



-
摘要:
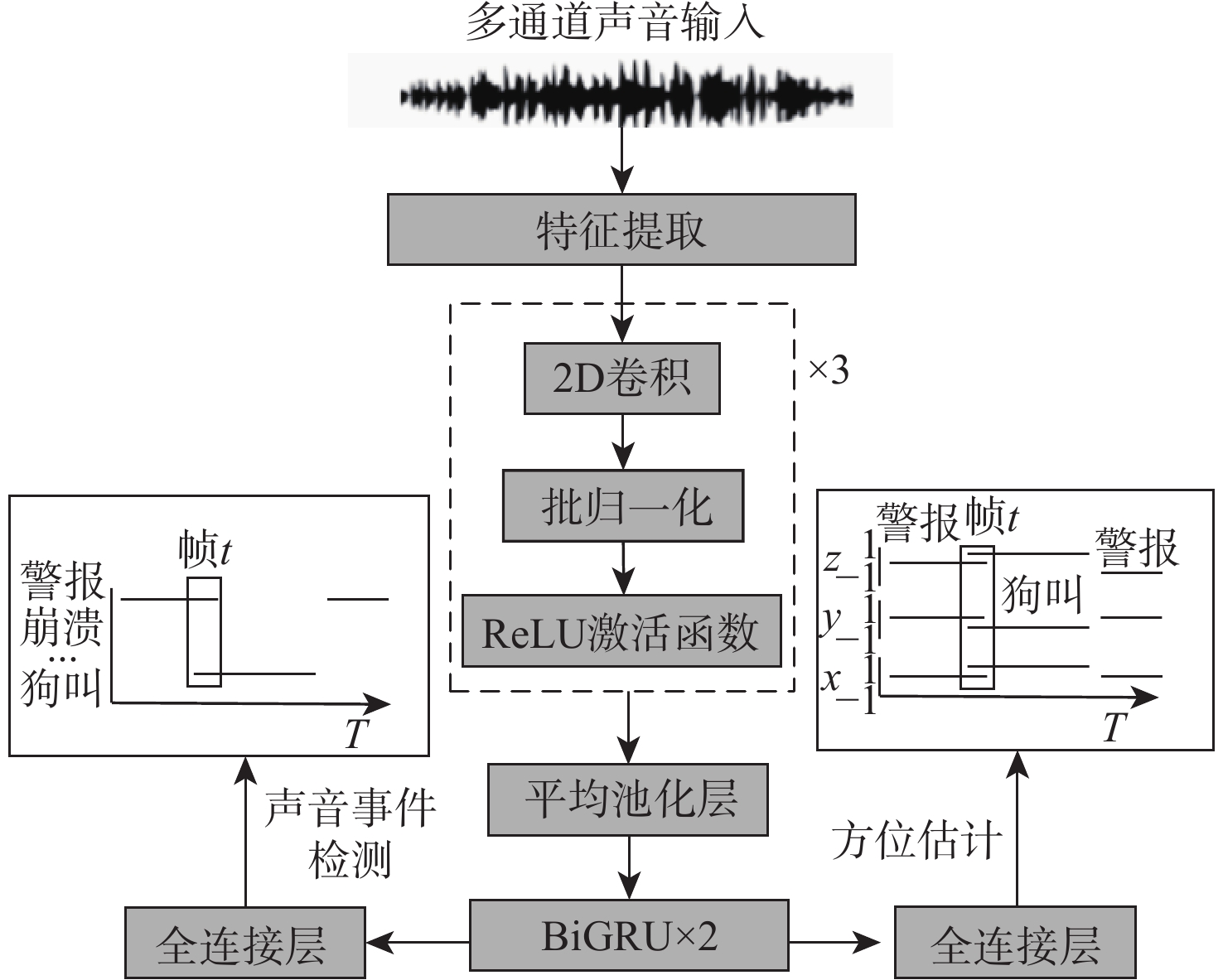
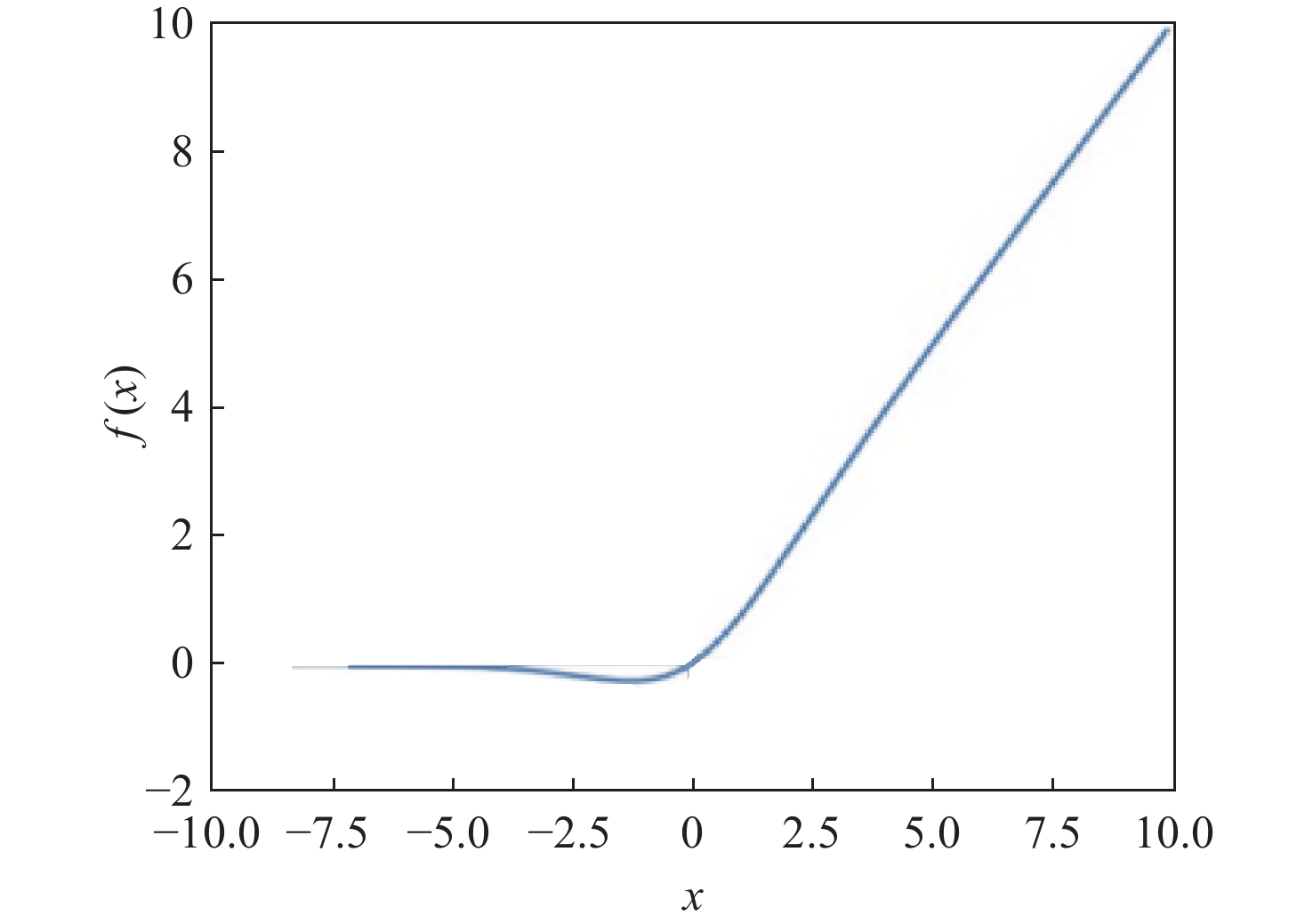
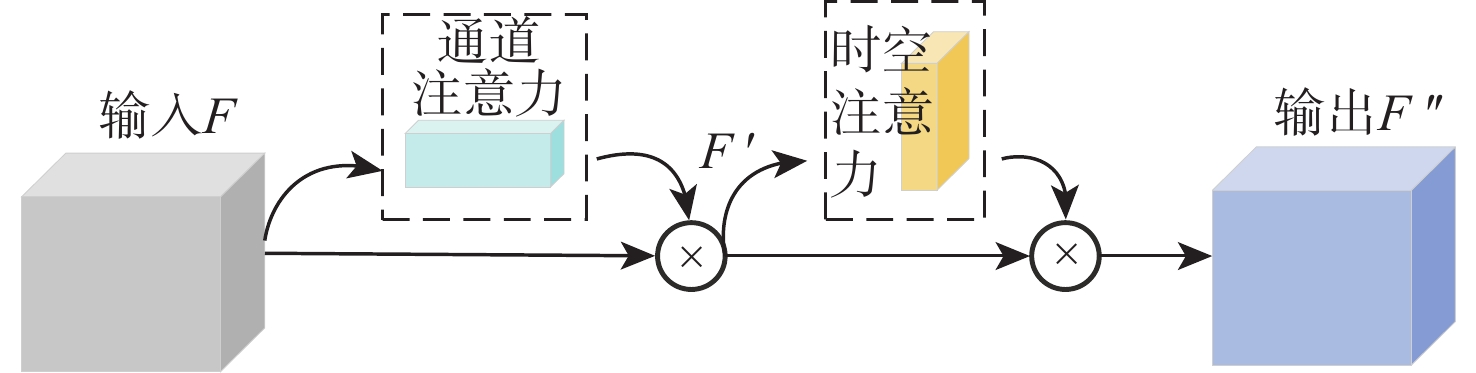
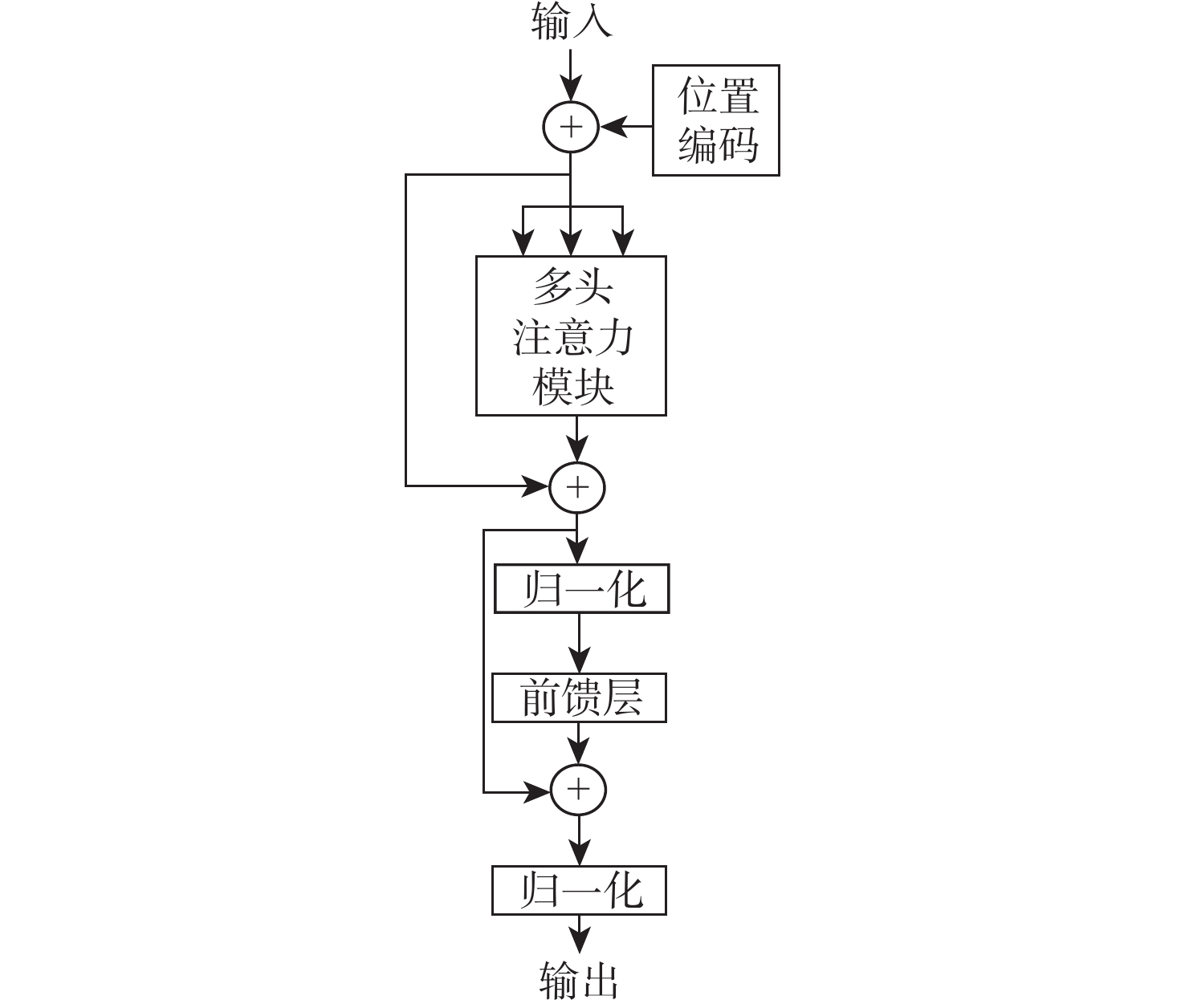
针对传统深度学习模型难以捕捉输入特征图中的长上下文特征关联及通道与空间维度上的关键特征信息,导致声音事件定位与检测(SELD)错误率高、性能不理想的问题,基于声学场景分类和声音事件检测挑战赛中的基线模型SELDnet,提出一种基于增强特征表达能力的声音事件定位与检测网络(FE-SELDnet)。采用组归一化和SiLU激活函数来解决函数无法反向传播导致神经元死亡的问题;引入卷积块注意力模块(CBAM)来捕捉声学特征中通道与空间2个维度的重要特征,抑制不必要的特征,加强网络对特征信息的敏感性和准确性,提高信息流动;引入Transformer模块来捕获更长的语音上下文特征关联,并结合局部特征,提升模型在声音事件定位与检测任务中的精确性和鲁棒性。在TUT Sound Events数据集上的实验结果表明:FE-SELDnet与基线网络性能相比有较大的提升,错误率从0.45降低到0.326,SED评分和DOA评分分别从0.45和0.32降至0.26和0.25,
F 1分数提高到79.4%,验证了FE-SELDnet具有更高的优越性。Abstract:To address the problem that traditional deep learning models are difficult to capture the long-context feature correlations in input feature maps as well as the key feature information in channel and spatial dimensions, resulting in high error rates and unsatisfactory performance in sound event localization and detection (SELD). Based on the baseline model SELDnet in the acoustic scene classification and sound event detection challenge, this paper proposes a feature enhanced sound event localization and detection network (FE-SELDnet). In order to address the issue of function failure to backpropagate, which leads to neuron death, it suggests using group normalization and the SiLU activation function; introducing the convolutional block attention module (CBAM) to capture significant features in both channel and spatial dimensions of acoustic features, suppressing superfluous features, improving network sensitivity and accuracy to feature information, and improving information flow; introducing the Transformer module to capture longer speech context feature association and combine local features to improve the accuracy and robustness of the model in sound event detection and localization tasks. The proposed FE-SELDnet significantly outperforms the original baseline network, according to experimental results on the TUT Sound Events dataset. The error rate decreased from 0.45 to 0.326, the SED and DOA scores decreased from 0.45 and 0.32 to 0.26 and 0.25, respectively, and the
F 1 score increased to 79.4%. The algorithm proposed in this paper has higher superiority. -
表 1 不同模型的评价指标
Table 1. Evaluation indexes of different models
方法 错误率↓ F1分数/%↑ DOA
评分↓SED
评分↓CRNNnet 0.428 71.2 0.42 0.31 CNN-Conformer 0396 72.4 0.39 0.301 M2MAST 0.374 74.1 0.375 0.291 FE-SELDnet
(本文)0.326 79.4 0.25 0.26 注: RE、SED评分、DOA评分越低,F1分数越高,SELD网络的性能越好,数据加黑表示性能最优。  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果比较
Table 2. Results comparison of ablation experiment
模型 错误率↓ F1
分数/%↑DOA
评分↓SED
评分↓SELDnet 0.45 68.7 0.32 0.45 SELDnet+GN、SiLU 0.34 76.6 0.27 0.34 SELDnet+GN、
SiLU+CBAM0.325 78.5 0.26 0.32 SELDnet+GN、
SiLU+CBAM+Transformer0.326 79.4 0.25 0.26
下载: 导出CSV
-
[1] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023. [2] DABRAN I, ELMAKIAS O, SHMELKIN R, et al. An intelligent sound alam recognition system for smart cars and smart homes[C]//Proceedings of the IEEE/IFIP Network Operations and Management Symposium. Piscataway: IEEE Press, 2018: 1-4. [3] SCHRÖDER J, MORITZ N, SCHÄDLER M R, et al. On the use of spectro-temporal features for the IEEE AASP challenge ‘detection and classification of acoustic scenes and events’ [C]//Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics. Piscataway: IEEE Press, 2013: 1-4. [4] HEITTOLA T, MESAROS A, ERONEN A, et al. Context-dependent sound event detection[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2013, 2013: 1. [5] KOMATSU T, TOIZUMI T, KONDO R, et al. Acoustic event detection method using semi-supervised non-negative matrix factorization with mixtures of local dictionaries[C]//Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016 Workshop. Budapest: [s.n.], 2016: 45-49. [6] XU X Y, YU J D, CHEN Y Y, et al. Leveraging audio signals for early recognition of inattentive driving with smartphones[J]. IEEE Transactions on Mobile Computing, 2018, 17(7): 1553-1567. [7] VELÁZQUEZ I M, REN Y, HANEDA Y, et al. A fusion method based on class rotations for DNN-DoA estimation on spherical microphone array[C]//Proceedings of the 29th European Signal Processing Conference. Piscataway: IEEE Press, 2021: 885-889. [8] 鄢社锋, 马远良, 侯朝焕. 宽带波束域相干信号子空间高分辨方位估计[J]. 声学学报, 2006, 31(5): 418-424.YAN S F, MA Y L, HOU C H. High resolution azimuth estimation of coherent signal subspace in broadband beam domain[J]. Journal of Acoustics, 2006, 31(5): 418-424(in Chinese). [9] 李伟红, 汤海兵, 龚卫国. 公共场所异常声源定位中时延估计方法研究[J]. 仪器仪表学报, 2012, 33(4): 750-756.LI W H, TANG H B, GONG W G. Research on time delay estimation method for abnormal sound source location in public places[J]. Chinese Journal of Instrumentation, 2012, 33(4): 750-756(in Chinese). [10] CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: USAACL, 2014: 1724-1734. [11] BAI S, KOLTER J Z, KOLTUN V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[EB/OL]. (2018-04-19)[2024-01-01]. https://arxiv.org/abs/1803.01271. [12] SHIMADA K, TAKAHASHI N, TAKAHASHI S, et al. Sound event localization and detection using activity-coupled cartesian DOA vector and RD3Net[EB/OL]. (2020-07-31)[2024-01-01]. https://dcase.community/documents/challenge2020/technical_reports/DCASE2020_Shimada_139.pdf. [13] TAKAHASHI N, MITSUFUJI Y. D3Net: densely connected multidilated DenseNet for music source separation[EB/OL]. (2021-05-27)[2024-01-01]. https://arxiv.org/abs/2010.01733v4. [14] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. (2023-08-02)[2024-01-01]. https://arxiv.org/abs/1706.03762. [15] BAI S J, KOLTER J Z, KOLTUN V. Trellis networks for sequence modeling[EB/OL]. (2019-05-11)[2024-01-01]. https://arxiv.org/abs/1810.06682. [16] ADAVANNE S, POLITIS A, NIKUNEN J, et al. Sound event localization and detection of overlapping sources using convolutional recurrent neural networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2019, 13(1): 34-48. [17] SAMEK W, BINDER A, MONTAVON G, et al. Evaluating the visualization of what a deep neural network has learned[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(11): 2660-2673. [18] BATTAGLINO D, LEPAULOUX L, EVANS N. Acoustic scene classification using convolutional neural networks[C]//Proceedings of the Detection and Classification of Acoustic Scenes and Events. Piscataway: IEEE Press, 2016: 1-5. [19] ZINEMANAS P, CANCELA P, ROCAMORA M. End-to-end convolutional neural networks for sound event detection in urban environments[C]//Proceedings of the 24th Conference of Open Innovations Association. Piscataway: IEEE Press, 2019: 533-539. [20] HAYASHI T, WATANABE S, TODA T, et al. Duration-controlled LSTM for polyphonic sound event detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(11): 2059-2070. [21] ZÖHRER M, PERNKOPF F. Virtual adversarial training and data augmentation for acoustic event detection with gated recurrent neural networks[C]//Interspeech 2017. [S.l.]: ISCA, 2017: 493-497. [22] HIRVONEN T. Classification of spatial audio location and content using convolutional neural networks[C]//Audio Engineering Society Convention 138. [S.l.]: Audio Engineering Society, 2015: 1-10. [23] GRUMIAUX P A, KITIĆ S, GIRIN L, et al. A survey of sound source localization with deep learning methods[J]. Journal of the Acoustical Society of America, 2022, 152(1): 107-151. [24] MEI P C, YANG J B, ZHANG Q, et al. A method of sound event localization and detection based on three-dimension convolution[C]//Proceedings of the 7th International Conference on Image, Vision and Computing. Piscataway: IEEE Press, 2022: 872-878. [25] CAO Y, KONG Q, IQBAL T, et al. Polyphonic sound event detection and localization using a two-stage strategy[EB/OL]. (2019-11-05)[2024-01-01]. https://arxiv.org/abs/1905.00268. [26] RANJAN R, JAYABALAN S, NGUYEN T N T, et al. Sound event detection and direction of arrival estimation using ResidualNet and recurrent neural networks[C]//Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop. [S.l.]: DCASE, 2019: 214-218. [27] NGUYEN T N T, NGUYEN N K, PHAN H, et al. A general network architecture for sound event localization and detection using transfer learning and recurrent neural network[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2021: 935-939. [28] ZHANG Y, WANG S, LI Z, et al. Data augmentation and class-based ensembled CNN-Conformer networks for sound event localization and detection[R]. [S.l.]: DCASE, 2021. [29] LEE S H, HWANG J W, SEO S B, et al. Sound event localization and detection using cross-modal attention and parameter sharing for DCASE2021 challenge[R]. [S.l.]: DCASE, 2021. [30] WU Y, HE K. Group normalization[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018. [31] RAMACHANDRAN P, ZOPH B, LE Q V. Swish: a self-gated active function[EB/OL]. (2017-10-27)[2024-01-01] https://arxiv.org/abs/1710.05941. [32] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]. Berlin: Springer, 2018: 3-19. [33] LIU Y, HOU M, LI A, et al. Automatic detection of timber-cracks in wooden architectural heritage using YOLOv3 algorithm[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2020, XLIII-B2-2020: 1471-1476. [34] POLITIS A, ADAVANNE S, KRAUSE D, et al. A dataset of dynamic reverberant sound scenes with directional interferers for sound event localization and detection[EB/OL]. (2021-07-04)[2024-01-01]. https://arxiv.org/sbs/2106.06999v2. [35] PARK S, JEONG Y, LEE T. Self-attention mechanism for sound event localization and detection[R]. [S.l.]: DCASE, 2021. -

 下载:
下载:
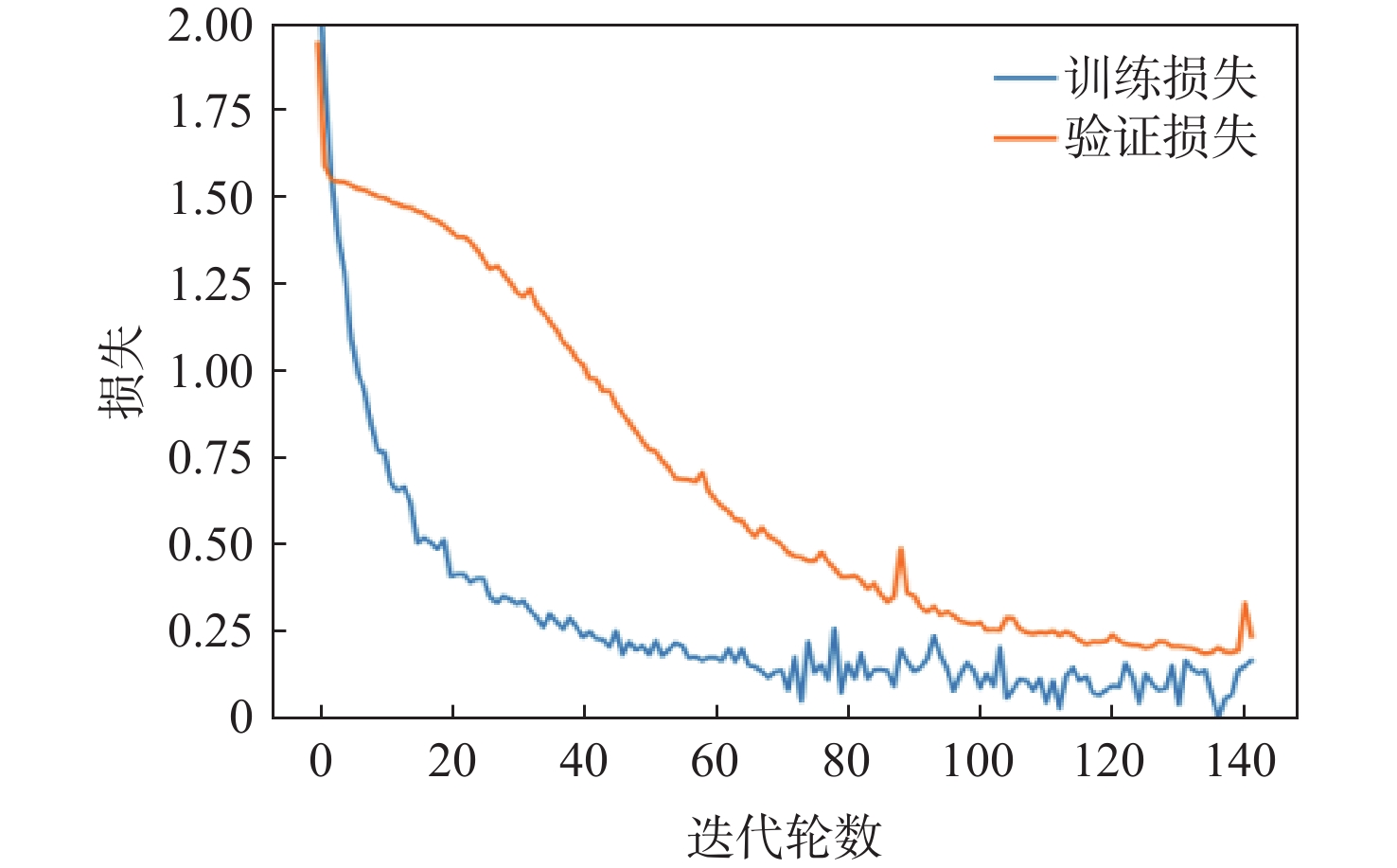
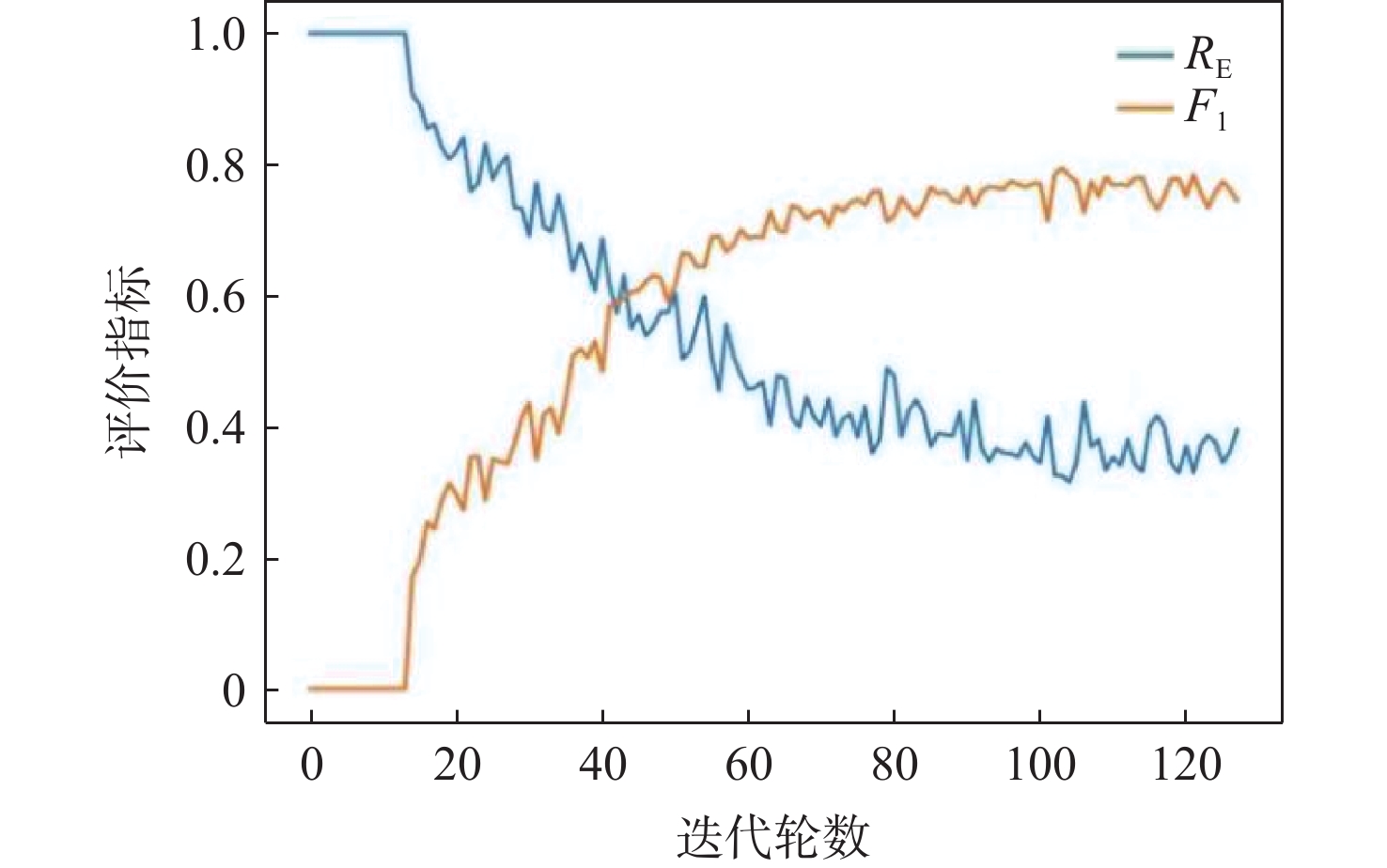
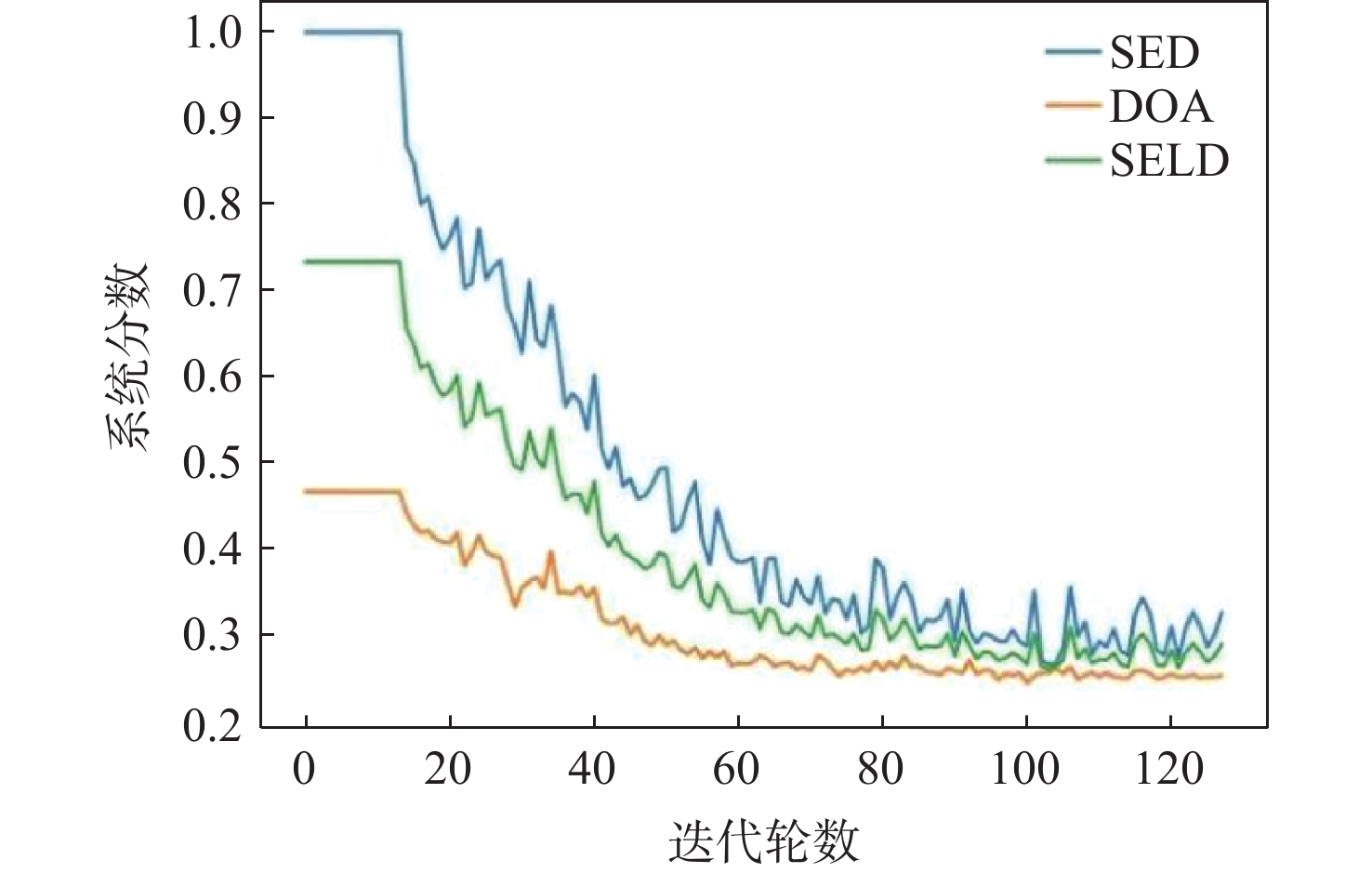

 点击查看大图
点击查看大图
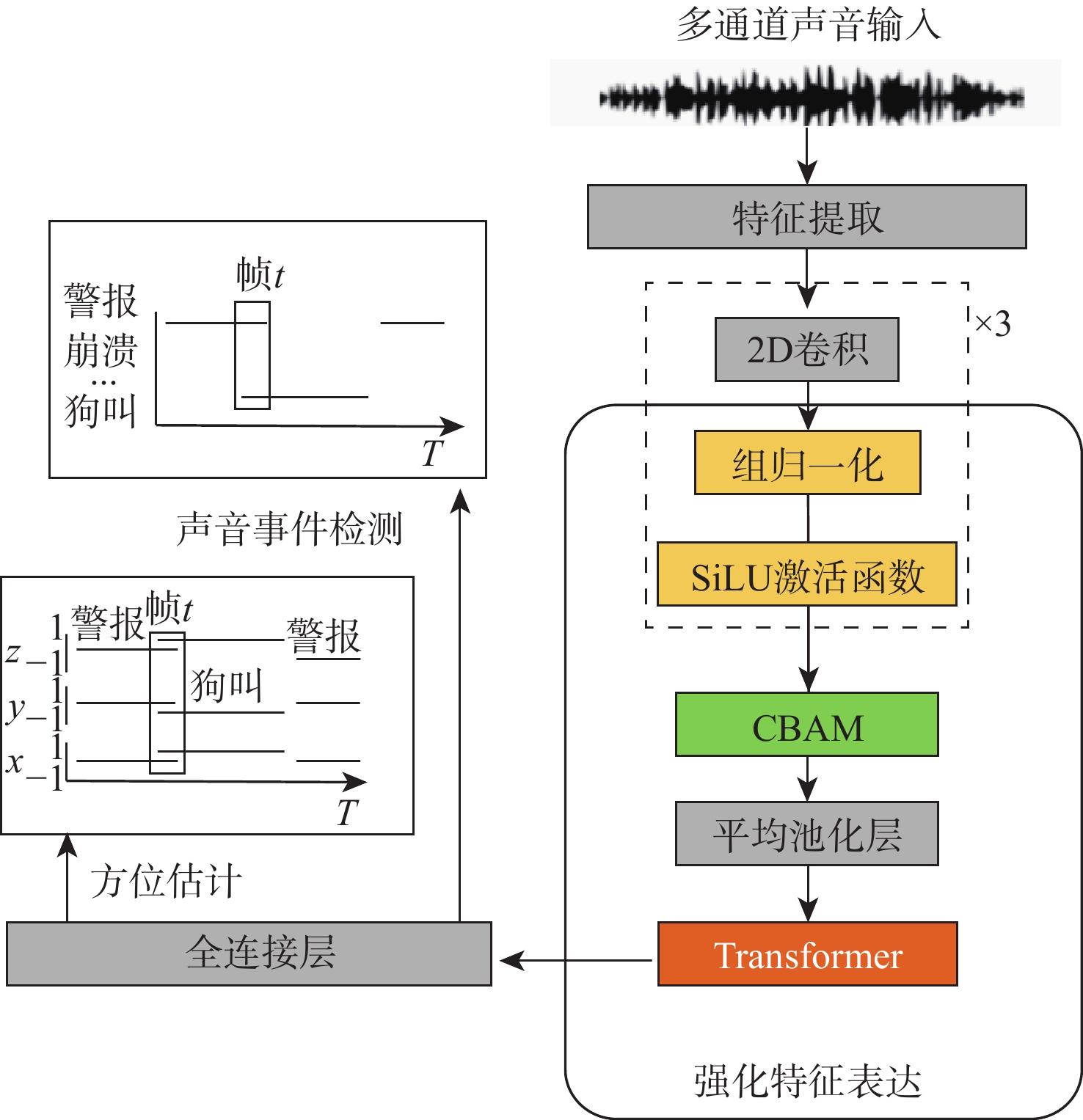
计量
- 文章访问数: 352
- HTML全文浏览量: 139
- PDF下载量: 15
- 被引次数: 0
