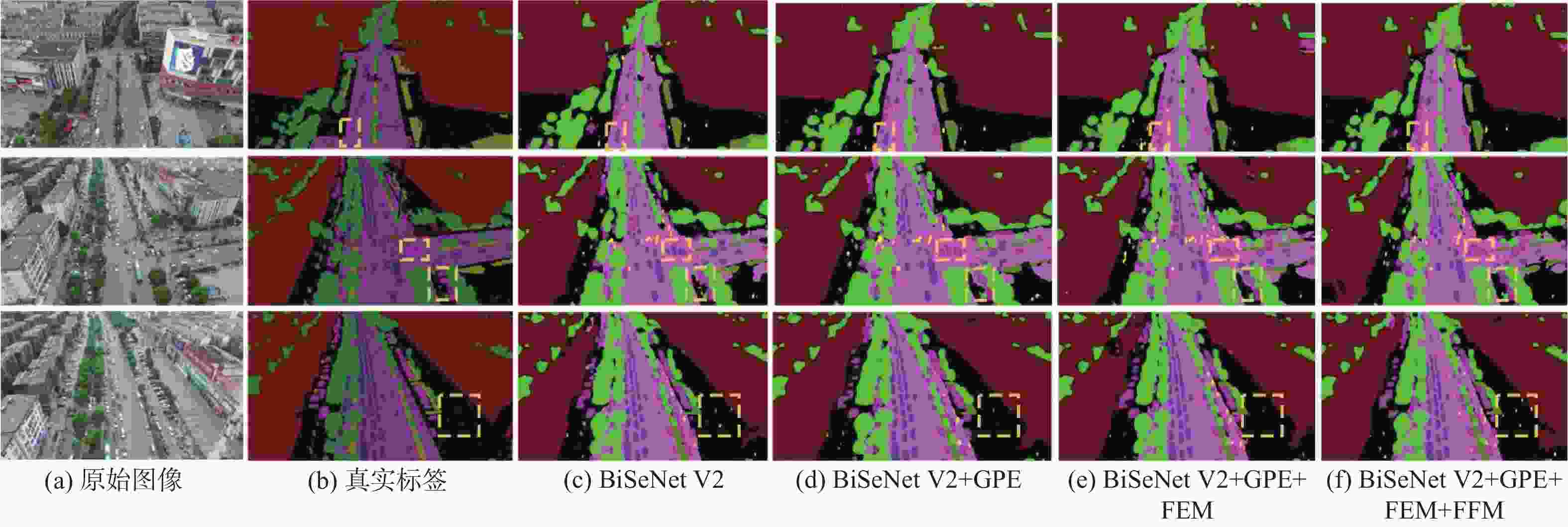
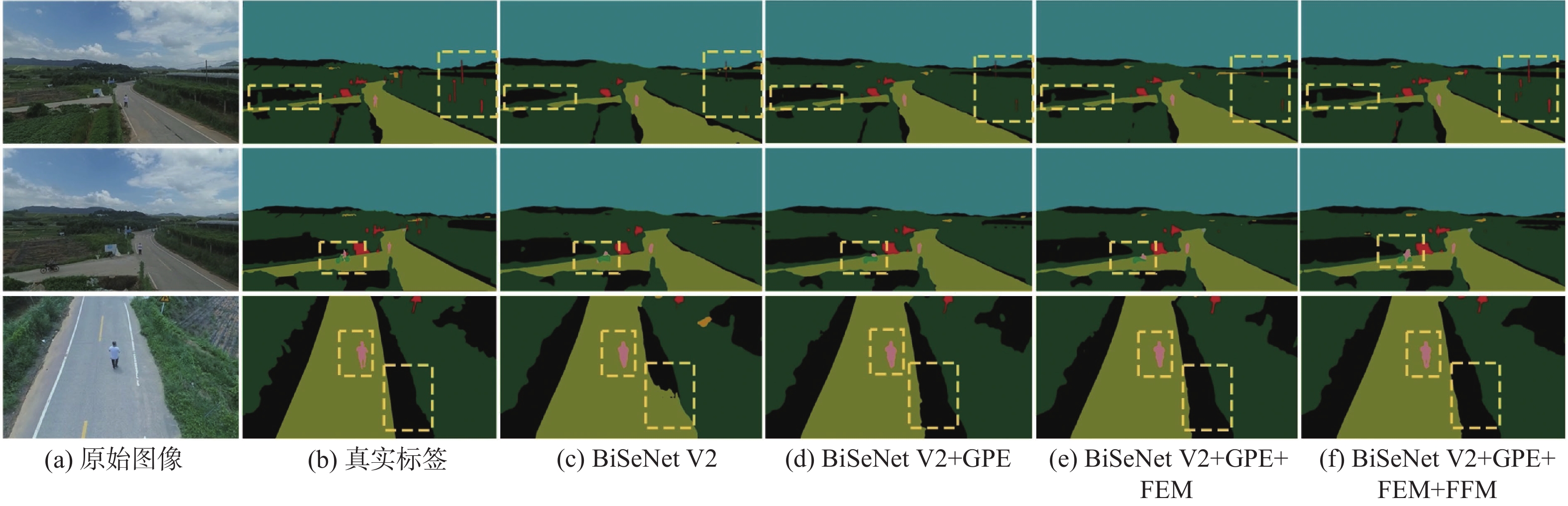
图 5 UAVid数据集上消融实验视觉对比结果
Figure 5. Visual comparison results of ablation experiments on UAVid dataset
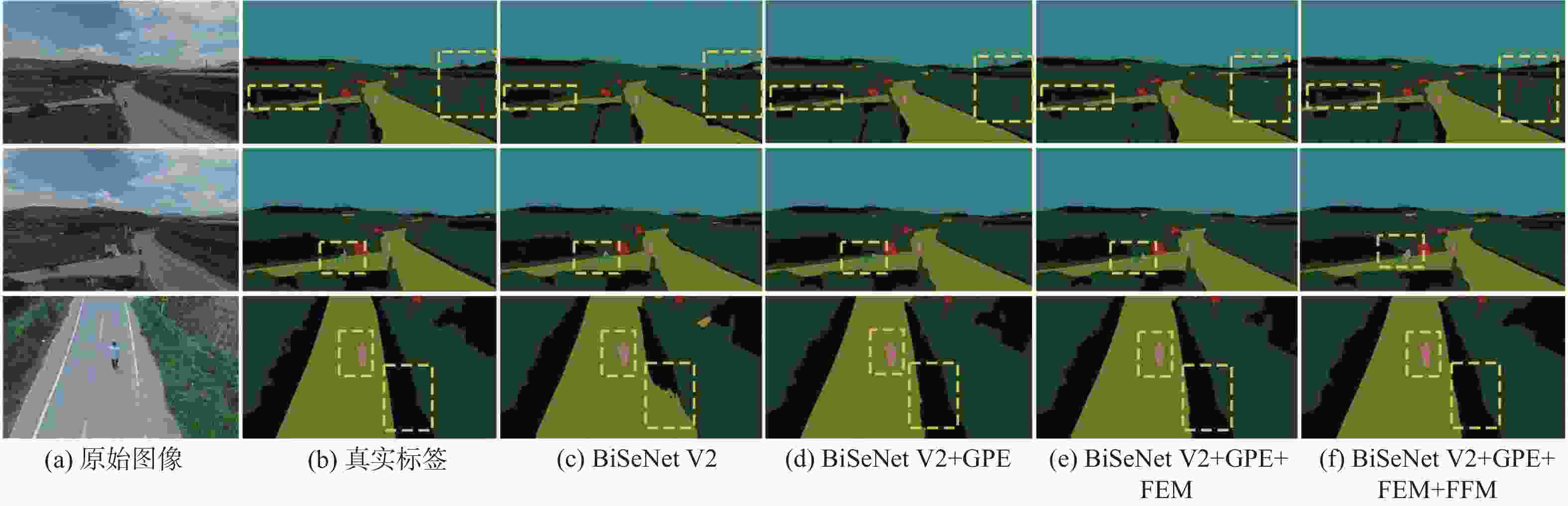
图 6 AeroScapes数据集上消融实验视觉对比结果
Figure 6. Visual comparison results of ablation experiments on AeroScape dataset

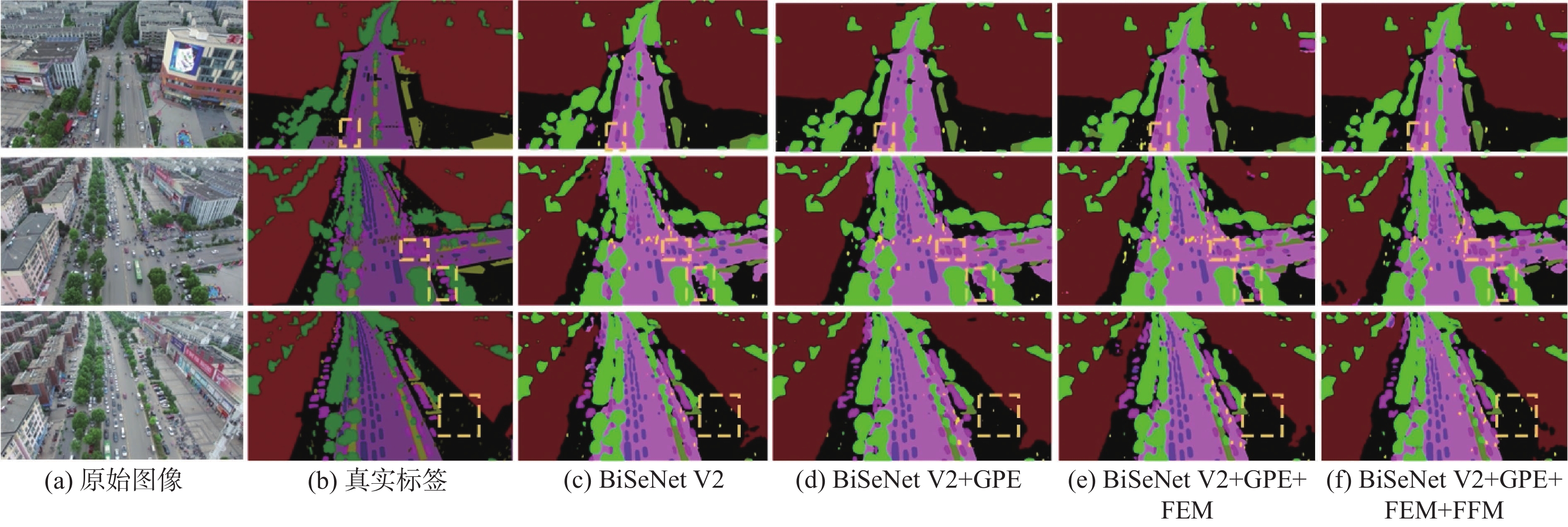
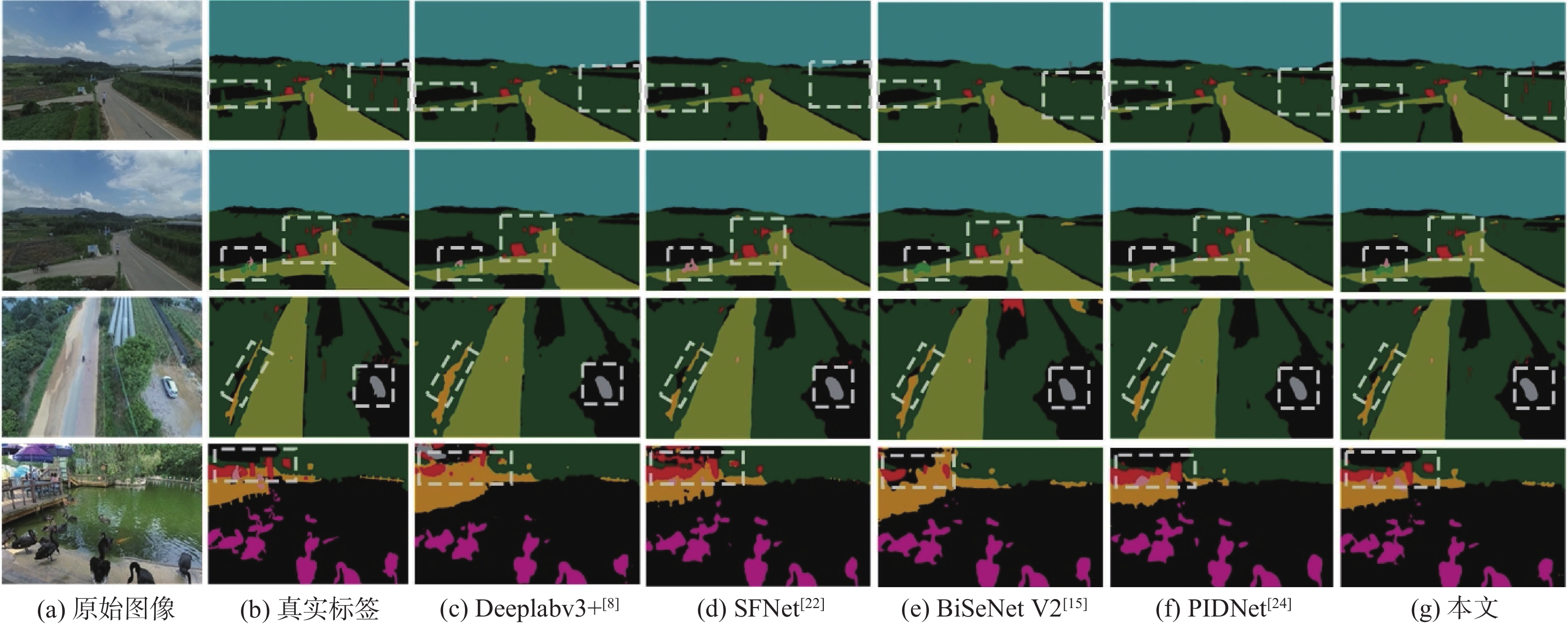
图 7 部分算法在UAVid数据集上预测结果比较
Figure 7. Comparison of prediction results of some selected algorithms on UAVid dataset
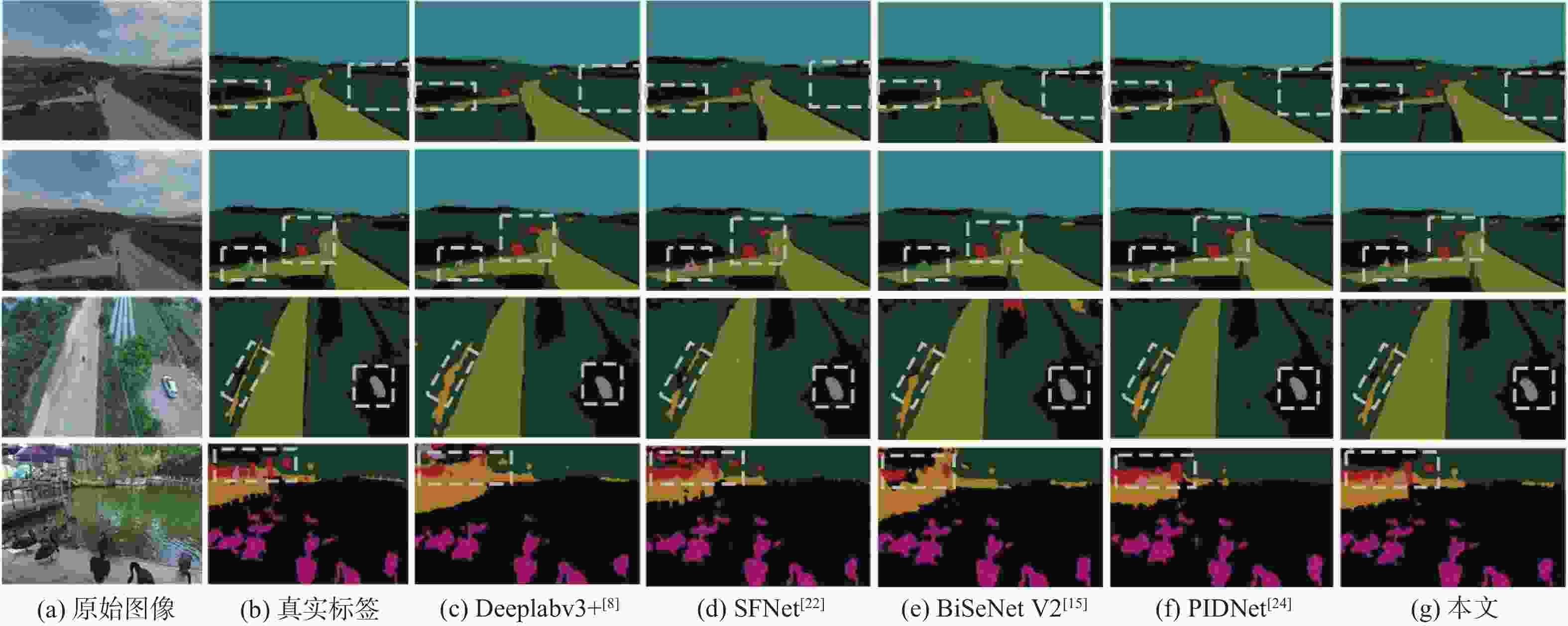
图 8 部分算法在AeroScapes数据集上预测结果比较
Figure 8. Comparison of prediction results of some selected algorithms on AeroScapes dataset
表 1 UAVid数据集上各模块消融实验数据
Table 1. Data from ablation experiment of modules on UAVid dataset
Baseline GPE模块 FEM FFM Swin-Block mIoU/% 浮点运算速度/109 s−1 分割速度/(帧·s−1) √ 63.9 14.78 71.6 √ √ 64.8 12.82 69.0 √ √ 65.2 11.58 74.8 √ √ 64.4 10.24 82.2 √ √ √ 65.7 11.79 74.1 √ √ √ 65.0 12.50 74.2 √ √ √ 65.4 11.24 81.7 √ √ √ √ 66.5 12.93 79.9 √ √ 65.3 21.65 38.3 √ √ √ 66.2 20.07 42.1 √ √ √ √ 66.9 19.84 45.6  下载: 导出CSV
下载: 导出CSV
表 2 AeroScapes数据集上各模块消融实验数据
Table 2. Data from ablation experiments of modules on AeroScapes dataset
Baseline GPE模块 FEM FFM mIoU/% 分割速度/(帧·s−1) √ 60.8 64.5 √ √ 61.1 59.2 √ √ 61.8 66.2 √ √ 61.3 77.4 √ √ √ 61.9 64.6 √ √ √ 62.5 66.8 √ √ √ 62.1 72.5 √ √ √ √ 63.0 71.4
下载: 导出CSV
表 3 不同算法在UAVid数据集上实验数据比较
Table 3. Comparison of experimental data of different algorithms on UAVid dataset
模型 Backbone mIoU/% 浮点运算速度/109 s−1 分割速度/(帧·s−1) SegNet[10] 55.3 112.63 11.5 U-Net[7] 58.4 64.01 12.6 SwiftNet[17] Resnet18 62.1 13.42 48.9 ICNet[11] PSPNet50 61.9 25.91 73.2 Deeplabv3+[8] MobileNetV2 61.4 20.47 71.2 BiSeNet[13] Resnet18 61.8 12.64 74.1 SFNet[22] Resnet18 65.3 18.52 62.4 BiSeNet V2[15] 63.9 14.78 71.6 HyperSeg-S[23] EfficientNet-B1 64.3 10.12 27.5 PIDNet[24] 62.0 5.07 74.8 本文 66.5 12.93 79.9
下载: 导出CSV
表 4 不同算法在AeroScapes数据集上实验数据比较
Table 4. Comparison of experimental data of different algorithms on AeroScapes dataset
模型 Backbone 参数量 mIoU/% 分割速度/(帧·s−1) SegNet[10] 15.62×106 50.6 11.8 U-Net[7] 17.26×106 51.4 11.1 SwiftNet[17] Resnet18 12.07×106 60.1 51.1 ICNet[11] PSPNet50 23.15×106 59.5 67.2 Deeplabv3+[8] MobileNetV2 5.82×106 59.9 61.8 BiSeNet[13] Resnet18 13.62×106 58.2 66.9 SFNet[22] Resnet18 12.72×106 62.1 64.0 BiSeNet V2[15] 5.21×106 60.8 64.5 HyperSeg-S[23] EfficientNet-B1 10.24×106 59.4 27.7 PIDNet[24] 7.72×106 60.9 66.5 本文 6.44×106 63.0 71.4
下载: 导出CSV
-
[1] 宝音图, 刘伟, 李润生, 等. 遥感图像语义分割的空间增强注意力U型网络[J]. 北京航空航天大学学报, 2023, 49(7): 1828-1837.BAO Y T, LIU W, LI R S, et al. Semantic segmentation of remote sensing images based on U-shaped network combined with spatial enhance attention[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(7): 1828-1837(in Chinese). [2] 吴泽康, 赵姗, 李宏伟, 等. 遥感图像语义分割空间全局上下文信息网络[J]. 浙江大学学报(工学版), 2022, 56(4): 795-802.WU Z K, ZHAO S, LI H W, et al. Spatial global context information network for semantic segmentation of remote sensing image[J]. Journal of Zhejiang University (Engineering Science), 2022, 56(4): 795-802(in Chinese). [3] LIU S Y, CHENG J, LIANG L K, et al. Light-weight semantic segmentation network for UAV remote sensing images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 8287-8296. [4] ZHANG G, LI Z, TANG C, et al. CEDNet: a cascade encoder-decoder network for dense prediction[J]. Pattern Recognition, 2025, 158: 111072. [5] OUYANG D L, HE S, ZHANG G Z, et al. Efficient multi-scale attention module with cross-spatial learning[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2023: 1-5. [6] YU C Q, XIAO B, GAO C X, et al. Lite-HRNet: a lightweight high-resolution network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 10435-10445. [7] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of the Medical Image Computing and Computer-Assisted Intervention. Berlin: Springer, 2015: 234-241. [8] CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 833-851. [9] PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation[EB/OL]. (2016-06-07)[2023-12-01]. https://arxiv.org/abs/1606.02147. [10] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. [11] ZHAO H S, QI X J, SHEN X Y, et al. ICNet for real-time semantic segmentation on high-resolution images[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 418-434. [12] WU T Y, TANG S, ZHANG R, et al. CGNet: a light-weight context guided network for semantic segmentation[J]. IEEE Transactions on Image Processing, 2020, 30: 1169-1179. [13] YU C Q, WANG J B, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 334-349. [14] DING X H, ZHANG X Y, MA N N, et al. RepVGG: making VGG-style ConvNets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13728-13737. [15] YU C Q, GAO C X, WANG J B, et al. BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129(11): 3051-3068. [16] YI S, LIU X, LI J J, et al. UAVformer: a composite transformer network for urban scene segmentation of UAV images[J]. Pattern Recognition, 2023, 133: 109019. [17] WOO S, DEBNATH S, HU R H, et al. Convnext v2: co-designing and scaling ConvNets with masked autoencoders[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 16133-16142. [18] ZHANG H, WU C R, ZHANG Z Y, et al. ResNeSt: split-attention networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 2735-2745. [19] ORŠIC M, KREŠO I, BEVANDIC P, et al. In defense of pre-trained ImageNet architectures for real-time semantic segmentation of road-driving images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 12599-12608. [20] ZHANG H K, HU W Z, WANG X Y. ParC-net: position aware circular convolution with merits from ConvNets and Transformer[C]// Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2022: 613-630. [21] LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 9992-10002. [22] LI X T, YOU A S, ZHU Z, et al. Semantic flow for fast and accurate scene parsing[C]//Proceedings of the 16th European Conference on Computer Vision. Berlin: Springer, 2020: 775-793. [23] NIRKIN Y, WOLF L, HASSNER T. HyperSeg: patch-wise hypernetwork for real-time semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 4060-4069. [24] XU J C, XIONG Z X, BHATTACHARYYA S P. PIDNet: a real-time semantic segmentation network inspired by PID controllers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 19529-19539. -

 下载:
下载:


 点击查看大图
点击查看大图
计量
- 文章访问数: 226
- HTML全文浏览量: 107
- PDF下载量: 148
- 被引次数: 0
