



-
摘要:
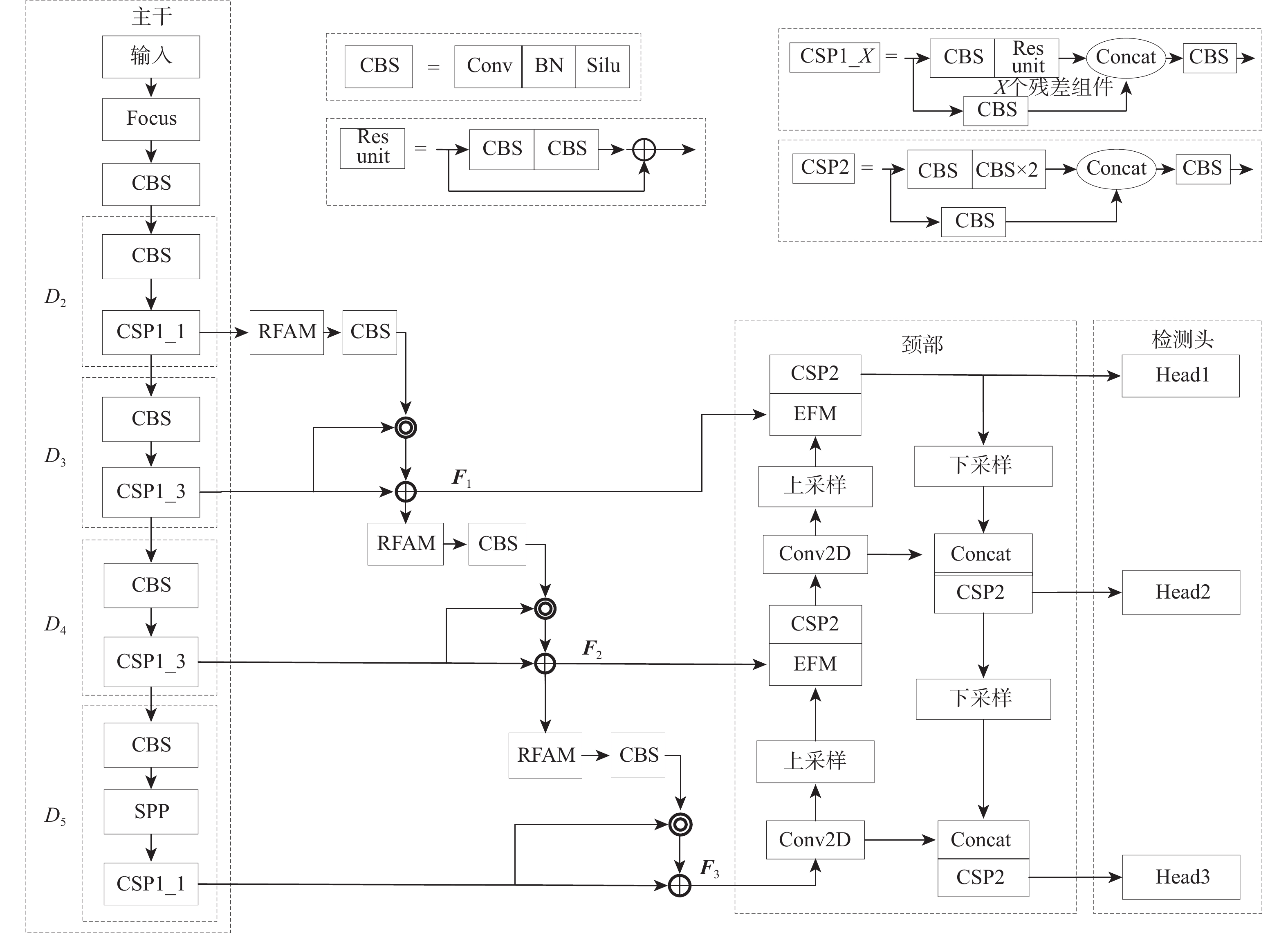
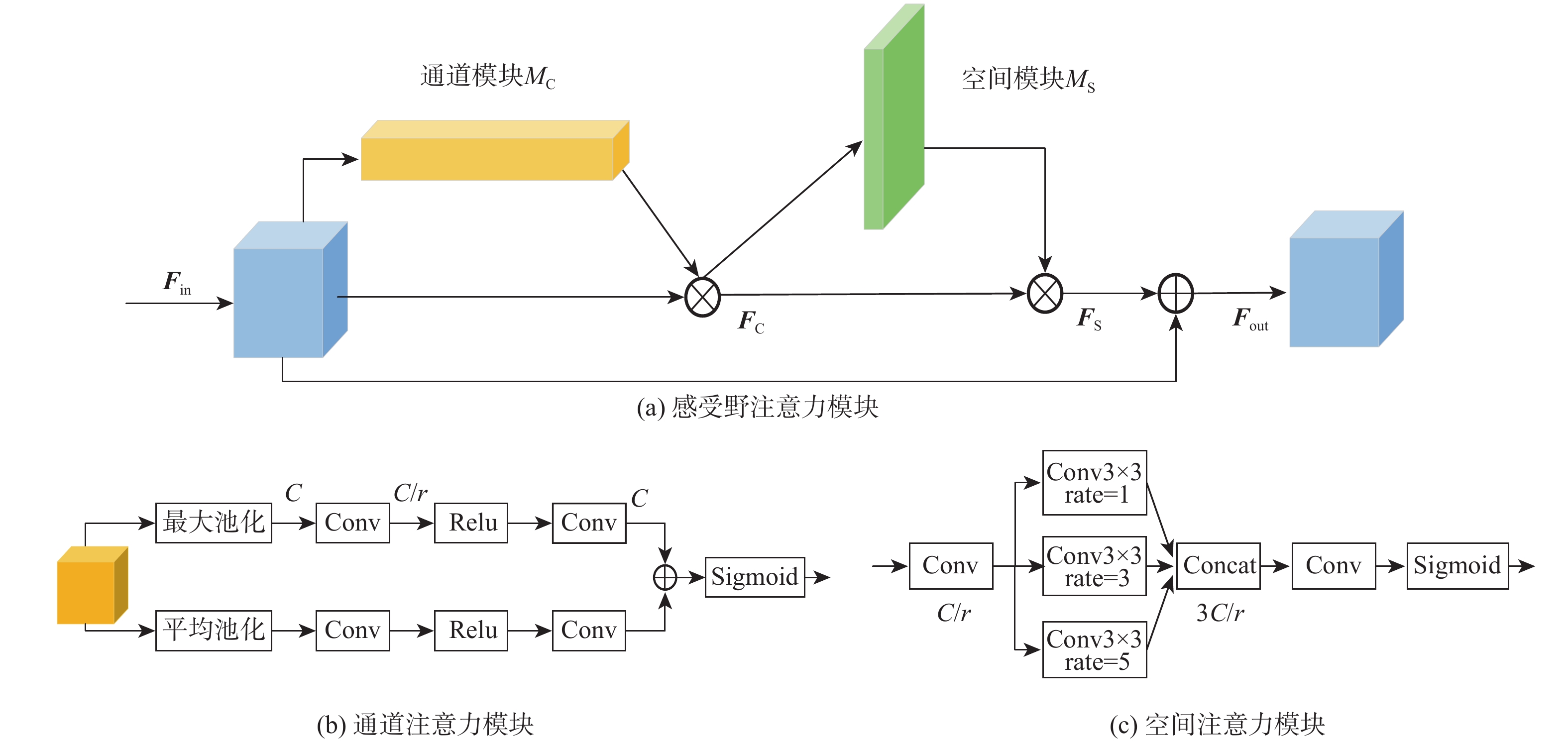
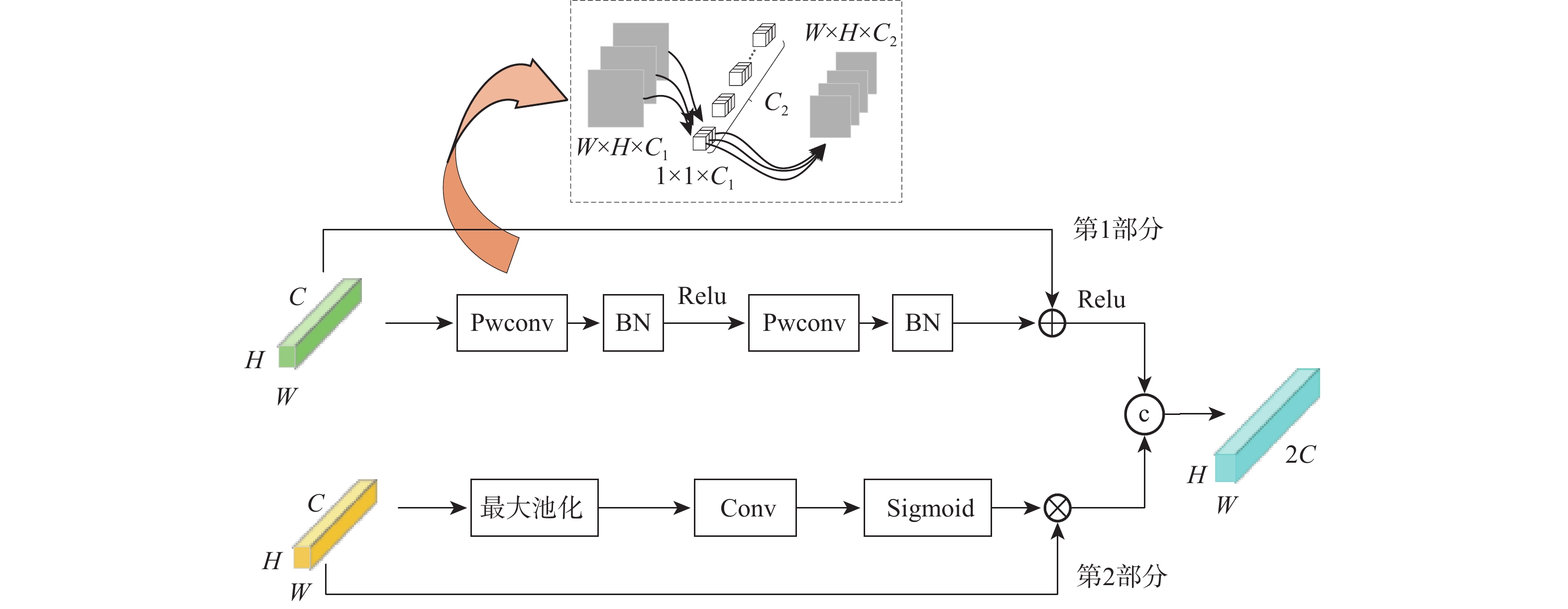
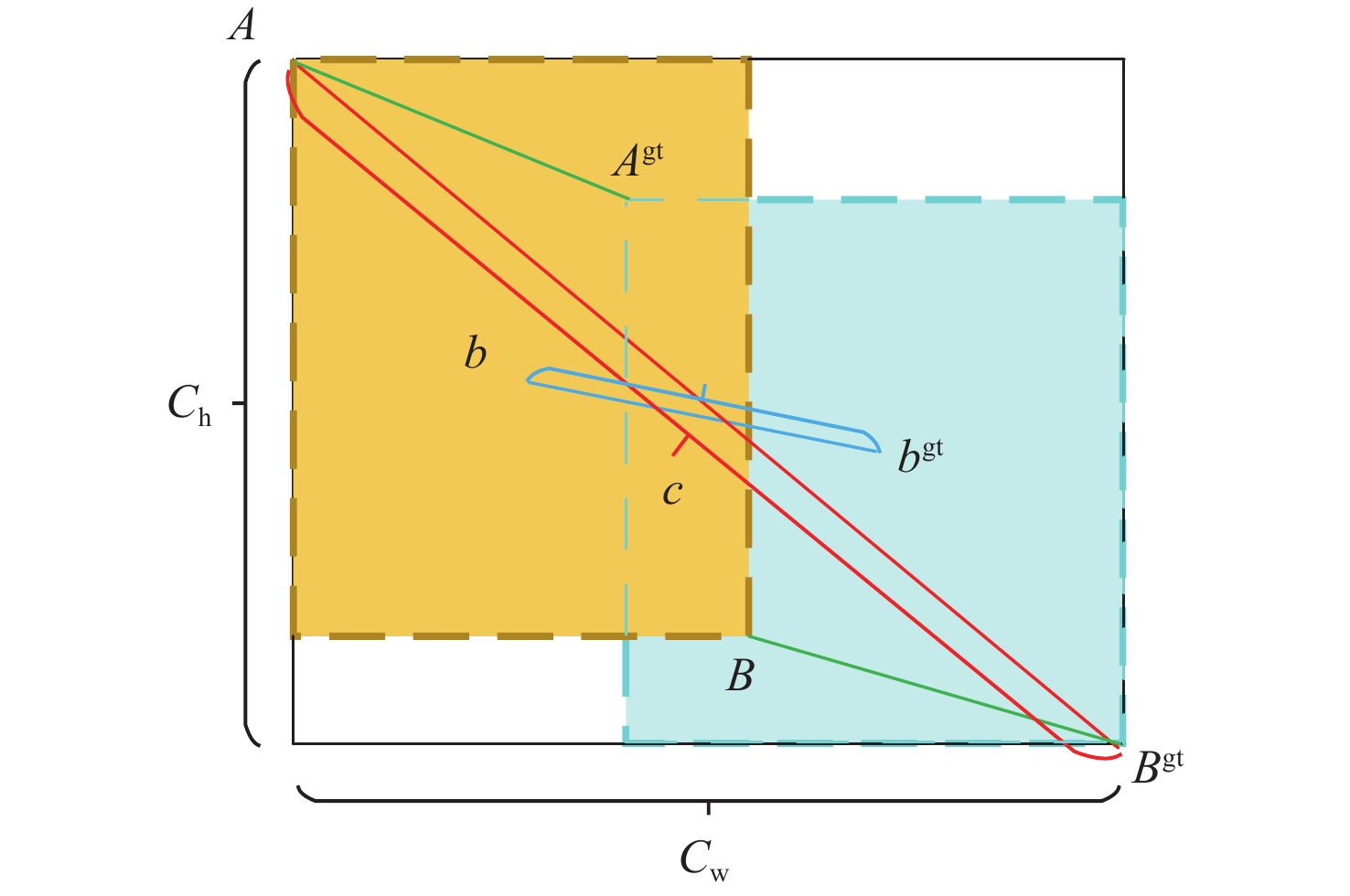
针对交通标志和交通灯等交通场景小目标特征不明显导致检测困难的问题,提出基于改进YOLOv5-s的交通场景小目标检测算法。设计特征补充模块(FSM),通过进一步获取浅层细节信息对相邻的深层检测层进行特征补充,有效提高了小目标的检测效果,并通过相邻层间的矩阵运算避免了特征冗余;设计有效融合模块(EFM),分别处理特征金字塔融合时的横向浅层特征和上采样特征,缓解二者之间的特征冲突,使其更有效的融合;提出超级增强交并比(SEIOU)损失计算方式,通过添加真实框和预测框主对角之间的距离度量,改善回归效果,提升检测精度。在CCTSDB、S2TLD、TLD和PASCAL VOC数据集上进行实验,结果表明:所提算法在精度上分别提升了2.54%、3.62%、4.33%和2.01%,检测速度达到了113帧/s,适用于实际交通场景下的检测任务。
-
关键词:
- YOLOv5-s算法 /
- 小目标检测 /
- 特征补充 /
- 特征融合 /
- 损失函数
Abstract:A traffic scene tiny target detection method based on enhanced YOLOv5-s was presented to address the issue that the properties of small targets in traffic scenes, such as traffic signs and traffic lights, are not readily apparent. Firstly, a feature supplement module (FSM) was designed to supplement the features of the adjacent deep detection layers by further obtaining the shallow details, which effectively improved the detection effect of small targets, and avoided feature redundancy by matrix operation between adjacent layers. Second, in order to reduce feature conflict and improve the effectiveness of the pyramid feature fusion, an effective fusion module (EFM) was created to handle the horizontal shallow feature and the upsampled feature, respectively. Then, the super enhanced intersection over union (SEIOU) loss calculation method was proposed to improve the regression effect and detection accuracy by adding the distance measurement between the main diagonal of the ground truth box and the prediction box. Finally, experiments were carried out on CCTSDB, S2TLD, the Traffic lights dataset and the PASCAL VOC dataset. According to the results, the proposed algorithm’s accuracy has increased by 2.54%, 3.62%, 4.33%, and 2.01%, respectively, and its detection speed has reached 113 frames per second, making it appropriate for detecting jobs in real-world traffic situations.
-
Key words:
- YOLOv5-s algorithm /
- small target detection /
- feature supplement /
- feature fusion /
- loss function
-
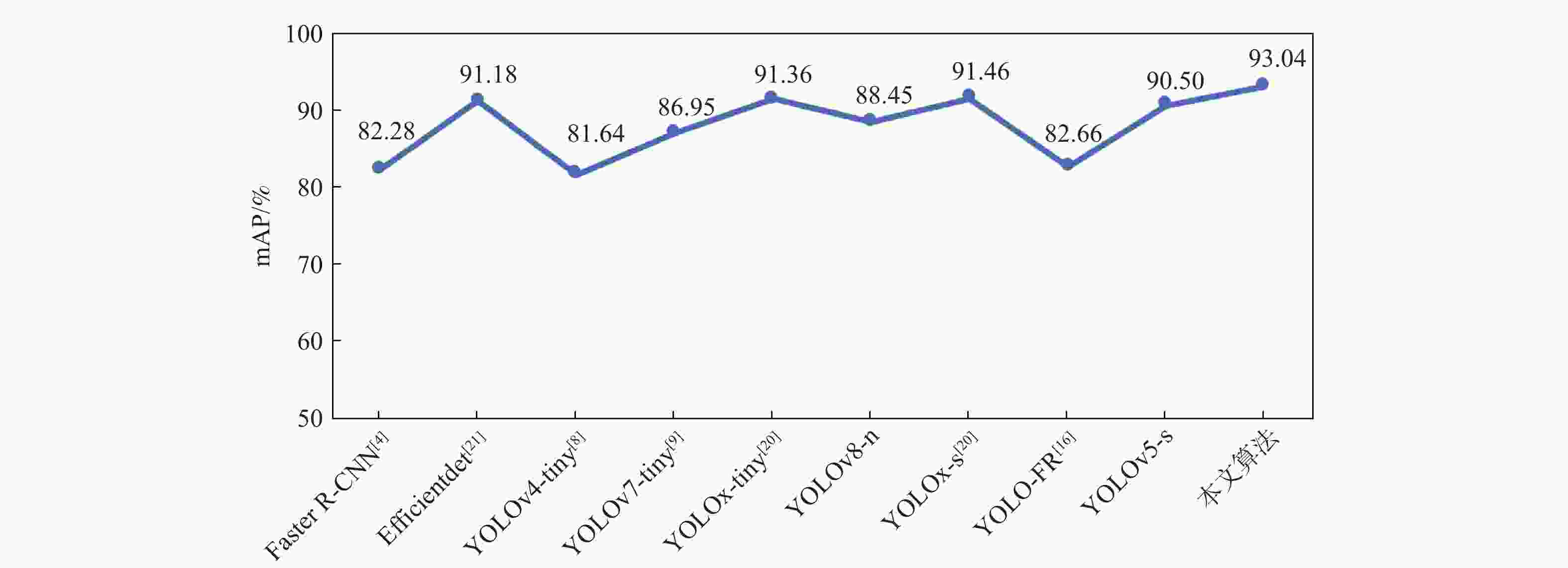
图 8 不同算法在CCTSDB数据集上检测结果
Figure 8. Detection results of different algorithms on CCTSDB dataset
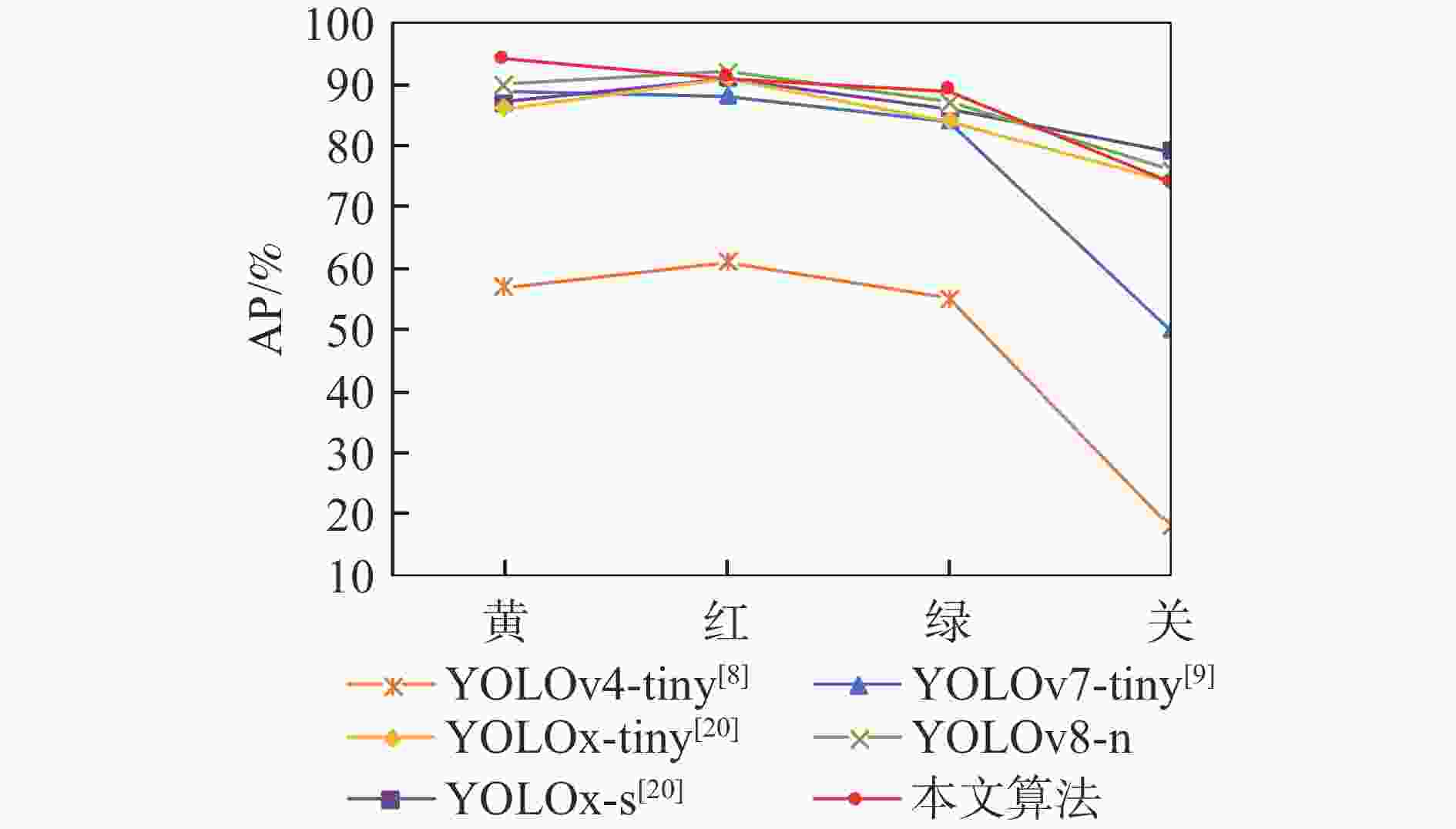
图 10 不同算法在S2TLD数据集上检测结果
Figure 10. Detection results of different algorithms on S2TLD dataset
表 1 CCTSDB数据集消融实验
Table 1. Ablation experiments of CCTSDB dataset
YOLOv5-s FSM EFM SEIOU mAP/% √ 90.50 √ √ 92.02 √ √ 91.76 √ √ 90.81 √ √ √ 92.56 √ √ √ √ 93.04  下载: 导出CSV
下载: 导出CSV
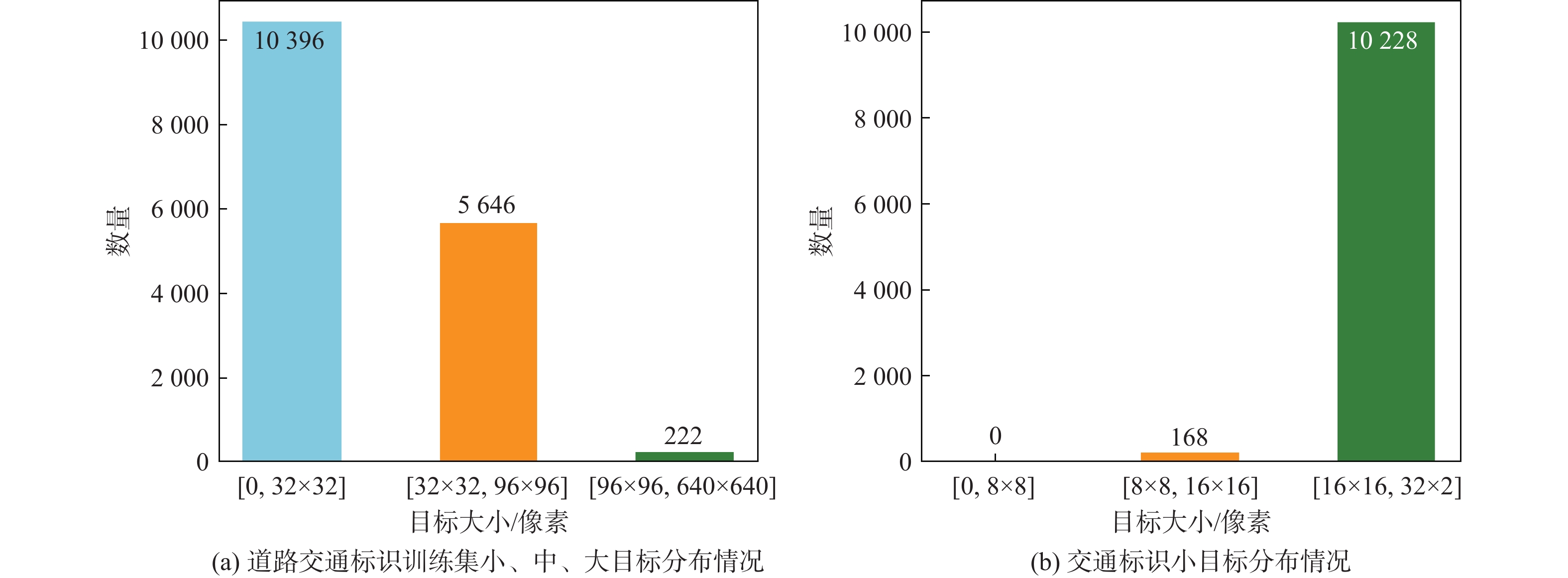
表 2 CCTSDB数据集上不同尺度目标检测结果
Table 2. Detection results of different scale targets on CCTSDB dataset
算法 AP/% AR/% 小目标 中目标 大目标 小目标 中目标 大目标 YOLOv5-s 38.5 67.4 83.5 47.5 74.4 89.5 本文算法 41.9 68.4 84.9 49.5 75.0 89.3
下载: 导出CSV
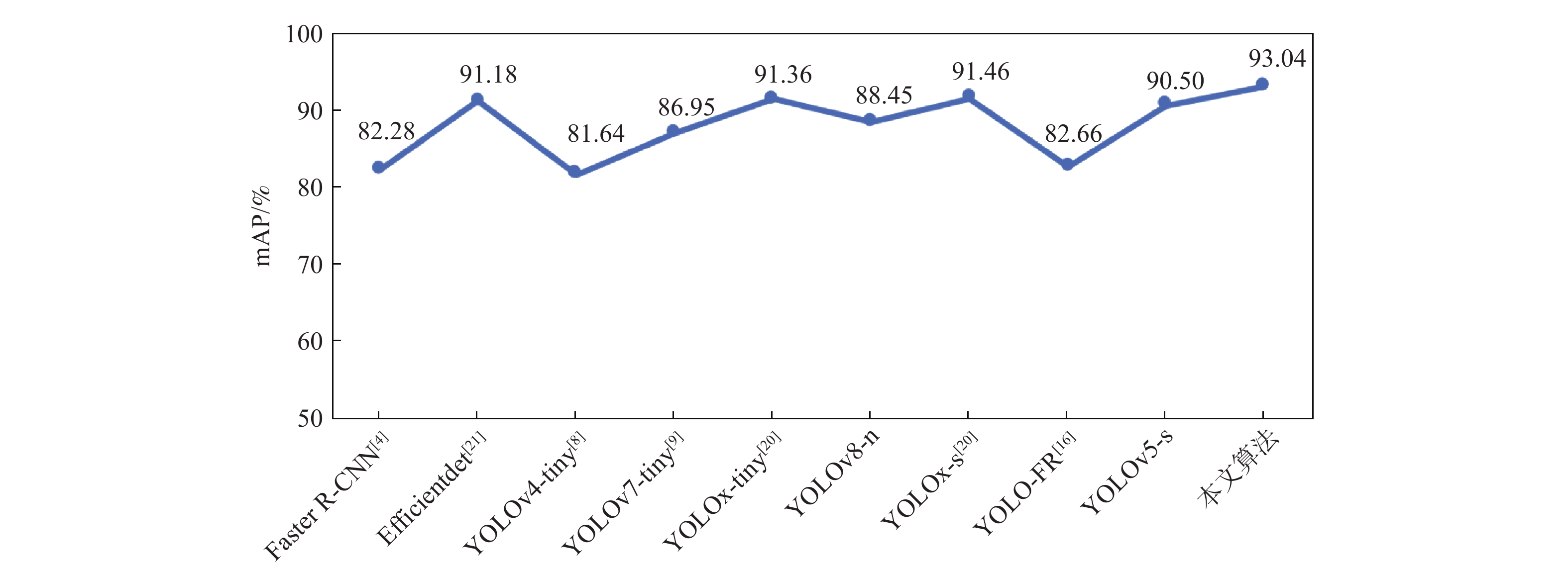
表 3 不同算法参数对比
Table 3. Comparison of different algorithm parameters
算法 mAP/% 参数量 检测速度/
(帧·s−1)Faster R-CNN[4] 82.28 28.4×106 29 Efficientdet[21] 91.18 6.5×106 34 YOLOv4-tiny[8] 81.64 5.9×106 271 YOLOv7-tiny[9] 86.95 6.0×106 140 YOLOv8-n 91.36 3.0×106 146 YOLOx-tiny[20] 88.45 5.0×106 103 YOLOx-s[20] 91.46 8.9×106 96 YOLO-FR[16] 82.66 6.5×106 94 YOLOv5-s 90.50 7.1×106 118 本文算法 93.04 8.8×106 113
下载: 导出CSV
表 4 内存相关参数量对比
Table 4. Comparison of memory-related parameters
算法 memory/MB (MemR+MemW)/MB Efficientdet[21] 673.26 1320.00 本文算法 333.75 558.43
下载: 导出CSV
表 5 S2TLD数据集上的消融实验
Table 5. Ablation experiments on S2TLD dataset
YOLOv5-s FSM EFM SEIOU mAP/% √ 83.17 √ √ 83.35 √ √ √ 86.37 √ √ √ √ 86.79
下载: 导出CSV
表 6 S2TLD数据集上不同尺度目标检测结果
Table 6. Detection results of different scale targets on S2TLD dataset
算法 AP/% AR/% 小目标 中目标 大目标 小目标 中目标 大目标 YOLOv5-s 30.4 53.2 76.7 42.6 63.8 78.1 本文算法 34.4 54.4 76.3 45.7 64.6 81.2
下载: 导出CSV
表 7 算法改进前后TLD数据集上的检测结果
Table 7. Detection results on TLD dataset before and after algorithm improvement
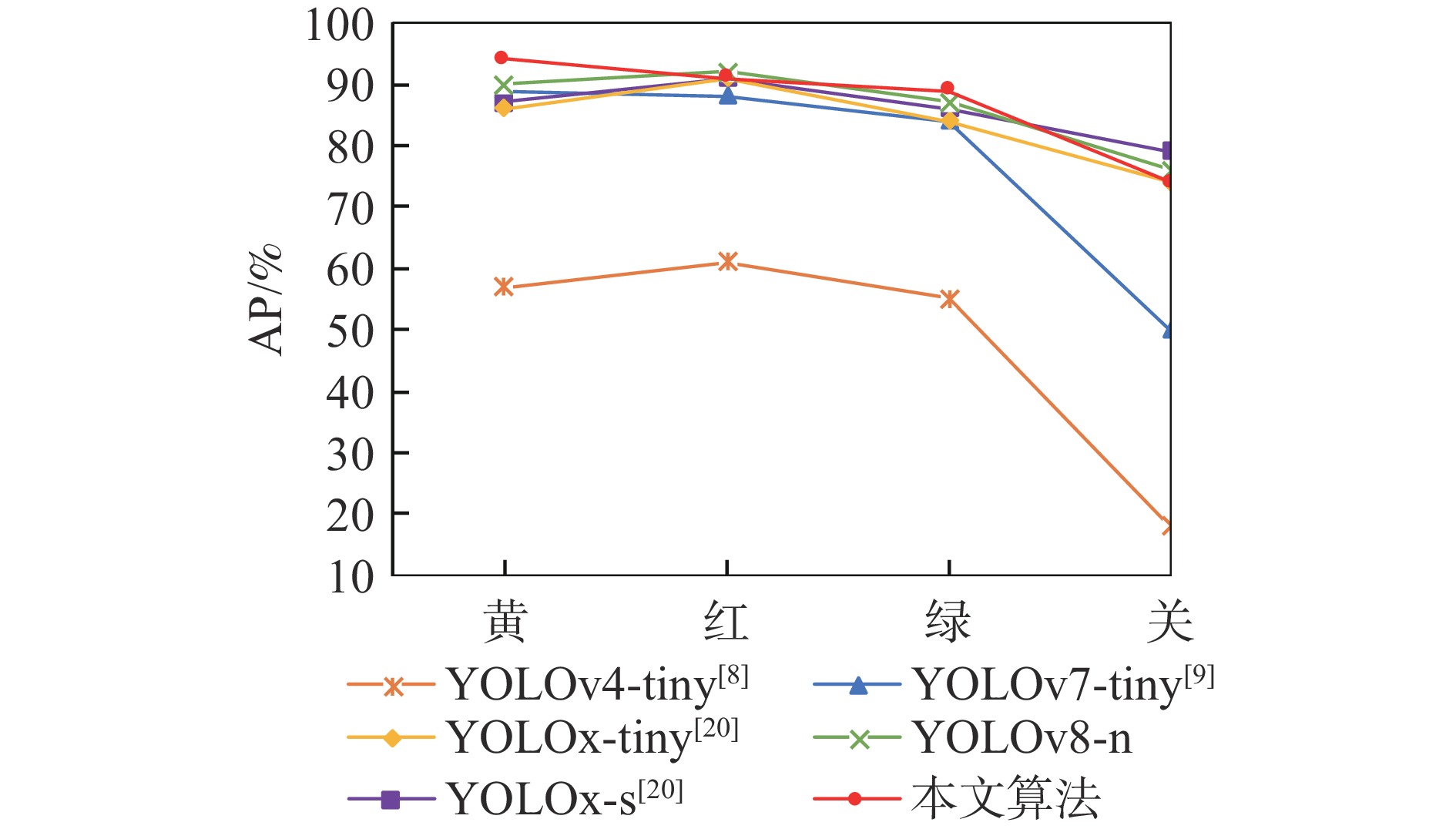
算法 AP/% mAP/% 红 绿 黄 关 YOLOv5-s 87.56 80.21 74.71 69.55 78.01 本文算法 89.98 85.48 78.57 75.32 82.34
下载: 导出CSV
表 8 TLD数据集上不同尺度目标检测结果
Table 8. Detection results of different scale targets on TLD dataset
算法 AP/% AR/% 小目标 中目标 大目标 小目标 中目标 大目标 YOLOv5-s 29.3 50.0 62.3 42.9 62.5 72.3 本文算法 31.5 52.6 58.5 44.4 63.5 65.3
下载: 导出CSV
表 9 算法改进前后PASCAL VOC数据集上的检测结果
Table 9. Detection results on PASCAL VOC dataset before and after algorithm improvement
算法 AP/% 飞机 自行车 鸟 船 瓶 巴士 汽车 猫 椅子 牛 YOLOv5-s 92.31 87.58 85.12 70.27 68.97 92.96 91.26 84.16 67.57 85.74 本文算法 91.95 90.13 92.32 74.15 69.61 95.42 91.02 86.89 69.72 89.46 算法 AP/% mAP/% 餐桌 狗 马 摩托车 人 盆栽 羊 沙发 火车 电视监视器 YOLOv5-s 60.81 82.28 92.67 83.67 92.60 59.70 87.68 75.89 86.50 89.42 81.84 本文算法 62.11 85.22 95.06 85.08 92.52 63.05 90.84 75.80 88.02 88.75 83.85
下载: 导出CSV
表 10 YOLOv7-tiny网络消融实验
Table 10. Ablation experiment of YOLOv7-tiny network
算法 AP/% mAP/% 禁止 指示 警告 YOLOv7-tiny 88.41 88.00 84.45 86.95 + FSM 90.42 89.09 90.28 89.93 + EFM 89.80 89.07 86.66 88.51 + SEIOU 88.64 88.88 85.07 87.53 + FSM+ EFM 91.77 90.18 90.37 90.77 +FSM+EFM+SEIOU 90.80 90.62 91.38 90.93
下载: 导出CSV
表 11 网络改进前后不同尺度目标检测结果
Table 11. Detection results of different scale targets before and after network improvement
算法 AP/% AR/% 小目标 中目标 大目标 小目标 中目标 大目标 YOLOv7-tiny 34.9 67.1 83.3 44.4 74.8 89.7 +FSM+EFM+SEIOU 41.0 67.6 82.1 49.6 74.8 88.5
下载: 导出CSV
-
[1] WANG Q Y, LI X Y, LU M. An improved traffic sign detection and recognition deep model based on YOLOv5[J]. IEEE Access, 2023, 11: 54679-54691. [2] LIU C S, LI S, CHANG F L, et al. Machine vision based traffic sign detection methods: review, analyses and perspectives[J]. IEEE Access, 2019, 7: 86578-86596. [3] 孙迎春, 潘树国, 赵涛, 等. 基于优化YOLOv3算法的交通灯检测[J]. 光学学报, 2020, 40(12): 143-151.SUN Y C, PAN S G, ZHAO T, et al. Traffic light detection based on optimized YOLOv3 algorithm[J]. Acta Optica Sinica, 2020, 40(12): 143-151(in Chinese). [4] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. [5] HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 2980-2988. [6] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//Proceedings of the Computer Vision-ECCV. Beilin: Springer, 2014: 346-361. [7] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08)[2024-01-02]. https://arxiv.org/abs/1804.02767. [8] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: opti- mal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2024-01-02]. http://arxiv.org/abs/2004.10934. [9] WANG C Y, BOCHKOVSKIY A, LIAO H M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 7464-7475. [10] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multi-box detector[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2016: 21-37. [11] 井方科, 任红格, 李松. 基于多尺度特征融合的小目标交通标志检测[J]. 激光与光电子学进展, 2024, 61(12): 372-380.JING F K, REN H G, LI S. Small object traffic sign detection based on multi-scale feature fusion[J]. Laser and Optoelectronics Progress, 2024, 61(12): 372-380(in Chinese). [12] 钱伍, 王国中, 李国平. 改进YOLOv5的交通灯实时检测鲁棒算法[J]. 计算机科学与探索, 2022, 16(1): 231-241.QIAN W, WANG G Z, LI G P. Improved YOLOv5 traffic light real-time detection robust algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 231-241(in Chinese). [13] YAO Y B, HAN L, DU C J, et al. Traffic sign detection algorithm based on improved YOLOv4-Tiny[J]. Signal Processing: Image Communication, 2022, 107: 116783. [14] SHI Y L, LI X D, CHEN M M. SC-YOLO: a object detection model for small traffic signs[J]. IEEE Access, 2023, 11: 11500-11510. [15] LI J Y, LIU C N, LU X C, et al. CME-YOLOv5: an efficient object detection network for densely spaced fish and small targets[J]. Water, 2022, 14(15): 2412. [16] MOU X G, LEI S, ZHOU X. YOLO-FR: a YOLOv5 infrared small target detection algorithm based on feature reassembly sampling method[J]. Sensors, 2023, 23(5): 2710. [17] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2020: 1571-1580. [18] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768. [19] ZHANG J M J, ZOU X, KUANG L D, et al. CCTSDB 2021: a more comprehensive traffic sign detection benchmark[J]. Human-centric Computing and Information Sciences, 2022, 12: 23. [20] YANG X, YAN J C, LIAO W L, et al. Scrdet++: detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(2): 2384-2399. [21] TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10778-10787. [22] CE Z, LIU S T, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. (2021-07-18)[2024-01-02]. https://arxiv.org/abs/2107.084. -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 461
- HTML全文浏览量: 188
- PDF下载量: 35
- 被引次数: 0
