



FastSAM-assisted representation enhancement for self-supervised monocular depth estimation
-
摘要:
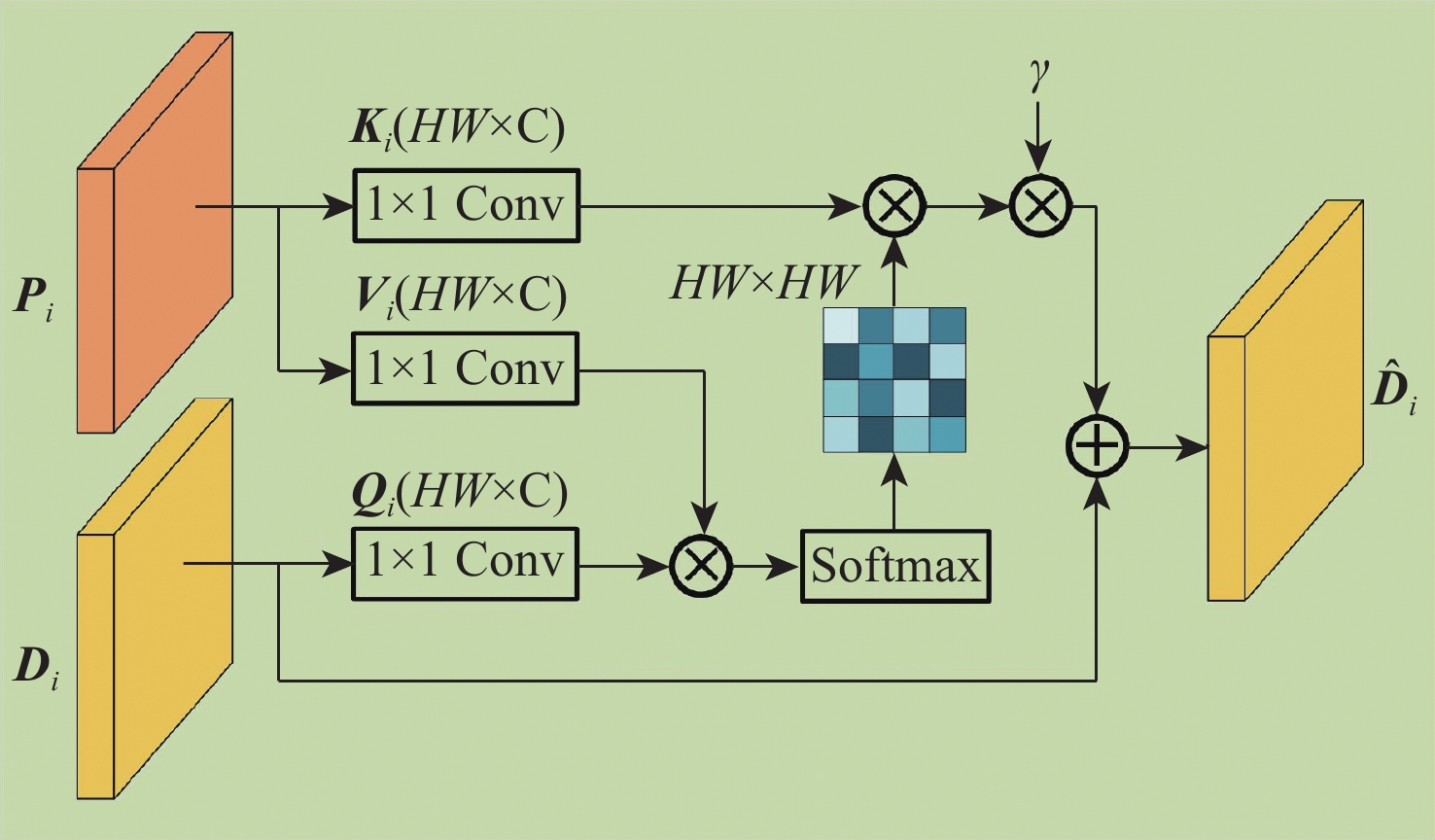
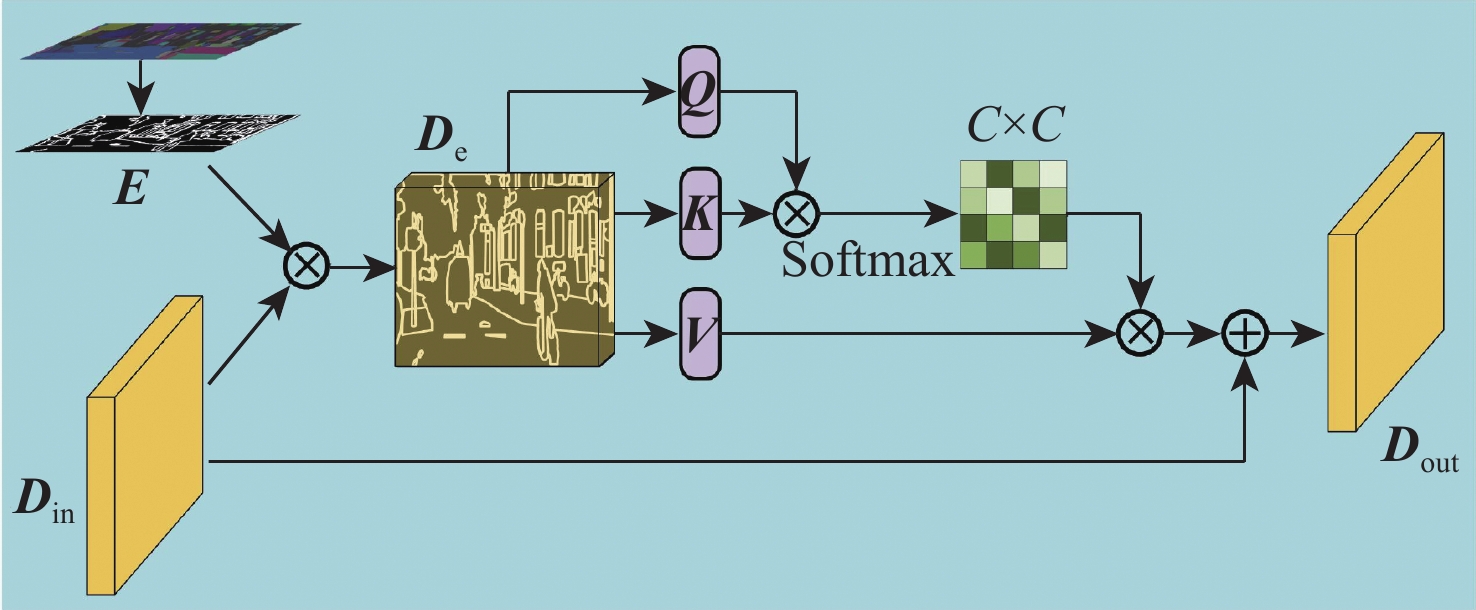
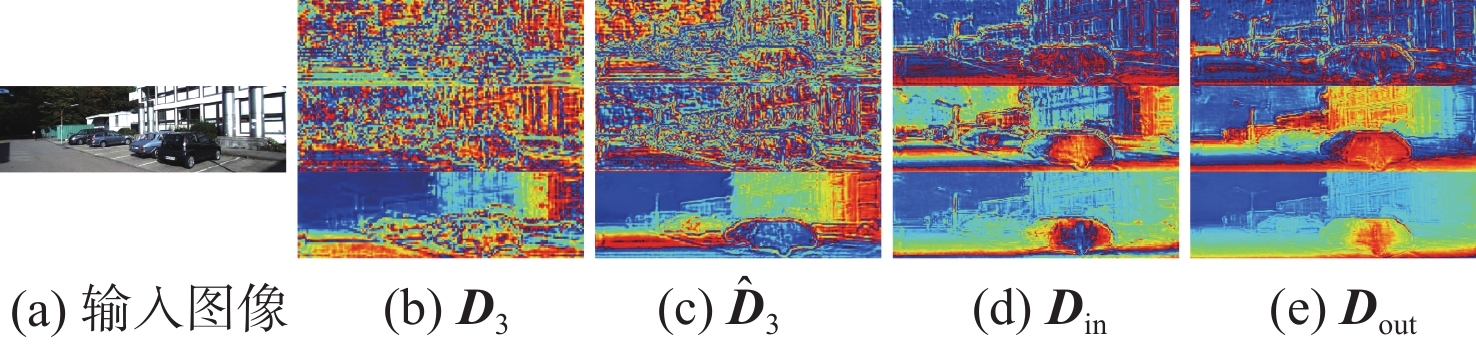
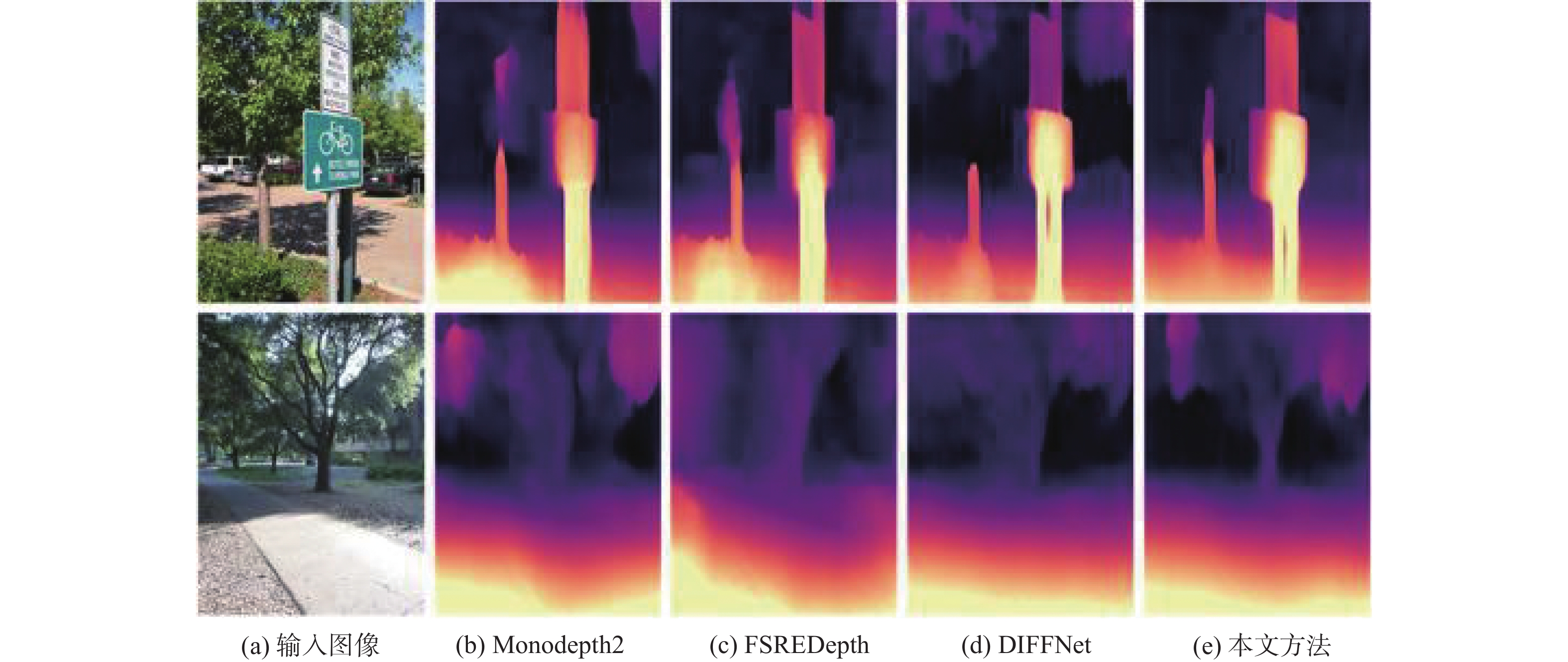
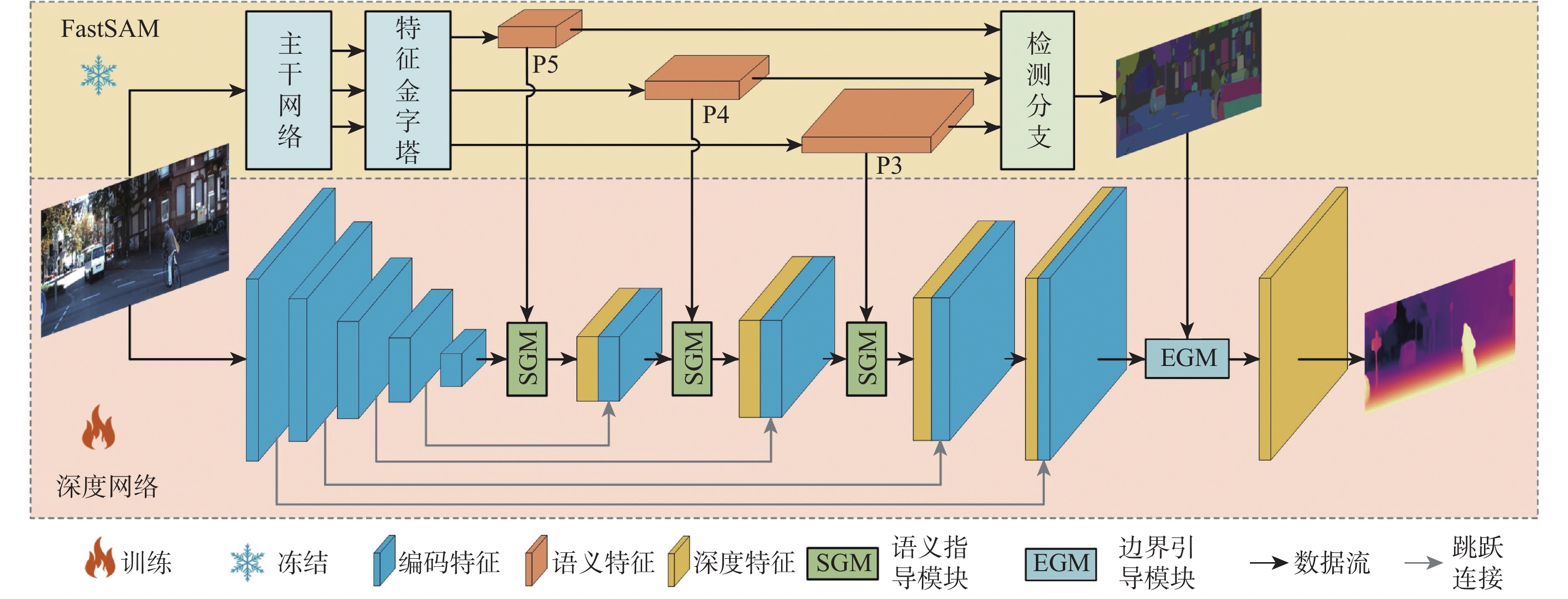
针对自监督单目深度估计方法对薄结构区域和边界区域深度估计效果不佳的问题,提出一种基于FastSAM辅助表示增强的自监督单目深度估计的方法。首先,引入FastSAM,在不引入额外监督的情况下为深度网络提供丰富的语义信息。其次,提出语义指导模块(SGM),以探索语义特征和深度特征之间的相关性,并增强全局特征表示。另外,设计(EGM),以引导网络更加关注局部特征,从而改善边界深度估计性能。大量实验表明,所提方法优于最先进的方法,尤其是在薄结构区域和边界区域的深度估计上具有明显优势。
Abstract:In order to address the issue of unsatisfactory performance in self-supervised monocular depth estimation methods when applied to thin structured regions and boundary regions, this paper proposes a method for self-supervised monocular depth estimation based on FastSAM-assisted representation enhancement. Firstly, without the need for extra supervision, FastSAM is presented to supply the depth network with rich semantic information. Secondly, a semantic guidance module (SGM) is proposed to explore the correlation between semantic features and depth features, and to enhance the global feature representation. Furthermore, to enhance the performance of boundary depth estimation, a edge guiding module (EGM) is built to direct the network to focus more on local features. Extensive experiments show that the proposed method outperforms the state-of-the-art methods, especially in depth estimation of thin-structured regions and boundary regions.
-
Key words:
- depth estimation /
- self-supervised /
- FastSAM /
- semantic information /
- feature representation
-
表 1 不同方法在KITTI数据集上的定量检测结果
Table 1. Quantitative detection results of different methods on the KITTI dataset
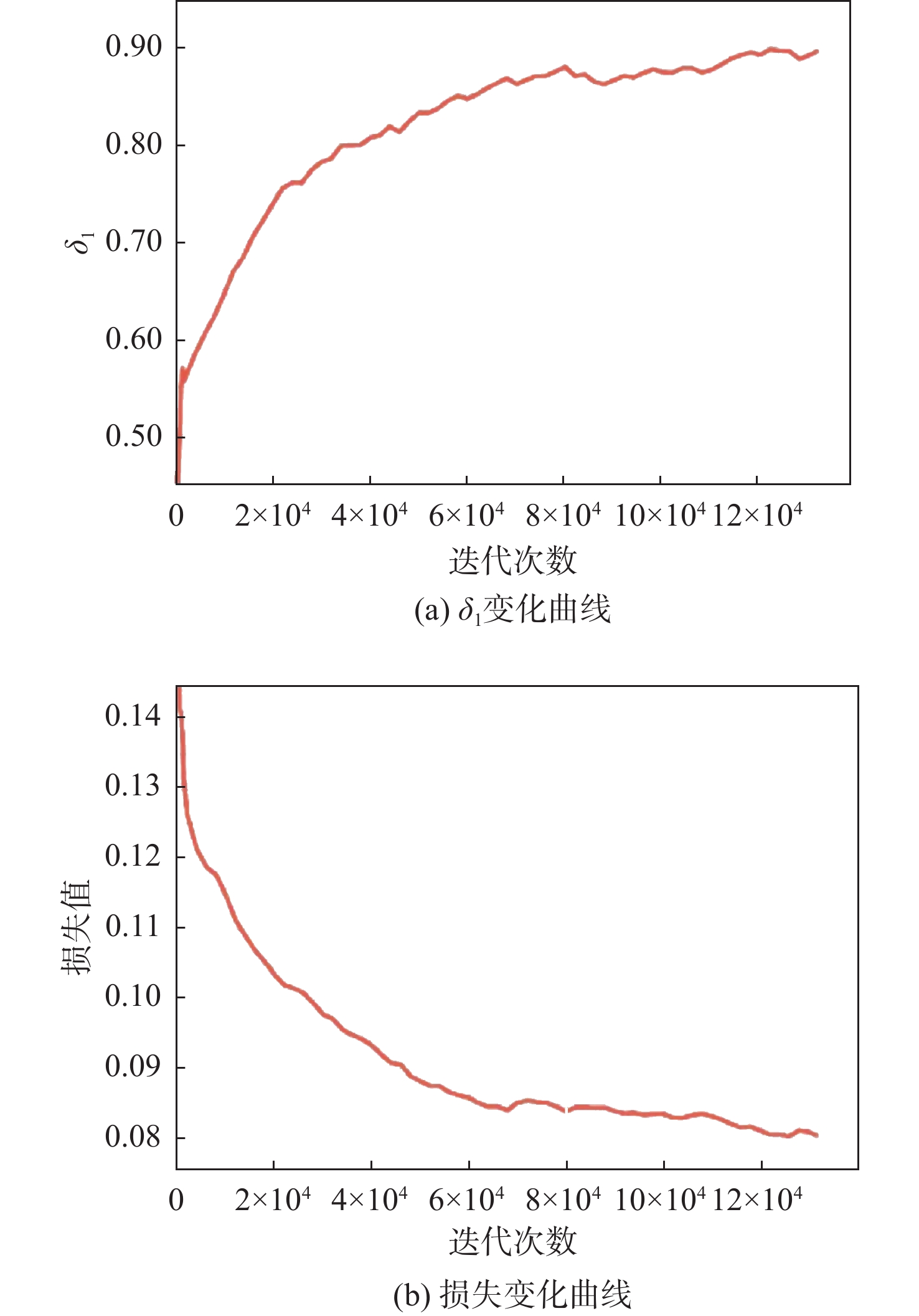
方法 监督方式 Abs Rel↓ Sq Rel↓ RMS↓ RMS log↓ δ1↑ δ2↑ δ3↑ Monodepth2[7] M 0.115 0.903 4.863 0.193 0.877 0.959 0.981 SAFENet[16] M+Se 0.112 0.788 4.582 0.187 0.878 0.963 0.983 SGDepth[25] M+Se 0.113 0.835 4.693 0.191 0.879 0.961 0.981 SGRLDepth[28] M 0.102 0.698 4.381 0.178 0.896 0.964 0.984 WaveletMonodepth[29] S 0.106 0.824 4.824 0.205 0.870 0.949 0.975 FSREDepth[17] M+Se 0.105 0.722 4.547 0.182 0.886 0.964 0.984 HRDepth[22] M 0.109 0.792 4.632 0.185 0.884 0.962 0.983 DepthHints[30] S 0.102 0.762 4.602 0.189 0.880 0.960 0.981 VADepth[31] M 0.109 0.785 4.624 0.190 0.875 0.960 0.982 DIFFNet[2] M 0.102 0.764 4.483 0.180 0.896 0.965 0.983 本文 M 0.101 0.688 4.383 0.178 0.900 0.965 0.984 注:“↓”表示数值越低越好,“↑”表示数值越高越好,M表示单目自监督,S表示立体对自监督,Se表示语义监督。最优结果用粗体表示,次优结果添加了下划线。  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果
Table 2. Results of ablation experiments
模型 Abs Rel↓ Sq Rel↓ RMS↓ RMS log↓ δ1↑ δ2↑ δ3↑ Baseline 0.109 0.816 4.605 0.186 0.878 0.962 0.983 Baseline+语义指导模块 0.102 0.709 4.436 0.180 0.893 0.964 0.984 Baseline+边界引导模块 0.105 0.743 4.501 0.183 0.886 0.963 0.983 本文 0.101 0.688 4.383 0.178 0.900 0.965 0.984
下载: 导出CSV
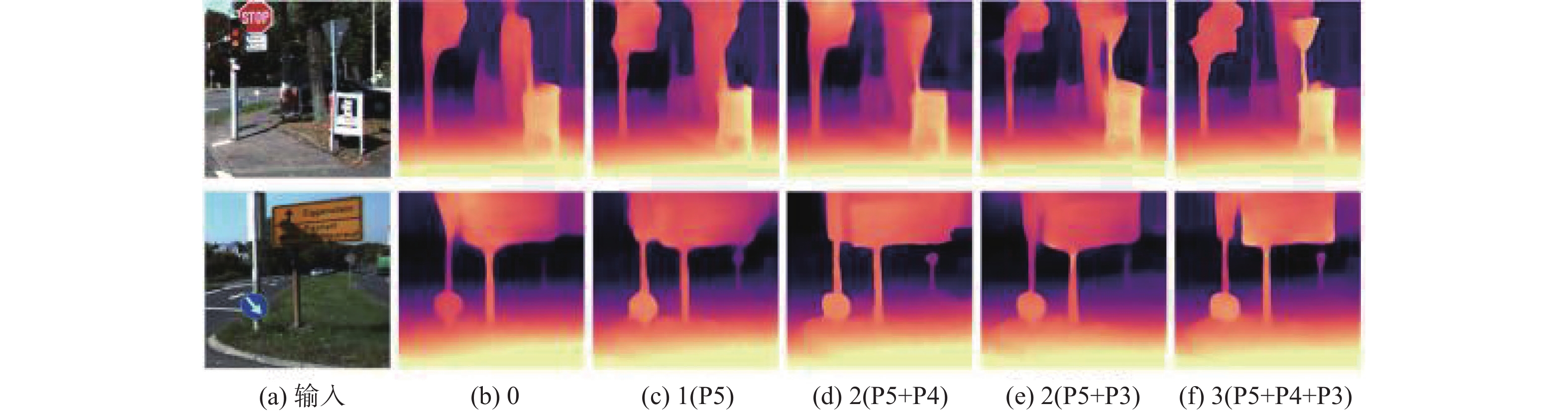
表 3 语义指导模块不同嵌入方案的定量结果
Table 3. Quantitative results of different embedding schemes for the semantic guidance module
数量 Abs Rel↓ Sq Rel↓ RMS↓ RMS log↓ δ1↑ δ2↑ δ3↑ 0 0.109 0.816 4.605 0.186 0.878 0.962 0.983 1(P5) 0.106 0.783 4.545 0.184 0.884 0.963 0.983 2(P5+P4) 0.104 0.761 4.507 0.182 0.887 0.964 0.984 2(P5+P3) 0.103 0.743 4.474 0.182 0.889 0.963 0.984 3(P5+P4+P3) 0.102 0.709 4.436 0.180 0.893 0.964 0.984
下载: 导出CSV
-
[1] 柴国强, 薄祥仕, 刘海军, 等. 基于不确定性单目图像自监督场景深度估计[J]. 北京航空航天大学学报, 2024, 50(12): 3780-3787.CHAI G Q, BO X S, LIU H J, et al. Self-supervised monocular depth estimation based on uncertainty[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(12): 3780-3787. [2] ZHOU H, GREENWOOD D, TAYLOR S. Self-supervised monocular depth estimation with internal feature fusion[EB/OL]. (2023-11-20)[2021-10-18]. https://doi.org/10.48550/arXiv.2110.09482. [3] 张冬冬, 王春平, 付强. 基于人眼视觉机制的伪装目标检测网络[J]. 北京航空航天大学学报, 2025, 51(7): 2553-2561.ZHANG D D, WANG C P, FU Q. Camouflaged object detection network based on human visual mechanisms[J]. Journal of Beijing University of Aeronautics and Astronautics, 2025, 51(7): 2553-2561(in Chinese). [4] LEE J H, HAN M, KO D W, et al. From big to small: Multi-scale local planar guidance for monocular depth estimation[EB/OL]. (2023-11-21)[2019-07-24]. https://doi.org/10.48550/arXiv.1907.10326. [5] PATIL V, SAKARIDIS C, LINIGER A, et al. P3Depth: monocular depth estimation with a piecewise planarity prior[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 1600-1611. [6] LIU C, KUMAR S, GU S, et al. Va-depthnet: A variational approach to single image depth prediction[EB/OL]. (2023-11-22)[2023-02-13]. https://doi.org/10.48550/arXiv.2302.06556. [7] GODARD C, MAC AODHA O, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 3827-3837. [8] EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]//Proceedings of Advances in Neural Information Processing Systems. Vancouver: NeurIPS, 2014. [9] FAROOQ BHAT S, ALHASHIM I, WONKA P. AdaBins: depth estimation using adaptive bins[C]//Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 4008-4017. [10] BHAT S F, ALHASHIM I, WONKA P. Localbins: improving depth estimation by learning local distributions[C]//Computer Vision–ECCV 2022. Berlin: Springer, 2022: 480-496. [11] GUO X Y, LI H S, YI S, et al. Learning monocular depth by distilling cross-domain stereo networks[C]//Computer Vision–ECCV 2018. Berlin: Springer, 2018: 506-523. [12] ZHAO S S, FU H, GONG M M, et al. Geometry-aware symmetric domain adaptation for monocular depth estimation[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 9780-9790. [13] RANFTL R, BOCHKOVSKIY A, KOLTUN V. Vision transformers for dense prediction[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 12159-12168. [14] KIM D, KA W, AHN P, et al. Global-local path networks for monocular depth estimation with vertical cutdepth[EB/OL]. (2023-11-30)[2022-01-19]. https://doi.org/10.48550/arXiv.2201.07436. [15] ZHANG N, NEX F, VOSSELMAN G, et al. Lite-mono: a lightweight CNN and transformer architecture for self-supervised monocular depth estimation[C]//Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 18537-18546. [16] CHOI J, JUNG D, LEE D, et al. SAFENet: self-supervised monocular depth estimation with semantic-aware feature extraction[EB/OL]. (2023-12-01)[2020-08-06]. https://doi.org/10.48550/arXiv.2010.02893. [17] JUNG H, PARK E, YOO S. Fine-grained semantics-aware representation enhancement for self-supervised monocular depth estimation[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 12622-12632. [18] LI R, MAO Q, WANG P, et al. Semantic-guided representation enhancement for self-supervised monocular trained depth estimation[EB/OL]. (2023-12-03)[2020-12-15]. https://doi.org/10.48550/arXiv.2012.08048. [19] KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[EB/OL]. (2023-12-04)[2024-04-05]. https://doi.org/10.48550/arXiv.2304.02643. [20] ZHAO X, DING W C, AN Y Q, et al. Fast segment anything[EB/OL]. (2023-12-05)[2023-06-21]. https://doi.org/10.48550/arXiv.2306.12156. [21] PENG R, WANG R, LAI Y, et al. Excavating the potential capacity of self-supervised monocular depth estimation[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 15540-15549. [22] LYU X Y, LIU L, WANG M M, et al. HR-Depth: high resolution self-supervised monocular depth estimation[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(3): 2294-2301. [23] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015. Berlin: Springer, 2015: 234-241. [24] NEKRASOV V, DHARMASIRI T, SPEK A, et al. Real-time joint semantic segmentation and depth estimation using asymmetric annotations[C]//Proceedings of the 2019 International Conference on Robotics and Automation. Piscataway: IEEE Press, 2019: 7101-7107. [25] KLINGNER M, TERMÖHlen J A, MIKOLAJCZYK J, et al. Self-supervised monocular depth estimation: solving the dynamic object problem by semantic guidance[C]//Computer Vision–ECCV 2020. Berlin: Springer, 2020: 582-600. [26] GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2012: 3354-3361. [27] ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6612-6619. [28] GUIZILINI V, HOU R, LI J, et al. Semantically-guided representation learning for self-supervised monocular depth[EB/OL]. (2023-12-15)[2020-02-27]. https://doi.org/10.48550/arXiv.2002.12319. [29] RAMAMONJISOA M, FIRMAN M, WATSON J, et al. Single image depth prediction with wavelet decomposition[C]//Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 11084-11093. [30] WATSON J, FIRMAN M, BROSTOW G, et al. Self-supervised monocular depth hints[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 2162-2171. [31] XIANG J, WANG Y, AN L F, et al. Visual attention-based self-supervised absolute depth estimation using geometric priors in autonomous driving[J]. IEEE Robotics and Automation Letters, 2022, 7(4): 11998-12005. [32] SAXENA A, SUN M, NG A Y. Make3D: learning 3D scene structure from a single still image[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(5): 824-840. -

 下载:
下载:



 点击查看大图
点击查看大图
计量
- 文章访问数: 298
- HTML全文浏览量: 127
- PDF下载量: 125
- 被引次数: 0
